
- 12022_AAAI_Meta-Learning for Online Update of Recommender Systems_aaai 模板在哪下载
- 2java.nio.file.InvalidPathException: Illegal char <“> at index 0:_java.nio.file.invalidpathexception: illegal char <
- 3基于JerseyToken安全设计
- 4Lua常用C API与C/C++交互
- 5Linux基础——MySQL(二)命令_ps -ef|grep mysql
- 6VMware安装Linux详细教程_vmware怎么用linux
- 7解决虚拟机安装docker报错 cannot find a valid baseurl for repo:base/7/x86_64_cannot find a valid baseurl for repo: base/7/x86_6
- 8java如何filechooser选择盘,Android第三方文件选择器aFileChooser使用方法详解
- 9添加Docker的官方GPG密钥出错,Add Docker’s official GPG key._添加 docker 官方 gpg 密钥 连接出错
- 10[图像处理]水平集(Level set)算法实现思路(简化)_水平集算法
基于Python的淘宝用户购物数据可视化分析_基于python的淘宝数据可视化分析
赞
踩
摘 要
淘宝是中国最大的电子商务平台,拥有数亿注册用户。随着互联网与电商平台的发展,网上购物正成为国内消费者购物的重要方式。在重要的电商平台淘宝中,用户通过浏览商品详情页、收藏、加购或直接购买等方式来进行网上购物。因此,通过对淘宝用户行为的数据分析,可以挖掘潜藏在用户行为数据背后的价值信息,制定提升电商的整体营收的策略。
淘宝用户分析的数据可视化项目旨在通过收集、整理和分析淘宝用户的购物行为、浏览习惯、消费偏好等数据,以图表、图像等形式直观地展示出来,帮助商家更好地理解用户需求,优化商品推荐策略,提高销售业绩。
我们使用Python、FineBI技术通过对大量用户数据的挖掘和分析,还可以发现潜在的市场趋势和消费者需求,为产品研发和市场营销提供决策支持。同时,对于政策制定者来说,也可以通过对淘宝用户数据的分析,了解社会经济状况,制定相应的政策措施。
关键词:Python;FineBI;淘宝用户;数据分析;购物
Taobao is the largest e-commerce platform in China, with hundreds of millions of registered users. With the development of the Internet and e-commerce platforms, online shopping is becoming an important way for domestic consumers to shop. On the important e-commerce platform Taobao, users shop online by browsing product details pages, bookmarking, adding purchases, or making direct purchases. Therefore, by analyzing the data of Taobao user behavior, the value information hidden behind user behavior data can be excavated, and strategies to improve the overall revenue of e-commerce can be formulated.
The data visualization project for Taobao user analysis aims to collect, organize, and analyze data on Taobao users' shopping behavior, browsing habits, consumption preferences, etc., and visually display them in the form of charts, images, etc., helping businesses better understand user needs, optimize product recommendation strategies, and improve sales performance.
We use Python and FineBI technologies to mine and analyze a large amount of user data, and can also discover potential market trends and consumer demands, providing decision support for product development and marketing. At the same time, for policy makers, they can also understand the socio-economic situation and formulate corresponding policy measures through the analysis of Taobao user data.
Key words:Python; FineBI; Taobao users; Data analysis; shopping
目录
1 绪论
1.1 引言
淘宝是中国最大的电子商务平台,拥有数亿注册用户。随着互联网与电商平台的发展,网上购物正成为国内消费者购物的重要方式。在重要的电商平台淘宝中,用户通过浏览商品详情页、收藏、加购或直接购买等方式来进行网上购物。因此,通过对淘宝用户行为的数据分析,可以挖掘潜藏在用户行为数据背后的价值信息,制定提升电商的整体营收的策略。
淘宝用户分析的数据可视化项目旨在通过收集、整理和分析淘宝用户的购物行为、浏览习惯、消费偏好等数据,以图表、图像等形式直观地展示出来,帮助商家更好地理解用户需求,优化商品推荐策略,提高销售业绩。
此外,通过对大量用户数据的挖掘和分析,还可以发现潜在的市场趋势和消费者需求,为产品研发和市场营销提供决策支持。同时,对于政策制定者来说,也可以通过对淘宝用户数据的分析,了解社会经济状况,制定相应的政策措施。
1.1.2选题研究意义
1. 提升用户体验:通过对淘宝用户的购物行为、偏好等数据进行分析和挖掘,可以为平台提供有针对性的改进建议,从而优化商品推荐、搜索排序等功能,提升用户在平台上的购物体验。
2. 指导营销策略:通过对淘宝用户的行为数据进行分析,可以发现用户的消费习惯、喜好等信息,为平台制定个性化的营销策略提供依据,提高营销效果。
3. 优化运营决策:通过对淘宝用户数据的可视化分析,可以帮助商家了解商品的销售情况、用户的需求变化等信息,为平台运营决策提供有力支持。
4. 促进电商行业发展:淘宝用户分析的数据可视化研究可以为整个电商行业的发展提供有益的经验和借鉴,推动行业的创新和发展。
5. 培养数据人才:通过开展淘宝用户分析的数据可视化研究,可以培养具备数据分析和可视化技能的专业人才,满足大数据时代对人才的需求。
总之,淘宝用户分析的数据可视化研究具有重要的理论和实践意义,有助于提升淘宝平台的竞争力,促进电商行业的持续发展。
2.1.1Python
Python是一种解释型、编译型、互动式和面向对象的脚本语言,它的设计具有很强的可读性。Python提供了高效的高级数据结构,并且能以简单有效的方式进行面向对象编程。此外,Python在人工智能大范畴领域内的机器学习、神经网络、深度学习等方面都是主流的编程语言,得到了广泛的应用和支持。
Python在数据分析方面具有显著的优势。首先,Python的语法简洁高效,易于理解,非常适合初学者入门。其次,Python拥有一个巨大且活跃的科学计算社区,这为使用者提供了强大的后盾。此外,Python在数据分析、探索性计算、数据可视化等方面都有非常成熟的库和活跃的社区,这使得Python成为数据处理的重要解决方案。
Python拥有一个巨大且活跃的科学计算社区。无论在数据分析、探索性计算、还是数据可视化等方面,Python都有非常成熟的库和活跃的社区支持,这使得Python成为数据处理的重要解决方案。
Python的一些核心库如NumPy、Pandas、Matplotlib、Scikit-learn等,为处理中型数据提供了很好的支持。特别是Pandas,它为我们提供了大量用于处理和分析数据的功能,使我们的工作变得更加简单和高效。另外,Python还支持交互式编程,使得数据分析的过程更加灵活和方便。
2.1.2FineBI
FineBI是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品,它是一种强大且易用的数据分析工具。FineBI支持多种数据源、图表、函数、预警、分享等功能,可以帮助企业快速搭建面向全员的BI数据分析平台,提升业务效率和决策能力。
FineBI的数据可视化处理和智能分析功能非常出色,用户只需要简单地拖拽即可实现各种维度和各种形式的分析。此外,它还侧重于数据分析场景并支持各种分析模型的搭建。这些特性使得FineBI能够更好地满足用户的多样化数据分析需求。
2.2.1数据来源
本数据来源于阿里平台天池数据库的淘宝用户数据
2.2.2数据解释
本实验数据包含以下内容:
- user id: 用户的唯一标识符,用于区分不同的用户。
- Product ID: 产品的唯一标识符,用于区分不同的产品。
- Product category ID: 产品类别的唯一标识符,用于将产品分类到不同的类别中。
- Behavior type: 用户的行为类型,包含buy、cart、pv、fav分别表示为buy: 表示用户的购买行为,可能包括购买的产品数量或金额等信息;cart: 表示用户购物车中的商品信息,可能包括商品ID、数量等;pv: 表示页面浏览量,即用户访问某个页面的次数;fav: 表示用户对某个产品的喜好程度,可能通过评分或其他方式进行表示。
- day: 行为发生的日期。
- buy_amount: 用户购买的金额或数量。
- address: 用户的地址信息,包括国家地址省份。
3数据分析处理

图3-1读取文件数据显示前5行
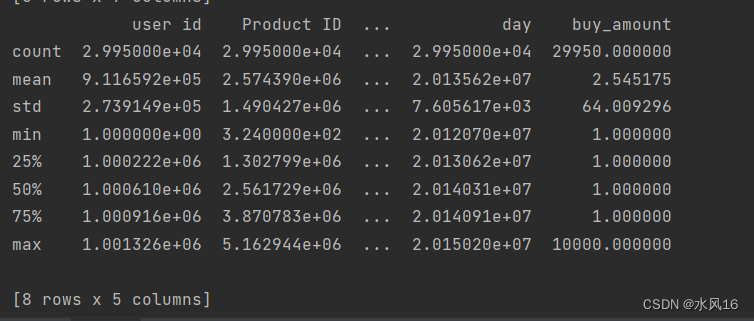

图3-3将数据集中每列的英文标签转换为中文标签
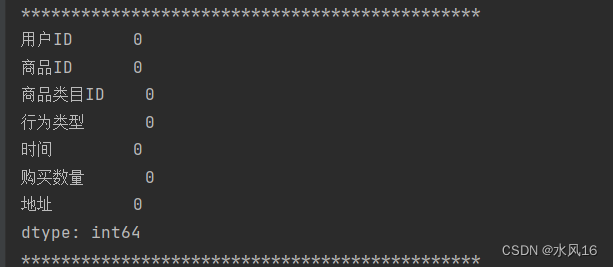
图3-4检测数据中是否有空缺值
可以看出数据集包含用户ID、商品ID等标量,而且数据集中无数据缺失等问题

图3-5显示‘行为类型’数据列的类型
行为类型这列数据中主要包含’pv’,’fav’,’buy’,’cart’这四中类型。

图3-6行为类中各类型占比
结果可以看出,用户中pv类型的行为类型购物次数最多,而pv表示页面浏览量,即用户访问某个页面的次数,这代表绝大多数的用户购买是根据该商品的页面浏览量来决定的,即pv可以作为评判用户等级的重要标签。

图3-7销量排名前十的商品
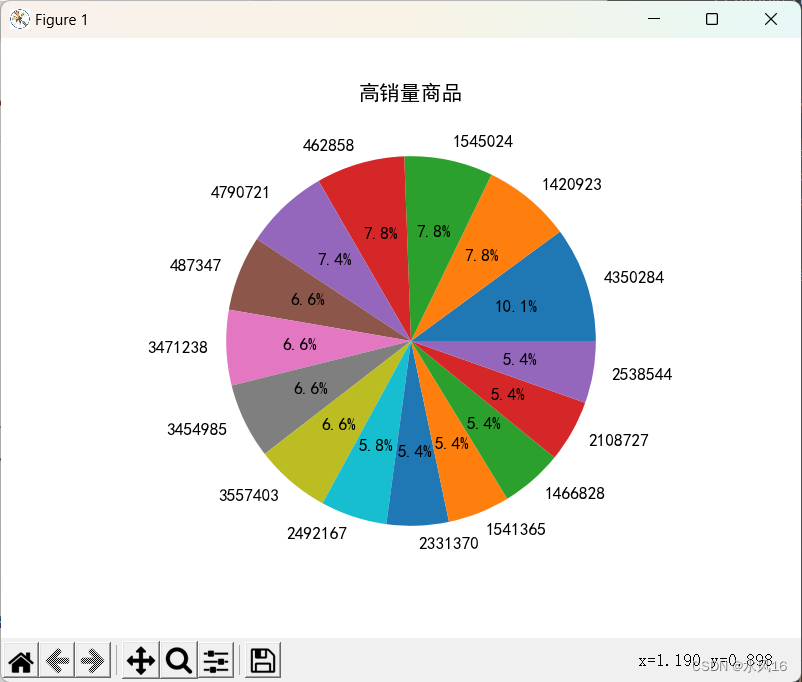
图3-8高销量商品占比
结果可以看出商品ID为350284的商品销售量远远超出其他商品,462858、420923、545024等商品销售量持平,471238、487347、492157等商品销售量稍逊其他商品。
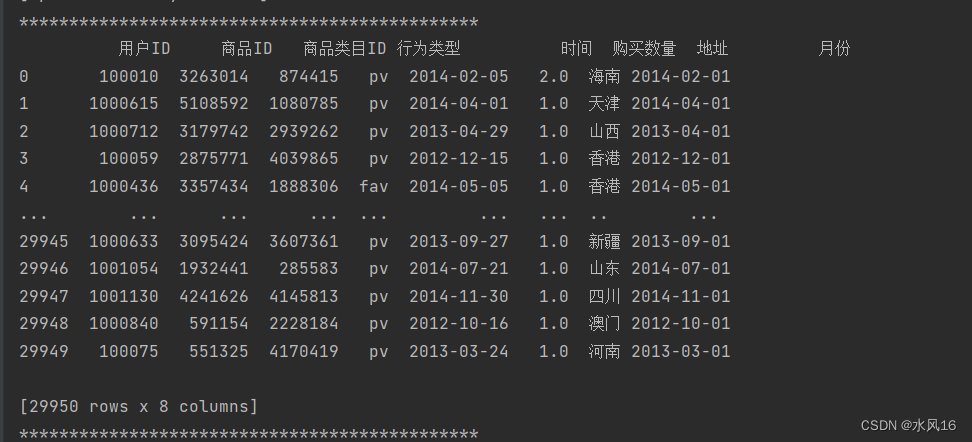
图3-9将时间转换为对应每月的一号

图3-10购买数量与时间折线图
结果分析:从横坐标时间轴可以看出在时间点附近或中间,折线都会出现波峰,且波峰不断增长;即用户的购买数量都会短暂的小幅度或大幅度的增长,而且随着时间的不断推进,此时间点的购买数量也不断增加;这些时间点都位于假期或春节附近,而这段时间的促销活动往往也会特别多,这代表用户越来越喜欢在有促销活动时购买商品。因此,商家可以多多增加促销活动次数或者增加打折商品的种类数量,这也代表这促销活动这一市场的影响在不断扩大,而且逐年成正增长趋势。
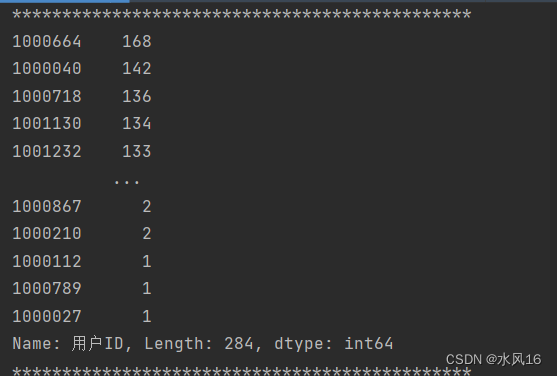
图3-11用户总共购买次数
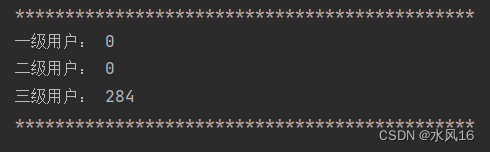
图3-12 2013年用户分级状况



图3-13 三年用户分级对比

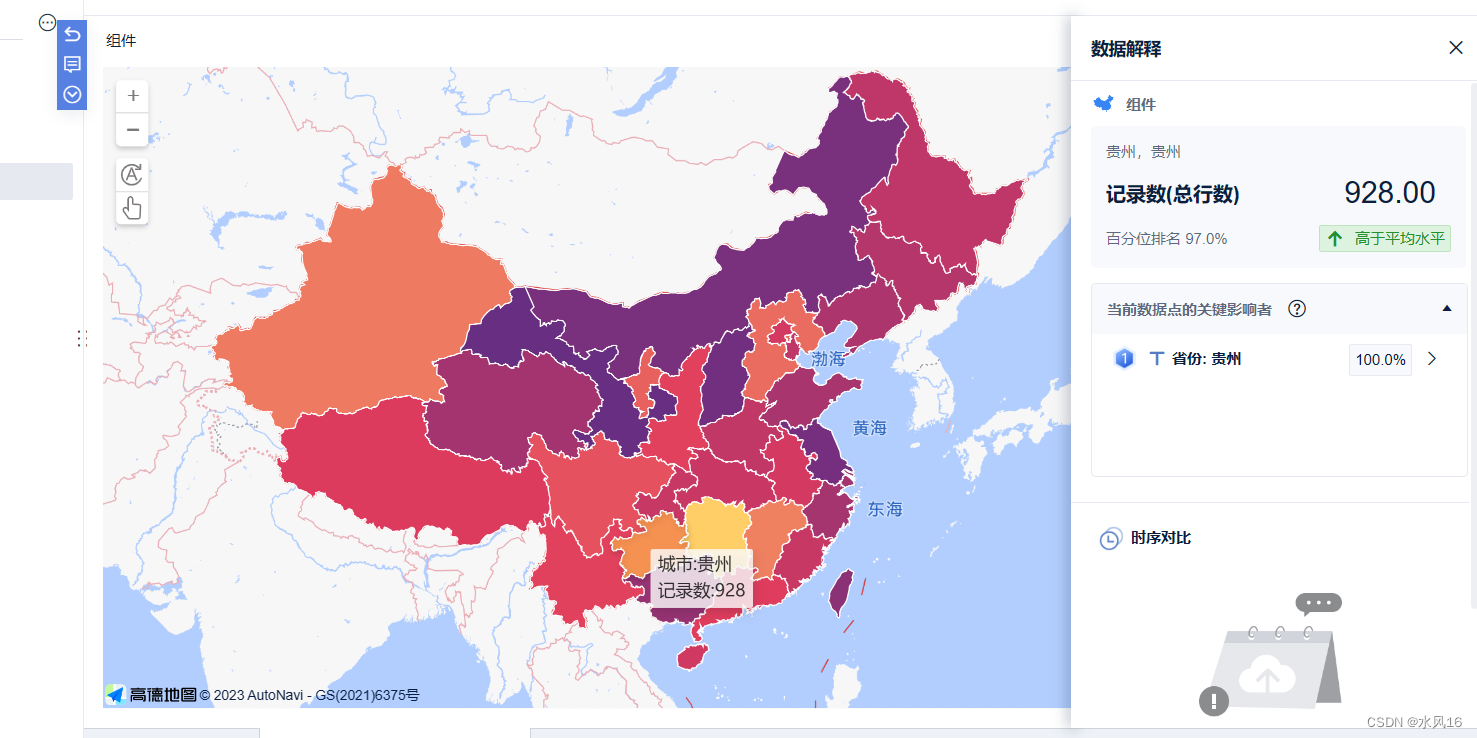

图3-14各地区用户数量对比(使用FineBI 6.0 在线分析)
结果分析可以看出2012年的三级用户为260,2013年的三级用户为284,2014年的三级用户为280,二级用户为4,每年的三级用户在不断增加,甚至在2014年新增加了4个二级用户,这也代表平台往常的运营模式是比较不错,在巩固老用户的基础上,不断吸引新用户的加入,但该模式需要稍做调整以应对更高等级的用户。地图方面可以看出颜色越鲜艳的地区购买商品用户人数越多,如:湖南、新疆、贵州等地区,商家应该增加对这些地区的快递、商品服务等。
1.购物行为分析:我们发现淘宝用户的购物行为呈现出明显的季节性和周期性。例如,每年的双十一、双十二等电商促销活动期间,用户的购物热情明显高涨。因此,商家可以在这些时间节点推出更多的优惠活动,以吸引更多的消费者。
2.用户偏好分析:通过对高销量商品分析,发现用户对于时尚服饰、美妆护肤、家居用品等类目的关注度较高。此外,用户对于品牌的认知度也较高,更倾向于购买知名品牌的商品。因此,淘宝可以加大对这些类目的投入,提高品牌商家的曝光度,提升用户购物体验;
3.消费习惯分析:根据用户的行为类型分析,发现用户更倾向于购买价格适中、品质可靠的商品。此外,用户对于新品的接受度较低,更愿意购买销量高、口碑好的商品。因此,淘宝可以加强对热销商品的推广,同时优化新品的上线策略,提高新品的销量和口碑。
1.针对不同品类的用户需求,商家可以制定差异化的营销策略,如举办限时折扣、满减活动等,吸引用户购买;
2.通过对用户数据分析,商家可以更好地了解用户需求和喜好,从而制定更有针对性的营销策略。例如,可以通过社交媒体、短视频等渠道进行广告投放,以吸引更多的潜在消费者;
3.提高商品质量和服务水平是提高用户满意度的关键。商家应加强对供应链的管理,确保商品质量;同时,完善售后服务体系,提升用户购物体验。
总之,通过对淘宝用户数据的深入分析,我们为商家提供了有针对性的营销策略建议,有助于提高商家的销售额和客户满意度。在未来的工作中,我们将继续关注淘宝用户数据的变化,为商家提供更多有价值的信息和建议。
[1]张盼.网购用户在线行为分析——基于淘宝网的实证研究[D].西南财经大学,2013
[2]蒋元芳.淘宝店铺数据化运营的研究[J].中国商贸,2013,F724.6
[3]赵红.天猫店铺BD需求前期数据分析——以“天猫眼镜专营店“为例[J].新经济,2015,F721
[4]张磊.NJ淘宝店营销策略优化研究[D].兰州交通大学,2017
[5]雷兵;常知刚;钟镇.基于网络店铺订单数据的群体用户画像构建研究[J].河南工业大学学报(社会科学版),2019,F274
[6]朱春颖.基于面板数据的店铺生成内容对销量影响研究[D]大连理工大学,2020
[7]马国勤.基于数据分析挖掘的电商数据化运营模式研究[D]广东岭南职业技术学院,2021
[8]张帆;杜迎晨.淘宝平台商家数据化运营与优化策略研究——以女装TD店铺为例[D]郑州科技学院财经学院,2021
[9]张文.基于Python数据可视化的研究与应用[J].电脑编程技巧与维护,2023,TP312.1
[10]李文娟.Python数据可视化的优势——以《三国演义》为例[J].中国教育技术装备,2023,G633.67
[11]丁屹;金莹;张洁.新文科背景下的大数据课程数据可视化能力培养——以FineBI平台为例[J].教育传播与技术,2023TP311.13-4;G642
[12]胡超;王雪芹;赵媛.基于Python城市历年气象数据可视化分析——以眉山市为例[J].河南科技,2023,P413
[13]班妙璇.基于Python的财务数据可视化应用探究[J].数字技术与应用,2023,TP311.13;F275
[14]刘静;王凤;孟星;周保林.Python在数据可视化中的应用案例分析[J].电子技术,2023,TP311.52
[15] 侯明雨;李文倚;呼和;王迪.基于数据可视化技术的勘探开发专业图形工具平台实践[J].软件,2023,TE319;TP311.52
数据分析代码:
import datetime
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 尝试使用不同的编码格式打开文件
for encoding in ['gbk', 'utf-8']:
try:
fdata = pd.read_csv("data.csv", encoding=encoding)
break
except UnicodeDecodeError:
continue
#展示数据内容显示前5行
print(fdata.head())
print(fdata.describe())
print('**********************************************')
#将英文标签转化为中文标签
fdata.rename(columns={'user id':'用户ID','Product ID':'商品ID','Product category ID':'商品类目ID','Behavior type':'行为类型','day':'时间','buy_amount':'购买数量','address':'地址'},inplace=True)
print(fdata.head())
print('**********************************************')
#检查数据中是否有空缺值
a=fdata.isnull().sum()
print(a)
print('**********************************************')
#显示‘行为类型’数据列的类型
b=fdata['行为类型'].unique()
print(b)
print('**********************************************')
#将'行为类型'数据转化为柱状图形式
c=sns.countplot(x='行为类型',order=['pv','fav','buy','cart'],data=fdata,linewidth=2,edgecolor=sns.color_palette("dark",4))
plt.show()
# 统计某一列的数量
counts = fdata['商品ID'].value_counts()
# 获取数量最多的前10个值
top_10 = counts.head(10)
# 绘制柱状图
top_10.plot(kind='bar', color=['red', 'blue','yellow'])
plt.show()
#饼图
# 统计某一列的数量
count = fdata['商品ID'].value_counts()
top_15 = counts.head(15)
# 绘制成饼图
plt.pie(top_15, labels=top_15.index, autopct='%1.1f%%')
plt.title('高销量商品')
plt.show()
#更改时间格式
fdata['时间'] = fdata['时间'].apply(lambda x: datetime.datetime.strptime(str(x), "%Y%m%d").date())
#将同一月份的时间设置成相同月份
fdata['月份']=fdata.时间.astype('datetime64[M]')
print(fdata)
print('**********************************************')
#按月份分类
month=fdata.groupby('月份',as_index=False)
df=month.购买数量.sum()
plt.figure(figsize=(20,5))
plt.plot(df['月份'],df['购买数量'], color='red')
plt.title('不同时间购买数量折线图')
plt.show()
# 提取时间列中的年份,并将其作为新一列加入
fdata['年份'] = pd.to_datetime(fdata['月份'], format='%Y').dt.year
print(fdata)
print('**********************************************')
年份 = 2013
行为类型 = 'pv'
filtered_data = fdata[(fdata['年份'] ==年份 ) & (fdata['行为类型'] == 行为类型)]
# 统计出有哪些用户有这些商品并对其进行排序
user_counts = filtered_data['用户ID'].value_counts().sort_values(ascending=False)
# 输出结果
print(user_counts)
print('**********************************************')
# 根据数量进行分类
result = user_counts.groupby(pd.cut(user_counts, bins=[0, 200, 400, float('inf')], right=False)).size()
# 输出结果
print("一级用户:", result[2])
print("二级用户:", result[1])
print("三级用户:", result[0])
print('**********************************************')
用户分级代码:
from pyecharts.charts import Bar, Timeline
from pyecharts.options import LabelOpts
from pyecharts.globals import ThemeType
bar1 = Bar()
bar1.add_xaxis(['一级', '二级', '三级'])
bar1.add_yaxis("pv用户分级", [0, 0,260], label_opts=LabelOpts(position="right")) # position可以设置参数位置
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(['一级', '二级', '三级'])
bar2.add_yaxis("pv用户分级", [0, 0, 284], label_opts=LabelOpts(position="right")) # position可以设置参数位置
bar2.reversal_axis()
bar3 = Bar()
bar3.add_xaxis(['一级', '二级', '三级'])
bar3.add_yaxis("pv用户分级", [0,4, 280], label_opts=LabelOpts(position="right")) # position可以设置参数位置
bar3.reversal_axis()
timeline = Timeline({"pv用户分级": ThemeType.LIGHT})
timeline.add(bar1, "2012年")
timeline.add(bar2, "2013年")
timeline.add(bar3, "2014年")
timeline.add_schema(
play_interval=2000, # 设置自动播放的时间间隔,单位毫秒
is_timeline_show=True, # 是否在自动播放的时候,显示时间线
is_auto_play=True, # 是否自动播放
is_loop_play=True # 是否循环自动播放
)
timeline.render("三年用户分级状况.html")
数据链接:csv为python数据,xls为FineBI数据
链接:https://pan.baidu.com/s/1bV3af1XwznmfbRvn3IGwbg
提取码:hbsf
链接:https://pan.baidu.com/s/1vBeQXEJ-DZh4Ezpnqu8ZWQ
提取码:hbsf

