
- 1python中的并发_python 并发
- 2python 货币换算库,货币转换python代码你知道怎么写吗?
- 3Python学生管理系统
- 4江苏民丰 x mPaaS | 县域小银行,技术团队就12人,却找到了数字化转型的秘籍_普惠金融数字化转型怎么做
- 5欧盟发布关于网络安全、通信网络弹性的综合风险评估报告:具有战略意义的十大网络安全风险场景
- 6机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾
- 7【重庆思庄Rhce技术分享】Unix domain socket 和 TCP/IP socket 的区别_unix socket 相比于tcpsocket
- 8鸿蒙4.0开发 - DevEco Studio如何使用Previewer窗口预览器报错_cannot preview this file. previews are available f
- 9ECharts圆环图(详细示例——满满的注释)_echarts环形图图例
- 10如何在 Debian 11 上设置一个静态 IP 地址
Java——《面试题——Redis篇》_java redis面试题
赞
踩
前文
本文目录
4,为什么 使用 Redis 而不是用 Memcache 呢?
9, pipeline 有什么好处,为什么要用 pipeline?
19,是否使用过 Redis Cluster 集群,集群的原理是什么?
20, Redis Cluster 集群方案什么情况下会导致整个集群不可用?
24,假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某 个固定的已知的前缀开头的,如果将它们全部找出来?
25,如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
1,为什么要用缓存
使用缓存的目的就是提升读写性能。而实际业务场景下,更多的是为了提升读性能,带来更好的性 能,带来更高的并发量。 Redis 的读写性能比 Mysql 好的多,我们就可以把 Mysql 中的热点数据缓存到 Redis 中,提升读取性能,同时也减轻了 Mysql 的读取压力。
2,使用 Redis 有哪些好处?
- 读取速度快,因为数据存在内存中,所以数据获取快;
- 支持多种数据结构,包括字符串、列表、集合、有序集合、哈希等;
- 支持事务,且操作遵守原子性,即对数据的操作要么都执行,要么都不支持;
- 还拥有其他丰富的功能,队列、主从复制、集群、数据持久化等功能。
3, 什么是 Redis?
Redis 是一个开源(BSD 许可)、基于内存、支持多种数据结构的存储系统,可以作为数据库、缓 存和消息中间件。它支持的数据结构有字符串(strings)、哈希(hashes)、列表(lists)、集合 (sets)、有序集合(sorted sets)等,除此之外还支持 bitmaps、hyperloglogs 和地理空间( geospatial )索引半径查询等功能。
它内置了复制(Replication)、LUA 脚本(Lua scripting)、LRU 驱动事件(LRU eviction)、事 务(Transactions)和不同级别的磁盘持久化(persistence)功能,并通过 Redis 哨兵(哨兵)和 集群(Cluster)保证缓存的高可用性(High availability)。
4,为什么 使用 Redis 而不是用 Memcache 呢?
这时候肯定想到的就是做一个 Memcache 与 Redis 区别。
- Redis 和 Memcache 都是将数据存放在内存中,都是内存数据库。不过 Memcache 还可用于缓存 其他东西,例如图片、视频等等。
- Memcache 仅支持key-value结构的数据类型,Redis不仅仅支持简单的key-value类型的数据, 同时还提供list,set,hash等数据结构的存储。
- 虚拟内存– Redis 当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
- 分布式–设定 Memcache 集群,利用 magent 做一主多从; Redis 可以做一主多从。都可以一主一 从
- 存储数据安全– Memcache 挂掉后,数据没了; Redis 可以定期保存到磁盘(持久化)
- Memcache 的单个value最大 1m , Redis 的单个value最大 512m 。
- 灾难恢复– Memcache 挂掉后,数据不可恢复; Redis 数据丢失后可以通过 aof 恢复
- Redis 原生就支持集群模式, Redis3.0 版本中,官方便能支持Cluster模式了, Memcached 没 有原生的集群模式,需要依赖客户端来实现,然后往集群中分片写入数据。
- Memcached 网络IO模型是多线程,非阻塞IO复用的网络模型,原型上接近于 nignx 。而 Redis 使用单线程的IO复用模型,自己封装了一个简单的 AeEvent 事件处理框架,主要实现类 epoll,kqueue 和 select ,更接近于Apache早期的模式。
5,为什么 Redis 单线程模型效率也能那么高?
1. C语言实现,效率高
2. 纯内存操作
3. 基于非阻塞的IO复用模型机制
4. 单线程的话就能避免多线程的频繁上下文切换问题
5. 丰富的数据结构(全称采用hash结构,读取速度非常快,对数据存储进行了一些优化,比如亚 索表,跳表等)
6,说说 Redis 的线程模型
这问题是因为前面回答问题的时候提到了 Redis 是基于非阻塞的IO复用模型。如果这个问题回 答不上来,就相当于前面的回答是给自己挖坑,因为你答不上来,面试官对你的印象可能就要 打点折扣了。
Redis 内部使用文件事件处理器 file event handler ,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket ,根据 socket 上的事 件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
1.多个 socket 。
2. IO 多路复用程序。
3. 文件事件分派器。
4. 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)。
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会 监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事 件,把该事件交给对应的事件处理器进行处理。
来看客户端与 Redis 的一次通信过程:
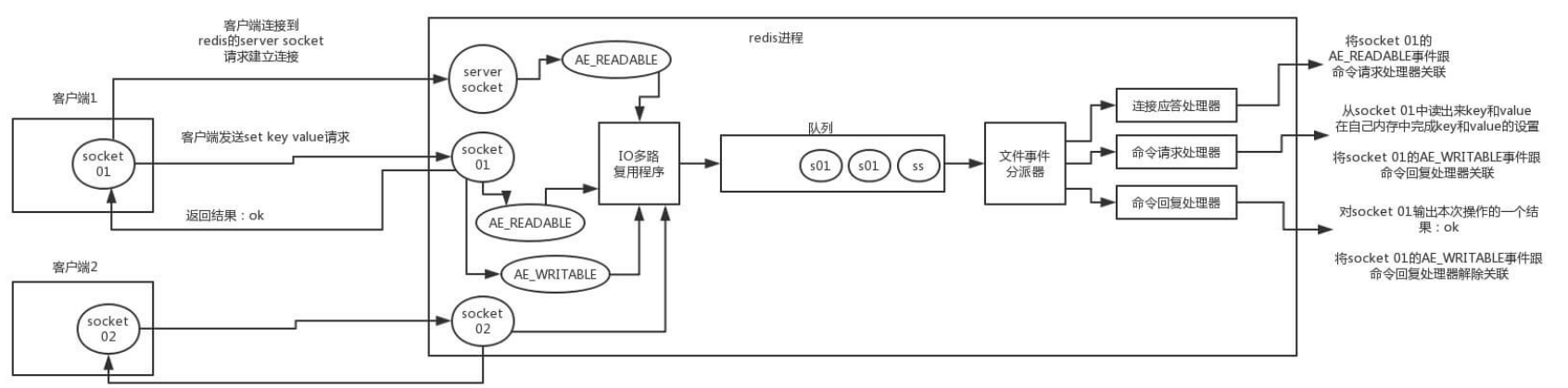
下面来大致说一下这个图:
1. 客户端 Socket01 向 Redis 的 Server Socket 请求建立连接,此时 Server Socket 会产生一个 AE_READABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该事件压入队列 中。文件事件分派器从队列中获取该事件,交给连接应答处理器。连接应答处理器会创建一个 能与客户端通信的 Socket01,并将该 Socket01 的 AE_READABLE 事件与命令请求处理器关 联。
2. 假设此时客户端发送了一个 set key value 请求,此时 Redis 中的 Socket01 会产生 AE_READABLE 事件,IO 多路复用程序将事件压入队列,此时事件分派器从队列中获取到该事 件,由于前面 Socket01 的 AE_READABLE 事件已经与命令请求处理器关联,因此事件分派器 将事件交给命令请求处理器来处理。命令请求处理器读取 Socket01 的 set key value 并在自己 内存中完成 set key value 的设置。操作完成后,它会将 Socket01 的 AE_WRITABLE 事件与令 回复处理器关联。
3. 如果此时客户端准备好接收返回结果了,那么 Redis 中的 Socket01 会产生一个 AE_WRITABLE 事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复 处理器对 Socket01 输入本次操作的一个结果,比如 ok ,之后解除 Socket01 的 AE_WRITABLE 事件与命令回复处理器的关联。
这样便完成了一次通信。 不要怕这段文字,结合图看,一遍不行两遍,实在不行可以网上查点资料 结合着看,一定要搞清楚,否则前面吹的牛逼就白费了。
7,为什么 Redis 需要把所有数据放到内存中?
Redis 将数据放在内存中有一个好处,那就是可以实现最快的对数据读取,如果数据存储在硬盘 中,磁盘 I/O 会严重影响 Redis 的性能。而且 Redis 还提供了数据持久化功能,不用担心服务器重 启对内存中数据的影响。其次现在硬件越来越便宜的情况下,Redis 的使用也被应用得越来越多, 使得它拥有很大的优势。
8,Redis 的同步机制了解是什么?
Redis 支持主从同步、从从同步。如果是第一次进行主从同步,主节点需要使用 bgsave 命令,再将 后续修改操作记录到内存的缓冲区,等 RDB 文件全部同步到复制节点,复制节点接受完成后将 RDB 镜像记载到内存中。等加载完成后,复制节点通知主节点将复制期间修改的操作记录同步到复 制节点,即可完成同步过程。
9, pipeline 有什么好处,为什么要用 pipeline?
使用 pipeline(管道)的好处在于可以将多次 I/O 往返的时间缩短为一次,但是要求管道中执行的 指令间没有因果关系。
用 pipeline 的原因在于可以实现请求/响应服务器的功能,当客户端尚未读取旧响应时,它也可以 处理新的请求。如果客户端存在多个命令发送到服务器时,那么客户端无需等待服务端的每次响应 才能执行下个命令,只需最后一步从服务端读取回复即可。
10,说一下 Redis 有什么优点和缺点
优点
速度快:因为数据存在内存中,类似于 HashMap , HashMap 的优势就是查找和操作的时间复杂 度都是O (1) 。
支持丰富的数据结构:支持 String ,List,Set,Sorted Set,Hash 五种基础的数据结构。
持久化存储:Redis 提供 RDB 和 AOF 两种数据的持久化存储方案,解决内存数据库最担心的 万一 Redis 挂掉,数据会消失掉
高可用:内置 Redis Sentinel ,提供高可用方案,实现主从故障自动转移。 内置 Redis Cluster ,提供集群方案,实现基于槽的分片方案,从而支持更大的 Redis 规模。
丰富的特性:Key过期、计数、分布式锁、消息队列等。
缺点
由于 Redis 是内存数据库,所以,单台机器,存储的数据量,跟机器本身的内存大小。虽然 Redis 本身有 Key 过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要期删除数据。
如果进行完整重同步,由于需要生成 RDB 文件,并进行传输,会占用主机的 CPU ,并会消耗现网的带宽。不过 Redis 2.8 版本,已经有部分重同步的功能,但是还是有可能有完整重同步 的。比如,新上线的备机。
修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中, Redis 不能提供服务。
11 Redis 缓存刷新策略有哪些?

12, Redis 持久化方式有哪些?以及有什么区别?
Redis 提供两种持久化机制 RDB 和 AOF 机制:
RDB 持久化方式
RDB全称Redis Database Backup file(Redis数据备份文件)也被叫做Redis数据快照,是指用数据集快照的方式半持久化模式)记录 redis 数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:
- 只有一个文件 dump.rdb ,方便持久化。
- 容灾性好,一个文件可以保存到安全的磁盘。
- 性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单 独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 Redis 的高性能)
- 相对于数据集大时,比 AOF 的启动效率更高。
缺点:
数据安全性低。 RDB 是间隔一段时间进行持久化,如果持久化之间 Redis 发生故障,会发生数据 丢失。所以这种方式更适合数据要求不严谨的时候
AOF=Append-only file(追加文件) 持久化方式
是指所有的命令行记录以 Redis 命令请求协议的格式完全持久化存储,保存为 AOF 文件。
优点:
(1)数据安全, AOF 持久化可以配置 appendfsync 属性,有 always,每进行一次命令操作就记录 到 AOF 文件中一次。
(2)通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据 一致性问题。
(3) AOF 机制的 rewrite 模式。 AOF 文件没被 rewrite 之前(文件过大时会对命令进行合并重 写),可以删除其中的某些命令(比如误操作的 flushall )
缺点:
(1) AOF 文件比 RDB 文件大,且恢复速度慢。
(2)数据集大的时候,比 RDB 启动效率低。
13,持久化有两种,那应该怎么选择呢?
1. 不要仅仅使用 RDB ,因为那样会导致你丢失很多数据。
2. 也不要仅仅使用 AOF ,因为那样有两个问题,第一,你通过 AOF 做冷备没有 RDB 做冷备的恢 复速度更快; 第二, RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备 份和恢复机制的 bug 。
3. Redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制, 用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
4. 如果同时使用 RDB 和 AOF 两种持久化机制,那么在 Redis 重启的时候,会使用 AOF 来重新 构建数据,因为 AOF 中的数据更加完整。
14,怎么使用 Redis 实现消息队列?
- 一般使用 list 结构作为队列, rpush 生产消息, lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。
- 面试官可能会问可不可以不用 sleep 呢?list 还有个指令叫 blpop ,在没有消息的时候,它会 阻塞住直到消息到来。
- 面试官可能还问能不能生产一次消费多次呢?使用 pub / sub 主题订阅者模式,可以实现 1:N 的消息队列。
- 面试官可能还问 pub / sub 有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用 专业的消息队列如 rabbitmq 等。
- 面试官可能还问 Redis 如何实现延时队列?我估计现在你很想把面试官一棒打死如果你手上有 一根棒球棍的话,怎么问的这么详细。但是你很克制,然后神态自若的回答道:使用 sortedset ,拿时间戳作为 score ,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的数据轮询进行处理。
面试扩散:很多面试官上来就直接这么问: Redis 如何实现延时队列?
15,说说你对Redis事务的理解
什么是 Redis 事务?原理是什么?
Redis 中的事务是一组命令的集合,是 Redis 的最小执行单位。它可以保证一次执行多个命令,每 个事务是一个单独的隔离操作,事务中的所有命令都会序列化、按顺序地执行。服务端在执行事务 的过程中,不会被其他客户端发送来的命令请求打断。
它的原理是先将属于一个事务的命令发送给 Redis,然后依次执行这些命令。
Redis 事务的注意点有哪些?
需要注意的点有:
Redis 事务是不支持回滚的,不像 MySQL 的事务一样,要么都执行要么都不执行; Redis 服务端在执行事务的过程中,不会被其他客户端发送来的命令请求打断。直到事务命令 全部执行完毕才会执行其他客户端的命令。
Redis 事务为什么不支持回滚?
Redis 的事务不支持回滚,但是执行的命令有语法错误,Redis 会执行失败,这些问题可以从程序层 面捕获并解决。但是如果出现其他问题,则依然会继续执行余下的命令。这样做的原因是因为回滚 需要增加很多工作,而不支持回滚则可以保持简单、快速的特性。
16,Redis 为什么设计成单线程的?
多线程处理会涉及到锁,并且多线程处理会涉及到线程切···换而消耗 CPU。采用单线程,避免了不 必要的上下文切换和竞争条件。其次 CPU 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存或 者网络带宽。
17,什么是 bigkey?会存在什么影响?
bigkey 是指键值占用内存空间非常大的 key。例如一个字符串 a 存储了 200M 的数据。
bigkey 的主要影响有:
- 网络阻塞;获取 bigkey 时,传输的数据量比较大,会增加带宽的压力。
- 超时阻塞;因为 bigkey 占用的空间比较大,所以操作起来效率会比较低,导致出现阻塞的可能性增加。
- 导致内存空间不平衡;一个 bigkey 存储数据量比较大,同一个 key 在同一个节点或服务器中存 储,会造成一定影响。
18,熟悉哪些 Redis 集群模式?
1. Redis Sentinel
体量较小时,选择 Redis Sentinel ,单主 Redis 足以支撑业务。
2. Redis Cluster
Redis 官方提供的集群化方案,体量较大时,选择 Redis Cluster ,通过分片,使用更多内 存。
3. Twemprox
Twemprox 是 Twtter 开源的一个 Redis 和 Memcached 代理服务器,主要用于管理 Redis 和 Memcached 集群,减少与Cache 服务器直接连接的数量。
4. Codis
Codis 是一个代理中间件,当客户端向 Codis 发送指令时, Codis 负责将指令转发到后面的 Redis 来执行,并将结果返回给客户端。一个 Codis 实例可以连接多个 Redis 实例,也可以启 动多个 Codis 实例来支撑,每个 Codis 节点都是对等的,这样可以增加整体的 QPS 需求,还能 起到容灾功能。
5. 客户端分片
在 Redis Cluster 还没出现之前使用较多,现在基本很少热你使用了,在业务代码层实现,起 几个毫无关联的 Redis 实例,在代码层,对 Key 进行 hash 计算,然后去对应的 Redis 实例操 作数据。这种方式对 hash 层代码要求比较高,考虑部分包括,节点失效后的替代算法方案, 数据震荡后的自动脚本恢复,实例的监控,等等。
19,是否使用过 Redis Cluster 集群,集群的原理是什么?
使用过 Redis 集群,它的原理是:
- 所有的节点相互连接
- 集群消息通信通过集群总线通信,集群总线端口大小为客户端服务端口 + 10000(固定值)
- 节点与节点之间通过二进制协议进行通信
- 客户端和集群节点之间通信和通常一样,通过文本协议进行
- 集群节点不会代理查询 数据按照 Slot 存储分布在多个 Redis 实例上
- 集群节点挂掉会自动故障转移
- 可以相对平滑扩/缩容节点
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号 在 0~16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
20, Redis Cluster 集群方案什么情况下会导致整个集群不可用?
Redis 没有使用哈希一致性算法,而是使用哈希槽。Redis 中的哈希槽一共有 16384 个,计算给定 密钥的哈希槽,我们只需要对密钥的 CRC16 取摸 16384。假设集群中有 A、B、C 三个集群节点, 不存在复制模式下,每个集群的节点包含的哈希槽如下:
- 节点 A 包含从 0 到 5500 的哈希槽;
- 节点 B 包含从 5501 到 11000 的哈希槽;
- 节点 C 包含从 11001 到 16383 的哈希槽;
- 这时,如果节点 B 出现故障,整个集群就会出现缺少 5501 到 11000 的哈希槽范围而不可用。
21,Redis 集群架构模式有哪几种?
Redis 集群架构是支持单节点单机模式的,也支持一主多从的主从结构,还支持带有哨兵的集群部 署模式。
22,说说 Redis 哈希槽的概念?
Redis 集群并没有使用一致性 hash,而是引入了哈希槽的概念。Redis 集群有 16384(2^14)个哈 希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
23,Redis 常见性能问题和解决方案有哪些?
Redis 常见性能问题和解决方案如下:
- Master 最好不要做任何持久化工作,如 RDB 内存快照和 AOF 日志文件;
- 如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次;
- 为了主从复制的速度和连接的稳定性,Master 和 Slave 最好在同一个局域网内;
- 尽量避免在压力很大的主库上增加从库;
- 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3….;这样的结构方便解决单点故障问题,实现 Slave 对 Master 的替换。如果 Master 挂 了,可以立刻启用 Slave1 做 Master,其他不变。
24,假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某 个固定的已知的前缀开头的,如果将它们全部找出来?
我们可以使用 keys 命令和 scan 命令,但是会发现使用 scan 更好。
1. 使用 keys 命令
直接使用 keys 命令查询,但是如果是在生产环境下使用会出现一个问题,keys 命令是遍历查询 的,查询的时间复杂度为 O(n),数据量越大查询时间越长。而且 Redis 是单线程,keys 指令会导 致线程阻塞一段时间,会导致线上 Redis 停顿一段时间,直到 keys 执行完毕才能恢复。这在生产 环境是不允许的。除此之外,需要注意的是,这个命令没有分页功能,会一次性查询出所有符合条 件的 key 值,会发现查询结果非常大,输出的信息非常多。所以不推荐使用这个命令。
2. 使用 scan 命令
scan 命令可以实现和 keys 一样的匹配功能,但是 scan 命令在执行的过程不会阻塞线程,并且查 找的数据可能存在重复,需要客户端操作去重。因为 scan 是通过游标方式查询的,所以不会导致 Redis 出现假死的问题。Redis 查询过程中会把游标返回给客户端,单次返回空值且游标不为 0,则 说明遍历还没结束,客户端继续遍历查询。scan 在检索的过程中,被删除的元素是不会被查询出来 的,但是如果在迭代过程中有元素被修改,scan 不能保证查询出对应元素。相对来说,scan 指令 查找花费的时间会比 keys 指令长。
25,如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
如果有大量的 key 在同一时间过期,那么可能同一秒都从数据库获取数据,给数据库造成很大的压 力,导致数据库崩溃,系统出现 502 问题。也有可能同时失效,那一刻不用都访问数据库,压力不 够大的话,那么 Redis 会出现短暂的卡顿问题。所以为了预防这种问题的发生,最好给数据的过期 时间加一个随机值,让过期时间更加分散。
26,什么情况下可能会导致 Redis 阻塞?
Redis 产生阻塞的原因主要有内部和外部两个原因导致:
内部原因
- 如果 Redis 主机的 CPU 负载过高,也会导致系统崩溃;
- 数据持久化占用资源过多;
- 对 Redis 的 API 或指令使用不合理,导致 Redis 出现问题。
外部原因
- 外部原因主要是服务器的原因,例如服务器的 CPU 线程在切换过程中竞争过大,内存出现问题、网 络问题等。
27,缓存和数据库谁先更新呢?
解决方案
1. 写请求过来,将写请求缓存到缓存队列中,并且开始执行写请求的具体操作(删除缓存中的数 据,更新数据库,更新缓存)。
2. 如果在更新数据库过程中,又来了个读请求,将读请求再次存入到缓存队列(可以搞n个队 列,采用key的hash值进行队列个数取模hash%n,落到对应的队列中,队列需要保证顺序性) 中,顺序性保证等待队列前的写请求执行完成,才会执行读请求之前的写请求删除缓存失败, 直接返回,此时数据库中的数据是旧值,并且与缓存中的数据是一致的,不会出现缓存一致性 的问题。
3. 写请求删除缓存成功,则更新数据库,如果更新数据库失败,则直接返回,写请求结束,此时 数据库中的值依旧是旧值,读请求过来后,发现缓存中没有数据, 则会直接向数据库中请求, 同时将数据写入到缓存中,此时也不会出现数据一致性的问题。
4. 更新数据成功之后,再更新缓存,如果此时更新缓存失败,则缓存中没有数据,数据库中是新 值 ,写请求结束,此时读请求还是一样,发现缓存中没有数据,同样会从数据库中读取数据, 并且存入到缓存中,其实这里不管更新缓存成功还是失败, 都不会出现数据一致性的问题。
上面这方案解决了数据不一致的问题,主要是使用了串行化,每次操作进来必须按照顺序进行。如 果某个队列元素积压太多,可以针对读请求进行过滤,提示用户刷新页面,重新请求。
潜在的问题,留给大家自己去想吧,因为这个问题属于发散性。
1,请求时间过长,大量的写请求堆压在队列中,一个读请求来得等都写完了才可以获取到数据。
2,读请求并发高
3,热点数据路由问题,导致请求倾斜。
28,怎么提高缓存命中率?
主要常用的手段有:
- 提前加载数据到缓存中;
- 增加缓存的存储空间,提高缓存的数据;
- 调整缓存的存储数据类型;
- 提升缓存的更新频率。
29,Redis 如何解决 key 冲突?
Redis 如果 key 相同,后一个 key 会覆盖前一个 key。如果要解决 key 冲突,最好给 key 取好名区 分开,可以按业务名和参数区分开取名,避免重复 key 导致的冲突。
30,Redis 报内存不足怎么处理?
Redis 内存不足可以这样处理:
- 修改配置文件 redis.conf 的 maxmemory 参数,增加 Redis 可用内存;
- 设置缓存淘汰策略,提高内存的使用效率;
- 使用 Redis 集群模式,提高存储量。
31、说说Redis持久化机制
Redis是一个支持持久化的内存数据库,通过持久化机制把内存中的数据同步到硬盘文件来保证数据 持久化。当Redis重启后通过把硬盘文件重新加载到内存,就能达到恢复数据的目的。 实现:单独 创建fork()一个子进程,将当前父进程的数据库数据复制到子进程的内存中,然后由子进程写入到临 时文件中,持久化的过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,内存 释放。
RDB是Redis默认的持久化方式。按照一定的时间周期策略把内存的数据以快照的形式保存到硬盘的 二进制文件。即Snapshot快照存储,对应产生的数据文件为dump.rdb,通过配置文件中的save参 数来定义快照的周期。( 快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。) AOF:Redis会将每一个收到的写命令都通过Write函数追加到文件最后,类似于MySQL的binlog。 当Redis重启是会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。 当两种方 式同时开启时,数据恢复Redis会优先选择AOF恢复。
32、缓存雪崩、缓存穿透、缓存击穿、缓存预热、缓存更新、缓存降级等问题
一、缓存雪崩
我们可以简单的理解为:由于原有缓存失效,新缓存未到期间 (例如:我们设置缓存时采用了相同的 过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了, 而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。 解决办法: 大多数系统设计者考虑用加锁( 最多的解决方案)或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存 储系统上。还有一个简单方案就时讲缓存失效时间分散开。
二、缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次 无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。 解决办法; 最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。 另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然 把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。 5TB的硬盘上放满了数据,请写一个算法将这些数据进行排重。如果这些数据是一些32bit大小的数据该如何解决?如果是64bit的呢?
对于空间的利用到达了一种极致,那就是Bitmap和布隆过滤器(Bloom Filter)。 Bitmap: 典型的就 是哈希表 缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠 牺牲更多的空间、时间来完成了。
布隆过滤器(推荐) 就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率 下,完成元素判重的过程。 它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定 的误识别率和删除困难。 Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲 突”。 Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减 少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那 么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存 在于集合中。这便是Bloom-Filter的基本思想。 Bloom-Filter一般用于在大数据量的集合中判定某 元素是否存在。
三、缓存击穿
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
解决方案一:互斥锁,强一致,性能差
解决方案二:逻辑过期,高可用,性能优,不能保证数据绝对一致
四、缓存预热
缓存预热这个应该是一个比较常见的概念,相信很多小伙伴都应该可以很容易的理解,缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据! 解决思路: 1、直接写个缓存刷新页面,上线时手工操作下; 2、数据量不大,可以在项目启动的时候自动进行加载; 3、定时刷新缓存;
五、缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种: (1)定时去清理过期的缓存; (2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。 两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
六、缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。 降级的最终目的是保证核心服务可用,即使是有损的。而 且有些服务是无法降级的(如加入购物车、结算)。 以参考日志级别设置预案: (1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级; (2)警告:有些服务在一 段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警; (3)错 误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级; (4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重 要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据 库查询,而是直接返回默认值给用户。
33、热点数据和冷数据是什么
热点数据,缓存才有价值 对于冷数据而言,大部分数据可能还没有再次访问到就已经被挤出内存, 不仅占用内存,而且价值不大。频繁修改的数据,看情况考虑使用缓存 对于上面两个例子,寿星列 表、导航信息都存在一个特点,就是信息修改频率不高,读取通常非常高的场景。 对于热点数据, 比如我们的某IM产品,生日祝福模块,当天的寿星列表,缓存以后可能读取数十万次。再举个例 子,某导航产品,我们将导航信息,缓存以后可能读取数百万次。 数据更新前至少读取两次,缓存 才有意义。这个是最基本的策略,如果缓存还没有起作用就失效了,那就没有太大价值了。 那存不 存在,修改频率很高,但是又不得不考虑缓存的场景呢?有!比如,这个读取接口对数据库的压力 很大,但是又是热点数据,这个时候就需要考虑通过缓存手段,减少数据库的压力,比如我们的某 助手产品的,点赞数,收藏数,分享数等是非常典型的热点数据,但是又不断变化,此时就需要将 数据同步保存到Redis缓存,减少数据库压力。
34、Memcache与Redis的区别都有哪些?
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,redis可以持久化其数据
2)、数据支持类型 memcached所有的值均是简 单的字符串,redis作为其替代者,支持更为丰富的数据类型 ,提供list,set,zset,hash等数据结 构的存储
3)、使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一 样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移 动和请求。
4). value 值大小不同:Redis 最大可以达到 1gb;memcache 只有 1mb。
5)redis的 速度比memcached快很多 6)Redis支持数据的备份,即master-slave模式的数据备份。
35、单线程的redis为什么这么快
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
36、redis的数据类型,以及每种数据类型的使用场景
回答:一共五种
(一)String 这个其实没啥好说的,最常规的set/get操作,value可以是String也可以 是数字。一般做一些复杂的计数功能的缓存。
(二)hash 这里value存放的是结构化的对象,比较方 便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以 cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(三)list 使用 List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于 redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适—取行情信息。就也是个生 产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
(四)set 因为set堆放的是一堆 不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系 统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公 共服务,太麻烦了。 另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好, 自己独有的喜好等功能。
(五)sorted set sorted set多了一个权重参数score,集合中的元素能够按 score进行排列。可以做排行榜应用,取TOP N操作。
37、redis的过期策略以及内存淘汰机制
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责 监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要 将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的 呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是, redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行 检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。 于 是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了 过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这 样,redis的内存会越来越高。那么就应该采用内存淘汰机制。 在redis.conf中有一行配置
maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
- volatile-lru:从已设置过期时 间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时 间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期 时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集 (server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集 (server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据,新写入操作会 报错
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatilerandom 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
38、Redis 为什么是单线程的
官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器 内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单 线程的方案了(毕竟采用多线程会有很多麻烦!)Redis利用队列技术将并发访问变为串行访问 1) 绝大部分请求是纯粹的内存操作(非常快速)2)采用单线程,避免了不必要的上下文切换和竞争条 件 3)非阻塞IO优点:
- 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复 杂度都是O(1)
- 支持丰富数据类型,支持string,list,set,sorted set,hash
- 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
- 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除如何解决redis的 并发竞争key问题
同时有多个子系统去set一个key。这个时候要注意什么呢? 不推荐使用redis的事务机制。因为我们 的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的 时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。 (1) 如果对这个key操作,不要求顺序: 准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可 (2) 如果对这个key操作,要求顺序: 分布式锁+时间戳。 假设这会系统B先抢到锁,将key1设置为 {valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做 set操作了。以此类推。 (3) 利用队列,将set方法变成串行访问也可以redis遇到高并发,如果保证 读写key的一致性 对redis的操作都是具有原子性的,是线程安全的操作,你不用考虑并发问题,redis内 部已经帮你处理好并发的问题了。
39、Redis 常见性能问题和解决方案?
(1) Master 最好不要做任何持久化工作,如 RDB 内存快照和 AOF 日志文件
(2) 如果数据比较重 要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳 定性, Master 和 Slave 最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从 复制不要用图状结构,用单向链表结构更为稳定,即: Master <- Slave1 <- Slave2 <-Slave3…
40、为什么Redis的操作是原子性的,怎么保证原子性的?
对于Redis而言,命令的原子性指的是:一个操作的不可以再分,操作要么执行,要么不执行。 Redis的操作之所以是原子性的,是因为Redis是单线程的。 Redis本身提供的所有API都是原子操 作,Redis中的事务其实是要保证批量操作的原子性。 多个命令在并发中也是原子性的吗? 不一 定, 将get和set改成单命令操作,incr 。使用Redis的事务,或者使用Redis+Lua==的方式实现.
41、了解Redis的事务吗?
Redis事务功能是通过MULTI、EXEC、DISCARD和WATCH 四个原语实现的 Redis会将一个事务中的 所有命令序列化,然后按顺序执行。
1.redis 不支持回滚“Redis 在事务失败时不进行回滚,而是继 续执行余下的命令”, 所以 Redis 的内部可以保持简单且快速。
2.如果在一个事务中的命令出现错 误,那么所有的命令都不会执行;
3.如果在一个事务中出现运行错误,那么正确的命令会被执行。
1)MULTI命令用于开启一个事务,它总是返回OK。 MULTI执行之后,客户端可以继续向服务器发 送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有 队列中的命令才会被执行。
2)EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回 值,按命令执行的先后顺序排列。 当操作被打断时,返回空值 nil 。
3)通过调用DISCARD,客户 端可以清空事务队列,并放弃执行事务, 并且客户端会从事务状态中退出。
4)WATCH 命令可以 为 Redis 事务提供 check-and-set (CAS)行为。 可以监控一个或多个键,一旦其中有一个键被修 改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。
42、Redis 的数据类型及使用场景
String
最常规的 set/get 操作,Value 可以是 String 也可以是数字。一般做一些复杂的计数功能的缓存。
Hash
这里 Value 存放的是结构化的对象,比较方便的就是操作其中的某个字段。我在做单点登录的时 候,就是用这种数据结构存储用户信息,以 CookieId 作为 Key,设置 30 分钟为缓存过期时间,能 很好的模拟出类似 Session 的效果。
List
使用 List 的数据结构,可以做简单的消息队列的功能。另外,可以利用 lrange 命令,做基于 Redis 的分页功能,性能极佳,用户体验好。
Set
因为 Set 堆放的是一堆不重复值的集合。所以可以做全局去重的功能。我们的系统一般都是集群部 署,使用 JVM 自带的 Set 比较麻烦。另外,就是利用交集、并集、差集等操作,可以计算共同喜 好,全部的喜好,自己独有的喜好等功能。
Sorted Set
Sorted Set 多了一个权重参数 Score,集合中的元素能够按 Score 进行排列。可以做排行榜应用, 取 TOP(N) 操作。Sorted Set 可以用来做延时任务。

