- 1silvaco deckbuild突然获取不到许可证_silvaco安装licence
- 2如何在cmd下切换python版本使用_在cmd中python改版本
- 3Cisco SG200配置备忘_cisco sg200配置手册
- 42023最新版JavaSE教程——第7天:面向对象编程(进阶)_比较新的java教程
- 5zabbix监控服务器交换机item参数参考_system.cpu.util
- 6isp计算机术语,03. 互联网发展的三个阶段 基于ISP和IXP的多层结构
- 7基于python-scrapy框架的爬虫系统_…… ,p1 th::?::::::::::::::::::
- 8牛客前端八股文
- 9ReactPy:使用 Python 构建动态前端应用程序
- 10基于Python的招聘信息可视化系统,附源码_基于python的招聘数据分析及可视化系统设计与实现的模块图
arm linux linker语法,计算机科学基础知识(三):静态库和静态链接
赞
踩
计算机科学基础知识(三):静态库和静态链接
作者:linuxer 发布于:2015-2-16 15:15
分类:基础学科
三、将relocatable object file静态链接成可执行文件
将relocatable object file链接成可执行文件分成两步,第一步是符号分析(symbol resolution),第二步是符号重新定位(Relocation)。本章主要描述这两个过程,为了完整性,静态库的概念也会在本章提及。
1、为什么会提出静态库的概念?
程序逻辑有共同的需求,例如数学库、字符串库等,如果每个程序员在撰写这些代码逻辑的时候都需要自己重新写那么该是多么麻烦的事情,而且容易出错,如果有现成的,何必自己制作轮子呢?因此,静态库的概念被提出来。静态库有下面的几种方案:
(1)发行的编译器带一些标准函数的source code
(2)发行的编译器带一个大的.o文件
(3)发行的编译器在某个目录下放置若干.o文件
(4)使用静态库
如果可以阅读到标准函数的source code,对于那些喜欢刨根问底的程序员而言是一种幸福,不过这种方案的缺陷是标准c的库函数太多,这样整起来compiler太复杂,而且库和compiler捆绑的太紧了,每次修正一个库的issue都需要重新release一个新的编译器。把所有的库函数变成一个大的.o文件可以解除库和compiler耦合太紧的问题,程序员总是可以把自己的程序和这个.o文件进行链接,从而屏蔽了库函数的底层细节。顺便说一下,使用linker可以将若干的.o文件合并成一个.o文件,命令如下:
arm-linux-ld –r -o result.o a.o b.o c.o……
命令行中的r表示链接的结果是一个relocatable file而不是一个executable file。当然,这种方法的缺陷是生成的目标文件太大(目前考虑静态链接),编译的的可执行文件中包括了.o中的所有内容,无论用到或者用不到。此外,由于所有的库函数都在一个.o文件中,任何一点改动都需要重新编译生成那个大的.o文件。针对这样的缺陷,我们可以考虑把一个大的.o文件分散成一个一个小的.o文件,并保存在一个特定的目录下。这样就解决了浪费磁盘空间的issue,只不过每次的编译都比较复杂,程序员需要知道自己调用了哪些库函数,涉及哪些.o的文件,并把这些.o文件作为输入文件传递给gcc。这样的使用对程序员而言是非常不方便的。最终的解决方案就是静态库,我们可以通过下面的命令来生成静态库:
arm-linux-ar rcs libtest.a a.o b.o c.o……
2、Linker解析符号的顺序
在生成可执行文件的时候,传递给linker的参数大概如下:
arm-linux-ld [all kinds of parameter] -o result a.o b.o c.o……aa.a bb.a cc.a……
也就是说,linker可以把一个个的.o文件(静态库本身也是.o文件的集合,只不过linker可以根据符号引用情况,智能的从.a文件中抽取它需要的.o文件)组合形成一个可执行文件。Linker扫描.o文件的顺序是从左到右,Scan的过程中维护三个集合
(1)集合E:E中包含了所有要merge成可执行文件的.o文件
(2)集合U:U中包含了所有的未定义的符号
(3)集合D:D中包含了已经定义的符号
符号解析(Symbol resolution)过程是这样的:初始态:E U D都是空集,扫描过程中,如果是.o文件,那么就将该.o文件加入E,并分析该.o文件的符号表,把该.o定义的符号信息假如到集合D中,该.o文件中未定义的符号会在集合D中scan,看看是否已经定义,如果以及定义,那么OK,符号已经解析了,如果在目前的集合D中没有定义该符号,那么就把该符号假如到集合U中。如果是库文件,那么linker会试图为当前的U集合中未定义的每一个符号找到归宿。对于U中的每一个符号,linker会遍历库文件中的各个.o文件,找到对应的,定义了集合U中符号的那个.o文件,如果找到,那么就将该.o文件加入E,并分析该.o文件的符号表,更新U和D。这个过程会反复迭代执行,直到U和D固定下来。这样的动作可以是的那些包含在.a文件中的、未涉及的.o文件被丢弃,不会加到集合E中。当扫描到最后一个.o的文件的时候,如果集合U中仍然是非空集合,那么linker就会报undefined reference的错误。
了解linker这些行为有助于解决链接过程的issue。假设命令行参数如下:
arm-linux-ld -static -o result libaa.a a.o
如果libaa库中定义了一个ahead的函数,并且在a.o中引用,看起来符号是定义了,但是由于linker的扫描顺序,实际上上面的linker会undefined reference to ahead的错误,当然,修正也很简单,把libaa放到a.o的后面就OK了,因此,在实际中,我们总是把.o文件放到前面,把库文件放到最后。
3、编译hello world
我们回到最原始的hello world程序,看看静态编译的过程。源代码我就不上了,大家自行想像。为了更清楚的看到链接过程,我们在命令行参数中增加-v的参数,如下:
arm-linux-gcc -v -static -o hello main.c
在控制台屏幕上跳动的是整个编译、链接的详细过程,当然,我们这里只关注link的过程,因此重点看看gcc是如何调用linker的,是传递了什么样的参数给linker:
/opt/arm-compiler/bin/../libexec/gcc/arm-none-linux-gnueabi/4.2.0/collect2 --sysroot=/opt/arm-compiler/bin/../arm-none-linux-gnueabi/libc -Bstatic -dynamic-linker /lib/ld-linux.so.3 -X -m armelf_linux_eabi -o hello /opt/arm-compiler/bin/../arm-none-linux-gnueabi/libc/usr/lib/crt1.o /opt/arm-compiler/bin/../arm-none-linux-gnueabi/libc/usr/lib/crti.o /opt/arm-compiler/bin/../lib/gcc/arm-none-linux-gnueabi/4.2.0/crtbeginT.o -L/opt/arm-compiler/bin/../lib/gcc/arm-none-linux-gnueabi/4.2.0 -L/opt/arm-compiler/bin/../lib/gcc -L/opt/arm-compiler/bin/../lib/gcc/arm-none-linux-gnueabi/4.2.0/../../../../arm-none-linux-gnueabi/lib -L/opt/arm-compiler/bin/../arm-none-linux-gnueabi/libc/lib -L/opt/arm-compiler/bin/../arm-none-linux-gnueabi/libc/usr/lib /var/tmp/ccg9aX7V.o --start-group -lgcc -lgcc_eh -lc --end-group /opt/arm-compiler/bin/../lib/gcc/arm-none-linux-gnueabi/4.2.0/crtend.o /opt/arm-compiler/bin/../arm-none-linux-gnueabi/libc/usr/lib/crtn.o
实际调用的不是ld,而是collect2,不过没有关系,它只不过是ld的马甲,都素一样一样D。--sysroot用来指定系统目录,这里替代了configure-time的缺省设置。-Bstatic表示创建静态链接的可执行文件,不要和动态库发生纠葛。-dynamic-linker就象其名字说明的,用来指明该可执行程序使用哪一个dynamic linker,当然,在我们这个场景下,设定dynamic linker没有意义。-X表示删除编译器生成的一些临时符号(有.L前缀)。-m用来指明linker处于哪一种emulation mode。我使用的linker支持armelf_linux_eabi和armelfb_linux_eabi两种mode,分别用来支持little endian的ARM和big endian的ARM。不同的emulation mode使用不同的链接脚本(可以参考arm-none-linux-gnueabi/lib/ldscripts目录下的内容),linker会根据gcc传递来的参数(静态编译还是动态编译、编译可执行文件还是编译动态库)以及emulation mode来选择合适的链接脚本(如果没有显示的使用-T来指定链接脚本的话)。当然,emulation mode还有一些其他的应用场景,我们这里浅尝辄止吧。
--start-group archives --end-group的参数是和linker如何扫描静态库相关,所有用--start-group和--end-group包含的静态库(-lgcc -lgcc_eh -lc)都需要特别对待。一般而言,linker对每个静态库都只是扫描一遍,不过如果用--start-group和--end-group包围起来的库则是重复性的扫描,直到没有新的未定义的符号被创建。c库是在意料之中的库,gcc库和gcc_eh库是什么东东呢?libgcc库提供了一些底层的runtime库函数,可以使用ar命令和nm命令观察静态库文件:
arm-linux-ar –t libgcc.a -----该命令可以看看libgcc.a中有多少个.o文件
arm-linux-nm –a libgcc.a -----该命令可以看看libgcc.a中定义的符号情况
libgcc库中多半是一些数学运算相关的函数,而这些函数在目标处理器上不能直接执行(没有对应的汇编指令),因此,在程序编译的时候,gcc编译器可以直接使用libgcc库中的代码来完成这些数学运算。例如:ARM处理器不支持除法,如果你的c代码中出现了整数的除法,实际上,compiler是无法使用div这样的指令来翻译c代码的,这种情况下,就需要libgcc库了,你可以自己写一段包括整数的除法的c代码,然后用objdump反汇编看看,在实际的汇编指令中,除法实际上是使用了__aeabi_idiv这个函数(位于libgcc库中的_divsi3.o模块中)。我们再来看libgcc_eh.a这个库,eh的含义是exception handler(我猜的),应该是和异常处理相关的。这里我也了解不多,暂且略过。
除了真正的mian.c对应的/var/tmp/ccg9aX7V.o文件,其他还有几个有趣的.o文件:crt1.o crti.o crtbeginT.o crtend.o crtn.o(crt就是c runtime的意思)。有些系统使用crt0.o,有些使用crt1.o,当然也有使用更高number的系统,类似crt2.o什么的。一般来说,程序员接触到的程序入口都是main函数(有些使用更高级工具的程序员可能连main函数都看不到),但是实际上在main函数之前还有一段程序setup环境的过程,而且这段bootstrap的代码是所有的程序共用的,因此被整理成了crt*.o的文件,在链接的时候,和所有的具体程序相关的object文件link在一起,形成最后的image。如果不这样做,势必每一个程序员写程序都需要处理一些相同的内容,这不符合软件工程师不应该制作新轮子的原则。当然,虽然我们不制作新轮子,但是一定要理解轮子的机制。我们先反汇编看看crt1.o的内容:
00000000 <_start>:
0: e59fc024 ldr ip, [pc, #36] ; 2c <.text>
4: e3a0b000 mov fp, #0 ; 0x0 --------最外层函数,清除frame pointer
8: e49d1004 ldr r1, [sp], #4 ----------r1 = argc, sp=sp+4,sp指向了argv[]
c: e1a0200d mov r2, sp -----------r2指向了argv[]
10: e52d2004 str r2, [sp, #-4]! --------这时候r2就是栈底,将stack end参数压入栈
14: e52d0004 str r0, [sp, #-4]! -------将内核传递的r0参数压入_start的栈
18: e59f0010 ldr r0, [pc, #16] ; 30 <.text> ---r0保存了main函数指针
1c: e59f3010 ldr r3, [pc, #16] ; 34 <.text> ---r3保存了__libc_csu_init
20: e52dc004 str ip, [sp, #-4]! -------将__libc_csu_init压入栈
24: ebfffffe bl 0 <__libc_start_main> ----将控制权交给c lib
28: ebfffffe bl 0
2C .word __libc_csu_fini 注:原始的dump文件不是这样的,我稍加修改
30 .word main
34 .word __libc_csu_init
首先映入眼帘的就是_start函数,没有错,_start函数才是这个静态编译程序的入口,然后历经千山万水,最后会调用main函数。站在应用程序的大门口,进入一个新的世界之前,有一个问题很关键:我是如何来到这里的?或者说内核做了些什么事情才让cpu跳转到_start执行?在那一点上,CPU的寄存器为何?这时候该程序的用户栈的状态为何?……太多太多的问题,只有让内核代码来回答了。当我们在terminal中执行hello这个静态链接的可执行程序的时候,shell进程会首先fork一个进程,然后调用exec系统调用进入内核,将新建进程的映像替换成hello。对于elf文件,内核会进入load_elf_binary函数,而具体和该进程用户栈上内容相关的是create_elf_tables函数,具体代码我们就不过了,但是这时候的用户栈的状态如下:

如果认为_start也是一个函数,那么它其实是一个特殊的函数,首先它是用户空间最外层的一个函数,因此需要将fp清零,在栈的回溯的过程中,当遇到fp等于0的时候,debugger就知道已经到了最外层的函数了。内核传递给_start函数的参数是通过某些寄存器传递的(例如X86平台,edx指向DT_FINI函数),对于ARM平台,规范规定通过r0来传递一个handler 函数,在atexit的时候执行该handler了,在3.14版本的内核中并没有这么做,这时候的r0等于NULL,具体参考ELF_PLAT_INIT这个内核宏定义。sp寄存器必须被内核正确的设定,并且在sp指向的用户栈上面保存argc、argv等数据。因此,内核转到userspace的关卡上,PC,SP,R0这三个寄存器被特别设定,其他的寄存器没有特别的规定。
OK,了解这些内核知识后,看_start的反汇编代码就比较轻松了,代码注释已经提供了,这里不再赘述,其本质就是设定传递给__libc_start_main函数的参数,我们可以认为该函数的调用c代码如下:
int __libc_start_main( int (*main) (int, char **, char ** ), ----通过r0传递
int argc, char **argv,----------通过r1 r2传递
__typeof (main) init,-----又一个函数指针,类型和main一样,用r3传递
void (*fini) (void),
void (*rtld_fini) (void),
void *stack_end )------上面三个参数通过stack传递
在这个主题上,我不想再深入下去了,读者有兴趣的话可以自行反汇编其他的.o文件,每个都有自己特定的用途,但无论如何,进入main函数之前,内核、编译器和c库已经完美的准备好了一切。
4、链接脚本
和compiler相比,linker的工作还是比较简单的。就是按照链接脚本进行各个.o文件的各个section的同类项合并,具体如何合并就要看link script file怎么规定了。相信有些同学会问:我编译hello world这样程序也没有使用链接脚本啊。虽然你可以直接使用简单的gcc命令来编译hello world程序,不过除了源代码之外,还有一个default的link script是幕后英雄。使用下面的命令可以看到这个link script:
arm-linux-ld --verbose
链接脚本是一个很复杂的东西,你可以在linker的user manual中找到详细的解释,这里我们只给出一些基本概念性的东西,让大家有个了解就OK了:
OUTPUT_FORMAT("elf32-littlearm", "elf32-bigarm", "elf32-littlearm")
OUTPUT_ARCH(arm)
ENTRY(_start)
SEARCH_DIR("=/usr/local/lib"); SEARCH_DIR("=/lib"); SEARCH_DIR("=/usr/lib");
缺省链接脚本的开始有一些内容如上,OUTPUT_FORMAT定义了linker输出文件的格式。OUTPUT_FORMAT的语法是:OUTPUT_FORMAT(default, big, little),如果没有command line中的-EL或者-EB参数传递给linker,那么linker就选择default的格式,如果command line传入-EL参数,那么选择little,如果传入-EB,那么就选择big。在上面的链接命令行中没有传递-EL或者-EB参数,因此,linker输出的是default,也就是elf32-littlearm的输出文件格式。OUTPUT_ARCH指明了输出的文件是for哪一个平台的。ENTRY指明了程序入口点的,和我们上面分析的一样,_start就是程序的入口点,这个链接脚本命令和命令行中的-e参数含义是一样的。SEARCH_DIR命令就像它的名字说明的一样,当linker搜索lib的时候,可以在SEARCH_DIR定义的路径中寻找,这个链接脚本命令和命令行中的-L path参数含义是一样的。根据链接脚本的定义,实际上linker总是会在/usr/local/lib,/usr/lib和/lib目录下寻找库文件。很明显,从这里就可以看出GNU/linux系统对用户态的lib是有进行grouping的:那些重要的、关键的操作系统相关的lib被放到/lib目录下(例如c库)。一旦有一个usr的前缀,其重要性就比较低了,至少不是系统级别,应该是和普通应用程序相关的库。普通的应用程序也有两种,一种是大家(所有登录用户)都使用的,另外一种是特定用户使用的。因此,GNU/linux将那些和多个用户相关的library放入/usr/lib中。如果你自己编写了一个lib,最优雅的方式是放入到/usr/local/lib目录下,这样才不会打搅到别人。
占据link script file大部分内容的是SECTIONS这个command,这个命令的作用就是告诉linker如何把输入的.o文件中的section映射到输出文件的section中,并且是如何和把这些section放到memory中的,我们摘取一个片段:
SECTIONS
{
PROVIDE (__executable_start = 0x00008000); . = 0x00008000 + SIZEOF_HEADERS;
.interp : { *(.interp) }
.hash : { *(.hash) }
……
.text :
{
*(.text .stub .text.* .gnu.linkonce.t.*)
KEEP (*(.text.*personality*))
*(.gnu.warning)
*(.glue_7t) *(.glue_7) *(.vfp11_veneer)
} =0
……
}
在链接脚本里面可以定义符号,并且该符号被放入到了符号表中(注意:link script中定义的符号是global的),可以被c代码访问。因此,上面脚本中的__executable_start = 0x00008000其实就是在符号表中定义了一个符号。PROVIDE的意思是:如果.o文件中定义了同名的符号,那么该符号的定义将被取代,如果.o文件中没有定义该符号,那么就使用链接脚本中的定义。在c代码中访问链接脚本中定义的符号没有那么直观,我们给出一个例子:
#include
extern int __executable_start;
int main(int argc, char ** argv)
{
printf("__executable_start=%p\n", &__executable_start);
return 0;
}
编译之后该程序执行的结果可以看到__executable_start等于0x00008000。如果在X86的PC上运行,__executable_start等于0x08048000。在c代码中,打印__executable_start的地址(&__executable_start)才可以输出正确的0x00008000信息。为什么呢?在c代码中,我们定义一个符号int xyz = 0x1234,实际上是做了两件事:
(1)分配一个memory的空间来保存xyz的值
(2)在符号表中保存了xyz这个符号的地址
当在程序中修改xyz这个符号的值的时候,需要通过符号表获取到xyz这个符号的地址:address_of_xyz,通过符号表中address_of_xyz可以访问xyz变量并修改其值。c代码中如此,但是链接脚本中定义一个符号并非如此,链接脚本中的符号不会分配memory,而仅仅是在符号表中有一个entry,该entry表示有一个符号是__executable_start,其地址是0x00008000。因此,在c程序中,直接访问__executable_start得到的是0x00008000地址上memory中的value,访问&__executable_start可以获取该符号的地址,也就是0x00008000了。
‘.’是一个特殊的linker变量,它总是保存在当前output的memory address。. = 0x00008000 + SIZEOF_HEADERS就是把当前的输出文件的section的地址调整为0x00008000加上ELF文件header size的一个位置上去。由此可见,输出文件的.interp section的首地址就是0x00008000 + SIZEOF_HEADERS。‘:’前面是输出文件的section,之后用{}包围起来的是输入文件section描述。输入文件section描述部分的格式是:
object file ( section a section b section c ……)
可以使用通配符*(.text)表示所有.o文件中的.text section。具体细节这里不再描述,通过链接脚本中的section命令可以将输入的若干个relocatable object file的各个section输出到目标文件(可能是动态库,也可能是executable file)指定的section,并分配适合的runtime address。
5、符号解析
通俗的讲,符号解析就是确定引用符号和定义符号的对应关系的过程。我们知道,各个.o文件中都会定义一些符号,也会引用一些符号,那么将若干个.o link成一个可执行文件的时候,我们需要把各个.o文件中引用的符号找到一个确定的位置,.o文件中的引用符号最好可以找到唯一一个.o文件中定义的符号,一一对应比较好处理,如果没有定义也简单,linker报错就可以了,当一个引用的符号有多个.o文件定义的时候会怎么样?这是本节主要的内容。
计算机科学是一门实践的科学,我们还是需要动手写一些非常简单的程序来理解符号,具体如下:
main.c
hello.c
int foo = 0x1234;
int main(int argc, char ** argv)
{
hello_world();
return 0;
}
#include int foo;
int hello_world()
{
printf("foo is:0x%x\n", foo);
return 0;
}
虽然定义了同样的符号,不过使用gcc main.c hello.c进行编译是不会报错的,hello.c中的foo符号放入common block而main.c文件中的foo放入data section,linker采纳了main.c中的定义的那个符号来对应hello_world中的对foo的引用。当然,如果你试图用gcc –fno-common main.c hello.c进行编译,linker会报multiple definition of `foo'的link error。如果在hello.c和main.c中都不初始化foo,那么linker也不会报错,随便选择一个就OK了。
还有一种比较容易引起错误的符号解析是函数符号。我们可以编译相同名字的函数在多个动态库中,假设这个函数名是foo,当然,你自己的文件中也可以定义同名的函数符号foo,这时候,当程序调用foo函数的时候,linker到底选择哪一个函数呢?这个留给大家自己做实验吧。
6、了解静态链接后的可执行文件
本节我们将深入观察静态编译链接后的hello world程序。首先看看源代码:
#include int main(int argc, char ** argv)
{
printf("hello, world!\n");
return 0;
}
编译后(arm-linux-gcc -static -o hello main.c)使用bin utilities来观察结果。我们首先看看ELF Header:
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)---类型是可执行文件
Machine: ARM
Version: 0x1
Entry point address: 0x8130--------入口地址
Start of program headers: 52 (bytes into file)
Start of section headers: 482924 (bytes into file)
Flags: 0x4000002, has entry point, Version4 EABI
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 6----------有六个program header
Size of section headers: 40 (bytes)
Number of section headers: 28
Section header string table index: 25
和.o文件不同的是程序入口地址有了具体的赋值,0x8130是什么呢?我们可以从dump的结果看到:这个地址就是_start符号(还记得cr1.o吗?)。另外,可执行文件比.o文件多了program header的内容。program header是用来告知OS如何创建进程映像的。既然牵扯到了进程映像,那么program header一定要提供进程地址空间的信息,用内核的语言描述这个需求就是:把ELF文件,从某个文件偏移处(offset)开始的指定大小(file size)映射到进程地址空间(virtual address或者physical address)开始的指定大小(memory size)去,当然还要包括type flag 对齐属性什么的,这些信息基本就勾勒了一个program header的data structure,具体可以参考内核中Elf32_Phdr和Elf64_Phdr的定义。我们来看看hello world的program header的组成:
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
EXIDX 0x06e600 0x00076600 0x00076600 0x006d0 0x006d0 R 0x4
LOAD 0x000000 0x00008000 0x00008000 0x6ed50 0x6ed50 R E 0x8000
LOAD 0x06f000 0x0007f000 0x0007f000 0x007ac 0x01ffc RW 0x8000
NOTE 0x0000f4 0x000080f4 0x000080f4 0x00020 0x00020 R 0x4
TLS 0x06f000 0x0007f000 0x0007f000 0x00010 0x00028 R 0x4
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x4
Type中的LOAD表示该program header描述了一个loadable segment。segment是程序加载相关的术语,加载其实就是让一个保存在磁盘的程序变成process image,用通俗的语言就是将磁盘文件中的一个个的loadable segemnt copy到内存,然后执行(当然实际中linux不是这样做的,linux内核如何做超出本文的主题)。我们先看第一个loadable segment(后文称之code segment,当然,并不是说该segment全部是可执行代码,只是一种代称),从文件偏移0处,将0x6ed50大小的内容mapping到虚拟地址从0x00008000开始的地址,memory中的size和文件size一样。后面的R(readonly)和E(executable)这两个flag已经基本出卖了这个segment,相信因该是和程序代码相关的。第二个loadable segment(后文称之data segment)是从文件偏移0x06f000开始,将0x007ac大小的内容mapping到虚拟地址从0x0007f000开始的地址,内存中的segment size是0x01ffc。当memory size大于file size的时候,"多余"那部分的memory被初始化成0。这个segment是可读写的,因此应该是程序需要访问的数据区域。
根据上面的信息,我们可以大概描述这两个loadable segment,code segment如下:
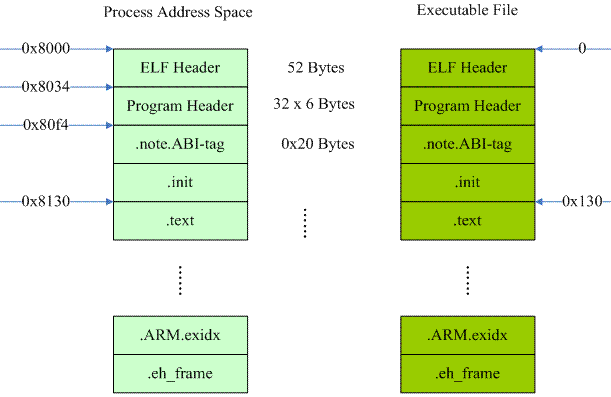
kernel在加载这个segment的时候很简单,就是把executable file映射到进程地址空间的0x8000开始,长度是0x6ed50的虚拟地址空间段就OK了。这个segment除了ELF header和program header之外,还包括.note.ABI-tag .init .text __libc_freeres_fn .fini .rodata __libc_subfreeres __libc_atexit .ARM.extab .ARM.exidx .eh_frame这些section。当然,这些section无论是在可执行文件中还是虚拟地址空间中都是连续的。
.note.ABI-tag section描述了操作系统信息,该section dump的结果如下:
000080f4 <.note.abi-tag>:
80f4: 00000004 .word 0x00000004 ------vendor name的长度
80f8: 00000010 .word 0x00000010 ------data的长度
80fc: 00000001 .word 0x00000001 ------note type
8100: 00554e47 .word 0x00554e47------vendor name,包含GNU 这三个字符
8104: 00000000 .word 0x00000000------0表示是linux下的可执行程序
8108: 00000002 .word 0x00000002------下面三个字节是linux的版本2.6.14
810c: 00000006 .word 0x00000006
8110: 0000000e .word 0x0000000e
对于有些编程语言,编译器需要提供constructor,所谓constructor就是一些特殊的初始化函数,这些函数在进入main函数之前已经调用完成。例如C++中,class的构建函数就是这样的函数。.init section就是为了解决这种需求的。对于c程序,.init比较简单,如下:
00008114 <_init>:
8114: e52de004 str lr, [sp, #-4]!-------将返回地址压栈
8118: e24dd004 sub sp, sp, #4 ; 0x4
811c: eb000011 bl 8168 ---enable profiling
8120: e28dd004 add sp, sp, #4 ; 0x4
8124: e8bd8000 ldmia sp!, {pc}-------恢复调用现场
剩下的section我们就不一一介绍了,大家可以自己看看反汇编分析。我们这里讨论一个有意思的问题:为何ARM target上的程序的mapping到了0x8000的地址上?为何loadable segment的对齐是0x8000呢?不把入口地址mapping到0地址是可以理解的,因为我们的程序需要捕获NULL指针的访问异常,因此对于用户进程的地址空间,必须把0开始的那个page保留下来,不建立页表。这样,当用户程序由于错误导致空指针的访问的时候,硬件可以产生异常,kernel可以发送信号给这个进程,你就可以看到segment fault的错误了。那么起始地址为何在0x8000呢?也就是说前面空闲了32kB的虚拟地址空间。一般而言,我们在前面空出一个page就OK了,因此用户程序的起始地址也就是和硬件相关起来,因为需要了解该CPU的MMU的硬件特性,其支持的虚拟地址到物理地址的映射的size限制。对于ARM,我们可以以4k为单位进行mapping,当然也可以用更大的单位,我们假设最大的page映射单位是MAXPAGESIZE,那么起始地址就是和MAXPAGESIZE这个最大的page映射单位的宏定义相关了。同样的,loadable segement的对齐size也是和page size相关的,有兴趣的话可以看一看链接脚本。对于linker,MAXPAGESIZE值可以build in(我估计对于我用的编译器,这个宏定义被设定为32K,因此首地址是0x8000)。当然,你也可以通过-z max-page-size=value来修改。我们交叉编译器不支持这个关键字,不过可以使用x86上的gcc来观察结果,通过这个选项,你可以修改起始地址和loadable segement的对齐size。
OK,根据上面的知识,我们可以计算code segment的起始地址。0x8000 + 0x6ed50 = 0x76d50,如果align到0x8000上,那么code segment起始地址应该是0x78000,不过有点遗憾,实际上是0x7f000,为何?我们需要看看链接脚本:
……
. = ALIGN (0x8000) - ((0x8000 - .) & (0x8000 - 1)); . = DATA_SEGMENT_ALIGN (0x8000, 0x1000);
……
. = DATA_SEGMENT_END (.);
在DATA_SEGMENT_ALIGN(maxpagesize, commonpagesize)和DATA_SEGMENT_END (.)之间就是data segment。DATA_SEGMENT_ALIGN 可以定义data segment的对齐方式。maxpagesize是该CPU支持的最大的page size,而commonpagesize则是一般情况下使用的那个page size。为何有max page size,又有common page size呢?为何要搞这么复杂?难道就是为了让广大人民群众望而却步吗?当然不是,一般而言,处理器的MMU不会设定一种page size,这主要和应用场景相关,对于大段的code segment,使用小一些的page size会比较浪费内存(要建立很多页表),这时候,系统多半使用较大的page size(甚至是max page size)。而对于data segment,其size没有那么大,使用max page size反而会浪费内存:虽然页表项少些,但是一个1k的data segment需要一个32k(假设max page size是0x8000)的物理内存与之对应,宝贵的内存资源岂能如此浪费。对于我使用的交叉编译器平台,这里max page size是0x8000,即32KB,common page size是0x1000,就是大家都比较习惯的4KB了。
在data segment使用common page size进行映射的时候(当data segment非常大的时候,也可以考虑使用max page size),DATA_SEGMENT_ALIGN(maxpagesize, commonpagesize)计算如下:
(ALIGN(maxpagesize) + (. & (maxpagesize - commonpagesize)))
上面的运算把当前的location counter设定为0x78000 + 0x6000 = 0x7f000。data segment的示意图如下:

kernel在加载这个segment的时候采用和code segment类似的手段,就是把executable file从0x6f000偏移开始的文件内容映射到进程地址空间的0x7f000开始,长度是0x01ffc的虚拟地址空间段就OK了。和code segment不同的是memory中的data segment要大一些,这些区域由于没有executable file中的内容与之对应,因此会被os设定为0。这个data segment包括.tdata .init_array .fini_array .jcr .data.rel.ro .got .data .bss __libc_freeres_ptrs这些section。当然,这些section无论是在可执行文件中还是虚拟地址空间中都是连续的。
.data和.bss相信大家都非常的熟悉了,这里不再赘述,我们挑选一两个data segment中的典型section来描述。我们来看看.tdata这个section。要想讲清楚这个section需要首先搞清楚什么是thread local storage(TLS)。在进行多线程编程的时候,我们知道,临时变量都是thread-specific的,而全局变量都是所有thread共享的,对其访问要有适合的锁的机制,以便控制multi thread的并发。但是这样的数据模型不能总是满足用户需求,有的时候,程序需要这样的一种数据模型,该数据是全局的(或者是static的),但是这种数据又不在多个线程中共享,每个thread访问的都是自己特定的副本,这种thread-specific的数据方法我们称之TLS。
对于linux环境,thread-local类型的数据并不是放入大家耳熟能详的.data或者.bss section,而是放入了.tdata和.tbss section。和.data或者.bss不同,执行中的程序不能直接访问.tdata和.tbss,这段section中数据更像是一个initial image,每个线程在创建的时候都会以.tdata或者.tbss为蓝本,创建自己thread-specific的数据,后续变量的访问都是针对自己thread local的数据区域。
了解了这些基础知识后,问题来了:我就写一个简单的hello world,又没有创建什么thread local的数据,为何还有.tdata和.tbss section呢?实际上虽然你的程序没有访问,但是c库中有访问,例如errno。在没有multi thread programming之前,errno是一个全局变量,然而,进入多线程编程环境之后,errno必须是thread local的才能不影响其接口形态。
原创文章,转发请注明出处。蜗窝科技
http://www.wowotech.net/basic_subject/static-link.html
评论:
mahjong
2017-07-08 17:28
扫描过程中,如果是.o文件,那么就将该.o文件加入E,并分析该.o文件的符号表,把该.o定义的符号信息假如到集合D中,该.o文件中未定义的符号会在集合D中scan,看看是否已经定义,如果以及定义,那么OK,符号已经解析了,如果在目前的集合D中没有定义该符号,那么就把该符号假如到集合U中
-----
这里貌似说反了,.o应该同样是后加入的给先加入的提供符号定义,如果.o和.a解析规则相反,岂不是很违反常理。
2015-10-23 14:09
楼主,如果程序用到了两个静态库,但两个静态库中有同名的函数该如何处理?
2015-10-23 15:59
@zuoertu:假设你用下面的命令来进行链接:
arm-linux-ld [all kinds of parameter] -o result a.o b.o c.o……aa.a bb.a cc.a……
并且bb.a和cc.a这两个静态库中都有一个叫做eee的函数,那么最终使用的是bb.a中的那个,因为linker的扫描顺序是从左到右
发表评论:
昵称
邮件地址 (选填)
个人主页 (选填)