
- 1精读《What‘s new in javascript》
- 2Python Project- Alien_invasion(外星人入侵)_外星人入侵python源代码
- 3Qt学习——利用Qt Assistant 定制帮助文档_制作qt assitant文件
- 4如何消耗更少资源?Unity优化技巧(上)_unity节省资源的方法
- 5linux em 网卡,Linux系统下查看网卡列表
- 6TCP 三次握手 四次挥手以及滑动窗口
- 7小米4A千兆版路由器刷入OpenWRT教程结合内网穿透远程访问_小米路由器4a刷openwrt
- 8Unity 2D独立开发手记(五):通用任务系统_unity2d游戏任务系统
- 9超级玛丽/超级马里奥_c#制作超级马里奥
- 10YOLOv7训练参数解释_yolov7训练时底下的参数
全文检索技术&&Lucene&&全文检索服务Solr部署详细步骤&&Solr后台管理界面的使用_全文检索后台管理页面示例
赞
踩
1.全文检索技术理论基础
1.全文检索技术的解决方案
原来的方法和实现搜索功能的流程图:
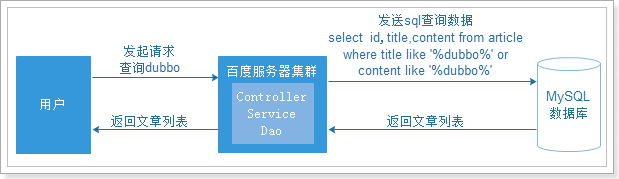
传统的搜索引擎技术,在一般数据库数据量比较小,用户量比较小的时候是比较常见的
但是在数据量增加到一定的量级的时候,数据库的压力就会变得很大,查询的速度会很慢,我们需要更好的解决方案来分担数据库的压力
使用全文检索技术的解决方案:

为了解决数据库的压力和速度的问题,我们的数据库变成了索引库,我们通过Lucene的API来操作服务器上的索引库,这样完全和数据库进行了隔离,从索引库中查询数据非常的快,但是在创建索引库的过程很慢,但是这个不影响我们在业务上的使用.
2.数据的查询方法
- 顺序扫描法
所谓顺序扫描法,在Windows中磁盘搜索框中搜索一个字符串的时候使用的就是顺序扫描法,打开第一个文件夹把里面的文件从头看到尾,再打开第二个文件夹...这样以此类推直到遍历完磁盘中的所有文件为止,就叫顺序扫描法,这种搜索方式如果数据量大速度很慢
- 倒排索引法
所谓倒排意思就是顺序扫描法是先找文档从文档中找出搜索项
倒排索引法是先在索引中找关键词,再根据索引去找文件,所以是倒序
Lucene会对文档建立倒排索引:
1.提取资源中的关键信息,建立索引(目录)
2.搜索时,根据关键字(目录),找到资源的位置
例如我们的新华字典查询汉字,查字的时候先查目录(索引),找到我想要找的字的页数,在根据这个页数去文档中找汉字
3.全文检索的特点
- 做了相关度排序
- 对文本中的关键字进行高亮显示
- 摘要截取
- 搜索效果更加精确,因为是基于单词搜索,比如搜索java时不会搜索出来JavaScript ,因为他们是两个不同的单词
- 只关注文本单词,不关注语义
4.索引和搜索的流程图

创建索引流程:
- 原始文档:原始文档有三类:网页,数据库,磁盘中的文件中获取到需要搜索的原始信息
- 获取文档:从互联网上,数据库中,文件系统中获取需要搜索的原始信息,
1.对于互联网上的网页,可以使用工具将网页抓取到本地生成html文件
2.数据库中的数据,可以连接数据库用select语句查询
3.文件系统中的某个文件用I/O流的方式读取文件的内容
- 创建文档对象:获取原始文档的目的就是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域,域中存储内容
我们可以将数据库中的一条记录当成一个Document,在这个Document中数据库中的列叫做Document中的域

注意:每个Document都可以有多个Filed(数据库中一条记录有多个字段),不同的Document可以有不同的Field(数据库中不同的记录有不同的字段),同一个Document可以有相同的Field(数据库中一条记录中允许有两个Id)(域名和域值都相同)
- 分析文档(分词)
将原始内容创建为包含域(Filed)的文档(Document),需要在对域中的内容进行分析,分析成一个个的单词
比如:源文档的内容:
Lucene is a Java full-text search engine. Lucene is not a complete
application, but rather a code library and API that can easily be used
to add search capabilities to applications.
分析后得到的词:
lucene、java、full、search、engine。。。。
- 创建索引
对文档分析(分词)后得到的词汇进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的词汇从而找到Document文档
查询索引流程:
搜索就是用户输入关键字,根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容
2.Lucene介绍
1.什么是Lucene
- Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供
- 是一个开放源码的全文检索引擎工具包,以方便在目标系统中实现全文检索功能
- Lucene只能够对文本类型的数据建立索引,其他格式的不行,所以你想要把其他格式的文件进行索引的话需要先把文件转换成文本类型之后在建立索引
2.Lucene,全文检索技术与搜索引擎的区别:
- 全文检索技术:一个文档,事先扫描程序会扫描文档中的每一个词,对每一个词建立一个索引,指明该词在文档中出现的位置和次数,当用户查询的时候,检索程序根据事先建立好的索引库进行查找,根据索引找到这个词的检索方式叫做全文检索技术.
- 搜索引擎:搜索引擎是全文检索技术最主要的一个应用,搜索引擎是一个用于提供全文检索服务的软件,是一个单独运行的软件系统,包括建立索引,处理查询返回结果,增加索引,优化索引等功能.例如:百度搜索,淘宝商品搜索等
- Lucene:Lucene是一个用来实现全文检索技术的类库,是一套用Java语言写的全文索引的工具包,为应用程序提供了多个API接口去调用,简单理解是一套能够实现全文检索技术的类库,通过全文检索技术才能实现一个完整的搜索引擎.
3.Field域类型
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包含多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容
Field属性:
- 是否分词
是:做分词处理,即将Field值进行分词,分词的目的是为了索引
比如:商品名称,商品描述等,这些内容用户要输入关键字搜索,但是原文的格式大内容多,需要分词之后将每一个词汇进行索引
否:不分词
比如:商品id,身份证号,订单号
- 是否索引
是:进行索引,将Field分词后的词进行索引,索引的目的是为了搜索
比如:商品名称,商品描述 分词后进行索引,订单号,身份证号不用分词但也要索引,这些将来都会作为查询条件
否:不索引
比如:图片路径,文件路径,不用作为查询条件的不用索引
- 是否存储
是:将Field值存储在文档域中,存储在文档域中的Field才能从Document中获取
比如:商品名称,订单号,凡是将来要从Document中获取的Field都要存储
否:不存储Field值
比如:商品描述,内容较大的不用存储,如果要向用户战术商品描述可以从系统的关系数据库中获取
Field常用类型:
| Field类 | 数据类型 | Analyzed 是否分词 | Indexed 是否索引 | Stored 是否存储 | 说明 |
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分词,会将整个串存储在索引中,比如(订单号,身份证号等) 是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) | Long型 | Y | Y | Y或N | 这个Field用来构建一个Long数字型Field,进行分词和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field 不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) | 字符串 或 流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
4.全文检索服务Solr
1.简介
Solr就是上文进行比较提到的搜索引擎服务
Solr是Apache下的顶级开源项目,采用java开发,它是基于Lucene的全文搜索服务.
Solr可以独立运行在Jetty,Tomcat等这些Servlet容器中
使用Solr进行创建索引和搜索索引的实现方法很简单:
- 创建索引:客户端(可以是浏览器也可以是Java程序)用Post方法向Solr服务器发送个描述Filed及其内容的XML文档,Solr服务器根据XML文档进行添加.删除.更新索引
- 搜索索引:客户端(可以是浏览器也可以是Java程序)用GET方法向Solr服务器发送请求,然后对Solr服务器返回XML.JSON等格式的查询结果进行解析,Solr不提供构建页面的UI功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况

2.Solr和Lucene的区别
Lucene是一个开源的全文检索引擎工具包,不是一个完整的全文检索应用,Lucene只提供了完整的查询引擎和索引引擎,母的是为开发人员在目标系统中实现全文检索功能
3.Solr的目录结构:
1.解压之后文件目录结构

SolrHome是Solr服务运行的主目录,该目录包括的多个SolrCore目录,SolrCore目录中包含了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,每个单独的SolrCore提供单独的搜索和索引服务
类似于mysql中有多个数据库
SolrHome目录

SolrCore目录

SolrCore里面的目录

4.Solr的安装配置
步骤一:把solr.war复制到tomcat/webapps/下
步骤二:exampl/lib/ext/*.jar 复制到 solr/WEB-INF/lib 下
步骤三:配置solr服务器连接索引库(SolrHome)
详细步骤:
1.找一个Tomcat解压到Solr目录下

2.把 solr-4.10.3/example/webapps/下的solr.war包复制到Tomcat中的webapp中

3.新创建一个solr文件夹,把solr.war解压进去

4.把solr额外需要的jar包拷贝进解压后的solr.war中的WEB-INF/lib的拓展包中

5.把solr源码包中的example/solr(家目录)拷贝到和tomcat为统同级目录

6.为了tomcat中的solr能连接上和tomcat同级目录的solrhome(solr家),更改tomcat/webapps/solr/WEB.INF/web.xml配置文件

把solr的家目录配置上

7.配置完成启动tomcat
5.配置IK分词器
步骤一:在solr目录下创建一个IK文件夹,把IK的.zip包解压到IK文件夹下

步骤二:进入到解压后的IK目录下,找到IKAnalyzer.cfg.xml主配置文件,把拓展词配置文件打开

步骤三:在拓展词配置文件和停止分词配置文件配置自己想设置的词组
步骤四:将IK分词器的jar包复制进tomcat中的solr下的lib的拓展包下

步骤五:在webapps/solr/WEB-INF下创建一个classes文件夹,因为在java工程中的classpath路径在发布之后就对应着这个WEB-INF/classes文件夹,把核心配置文件.拓展和停止分词这三个配置文件复制到classes下


步骤六:去schame配置文件中配置一个域类型使用IK分词器,并指定一个域使用这个域类型

步骤七:重启tomcat
步骤八:在管理界面中使用分词器为IK的域进行测试:

6.使用后台管理界面进行数据的批量导入
步骤一:在Schame.xml配置文件中配置业务域.准备迎接新添加到索引库中的数据表中的字段

步骤二:由于需要把Mysql数据库中的数据导入到索引库中,所以需要Mysql的驱动包,并且把Mysql的数据存到索引库中还需要两个转换包
这三个包需要放到Solrhome家目录下,所以在家目录下的Collection1这个核中创建一个lib文件夹用于保存这三个jar包

数据库驱动包需要自己准备,两个转换包在solr的源代码包中的dist目录下:/root/solr/solr-4.10.3/dist的 solr-dataimporthandler-4.10.3.jar 和 solr-dataimporthandler-extras-4.10.3.jar这两个包 这三个包都复制到家目录下的lib包下

步骤三:找到与schame同级的solrconfig.xml这个核心配置文件,添加一个requestHandler

步骤四:在solrconfig.xml的同级目录下创建data-config.xml文件,配置数据源和查询数据

步骤五:重启tomcat
步骤六:进入后台管理界面进行导入

7.solr家目录下schema.xml文件的详解
1.field
- name:域名城
- Type:域的类型
- indexed:是否索引
- Stored:是否存储
- Required:是否必须
- multiValued:是否多值,存储多个值时设置为true,solr允许一个Field存储多个值

2.动态域
- name:动态域的名称,是一个表达式,*匹配任意字符,只要域的名称和表达式的规则能够匹配就可以使用

3.主键
代表主键域,每个文档中必须有一个id域

4.复制域
可以将多个Field复制到一个Field中,以便进行统一的 搜索,当创建索引时,Solr服务会自动将源域的内容复制到目标域中
- source:源域
- dest:目标域,搜索时指定目标域为默认的搜索域.可以提高查询效率
定义目标域:
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
目标域必须要使用:multiValued="true"

5.域类型
- name:域类型的名称
- class:指定域类型的Solr类型
- analyzer:指定分词器,在FildType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分词器analyzeer,包括分词和过滤
- type:index和query.index是创建索引,query是查询索引
- tokenizer:指定分词器
- filter:指定过滤器

8.solr后台管理页面上的查询


