
- 1万字长文,详述TRIDENT: Poseidon 哈希算法的硬件加速与实现!_hash算法硬件
- 2Android 打开输入法,中文模式没有候选栏的问题_flagnoextractui
- 3python的webbrowser库如何使用
- 4Java开发者的囧境:那些让你苦笑不得的Bug_java时间bug
- 5基于反向传播的多层神经网络训练原理_(反向传播)神经网络的结构由输入层、______、输出层组成 site:blog.csdn.net
- 6微信小程序引入Vant Weapp修改样式不起作用,使用外部样式类进行覆盖_微信小程序修改vant样式
- 7数据库系统课程设计(高校成绩管理数据库系统的设计与实现)_数据库学生成绩管理系统课程设计
- 8Azure中的Blob存储_azure blob临时访问地址
- 9这十套练习,教你如何使用Pandas做数据分析_一共有多少种不同的商品被售出
- 10Flutter Slider自定义滑块样式 Slider的label标签框常显示
探讨生产环境下缓存雪崩的几种场景及解决方案_生产环境的redis、雪崩
赞
踩
本文首发自「慕课网」(www.imooc.com),想了解更多IT干货内容,程序员圈内热闻,欢迎关注"慕课网"或慕课网公众号!
作者:大能 | 慕课网讲师
缓存我们经常使用,但是有时候我们却会忽略缓存中的一些问题。我们将从生产环境的应用的角度,去考虑需要注意的一些异常情况,特别的是在高并发的场景下,如何让我们的缓存在提供高性能支持的同时,去保证数据的准确性,还有系统的稳定性。
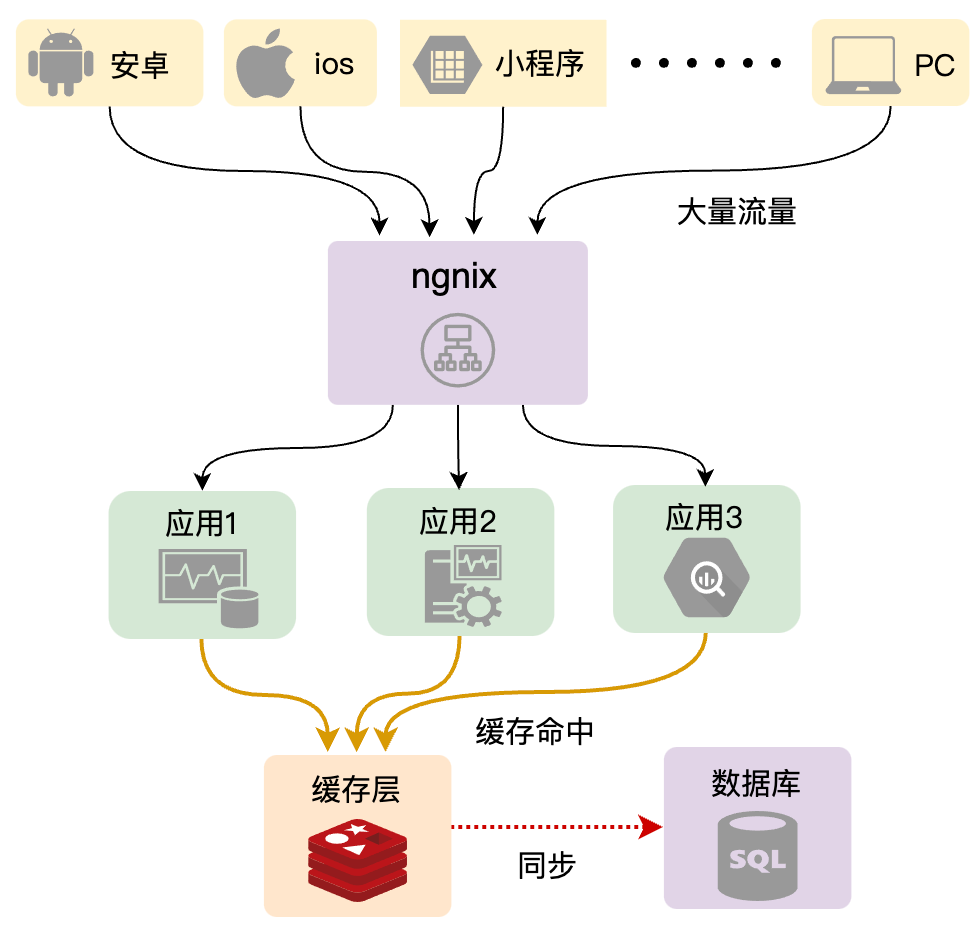
那么首先我们来看第一个问题,我们看这张图这里,这里我们引入的缓存的目的,就是用来帮助数据库去挡掉大部分的读请求,从而提升读请求的响应速度和并发能力,但是假如有一段时间,由于种种原因,这个缓存的数据不在了,那这个时候,这些读请求全部都直接落到数据库上面来,那如果这个时候并发量很大的话,就很有可能会把数据库给压垮,那数据库一垮基本上整个应用都会被拖垮了,更严重的话会造成一系列的连锁反应,会影响到上下游系统。
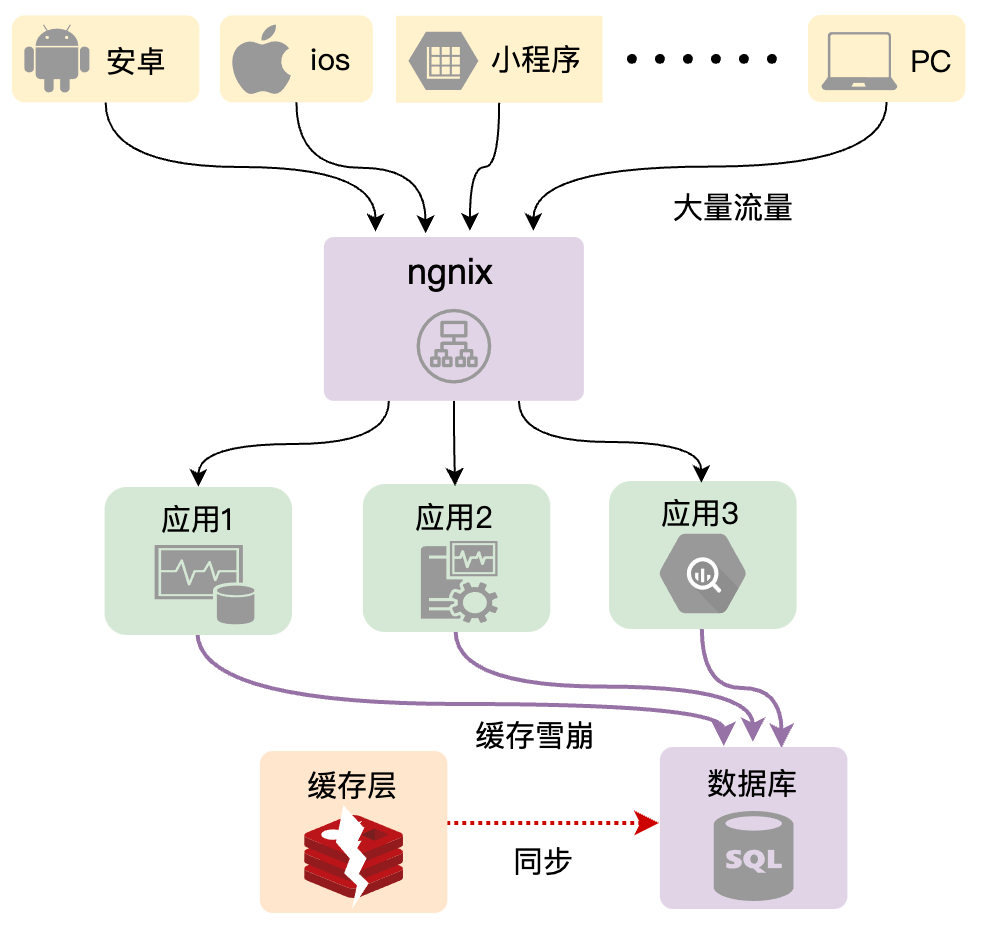
生产环节出现缓存雪崩的几种情况
那么我们总结一下这个问题就是:由于缓存数据失效(或不存在),导致大量读请求直接访问数据库,把数据库甚至应用拖垮。这个就是缓存雪崩问题。那么我们可以看到这里问题的关键点,在于大量的缓存数据失效(或不存在),一般在生产环节中,主要有这几种情况,可能会导致引起缓存雪崩问题:
情况一:
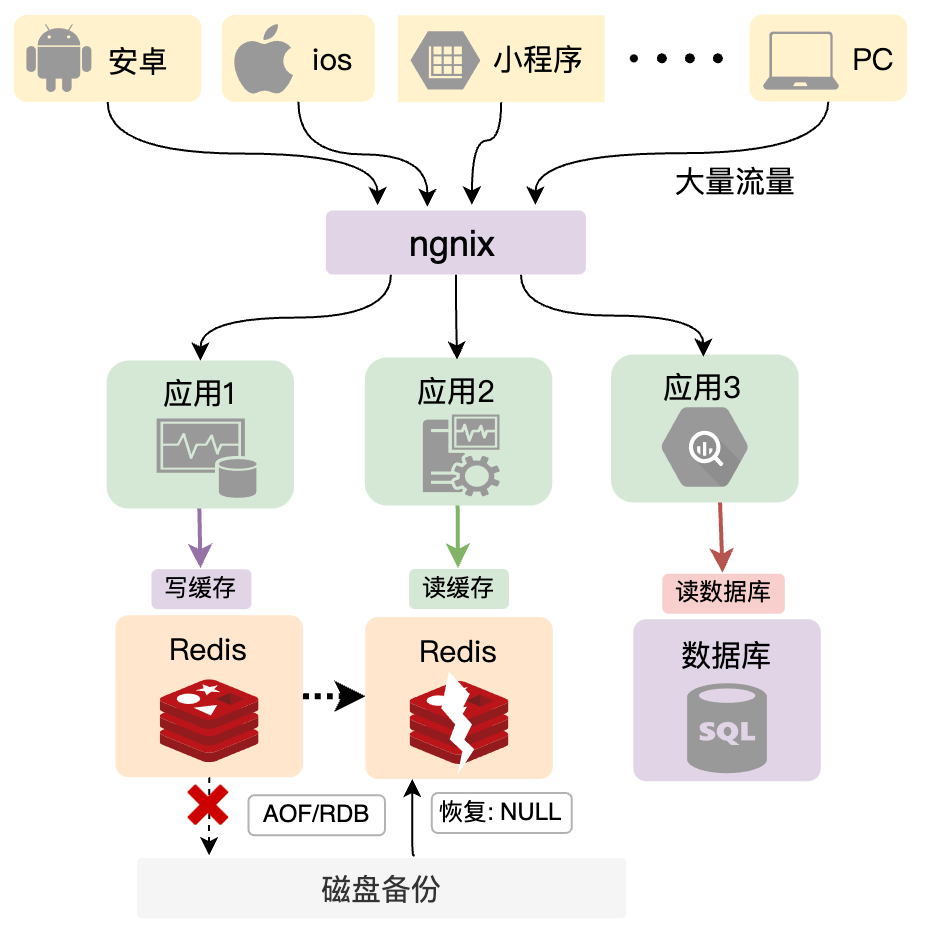
第一种情况可能是我们本身就没有进行提前预设置缓存,或者说有设置缓存,但是写入redis 的数据还没来的及持久化,redis服务异常重启,那么这种情况下就可能会导致缓存数据丢失。虽然说Redis提供了持久化机制,但它的两种持久化模式,RDB和AOF,都没办法百分之百保证数据不丢失,实际上在实战项目中,很多时候为了减少对中间件的依赖,为了降低运维成本,或者为了提升Redis性能等等这些因素的考虑,很多系统都是不开启Redis持久化机制的,那么这样当Redis发生重启的话,缓存数据就全部清空了。
情况二:
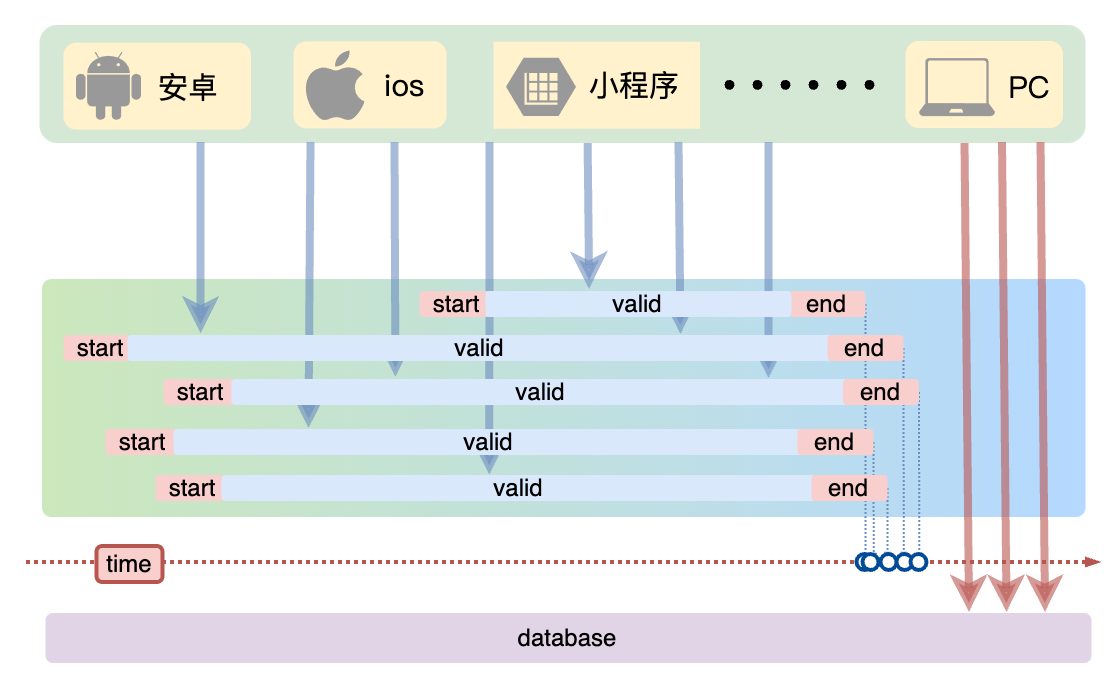
还有一种情况就是提前设置了缓存,但是呢缓存的过期时间设置过于集中,导致大批数据同时过期,所以我们在使用redis的时候呢也不得不考虑到这种情况的产生。就拿一年一度的双十一购物节来说,假如马上就要到双十一零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰,如果没有一个好的处理方案,可能在缓存失效的一瞬间,数据库就扛不住压力挂掉了,进而导致其它关联的系统被拖累,最终导致整个系统崩溃,这种情况就是我们常说的缓存雪崩,想象下这种情况如果发生在双十一会产生多么严重的影响。所以我们就得提前针对这种情况进行思考设计。
情况三:
最后还有一种情况就是,我们都知道为了保证较高的性价比,缓存的空间容量必然要小于后端数据库的数据总量,随着要缓存的数据量越来越大,缓存空间就不可避免的会被写满。这个时候redis就会有一个缓存数据的淘汰机制,如果我们这个缓存淘汰机制设置得不是很合理就会大面积的淘汰掉正在使用的缓存,就会导致上面说的问题。
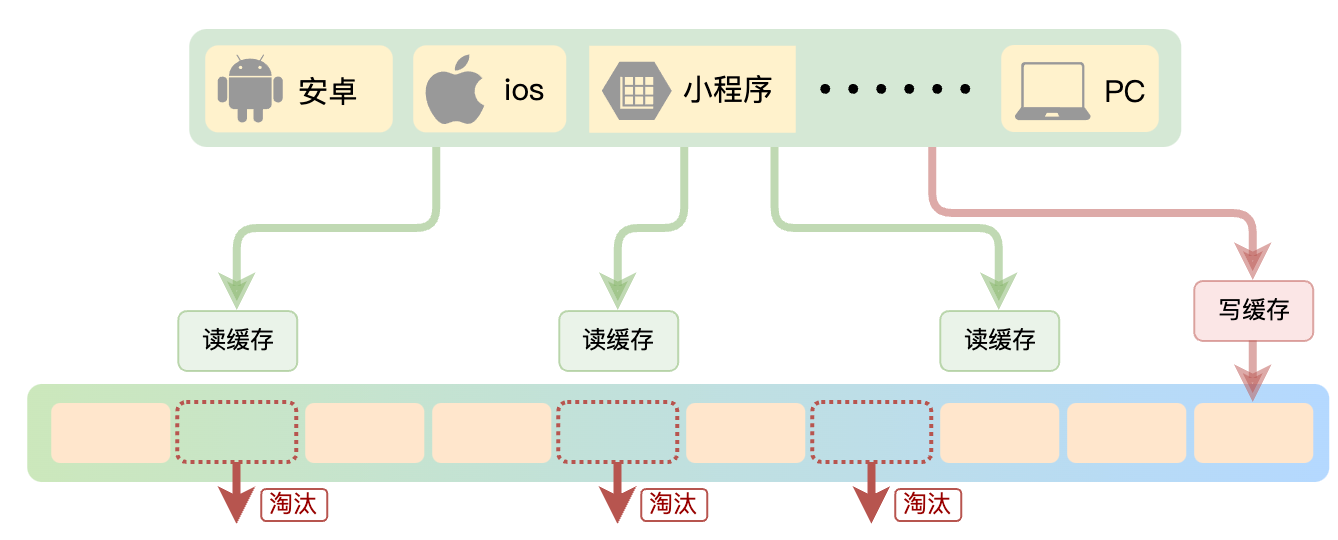
redis的缓存淘汰策略是指在Redis用于缓存的内存不足时, 怎么处理
这里我们看下redis的两个参数,我们可以通过设置maxmemory参数来设置内存的最大使用量(配置)
同时来配置maxmemory-policy参数:选择对应的内存淘汰规则(配置), 当内存不够用时, 会设置的内存淘汰规则
其中在Redis 中有如下淘汰规则
| 规则 | 规则说明 |
|---|---|
| noeviction | 当内存不足以容纳新写入的数据时, 新写入操作会报错 |
| allkeys-lru | 当内存不足以容纳新写入数据时, 在键空间中, 移除最近最少使用的key |
| allkeys-random | 当内存不足以容纳新写入数据时, 在键空间中, 随机移除某个key |
| volatile-lru | 当内存不足以容纳新写入数据时, 在设置了过期时间的键空间中, 移除最近最少使用的key |
| allkeys-random | 当内存不足以容纳新写入数据时, 在键空间中, 随机移除某个key |
| volatile-ttl | 当内存不足以容纳新写入数据时, 在设置了过期时间的键空间中, 有更早过期时间的key优先移除 |
那针对这种情况,我们可以结合项目的实际情况,通过指定合适的淘汰规则来避免有效的缓存数据丢失,那么这个也只能稍微缓解一下,如果应用中需要缓存的数据量非常大,这个时候可以通过扩大集群的部署规模,来增加整个缓存组件的容量。
处理缓存雪崩的几种解决方案
好那么上面就是三种主要的缓存失效的容易导致缓存雪崩的情况。
接下来我们来看一下常见的几种解决缓存雪崩的方案:
首先结合业务的特点和场景,从业务角度出发,我们来看一下有哪些优化手段 :
针对上面提到的缓存集中失效这个场景,我们可以采用这样的思路来缓解:
分散缓存失效时间
- 分散缓存失效时间。首先我们可以采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能
分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
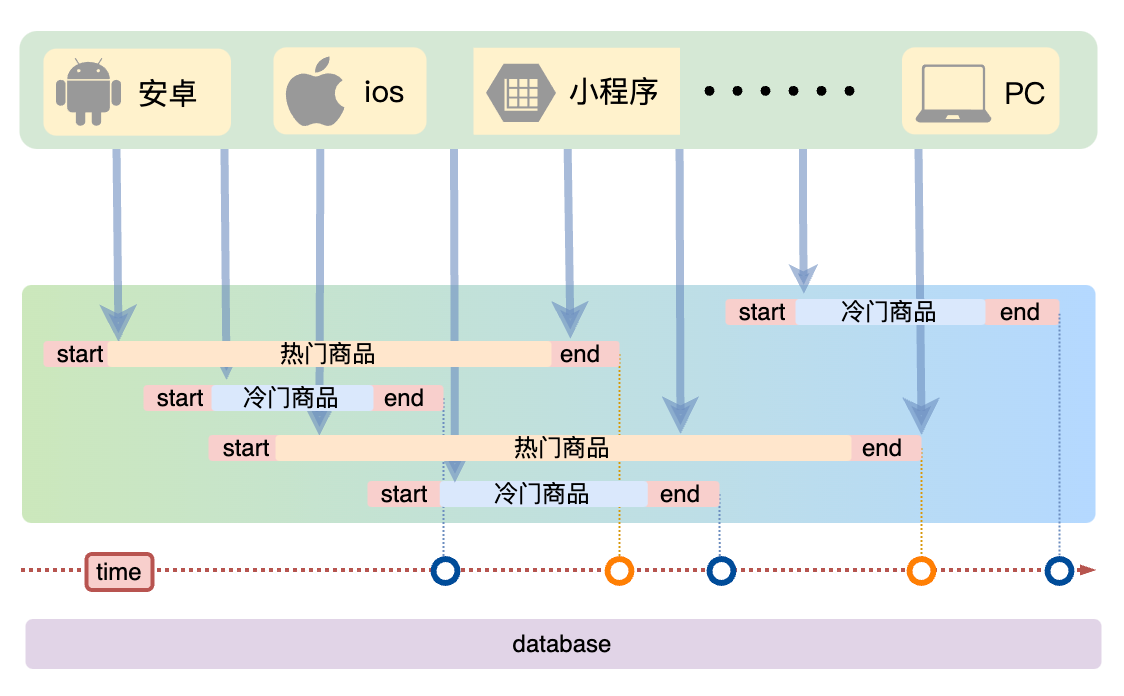
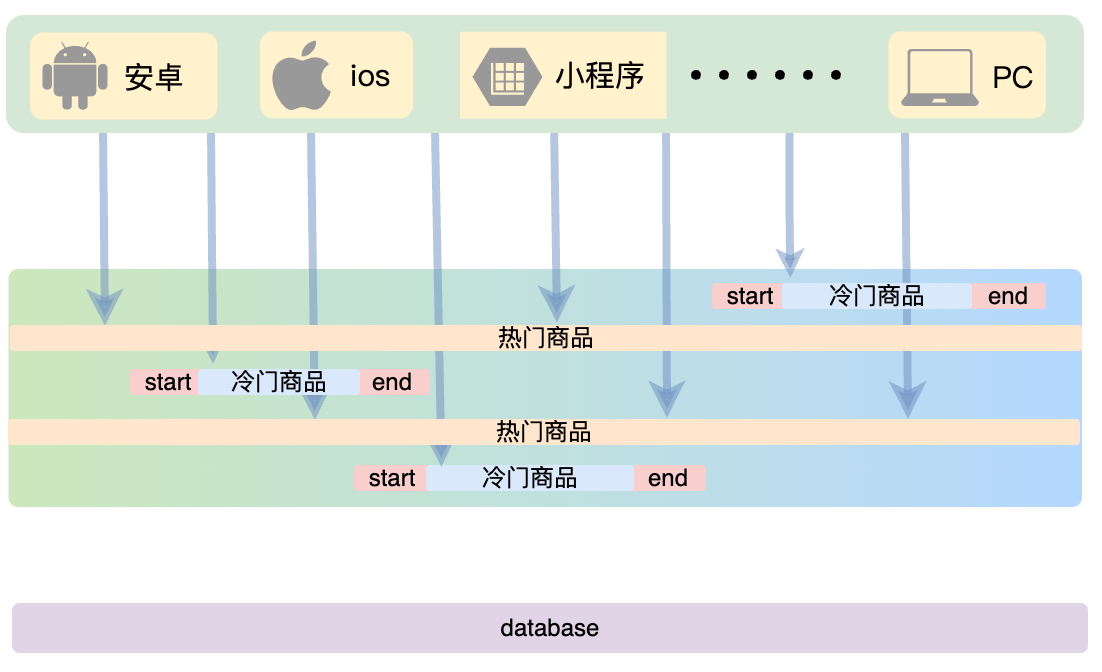
热门数据不设置过期时间
- 热门数据不设置过期时间。我们可以针对一些热门商户和热门商品的数据,也就是系统中最热门的数据,设置为数据永不过期。这样可这样可以保证这部分请求量很大的数据,一直能够从缓存中去获取数据
提前预热缓存数据
- 还有一个策略,就是提前预热缓存数据。什么叫缓存预热,缓存预热就是在系统启动之后,或者系统运行期间定期地将一些缓存数据直接加载到缓存系统,这样就可以避免等到用户请求的时候再去查询数据库,然后再将数据回写到缓存。那么这种策略,除了适合前面提到的系统中最热那一部分数据,也适合当系统有营销活动的时候,去提前预热相关的数据,避免活动一开始的时候,瞬间涌进来的流量把系统冲垮。
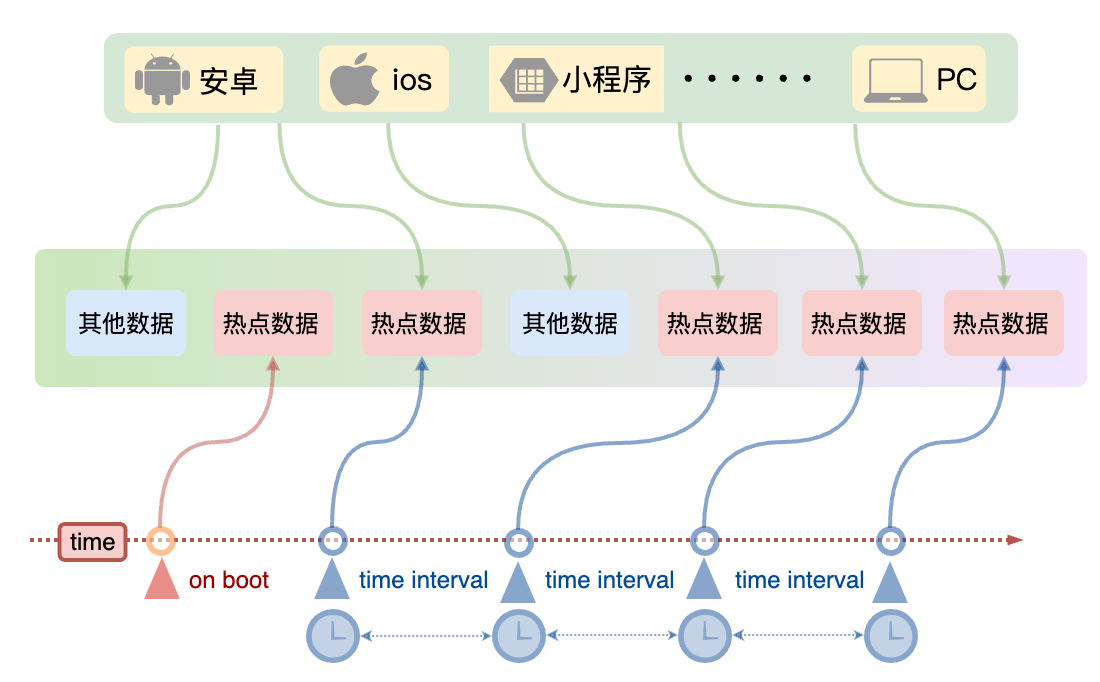
那么缓存预热的思路一般是这样的:
当数据量不大的时候,我们可以在工程启动的时候,就进行加载缓存动作;如果数据量比较大,那可以在运行期间通过定时任务脚本,去进行缓存的刷新;重点呢是优先保证热点数据能够提前加载到缓存。
好那这几个就是结合业务场景,从业务角度出发去优化的策略,但是光靠这些策略只能起到缓解的作用,还是不足以完全保证我们系统稳定,我们还是需要通过技术手段来进行保证,那么除了上面我们提到的通过扩大集群规模去解决容量不够的问题,我们接下来主要看一下针对缓存失效的情况,如何通过技术手段来防止系统雪崩问题
-
首先我们可以对数据库访问增加限流的处理 ,来保护我们的数据库,保护我们这个系统的核心资源。数据库它跟缓存组件不一样,它并不擅长应对高并发的场景,它所能承载的并发量,是远小于缓存中间件的, 那如果把访问缓存的请求全部怼到数据库,分分钟就把数据库搞垮了,通过限流让系统响应慢一点,总归比直接把系统拖垮好一些。
-
还有一种方式,我们可以进行缓存降级。那么缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认的数据,从而避免数据库遭受巨大压力,当然降级一般是对用户体验有损的,所以尽量减少降级对于业务的影响程度。
好了,通过上面说的这些方法,基本上可以避免缓存雪崩问题。谢谢大家。
欢迎关注「慕课网」官方帐号,我们会一直坚持提供IT圈优质内容,分享干货知识,大家一起共同成长吧!
本文原创发布于慕课网 ,转载请注明出处,谢谢合作

