
- 1ubuntu 22.04 下载安装网易云音乐_网易云音乐 ubuntu22.04
- 2牛客网在线编程本地调试正确而在线提交错误的最可能原因_牛客网站题目自测运行可以通过,但是保存体检显示错误
- 3【附源码】计算机毕业设计java疫苗接种管理系统设计与实现
- 4目标检测:YOLOv8 + PySide6 可视化界面设计步骤_pyside6写yolov8界面
- 5Linux 查看java进程的命令_查看linux java -jar的进程
- 6什么是GPU?跟CPU有什么区别?终于有人讲明白了_tensorflowcpu和gpu区别
- 7Spring boot 使用 WebSocket 的解决方案 包括sockjs stomp_springboot websocket sockjs
- 8【正点原子STM32连载】 第四十七章 FATFS实验 摘自【正点原子】APM32E103最小系统板使用指南_fatfs 正点原子
- 9使用Docker Compose_docker run -d -p 3000:3000
- 10C++基础——向上取整/向下取整_c++向上取整函数
Promethues (普罗米修斯)详细介绍_prometheus
赞
踩
目录
1、prometheus如何收集k8s/服务的–三种方式收集
引言
zabbix是传统的监控系统,出现比云原生早,使用的是SQL关系型数据库;而Prometheus基于谷歌的borgemon使用go语言开发,使用TSDB数据库,所以支持云原生。zabbix最新发布的6.0版本,知道自己处于生死存亡时刻,也支持了Prometheus使用的TSDB数据库。
一、Prometheus 概述
1、什么是Prometheus
Prometheus 是一个开源的服务监控系统和时序数据库,其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件Prometheus server会定期从静态配置的监控目标或者基于服务发现自动配置的自标中进行拉取数据,当新拉取到的数据大于配置的内存缓存区时,数据就会持久化到存储设备当中。
1.每个被监控的主机都可以通过专用的exporter 程序提供输出监控数据的接口,它会在目标处收集监控数据,并暴露出一个HTTP接口供Prometheus server查询,Prometheus通过基于HTTP的pull的方式来周期性的采集数据。
2.任何被监控的目标都需要事先纳入到监控系统中才能进行时序数据采集、存储、告警和展示,监控目标可以通过配置信息以静态形式指定,也可以让Prometheus通过服务发现的机制进行动态管理。
3.Prometheus 能够直接把API Server作为服务发现系统使用,进而动态发现和监控集群中的所有可被监控的对象。
2、Zabbix和Prometheus区别
1.和Zabbix类似,Prometheus也是一个近年比较火的开源监控框架,和Zabbix不同之处在于Prometheus相对更灵活点,模块间比较解耦,比如告警模块、代理模块等等都可以选择性配置。服务端和客户端都是开箱即用,不需要进行安装。zabbix则是一套安装把所有东西都弄好,很庞大也很繁杂。
2.zabbix的客户端 agent 可以比较方便的通过脚本来读取机器内数据库、日志等文件来做上报。而 Prometheus 的上报客户端则分为不同语言的SDK和不同用途的 exporter 两种,比如如果你要监控机器状态、mysql性能等,有大量已经成熟的 exporter 来直接开箱使用,通过http 通信来对服务端提供信息上报(server去pull信息);而如果你想要监控自己的业务状态,那么针对各种语言都有官方或其他人写好的 sdk供你使用,都比较方便,不需要先把数据存入数据库或日志再供zabbix-agent采集。
3.zabbix的客户端更多是只做上报的事情,push模式。而Prometheus则是客户端本地也会存储监控数据,服务端定时来拉取想要的数据。
4.界面来说zabbix比较陈旧,而prometheus比较新且非常简洁,简洁到只能算一个测试和配置平台。要想获得良好的监控体验,搭配Grafana还是二者的必走之路。
3、Prometheus的特点
多维数据模型:由度量名称和键值对标识的时间序列数据
时序数据,是在一段时间内通过重复测量(measurement)而获得的观测值的集合;将这些观测值绘制于图形之上,它会有一个数据轴和一个时间轴;
服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据;
1.内置时间序列(pime series)数据库:Prometheus;外置的远端存储通常会用:InfluxDB、openTsDB等
2.promQL一种灵活的查询语言,可以利用多维数据完成复杂查询
3.基于HTTP的pull(拉取)方式采集时间序列数据
4.同时支持PushGateway组件收集数据
5.通过服务发现或者静态配置,来发现目标服务对象
6.支持作为数据源接入Grafana
二、运维监控平台设计思路
① 数据收集模块
② 数据提取模块(prometheus-TSDB,查询语言是promQL)
③ 监控告警模块(布尔值表达式判断是否需要告警,不成立是健康状态)
可以细化为6层
第六层:用户展示管理层 同一用户管理、集中监控、集中维护
第五层:告警事件生成层 实时记录告警事件、形成分析图表(趋势分析、可视化)
第四层:告警规则配置层 告警规则设置、告警伐值设置(定义布尔值表达式,筛选异常状态)
第三层:数据提取层 定时采集数据到监控模块
第二层:数据展示层 数据生成曲线图展示(对时序数据的动态展示)
第一层:数据收集层 多渠道监控数据(网络,硬件,应用,数据,物理环境)
三、Prometheus监控体系
1、系统层监控(需要监控的数据)
1.CPU、Load、Memory、swap、disk、I/O、process等
2.网络监控:网络设备、工作负载、网络延迟、丢包率等
2、中间件及基础设施类监控
1.消息中间件:kafka、RocketMQ、等消息代理(redis 中间件)
2.WEB服务容器:tomcat、weblogic、apache、php、spring系列
3.数据库/缓存数据库:Mysql、Postgresql、MongoDB、es、redis
2.1 redis监控内容
① redis的服务状态
② redis所在服务器的系统层监控
③ RDB和AOF日志监控
日志--->如果是哨兵模式--->哨兵共享集群信息,产生的日志--->直接包含的其他节点哨兵信息及mysql信息
3、应用层监控
用于衡量应用程序代码状态和性能
监控的分类:
白盒监控:自省指标,等待被下载(cadvisor)
黑盒监控:基于探针(snmp)的监控方式,不会主动干预、影响数据
4、业务层监控
用于衡量应用程序的价值,如电商业务的销售量,ops、dau日活、转化率等,
业务接口:登入数量,注册数、订单量、搜索量和支付量
四、prometheus时间序列数据
时序数据,是在一段时间内通过重复测量(measurement)而获得的观测值的集合将这些观测值绘制于图形之上,它会有一个数据轴和一个时间轴,服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据
1、数据来源
prometheus基于HTTP call (http/https请求),从配置文件中指定的网络端点(endpoint/IP:端口)上周期性获取指标数据。
很多环境、被监控对象,本身是没有直接响应/处理http请求的功能,prometheus-exporter则可以在被监控端收集所需的数据,收集过来之后,还会做标准化,把这些数据转化为prometheus可识别,可使用的数据(兼容格式)
2、收集数据
监控概念:白盒监控、黑盒监控
白盒监控:自省方式,被监控端内部,可以自己生成指标,只要等待监控系统来采集时提供出去即可
黑盒监控:对于被监控系统没有侵入性,对其没有直接"影响",这种类似于基于探针机制进行监控(snmp协议)
Prometheus支持通过三种类型的途径从目标上"抓取(Scrape)"指标数据(基于白盒监控);
Exporters ——>工作在被监控端,周期性的抓取数据并转换为pro兼容格式等待prometheus来收集,自己并不推送
Instrumentation ——>指被监控对象内部自身有数据收集、监控的功能,只需要prometheus直接去获取
Pushgateway ——>短周期5s—10s的数据收集
3、prometheus(获取方式)
Prometheus同其它TSDB相比有一个非常典型的特性:它主动从各Target上拉取(pull)数据,而非等待被监控端的推送(push)
两个获取方式各有优劣,其中,Pull模型的优势在于:
集中控制:有利于将配置集在Prometheus server上完成,包括指标及采取速率等;
Prometheus的根本目标在于收集在rarget上预先完成聚合的聚合型数据,而非一款由事件驱动的存储系统
通过targets(标识的是具体的被监控端)
比如配置文件中的 targets:['localhost:9090']
五、prometheus生态组件
1、Prometheus Server
收集和储存时间序列数据
Prometheus server:服务核心组件,采用pull方式收集监控数据,通过http协议传输。并存储时间序列数据。Prometheus server 由三个部分组成:Retrival,Storage,PromQL
Retrieval:负责在活跃的target 主机上抓取监控指标数据。
Storage:存储,主要是把采集到的数据存储到磁盘中。默认为15天(可修改)。
PromQL:是Prometheus提供的查询语言模块。
2、Client Library
client Library:客户端库,目的在于为那些期望原生提供 Instrumentation 功能的应用程序提供便捷的开发途径,用于基于应用程序内建的测量系统。
3、Push Gateway
Pushgateway:类似一个中转站,Prometheus的server端只会使用pull方式拉取数据,但是某些节点因为某些原因只能使用push方式推送数据,那么它就是用来接收push而来的数据并暴露给Prometheus的server拉取的中转站。可以理解成目标主机可以上报短期任务的数据到Pushgateway,然后Prometheus server 统一从Pushgateway拉取数据。
4、Exporters
用于暴露现有应用程序或服务(不支持Instrumentation)的指标给Prometheus Server
而pro内建了数据样本采集器,可以通过配置文件定义,告诉prometheus到那个监控对象中采集指标数据,prometheus 采集过后,会存储在自己内建的TSDB数据库中,提供了promQL 支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alerter来发送告警信息,还支持对接外置的UI工具(grafana)来展示数据
采集、抓取数据是其自身的功能,但一般被抓去的数据一般来自于:
export/instrumentation (指标数据暴露器) 来完成的,或者是应用程序自身内建的测量系统(汽车仪表盘之类的,测量、展示)来完成
5、Alertmanager
Alertmanager:是一个独立的告警模块,从Prometheus server端接收到“告警通知”后,会进行去重、分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件、钉钉、企业微信等。
1.Prometheus Server 仅负责生成告警指示,具体的告警行为由另一个独立的应用程序AlertManager负责;
2.告警指示由 Prometheus Server基于用户提供的告警规则周期性计算生成,Alertmanager 接收到Prometheus Server发来的告警指示后,基于用户定义的告警路由向告警接收人发送告警信息。
6、Service Discovery
Service Discovery:服务发现,用于动态发现待监控的Target,Prometheus支持多种服务发现机制:文件、DNS、Consul、Kubernetes等等。
服务发现可通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮询这些Target 获取监控数据。该组件目前由Prometheus Server内建支持
7、grafana
Grafana:是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。其官方库中具有丰富的仪表盘插件。
Prometheus 数据流向
① Prometheus server 定期从配置好的 jobs 或者 exporters 中拉取 metrics,或者接收来自 Pushgateway 发送过来的metrics,或者从其它的Prometheus server中拉取 metrics。
② Prometheus server在本地存储收集到的 metrics,并运行定义好的 alerts.rules,记录新 的时间序列或者向Alert manager推送警报。
③ Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
④ 在图形界面中,可视化采集数据。
六、prometheus工作原理
1、prometheus工作模式
1. Prometheus Server 基于服务发现(Service Discovery)机制或静态配置获取要监视的目标(Target),并通过每个目标上的指标 exporter来采集(Scrape)指标数据;
2. Prometheus Server 内置了一个基于文件的时间序列存储来持久存储指标数据,用户可使用PromQL接口来检索数据,也能够按需将告警需求发往Altermanager完成告警内容发送;
3. 一些短期运行的作业的生命周期过短,难以有效地将必要的指标数据供给到Server端,它们一般会采用推送(Push)方式输出指标数据,Prometheus借助于Pushgateway 接收这些推送的数据,进而由server端进行抓取
2、prometheus工作流程
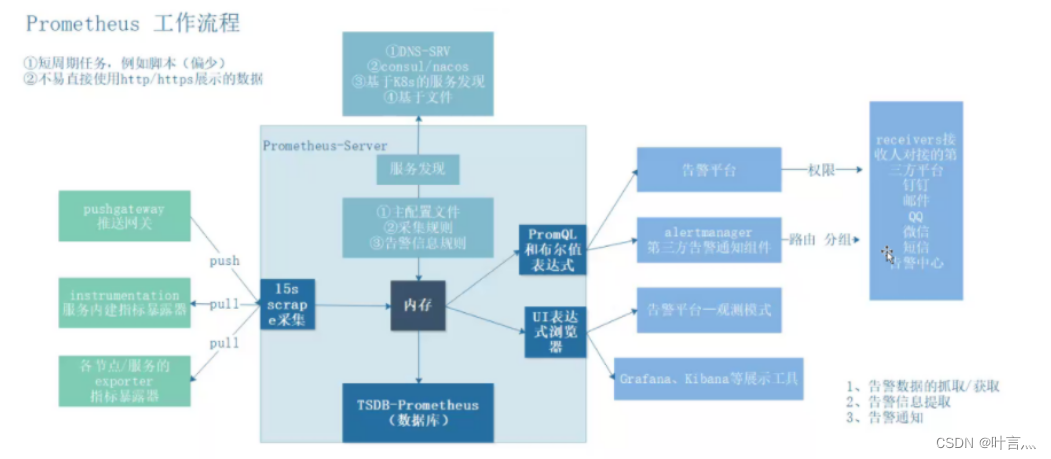
① Prometheus以prometheus Server 为核心,用于收集和存储时间序列数据。Prometheus Server从监控目标中通过pull方式拉取指标数据,或通过pushgateway 把采集的数据拉取到Prometheus server中。
② Prometheus server 把采集到的监控指标数据通过 TSDB存储到本地HDD/ssD中。
③ Prometheus 采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发 送到Alertmanager。
④ Alertmanager 通过配置报警接收方,发送报警到邮件、钉钉或者企业微信等。
⑤ Prometheus 自带的Web UI 界面提供 PromQL 查询语言,可查询监控数据。
⑥ Grafana 可接入Prometheus 数据源,把监控数据以图形化形式展示出。
ps:告警数据采集、告警信息提取、告警通知
① 首先,需要采集监控数据,pro会周期性的pull或被push指标数据,数据采集的方式主要包括exporters、instrumentation、pushgateway 3种方式,前两者为pull方式获取,pushgateway借助于push方式推送给prometheus。
② 根据prometheus配置文件中(K8S-configmap的配置种),获取被监控端的数据之后,保存在TSDB中,我们可以借助Grafana或者告警平台来展示数据,grafana的展示是通过PromQL来获取数据。
③ prometheus通过rule配置来借助于PromQL来定义布尔值表达式,产生告警信息
④ 一旦出现告警,prometheus产生告警信息,发送给altermanager,altermanager根据自定义的告警路由,来进行告警通知,对接第三方平台,例如告警平台、邮件、钉钉。
3、prometheus的局限性
1. Prometheus是一款指际监控系统,不适合存储事件及日志等;它更多地展示的是趋势性的监控,而非精准数据;
2. Prometheus认为只有最近的监控数据才有查询的需要,其本地存储的设计初衷只是保存短期(例如一个月)数据,因而不支持针对大量的历史数据进行存储;若需要存储长期的历史数据,建议基于远端存储机制将数据保存于InfluxDB或openTsDB等系统中;
3. Prometheus的集群机制成熟度不高,可基于Thanos(和灭霸是一个单词)实现Prometheus集群的高可用及联邦集群
总结
1、prometheus如何收集k8s/服务的–三种方式收集
Exporters(指标暴露器):收集节点的信息、将数据格式化或转化为 promtheus 可识别的http这种转化方式/镜像拉取方式
Instrumentation (应用内置的指标暴露器): 收集有内置指标暴露器的信息
Pushgateway : 收集短周期的数据
2 、如何防止告警信息轰炸
alertmanagr: prometheus可以生成告警信息,但是不能直接提供告警,需要使用一个外置的组件alertmanager来进行告警,emailetctif优势在于,收敛、支持静默、去重、可以防止告警信息的轰炸
把这条告警规则中的支持静默开启,让它必须,配置文件里直接改alertmanager改一个单词
3、prometheus监控什么
| 级别 | 监控什么 | exporter |
| 网络 | 网络协议:http、dns、tcp、icmp; 网路硬件:路由器、交换机等 | BlockBox Exporter;SNMP Exporter |
| 主机 | 资源用量 | node exporter |
| 容器 | 资源用量 | cadvisor |
| 应用(包括Library) | 延迟、错误,QPS,内部状态 | 代码集中集成Prometheus Client |
| 中间件状态 | 资源用量,以及服务状态 | 代码集中集成Prometheus Client |
| 编排工具 | 集群资源用量,调度等 | Kubernetes Components |
4、常见的时间序列数据库
| TSDB项目 | 官网 |
| influxDB | InfluxDB: Open Source Time Series Database | InfluxData |
| RRDtool | RRDtool - About RRDtool |
| Graphite | Graphite |
| OpenTSDB | OpenTSDB - A Distributed, Scalable Monitoring System |
| Kdb+ | KX: The Leading Provider of Time-Series Database Technology |
| Druid | Druid | Database for modern analytics applications |
| KairosDB | KairosDB |
| Prometheus | Prometheus - Monitoring system & time series database |

