- 1【云计算学习】open stack云平台安装部署(一)(小白手把手教会、保姆级教程)_从零部署openstack
- 2intellij中svn提示authentication required的解决方法_idea svn需要身份验证
- 3常用显著性检验_联合显著性检验
- 4自动化测试工具软测界的不二之选,还不快速来了解_龙测科技的私有设备需要收费吗
- 5鸿蒙5.0到来,能与IOS和安卓对抗吗?_鸿蒙支持electron吗
- 6uni-app与HTML的标签变化_uniapp v-html 显示a标签
- 7计算机网络基本概念汇总_计算机通信与网络概念知识汇总
- 8生产者消费者_thread demon
- 9HarmonyOS入门学习
- 10网页播放器的全屏代码
ArkUI - 状态管理_arkui @state
赞
踩
目录
三、@Prop和@Link、@Provide和@Consume
一、@State装饰器

这里涉及到两个概念 状态 和 视图
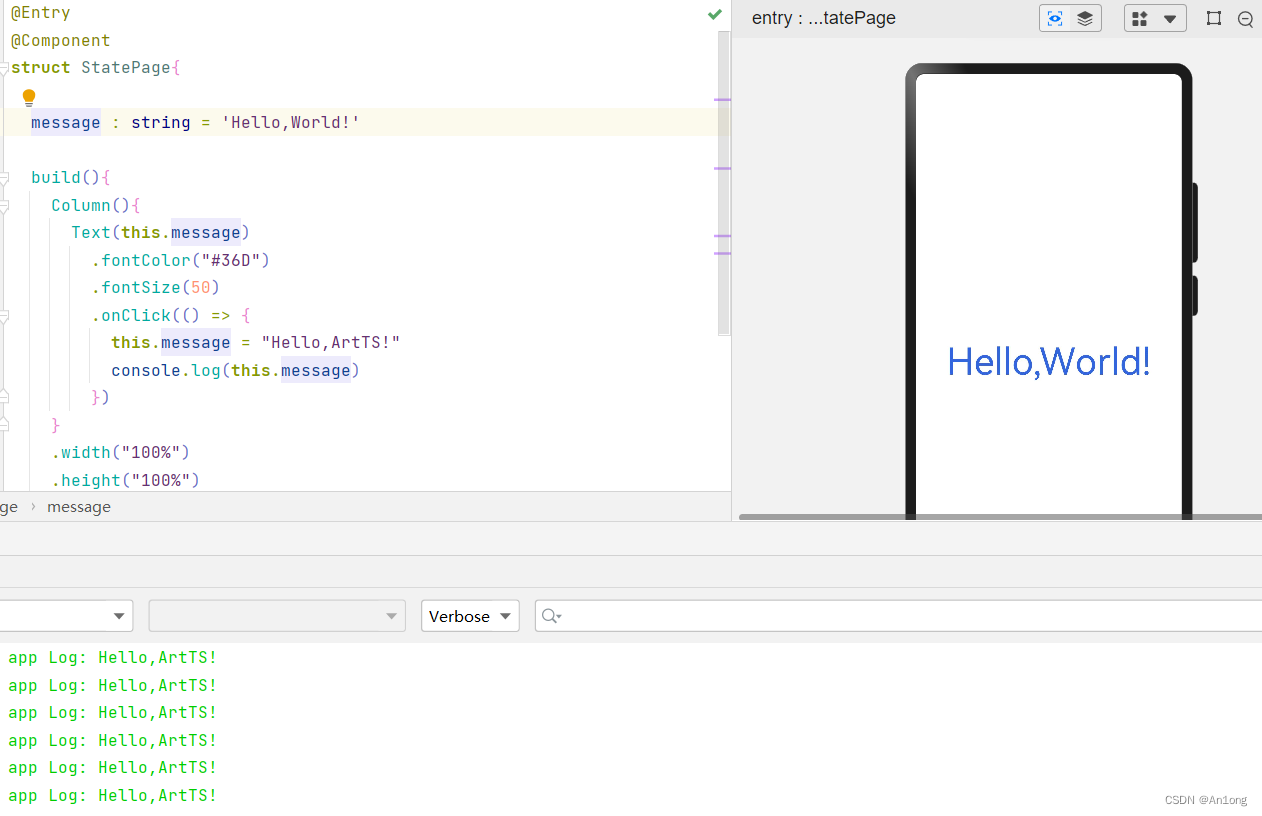
- 状态(State):指驱动视图更新的数据(就是被@State注解标记的变量)
- 视图(View):基于UI描述渲染的得到的用户界面
简单来说,就是被@State修饰的变量如果在视图中被互动事件修改了,如果别的地方要是用到了这个变量也会同时被修改。但如果只是一个普通的变量的话视图里面不会发生任何变化(不过在底层里是被真正修改了的,只是不会触发视图更新渲染而已)。
注意:
1、@State装饰器标记的变量必须初始化,不能为空值,否则直接报错
2、@State装饰器不允许标记any、union这种复杂的类型
3、嵌套类型以及数组中的对象属性不能触发视图更新,如果真的需要实现这个情况,那么就要使用@Observed和ObjectLink注解,最后会讲到。
二、自定义组件
ArkTS通过struct声明组件名,并通过@Component和@Entry装饰器,来构成一个自定义组件。使用@Entry和@Component装饰的自定义组件作为页面的入口,会在页面加载时首先进行渲染。
其实说白了就是把你写好的一个组件分模块封装起来,类似于Vue的组件
这里会涉及到三个注解,上一篇只是简单提及了一下
- @Bulider:将组件封装为一个函数
- @Extend():括号中写组件,这个是控制这个组件在这个项目中全局的样式
- @Styles:这是将样式封装起来作为一函数
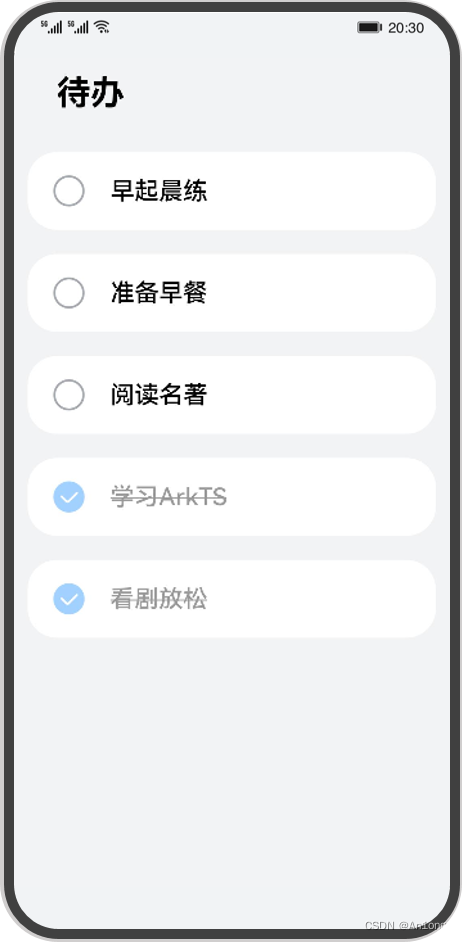
比如在这个页面中,每一个待办项其实都是相同的,复用性极高,我们可以将这个组件单独提取出来然后多次复用。

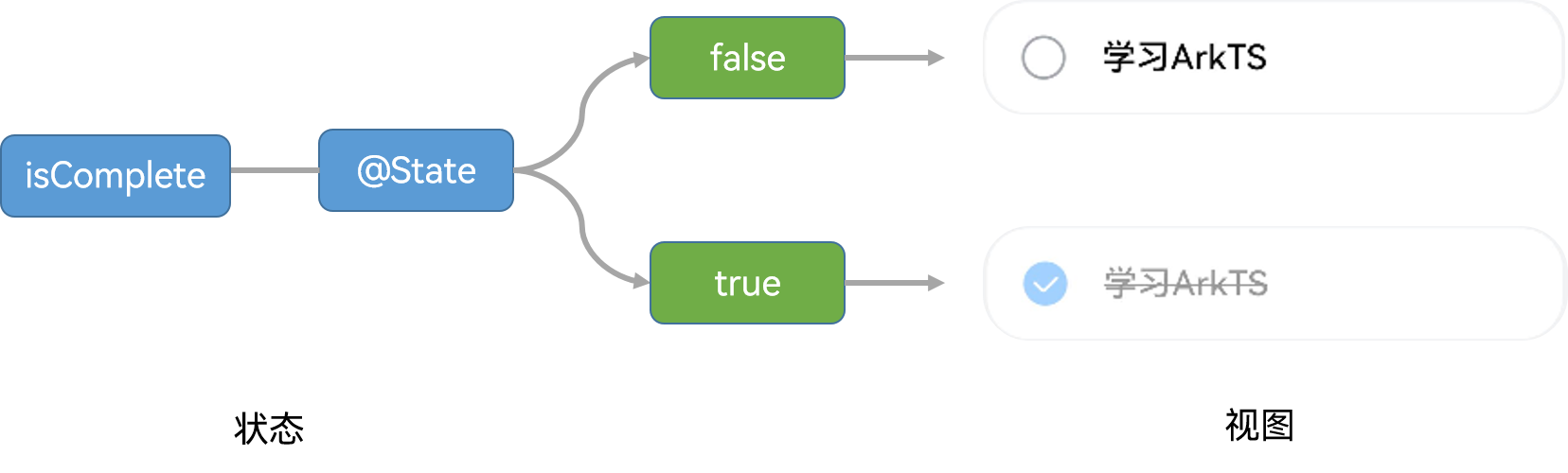
其次就是每个待办项有两种渲染状态,完成以及待办
先来看看这个部分的代码
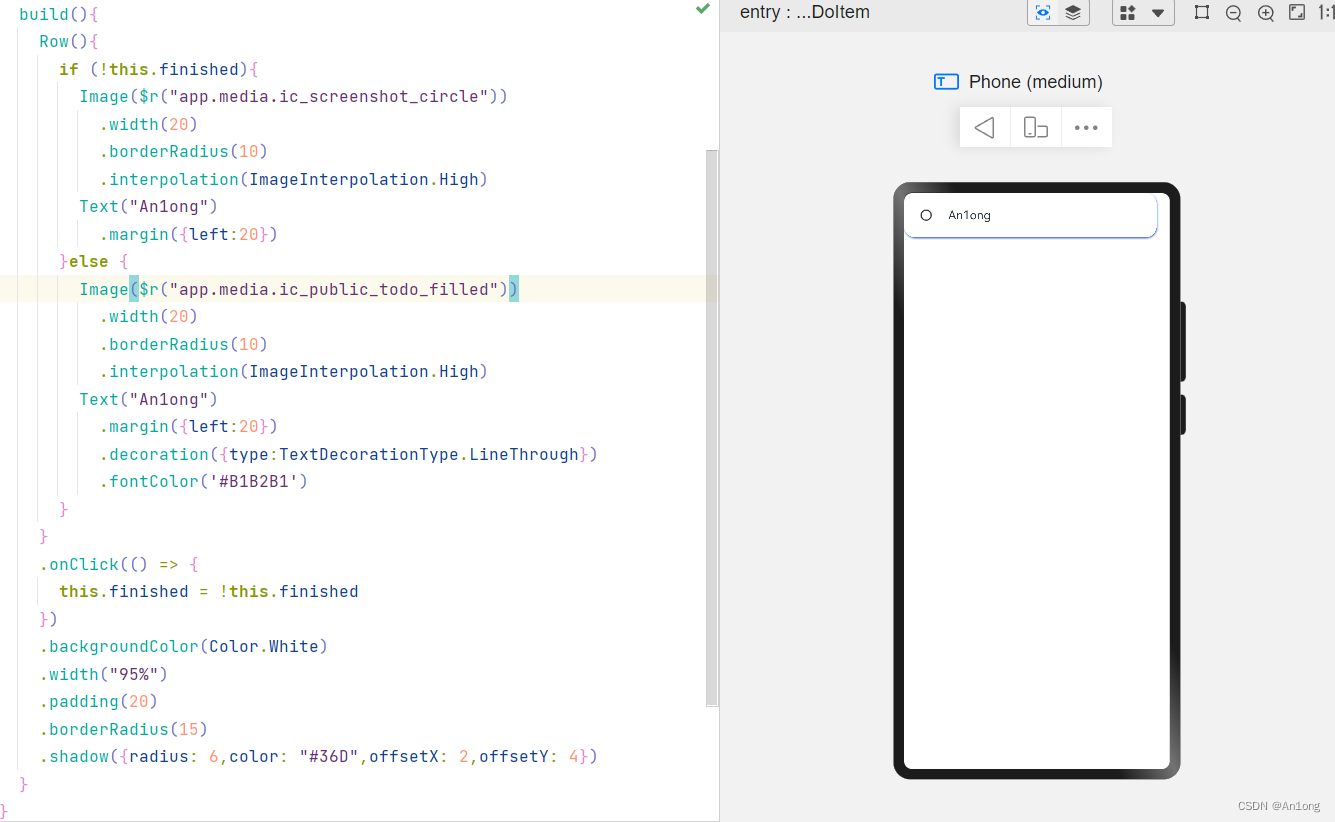
可以看出这两个Image的实现具有大量重复代码,也就图片参数不一样,这两个图片可以在鸿蒙官网上直接下载然后放在media文件里。
最后强调一次$r("app.xxx")是查找本地资源,app是默认前缀必须携带。
@Bulider装饰器可以将组件直接封装在函数里面多次调用。
现在我们使用@Bulider将这部分重复的逻辑封装起来,然后用@Styles和@Extend将样式也封装起来。
- @Component
- export struct ToDoItem {
- @State private finished: boolean = false;
- private content: string = "新任务";
-
- build() {
- Row() {
- this.card(this.content)
-
- }
- .cardStyle()
-
- .onClick(() => {
- this.finished = !this.finished
- })
- }
-
- @Builder card(content: string) {
-
- if (!this.finished) {
- Image($r("app.media.ic_screenshot_circle"))
- .ToDoImg()
- Text(content)
- .margin({ left: 20 })
- } else {
- Image($r("app.media.ic_public_todo_filled"))
- .ToDoImg()
- Text(content)
- .finishedToDo()
- }
-
-
- }
-
- @Styles cardStyle() {
- .backgroundColor(Color.White)
- .width("95%")
- .padding(20)
- .borderRadius(15)
- .shadow({ radius: 6, color: "#36D", offsetX: 2, offsetY: 4 })
- .margin(10)
- }
- }
-
- @Extend(Text) function finishedToDo() {
- .margin({ left: 20 })
- .decoration({ type: TextDecorationType.LineThrough })
- .fontColor('#B1B2B1')
- }
-
- @Extend(Image) function ToDoImg() {
- .width(20)
- .borderRadius(10)
- .interpolation(ImageInterpolation.High)
- }
-
-

这样一个自定义组件就完成了
注意:
1、@Builder与@Styles写在struct的外面里面都可以,不过@Extent只能写在struct外面
2、如果要写在struct外面,就要像Extent一样在名字前加上function关键字
然后在另一个组件中调用,这样的话,ToDoList就是父组件了,相对的其调用的ToDoItem就是子组件
- import { ToDoItem } from '../TODO/ToDoItem'
- @Entry
- @Component
- struct ToDoList{
- build(){
- Column(){
- ToDoItem({content:"An1ong"})
- ToDoItem({content:"完成啦!"})
- }
- }
- }
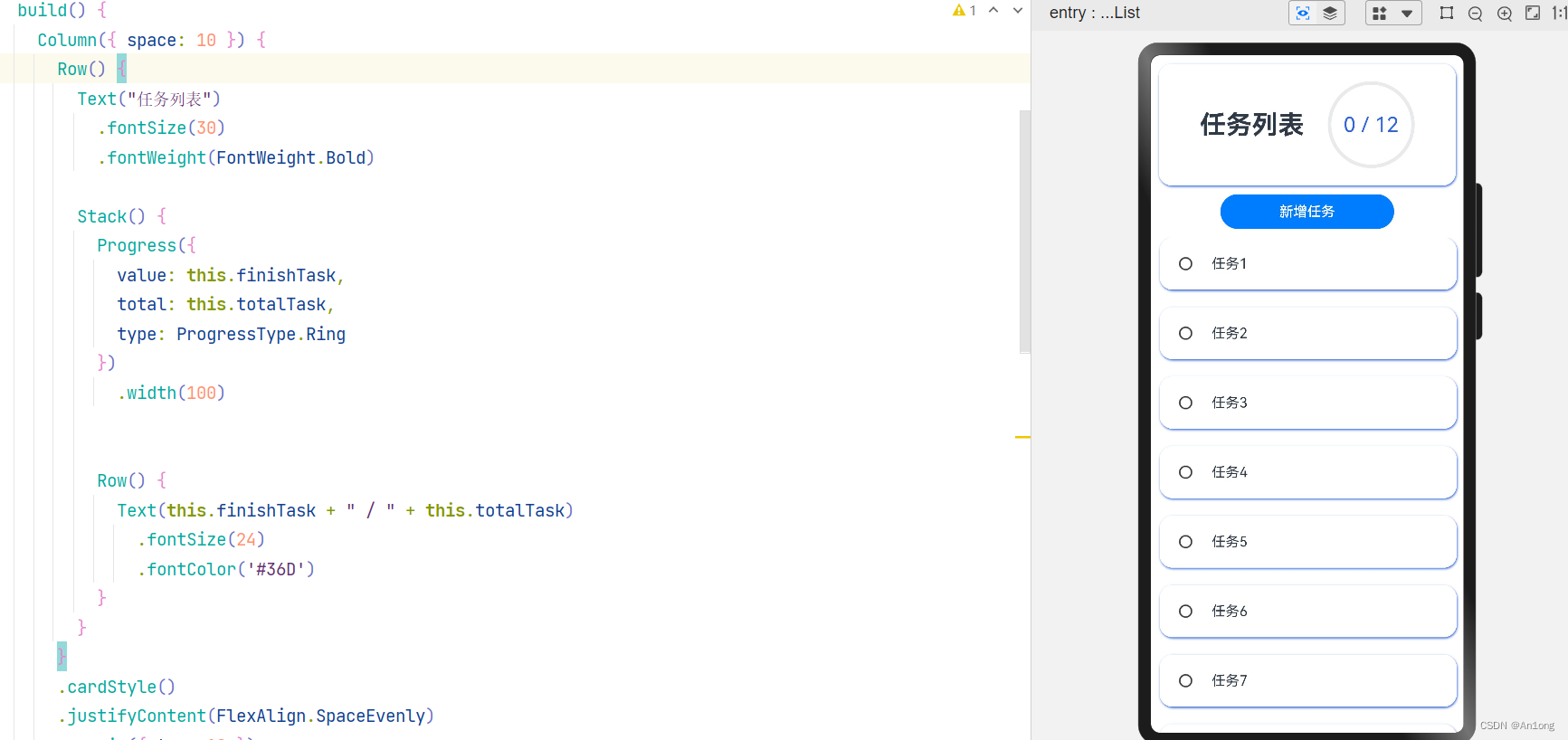
效果

是不是感觉代码一下子就整洁规范起来了。你也可以使用之前学到的List和ListItem,以及一些组件优化这个页面。
三、@Prop和@Link、@Provide和@Consume
当父子组件之间需要数据同步时,可以使用@Porp和@Link装饰器
啥是父子组件呢?就比如我们刚才的ToDoList案例中,我们将每一个ToDoItem分离了出来,然后在总体的Entry入口ToDoList中调用,这就是父子组件。如果在父组件定义了一个变量,在子组件中是无法直接调用获取的(当然你专门写个方法传递也是可以的)
这两个注解的区别是:
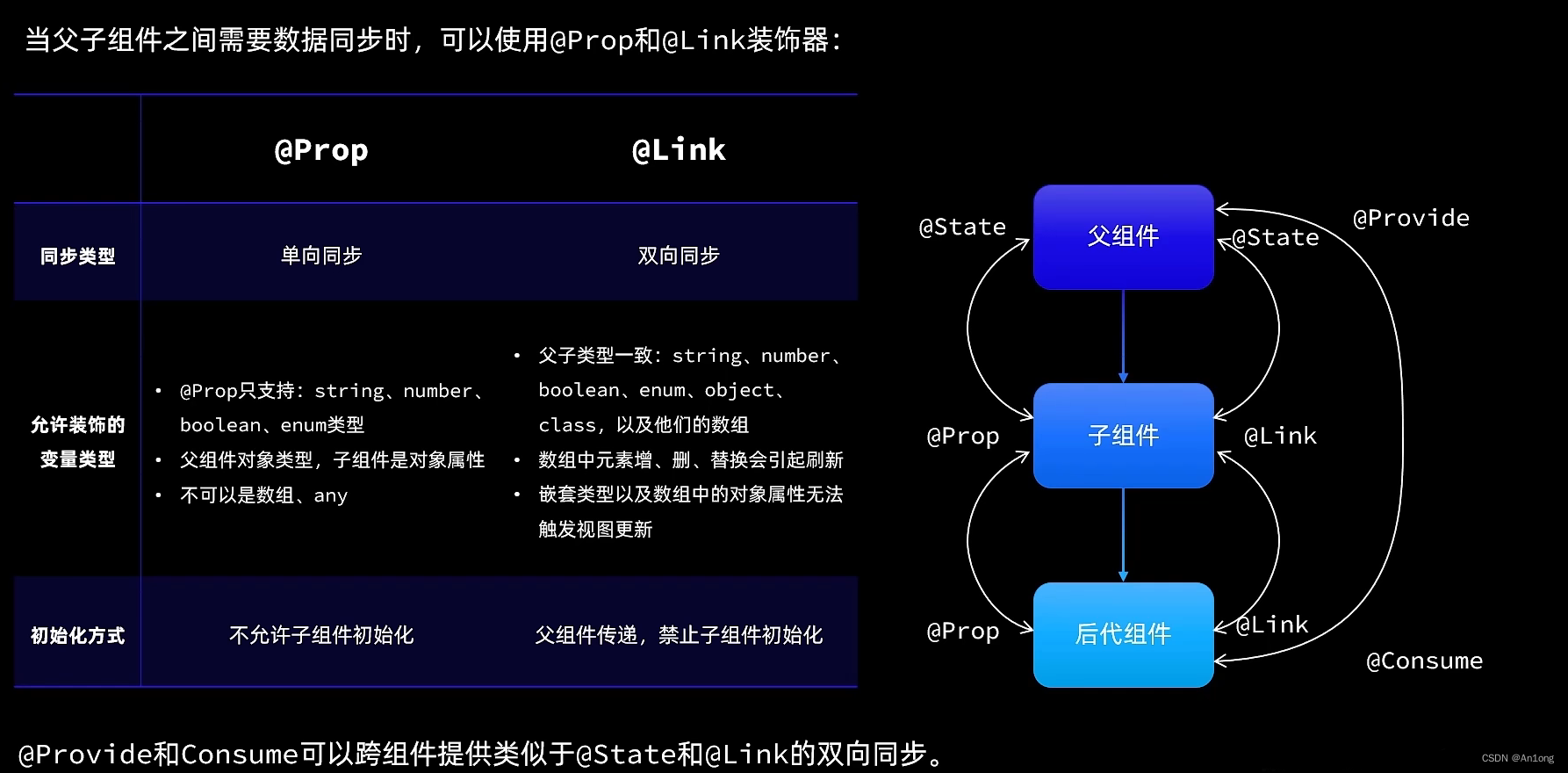
单向传递意思就是父组件将数据传递给子组件之后,子组件的这个数据发生改变时不会导致父组件的视图刷新。而双向同步之后子组件的这个数据发生变化之后就会同步给父组件导致视图刷新。
再以我们刚才的ToDoList案例举例,现在要实现点击子组件完成任务并同步至视图
父组件中传递参数时要使用 $ 变量 的这种格式才能传递
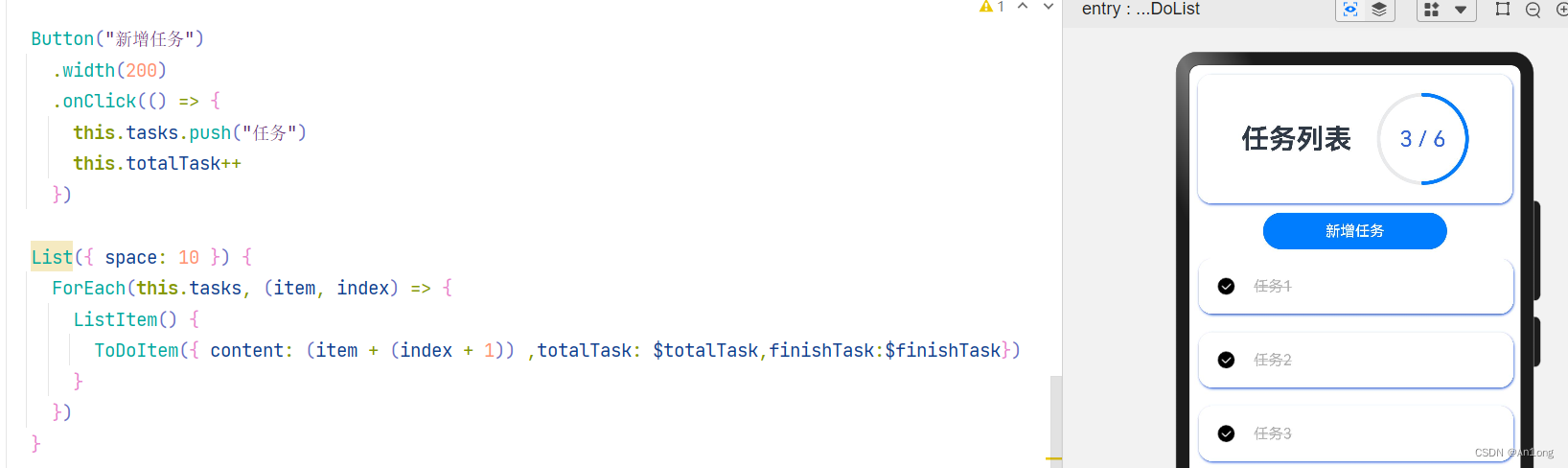
子组件中就要使用@Link修饰并且不能初始化一个值了

至于@Provide和@Consume,这个是用来跨组件使用的。比如@Link和@Prop是父子关系使用,而@Provide和@Consume就不只是父子关系了,你可以多层关系使用,爷孙组件,祖宗和祖孙组件直接使用。
而且使用也不用自己传递参数了,就比如把这个案例中修改为@Provide和@Consume就需要做一些小小的修改
父组件中使用@Provide代替@State,并且调用子组件时不需要传递被修饰的变量
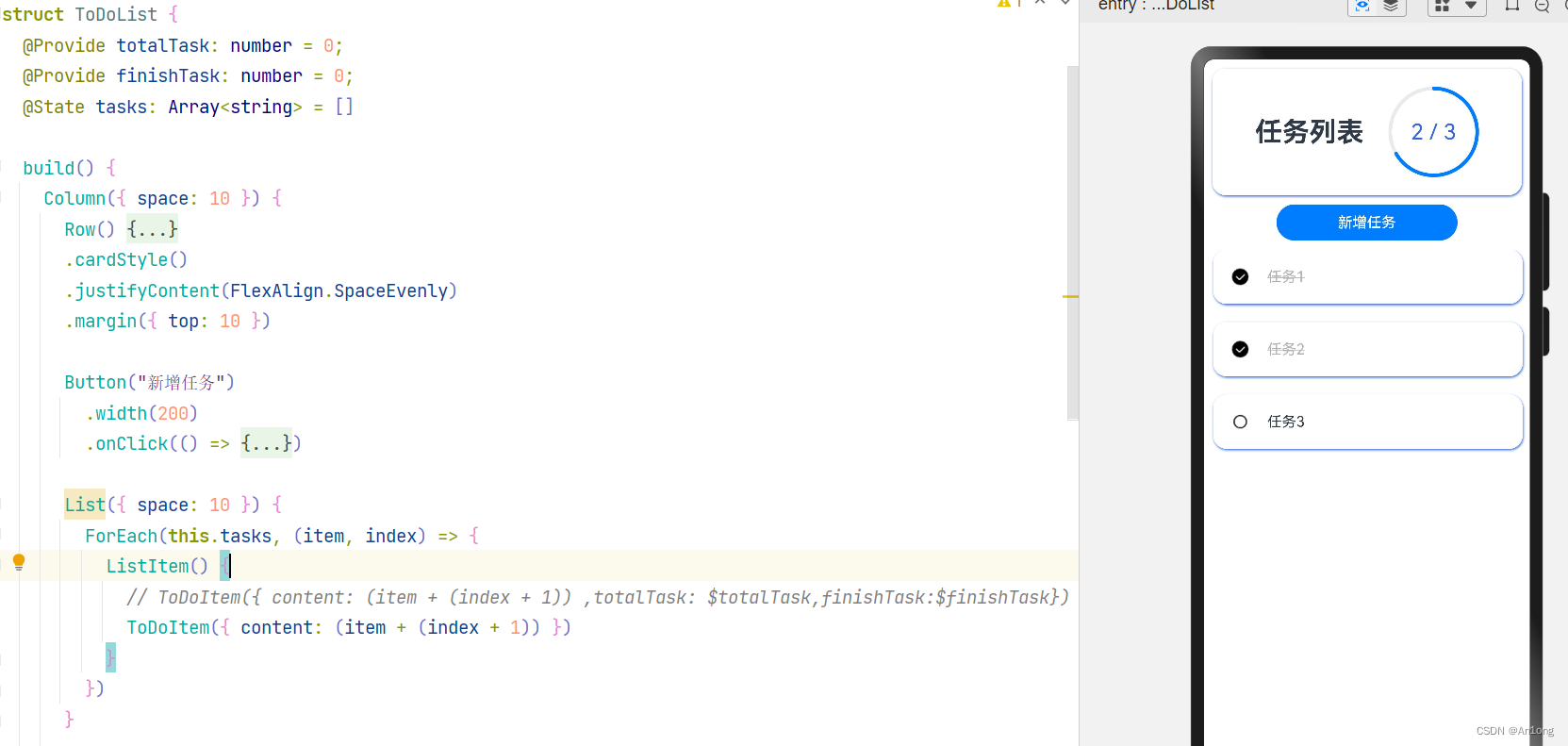
子组件中将@Link改为@Consume
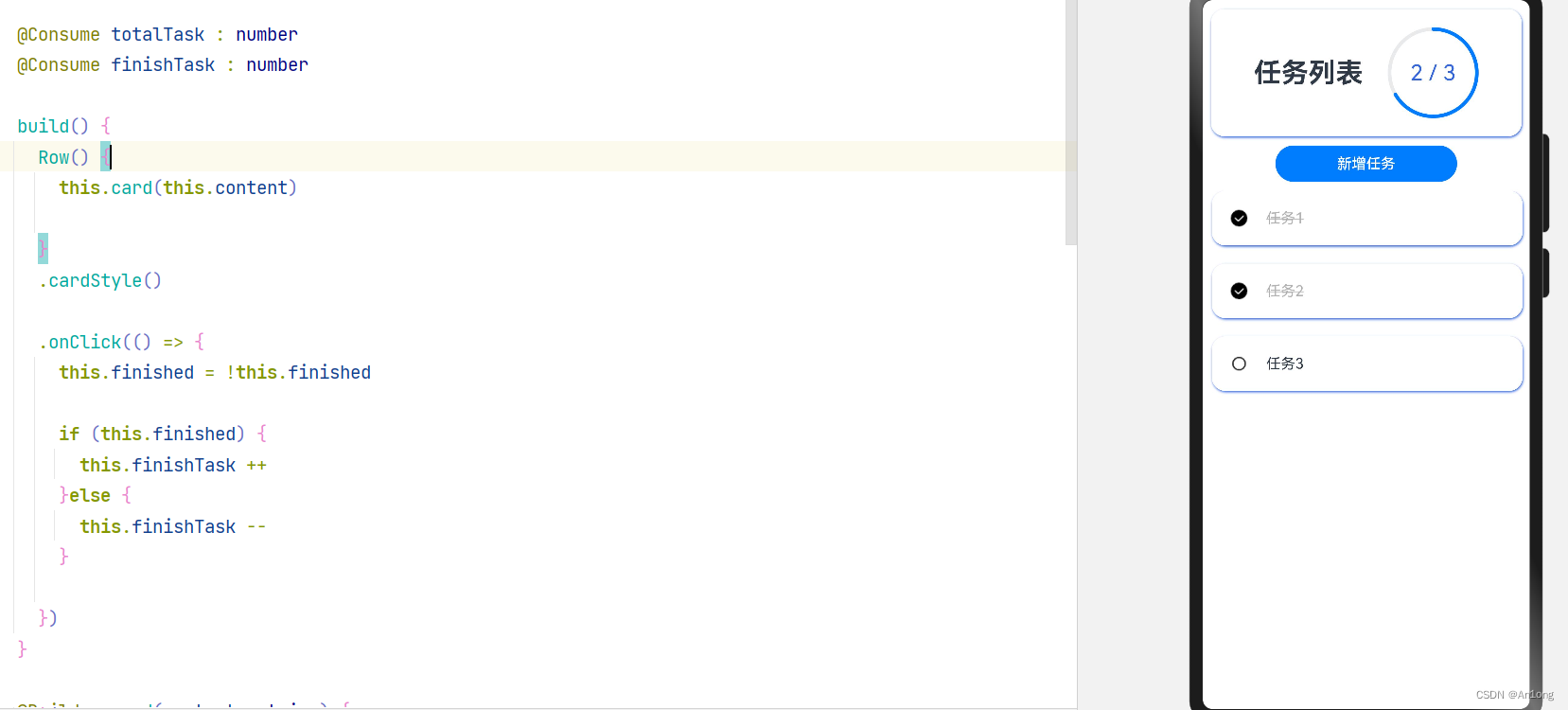
可以达到同样的效果,并且看起来更方便了,不需要自己去传递参数也不用考虑跨了多少组件的问题
那么,古尔丹,代价是什么呢?
本来直接传递就行了,现在又要在底层帮你维护。这样势必会造成大量的资源浪费。
所以除非是真的需要用到跨组件传递,否则只是父子组件的话还是尽量还是使用@Link直接去传递参数。
四、@Observed和@ObjectLink
@ObjectLink和@Observed装饰器用于在涉及嵌套对象或数组元素对象的场景中进行双向数据同步
@Observed修饰于对象类上
@ObjectLink修饰于变量
我们曾在一开始将@State的时候就说过,使用@State修饰的变量如果是嵌套类型以及数组中的对象属性的话就不能触发视图更新。
因此我们需要使用别的注解来解决这个问题
例如我现在有一个对象类Person
- class Person{
- name:string
- age:number
- girlFriend:Person
-
- constructor(name: string, age: number, girlFriend ?: Person) {
- this.name = name;
- this.age = age;
- this.girlFriend = girlFriend;
- }
- }
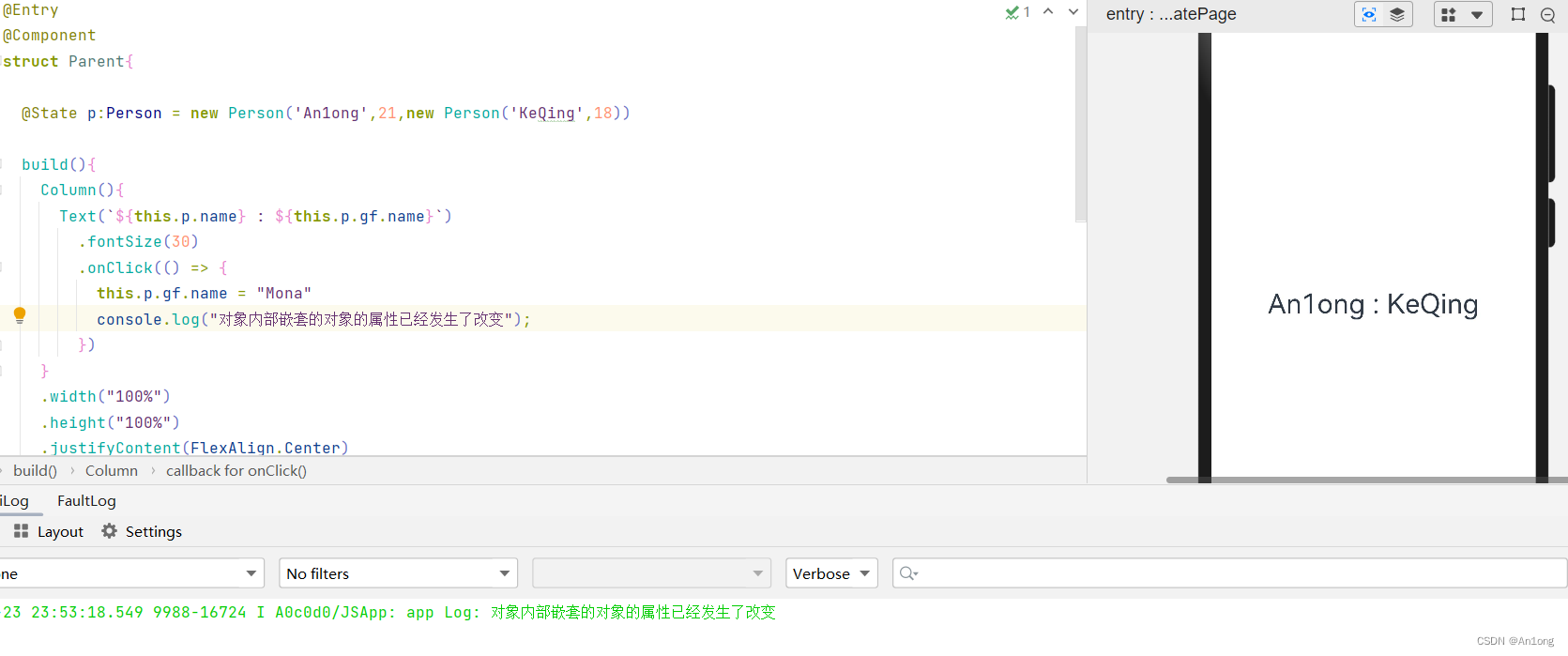
可以看到改变了对象内部嵌套的对象的属性被不会触发更新视图
因此使用方法为
在对象类上加上@Observed注解,然后创建一个新的组件,间接传入对象嵌套的那个对象作为参数
- @Entry
- @Component
- struct Parent{
-
- @State p:Person = new Person('An1ong',21,new Person('KeQing',18))
-
- build(){
- Column(){
- Child({p:this.p.gf})
- }
- .width("100%")
- .height("100%")
- .justifyContent(FlexAlign.Center)
-
- }
- }
-
- @Component
- struct Child{
-
- @ObjectLink private p:Person;
-
- build(){
- Text(`${this.p.name} : ${this.p.age}`)
- .fontSize(30)
- .onClick(() => {
- this.p.name = "Mona"
- console.log("对象内部嵌套的对象的属性已经发生了改变");
- })
- }
- }
-
- @Observed
- class Person{
- name:string
- age:number
- gf:Person
-
- constructor(name: string, age: number, gf ?: Person) {
- this.name = name;
- this.age = age;
- this.gf = gf;
- }
- }
五、页面路由
页面路由是指应用程序中实现不同页面之间的跳转和数据传递
就像我们登录页面登录成功之后就会进入首页这么一个过程。
你可能会好奇,我们跳转至下一个页面之后原本的页面去了哪里呢?
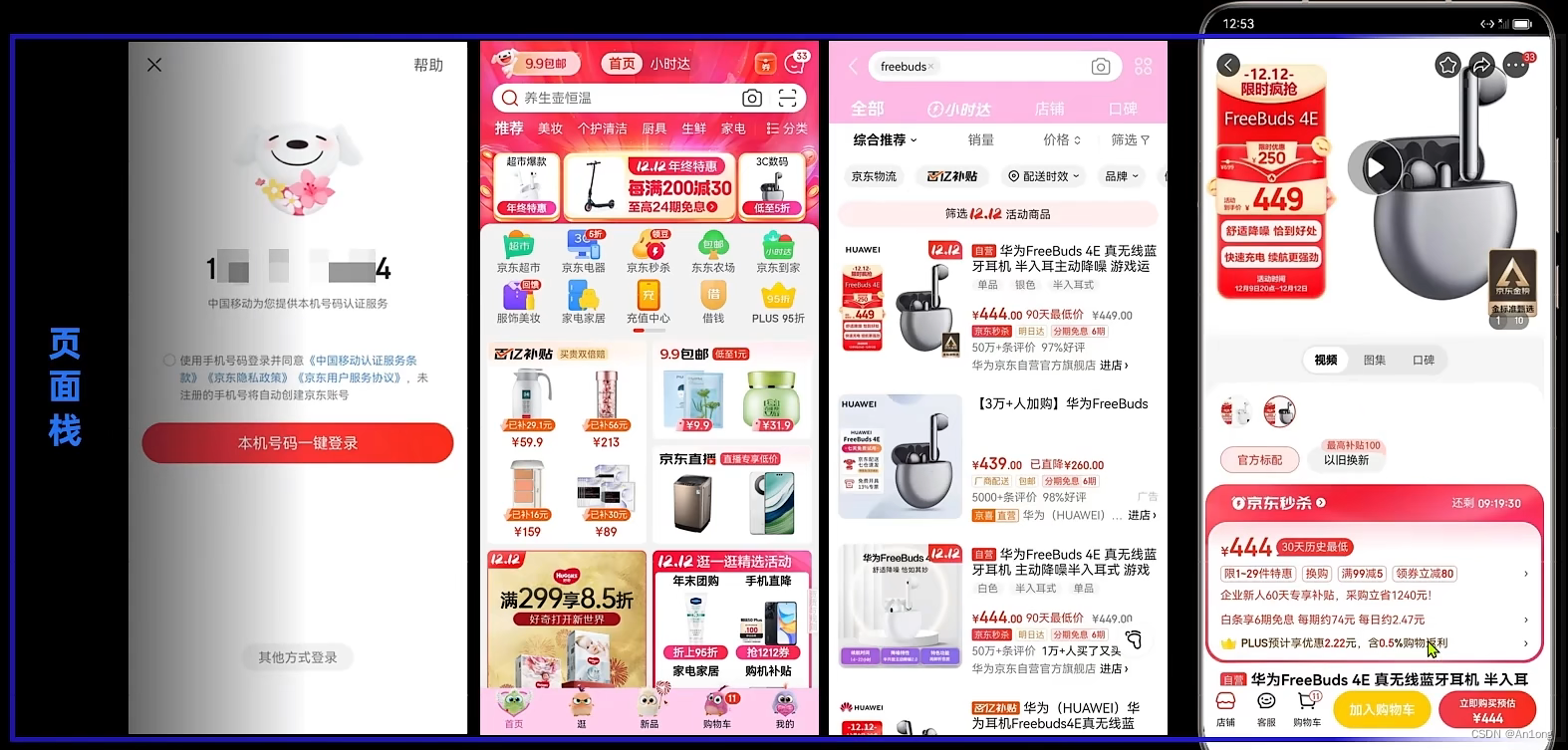
页面进了页面栈中,栈就是先进后出,位于栈顶的页面自然就是当前页面了。
这样做的好处就是,当我们点击返回按钮想要返回上一个页面的时候就不用再写一个跳转页面的代码了,只需要将栈顶的元素移除那么下一个自然就是上一个页面了。
注意:
- 页面栈的最大容量是32个页面,使用router.clear()可以清空页面栈,释放内存(慎用)
跳转模式
Router有两种跳转模式
1、router.pushUrl()
目标下一页也不会替换当前页,而是压入页面栈,因此进入下一页后可以用router.back()返回当前页
2、router.replaceUrl()
目标页替换当前页,当前页会被销毁并释放资源,因此进入下一页后无法返回当前页
这两种跳转模式没有哪个更好哪个更坏的说法,需要根据自己的使用情况来选择使用
比如登陆页面,登录之后自然就不需要再返回登录页了,除非你退出登录此时才需要再跳转至登录页面。因此使用replaceUrl来销毁登录页即可。
而其他的首页等就需要进行频繁的切换,就需要使用pushUrl来进行压栈了
实例模式
当你选择使用pushUrl时就会有两种实例模式
1、Standard
标准模式,每次跳转都会新建一个目标也并压入栈顶。默认就是这种模式
2、Single
单例模式,如果跳转目标也已经在栈中,则离栈顶最近的同Url页面会被推至栈顶并重新加载
这样就可以避免页面栈容量达到上限
使用步骤

注意:我们在创建一个新的页面的时候,直接使用IDE自带的page选项就行了,这样IDE会自动将页面路径放到main_pages.json文件下
只有在main_pages.json文件里面标注的页面路径才可以使用路由
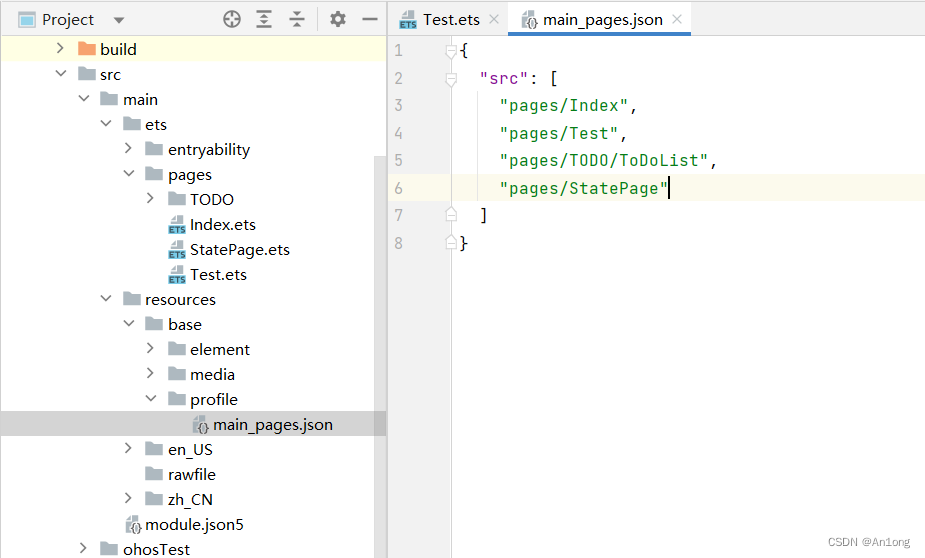
如果你发现你写的路由报错10002显示找不到该路由,记得手动把路径加到main_pages.json文件下。
注意:这里面添加的页面中每个都必须要添加一个@Entry入口,否则会出错
现在来集合我们之前写的案例,简单写一个跳转页面功能吧。
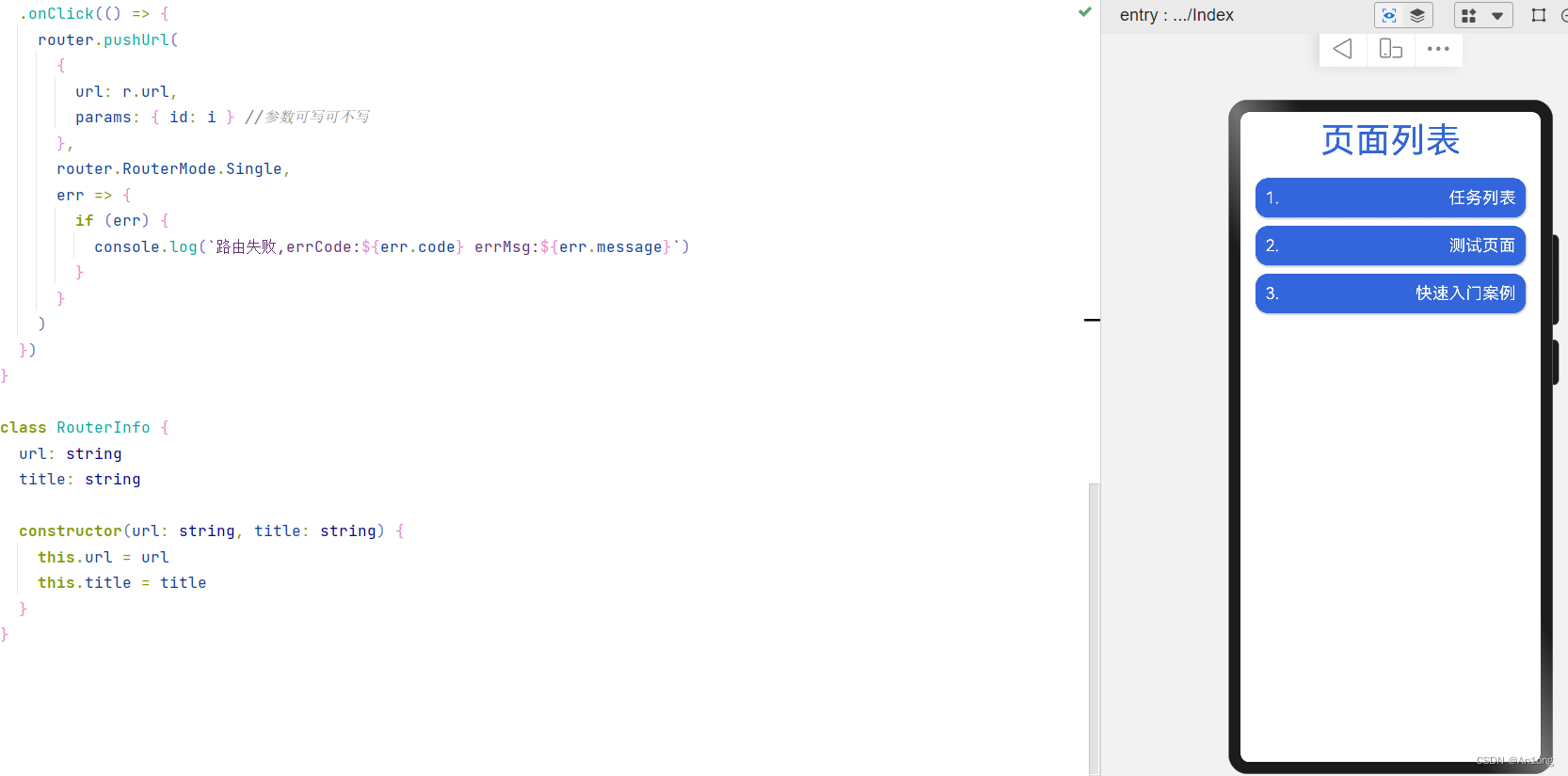
点击跳转,成功实现