
- 1QT交叉编译_qt交叉编译环境搭建
- 2jquery插件大全_juqer相关的组件库
- 30基础学springboot之对数据库的增删改查_springboot数据库增删改查
- 4微信小程序uniapp校园租房指南房屋租赁系统java+python+nodejs+php_uniapp 房屋中介
- 5Vuejs在v-for中,利用index来对第一项添加class的方法_js给列表第一个标签添加一个class
- 6Android App 版本更新实现_android app 更新版本的實例 無新版本繼續運行
- 7GPT4.0:探索下一代自然语言处理技术_gpt4.0 csdn
- 8二叉树(构造篇)_构造二叉树
- 9【HarmonyOS】如何实现应用内引用HSP模块中ArkUI组件_harmonyos添加httplibrary模块
- 10微信小程序 自定义 下拉列表 组件_微信小程序下拉列表组件
十八、软考-系统架构设计师笔记-真题解析-2022年真题_效应树是采用架构
赞
踩
软考-系统架构设计师-2022年上午选择题真题
考试时间 8:30 ~ 11:00 150分钟
1.云计算服务体系结构如下图所示,图中①、②、③分别与SaaS、PaaS、IaaS相对应,图中①、②、③应为( )。
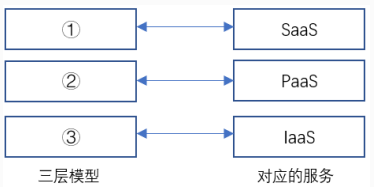
A.应用层、基础设施层、平台层
B.应用层、平台层、基础设施层
C.平合层、应用层、基础设施层
D.平台层、基础设施层、应用层
解析:
SaaS( Software as a Service 软件即服务)、PaaS(Platform as a Service 平台即服务)、IaaS(Infrastructure as a Service 基础设施即服务)
答案 : B
2.前趋图(Precedence Graph)是一个有向无环图,记为∶→={(Pi, Pj)} {Pi must complete before Pj may start},假设系统中进程P={P1, P2,P3, P4, P5, P6, P7, P8},且进程的前趋图如下图所示,那么该前趋图可记为( )。

A.→={P1,P2),(P1,P3),(P1,P4),(P2,P5),(P3,P5),(P4,P7),(P5,P6),(P5,P7),(P7,P6),(P4,P5),(P6,P7),(P7, P8)}
B.→={(P1,P2),(P1,P3),(P1,P4),(P2,P3),(P2,P5),(P3,P4),(P3,P6),(P4,P7),(P5,P6),(P5,P8),(P6,P7),(P7,P8)}
C.→={(P1,P2),(P1,P3),(P1,P4),(P2,P3),(P2,P5),(P3,P4),(P3,P5),(P4,P6),(P5,P7),(P5,P8),(P6,P7),(P7,P8)}
D.→={P1,P2),(P1,P3),(P2,P3),(P2,P5),(P3,P4),(P3,P6),(P4,P7),(P5,P6),(P5,P8),(P6,P7),(P6,P8),(P7,P8)}
解析:
前驱图 从活动最小编号的按照箭头顺序往后排即可 例如 P1开始 (P1,P2),(P1,P3),(P1,P4) P1排完了 继续排P2
一直到最后一个P7
答案: B
3.若系统正在将( )文件修改的结果写回磁盘时系统发生掉电、则对系统影响相对较大。
A.目录 B.空闲块 C.用户程序 D.用户数据
解析:
对系统而言,目录是记录文件名和其存储位置的数据结构。当系统正在将文件的修改结果写回磁盘时,如果目录信息还未写入磁盘或写入未完成,而系统突然发生掉电,可能会导致目录信息的丢失或不一致。这将导致系统无法准确地找到文件,进而影响系统的文件管理和文件访问功能。因此,目录的丢失或损坏对系统影响相对较大。而空闲块、用户程序和用户数据等部分可以通过一些文件系统的一致性检查和恢复机制来进行修复和恢复,对系统的影响相对较小。
答案: A
4.在磁盘调度管理中,应先进行移臂调度,再进行旋转调度。假设磁盘移动臂位于20号柱面上,进程的请求序列如下表所示。如果采用最短移臂调度算法,那么系统的调度序列应为( )。

解析:
采用最短移臂调度算法
当前磁盘移动臂位于20号柱面 离20号柱面 最近的是 21号柱面 请求序列是④和⑥ 且当柱面号相同时 先访问扇区号小的
所以先是 柱面号 21 对应的请求序列 ④⑥
柱面号 18 和 22 离20号柱面第二近 请求序列有 ⑨ ① ⑤ ⑦ 按照扇区号从小到大排序是 ⑨ ⑤ ⑦ ① 或者 ⑨ ⑤ ① ⑦ ( 由于22 之上就没数据了 而18之下还有16 所以 ⑨放在开头 )
柱面号 16 离20号柱面第三近 请求序列有 ② ③ ⑧ 按照扇区号从小到大排序是 ② ⑧ ③
最终组合起来 只有C选项符合
答案: C
5.采用三级模式结构的数据库系统中,如果对一个表创建聚簇索引,那么改变的是数据库的( )。
A.外模式
B.模式
C.内模式
D.用户模式
解析:
内模式是数据库真实存储方式的定义。它描述了数据在存储介质上的物理组织方式,如数据存储的文件格式、索引结构等。
当在一个表上创建聚簇索引时,实际上是改变了数据库的内模式。
答案: C
6.假设系统中有正在运行的事务,若要转储全部数据库,则应采用( )方式。
A.静态全局转储
B.动态增量转储
C.静态增量转储
D.动态全局转储
解析:
动态全局转储可以在运行时获取数据库的当前状态并转储,包括正在进行的事务的数据。它能够捕获事务的变化以及正在进行的写操作,并将其同步到转储中,从而保证了转储数据的完整性和一致性。
相比之下,静态全局转储只能在系统空闲或者事务未开始的情况下进行,无法捕获事务的动态修改,因此不适合在有正在进行的事务时进行全局转储。
答案: D
7.给定关系模式R(U, F),其中U为属性集,F是U上的一组函数依赖,那么函数依赖的公理系统(Armstrong)中的分解规则是指( )为F所蕴涵。
A.若X→Y,Y→Z,则X→Z
B.若Y⊆X⊆U,则X→Y
C.若X→Y,Z⊆Y,则X→Z
D.若X→Y,X→Z,则X→YZ
解析:
Armstrong公理系统设关系模式R<U,F>,其中U为属性集,F是U上的一组函数依赖,那么有如下推理规则:
① A1自反律:若Y⊆X⊆U,则X→Y为F所蕴含
② A2增广律:若X→Y为F所蕴含,且Z⊆U,则XZ→YZ为F所蕴含:
③ A3传递律:若X→Y,Y→Z为F所蕴含,则X→Z为F所蕴含。
根据上面三条推理规则,又可推出下面三条推理规则:
④ 合并规则:若X→Y,X→Z,则X→YZ为F所蕴含;
⑤ 伪传递规则:若X→Y,WY→Z,则XW→Z为F所蕴含;
⑥ 分解规则:若X→Y,Z⊆Y,则X→Z为F所蕴含
答案: C
8.给定关系R(A, B, C, D)和S(A, C, E, F),以下( )与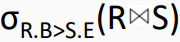 等价。
等价。
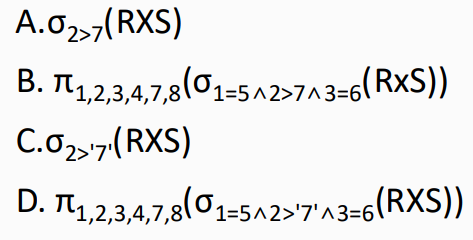
解析: (数据库的运算 可以参考本专栏的第7篇文章 七、软考-系统架构设计师笔记-数据库设计基础知识)
解析: 题目中
是关系R和关系S的自然连接 其中R(A, B, C, D)和S(A, C, E, F) 有相同属性列 A 、 C
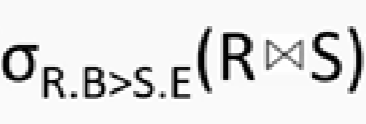
并且在 R和S 自然连接后 选择 R的B列的值 大于S的E列的值 的过程
其中R的B列 可以用下标2表示 S的E列可以用下标 7表示 如果是带 单引号的 ‘7’ 表示字符串7 而不是第7列
选项A中 RXS 只是R和S的笛卡尔积 并没有选择 R和S中 进行比较的分量必须是相同的属性组,在结果中把重复的属性列去掉
所以A错误
选项B 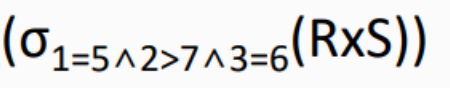
先把R和S求笛卡尔积 然后 选择 相同的属性组 并且 符合题目中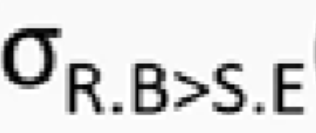
R.B > S.E的选择条件
最后使用投影 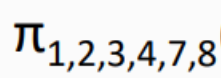
在结果中把重复的属性列去掉 所以B选项正确
C选项和A选项类似的错误 并且比较的是字符串 ‘7’ 错误
D选项和B选项类似 但是比较的是字符串 ‘7’ 错误
答案: B
9.以下关于鸿蒙操作系统的叙述中,不正确的是( )。
A.鸿蒙操作系统整体架构采用分层的层次化设计,从下向上依次为∶内核层、系统服务层、框架层和应用层
B.鸿蒙操作系统内核层采用宏内核设计,拥有更强的安全特性和低时延特点
C.鸿蒙操作系统架构采用了分布式设计理念,实现了分布式软总线、分布式设备虚拟化、分布式数据管理和分布式任务调度等四升分布式能力
D.架构的系统安全性主要体现在搭载HamonyOS的分布式终端上,可以保证"正确的人,通过正确的设备,正确的使用数据”。
解析:
鸿蒙是基于微内核的OS
答案: B
10.GPU目前已广泛应用于各行各业,GPU中集成了同时运行在GHZ的频率上的成千上万个core,可以高速处理图像数据。最新的GPU峰值性能可高达( )以上。
A.100 TFlops
B.50 TFlops
C.10 TFlops
D.1TFlops
解析:最新的GPU峰值性能可高达100 TFlops以上。这是由于GPU(图形处理器)的设计和架构使其在并行计算和图形处理方面具有优势。GPU中集成了许多处理核心,每个核心都能同时处理多个数据和指令,以高效地进行并行计算。因此,最新的GPU能够提供高达100 TFlops(百万亿次浮点运算)以上的峰值性能,使其在图像处理、科学计算、人工智能等领域具有广泛的应用价值。
答案: A
11. AI芯片是当前人工智能技术发展的核心技术,其能力要支持训练和推理,通常AI芯片的技术架构包括( )等三种。
A.GPU、FPGA、ASIC
B.CPU、FPGA,DSP
C.GPU、CPU、ASIC
D.GPU、FPGA、SOC
解析:
AI芯片从技术架构发展来看,大致也分为四个类型:通用类芯片,代表如 GPU、FPGA;
基于 FPGA 的半定制化芯片,代表如深鉴科技 DPU、百度 XPU 等;
全定制化 ASIC 芯片,代表如TPU、寒武纪 Cambricon-1A等;
类脑计算芯片,代表如IBMTrueNorth、westwell、高通 Zeroth 等
答案:A
12.通常,嵌入式中间件没有统一的架构风格,根据应用对象的不同可存在多种类型,比较常见的是消息中间件和分布式对象中间件,以下有关消息中间件的描述中,不正确的是( )。
A.消息中间件是消息传输过程中保存消息的一种容器
B.消息中间件具有两个基本特点:采用异步处理模式、应用程序和应用程序调用关系为松耦合关系
C.消息中间件主要由一组对象来提供系统服务,对象间能够跨平台通信
D.消息中间件的消息传递服务模型有点对点模型和发布–订阅模型之分
解析:
消息中间件主要由一组对象来提供系统服务,对象间能够跨平台通信 说法不正确
消息中间件通常由一个消息队列系统、消息传输协议和相关的管理和控制组件组成而不是一组对象提供系统服务
答案:C
13.以下关于HTTPS和HTTP协议的描述中,不正确的是( )。
A.HTTPS协议使用加密传输
B.HTTPS协议默认服务端口号是443
C.HTTP协议默认服务端口是80
D.电子支付类网站应使用HTTP协议
解析:
电子支付类网站一般需要比较高的安全防护 需要使用 HTTPS协议加密传输
答案: D
14.15.电子邮件客户端通过发起对( )服务器的( )端口的TCP连接来进行邮件发送。
A.POP3 B.SMTP C.HTTP D.IMAP
A.23 B.25 C.110 D.143
解析:
记忆类题目:
POP3,邮件接收协议,缺省端口110
SMTP,邮件发送协议,缺省端口25
HTTP,超文本传输协议,缺省端口80
IMAP.交互式邮件存取协议,缺省端口143
答案:B、B
16.17.系统( )是指在规定的时间内和规定条件下能有效地实现规定功能的能力。它不仅取决于规定的使用条件等因素,还与设计技术有关。常用的度量指标主要有故障率(或失效率)、平均失效等待时间、平均失效间隔时间和可靠度等。其中,( )是系统在规定工作时间内无故障的概率。
A.可靠性 B.可用性 C.可理解性 D.可测试性
A.失效率 B.平均失效等待时间 C.平均失效间隔时间 D.可靠度
解析:
可靠性(Reliability)是指产品在规定的条件下和规定的时间内完成规定功能的能力。
常用的度量指标主要有故障率(或失效率)、平均失效等待时间、平均失效间隔时间和可靠度等。
可靠度就是软件系统在规定的条件下、规定的时间内不发生失效的概率。
答案: A、 D
18.数据资产的特征包括( )。①可增值 ②可测试 ③可共享 ④可维护 ⑤可控制 ⑥可量化
A.①②③④
B.①②③⑤
C.①②④⑤
D.①③⑤⑥
解析:
记忆类题目
数据资产的特性包括:
可控制,可量化,可变现、共享性、时效性、安全性、交换性、虚拟性、规模性
答案:D
19.数据管理能力成熟度评估模型(DCMM)是我国首个数据管理领域的国家标准,DCMM提出了符合我国企业的数据管理框架,该框架将组织数据管理能力划分为8个能力域,分别为∶数据战略、数据治理、数据架构、数据标准,数据质量、数据安全、( )。
A.数据应用和数据生存周期
B.数据应用和数据测试
C.数据维护和数据生存周期
D.数据维护和数据测试
解析:
DCMM评估内容包括数据战略、数据治理、数数据架构、数据应用、数据安全、数据质量、数据标准和数据生存周期。
答案:A
20.21.完整的信息安全系统至少包含三类措施,即技术方面的安全措施、管理方面的安全措施和相应的( )。其中,信息安全的技术措施主要有∶信息加密、数字签名、身份鉴别、访问控制、网络控制技术、反病毒技术、( )。
A.用户需求 B.政策法律 C.市场需求 D.领域需求
A.数据备份和数据测试
B.数据迁移和数据备份
C.数据备份和灾难恢复
D.数据迁移和数据测试
解析:
记忆类
一个完整的信息安全系统至少包含三类措施:技术方面的安全措施,管理方面的安全措施和相应的政策法律。
信息安全的技术措施主要有:信息加密、数字签名、数据完整性保护、身份鉴别、访问控制、数据备份和灾难恢复、网络控制技术、反病毒技术、安全审计、业务填充、路由控制机制、公证机制等。
答案:B、C
22.与瀑布模型相比,( )降低了实现需求变更的成本,更容易得到客户对于已完成开发工作的反馈意见,并且客户可以更早地使用软件并从中获得价值。
A.快速原型模型
B.敏捷开发
C.增量式开发
D.智能模型
解析:
考察软件开发模型相关概念
增量式开发相比于瀑布模型的一些重要优点:降低了适应用户需求变更的成本。重新分析和修改文档的工作量较之瀑布模型要少很多。
在开发过程中更容易得到用户对于已做的开发工作的反馈意见。用户可以评价软件的现实版本,并可以看到已经实现了多少。这比让用户从软件设计文档中判断工程进度要好很多。使更快地交付和部署有用的软件到客户方变成了可能,虽然不是所有的功能都已经包含在内。
相比于瀑布模型,用户可以更早地使用软件并创造商业价值。
答案:A
23.CMMI是软件企业进行多方面能力评价的、集成的成熟度模型,软件企业在实施过程中,为了达到本地化,应组织体系编写组,建立基于CMMI的软件质量管理体系文件,体系文件的层次结构一般分为四层,包括:①顶层方针 ②模板类文件 ③过程文件 ④规程文件
按照自顶向下的塔型排列,以下顺序正确的是( )。
A.①④③② B.①④②③ C.①②③④ D.①③④②
解析:
软件过程构架结构由四个层次组成:方针、过程、规程和第四层的标准、规范、指南、板、Checklist等组成。
1、方针为第一层文件,它是组织标准软件的高层次的抽象描述,它反映在公司的过程改进总体方针、政策中,由公司主管副总裁批准行。
2、过程为第二层文件,主要规定在项目开发中执行该过程时应当执行的各项活动及适用标准。过程定义文件及其相关文件制定必须符合方针的要求。
3、规程为第三层文件,是对过程某些复杂活动的具体描述。
4、模板文件 。
答案:D
24.信息建模方法是从数据的角度对现实世界建立模型,模型是现实系统的一个抽象,信息建模方法的基本工具是( )。
A.流程图
B.实体联系图
C.数据流图
D.数据字典
解析:
业务流程图(TFD)是分析和描述现有系统的传统工具,是业务流程调查结果的图形化表示。
实体联系图(E-R图)它是描述概念世界,建立概念模型的实用工具。
数据流图(DFD)是表达系统内数据的流动并通过数据流描述系统功能的一种方法。
数据字典(DD)是在DFD的基础上,对DFD中出现的所有命名元素都加以定义,使得每个图形元素的名字都有一个确切的解释。
答案:B
25. ( )通常为一个迭代过程,其中的活动包括需求发现、需求分类和组织、需求协商、需求文档化。
A.需求确认
B.需求管理
C.需求获取
D.需求规格说明
解析:记忆类题目
需求获取通常为一个迭代过程,其中的活动包括需求发现、需求分类和组织、需求协商、需求文档化。
答案:C
26.使用模型驱动的软件开发方法,软件系统被表示为一组可以被自动转换为可执行代码的模型。其中,( )在不涉及实现的情况下对软件系统进行建模。
A.平台无关模型
B.计算无关模型图像
C.平台相关模型
D.实现相关模型
解析:
平台无关模型(Platform-Independent Model,PIM)是指与具体实现平台无关的抽象模型,描述了系统的业务逻辑、功能和行为,不关注具体的实现细节和技术平台。
答案:A
27.在分布式系统中,中间件通常提供两种不同类型的支持,即( )。
A.数据支持和交互支持
B.交互支持和提供公共服务
C.安全支持和提供公共服务
D.数据支持和提供公共服务
解析:
中间件一般提供如下功能:
1、通信支持。中间件为其所支持的应用软件提供平台化的运行环境,该环境屏蔽底层通信之间的接口差异,实现互操作,所以通信支持是中间件一个最基本的功能。
2、应用支持。中间件的目的就是服务上层应用,提供应用层不同服务之间的互操作机制。
3、公共服务。公共服务是对应用软件中共性功能或约束的提取。将这些共性的功能或者约束分类实现,并支持复用,作为公共服务,提供给应用程序使用。
答案:B
28.工作流表示的是业务过程模型,通常使用图形形式来描述,以下不可用来描述工作流的是( )。
A.活动图
B.BPMN
C.用例图
D.Petri-Net
解析:
活动图(Activity Diagram)、BPMN(Business Process Model and Notation)和Petri-Net(Petri网)都是常用来描述工作流的图形化表示方法。
用例图(Use Case Diagram)是用于表达系统功能和参与者之间交互的图形模型,主要用于定义系统的功能需求,而不是直接描述业务流程。
答案:C
29. ( )的常见功能包括版本控制、变更管理、配置状态管理,访问控制和安全控制等。
A.软件测试工具
B.版本控制工具
C.软件维护工具
D.软件配置管理工具
解析:
软件配置管理工具是用于管理和控制软件系统的配置项、版本、变更和相关文档等的工具。它可以帮助团队有效地管理软件开发和维护过程中的各种配置和变更,确保系统的稳定性和可追溯性。
常见的软件配置管理工具包括Git、SVN(Subversion)、Mercurial、Perforce等。这些工具提供了版本控制、变更管理、配置状态管理等功能,可以支持团队协作、版本追踪、分支管理等操作。
此外,软件配置管理工具还可以实现访问控制和安全控制的功能,确保只有授权人员可以进行修改和访问系统配置和资源。
答案:D
30.与UML1.x不同,为了更清楚地表达UML的结构,从UML2开始,整个UML规范被划分为基础结构和上层结构两个相对独立的部分,基础结构是UML的( ),它定义了构造UML模型的各种基本元素;而上层结构则定义了面向建模用户的各种UML模型的语法、语义和表示。
A.元元素 B.模型 C.元模型 D.元元模型
解析:
从UML2开始,整个UML规范被划分为基础结构和上层结构两个相对独立的部分。基础结构是UML的元模型(Metamodel),它定义了构造UML模型的各种基本元素,如类、关联、属性、操作等。元模型规定了这些基本元素的语义和关系,以及它们之间的组织和结构。上层结构定义了面向建模用户的各种UML模型的语法、语义和表示。上层结构包括用例图、类图、时序图、活动图等各种图形表示法,以及用于描述这些图形中元素之间关系和行为的规则和约束。
答案:C
31.领域驱动设计提出围绕( )进行软件设计和开发,该模型是由开发人员与领域专家协作构建出的一个反映深层次领域知识的模型。
A.行为模型
B.领域模型
C.专家模型
D.知识库模型
解析:
领域驱动设计(Domain-Driven Design)提出围绕领域模型进行软件设计和开发。领域模型是由开发人员与领域专家协作构建出的一个反映深层次领域知识的模型。
在领域驱动设计中,领域模型是对业务领域的概念、规则和过程的抽象表示。它通过对领域对象、关系和行为进行建模,用于描述业务领域的核心概念和关键业务逻辑。领域模型通过领域语言和领域专家的交流,帮助开发人员深入理解业务需求和业务流程,从而更好地设计和实现软件系统。
答案:B
32.以下关于微服务架构与面向服务架构的描述中,正确的是( )。
A.两者均采用去中心化管理
B.两者均采用集中式管理
C.微服务架构采用去中心化管理,面向服务架构采用集中式管理
D.微服务架构采用集中式管理,面向服务架构采用去中心化管理
解析:
微服务架构采用去中心化管理,面向服务架构采用集中式管理
答案:C
33.34.在UML2.0 (Unified Modeling Language)中,顺序图用来描述对象之间的消息交互,其中循环、选择等复杂交互使用( )表示,对象之间的消息类型包括( )。
A.嵌套 B.泳道 C.组合 D.序列片段
A.同步消息、异步消息、返回消息、动态消息、静态消息
B.同步消息、异步消息、动态消息、参与者创建消息、参与者销毁消息
C.同步消息、异步消息、静态消息、参与者创建消息、参与者销毁消息
D.同步消息、异步消息、返回消息、参与者创建消息、参与者销毁消息
解析:
在UML2.0中,顺序图使用泳道(swimlanes)来表示不同的参与者、角色或对象。泳道可将消息交互按参与者进行分组,以显示对象之间的交互关系。
在UML2.0的顺序图中,对象之间的消息类型包括以下几种:
同步消息:表示发送消息后,等待接收方返回响应。
异步消息:表示发送消息后,不等待接收方响应,继续执行后续操作。
返回消息:表示方法或操作的返回值消息。
动态消息:表示选择或循环等复杂的交互行为。
静态消息:表示静态方法或简单的消息。
答案:B、A
35.以下有关构件特性的描述中,说法不正确的是( )。
A.构件是独立部署单元
B.构件可作为第三方的组装单元
C.构件没有外部的可见状态
D.构件作为部署单元,是可拆分的
解析:
构件可以维护和管理自己的状态,并与其他构件进行交互和通信。
答案:C
36.在构件的定义中,( )是一个已命名的一组操作的集合。
A.接口
B.对象
C.函数
D.模块
解析:
在构件的定义中,接口是一个已命名的一组操作的集合。
接口定义了构件对外提供的可见行为,它描述了构件与外部环境之间的交互。接口定义了一组操作、方法或服务,并指定了这些操作的参数和返回值的类型。
答案:A
37.在服务端构件模型的典型解决方案中,( )较为适用于应用服务器。
A.EJB和COM+模型
B.EJB和servlet模型
C.COM+和ASP模型
D.COM+和servlet模型
解析:
在服务端构件模型的典型解决方案中, COM+和servlet模型较为适用于应用服务器。
答案:D
38.以下有关构件演化的叙述中,说法不正确的是( )。
A.安装新版本构件可能会与现有系统发生冲突
B.构件通常也会经历一般软件产品具有的演化过程
C.解决“遗留系统移植”问题还需要通过使用包裹器构件来适配旧版软件
D.为安装新版本的构件,必须终止系统中所有现有版本构件的运行
解析:
在构件演化的过程中,升级或安装新版本的构件时,并不需要终止系统中所有现有版本构件的运行
答案:D
39.软件复杂性度量中,( )可以反映源代码结构的复杂度。
A.模块数
B.环路数
C.用户数
D.对象数
解析:
环路数是指在软件系统的源代码中存在的闭合路径(比如循环)的数量。环路数反映了程序的控制流复杂度和逻辑复杂度。较高的环路数可能意味着代码的可读性和可维护性较低,难以理解和调试。
答案:B
40.在白盒测试中,测试强度最高的是( )。
A.语句覆盖
B.分支覆盖
C.判定覆盖
D.路径覆盖
解析:
在白盒测试中,不同的覆盖准则可以用来度量测试用例的测试强度。其中,路径覆盖被认为是测试强度最高的一种覆盖准则。
语句覆盖是指测试用例是否能够执行每个源代码语句,它是一种较基本的覆盖准则。通过语句覆盖,可以确保测试用例覆盖了代码的每一行。
分支覆盖是指测试用例是否能够覆盖每一个条件语句的每个分支。通过分支覆盖,可以确保测试用例覆盖了代码中的所有条件情况。
判定覆盖是指测试用例是否能够覆盖每一个条件语句的每个判定结果。通过判定覆盖,可以确保测试用例覆盖了代码中的所有条件决策。
答案:D
41.在黑盒测试方法中,( )方法最适合描述在多个逻辑条件取值组合所构成的多种情况下,分别要执行哪些不同的动作。
A.等价类 B.边界值 C.判定表 D.因果图
解析:
判定表是一种表格形式的测试设计技术,用于表示逻辑条件与动作之间的关系。它能够清晰地展示多个条件的组合和对应的动作,从而帮助测试人员设计出覆盖各种情况的测试用例。
判定表通常由条件和动作两个部分组成。条件部分列出所有可能的逻辑条件,动作部分列出在不同条件组合下需要执行的动作。使用判定表,可以系统地定义和识别所有可能的逻辑条件组合,并确定对应的动作。
答案:C
42. ( )的目的是测试软件变更之后,变更部分的正确性和对变更需求的符合性,以及软件原有的、正确的功能、性能和其它规定的要求的不损害性。
A.验收测试
B.Alpha测试
C.Beta测试
D.回归测试
解析:
当软件发生变更时,无论是修复错误、添加新功能、优化性能还是进行其他修改,都存在潜在的风险会引入新的错误或破坏现有功能。回归测试通过再次运行原有的测试用例来验证软件的正确性和稳定性。
答案:D
43.在对遗留系统进行评估时,对于技术含量较高、业务价值较低且仅能完成某个部门的业务管理的遗留系统,一般采用的遗留系统演化策略是( )策略。
A.淘汰
B.继承
C.集成
D.改造
解析:
集成
答案:C
44.45.在软件体系结构的建模与描述中,多视图是一种描述软件体系结构的重要途径,其体现了( )的思想,其中,4+1模型是描述软件体系结构的常用模型,在该模型中,"1"指的是( )。
A.关注点分离 B.面向对象 C.模型驱动 D.UML
A.统一场景 B.开发视图 C.逻辑视图 D.物理视图
解析:
“4+1”视图模型从5个不同的视角来描述软件架构,每个视图只关心系统的一个侧面,5个视图结合在一起才能反映软件架构的全部内容,其思想即为关注点分离。其中,“4”为逻辑视图、开发视图、进程视图、物理视图:“1”为场景。
答案:A、A
46.47.基于体系结构的软件设计(Architecture-Based Software Design,ABSD)方法是体系结构驱动,即指构成体系结构的( )的组合驱动的。ABSD方法是一个自顶向下、递归细化的方法,软件系统的体系结构通过该方法得到细化,直到能产生( )。
A.产品、功能需求和设计活动 B.商业、质量和功能需求 C.商业、产品和功能需求 D.商业、质量和设计活动
A.软件产品和代码 B.软件构件和类 C.软件构件和连接件 D.类和软件代码
解析:
体系结构驱指 构成体系结构的商业、质量和功能需求的组合驱动
软件构件和类
答案:B、B
48.49.软件体系结构风格是描述某一特定应用领域中系统组织方式的惯用模式,其中,在批处理风格软件体系结构中,每个处理步骤是一个单独的程序,每一步必须在前一步结束后才能开始,并且数据必须是完整的,以( )的方式传递。基于规则的系统包括规则集、规则解释器、规则/数据选择器及( )。
A.迭代 B.整体 C.统一格式 D.递增
A.解释引擎 B.虚拟机 C.数据 D.工作内存
解析:
构件为一系列固定顺序的计算单元,构件之间只通过数据传递交互。每个处理步骤是一个独立的程序,每一步必须在其前一步结束后才能开始,数据必须是完整的,以整体的方式传递。
基于规则的系统包括规则集、规则解释器、规则/数据选择器和工作内存,一般用在人工智能领域和DSS中。
答案:B、D
50.51.在软件架构复用中,( )是指开发过程中,只要发现有可复用的资产,就对其进行复用。( )是指在开发之前,就要进行规划,以决定哪些需要复用。
A.发现复用 B.机会复用 C.资产复用 D.过程复用
A.预期复用 B.计划复用 C.资产复用 D.系统复用
解析:
资产复用是指开发过程中,只要发现有可复用的资产,就对其进行复用。
计划复用是指在开发之前,就要进行规划,以决定哪些需要复用。
答案:C、B
52.软件复用过程的主要阶段包括( )。
A.分析可复用的软件资产、管理可复用资产和使用可复用资产
B.构造/获取可复用的软件资产、管理可复用资产和使用可复用资产
C.构造/获取可复用的软件资产和管理可复用资产
D.分析可复用的软件资产和使用可复用资产
解析:
软件复用过程包含:创建、复用、支持、管理4个过程。
答案:B
53.DSSA(Domain Specific Software Architecture)就是在一个特定应用领域中为一组应用提供组织结构参考的标准软件体系结构,实施DSSA的过程中包含了一些基本的活动。其中,领域模型是( )阶段的主要目标。
A.领域设计
B.领域实现
C.领域分析
D.领域工程
解析:
领域分析的主要目标是获取领域模型
答案:C
54.55.软件系统质量属性(Quality Attribute)是一个系统的可测量或者可测试的属性,它被用来描述系统满足利益相关者需求的程度,其中,
( )关注的是当需要修改缺陷、增加功能、提高质量属性时,定位修改点并实施修改的难易程度;( )关注的是当用户数和数据量增加时,软件系统维持高服务质量的能力。
A.可靠性 B.可测试性 C.可维护性 D.可重用性
A.可用性 B.可扩展性 C.可伸缩性 D.可移植性
解析:
具体见本专栏 第八篇 八、软考-系统架构设计师笔记-系统质量属性和架构评估
开发期质量属性
可维护性:当需要修改缺陷、增加功能、提高质量属性时,定位修改点并实施修改的难易程度;.0
运行期质量属性
可伸缩性:指当用户数和数据量增加时,软件系统维持高服务质量的能力。
答案:C、C
56.57.为了精确描述软件系统的质量属性,通常采用质量属性场景(Quality Attibute Scenario)作为描述质量属性的手段。质量属性场景是一个具体的质量属性需求,是利益相关者与系统的交互的简短陈述,它由刺激源、刺激、环境、制品、( )六部分组成。其中,想要学习系统特性、有效使用系统、使错误的影响最低、适配系统、对系统满意属于( )质量属性场景的刺激。
A.响应和响应度量 B.系统和系统响应 C.依赖和响应 D.响应和优先级
A.可用性 B.性能 C.易用性 D.安全性
解析:
刻画质量属性的手段由六部分组成:刺激源、刺激、环境、制品、响应、响应度量;
最常见的质量属性分别是:可用性(Availability)、可修改性(Modifiability)、性能(Performance)、安全性(Security)、可测试性(Testability)、易用性(Usability)
答案:A、C
58.改变加密级别可能会对安全性和性能产生非常重要的影响,因此,在软件架构评估中,该设计决策是一个( )。
A.敏感点
B.风险点
C.权衡点
D.非风险点
解析:
敏感点是一个或多个构件的特性。权衡点是影响多个质量属性的特性,是多个质量属性的敏感点。
题目中,改变加密级别会影响安全性和性能两个质量属性,因此属于权衡点。
答案:C
59.效用树是采用架构权衡分析方法(Architecture Tradeoff AnalysisMethod,ATAM)进行架构评估的工具之一,其树形结构从根部到叶子节点依次为( )。
A.树根、属性分类、优先级,质量属性场景
B.树根、质量属性、属性分类,质量属性场景
C.树根、优先级、质量属性、质量属性场景
D.树根、质量属性、属性分类,优先级
解析:
质量属性效用树结构为:根——质量属性——属性求精(细 分)——场景(叶)
答案:B
60.平均失效等待时间(mean time to failure, MTTF)和平均失效间隔时间(mean time between failure, MTBF)是进行系统可靠性分析时的重要指标,在失效率为常数和修复时间很短的情况下,( )。
A.MTTF远远小于MTBF
B.MTTF和MTBF无法计算
C.MTTF远远大于MTBF
D.MTTF和MTBF几乎相等
解析:
在失效率为常数和修复时间很短的情况下,MTTF和MTBF几乎相等
答案:D
61.62.在进行软件系统安全性分析时,( )保证信息不泄露给末授权的用户、实体或进程;完整性保证信息的完整和准确,防止信息被非法修改;( )保证对信息的传播及内容具有控制的能力,防止为非法者所用。
A.完整性 B.不可否认性 C.可控性 D.机密性
A.完整性 B.安全审计 C.机密性 D.可控性
解析:
信息安全包括的要素有:
1、机密性:确保信息不暴露给未授权的实体或进程。
2、完整性:只有得到允许的人才能修改数据,并且能够判别出数据是否已被篡改。
3、可用性:得到授权的实体在需要时可以访问数据,即攻击者不能占用所有的资源而阻碍授权者的工作。
4、可控性:可以控制授权范围内的信息流向及行为方式。
5、可审查性:对出现的网络安全问题提供调查的依据和手段。
答案:D、D
63.在进行架构评估时,首先要明确具体的质量目标,并以之作为判定该架构优劣的标准。为得出这些目标而采用的机制叫做场景,场景是从( )的角度对与系统的交互的简短描述。
A.用户 B.系统架构师 C.项目管理者 D.风险承担者
解析:
场景(scenarios)在进行体系结构评估时,一般首先要精确地得出具体的质量目标,并以之作为判定该体系结构优劣的标准。
为得出这些目标而采用的机制做场景。
场景是从风险承担者的角度对与系统的交互的简短描述。
在体系结构评估中,一般采用刺激(stimulus)、环境(environment)和响应(response)三方面来对场景进行描述。
答案:D
64. 5G网络采用( )可将5G网络分割成多张虚拟网络,每个虚拟网络的接入,传输和核心网是逻辑独立的,任何一个虚拟网络发生故障都不会影响到其它虚拟网络。
A.网络切片技术
B.边缘计算技术
C.网络隔离技术
D.软件定义网络技术
解析:
5G网络的切片技术是将5G网络分割成多张虚拟网络,从而支持更多的应用。
就是将一个物理网络切割成多个虚拟的端到端的网络,每个虚拟网络之间,包括网络内的设备、接入、传输和核心网,是逻辑独立的,任何一个虚拟网络发生故障都不会影响到其它虚拟网络。
在一个网络切片中,至少可分为无线网子切片、承载网子切片和核心网子切片三部分。
答案:A
65.以下 Wifi 认证方式中,( ) 使用了AES加密算法,安全性更高。
A.开放式
B.WPA
C.WPA2
D.WEP
解析:
WPA2 WPA2是IEEE 802.11i标准的认证形式,WPA2实现了802.11i的强制性元素,特别是Michael算法被公认彻底安全的CCMP
(计数器模式密码块链消息完整码协议)讯息认证码所取代、而RC4加密算法也被AES所取代。
WPA2是WPA的增强版,安全性更高。
答案:C
66.程序员甲将其编写完成的某软件程序发给同事乙并进行讨论,之后甲放弃该程序并决定重新开发,后来乙将该程序稍加修改并署自己名在某技术论坛发布。以下说法中,正确的是( )。
A.乙的行为侵犯了甲对该程序享有的软件著作权
B.乙的行为未侵权,因其发布的场合是以交流学习为目的的技术论坛
C.乙的行为没有侵犯甲的软件著作权,因为甲已放弃该程序
D.乙对该程序进行了修改,因此乙享有该程序的软件著作权
解析:
甲完成该软件的开发后就拥有了该软件的著作权,乙将该程序稍加修改就发布,侵犯了甲的软件著作权。
答案:A
67.以下关于软件著作权产生时间的叙述中,正确的是( )。
A.软件著作权产生自软件首次公开发表时
B.软件著作权产生自开发者有开发意图时
C.软件著作权产生自软件开发完成之日起
D.软件著作权产生自软件著作权登记时
解析:
《中华人民共和国计算机软件保护条例》第十四条软件著作权自软件开发完成之日起产生
答案:C
68.M公司将其开发的某软件产品注册了商标为S,为确保公司可在市场竞争中占据优势地位,M公司对员工进行了保密约束,此情形下,该公司不享有( )。
A.软件著作权
B.专利权
C.商业秘密权
D.商标权
解析:
M公司的软件产品开发完成时就自动享有软件著作权,注册了商标就享有了商标权,对员工签了保密协议就享有了商业秘密权。
因此只有专利权未提及。
答案:B
69.计算机产生的随机数大体上能在(0,1)区间内均匀分布。假设某初等函数f(x)在 (0,1) 区间内取值也在 (0,1) 区间内,如果由计算机产生的大量的 (M个) 随机数对(r1, r2)中,符合r2≤f(r1) 条件的有N个,则N/M可作为( )的近似计算结果。
A.求解方程f(x)=x
B.求f(x)极大值
C.求f(x)的极小值
D.求积分
解析:
根据题目描述,我们得到条件是 r2 ≤ f(r1),表示一个点 (r1, r2) 在函数曲线 y = f(x) 的下方或等于该曲线上的面积。
如果我们在 (0,1) 区间生成大量的随机点 (r1, r2),并计算满足条件 r2 ≤ f(r1) 的点的个数 N,那么 N/M 就是函数 y = f(x) 在 (0,1) 区间上下方面积比例的一个近似值。
这可以通过求解函数 f(x) 的积分来获得。积分可以用来计算函数曲线下面积,因此 N/M 可以近似作为函数 f(x) 在 (0,1) 区间上下方面积比例的计算结果。
答案:D
70.某项目包括A、B、C、D四道工序,各道工序之间的衔接关系。正常进度下各工序所需的时间和直接费用、赶工进度下所需的时间和直接费用如下表所示。该项目每天需要的间接费用为4.5万元。根据此表,以最低成本完成该项目需要( )天。
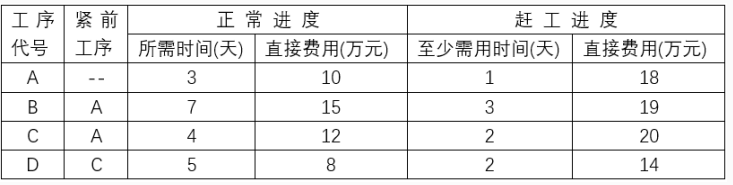
A.7
B.9
C.10
D.5
解析:
这题的目标就是 尽量去赶工 那些直接费用小 并且能缩短总总工期的活动 来达到 项目总费用最低的结果
按照正常进度画网络图
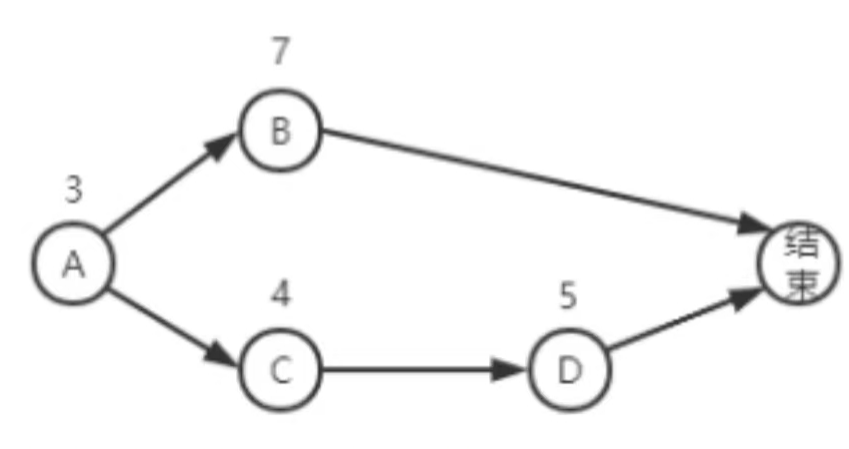
关键路径为 A -> C -> D 总工期为12 完成项目总费用为 10 + 15 + 12 + 8 + 12 x 4.5 = 99w
根据表格计算下 每个活动 赶工天数和费用的数据

由上图可以看出 每个活动赶工每天增加的直接费用 和项目每天需要的间接费用 相比都是小的
所以 在能缩短项目总工期的前提下 每个活动都能赶工 以减小总费用
如果全部活动按照最大限度赶工 画网络图

关键路径为 A -> C -> D 总工期为5 完成项目总费用为 18 + 19 + 12 + 14 + 5 x 4.5 = 93.5w
表中给出的赶工进度 每个活动写的是至少需要的天数 所以每个活动不一定需要压缩到极限天数
例如A 活动至少是1天 正常进度是3天 那我赶工A活动 可以赶工到1天完成是极限状态
也可以赶工到2天完成
实际上 总工期极限压缩 最短就是5天 上图 B活动 压缩到3天 并没有缩短总工期 还白白浪费了1w块
所以可以优化一下 B只赶工3天 也就是赶工后B 4天完成 总工期还是5天 但是总费用可以少去B赶工多出一天的1w
也就是 92.5w
网络图如下:

但是92.5w 并不是最优解
继续分析、根据网络图可知 B 和 C 、D 活动是并行 进行的
再结合上表 如果B C同时赶工 那么B C 两个活动每天一共多产生的直接费用就是 5w 就大于了每天的间接成本 4.5w 所以 B C 如果同时赶工只会增加总费用
如果B D同时赶工 那么B D 两个活动每天一共多产生的直接费用就是 3w 小于每天的间接成本 4.5w 所以 B D 同时赶工能降低总费用
(PS: 这里可能有人会问 能不能 C D 赶工 B 不赶工 其实上面第一种情况就是 ACD赶工 总工期5 如果B不赶工 就无法把总工期缩短到5 毕竟B赶工一天花1w 如果能缩短1天总工期 能节省4.5w 算下来靠B缩短一天总工期 一天就省3.5w 所以ACD赶工 B不赶工 并不是最优解 )
那么就能得出如下方式
A 赶工 B赶工 D赶工 C不赶工 如下图

A C D路径 是7天 如果B不赶工 那么总工期就是 AB 路径 8天 由于 B赶工一天 直接成本增加1w 间接费用能减少4.5w
所以 B 需要再 赶工一天 把总工期降到7天
为什么B只赶工1天呢 ? 因为 B再赶工2天或更高的话 也无法再缩短总工期 也就无法再减少间接费用 而且还会增加直接费用
所以B只要 再赶工一天 把总工期降到7天 就够了
最终的网络图如下
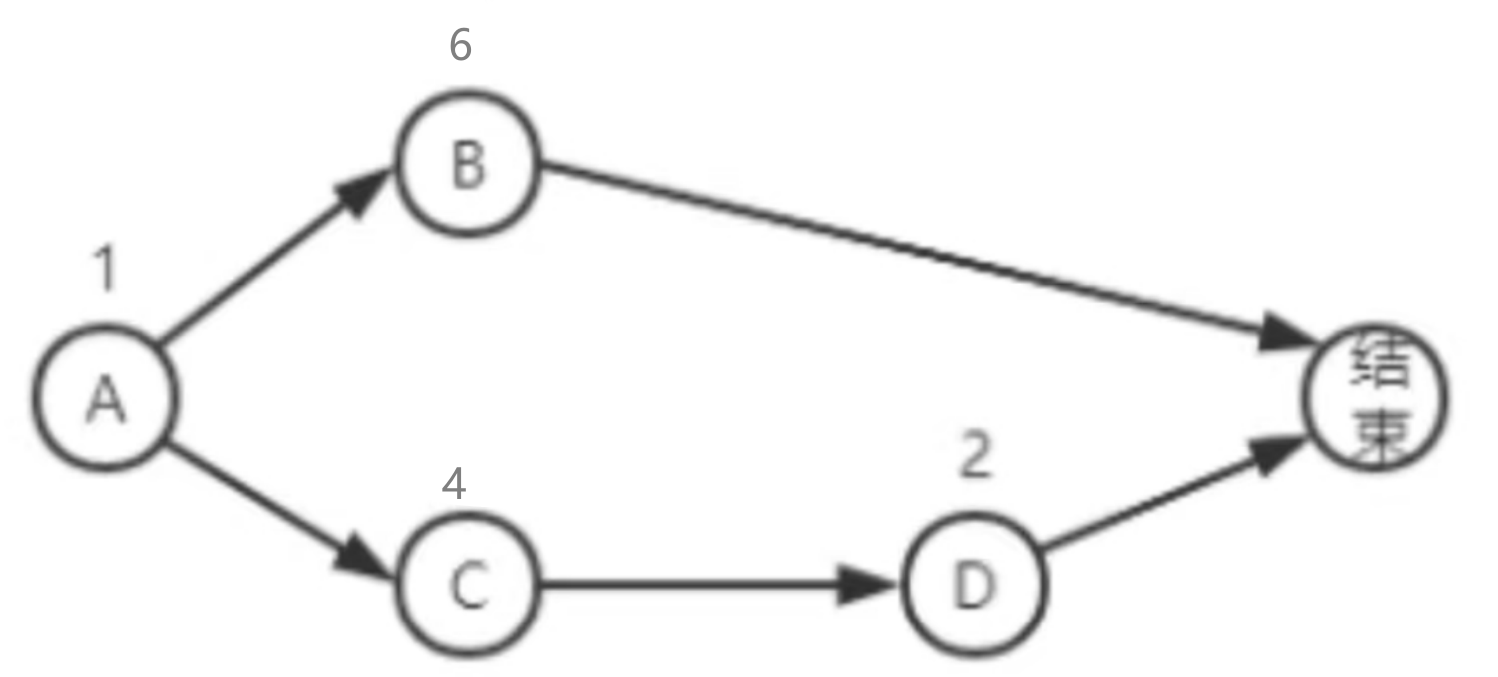
总工期为7 完成项目总费用为 A 赶工最大限度:18 B赶工一天:15+1=16 C不赶工 :12 D 赶工最大限度:14 再加 7x4.5
18+16+12+14+7x4.5=91.5
答案:A
71~75:
Micro-service is a software development technology, which advocates dividing a single applicationinto a group of small services, which coordinates and cooperates with each other to provide ultimate value for users. The micro-service (71) has many important benefits. First,it solves the problem of business complexity. lt decomposes the original huge single application into a group of services. Although the total amount of functions remains the same, the application has been decomposed into manageable services.The development speed of a single service is much faster, and it is easier to understand and (72). Second, this architecture allows each service to be (73) independently by a team. Developers are free tochoose any appropriate technology. Third, the micro-service architecture mode enables each service to be (74) independently. Developers never need to coordinate the deployment of local changes to their services. These types of changes can be deployed immediately after testing. Finally, the micro-service architecture enables each service to (75) independently.
71:
A: architecture
B: software
C: application
D: technology
72:
A: develop
B: maintain
C: utilized
D: deploy
73:
A: planned
B: developed
C: utilized
D: deployed
74:
A: utilized
B: developed
C: tested
D: deployed
75:
A: analyze
B: use
C: design
D: expand
答案: A、B、B、D、D
解析:
微服务是一种软件开发技术,主张将单个应用程序划分为一组小服务,相互协调合作,为用户提供最终价值。微服务 (71 架构)
有许多重要的好处。首先,它解决了业务复杂性的问题。它将原来庞大的单个应用程序分解为一组服务。尽管功能总量保持不变,但应用程序已分解为可管理的服务。单个服务的开发速度要快得多,而且更容易理解和 (72 维护) 。其次,这种体系结构允许每个服务由一个团队独立 (73 开发) 。开发人员可以自由选择任何合适的技术。第三,微服务架构模式使每个服务能够独立地 (74 部署) 。开发人员从不需要协调对其服务的本地更改的部署。这些类型的更改可以在测试后立即部署。最后,微服务体系结构使每个服务能够独立地 (75 扩展) 。
71:
A: architecture 体系结构\架构
B: software 软件
C: application 应用
D: technology 技术
72:
A: develop 发展
B: maintain 维护
C: utilized 已使用
D: deploy 部署
73:
A: planned 计划的
B: developed 开发
C: utilized 已使用
D: deployed 已部署
74:
A: utilized 已使用
B: developed 部署
C: tested 已测试
D: deployed 已部署
75:
A: analyze 分析
B: use 使用
C: design 设计
D: expand 扩展
软考-系统架构设计师-2022年下午案例真题
考试时间 14:30 ~18:00
案例最长答题时间 14:30 ~ 16:00
(第一题必答,二~五题选两个)
试题一(共25分) :
阅读以下关于软件架构设计与评估的叙述,在答题纸上回答问题1和问题2
【说明】 某电子商务公司拟升级其会员与促销管理系统,向用户提供个性化服务,提高用户的粘性。在项目立项之初,公司领导层一致认为本次升级的主要目标是提升会员管理方式的灵活性,由于当前用户规模不大,业务也相对简单,系统性能方面不做过多考虑,新系统除了保持现有的四级固定会员制度外,还需要根据用户的消费金额、偏好、重复性等相关特征动态调整商品的折扣力度,并支持在特定的活动周期内主动筛选与活动主题高度相关的用户集合,提供个性化的打折促销活动。 在需求分析与架构设计阶段,公司提出的需求和质量属性描述如下:
(a)管理员能够在页面上灵活设置折扣力度规则和促销活动逻辑,设置后即可生效;
(b)系统应该具备完整的安全防护措施,支持对恶意攻击行为进行检测与报警;
©在正常负载情况下,系统应在0.3秒内对用户的界面操作请求进行响应;
(d)用户名是系统唯一标识,要求以字母开头,由数字和字母组合而成,长度不少于6个字符。
(e)在正常负载情况下,用户支付商品费用后在3秒内确认订单支付信息;
(f)系统主站点电力中断后,应在5秒内将请求重定向到备用站点;
(g)系统支持横向存储扩展,要求在2人天内完成所有的扩展与测试工作;
(h)系统宕机后,需要在10秒内感知错误,并自动启动热备份系统;
(i)系统需要内置接口函数,支持开发团队进行功能调试与系统诊断;
(j)系统需要为所有的用户操作行为进行详细记录,便于后期查阅与审计;
(k)支持对系统的外观进行调整和配置,调整工作需要在4人天内完成。
在对系统需求、质量属性描述和架构特性进行分析的基础上,系统架构师给出了两种候选的架构设计方案,公司目前正在组织相关专家对系统架构进行评估。
【问题1】(12分) 在架构评估过程中,质量属性效用树 (utility tree)是对系统质量属性进行识别和优先级排序的重要工具。请将合适的质量属性名称填入图1-1中(1)、(2)空白处,并选择题干描述的(a)~(k)填入(3)~(6)空白处,完成该系统的效用树。
图1-1会员与促销管理系统效用树
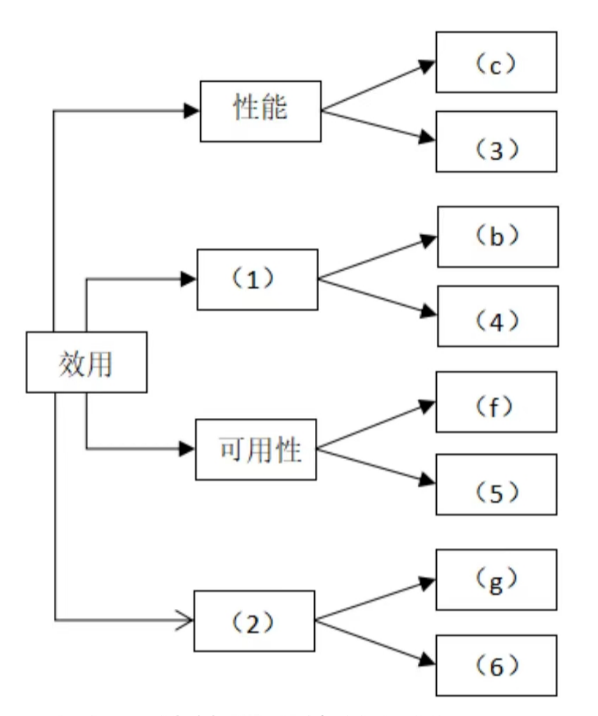
解析:
(1)中包含 (b)系统应该具备完整的安全防护措施,支持对恶意攻击行为进行检测与报警; 所以 (1)是 安全性
(2)中包含 (g)系统支持横向存储扩展,要求在2人天内完成所有的扩展与测试工作; 所以 (2)是可修改性
(e)在正常负载情况下,用户支付商品费用后在3秒内确认订单支付信息; 属于性能
(j)系统需要为所有的用户操作行为进行详细记录,便于后期查阅与审计; 属于安全性
(h)系统宕机后,需要在10秒内感知错误,并自动启动热备份系统; 属于可用性
(k)支持对系统的外观进行调整和配置,调整工作需要在4人天内完成。 属于可修改性
答案:
(1)安全性 (2)可修改性 (3) e (4) j (5) h (6) k
【问题2】(13分) 针对该系统的功能,李工建议采用面向对象的架构风格,将折扣力度计算和用户筛选分别封装为独立对象,通过对象调用实现对应的功能:王工则建议采用解释器(interpreters) 架构风格,将折扣力度计算和用户筛选条件封装为独立的规则,通过解释规则实现对应的功能。请针对系统的主要功能,从折扣规则的可更改性、个性化折扣定义灵活性和系统性能三个方面对这两种架构风格进行比较与分析,并指出该系统更适合采用哪种架构风格。
解析:
面向对象的特点是 把一些静态内容封装成对象的属性 动态内容 封装成方法 通过方法调用完成功能
优点是易于理解和设计 执行效率高 缺点是 可修改性 灵活性不好
答案:
更适合解释器架构风格。
| 面向对象的架构风格 | 解释器架构风格 | |
|---|---|---|
| 折扣规则的可修改性 | 面向对象需要封装成对象,可修改性不好。 | 可以要求设置各独立的折扣规则,解释器对变化的规则进行解析,可修改性好。 |
| 个性化折扣定义灵活性 | 面向对象相对固定,灵活性差 | 解释器可以根据用户筛选条件灵活设置规则,灵活性好。 |
| 系统性能 | 面向对象的架构执行效率高 | 解释器是运行期动态绑定执行,执行效率较低 |
试题二(25分)
煤炭生产是国民经济发展的主要领域之一,其煤矿的安全非常重要。某能源企业拟开发一套煤矿建设项目安全预警系统,以保护煤矿建设项目从业人员的生命安全。本系统的主要功能包括如下
(a)~(h)所述。
(a)项目信息维护
(b)影响因素录入
©关联事故录入
(d)安全评价得分
(e)项目指标预警分析
(f)项目指标填报
(g)项目指标审核
(h)项目指标确认
问题1 (9分)
王工根据煤矿建设项目安全预警系统的功能要求,设计完成了系统的数据流图,如图2-1所示。请使用题干中描述的功能(a)~(h),
补充完善空(1)~(6)处的内容,并简要介绍数据流图在分层细化过程中遵循的数据平衡原则。

解析:
安全员 指标数据 (1)为 (f)项目指标填报
安全副经理 审核信息 (2) (g)项目指标审核
项目经理 确认信息 (3) (h)项目指标确认
(6) 向指标预警分析表输出数据 所以 是 (e)项目指标预警分析 ,同时又向项目信息维护输送
(5) 向事故及影响因素参数表输出信息 所以 是 (b)影响因素录入
还剩个 (d)安全评价得分 给 (4)
答案:
(1)f (2)g (3)h (4)d (5)b (6)e
分层细化的数据平衡原则:
1.父图与子图的平衡:父图与-图之间平衡是指任何一张DFD子图边界上的输入/输出数据流必须与其父图中对应加工的输入/输出数据流保持一致。
2.数据守恒:一个加工的所有输出数据流中的数据必须能从该加工的输入数据流中直接获得或能通过该加工的处理而产生。
问题2(9分)
请根据问题1中数据流图表示的相关信息,补充完整煤矿建设项目安全预警系统总体E-R图(见图2-2)中实体(1)~(6)的具体内容。
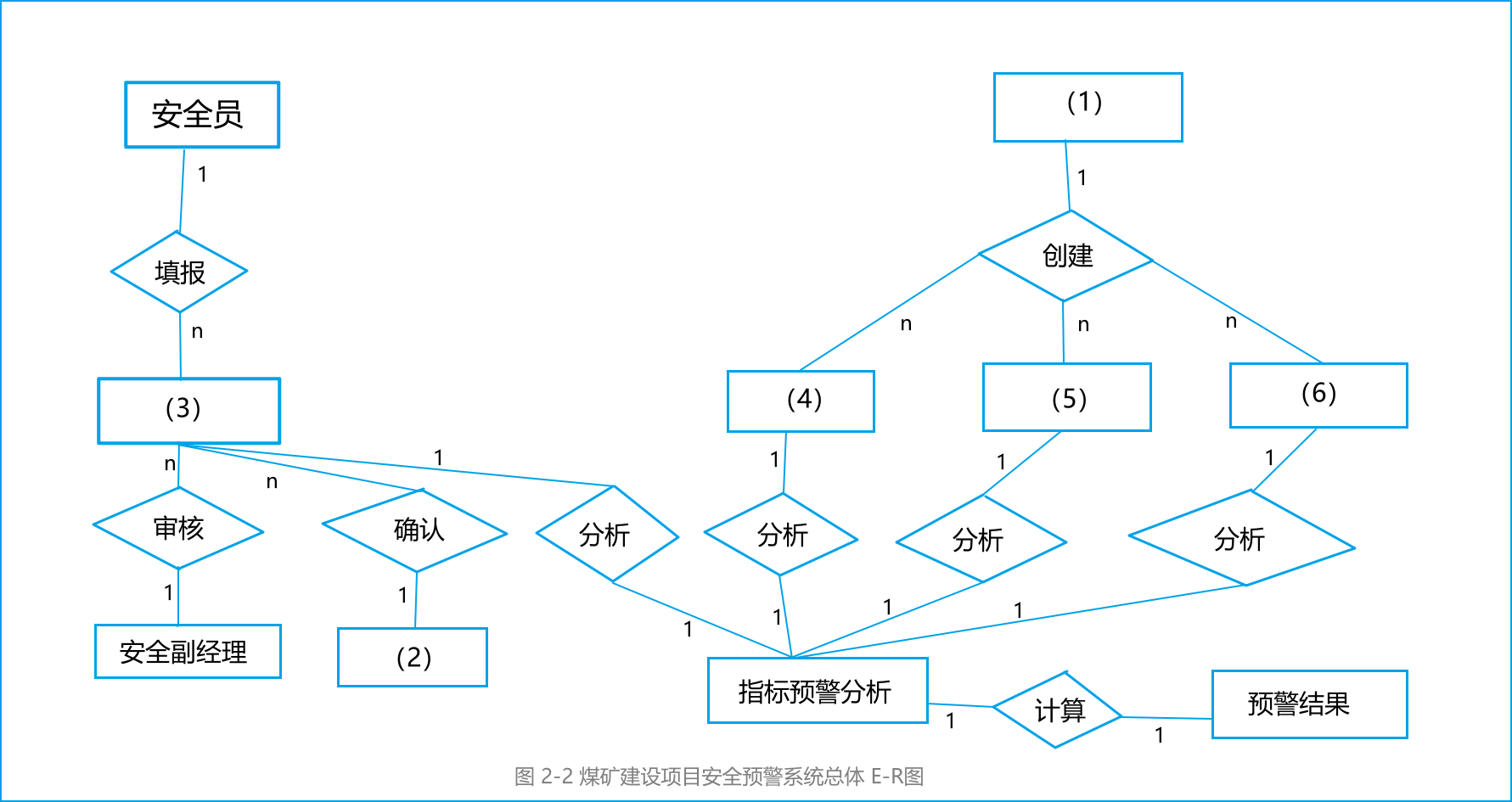
解析:
由图可知 安全员 填报 项目指标数据 所以 (3) 是项目指标数据
由数据流图 可知 项目经理确认数据 所以 (2) 是项目经理
ER图中 (1) (4) (5) (6) 均指向 指标预警分析
所以 (4)项目信息 (5)指标参数 (6)事故及影响因素参数 (4~6可互换)
(1) 是项目管理员
答案:
(1)项目管理员 (2)项目经理 (3)项目指标数据
(4)项目信息 (5)指标参数 (6)事故及影响因素参数 (4~6可互换)
问题3(7分)
在结构化分析和设计过程中,数据流图和数据字典是常用的技术手段,请用200字以内的文字简要说明它们在软件需求分析和设计阶段的作用。
解析:
见答案
答案:
| 需求分析阶段 | 设计阶段 | |
|---|---|---|
| 数据流图 | 数据流图用于界定系统上下文范围和建立业务流程的加工说明,自顶向下对系统进行功能分解;指明数据在系统内移动变换;描述功能及加工规约 | 将分析阶段的结果(数据流图)映射成软件的体系结构(结构图),为模块的划分与模块之间的接口设计提供依据 |
| 数据字典 | 数据字典用于建立业务概念有组织的集合,是模型核心库,有组织的系统相关数据元素列表,使涉众对模型中元素有共同的理解 | 根据数据字典中的数据存储描述来建立数据库存储设计 |
试题三(25分)
阅读以下关于嵌入式系统故障检测和诊断的相关描述,在答题纸上回答问题1至问题3
【说明】
系统的故障检测和诊断是宇航系统提高装备可靠性的主要技术之一,随着装备信息化的发展,分布式架构下的资源配置越来越多、资源布局也越来越分散,这对系统的故障检测和诊断方法提出了新的要求,为了适应宇航装备的分布式综合化电子系统的发展,解决由于系统资源部署的分散性,造成系统状态的综合和监控困难的问题,公司领导安排张工进行研究。张工经过分析、调研提出了针对分布式综合化电子系统架构的故障检测和诊断的方案。
【问题1】(8分)
张工提出:宇航装备的软件架构可采用四层的层次化体系结构,即模块支持层、操作系统层、分布式中间件层和功能应用层。为了有效、方便地实现分布式系统的故障检测和诊断能力,方案建议将系统的故障检测和诊断能力构建在分布式中间件内,通过使用心跳或者超时探测技术来实现故障检测器。请用300字以内的文字分别说明心跳检测和超时探测技术的基本原理及特点。
解析:
见答案
答案:
心跳检测技术是节点每隔一个固定周期就向其他节点发送心跳信息,表示自己存活。如果其他节点在几个周期之后仍然没有收到来自此节点的心跳,就认定节点已失效,接管其资源和服务。其优点是可以快速反应,缺点是容易产生误判。为了减少误判,通常会采用多种介质冗余传输心跳信息,如串口、网络、共享磁盘等。
超时探测技术是节点主动向被探测节点发出PING信号,被探测节点则在收到PING信号后回复一个ECHO信号,表示自己的健康状态良好,还可以附加一些状态信息。如果在预定的时间之后仍然收不到ECHO信号,则判定被探测节点失效。优点是可以获得更详细的探测结果,缺点是判断的周期较长。
【问题2】(8分)
张工针对分布式综合化电子系统的架构特征,给出了初步设计方案,指出每个节点的故障监测与诊断器主要负责监控系统中所有的故障信息,并将故障信息进行综合分析判断,使用故障诊断器分析出故障原因,给出解决方案和措施。系统可以给模块的每个处理机器核配置核状态监控器、给每个分区配置分区状态监控器、给每个模块配置模块状态监控器、给系统配置系统状态监控器,
如图3-1所示。
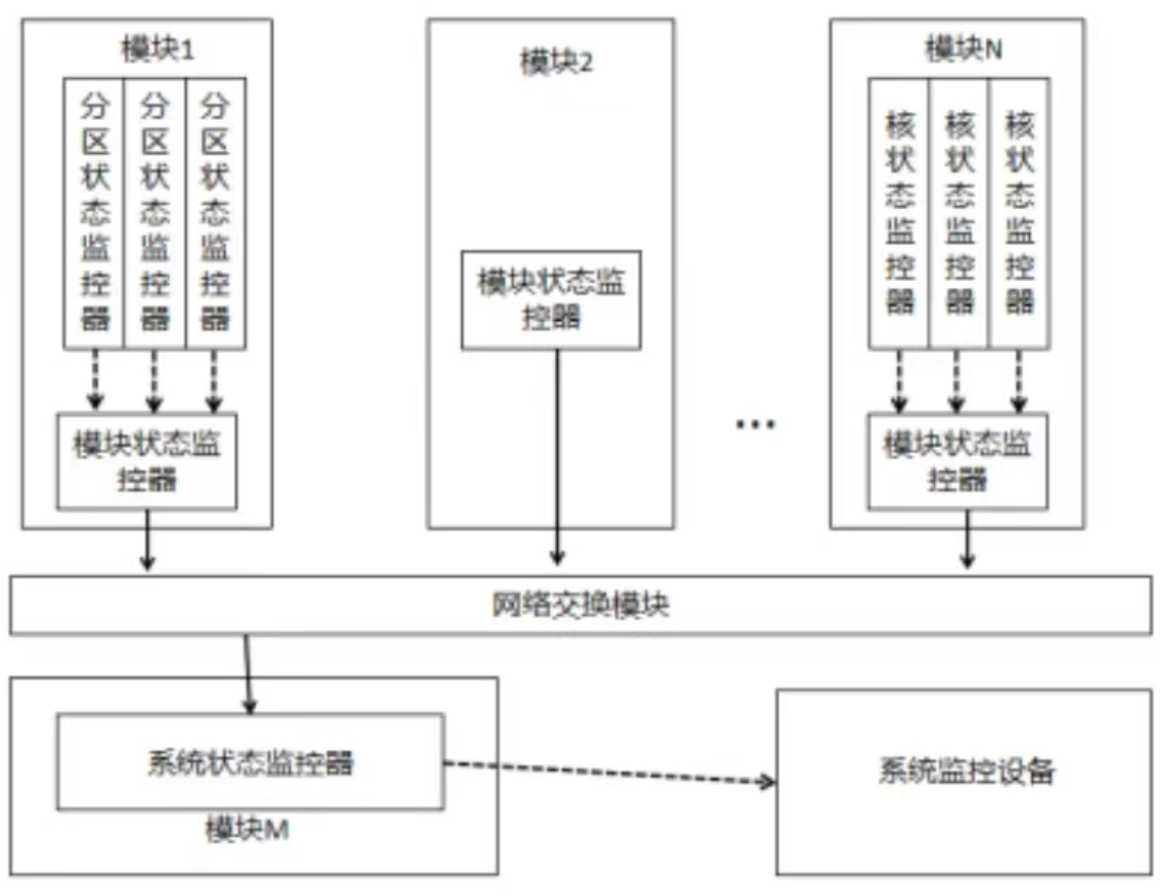 图3-1系统故障检测和诊断原理
图3-1系统故障检测和诊断原理
请根据下面给出的分布式综合化电子系统可能产生的故障(a)–(h),判断这些故障分别属于哪类监控器检测的范围,完善表3-1的(1)–(8)的空白。
(a)应用程序除零
(b)看门狗故障
( c) 任务超时
(d)网络诊断故障
(e)BIT检测故障
(f)分区堆栈溢出
(g)操作系统异常
(h)模块掉电
表3-1故障分类

解析:
| 核状态监控器 | 应用程序除零 、看门狗故障 |
|---|---|
| 分区状态监控器 | 分区堆栈溢出 |
| 模块状态监控器 | 任务超时、BIT检测故障 、模块掉电 |
| 系统状态监控器 | 网络诊断故障、操作系统异常 |
答案:
(1)a (2)b (3)f (4)c (5)e (6)h (7)d (8)g
【问题3】(9分)
张工在方案中指出,本系统的故障诊断采用故障诊断器实现,它可综合多种故障信息和系统状态,依据智能决策数据库提供的决策策略判定出故障类型和处理方法。智能决策数据库中的策略可以对故障开展定性或定量分析,通常,在定量分析中,普遍采用基于解析模型的方法和数据驱动的方法,张工在方案中提出该系统定量分析时应采用基于解析模型的方法。但是此提议受到王工的反对,王工指出采用数据驱动的方法更适合分布式综合化电子系统架构的设计。请用300字以内的文字,说明数据驱动方法的基本概念,以及王工提出采用此方法的理由。
解析:
见答案
答案:
数据驱动方法是一种问题求解方法。从初始的数据或观测值出发,运用启发式规则,寻找和建立内部特征之间的关系,从而发现一些定理或定律。通常也指基于大规模统计数据的自然语言处理方法。 在本题中,由于是分布式环境,需要综合多种故障信息和系统状态,依据智能决策数据库的决策策略判定,如果采用预先定制的解析模型,这个模型可能会非常复杂。因此采用数据驱动方法能通过已有的数据去训练模型,可以达到逐渐精细化,并兼容未来的变化。
试题四(25分)
某大型电商平台建立了一个在线B2B商店系统,并在全国多地建设了货物仓储中心,通过提前备货的方式来提高货物的运送效率。但是在运营过程中,发现会出现很多跨仓储中心调货从而延误货物运送的情况。为此,该企业计划新建立一个全国仓储货物管理系统,在实现仓储中心常规管理功能之外,通过对在线B2B商店系统中订单信息进行及时的分析和挖掘,并通过大数据分析预测各地仓储中心中各类货物的配置数量,从而提高运送效率,降低成本。当用户通过在线B2B商店系统选购货物时,全国仓储货物管理系统会通过该用户所在地址、商品类别以及仓储中心的货物信息和地址,实时为用户订单反馈货物起运地(某仓储中心)并预测送达时间。反馈送达时间的响应时间应小于1秒。为满足反馈送达时间功能的性能要求,设计团队建议在全国仓储货物管理系统中采用数据缓存集群的方式,将仓储中心基本信息、商品类别以及库存数量放置在内存的缓存中,而仓储中心的其它商品信息则存储在数据库系统。
问题1(9分)
设计团队在讨论缓存和数据库的数据一致性问题时,李工建议采取数据实时同步更新方案,而张工则建议采用数据异步准实时更
新方案。请用200字以内的文字,简要介绍两种方案的基本思路,说明全国仓储货物管理系统应该采用哪种方案,并说明采取该方
案的原因。
解析:
答案:
问题2(9分)
随着业务的发展,仓储中心以及商品的数量日益增加,需要对集群部署多个缓存节点,提高缓存的处理能力。李工建议采用缓存分片方法,把缓存的数据拆分到多个节点分别存储,减轻单个缓存节点的访问压力,达到分流效果。缓存分片方法常用的有哈希算法和一致性哈希法,李工建议采用一致性哈希算法来进行分片。请用200字以内的文字简要说明两种算法的基本原理,并说明李工采用一致性哈希算法的原因。
解析:
答案:
问题3(7分)
全国仓储货物管理系统开发完成,在运营一段时间后,系统维护人员发现大量黑客故意发起非法的商品送达时间查询请求,造成了缓存击穿。张工建议尽快采用布隆过滤器方法解决。请用200字以内的文字解释布隆过滤器的工作原理和优缺点。
解析:
答案:
试题五(25分)
某公司拟开发一套基于边缘计算的智能门禁系统,用于如园区、新零售、工业现场等存在来访、被访业务的场景。来访者在来访前,可以通过线上提前预约的方式将自己的个人信息记录在后台,被访者在系统中通过此请求后,来访者在到访时可以直接通过"刷脸"的方式通过门禁,无需做其他验证。此外,系统的管理员可对正在运行的门禁设备进行管理。基于项目需求,该公司组建项目组,召开了项目讨论会。会上,张工根据业务需求并结合边缘计算的思想,提出本系统可由访客注册模块、模型训练模块、端侧识别模块与设备调度平台模块等四项功能组成。李工从技术层面提出该系统可使用Flask框架与SSM框架为基础来开发后台服务器,将开发好的系统通过Docker进行部署,并使用MQTT协议对Docker进行管理。
问题1(5分)
MQTT协议在工业物联网中得到广泛的应用,请用300字以内的文字简要说明MQTT协议。
问题2 (14分)
在会议上,张工对功能模块进行了更进一步的说明:访客注册模块用于来访者提交申请与被访者确认申请,主要处理提交来访申请、来访申请审核业务,同时保存访客数据,为训练模块准备训练数据集;模型训练模块用于使用访客数据进行模型训练,为端侧设备的识别提供模型基础;端侧识别模块在边缘门禁设备上运行,使用训练好的模型来识别来访人员,与云端服务协作完成访客来访的完整业务;设备调度平台模块用于对边缘门禁设备进行管理,管理人员能够使用平台对边缘设备进行调度管理与状态监控,实现云端协同。
图5-1
给出了基于边缘计算的智能门禁系统架构图,请结合HTTP协议和MQTT协议的特点为图5-1中(1)~(6)处选择合适的协议;并结合张工关于功能模块的描述,补充完善图5-1中(7)~(10)处的空白。
问题3(6分)
请用300字以内的文字,从数据通信、数据安全和系统性能等方面简要分析在传统云计算模型中引入边缘计算模型的优势。
软考-系统架构设计师-2022年下午论文真题
考试时间 14:30 ~18:00
论文建议答题时间 16:00 ~ 18:00
持续更新中。。。

