- 1【强化学习】DQN及其变体网络的原理讲解和代码实现_dqn中的参数更新损失函数
- 2fedora 20 安装mysql_在Fedora 20 上安装Mysql并初始化root密码
- 3九章云极DataCanvas公司牵手国家超算互联网,实现算法与算力一体化服务
- 4华为鸿蒙系统与电动无人汽车功能定位,华为鸿蒙系统发布在即,新日智能锂电车蓄势待发...
- 5vscode函数跳转环境搭建(C/C++)
- 6祝大家新年快乐,龙年大吉大利
- 7etcd raft cap 理解_cap etcd
- 8逻辑回归(Logistic Regression):原理、实现与应用_1.掌握逻辑回归的数学原理及推导过程; 2.编程实现逻辑回归函数,并应用与给定手
- 9野百合也有春天
- 10uni-app 中实现 onLaunch 异步回调后执行 onLoad 最佳实践_uniapp+vuex 微信小程序检查异步接口回调完成
带你深入了解spark(重生之最牛逼最详细版)
赞
踩
1.什么是spark
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
spark官网:Apache Spark™ - Unified Engine for large-scale data analytics
spark概述
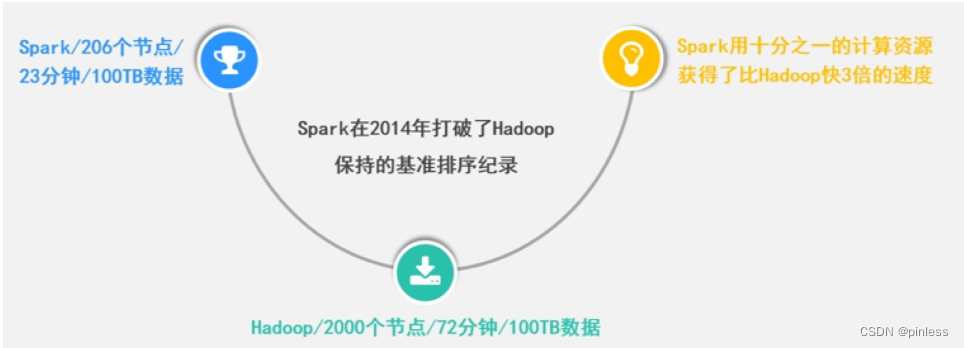
第一阶段:Spark最初由美国加州伯克利大学( UC Berkelcy)的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序
第二阶段:2013年Spark加入Apache孵化器项日后发展迅猛,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一( Hadoop磁盘MR离线式、Spark基于内存实时数据分析框架、Storm数据流分析框架 )
第三阶段:
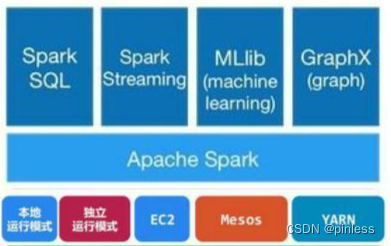
spark的生态圈
Spark的核心,提供底层框架及核心支持。
一个用于在海量数据上进行交互式SQL查询的大规模并行查询引擎,允许用户通过权衡数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内。
可以执行SQL查询,支持基本的SQL语法和HiveQL语法,可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
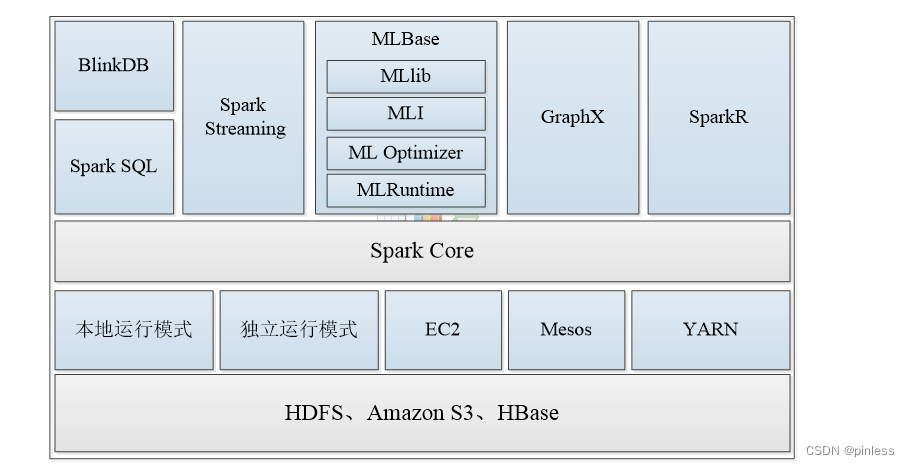
是Spark生态圈的一部分,专注于机器学习领域,学习门槛较低。
MLBase由4部分组成:MLlib、MLI、ML Optimizer和MLRuntime。
MLlib部分算法如下

2.spark和Mapreduce的简单介绍
MapReduce和Spark都是用于大数据处理的框架,但们在设计和功能上有一些区别。

MapReduce是一种编程模型,用于处理大规模数据集的并行计算。它由Google提出,并被Apache Hadoop项目采纳。MapReduce将计算任务分为两个阶段:Map阶段和Reduce阶段。在Map阶段,数据被切分成小块,并由多个计算节点并行处理。在Reduce阶段,计算节点将Map阶段的结果进行合并和汇总。MapReduce适用于离线批处理任务,但由于其磁盘读写较多,对实时性要求较高的场景下性能较差。
Spark是一种快速、通用的大数据处理引擎,也是Apache软件基金会的开源项目。与MapReduce不同,Spark将数据存储在内存中,通过弹性分布式数据集(RDD)来实现高效的并行计算。Spark提供了丰富的API,包括支持SQL查询、流处理、机器学习和图计算等功能。相比于MapReduce,Spark具有更低的延迟和更高的性能,适用于需要实时处理和交互式查询的场景。
① mapreduce是基于磁盘的,spark是基于内存的。mapreduce会产生大量的磁盘IO,而 spark基于DAG计算模型,会减少Shaffer过程即磁盘IO减少。
②spark是多线程运行,mapreduce是多进程运行。进程的启动和关闭和会耗费一定的时间。
③兼容性:spark可单独也可以部署为on yarn模式,mapreduce一般都是on yarn模式
④shuffle与排序,mapreduce有reduce必排序
⑤spark有灵活的内存管理和策略
总结:MapReduce适用于离线批处理任务,而Spark适用于需要实时处理和交互式查询的场景。
3.结构化数据和非结构化数据有何区别?
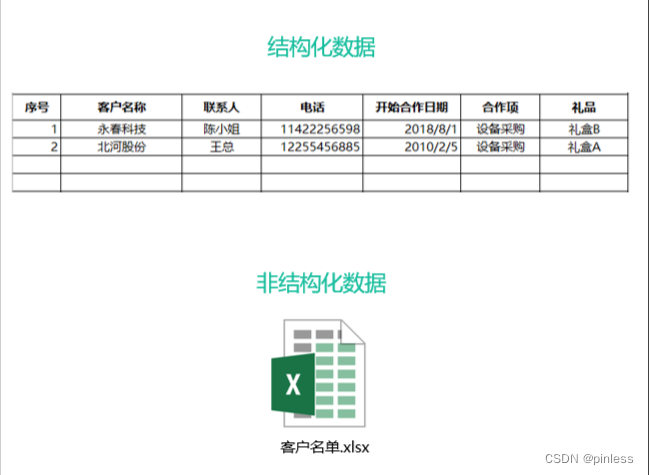
什么是结构化数据
大多数人都熟悉结构化数据的工作原理。结构化数据,可以从名称中看出,是高度组织和整齐格式化的数据。它是可以放入表格和电子表格中的数据类型。它可能不是人们最容易找到的数据类型,但与非结构化数据相比,无疑是两者中人们更容易使用的数据类型。另一方面,计算机可以轻松地搜索它。
结构化数据也被成为定量数据,是能够用数据或统一的结构加以表示的信息,如数字、符号。在项目中,保存和管理这些的数据一般为关系数据库,当使用结构化查询语言或SQL时,计算机程序很容易搜索这些术语。结构化数据具有的明确的关系使得这些数据运用起来十分方便,不过在商业上的可挖掘价值方面就比较差。
典型的结构化数据包括:信用卡号码、日期、财务金额、电话号码、地址、产品名称等。
什么是非结构化数据
非结构化数据本质上是结构化数据之外的一切数据。它不符合任何预定义的模型,因此它存储在非关系数据库中,并使用NoSQL进行查询。它可能是文本的或非文本的,也可能是人为的或机器生成的。简单的说,非结构化数据就是字段可变的的数据。
非结构化数据不是那么容易组织或格式化的。收集,处理和分析非结构化数据也是一项重大挑战。这产生了一些问题,因为非结构化数据构成了网络上绝大多数可用数据,并且它每年都在增长。随着更多信息在网络上可用,并且大部分信息都是非结构化的,找到使用它的方法已成为许多企业的重要战略。更传统的数据分析工具和方法还不足以完成工作。
4.spark的应用场景
Spark 是一种与 Hadoop 相似的开源集群计算环境,是专为大规模数据处理而设计的快速通用的计算引擎,现已形成一个高速发展应用广泛的生态系统,主要应用场景如下:
1. Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小;
2. 由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合:
3. 数据量不是特别大,但是要求实时统计分析需求。
满足以上条件的均可采用Spark技术进行处理,在实际应用中,目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上,在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。
这些应用场景的普遍特点是计算量大、效率要求高,Spark恰恰可以满足这些要求,该项目一经推出便受到开源社区的广泛关注和好评,并在近两年内发展成为大数据处理领域炙手可热的开源项目。
5.Spark运行架构以及运行模式
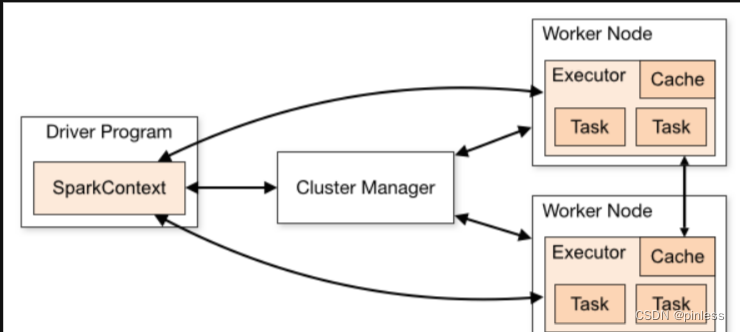
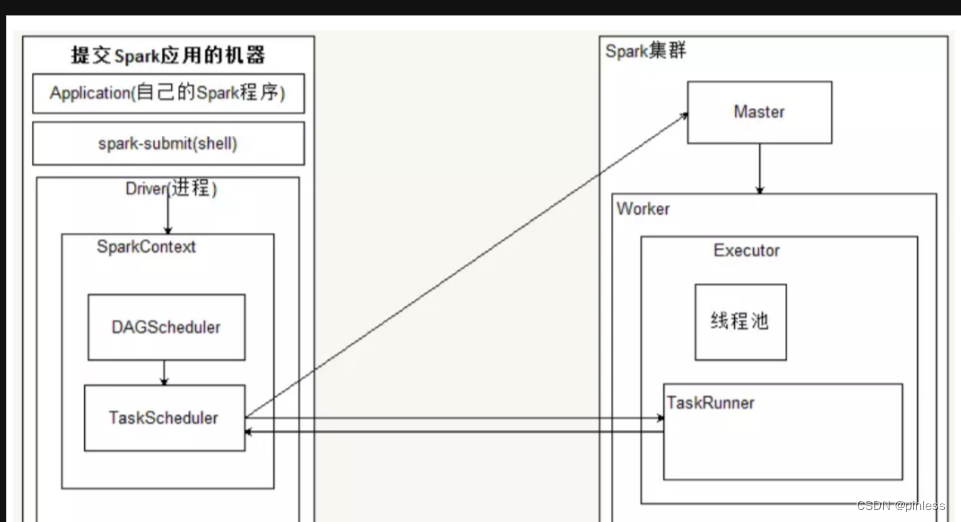
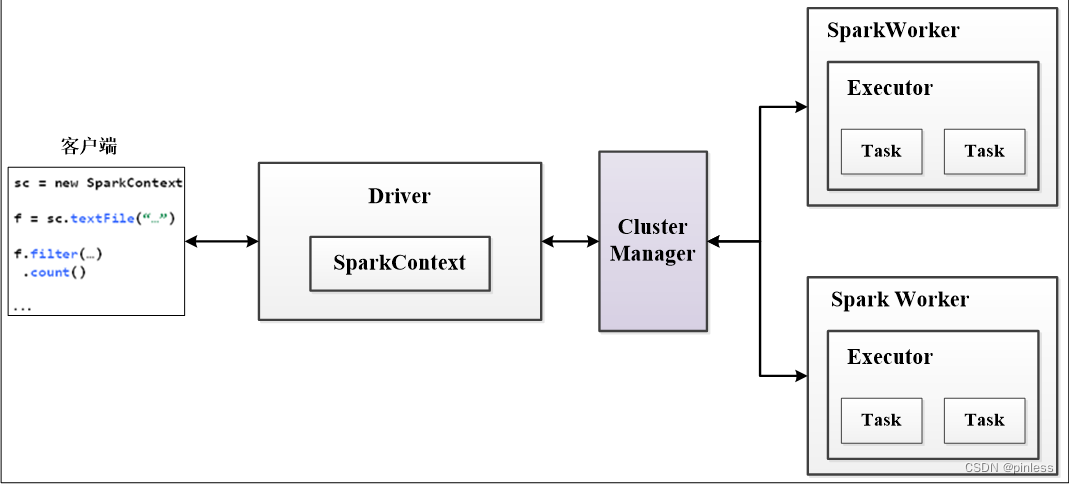
Spark框架的核心是一个计算引擎,整体来说,它采用了标准的master-slave的结构
图所示:展示了一个Spark执行时的基本架构,图中的Driver表示master,负责管理整个集群中的作业任务调度。图中的Executor则是slave,负责实际执行任务。
Local模式
Standalone模式的单机版,Master和Worker分别运行在一台机器的不同进程上
Standalone模式
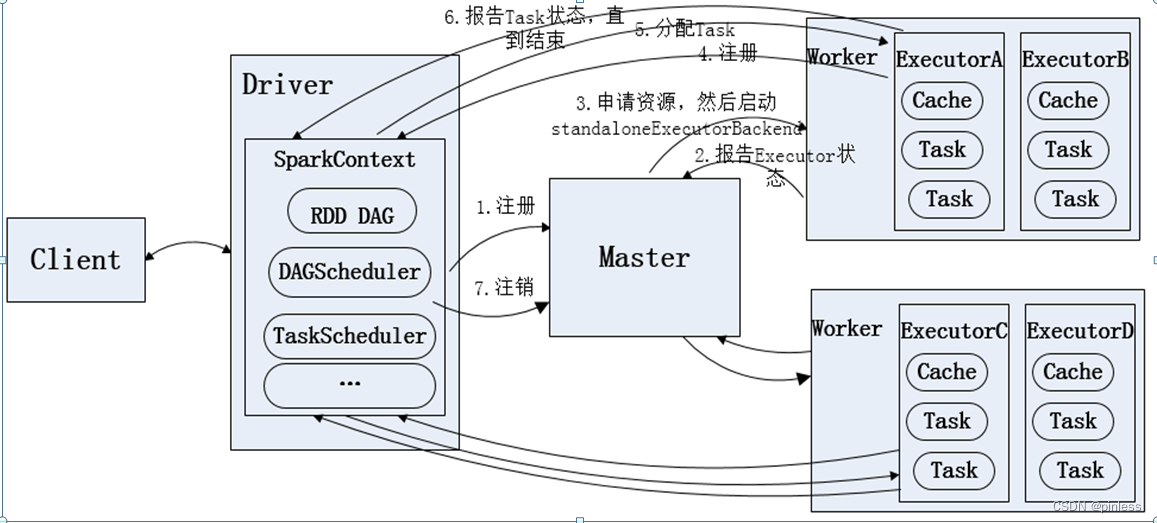
Standalone模式即独立模式,自带完整的服务,可以单独部署到一个集群中,不需要任何的资源管理系统,只支持FIFO调度,在该模式下没有AM和NM的概念,也没有RM的概念,用户节点直接与Master交互,由Driver负责向Master申请资源,由Driver进行资源的分配和调度等。目前Spark在Standalone模式下是没有任何单点故障问题的,借助了zk思想类似hbase Master单点故障解决方案。 各个节点上的资源被抽象成粗粒度的slot,有多少slot就能同时运行多少task。
Spark on Mesos模式
Spark on Mesos模式。在Spark on Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序(可参考Andrew Xia的“Mesos Scheduling Mode on Spark”)
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用5个executor运行你的应用程序,每个executor占用5GB内存和5个CPU,每个executor内部设置了5个slot,则Mesos需要先为executor分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,Mesos的Master和slave并不知道executor内部各个task的运行情况,executor直接将任务状态通过内部的通信机制汇报给Driver,从一定程度上可以认为,每个应用程序利用Mesos搭建了一个虚拟集群自己使用。
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark on Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,Mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
Spark on Yarn
当在Spark on Yarn模式下,每个Spark Executor作为一个Yarn Container在运行,同时支持多个任务在同一个Container中运行,极大地节省了任务的启动时间。在Spark中,有Yarn-Client和Yarn-cluster两种模式可以运行在Yarn上,下面是两种的区别
(1)SparkContext初始化不同,这也导致了Driver所在位置的不同,Yarn-Cluster的Driver是在集群的某一台NM上,Yarn-Client 的Driver运行在客户端
(2)而Driver会和Executors进行通信,这也导致了Yarn-Cluster在提交App之后可以关闭Client,而Yarn-Client不可以;
(3)最后再来说应用场景,Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。

standalone 作为 spark 自带的分布式部署模式,是最简单也是最基本的 spark 应用程序部署模式。
yarn 和 mesos 的区别:
(1) 就两种框架本身而言,mesos上可部署 yarn 框架。而 yarn 是更通用的一种部署框架,而且技术较成熟。
(2) mesos 双层调度机制,能支持多种调度模式,而 yarn 通过 Resource Mananger 管理集群资源,只能使用一种调度模式。Mesos 的双层调度机制为:mesos 可接入如 yarn 一般的分布式部署框架,但 Mesos 要求可接入的框架必须有一个调度器模块,该调度器负责框架内部的任务调度。当一个 Framework 想要接入 mesos 时,需要修改自己的调度器,以便向 mesos 注册,并获取 mesos 分配给自己的资源,这样再由自己的调度器将这些资源分配给框架中的任务,也就是说,整个 mesos 系统采用了双层调度框架:第一层,由 mesos 将资源分配给框架;第二层,框架自己的调度器将资源分配给自己内部的任务。
哥们就是说, 从 yarn 和 mesos 的区别可看出,它们各自有优缺点。因此实际使用中,选择哪种框架,要根据本公司的实际需要而定,可考虑现有的大数据生态环境。如我司采用 yarn 部署 spark,原因是,我司早已有较成熟的 hadoop 的框架,考虑到使用的方便性,采用了 yarn 模式的部署。
6.了解Spark核心数据集RDD
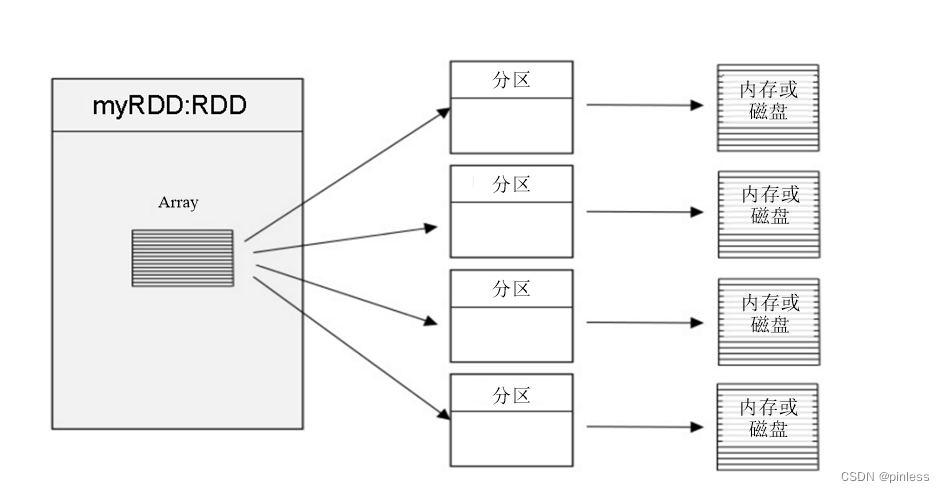
RDD(Resilient Distributed Datasets弹性分布式数据集),可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)。
(2).Spark RDD转换和操作示例

(3).了解Spark核心原理