
热门标签
热门文章
- 1npm 切换镜像后,npm i 安装依然卡,需要好久才完成_node设置淘宝镜像还是卡
- 2手机上python编程工具3和3h有区别吗_qpython3h编程 (python手机版)app下载_qpython3h编程 (python手机版) v3.0 安卓版 - D9下载站...
- 3iOS Crash收集与分析详解(基础篇)_crash收集机制
- 4springboot整合dubbo以后将zookeeper注册中心更换为nacos_dubbo zk 切换到nacos
- 5刷题统计-蓝桥杯真题-python解法_python蓝桥杯刷题统计
- 6五、C#归并排序算法
- 7Docker教程小白实操入门(21)--如何备份、恢复数据卷_将vo1数据卷的数据备份到宿主机的
- 8将 java 项目部署到 linux 上的具体步骤_怎么将java项目部署到linux上
- 9系统集成项目管理工程师第三版第六章要点笔记_系统集成项目管理工程师第6章重点内容
- 10Android SDK下载和更新失败的解决方法
当前位置: article > 正文
大模型机器人的爆发时刻:OpenAI参与打造的Figure 01——直接口头让机器人整理桌面_openai和figure机器人背后的技术原理是什么?
作者:不正经 | 2024-03-24 00:17:01
赞
踩
openai和figure机器人背后的技术原理是什么?
前言
一年多前,OpenAI重塑了聊天机器人,彻底推动大模型技术的突飞猛进,一个月前,OpenAI又重塑了视频生成,当sora的热度还在持续时,没想到OpenAI在机器人领域也出手了,和Figure联合打造的人形机器人,边与人类自然流畅对话、边干活(给人类苹果、整理桌面)
第一部分 Figure人形机器人
1.1 史无前例:Figure人形机器人的惊艳时刻
1.2 机器人与人类流畅对话并流畅干活背后的原理
Figure 的创始人 Brett Adcock 和 AI 团队的负责人 Corey Lynch 在 X 上解释了此次视频中机器人互动背后的原理
此次的突破,由 OpenAI 与 Figure 共同做出。OpenAI 提供负责提供视觉推理和语言理解,而 Figure 的神经网络提供快速、低水平、灵巧的机器人动作
机器人所做出的所有行为都是出于已经学习过,内化了的能力,而不是来自远程操作
整个流程为:图像 + speech to text =》VLM接收并做综合处理 =》NNP输出执行策略 =》 WBC执行策略且将VLM处理得到的response speak出来,具体则如下

- 研究人员将机器人摄像头中的图像输入(Figure 的机载摄像头以 10hz 的频率拍摄图像),和机载麦克风捕获的语音中的文本转录到由 OpenAI 训练的,可以理解图像和文本的多模态模型(VLM)中
由该VLM模型处理对话的整个历史记录,且对于接下来要采取什么动作干活已有大概的规划 - 然后通过Neural Network Policies细化「VLM给定的大概规划」,得到更具体的动作策略(决定在机器人上运行哪些学习到的闭环行为来完成给定的命令)
- 最后,一方面将特定的神经网络权重加载到 GPU 上并执行策略(相当于Whole body controller)
二方面 通过VLM处理得到的语言响应通过文本到语音的方式将其speak给人类
这也是为什么这个机器人,属于「端到端」的机器人控制。从语言输入开始,模型接管了一切处理,直接输出语言和行为结果,而不是中间输出一些结果,再加载其他程序处理这些结果
1.2.1 OpenAI的VLM模型:理解环境 + 人类的口头任务 + 基本的常识和上下文记忆能力
OpenAI 的模型的多模态能力,是机器人可以与世界交互的关键,我们能够从视频中展示中看到许多类似的瞬间,比如:
- 描述一下它的周围环境
- 做出决定时使用常识推理。例如,「桌子上的盘子和杯子等餐具接下来很可能会进入晾衣架」
- 比如在视频中,当人说“我饿了”,Figure思考了2-3秒后(因为语音识别、大语言模型、TTS是通过pipeline方式连起来的,都需要计算时间),小心翼翼地伸手抓住苹果,并迅速给人递过来
因为Figure基于大语言模型的常识,明白苹果是它面前唯一可以“吃”的事物,在人类没有任何提示和说明的前提下,即可以接近于人类的反应速度,与人自然交互
相当于有了大模型的支持,让该机器人具备了一定的常识 - 比如视频中展示的「你能把它们放在那里吗?」「它们」指的是什么?「那里」又在哪里?正确回答需要反思记忆的能力(能够拥有短期记忆的背后得益于大模型的长上下文的理解能力,使得可以精准抓取长上下文里的指代关系)
1.2.2 机器人操控小模型(类似Google的RT-1):输出action
而具体的双手动作,可以分成两步来理解:
- 首先,互联网预训练模型对图像和文本进行常识推理,以得出高级计划。如视频中展示的:Figure 的人形机器人快速形成了两个计划:
1)将杯子放在碗碟架上,2)将盘子放在碗碟架上 - 其次,一个基于neutral network的机器人操控小模型以 200hz 的频率(RT-2论文里提到的决策频率则只有1到5hz)生成的 24-DOF 动作(手腕姿势和手指关节角度),充当高速「设定点(setpoint)」,供更高速率的全身控制器跟踪。全身控制器确保安全、稳定的动力,如保持平衡
所有行为均由Transformer 策略驱动(比如mobile aloha所用过的ACT算法,本质是一个模仿学习),将像素直接映射到动作
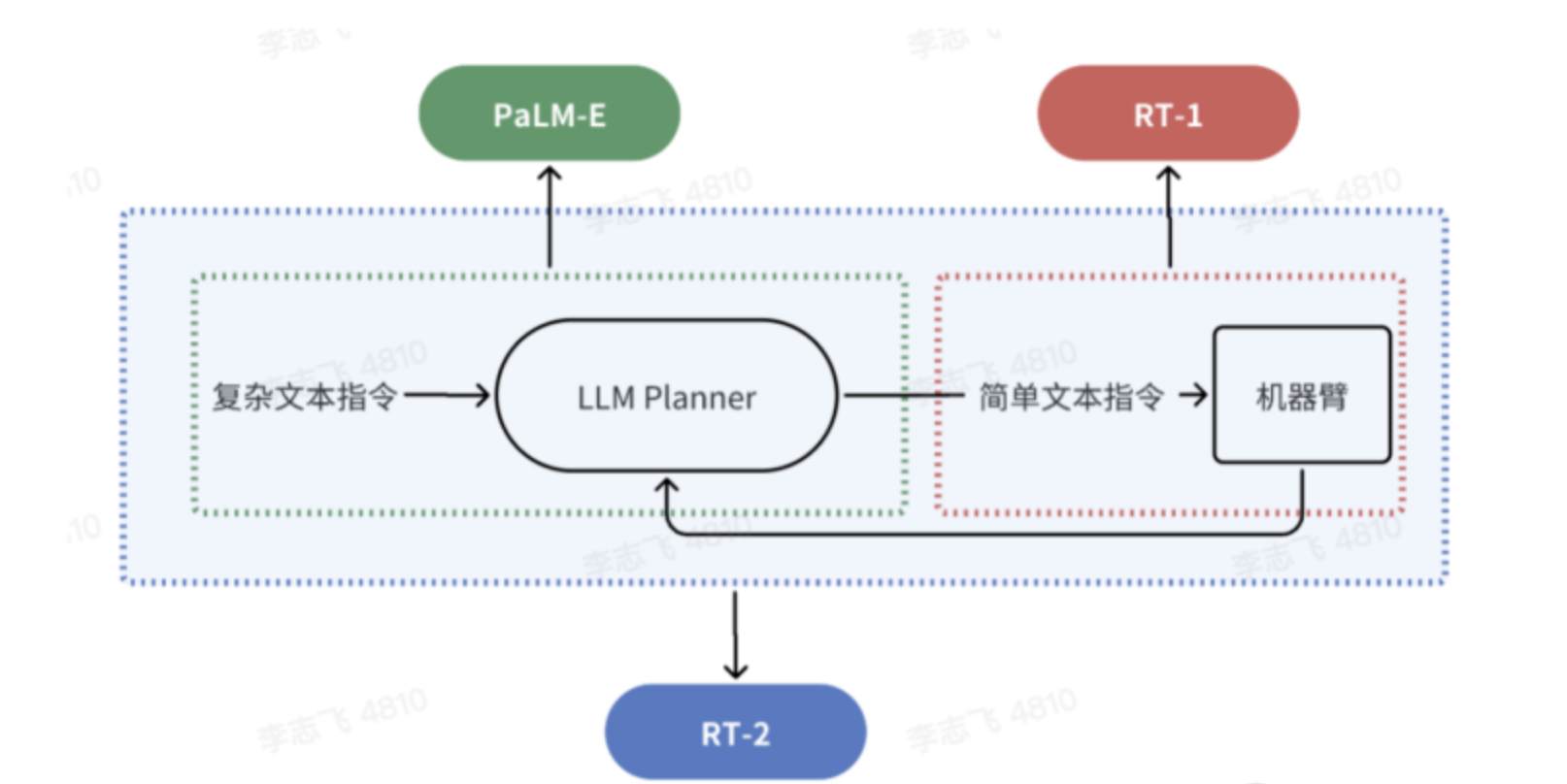
出门问问的李志飞认为
- Figure 01的整个框架类似于PaLM-E和RT-1的pipeline组合,即分两步:多模态模型把复杂的自然语言指令分解为简单指令后,继而调用机器人的操控系统(类似Google的RT-1)执行相应的动作
- 而非RT-2,因为RT-2中间不再需要将其转化成简单指令,通过自然语言就可得到最终的 Action,算是一个 VLA(Vision-Language-Action Model)模型
相当于RT-2全程就一个模型,但Figure 01还是组合了OpenAI的VLM + Figure公司的机器人操控小模型
RT-2的好处在于做到了真正的端到端 根据输入直接得到输出action(没有Figure 01中的机器人操控小模型),坏处是执行速度有限,故没法做到200hz的决策速度
参考文献与推荐阅读
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/298623
推荐阅读

相关标签

