
- 1自然语言处理相关工具调研_基于情感词典的方法和工具有哪些
- 2【损失函数】(一) L1Loss原理 & pytorch代码解析_pytorch l1 loss
- 323种设计模式-- 思路分析+代码实现_设计一个类,文字描述设计思路,并转化为代码在主函数中实现
- 4Linux(CentOS-7)-全面详解(学习总结---从入门到深化)_centos7
- 5Web 前端性能优化之三:加载优化
- 6K8s 超详细总结!
- 7过拟合的原因以及解决办法(深度学习)_matlab训练神经网络过拟合原因
- 8【Pytorch神经网络理论篇】 37 常用文本处理工具:spaCy库+torchtext库
- 9阿里云服务器镜像和快照区别对比
- 10机器学习与ML.NET–NLP与BERT_net nlp
(DSTT)Decoupled Spatial-Temporal Transformer for Video Inpainting_frequency-aware spatiotemporal transformers for vi
赞
踩
Abstract
Video inpainting aims to fill the given spatiotemporal holes with realistic appearance but is still a challenging task even with prosperous deep learning approaches. Recent works introduce the promising Transformer architecture into deep video inpainting and achieve better performance. However, it still suffers from synthesizing blurry texture as well as huge computational cost. Towards this end, we propose a novel Decoupled Spatial-Temporal Transformer (DSTT) for improving video inpainting with exceptional efficiency. Our proposed DSTT disentangles the task of learning spatial-temporal attention into 2 sub-tasks:
1、one is for attending temporal object movements on different frames at same spatial locations, which is achieved by temporally decoupled Transformer block,
2、and the other is for attending similar background textures on same frame of all spatial positions, which is achieved by spatially decoupled Transformer block.
The interweaving stack of such two blocks makes our proposed model attend background textures and moving objects more precisely, and thus the attended plausible and temporally-coherent appearance can be propagated to fill the holes. In addition, a hierarchical encoder is adopted before the stack of Transformer blocks, for learning robust and hierarchical features that maintain multi-level local spatial structure, resulting in the more representative token vectors. Seamless combination of these two novel designs forms a better spatial-temporal attention scheme and our proposed model achieves better performance than state-of-the art video inpainting approaches with significant boosted efficiency. Training code and pretrained models are available at https://github.com/ruiliu-ai/DSTT.
视频修复旨在用逼真的外观填补给定的时空空洞,我们提出了一种新颖的解耦时空转换器(DSTT)【为了解决合成模糊纹理以及巨大的计算成本】来提高视频修复的效率。
我们提出的DSTT将学习时空注意的任务分解为两个子任务:
1、一个是在相同空间位置的不同帧上关注时间对象运动,这是通过时间解耦的Transformer块实现的,
2、另一个是在所有空间位置的相同帧上关注相似的背景纹理,这是通过空间解耦的Transformer块实现的。
这两个块的交织堆叠使得我们提出的模型能够更精确地处理背景纹理和运动对象,从而可以传播所处理的似是而非且时间连贯的外观来填充孔洞。此外,在Transformer块的堆叠之前采用了分层编码器,用于学习保持多级局部空间结构的健壮和分层特征,从而产生更具代表性的令牌向量。这两种新颖设计的无缝结合形成了更好的时空注意力方案。
1. Introduction
Although deep learning-based image inpainting approaches have made great progress, processing videos frame-by-frame can hardly generate videos with temporal consistency. Some other works used propagation-based methods to align and propagate temporally-consistent visual contents to obtain more vivid inpainting results [33, 10]. However, they usually fail when faced with occluded stationary backgrounds. End-to-end training a deep generative model for video inpainting and performing direct inference has drawn great attention in recent years.
虽然基于深度学习的图像修复方法已经取得了很大的进展[13,34,35],但是逐帧处理视频很难生成具有时间一致性的视频。其他一些作品使用基于传播的方法来对齐和传播时间一致的视觉内容,以获得更生动的修复结果[33,10]。然而,当面对被遮挡的静止背景时,它们通常会失败。端到端训练一种用于视频修复和执行直接推理的深度生成模型近年来引起了极大的关注。

Figure 2. Illustration of the attention maps for missing regions learned by STTN [36] and the proposed DSTT at the first Transformer block. Red lines indicate the attention map of target hole patch on other reference frames. Orange lines indicate the scheme of temporal decoupling that splits frame into 4 zones. With such spatial splitting operation, the self-attention module calculates the attention score among tokens from the same zone of different frames, making this task easier. Therefore, our method can attend occluded object on other reference frames and propagate its appearance to fill the hole more precisely.
These methods, however, usually yield blurry videos by using 3D convolution [29, 5, 4]. Very recently, attention mechanisms are adopted to further promote both realism and temporal consistency via capturing long-range correspondences. Temporally-consistent appearance is implicitly learned and propagated to the target frame via either frame-level attention [23] or patch-level attention [36]. These methods improve video inpainting performance to a great extent, yet still suffer from the following shortcomings:
1、On the one hand, processing spatial-temporal information propagation with self-attention modules is challenging in complex scenarios, for example, the arbitrary object movement (see Fig. 2). A camel is occluded for some frames and appears at some other frames, but the previous method [36] can not attend and propagate it precisely.
2、On the other hand, Transformer-based attention inevitably brings huge computational cost, hindering its usage in real world applications.
然而,这些方法通常通过使用3D卷积产生模糊的视频[29,5,4]。最近,注意力机制被用来通过捕捉远程对应来进一步促进真实感和时间一致性。时间一致的外观通过帧级注意[23]或补丁级注意[36]被隐含地学习并传播到目标帧。这些方法在很大程度上提高了视频修复性能,但仍然存在以下缺点:
一方面,在复杂场景下,例如任意对象移动(见图2),用自关注模块处理时空信息传播具有挑战性。骆驼在某些帧中被遮挡,而在另一些帧中出现,但是以前的方法不能精确地关注和传播它。另一方面,基于Transformer的注意力不可避免地带来巨大的计算成本,阻碍了它在现实世界应用中的使用。
To tackle the challenges, we propose the decoupled spatial-temporal Transformer (DSTT) framework for video inpainting with an interweaving stack of temporally decoupled and spatially-decoupled Transformer blocks. Specifically, following STTN [36],
1、we first extract the downsampled feature maps and embed this feature map into many spatiotemporal token vectors with a convolution based encoder.(首先提取下采样的特征图并将这些特征图嵌入到时空token vectors中)
2、Then the obtained spatiotemporal tokens pass through a stack of Transformer blocks for thorough spatial-temporal propagation.(然后再经过一系列的Transformer blocks)
Different from the Transformer block in STTN that simultaneously processes spatial-temporal propagation, we decouple the spatial propagation and temporal propagation into 2 different Transformer blocks.(将空间传播和时间传播解耦为两个不同的Transformer块)
①、In temporally-decoupled Transformer block, the obtained tokens are spatially divided into multiple zones, and the model calculates the attention between tokens from different frames’ same zone, which is used to model temporal object movement.(在时间解耦的Transformer块中,所获得的tokens在空间上被划分为多个区域,并且该模型计算来自不同帧的相同区域的tokens之间的关注度,该注意力用于建模时间对象运动。)
②、By contrast, in spatially decoupled Transformer block, the model calculates the attention between all tokens from the same frame. This is designed for modelling the stationary background texture in the same frame.(相比之下,在空间解耦的Transformer块中,模型计算来自同一帧的所有tokens之间的注意力。这是为模拟同一帧中的静止背景纹理而设计的。)
These two different Transformer blocks are stacked in an interweaving manner such that all spatial temporal pixels can be interacted with each other, leading to thorough spatial-temporal searching and propagation. Meanwhile, this spatial-temporal operation becomes much easier after this decoupling scheme, resulting in better video inpainting performance, as shown in Fig. 2. Not only can the occluded object be displayed, but also more coherent texture can be synthesized.(这两个不同的Transformer块以交织的方式堆叠,使得所有的空间时间像素可以相互作用,导致彻底的时空搜索和传播。同时,在这种解耦方案之后,这种时空操作变得容易得多,导致更好的视频修复性能,如图2所示。不仅可以显示被遮挡的物体,还可以合成更加连贯的纹理。)
Although an effective and efficient way is provided for thorough spatiotemporal propagation, learning representative and robust feature representation before entering the Transformer blocks is still significant. Because roughly separating image into many patches and squeezing them into token vectors like ViT [7] is not a good way to dealing with low-level vision tasks due to the requirement of maintaining spatial structure. Therefore we also design a hierarchical CNN-based encoder for making the extracted feature maps maintain multi-level local spatial structure. By mixing feature maps from various levels that possess different sizes of receptive fields, the characteristics of obtained feature maps vary from channel to channel, which is beneficial to reaching information interaction along spatial and temporal dimension in following Transformer blocks.(尽管为彻底的时空传播提供了一种有效且高效的方式,但是在进入Transformer块之前学习代表性且健壮的特征表示仍然是重要的。因为由于保持空间结构的要求,粗略地将图像分成许多小块,并将其压缩成像ViT [7]这样的token vector,并不是处理低级视觉任务的好方法。因此,我们还设计了一个基于分层CNN的编码器,使提取的特征图保持多层次的局部空间结构。通过混合具有不同感受野大小的不同层次的特征图,所获得的特征图的特征因通道而异,这有利于在随后的Transformer块中实现沿空间和时间维度的信息交互。)
In summary:
• We propose a novel decoupled spatial-temporal Transformer (DSTT) framework for video inpainting to improve video inpainting quality with higher running efficiency, by disentangling the task of spatial-temporal propagation into 2 easier sub-tasks. A hierarchical encoder is also introduced for capturing robust and representative features. The seamless combination of decoupled spatial-temporal Transformer and hierarchical encoder benefits video inpainting performance a lot.(我们提出了一种新颖的解耦时空转换器(DSTT)视频修复框架,通过将时空传播任务分解为两个更简单的子任务,以更高的运行效率提高视频修复质量。还引入了分级编码器,用于捕获健壮和有代表性的特征。解耦时空转换器和分层编码器的无缝结合极大地提高了视频修复性能。)
3. Method
Video inpainting targets at filling a corrupted video sequence with plausible contents and smooth pixel flows.
Let = {X1 , X2 , . . . , Xt} denote a corrupted video sequence with length t【
表示长度为t的待修复的视频】
where means the i-th frame of this video sequence.【
表示待修复的视频的第i祯】
We aim to learn a mapping function that takes the corrupted video as input and outputs a realistic video
.【
代表待修复视频
对应的完好视频】
However, there is usually no ground truth provided for training in real scenarios. We therefore formulate this problem as a self-supervised learning framework by randomly corrupting an original videos with a randomly generated mask sequence
, i.e.,
where \(\odot \\) denotes element-wise multiplication.【\(\odot \\) 代表逐像素相乘】 is a binary mask whose values are either 0 referring to the original regions or 1 meaning the corrupted regions that need filling.【
是待修复视频对应的二进制mask,其中0代表原始区域,1代表待修复的损坏视频】
Our goal is thus to learn a mapping for reconstructing the original videos, i.e.,
, benefited from which a huge quantity of natural videos can be used for training our framework.

Figure 3. The illustration of proposed framework which is composed of a hierarchical encoder and a stack of decoupled temporal-spatial Transformer blocks, for improving its effectiveness and efficiency. In hierarchical encoder, features of different levels are represented as different colors. The higher the level of feature is, the darker its color is. With such hierarchical grouping processing, the local spatial structures of difference levels are stored in the final robust and representative features.
The overall framework of our proposed method is illustrated in Fig. 3.
Given a corrupted video sequence with its corresponding mask sequence, individual frames are first input into a frame-based hierarchical encoder for downsampling and embedding into spatial-temporal token vectors. With such hierarchical channel-mixing encoder, the robust and representative feature maps are extracted from the input video clip.
After that, we feed the obtained tokens into an interweaving stack of Decoupled Spatial-Temporal Transformer (DSTT) for fully aggregating information across tokens of different frames.
At last, these processed tokens are transformed by a frame-based CNN decoder and synthesize the final frames, composing the inpainted video.
The overall generator G can thus be formulated as:
3.1. Hierarchical Encoder
To achieve this, we propose a novel hierarchical encoder (HE) that mixes the feature maps from different levels frame by frame, to produce tokens containing rich information for each frame.【hierarchical encoder (HE),它逐帧混合来自不同层次的特征图,为每一帧产生包含丰富信息的token】
Specifically, given an input image four cascaded convolutions with kernel size 3, 3, 3, 3 and stride 2, 1, 2, 1 make it a down-sampled feature map
. Starting from this feature, we establish our hierarchical structure for multi-level channel mixing, as shown in Fig. 3.
We name the feature map as the first-level feature map for clearly illustrating our hierarchical structure.【
是一级特征图】
It first passes through a convolution layer with kernel size 3 × 3 to obtain the second-level feature map whose shape is consistent with first-level feature map while possessing a larger receptive field, i.e., a larger local spatial structure. It is then concatenated with the first-level one, having the feature map
that include both first-level and second-level local spatial structure.【二级特征图与一级特征图有一样的形状,且有较大的感受野,串联了一级特征图的二级特征图的既包含了一级又包含了二级的局部空间信息】
Then at each layer of our hierarchical encoder, all different-level features will go into next-level, with growing larger receptive field and a first-level feature is always concatenated to the hierarchical feature map. This process is formulated as
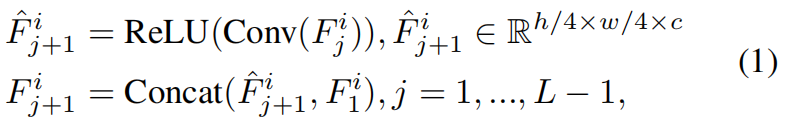
where Conv denotes a regular convolution operation with kernel size 3 × 3, ReLU denotes the Rectified Linear Unit for modelling non-linear transformation, Concat denotes the concatenation along channel dimension and denotes the total number of hierarchical layers. We empirically set L = 4 for our final model .
With this processing, the finally obtained feature map will include multi-level (from first-level to L-th level) local spatial structures of the input image, thus leading to robust and representative feature maps, which is beneficial to the follow-up general patch-level spatial-temporal aggregation. To further maintain the original local spatial structure, we adopt a group convolution at each layer to separately process feature refinement for various levels. Since the highest-level feature always has least channels, we correspondingly set the number of groups at j-th layer to , which avoids feature fusion in the intermediate layers and hence the original local spatial structure at all different levels brings into the last output feature.(通过这种处理,最终获得的特征图将包括输入图像的多级(从第一级到第L级)局部空间结构,从而产生鲁棒和有代表性的特征图,这有利于后续的patch聚集。为了进一步保持原有的局部空间结构,我们在每一层采用一组卷积来分别对不同层次进行特征细化。由于最高层的特征总是具有最少的通道,因此我们相应地将第j层的组数设置为,这避免了中间层的特征融合,从而将所有不同层的原始局部空间结构带入最后的输出特征。 )
After L times recursion, the processed feature would be embedded with a convolution layer with kernel size 7 × 7 and stride 3 × 3 to obtain the final output token feature representation
3.2. Decoupled Spatial Temporal Transformer
Different from STTN [36] that simultaneously processes spatial and temporal propagation, we disentangle this challenging task into 2 easier tasks:
1、a temporally-decoupled Transformer block for searching and propagating features from smaller spatial zone along temporal dimension(时间解耦的Transformer块,用于沿时间维度从较小的空间区域搜索和传播特征)
2、and a spatially-decoupled Transformer block for searching and propagating features from the whole spatial zone without other frames.(空间解耦的Transformer块,用于在没有其他帧的情况下从整个空间区域搜索和传播特征。)
Two such blocks are stacked for reaching arbitrary pixels across all the spatial-temporal positions.
Specifically, given the token feature ,【
:token feature】
we split it into zones along both the height and width dimension where each zone of
is denoted as
where j, k = 1, . . . , s.【
被分为
个地区,每个地区表示为
】
So far we have a total number of tokens where
. We then take 2 different ways to grouping these tokens together.
①、One way is to group them together along temporal dimension, i.e., ,
so that temporally-decoupled Transformer block takes each
as input and performs multi-head self-attention across tokens in it. By doing so, continuous movement of complex object in a small spatial zone can be detected and propagated into target hole regions.
②、Another way is to gather them along spatial dimension , t so that spatially-decoupled Transformer block takes each
as input and performs multi-head self-attention across tokens in it. This helps the model detect similar background textures in the spatially-neighboring pixels and propagate these textures to target hole regions to achieve coherent completion.
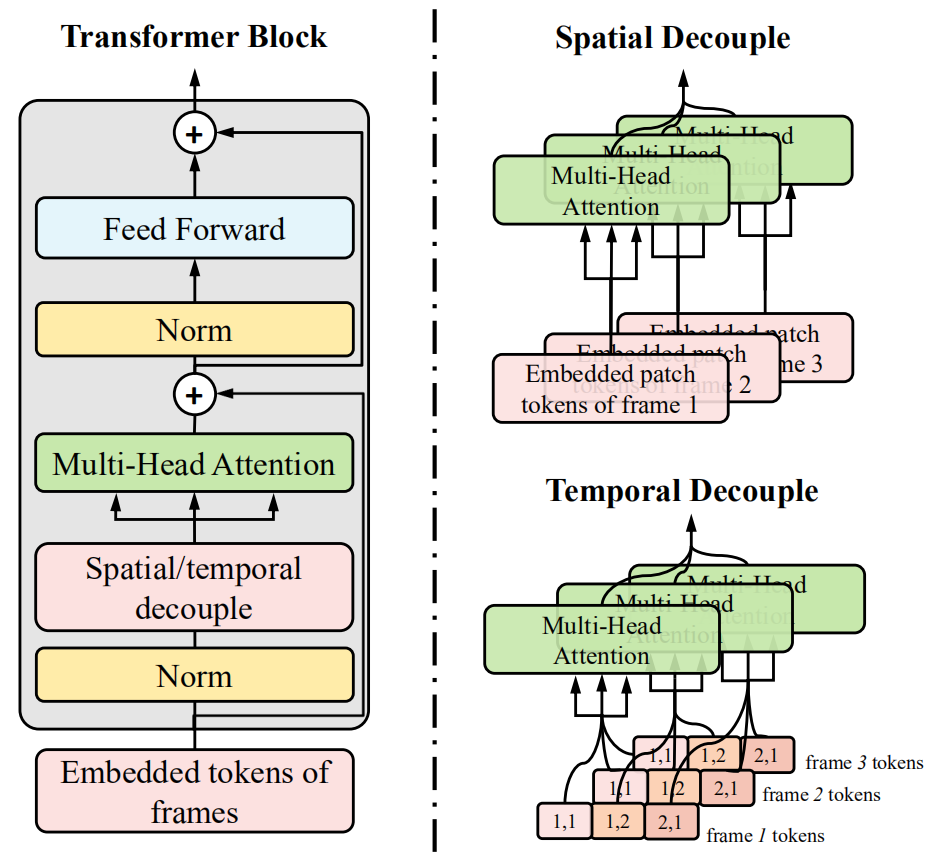
Figure 4. The illustration of a block of the proposed Decoupled Spatial Temporal Transformer (DSTT). A Transformer block consists a decoupled spatial/temporal MSA and a vanilla feed forward net.
Two different ways are illustrated clearly as in Fig. 4. Both of temporally-decoupled and spatially-decoupled self-attention modules are followed by a vanilla feed forward network, composing two different Transformer blocks, which is formulated as:
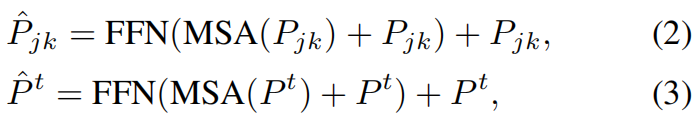
where the former equation stands for the temporally-decoupled Transformer block and the latter stands for the spatially-decoupled Transformer block. FFN denotes the vanilla feed forward (FFN:最原始的前向传播网络)net and MSA denotes multi-head self-attention module. Note that the mechanism of temporally-decoupled MSA and spatially-decoupled MSA are same, only their inputs vary in different grouping ways and thus different searching zones.
By doing so, we significantly reduce the computational complexity of MSA from into
(temporally-decoupled MSA) and
(spatially-decoupled MSA). Although t = 5 is chosen during training, using a larger t during inference will produce videos with much better visual quality and temporal consistency. So the inference speed is boosted to a great extent. Following STTN [36], we set the number of all stacked Transformer blocks to 8. As for the stacking strategy, we empirically make a temporally-decoupled block followed by a spatially-decoupled block and repeat this for 4 times.
3.3. Optimization Objective
As outlined above, we end-to-end train our DSTT framework in a self-supervised manner. After passing through the generator G introduced above, we abtain the inpainted video sequence .
For constraining the synthesized video to recover the original video
, we firstly choose a simple pixel-level reconstruction loss L1 between them as our supervision. Note that the L1 for valid region and hole region may be of distinct importance so we calculate them separately. The reconstruction loss for hole region is formulated as:
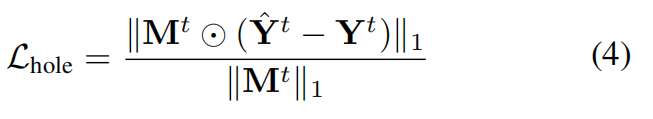
and the reconstruction loss for valid region is formulated as:
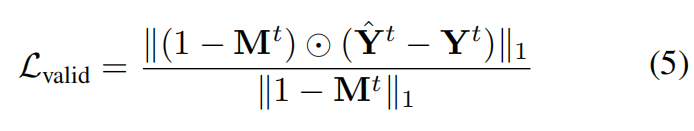
where ⨀
In addition, to enhance the realism and temporal coherence of the generated video, we adopt a similar structure of Temporal Patch Generative Adversarial Network (TPatchGAN) [4] as our discriminator D, for training with the generator in an adversarial manner. The discriminator attempts to distinguish the generated videos from real ones, while the generator attempts to synthesize a video that would be categorized into “real” by the discriminator D. So the adversarial loss for D is as:
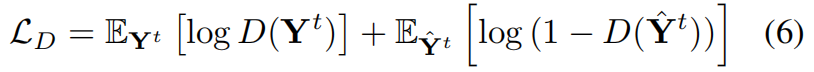
Contrarily the adversarial loss for G is the opposite direction:
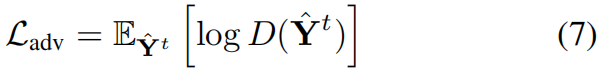
To sum up, our fifinal optimization objective for G is:
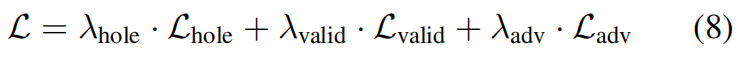
where λhole, λvalid and λadv are hyper-parameters weighing importance for different terms. We empirically set λhole to 1, λvalid to 1 and λadv to 0.01 for following experiments.

