
- 1Python数值方程根_python输出实根
- 2前端理论总结(css3)——link/import区别 // 伪类/伪元素
- 3pythoniris补全缺失值_5.4 缺失值插补
- 4NLTK下载错误的终极解决办法_[nltk_data] downloading package averaged_perceptro
- 5Mybatis的<where>,<if>等标签用法
- 6深度学习中的一些常见的激活函数集合(含公式与导数的推导)sigmoid, relu, leaky relu, elu, numpy实现_numpy leakyrelu
- 7深入理解Android之Java Security第一部分_get /assets/index.d9b61ab0.js http/1.1
- 8win7安装VMware Player+os x 10.10 +xcode7.2_vmware player 安装xcode
- 9Peft库实战(一):Lora微调bert(文本情感分类)_peft库实战(一):lora微调bert(文本情感分类)
- 10ChatGPT 商业金矿(下)
07蚂蚁-高并发解决方案——1.Hystrix服务降级,服务隔离,服务熔断,服务限流,CDN_hystrix配置错误导致高并发场景下gateway网关调用其他服务时迅速被降级
赞
踩
高并发服务降级特技
背景
在今天,基于SOA的架构已经大行其道。伴随着架构的SOA化,相关联的服务熔断、降级、限流等思想,也在各种技术讲座中频繁出现。本文将结合Netflix开源的Hystrix框架,对这些思想做一个梳理。
伴随着业务复杂性的提高,系统的不断拆分,一个面向用户端的API,其内部的RPC调用层层嵌套,调用链条可能会非常长。这会造成以下几个问题:
API接口可用性降低
引用Hystrix官方的一个例子,假设tomcat对外提供的一个application,其内部依赖了30个服务,每个服务的可用性都很高,为99.99%。那整个applicatiion的可用性就是:99.99%的30次方 = 99.7%,即0.3%的失败率。
这也就意味着,每1亿个请求,有30万个失败;按时间来算,就是每个月的故障时间超过2小时。
服务熔断
为了解决上述问题,服务熔断的思想被提出来。类似现实世界中的“保险丝“,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时。
熔断的触发条件可以依据不同的场景有所不同,比如统计一个时间窗口内失败的调用次数。
服务降级
有了熔断,就得有降级。所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。
这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当然这也要看适合的业务场景。
关于Hystrix中fallback的使用,此处不详述,参见官网。
项目搭建
需求:搭建一套分布式rpc远程通讯案例:比如订单服务调用会员服务实现服务隔离,防止雪崩效应案例
订单工程
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.0.RELEASE</version> </parent> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> <dependency> <groupId>com.netflix.hystrix</groupId> <artifactId>hystrix-metrics-event-stream</artifactId> <version>1.5.12</version> </dependency> <dependency> <groupId>com.netflix.hystrix</groupId> <artifactId>hystrix-javanica</artifactId> <version>1.5.12</version> </dependency> </dependencies>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
@RestController @RequestMapping("/order") public class OrderController { @Autowired private MemberService memberService; @RequestMapping("/orderIndex") public Object orderIndex() throws InterruptedException { JSONObject member = memberService.getMember(); System.out.println("当前线程名称:" + Thread.currentThread().getName() + ",订单服务调用会员服务:member:" + member); return member; } @RequestMapping("/orderIndexHystrix") public Object orderIndexHystrix() throws InterruptedException { return new OrderHystrixCommand(memberService).execute(); } @RequestMapping("/orderIndexHystrix2") public Object orderIndexHystrix2() throws InterruptedException { return new OrderHystrixCommand2(memberService).execute(); } @RequestMapping("/findOrderIndex") public Object findIndex() { System.out.println("当前线程:" + Thread.currentThread().getName() + ",findOrderIndex"); return "findOrderIndex"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
@RestController @RequestMapping("/order") public class OrderController { @Autowired private MemberService memberService; @RequestMapping("/orderIndex") public Object orderIndex() throws InterruptedException { JSONObject member = memberService.getMember(); System.out.println("当前线程名称:" + Thread.currentThread().getName() + ",订单服务调用会员服务:member:" + member); return member; } @RequestMapping("/orderIndexHystrix") public Object orderIndexHystrix() throws InterruptedException { return new OrderHystrixCommand(memberService).execute(); } @RequestMapping("/orderIndexHystrix2") public Object orderIndexHystrix2() throws InterruptedException { return new OrderHystrixCommand2(memberService).execute(); } @RequestMapping("/findOrderIndex") public Object findIndex() { System.out.println("当前线程:" + Thread.currentThread().getName() + ",findOrderIndex"); return "findOrderIndex"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
@Service
public class MemberService {
public JSONObject getMember() {
JSONObject result = HttpClientUtils.httpGet("http://127.0.0.1:8081/member/memberIndex");
return result;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
public class HttpClientUtils { private static Logger logger = LoggerFactory.getLogger(HttpClientUtils.class); // 日志记录 private static RequestConfig requestConfig = null; static { // 设置请求和传输超时时间 requestConfig = RequestConfig.custom().setSocketTimeout(2000).setConnectTimeout(2000).build(); } /** * post请求传输json参数 * * @param url * url地址 * @param json * 参数 * @return */ public static JSONObject httpPost(String url, JSONObject jsonParam) { // post请求返回结果 CloseableHttpClient httpClient = HttpClients.createDefault(); JSONObject jsonResult = null; HttpPost httpPost = new HttpPost(url); // 设置请求和传输超时时间 httpPost.setConfig(requestConfig); try { if (null != jsonParam) { // 解决中文乱码问题 StringEntity entity = new StringEntity(jsonParam.toString(), "utf-8"); entity.setContentEncoding("UTF-8"); entity.setContentType("application/json"); httpPost.setEntity(entity); } CloseableHttpResponse result = httpClient.execute(httpPost); // 请求发送成功,并得到响应 if (result.getStatusLine().getStatusCode() == HttpStatus.SC_OK) { String str = ""; try { // 读取服务器返回过来的json字符串数据 str = EntityUtils.toString(result.getEntity(), "utf-8"); // 把json字符串转换成json对象 jsonResult = JSONObject.parseObject(str); } catch (Exception e) { logger.error("post请求提交失败:" + url, e); } } } catch (IOException e) { logger.error("post请求提交失败:" + url, e); } finally { httpPost.releaseConnection(); } return jsonResult; } /** * post请求传输String参数 例如:name=Jack&sex=1&type=2 * Content-type:application/x-www-form-urlencoded * * @param url * url地址 * @param strParam * 参数 * @return */ public static JSONObject httpPost(String url, String strParam) { // post请求返回结果 CloseableHttpClient httpClient = HttpClients.createDefault(); JSONObject jsonResult = null; HttpPost httpPost = new HttpPost(url); httpPost.setConfig(requestConfig); try { if (null != strParam) { // 解决中文乱码问题 StringEntity entity = new StringEntity(strParam, "utf-8"); entity.setContentEncoding("UTF-8"); entity.setContentType("application/x-www-form-urlencoded"); httpPost.setEntity(entity); } CloseableHttpResponse result = httpClient.execute(httpPost); // 请求发送成功,并得到响应 if (result.getStatusLine().getStatusCode() == HttpStatus.SC_OK) { String str = ""; try { // 读取服务器返回过来的json字符串数据 str = EntityUtils.toString(result.getEntity(), "utf-8"); // 把json字符串转换成json对象 jsonResult = JSONObject.parseObject(str); } catch (Exception e) { logger.error("post请求提交失败:" + url, e); } } } catch (IOException e) { logger.error("post请求提交失败:" + url, e); } finally { httpPost.releaseConnection(); } return jsonResult; } /** * 发送get请求 * * @param url * 路径 * @return */ public static JSONObject httpGet(String url) { // get请求返回结果 JSONObject jsonResult = null; CloseableHttpClient client = HttpClients.createDefault(); // 发送get请求 HttpGet request = new HttpGet(url); request.setConfig(requestConfig); try { CloseableHttpResponse response = client.execute(request); // 请求发送成功,并得到响应 if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) { // 读取服务器返回过来的json字符串数据 HttpEntity entity = response.getEntity(); String strResult = EntityUtils.toString(entity, "utf-8"); // 把json字符串转换成json对象 jsonResult = JSONObject.parseObject(strResult); } else { logger.error("get请求提交失败:" + url); } } catch (IOException e) { logger.error("get请求提交失败:" + url, e); } finally { request.releaseConnection(); } return jsonResult; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
会员工程
@RestController
@RequestMapping("/member")
public class MemberController {
@RequestMapping("/memberIndex")
public Object memberIndex() throws InterruptedException {
Map<String, Object> hashMap = new HashMap<String, Object>();
hashMap.put("code", 200);
hashMap.put("msg", "memberIndex");
Thread.sleep(1500);
return hashMap;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Hystrix简介
使用Hystrix实现服务隔离
Hystrix 是一个微服务关于服务保护的框架,是Netflix开源的一款针对分布式系统的延迟和容错解决框架,目的是用来隔离分布式服务故障。它提供线程和信号量隔离,以减少不同服务之间资源竞争带来的相互影响;提供优雅降级机制;提供熔断机制使得服务可以快速失败,而不是一直阻塞等待服务响应,并能从中快速恢复。Hystrix通过这些机制来阻止级联失败并保证系统弹性、可用。
什么是服务隔离
当大多数人在使用Tomcat时,多个HTTP服务会共享一个线程池,假设其中一个HTTP服务访问的数据库响应非常慢,这将造成服务响应时间延迟增加,大多数线程阻塞等待数据响应返回,导致整个Tomcat线程池都被该服务占用,甚至拖垮整个Tomcat。因此,如果我们能把不同HTTP服务隔离到不同的线程池,则某个HTTP服务的线程池满了也不会对其他服务造成灾难性故障。这就需要线程隔离或者信号量隔离来实现了。
使用线程隔离或信号隔离的目的是为不同的服务分配一定的资源,当自己的资源用完,直接返回失败而不是占用别人的资源。
Hystrix实现服务隔离两种方案
Hystrix的资源隔离策略有两种,分别为:线程池和信号量。
线程池方式
1、 使用线程池隔离可以完全隔离第三方应用,请求线程可以快速放回。 2、 请求线程可以继续接受新的请求,如果出现问题线程池隔离是独立的不会影响其他应用。
3、 当失败的应用再次变得可用时,线程池将清理并可立即恢复,而不需要一个长时间的恢复。
4、 独立的线程池提高了并发性
缺点:
线程池隔离的主要缺点是它们增加计算开销(CPU)。每个命令的执行涉及到排队、调度和上 下文切换都是在一个单独的线程上运行的。
public class OrderHystrixCommand extends HystrixCommand<JSONObject> { @Autowired private MemberService memberService; /** * @param group */ public OrderHystrixCommand(MemberService memberService) { super(setter()); this.memberService = memberService; } protected JSONObject run() throws Exception { JSONObject member = memberService.getMember(); System.out.println("当前线程名称:" + Thread.currentThread().getName() + ",订单服务调用会员服务:member:" + member); return member; } private static Setter setter() { // 服务分组 HystrixCommandGroupKey groupKey = HystrixCommandGroupKey.Factory.asKey("members"); // 服务标识 HystrixCommandKey commandKey = HystrixCommandKey.Factory.asKey("member"); // 线程池名称 HystrixThreadPoolKey threadPoolKey = HystrixThreadPoolKey.Factory.asKey("member-pool"); // ##################################################### // 线程池配置 线程池大小为10,线程存活时间15秒 队列等待的阈值为100,超过100执行拒绝策略 HystrixThreadPoolProperties.Setter threadPoolProperties = HystrixThreadPoolProperties.Setter().withCoreSize(10) .withKeepAliveTimeMinutes(15).withQueueSizeRejectionThreshold(100); // ######################################################## // 命令属性配置Hystrix 开启超时 HystrixCommandProperties.Setter commandProperties = HystrixCommandProperties.Setter() // 采用线程池方式实现服务隔离 .withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD) // 禁止 .withExecutionTimeoutEnabled(false); return HystrixCommand.Setter.withGroupKey(groupKey).andCommandKey(commandKey).andThreadPoolKey(threadPoolKey) .andThreadPoolPropertiesDefaults(threadPoolProperties).andCommandPropertiesDefaults(commandProperties); } @Override protected JSONObject getFallback() { // 如果Hystrix发生熔断,当前服务不可用,直接执行Fallback方法 System.out.println("系统错误!"); JSONObject jsonObject = new JSONObject(); jsonObject.put("code", 500); jsonObject.put("msg", "系统错误!"); return jsonObject; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
信号量
使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,当请求进来时先判断计数 器的数值,若超过设置的最大线程个数则拒绝该请求,若不超过则通行,这时候计数器+1,请求返 回成功后计数器-1。
与线程池隔离最大不同在于执行依赖代码的线程依然是请求线程
tips:信号量的大小可以动态调整, 线程池大小不可以
public class OrderHystrixCommand2 extends HystrixCommand<JSONObject> { @Autowired private MemberService memberService; /** * @param group */ public OrderHystrixCommand2(MemberService memberService) { super(setter()); this.memberService = memberService; } protected JSONObject run() throws Exception { // Thread.sleep(500); // System.out.println("orderIndex线程名称" + // Thread.currentThread().getName()); // System.out.println("success"); JSONObject member = memberService.getMember(); System.out.println("当前线程名称:" + Thread.currentThread().getName() + ",订单服务调用会员服务:member:" + member); return member; } private static Setter setter() { // 服务分组 HystrixCommandGroupKey groupKey = HystrixCommandGroupKey.Factory.asKey("members"); // 命令属性配置 采用信号量模式 HystrixCommandProperties.Setter commandProperties = HystrixCommandProperties.Setter() .withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.SEMAPHORE) // 使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,当请求进来时先判断计数 // 器的数值,若超过设置的最大线程个数则拒绝该请求,若不超过则通行,这时候计数器+1,请求返 回成功后计数器-1。 .withExecutionIsolationSemaphoreMaxConcurrentRequests(50); return HystrixCommand.Setter.withGroupKey(groupKey).andCommandPropertiesDefaults(commandProperties); } @Override protected JSONObject getFallback() { // 如果Hystrix发生熔断,当前服务不可用,直接执行Fallback方法 System.out.println("系统错误!"); JSONObject jsonObject = new JSONObject(); jsonObject.put("code", 500); jsonObject.put("msg", "系统错误!"); return jsonObject; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
应用场景
线程池隔离:
1、 第三方应用或者接口
2、 并发量大
信号量隔离:
1、 内部应用或者中间件(redis)
2、 并发需求不大
高并发服务限流特技
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。缓存的目的是提升系统访问速度和增大系统能处理的容量,可谓是抗高并发流量的银弹;而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询(评论的最后几页),因此需有一种手段来限制这些场景的并发/请求量,即限流。
为什么要互联网项目要限流
互联网雪崩效应解决方案
服务降级: 在高并发的情况, 防止用户一直等待,直接返回一个友好的错误提示给客户端。
服务熔断:在高并发的情况,一旦达到服务最大的承受极限,直接拒绝访问,使用服务降级。
服务隔离: 使用服务隔离方式解决服务雪崩效应
服务限流: 在高并发的情况,一旦服务承受不了使用服务限流机制(计时器(滑动窗口计数)、漏桶算法、令牌桶(Restlimite))
高并发限流解决方案
高并发限流解决方案限流算法(令牌桶、漏桶、计数器)、应用层解决限流(Nginx)
限流算法
常见的限流算法有:令牌桶、漏桶。计数器也可以进行粗暴限流实现。
计数器
它是限流算法中最简单最容易的一种算法,比如我们要求某一个接口,1分钟内的请求不能超过10次,我们可以在开始时设置一个计数器,每次请求,该计数器+1;如果该计数器的值大于10并且与第一次请求的时间间隔在1分钟内,那么说明请求过多,如果该请求与第一次请求的时间间隔大于1分钟,并且该计数器的值还在限流范围内,那么重置该计数器
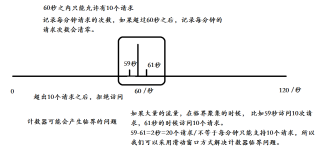
/** * 功能说明: 纯手写计数器方式<br> */ public class LimitService { private int limtCount = 60;// 限制最大访问的容量 AtomicInteger atomicInteger = new AtomicInteger(0); // 每秒钟 实际请求的数量 private long start = System.currentTimeMillis();// 获取当前系统时间 private int interval = 60;// 间隔时间60秒 public boolean acquire() { long newTime = System.currentTimeMillis(); if (newTime > (start + interval)) { // 判断是否是一个周期 start = newTime; atomicInteger.set(0); // 清理为0 return true; } atomicInteger.incrementAndGet();// i++; return atomicInteger.get() <= limtCount; } static LimitService limitService = new LimitService(); public static void main(String[] args) { ExecutorService newCachedThreadPool = Executors.newCachedThreadPool(); for (int i = 1; i < 100; i++) { final int tempI = i; newCachedThreadPool.execute(new Runnable() { public void run() { if (limitService.acquire()) { System.out.println("你没有被限流,可以正常访问逻辑 i:" + tempI); } else { System.out.println("你已经被限流呢 i:" + tempI); } } }); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
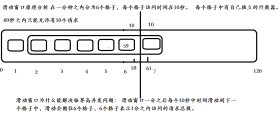
滑动窗口计数
滑动窗口计数有很多使用场景,比如说限流防止系统雪崩。相比计数实现,滑动窗口实现会更加平滑,能自动消除毛刺。
滑动窗口原理是在每次有访问进来时,先判断前 N 个单位时间内的总访问量是否超过了设置的阈值,并对当前时间片上的请求数 +1。
令牌桶算法
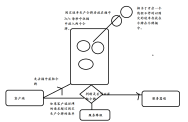
令牌桶算法是一个存放固定容量令牌的桶,按照固定速率往桶里添加令牌。令牌桶算法的描述如下:
假设限制2r/s,则按照500毫秒的固定速率往桶中添加令牌;
桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝;
当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上;
如果桶中的令牌不足n个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
使用RateLimiter实现令牌桶限流
RateLimiter是guava提供的基于令牌桶算法的实现类,可以非常简单的完成限流特技,并且根据系统的实际情况来调整生成token的速率。
通常可应用于抢购限流防止冲垮系统;限制某接口、服务单位时间内的访问量,譬如一些第三方服务会对用户访问量进行限制;限制网速,单位时间内只允许上传下载多少字节等。
下面来看一些简单的实践,需要先引入guava的maven依赖。
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.0.RELEASE</version> </parent> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>25.1-jre</version> </dependency> </dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
/** * 功能说明:使用RateLimiter 实现令牌桶算法 * */ @RestController public class IndexController { @Autowired private OrderService orderService; // 解释:1.0 表示 每秒中生成1个令牌存放在桶中 RateLimiter rateLimiter = RateLimiter.create(1.0); // 下单请求 @RequestMapping("/order") public String order() { // 1.限流判断 // 如果在500秒内 没有获取不到令牌的话,则会一直等待 System.out.println("生成令牌等待时间:" + rateLimiter.acquire()); boolean acquire = rateLimiter.tryAcquire(500, TimeUnit.MILLISECONDS); if (!acquire) { System.out.println("你在怎么抢,也抢不到,因为会一直等待的,你先放弃吧!"); return "你在怎么抢,也抢不到,因为会一直等待的,你先放弃吧!"; } // 2.如果没有达到限流的要求,直接调用订单接口 boolean isOrderAdd = orderService.addOrder(); if (isOrderAdd) { return "恭喜您,抢购成功!"; } return "抢购失败!"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
漏桶算法
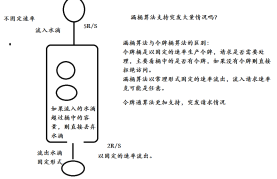
漏桶作为计量工具(The Leaky Bucket Algorithm as a Meter)时,可以用于流量整形(Traffic Shaping)和流量控制(TrafficPolicing),漏桶算法的描述如下:
一个固定容量的漏桶,按照常量固定速率流出水滴;
如果桶是空的,则不需流出水滴;
可以以任意速率流入水滴到漏桶;
如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。
令牌桶和漏桶对比:
令牌桶是按照固定速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数减为零时则拒绝新的请求;
漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入的请求数累积到漏桶容量时,则新流入的请求被拒绝;
令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌),并允许一定程度突发流量;
漏桶限制的是常量流出速率(即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次又是2),从而平滑突发流入速率;
令牌桶允许一定程度的突发,而漏桶主要目的是平滑流入速率;
两个算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
另外有时候我们还使用计数器来进行限流,主要用来限制总并发数,比如数据库连接池、线程池、秒杀的并发数;只要全局总请求数或者一定时间段的总请求数设定的阀值则进行限流,是简单粗暴的总数量限流,而不是平均速率限流。
一个固定的漏桶,以常量固定的速率流出水滴。
如果桶中没有水滴的话,则不会流出水滴
如果流入的水滴超过桶中的流量,则流入的水滴可能会发生溢出,溢出的水滴请求是无法访问的,直接调用服务降级方法,桶中的容量是不会发生变化。
漏桶算法与令牌桶算法区别
主要区别在于“漏桶算法”能够强行限制数据的传输速率,而“令牌桶算法”在能够限制数据的平均传输速率外,还允许某种程度的突发传输。在“令牌桶算法”中,只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,因此它适合于具有突发特性的流量。
封装RateLimiter
自定义注解封装RateLimiter.实例:
@RequestMapping("/myOrder")
@ExtRateLimiter(value = 10.0, timeOut = 500)
public String myOrder() throws InterruptedException {
System.out.println("myOrder");
return "SUCCESS";
}
- 1
- 2
- 3
- 4
- 5
- 6
自定义注解
@Target(value = ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ExtRateLimiter {
double value();
long timeOut();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
编写AOP
@Aspect @Component public class RateLimiterAop { // 存放接口是否已经存在 private static ConcurrentHashMap<String, RateLimiter> rateLimiterMap = new ConcurrentHashMap<String, RateLimiter>(); @Pointcut("execution(public * com.itmayeidu.api.*.*(..))") public void rlAop() { } @Around("rlAop()") public Object doBefore(ProceedingJoinPoint proceedingJoinPoint) throws Throwable { MethodSignature signature = (MethodSignature) proceedingJoinPoint.getSignature(); // 使用Java反射技术获取方法上是否有@ExtRateLimiter注解类 ExtRateLimiter extRateLimiter = signature.getMethod().getDeclaredAnnotation(ExtRateLimiter.class); if (extRateLimiter == null) { // 正常执行方法 Object proceed = proceedingJoinPoint.proceed(); return proceed; } // ############获取注解上的参数 配置固定速率 ############### // 获取配置的速率 double value = extRateLimiter.value(); // 获取等待令牌等待时间 long timeOut = extRateLimiter.timeOut(); RateLimiter rateLimiter = getRateLimiter(value, timeOut); // 判断令牌桶获取token 是否超时 boolean tryAcquire = rateLimiter.tryAcquire(timeOut, TimeUnit.MILLISECONDS); if (!tryAcquire) { serviceDowng(); return null; } // 获取到令牌,直接执行.. Object proceed = proceedingJoinPoint.proceed(); return proceed; } // 获取RateLimiter对象 private RateLimiter getRateLimiter(double value, long timeOut) { // 获取当前URL ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); String requestURI = request.getRequestURI(); RateLimiter rateLimiter = null; if (!rateLimiterMap.containsKey(requestURI)) { // 开启令牌通限流 rateLimiter = RateLimiter.create(value); // 独立线程 rateLimiterMap.put(requestURI, rateLimiter); } else { rateLimiter = rateLimiterMap.get(requestURI); } return rateLimiter; } // 服务降级 private void serviceDowng() throws IOException { // 执行服务降级处理 System.out.println("执行降级方法,亲,服务器忙!请稍后重试!"); ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletResponse response = attributes.getResponse(); response.setHeader("Content-type", "text/html;charset=UTF-8"); PrintWriter writer = response.getWriter(); try { writer.println("执行降级方法,亲,服务器忙!请稍后重试!"); } catch (Exception e) { } finally { writer.close(); } } public static void main(String[] args) { // 使用Java反射技术获取方法上是否有@ExtRateLimiter注解类 ExtRateLimiter extRateLimiter = IndexController.class.getClass().getAnnotation(ExtRateLimiter.class); System.out.println(extRateLimiter); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
运行效果
@RequestMapping("/myOrder")
@ExtRateLimiter(value = 10.0, timeOut = 500)
public String myOrder() throws InterruptedException {
System.out.println("myOrder");
return "SUCCESS";
}
- 1
- 2
- 3
- 4
- 5
- 6
应用级限流
限流总并发/连接/请求数
对于一个应用系统来说一定会有极限并发/请求数,即总有一个TPS/QPS阀值,如果超了阀值则系统就会不响应用户请求或响应的非常慢,因此我们最好进行过载保护,防止大量请求涌入击垮系统。
如果你使用过Tomcat,其Connector其中一种配置有如下几个参数:
acceptCount:如果Tomcat的线程都忙于响应,新来的连接会进入队列排队,如果超出排队大小,则拒绝连接;
maxConnections:瞬时最大连接数,超出的会排队等待;
maxThreads:Tomcat能启动用来处理请求的最大线程数,如果请求处理量一直远远大于最大线程数则可能会僵死。
详细的配置请参考官方文档。另外如MySQL(如max_connections)、Redis(如tcp-backlog)都会有类似的限制连接数的配置。
限流总资源数
如果有的资源是稀缺资源(如数据库连接、线程),而且可能有多个系统都会去使用它,那么需要限制应用;可以使用池化技术来限制总资源数:连接池、线程池。比如分配给每个应用的数据库连接是100,那么本应用最多可以使用100个资源,超出了可以等待或者抛异常。
限流某个接口的总并发/请求数
如果接口可能会有突发访问情况,但又担心访问量太大造成崩溃,如抢购业务;这个时候就需要限制这个接口的总并发/请求数总请求数了;因为粒度比较细,可以为每个接口都设置相应的阀值。可以使用Java中的AtomicLong进行限流:
适合对业务无损的服务或者需要过载保护的服务进行限流,如抢购业务,超出了大小要么让用户排队,要么告诉用户没货了,对用户来说是可以接受的。而一些开放平台也会限制用户调用某个接口的试用请求量,也可以用这种计数器方式实现。这种方式也是简单粗暴的限流,没有平滑处理,需要根据实际情况选择使用;
限流某个接口的时间窗请求数
即一个时间窗口内的请求数,如想限制某个接口/服务每秒/每分钟/每天的请求数/调用量。如一些基础服务会被很多其他系统调用,比如商品详情页服务会调用基础商品服务调用,但是怕因为更新量比较大将基础服务打挂,这时我们要对每秒/每分钟的调用量进行限速;一种实现方式如下所示:
平滑限流某个接口的请求数
之前的限流方式都不能很好地应对突发请求,即瞬间请求可能都被允许从而导致一些问题;因此在一些场景中需要对突发请求进行整形,整形为平均速率请求处理(比如5r/s,则每隔200毫秒处理一个请求,平滑了速率)。这个时候有两种算法满足我们的场景:令牌桶和漏桶算法。Guava框架提供了令牌桶算法实现,可直接拿来使用。
Guava RateLimiter提供了令牌桶算法实现:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现。
接入层限流
接入层通常指请求流量的入口,该层的主要目的有:负载均衡、非法请求过滤、请求聚合、缓存、降级、限流、A/B测试、服务质量监控等等,可以参考笔者写的《使用Nginx+Lua(OpenResty)开发高性能Web应用》。
对于Nginx接入层限流可以使用Nginx自带了两个模块:连接数限流模块ngx_http_limit_conn_module和漏桶算法实现的请求限流模块ngx_http_limit_req_module。还可以使用OpenResty提供的Lua限流模块lua-resty-limit-traffic进行更复杂的限流场景。
limit_conn用来对某个KEY对应的总的网络连接数进行限流,可以按照如IP、域名维度进行限流。limit_req用来对某个KEY对应的请求的平均速率进行限流,并有两种用法:平滑模式(delay)和允许突发模式(nodelay)。
ngx_http_limit_conn_module
limit_conn是对某个KEY对应的总的网络连接数进行限流。可以按照IP来限制IP维度的总连接数,或者按照服务域名来限制某个域名的总连接数。但是记住不是每一个请求连接都会被计数器统计,只有那些被Nginx处理的且已经读取了整个请求头的请求连接才会被计数器统计。
Web前端优化
1.使用网站动静分离架构
2.减少Http请求的传输,CSS/JS合并传输,压缩JS、CSS技术
3.使用浏览器缓存静态资源,减少服务器端压力
4.使用CDN内容分发,减少宽带传输,获取用户Ip,分配到最近的服务器访问
实战CDN内容分发
DNS域名解析过程
DNS即Domain Name System,是域名解析服务的意思。它在互联网的作用是:把域名转换成为网络可以识别的ip地址。人们习惯记忆域名,但机器间互相只认IP地址,域名与IP地址之间是一一对应的,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,整个过程是自动进行的。比如:上网时输入的www.baidu.com会自动转换成为220.181.112.143。
常见的DNS解析服务商有:阿里云解析,万网解析,DNSPod,新网解析,Route53(AWS),Dyn,Cloudflare等。
传统方式请求静态资源
1.比如访问页面请求
http://www.itmayiedu.com/images/upload/image/20180709/1531101991431.png
2.
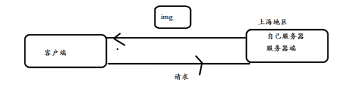
传统方式架构弊端:
1.带宽传输压力大
2.因为所有用户全部聚集到同一个地区服务器上访问,无法保证整体的系统高可用
3.因为如果客户端与服务器端传输距离越远,那么宽带传输非常耗资源,导致用户体验非常差,响应慢。
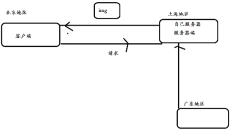
什么是CDN
CDN加速意思就是在用户和我们的服务器之间加一个缓存机制,动态获取IP地址根据地理位置,让用户到最近的服务器访问。
CDN的全称是Content Delivery Network,即内容分发网络。
CDN是一组分布在多个不同地理位置的Web服务器,用于更加有效地向用户发布内容,在优化性能时,会根据距离的远近来选择。
CDN系统能实时地根据网络流量和各节点的连接,负载状况及用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上,其目的是使用户能就近地获取请求数据,解决网络拥塞,提高访问速度,解决由于网络带宽小、用户访问量大、网点分布不均等原因导致的访问速度慢的问题。
由于CDN部署在网络运营商的机房,这些运营商又是终端用户网络的提供商,因此用户请求的第一跳就到达CDN服务器,当CDN服务器中缓存有用户请求的数据时,就可以从CDN直接返回给浏览器,因此可以提高访问速度。
CDN能够缓存JavaScript脚本、CSS样式表、图片、图标、Flash等静态资源文件(不包括html页面),这些静态资源文文件的访问频率很高,将其缓存在CDN可以极大地提高网站的访问速度,但由于CDN是部署在网络运营商的机房,所以在一般的网站中都很少用CDN加速。
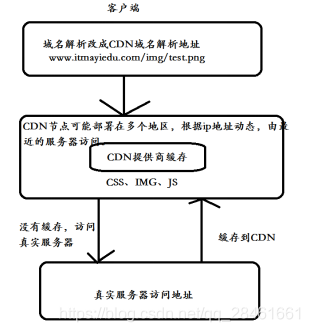
CDN内容分发原理
- 用户向浏览器提供要访问的域名;
- 浏览器调用域名解析库对域名进行解析,由于CDN对域名解析过程进行了调整,所以解析函数库一般得到的是该域名对应的
CNAME记录,为了得到实际IP地址,浏览器需要再次对获得的CNAME域名进行解析以得到实际的IP地址;在此过程中,使用的全局负载均衡DNS解析,如根据地理位置信息解析对应的IP地址,使得用户能就近访问; - 此次解析得到CDN缓存服务器的IP地址,浏览器在得到实际的IP地址以后,向缓存服务器发出访问请求;
- 缓存服务器根据浏览器提供的要访问的域名,通过Cache内部专用DNS解析得到此域名的实际IP地址,再由缓存服务器向此实际IP地址提交访问请求;
- 缓存服务器从实际IP地址得得到内容以后,一方面在本地进行保存,以备以后使用,二方面把获取的数据返回给客户端,完成数据服务过程;
- 客户端得到由缓存服务器返回的数据以后显示出来并完成整个浏览的数据请求过程。
阿里云环境实战搭建CDN内容分发
环境要求:阿里云 121.40.18.24
客户端访问域名testwww.itmayiedu.com—能够实现内容分发
蚂蚁课堂真实服务器IP地址 121.40.18.24
步骤:
1.创建阿里云CDN地址
2.前往解析CNAME
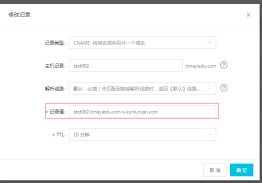
https://dns.console.aliyun.com/?spm=5176.100251.0.0.72014f15aeNUyY#/dns/setting/itmayiedu.com
1.阿里云全站CDN后台管理页面
https://dcdn.console.aliyun.com/?spm=5176.8232187.domainlist.2.1afb142fNzk20a#/overview
2.阿里云CDN帮助文档
https://help.aliyun.com/document_detail/27101.html?spm=a2c4g.11174283.6.539.NPTXlI
名词解释
CNAME记录(CNAME Record)
CNAME即别名( Canonical Name );可以用来把一个域名解析到另一个域名。当 DNS 系统在查询 CNAME 左面的名称的时候,都会转向 CNAME 右面的名称再进行查询,一直追踪到最后的 PTR 或 A 名称,成功查询后才会做出回应,否则失败。例如,你有一台服务器上存放了很多资料,你使用docs.example.com去访问这些资源,但又希望通过documents.example.com也能访问到这些资源,那么你就可以在您的DNS解析服务商添加一条CNAME记录,将documents.example.com指向docs.example.com,添加该条CNAME记录
后,所有访问documents.example.com的请求都会被转到docs.example.com,获得相同的内容。
CNAME域名
接入CDN时,在阿里云控制台添加完加速域名后,您会得到一个阿里云CDN给您分配的CNAME域名,(该CNAME域名一定是*.kunlun.com), 您需要在您的DNS解析服务商添加CNAME记录,将自己的加速域名指向这个*.kunlun.com的CNAME域名,这样该域名所有的请求才会都将转向阿里云CDN的节点,达到加速效果。
详细参考地址:
https://help.aliyun.com/document_detail/27102.html?spm=a2c4g.11186623.6.544.ERnv0c
DNS域名解析
DNS即Domain Name System,是域名解析服务的意思。它在互联网的作用是:把域名转换成为网络可以识别的ip地址。人们习惯记忆域名,但机器间互相只认IP地址,域名与IP地址之间是一一对应的,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,整个过程是自动进行的。比如:上网时输入的www.baidu.com会自动转换成为220.181.112.143。
常见的DNS解析服务商有:阿里云解析,万网解析,DNSPod,新网解析,Route53(AWS),Dyn,Cloudflare等。
常见名称
高并发
高可用
幂等性
心跳检测
隔离技术
限流技术
降级技术
雪崩效应
超时机制
防重设计
重试机制
补偿机制
回滚机制
注册中心
服务化
拆分
命中率
多级缓存
异步并发
平滑扩容
可伸缩
敏捷迭代
无状态

