
热门标签
热门文章
- 1【BIM+GIS】Supermap加载实景三维倾斜摄影模型_supermap打开osgb
- 2SSH生成密钥_生成 ssh秘钥 命令
- 3用java计算文本相似度_java 文本相似度
- 4案例21:Java农产品供求信息系统设计与实现开题报告_农产品商品信息系统开题报告
- 5免费的ChatGPT 镜像网站列表_chat.freegpts.org
- 6RTX操作系统教程[02]_rtx教程
- 7解决vmware克隆centos7后重复ip的问题_centos克隆虚拟机后ip与原来一样
- 8用python gdal裁剪栅格数据提取添加xy经纬度和栅格值_python 如何识别栅格图片的经纬度
- 9python gdal 矢量裁剪栅格_gdal tif切图五级之前有偏移
- 10《大道至简》改名记_大道至简,给所有人看的编程书
当前位置: article > 正文
【AI实战】最强开源 6B 中文大语言模型ChatGLM2-6B,从零开始搭建_大语言模型 6b
作者:不正经 | 2024-04-01 22:32:36
赞
踩
大语言模型 6b

ChatGLM2-6B 简介
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
ChatGLM2-6B 评测结果
我们选取了部分中英文典型数据集进行了评测,以下为 ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。
- MMLU
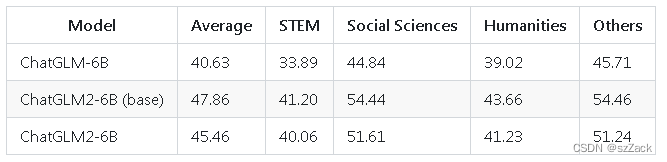
- C-Eval

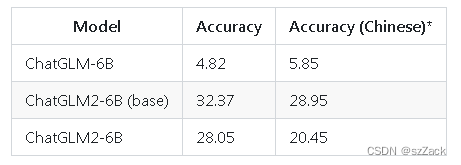
- GSM8K
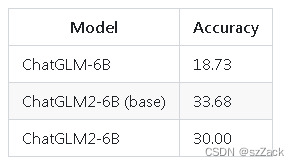
- BBH
ChatGLM2-6B 搭建
-
1、拉取docker镜像
docker pull nvcr.io/nvidia/pytorch:21.08-py3- 1
【】需要 cuda 11.1 及以上版本
-
2、创建docker
nvidia-docker run -it -d \ --name chatglm2 \ -v /llm:/notebooks \ -e TZ='Asia/Shanghai' \ --shm-size 16G \ nvcr.io/nvidia/pytorch:21.08-py3- 1
- 2
- 3
- 4
- 5
- 6
进入容器内:
docker exec -it chatglm2 env LANG=C.UTF-8 /bin/bash- 1
-
3、下载代码
cd /notebooks/ git https://github.com/THUDM/ChatGLM2-6B.git- 1
- 2
-
4、下载模型权重文件
cd ChatGLM2-6B/ git clone https://huggingface.co/THUDM/chatglm2-6b- 1
- 2
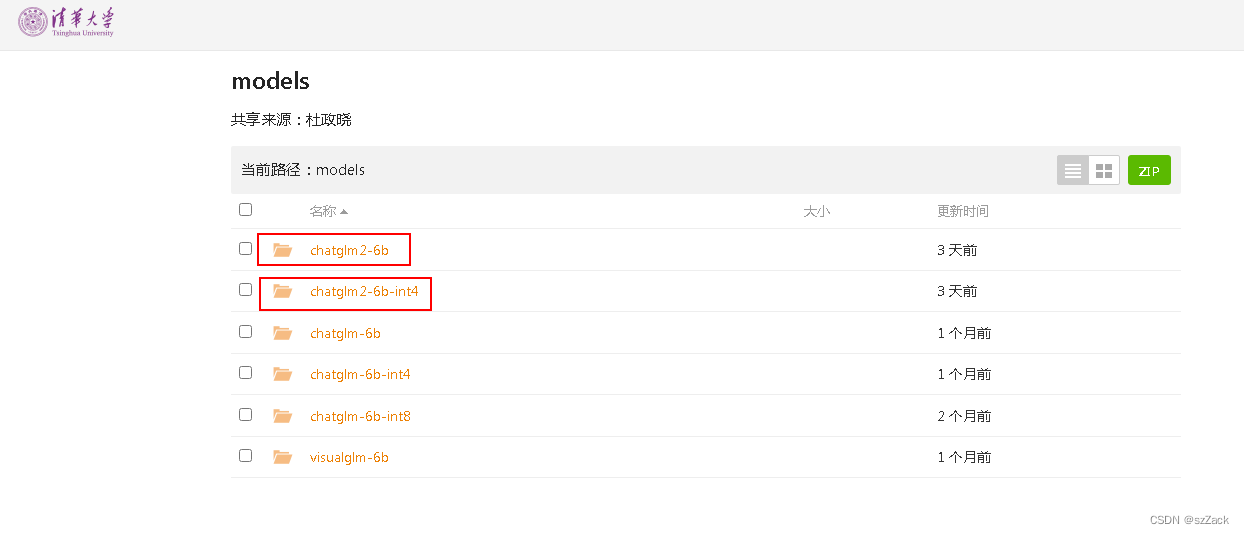
- 可能上述方法权重文件下载失败,用下面的方法下载权重文件
地址:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2F&mode=list
选择下面中的一个进行下载:
chatglm2-6b
chatglm2-6b-int4
-
5、按照依赖库
pip install -r requirements.txt- 1
-
6、推理
-
推理速度对比
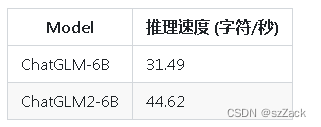
-
显存占用
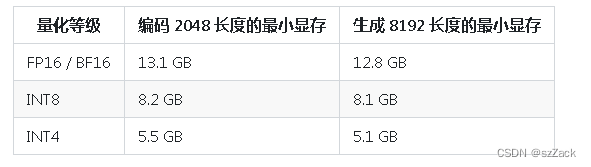
-
推理代码
from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True) model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda') model = model.eval() response, history = model.chat(tokenizer, "你好", history=[]) print(response) 你好声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/350345
-
推荐阅读相关标签Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

