
- 1开发者实战 | OpenVINO™ 赋能 BLIP 实现视觉语言 AI 边缘部署
- 2第十三届蓝桥杯省赛C++B组错题笔记_小明特别喜欢顺子。顺子指的就是连续的三个数字:123、456 等。顺子日期指的就是在
- 3详解机器学习概念、算法
- 4自然语言处理实战项目7-利用层次聚类方法做文本的排重,从大量的文本中找出相似文本_相似文本聚类
- 5Python学习笔记:面向对象高级编程(上)_python中面向对象高级编程
- 6【git基础】git merge使用简介
- 7强化CentOS安全防线:如何有效应对常见安全威胁
- 8Android跳转到应用下载平台,给当前APP评分_安卓 给app我们评分
- 9Kalibr进行相机-IMU联合标定踩坑记录RuntimeError: Optimization failed!_kalibr runtimeerror: optimization failed!
- 10大模型工具学习系统性综述+开源工具平台,清华、人大、北邮、UIUC、NYU、CMU等40多位研究者联合发布...
【论文笔记】——从transformer、bert、GPT-1、2、3到ChatGPT_chatgpt和transformer
赞
踩
笔记脉络
从GPT到ChatGPT
1.整体发展脉络
18年有bert和gpt这两个语言模型,分别源自transformer的编码器和解码器,都是无监督方式训练的
- GPT-1用的是无监督预训练+有监督微调
- GPT-2用的是纯无监督预训练。提升了网络层数和训练数据量
- GPT-3沿用了GPT-2的纯无监督预训练,但是数据大了好几个量级
- InstructGPT在GPT-3上用来自人类反馈的强化学习RLHF做微调,内核模型为PPO-ptx
- ChatGPT沿用了InstructGPT,但是数据大了好几个量级,ChatGPT相当于超大版本的InstructGPT
(私密马赛给李沐老师截这么丑o(╥﹏╥)o)
2.transformer回顾-2017
Transformer是2017年Google提出的一种基于注意力机制的神经网络模型,用于处理序列到序列(sequence-to-sequence)的问题,如自然语言翻译、文本摘要和语言模型等任务。Transformer模型的提出,一定程度上解决了传统RNN等序列模型中长序列计算效率低下、梯度消失等问题。
动机
在传统的序列模型中,如RNN等,模型需要按顺序处理序列中的每个元素,并将上下文信息通过隐藏状态依次传递下去。这种逐个计算的方式不仅计算效率低下,而且容易出现梯度消失和梯度爆炸等问题,限制了模型的表现能力。Transformer模型的提出是为了解决这些问题,它引入了一种新的机制——自注意力机制(Self-Attention Mechanism),以更高效和灵活的方式捕捉序列中的上下文信息。
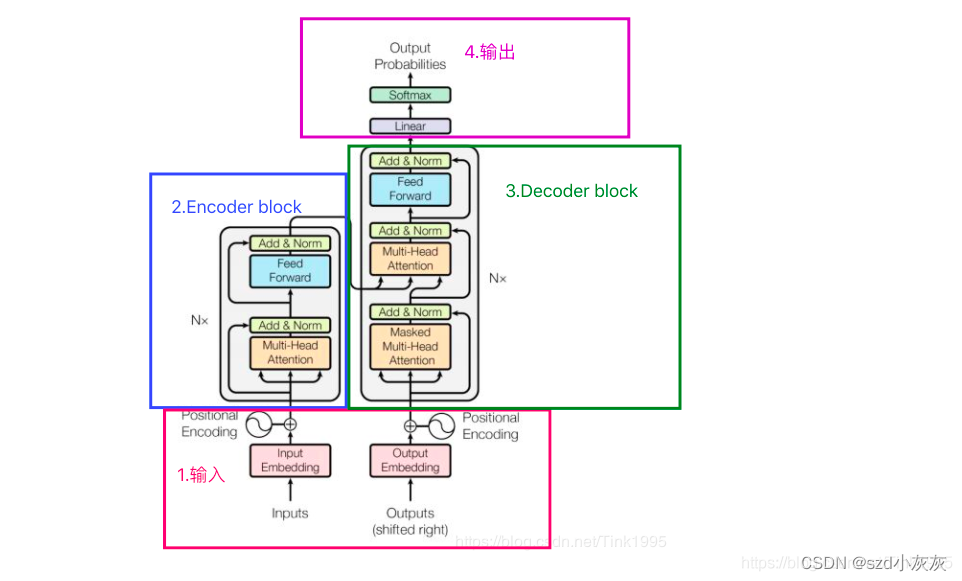
模型结构
Transformer的核心思想是将序列到序列的问题(sequence-to-sequence)分为编码器(encoder)和解码器(decoder)两部分,其中编码器将输入序列映射到一个高维空间的表示,解码器则利用这个表示生成输出序列。在编码器和解码器之间,Transformer引入了多头自注意力机制,它可以让模型在生成每个单词时同时考虑输入序列中其他单词的语义信息。Transformer模型包含编码器(Encoder)和解码器(Decoder)两个部分,其中编码器和解码器均由若干个相同的Transformer block组成。每个Transformer block又包含若干个层,其中最核心的是Multi-Head Self-Attention层和Feed-Forward层。Multi-Head Self-Attention层用于计算序列中各元素的自注意力表示,而Feed-Forward层则用于对自注意力表示进行非线性变换。整个模型的输入和输出均为由词向量表示的序列。
创新点
相比传统序列模型,Transformer模型的最大创新点是引入了自注意力机制,使得模型能够在一次前向计算中同时考虑序列中所有元素之间的依赖关系,而不需要像传统模型那样逐个计算。具体来说,对于每个位置,Transformer使用自注意力机制来计算它与其他位置的相似度,从而得到一个权重向量,表示不同位置对当前位置的贡献。通过这种方式,Transformer能够有效地捕捉输入序列中不同位置之间的依赖关系,从而更好地处理序列到序列的任务。另外,Transformer模型使用了Layer Normalization(层归一化)技术,使得模型更容易训练,同时还使用了残差连接(Residual Connection)和前向网络(Feed-Forward Network)来加速模型收敛和提高模型表现能力。
算法原理
在Transformer模型中,每个Encoder和Decoder block均包含Self-Attention层和Feed-Forward层。Self-Attention层是Transformer的核心部分,它通过计算序列中所有元素之间的相关性来得到每个元素的自注意力表示。具体地,Self-Attention层先将序列中每个元素表示为三个向量,即Query、Key和Value,然后计算Query和Key之间的相似度得到注意力权重,最后将注意力权重和Value进行加权求和。Transformer的创新点还包括多头自注意力机制(Multi-Head Attention),它能够让模型在计算注意力时同时考虑不同的表示空间,以获取更多的语义信息。另一个创新点是残差连接(Residual Connection)和层归一化(Layer Normalization),它们能够提升模型的训练效果和泛化能力。
3.Bert回顾(2018-10)
动机
BERT 来自 Google 的论文Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT 是“Bidirectional Encoder Representations from Transformers”的首字母缩写,整体是一个自编码语言模型(Autoencoder LM),并且其设计了两个任务来预训练该模型。
- 第一个任务是采用 MaskLM的方式来训练语言模型,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。
- 第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。 最后的实验表明 BERT 模型的有效性,并在 11项 NLP 任务中夺得 SOTA 结果。
BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。同时缺点也是显而易见的,模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
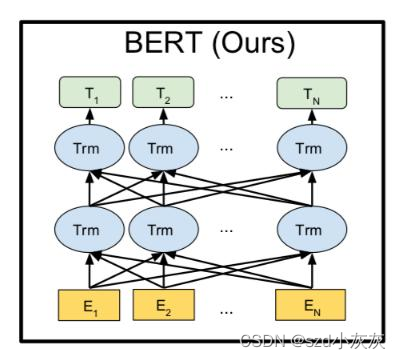
BERT模型结构
BERT 只使用了 Transformer 的 Encoder 模块,原论文中,作者分别用 12 层和 24 层 Transformer Encoder 组装了两套 BERT 模型,分别是:
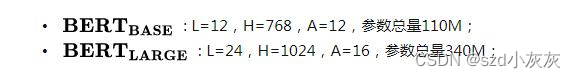
其中层的数量(即,Transformer Encoder 块的数量)为L ,隐藏层的维度为H ,自注意头的个数为A 。在所有例子中,我们将前馈/过滤器(Transformer Encoder 端的 feed-forward 层)的维度设置为4H ,即当 H=768 时是3072 ;当 H=1024 是 4096 。
图示如下:
4.GPT-1 (2018-6)
GPT-1:Improving Language Understanding by Generative Pre-Training 2018(6)
动机
GPT:Generative Pre-Training
(在自然语言中,大量的未标记文本语料库非常丰富,但用于学习特定任务的标记数据却非常缺乏,这使得有区别训练的模型难以充分发挥作用。)
在NLP任务中有很多不一样的任务,虽然有很多大量的没有标签的文本数据,但是有标签的数据训练的效果比较好,如果想要在没有标签的数据集上训练出好的模型比较难。因此作者提出了一个想法,在无标签的数据上训练一个预训练模型,然后在这些有标签的子任务上训练一个微调模型。(当时之前是CV领域的主流做法)与以前的方法相比,在微调期间利用任务感知的输入转换来实现有效的迁移,同时只需要对模型体系结构进行最小的更改。
模型架构
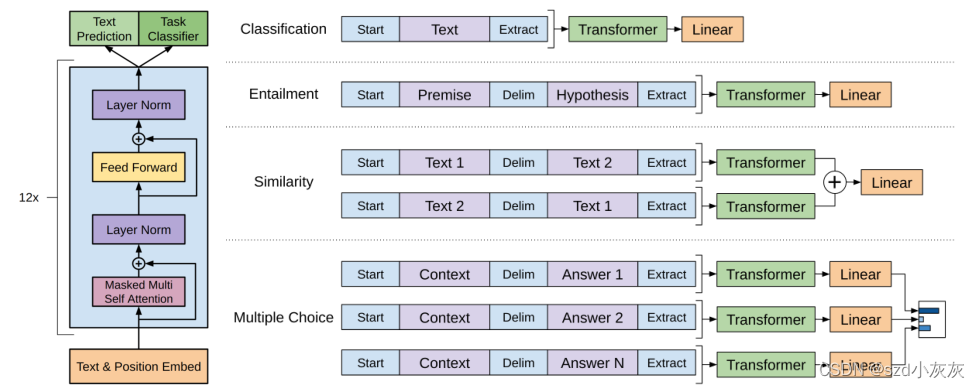
GPT-1的模型架构基于Transformer的解码器,由多个相同的Transformer块组成。每个Transformer块包括多头自注意力层和前馈神经网络层,其中前馈神经网络层由两个全连接层和一个激活函数组成。每个Transformer块之间都有残差连接和层归一化,用于保持信息流的顺畅和避免梯度消失。GPT-1的输入是一个固定长度的文本序列,输出是预测下一个单词的概率分布。
训练
GPT1的训练主要分成无监督预训练和有监督微调两部分:
无监督预训练指的是现在大规模语料下,训练一个语言模型;
有监督微调指的是基于下游任务的标注数据进行模型参数调整。
无监督训练:
给一组无监督学习语料的tokens:U = { u 1 , u 2 , . . . , u n },以语言模型的目标函数作为目标,最大化其似然函数:
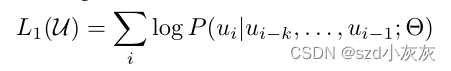

对应不同任务有监督微调:
对微调来说是用有标签的数据,具体来说每一次给一个长为m的一个词的序列,这个序列它对应的标签是y,也就是每次给定一个序列预测这个标签y.具体来说就是每次给x1到xm的数据,来预测y的概率,这里的做法是把整个这个序列放进训练好的GPT模型中,然后拿到Transformer块的最后一层的输出,对应的hm这个词的这个输出,然后再乘以一个输出层,再做一个 Softmax,就得到它的概率了。
也就在是微调任务里面,用所有的带标号的这些序列对,然后把这个序列 x1 到 xm 输入进去之后,计算真实的那个标号上面的概率,要对它做最大化,这是一个非常标准的一个分类目标函数,作者表面在微调的时候虽然只关心这一个分类的精度。但如果把之前的这个语言模型同样放进来,效果也不错。即在做微调的时候有两个目标函数,第一个是给这些序列,然后预测序列的下一个词。以及给完整的序列,预测序列对应的标号,这两个一起训练效果是最佳的。然后通过一个λ,把这两个目标函数加起来。

实验
GPT通过在包含长段连续文本的不同语料库上进行预训练,模型获得了重要的世界知识和处理长期依赖关系的能力,然后成功地迁移到问题回答、语义相似度评估、语义确定、文本分类任务中,改进了12个数据集中的9个数据集的技术水平。
为什么使用transform的解码器?
它用到的模型是Transformer的解码器,Transformer分为编码器和解码器,两者最大的不同是编码器是进来一个序列,它对第i个元素抽取特征的时候,它能够看到序列中所有的元素,但是对解码器来讲,因为有掩码的存在,所以他在对第i个元素抽特征的时候,它只会看到当前元素和它之前的这些元素,他后面那些元素会通过一个掩码,使得在计算注意力机制的时候变成0,所以不看后面的东西,这个地方因为我们用的是标准的语言模型,只能用前面的信息来预测,所以预测第i个词的时候,不会看到这个词的后面这些词是谁,而只能看到前面的,所以这个地方只能用Transformer的解码器。
BERT和GPT都是基于Transformer架构的预训练语言模型,但在一些关键方面有所不同:
预训练任务
BERT采用的是Masked Language Model (MLM)和Next Sentence Prediction (NSP) 两个任务。其中,MLM任务是将输入文本中的一部分随机被遮挡掉,然后模型需要根据上下文预测这些遮挡掉的词是什么;NSP任务则是判断两个句子是否是相邻的。这两个任务使得BERT在理解句子内部和句子之间的关系方面都具有很好的表现。
GPT则采用的是单一的预测任务,即语言模型。该模型通过训练预测一个序列中下一个单词的概率分布,从而学习到文本中单词之间的关系。
训练数据
BERT的训练数据来自于网页文本和书籍,因此涵盖了非常广泛的领域和主题。
而GPT则主要采用了新闻和维基百科等文章,使其在学术和知识层面的表现更好。
网络结构
BERT是一个双向的Transformer Encoder,通过自注意力机制来学习句子内部和句子之间的关系。
而GPT是一个单向的Transformer Decoder,仅通过自注意力机制学习句子内部的关系。
应用场景
由于BERT具有双向性和广泛的训练数据,因此在自然语言理解的任务中表现非常出色。而GPT则在生成自然语言的任务中表现更加突出,比如文本摘要、对话生成和机器翻译等方面。
主要区别在于两者要解决的问题不同,bert(完形填空),GPT(预测未来)。BERT主要用于自然语言理解的任务,而GPT则主要用于生成自然语言的任务。
5.GPT-2论文解读 (2019-02)
Language Models are Unsupervised Multitask Learners, OpenAI
(语言模型是无监督多任务学习器)
摘要
本文介绍了GPT-2模型,与GPT相比,GPT-2模型更大,有12到48层,最大的48层包含1542M的参数量。GPT-2主要测试是zero-shot setting下完成的,它具备强大的语言理解能力,同时也具备了一定的生成能力,测试的一些生成任务如摘要,翻译等已经超过了一些简单的baseline。
在一个新数据集WebText上训练,是百万级别的;
提出GPT-2,参数量1.5B,15亿;
提到zero-shot;
引言
当前的机器学习对数据分布的微小变化脆弱而敏感,是狭隘的专家模型,而不是一个多面手。我们的目标是构建能执行很多任务的通用系统,最终不需要为每个任务创建和标准训练集。
之前工作大多是一个任务利用一个数据集;多任务学习在NLP中使用较少;目前最好方式还是预训练+微调。
语言模型可以在zero-shot设定下实现下游任务,即不需要用有标签的数据再微调训练。
为了实现zero-shot,下游任务的输入就不能像GPT那样在构造输入时加入开始、中间和结束的特殊字符,这些是模型在预训练时没有见过的,而是应该和预训练模型看到的文本一样,更像一个自然语言。
例如机器翻译和阅读理解,可以把输入构造成,翻译prompt+英语+法语;或问答prompt+文档+问题+答案,可以把前面不同的prompt当做是特殊分割符。
数据是从Reddit中爬取出来的优质文档,共800万个文档,40GB。
实现
1.无监督的预训练阶段(同GPT)
2.zero-shot的下游任务
下游任务转向做zero-shot而放弃微调,相较于GPT,出现一个新的问题:样本输入的构建不能保持GPT的形态,因为模型没有机会学习Start,Delim,Extract这些特殊token。因此,GPT-2使用一种新的输入形态:增加文本提示,后来被称为prompt(不是GPT-2第一个提出,他使用的是18年被人提出的方案)。
For example, a translation training example can be written as the sequence (translate to french, English text, french text). Likewise, a reading comprehension training example can be written as (answer the question, document, question, answer).
实验
模型越大,效果越好
所以考虑用更多的数据,做更大的模型,于是GPT-3应运而生。
6.GPT-3论文解读(2020-05 暴力出奇迹)
Language Models are Few-Shot Learners, OpenAI
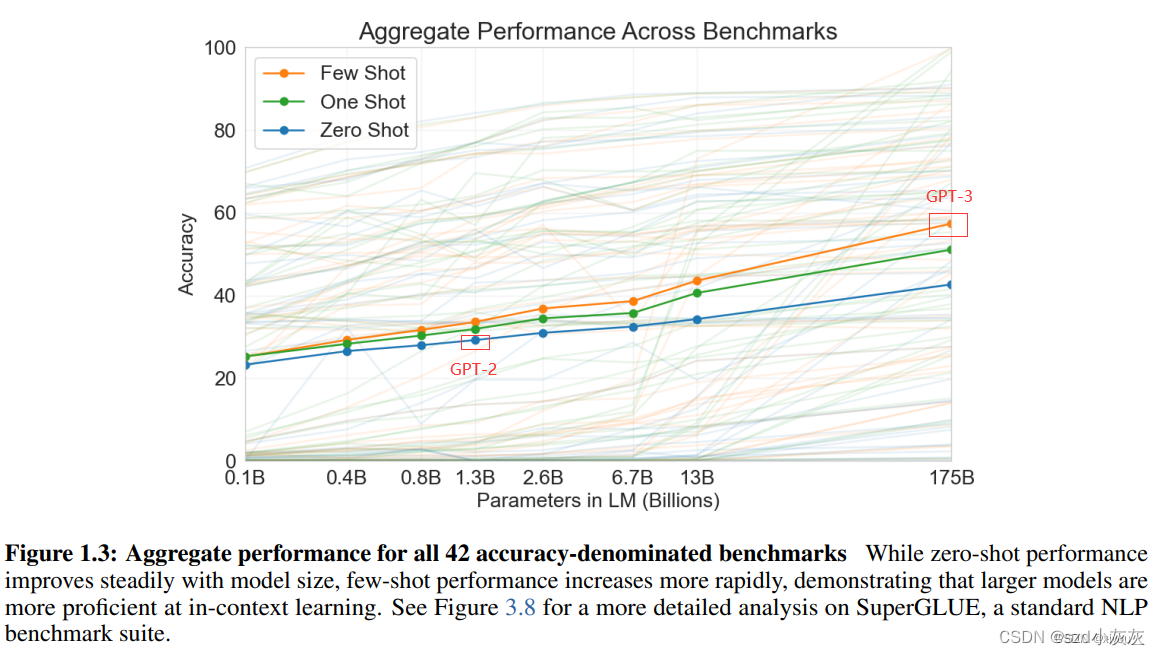
GPT-2虽然提出zero-shot,比bert有新意,但是有效性方面不佳。GPT-3考虑Few-Shot,用少量文本提升有效性。
GPT-3的可学习参数达到1750亿,是之前的非稀疏语言模型的10倍以上,并在few-shot的设置上测试它的性能。对于所有子任务,GPT-3不做任何的梯度更新或者是微调。GPT-3的模型和GPT-2一样。
摘要
提出GPT-3,参数量1750亿;
GPT-3比非稀疏模型参数量大10倍(稀疏模型是指很多权重是0,是稀疏的)。
做子任务时不需要计算梯度,因为参数量很大参数很难调。
引言
mera-learning,在不同多样性的段落中能够学习到大量的任务,训练一个泛化性能好的预训练模型;
in-context learning,段落内数据的上下文之间是相关的,有训练样本但不更新预训练模型的权重。
评估方法:
few-shot learning(10-100个小样本);
one-shot learning(1个样本);
zero-shot(0个样本);
其中few-shot效果最佳。
模型
Fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数
Zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数
One-shot:预训练 + task description + example + prompt,预测。不更新模型参数
Few-shot:预训练 + task description + examples + prompt,预测。不更新模型参数
GPT-3模型和GPT-2一样,GPT-2和GPT-1区别是初始化改变了,使用pre-normalization预格式化,以及可反转的词元。GPT-3应用了Sparse Transformer中的结构。提出了8种大小的模型。
GPT-3是不做梯度更新的few-shot。将一些有标签的样例放在预测文本的上下文。

数据集生成
对抗学习(将GPT2数据集中的样本作为正例,CommonCrawl数据集中的样本作为负例,训练一个线性分类模型,然后对于CommonCrawl中的其他样本,去预测它属于正例还是负例,如果属于正例,则采纳他作为GPT3的数据集)+去重(lsh)
lsh算法
主要用于大数据规模时,计算两两之间的相似度。基本思想:基于一个假设,如果两个文本在原有数据空间是相似的,那么他们分别经过哈希函数转换以后的他们也具有很高的相似度。
- 爬取一部分低质量的Common Crawl作为负例,高质量的Reddit作为正例,用逻辑回归做二分类,判断质量好坏。接下来用分类器对所有Common
Crawl进行预测,过滤掉负类的数据,留下正类的数据; - 去重,利用LSH算法,用于判断两个集合的相似度,经常用于信息检索;
- 加入之前gpt,gpt-2,bert中使用的高质量的数据
局限性
- 生成长文本依旧困难,比如写小说,可能还是会重复;
- 语言模型只能看到前面的信息;
- 语言模型只是根据前面的词均匀预测下一个词,而不知道前面哪个词权重大;
- 只有文本信息,缺乏多模态;
- 样本有效性不够;
- 模型是从头开始学习到了知识,还是只是记住了一些相似任务,这一点不明确;
- 可解释性弱,模型是怎么决策的,其中哪些权重起到决定作用?
负面影响
可能会生成假新闻;可能有一定的性别、地区及种族歧视
7.InstructGPT和ChatGPT
ChatGPT目前没有给出论文,从官网给出的训练过程来看,它和InstructGPT的不同在于,ChatGPT由GPT3.5训练而来
InstructGPT:Training language models to follow instructions with human feedback(GPT-3➡InstructGPT)
这篇文章介绍了instructGPT,本文提到的instructGPT是对GPT-3的大升级
摘要
本文中展示了通过使用人类反馈进行微调来使语言模型在各种任务上与用户意图保持一致的方法。
本文使用有监督学习来微调GPT-3,通过使用一组标注人员编写的提示以及由OpenAI API提交的提示开始,收集了一组由模型输出排名得到的数据集,然后进一步使用强化学习从人类反馈中来微调有监督模型,最终得到的模型称为InstructGPT。
在人类评估中,1.3B的InstructGPT优于175B的GPT-3。此外,结果表明InstructGPT模型有更好的真实性且减少了有毒输出,同时对公共NLP数据集的性能回归很小。尽管InstructGPT依然会犯一些简单的错误,但是结果表面基于人类反馈进行微调是使语言模型与人类意图相结合的有前途的方向。
Motivation
OpenAI GPT-3 可以使用精心设计的文本提示执行自然语言任务。 但这些模型也可能产生不真实、有毒或反映有害情绪的输出。 这部分是因为 GPT-3 被训练来预测大型互联网文本数据集上的下一个单词,而不是安全地执行用户想要的语言任务。 换句话说,这些模型与他们的用户不一致。
大型语言模型依赖prompt来执行任务。这些模型通常会表达潜在的行为,比如编造事实,生成带有偏见或者毒性的文本,抑或是并没有完成用户需要的任务。
发生这个问题的原因是这些语言的建模对象是“预测网页上文本的下一句话”,而不是“安全的忠实的完成用户的命令”。而对于要广泛应用的场景中,是必须要规避这样的情况出现的。
因此作者给语言模型定下了3H的目标:
- helpful 要能够帮助用户完成指定的任务
- honest 不要编造事实或者误导读者
- harmless 不要带有害信息和偏见
使用感受 chatgpt能很好理解我的意图,也能避开有害的有偏见的言论,但是有一本正经胡说八道的现象,在honest上还需要提升
Implementation
对语言模型,要达到这3H, 这篇文章开始了fine tuning。核心技术就是使用来自人类反馈中强化学习(RLHF)来fine tune GPT-3,使得GPT-3模型能够执行指定的任务。因为安全和对齐问题是复杂且主观的,无法通过简单的自动指标完全捕获,所以使用人类偏好作为奖励信号这种技术来微调模型。
整个fine tune过程分为三个步骤(上图是instructGPT训练过程,下图是ChatGPT):
- 首先作者雇佣了40人,对每个prompt,写出期待的输出,用来训练监督学习的baseline。
- 对于更大范围的prompt,对比模型输出和人类标注的输出,从而训练一个奖励模型。
- 使用这个奖励模型做RF来fine-tune第一步生成的baseline,最大化reward。
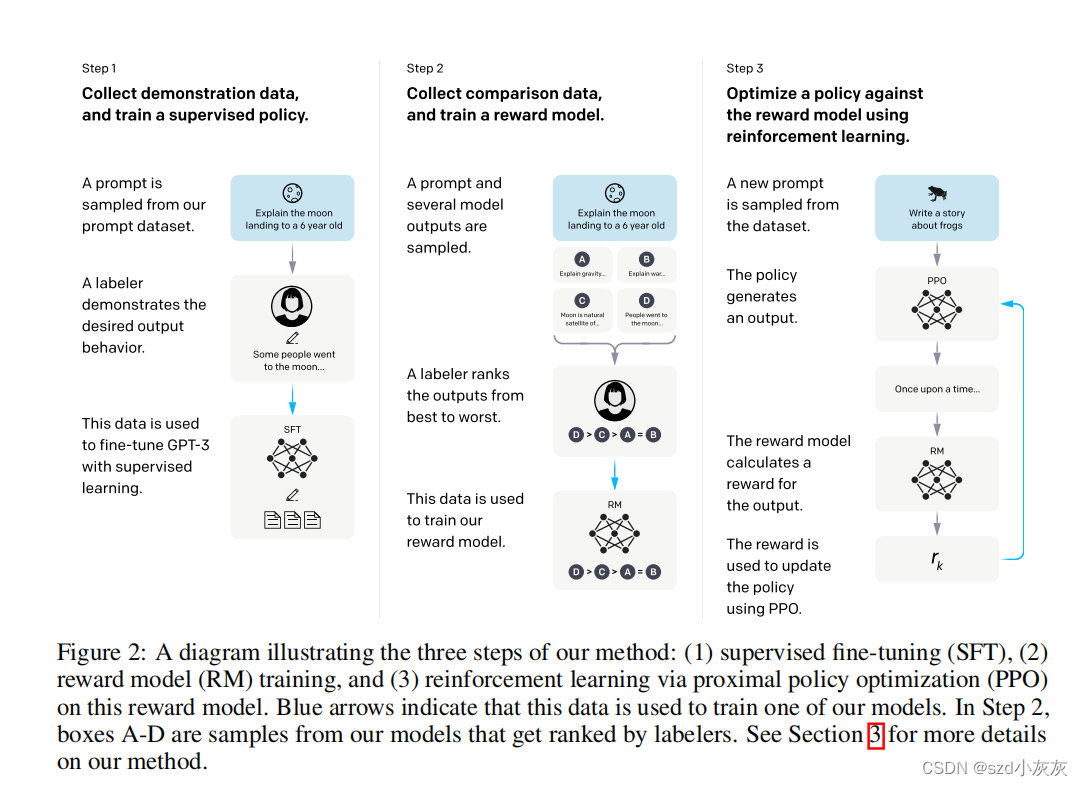
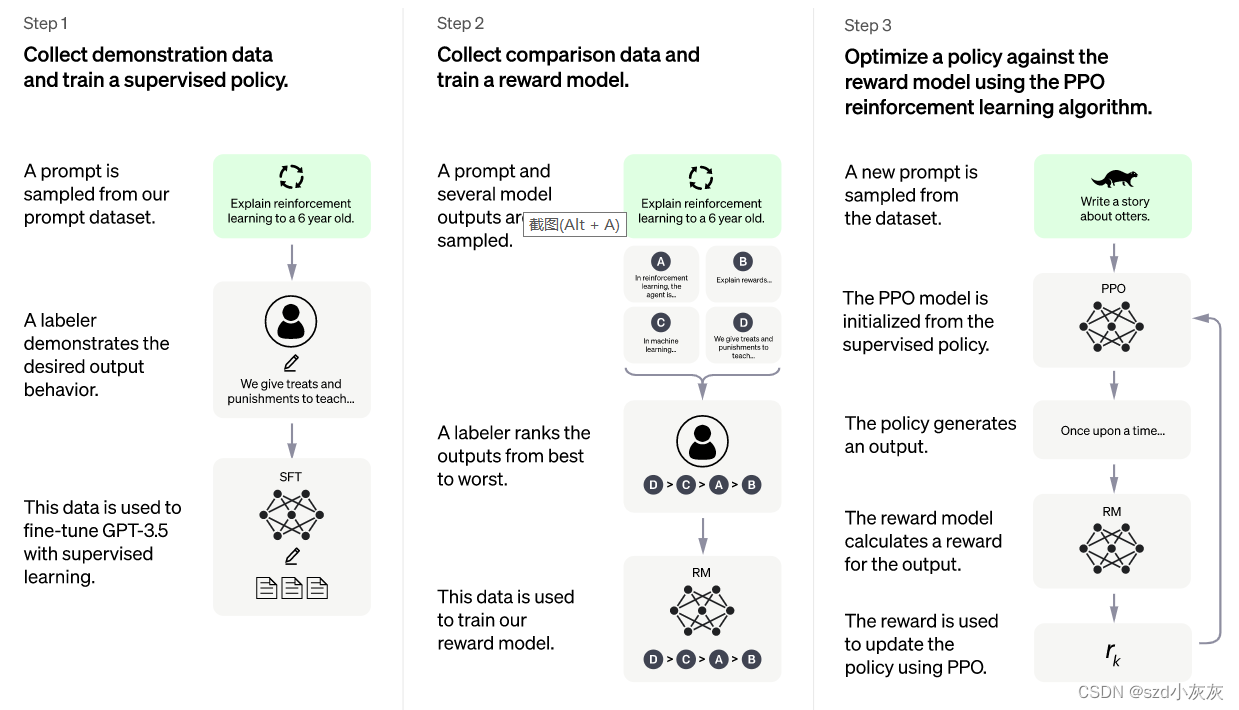
这些步骤具体而言如下:
首先有一个GPT-3模型。第一步SFT(supervised fine-tuning),先简单地微调一下GPT-3,需要人工标注。
- 工程师团队设计了一个prompt dataset,里面有大量的提示文本,这些文本介绍了任务是啥。
- 把这个prompt dataset发给人类标注员进行标注,其实就是回答问题。
- 用这个标注过的数据集微调GPT-3。

第二步,训练一个奖励模型,需要人工标注,目的是让RM模型学习人类导师对GPT-3输出的答案的排序的能力,最终K取的是9,也就是需要对9个输出结果排序,控制好的答案和差的答案之间的奖励分数差要大,使得sigmoid中的差值大,log中的趋于1,损失趋于0。
- 拿这个微调过的GPT-3去预测prompt dataset里面的任务,获得一系列结果,图中是四个。
- 把这四个结果交给人类标注员进行标注,把预测的结果从好到坏进行标注。
- 用这些标注的结果训练一个奖励模型(reward model),这个模型在下一步会用到。

第三步,用PPO持续更新策略的参数,不用任何人工标注。
- 再拿GPT-3预测prompt dataset中的文本,这里GPT-3被一个策略包装并且用PPO更新。
- 用第二步训练好的奖励模型给策略的预测结果打分,用强化学习术语说就是计算reward。
- 这个计算出来的分数会交给包着GPT-3内核的策略来更新梯度。
损失函数
其损失函数包括两部分:基于自然语言的损失函数和基于强化学习的奖励函数。
基于强化学习的奖励函数则是针对模型生成的完整指令序列进行评价,奖励模型生成的指令序列中包含正确的操作,并惩罚模型生成的指令序列中包含错误的操作。具体来说,当模型按照生成的指令成功完成任务时,会给予一个正向的奖励,反之,当模型未能成功完成任务时,会给予一个负向的奖励。这种基于奖励和惩罚的训练方法可以让模型更好地理解任务和环境,从而生成更准确和可执行的指令。
基于自然语言的损失函数主要是通过预测下一个单词的方式,来训练模型的语言生成能力。该损失函数通常使用交叉熵作为度量标准,计算模型预测下一个单词与实际下一个单词之间的差距,进而更新模型的参数,提高模型生成下一个单词的准确性。
在训练过程中,基于自然语言的损失函数和基于强化学习的奖励函数会同时计算,二者的权重可以通过调整超参数来控制。模型的训练过程是通过不断迭代,更新模型参数,使模型生成的指令序列更加准确和可执行。

总结来看
就是结合了监督学习和强化学习。监督学习先让GPT-3有一个大致的微调方向,强化学习用了AC(Actor-Critic)架构里面的近端策略优化PPO(Proximal Policy Optimization)更新方法来更新GPT-3的参数。PPO是OpenAI的baseline method,可以说使用PPO是InstructGPT非常自然的一个选择。
模型评估
主要通过让贴标机对测试集上模型输出的质量进行评分来评估模型,还对一系列公共 NLP 数据集进行自动评估。 本文训练三种模型尺寸(1.3B、6B 和 175B 参数),所有的模型都使用 GPT-3 架构。 主要发现如下:
- 1.3B 参数 InstructGPT 模型的输出优于 175B GPT-3 的输出,且参数少了 100 多倍。 这些模型具有相同的架构,唯一不同的是 InstructGPT 是根据人类数据进行微调的。
- InstructGPT 模型在真实性方面比 GPT-3 强。
- InstructGPT 与 GPT-3 相比有害性上略有改善,但偏差并没有改善。
- 可以通过修改RLHF 微调程序来最小化公共 NLP 数据集的性能回归。(性能回归测试regression
tests是一种比较方法,用于检查软件应用程序在连续构建中的性能。通俗地讲,如果第二个版本基于第一个版本之上,那么认为第二个版本在几乎所有指标上都取得比第一个版本更好的性能,才算通过第二个版本的性能回归测试。) - 模型不产生任何训练数据的“保留”标签的偏好。
- InstructGPT 模型显示了对 RLHF 微调分布之外的指令的有前途的泛化。
- InstructGPT 仍然会犯一些简单的错误。 例如,InstructGPT
仍然可能无法遵循指令、编造事实、对简单问题给出长对冲答案,或者无法检测到带有错误前提的指令。
未来改进方向
- 可以尝试许多方法来进一步降低模型产生有毒、有偏见或其他有害输出的倾向。
- 可以将本文方法与过滤预训练数据的方法结合起来,或者用于训练初始预训练模型,或者用于本文用于预训练混合方法的数据。
- 同样,可以将本文的方法与提高模型真实性的方法结合起来。
- 使用语言模型生成有毒输出作为数据增强管道的一部分可能是有效的。
- 虽然本文主要关注 RLHF,但还有许多其他算法可用于训练策略以获得更好的结果。
- 比较也不一定是提供对齐信号的最有效方式。 例如,可以让标记者编辑模型响应以使其更好,或者用自然语言生成对模型响应的评论。
- 为标注者设计界面以向语言模型提供反馈也有广阔的选择空间。
- 另一个可能改进的修改方法是过滤预训练混合数据中的有毒内容,或使用合成指令扩充此数据。

