
- 1车道线检测数据集介绍
- 2NLP 中文同义词 反义词 否定词表_否定词表txt
- 3Atomikos多数据源配置项目实例_atomikosdatasourebean 'tifarecorddatasource': pool
- 4C#OpenCvSharp YOLO v3 Demo
- 5Oracle ASM 磁盘组详解_asmca high normal esternal
- 6【深度学习】问答系统与知识图谱:自然语言处理应用案例_自然语言处理问答系统
- 7Edge游览器,新插件WeTab标签页_wetab怎么在edge中打开
- 8探索Sora:AI视频模型的创新与未来展望
- 9【AI大模型应用开发】【RAG优化 / 前沿】0. 综述:盘点当前传统RAG流程中存在的问题及优化方法、研究前沿_rag中文档加载loader的优化
- 10编码器与解码器LLM全解析:掌握NLP核心技术的关键!_llm 编码和解码
向量数据库介绍_什么业务会用向量数据库
赞
踩
1.什么是向量数据
向量数据库是一种专门用于存储和检索向量数据的数据库。它不同于传统的关系型数据库,而是基于向量相似度匹配的方式来实现高效的数据查询和分析。
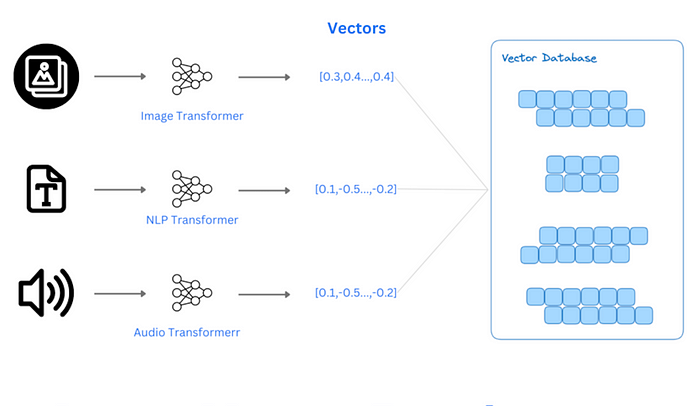
2.向量数据库的应用场景
2.1 应用场景概览
向量数据库是一种专门用于存储和检索向量数据的数据库,它可以处理高维稠密和稀疏向量数据,对于数据量大、数据维度高、需要实时检索和相似度匹配的场景非常适用。以下是一些常见的向量数据库应用场景:
-
图像、音频和视频检索:向量数据库可以根据相似度来检索图片、音频和视频资料,用于图像识别、音频识别、视频识别等应用。
-
自然语言处理:向量数据库可以存储和检索大量的文本数据,用于自然语言处理领域的文本分类、聚类和相似度计算等。
-
推荐系统:向量数据库可以存储和检索用户行为数据和商品特征向量,用于推荐系统的商品推荐、用户画像和个性化推荐等。
-
医疗领域:向量数据库可以存储和检索医疗图像和病历数据,用于医疗图像诊断、病历分类和病情分析等应用。
-
金融领域:向量数据库可以存储和检索金融数据,用于金融风控、股票分析和交易策略等应用。
-
搜索引擎:向量数据库可以存储和检索网页、图片等数据,用于搜索引擎的文本和图像
2.2 向量数据库在人工智能领域的应用
向量数据库被广泛地用于大模型训练、推理和知识库补充等场景:支撑训练阶段海量数据的分类、去重和清洗,给大模型的训练降本增效;通过新数据的带入,帮助大模型提升处理新问题的能力,突破预训练带来的知识时间限制,避免大模型出现幻觉;提供一种私有数据连接大模型的方式,解决私有数据注入大模型带来的安全和隐私问题,加速大模型在产业落地。
简而言之,向量数据库可以解决大模型预训练成本高、没有“长期记忆”、知识更新不足、提示词工程复杂等问题,突破大模型在时间和空间上的限制,加速大模型落地行业场景。
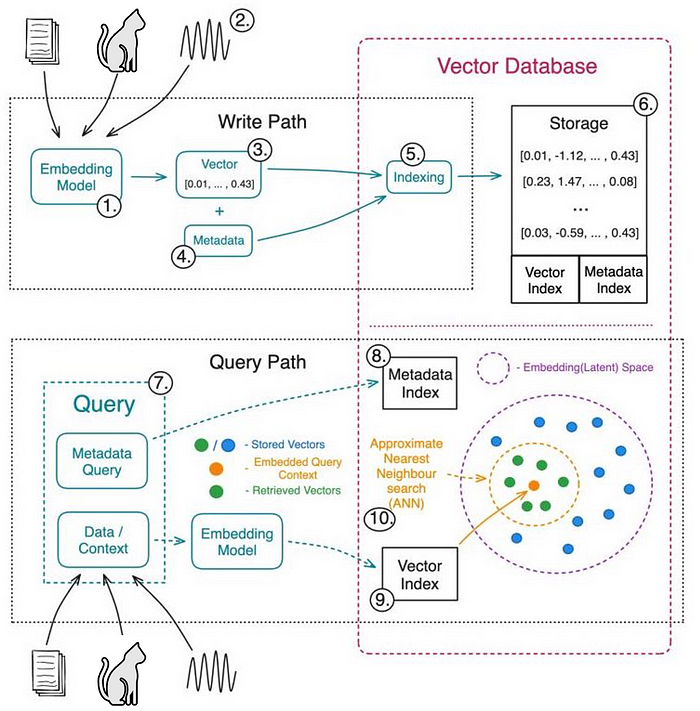
3.向量数据库的使用
3.1 向量数据库产品
目前市场上有很多向量数据库产品,以下是一些比较知名的向量数据库产品:
-
Milvus:由开源社区提供的向量数据库,支持高维向量数据存储、检索和相似度匹配,可应用于图像、音频、自然语言处理等多个领域。
-
Faiss:由Facebook开发的向量数据库,支持高效的向量相似度计算和查询,是图像检索、自然语言处理等领域的重要工具。
-
Annoy:也是一款开源的向量数据库,支持快速的近似最近邻搜索和低维向量数据的可视化,可应用于推荐系统、计算机视觉等领域。
-
TencentCloud Vector Database:由腾讯云提供的向量数据库,支持高维向量数据存储、检索和相似度匹配,可应用于推荐系统、金融风控等领域。
-
MilvusDB:由Zilliz公司开发的向量数据库,支持高维向量数据存储、检索和相似度匹配,可应用于图像、音频、自然语言处理等多个领域。
3.2 选择向量数据库时考虑哪些因素
-
数据存储和检索效率:好的向量数据库应当具有高效的数据存储和检索能力,能够快速地存储和检索大量的向量数据。
-
相似度匹配精度:好的向量数据库应当具有高精度的相似度匹配能力,能够准确地计算和返回最相似的向量数据。
-
支持的向量数据类型和维度:好的向量数据库应当支持多种向量数据类型和高维向量数据存储和检索,能够满足不同场景的需求。
-
可扩展性和易用性:好的向量数据库应当具有良好的可扩展性和易用性,能够方便地集成到现有系统中,支持横向和纵向扩展。
-
安全性和稳定性:好的向量数据库应当具有高度的安全性和稳定性,能够保障数据的安全和稳定的运行。
综合以上几个方面,可以评估一个向量数据库的好坏。另外,需要根据不同的应用场景和需求,选择适合的向量数据库产品。
4.使用示例-PostgreSQL向量扩展
pgvector 是一个基于 PostgreSQL 的扩展,为用户提供了一套强大的功能,用于高效地存储、查询和处理向量数据。它具有以下特点:
-
直接集成:pgvector 可以作为扩展直接添加到现有的 PostgreSQL 环境中,方便新用户和长期用户获得矢量数据库的好处,无需进行重大系统更改。
-
支持多种距离度量:pgvector 内置支持多种距离度量,包括欧几里德距离、余弦距离和曼哈顿距离。这样的多功能性使得可以根据具体应用需求进行高度定制的基于相似性的搜索和分析。
-
索引支持:pgvector 扩展为矢量数据提供高效的索引选项,例如 k-最近邻 (k-NN) 搜索。即使数据集大小增长,用户也可以实现快速查询执行,并保持较高的搜索准确性。
-
易于查询语言访问:作为 PostgreSQL 的扩展,pgvector 使用熟悉的 SQL 查询语法进行向量操作。这简化了具有 SQL 知识和经验的用户使用矢量数据库的过程,并避免了学习新的语言或系统。
-
积极的开发和支持:pgvector 经常更新,以确保与最新的 PostgreSQL 版本和功能兼容,并且开发者社区致力于增强其功能。用户可以期待一个受到良好支持的解决方案,满足其矢量数据的需求。
-
稳健性和安全性:通过与 PostgreSQL 的集成,pgvector 继承了相同级别的稳健性和安全性功能,使用户能够安全地存储和管理其矢量数据。
总之,pgvector 是一个功能强大的 PostgreSQL 扩展,为用户提供了高效、灵活和可靠的方式来处理向量数据。它的直接集成、多种距离度量支持、索引支持和易于访问的查询语言使其成为处理矢量数据的理想选择。
4.1 使用示例
使用类型为 vector(3) 的 embedding 列创建 tblvector 表。 这样定义,它在三维平面中表示为 three coordinates,这有助于评估向量的位置。
(1)新建表
- CREATE TABLE tblvector(
- id bigserial PRIMARY KEY,
- embedding vector(3)
- );
(2)数据插入
INSERT INTO tblvector (id, embedding) VALUES (1, '[1,2,3]'), (2, '[4,5,6]'), (3, '[5,4,6]'), (4, '[3,5,7]'), (5, '[7,8,9]');
(3)利用 Insert into ... ON CONFLICT 语句,插入记录,如果存在则更新
- INSERT INTO tblvector (id, embedding) VALUES (1, '[1,2,3]'), (2, '[4,5,6]')
- ON CONFLICT (id) DO UPDATE SET embedding = EXCLUDED.embedding;
(4)删除
DELETE FROM tblvector WHERE id = 1;
(5)若要检索向量并计算相似性,请使用 SELECT 语句和内置向量运算符。 例如,查询会计算给定向量与存储在 tblvector 表中的向量之间的欧几里得距离(L2 距离),根据计算的距离对结果进行排序,并返回最接近的五个最相似的项。
- SELECT * FROM tblvector
- ORDER BY embedding <-> '[3,1,2]'
- LIMIT 5;
(6)使用“<->”运算符穿查询,这是用于计算多维空间中两个向量之间距离的“距离运算符”。 查询返回所有与向量 [3,1,2] 的距离小于 6 的行。
SELECT * FROM tblvector WHERE embedding <-> '[3,1,2]' < 6;
5.总结
最近在学习基于大模型的应用搭建的能力,刚刚碰到了向量数据库这个概念,本文是向量数据库的科普文,介绍了向量数据库的概念、应用场景、选择向量数据库产品的考虑点,最后以PostgreSQL向量扩展示例展示向量数据库的使用。

