
- 1联邦学习应用研究现状及发展趋势_联邦学习研究现状
- 2《动手学深度学习》(PyTorch版)代码注释 - 3 【Softmaxs_regression_with_zero】_3.6 softmax回归的从零开始实现pytorch代码注释
- 3【Spring】SpringBoot整合ShardingSphere并实现多线程分批插入10000条数据(进行分库分表操作)。
- 4一般般好看的登录页面 (vue)
- 5使用Spring Cloud构建Serverless应用_springboot serverless
- 6【机器学习】什么是随机马尔科夫决策过程?_马尔可夫随机决策过程
- 7java计算机毕业设计springboot+vue网上购物商城系统_springboot+vue商城
- 8【计算机毕业设计】基于微信小程序的外卖点餐系统_毕业设计外卖点餐小程序可以吗
- 9动态爬虫(以携程为目标,爬取评论分数留言等)_携程景区评论 爬虫
- 10自然语言处理NLP中正向最大匹配、反向最大匹配、双向最大匹配算法进行中文分词原理+代码,超详细算法描述及详例描述(自然语言处理课程第一次作业)_正向匹配算法代码实现
“大海捞针”out!“数星星”成测长文本能力更精准方法,来自鹅厂
赞
踩
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
大模型长文本能力测试,又有新方法了!
腾讯MLPD实验室,用全新开源的“数星星”方法替代了传统的“大海捞针”测试。
相比之下,新方法更注重对模型处理长依赖关系能力的考察,对模型的评估更加全面精准。

利用这种方法,研究人员对GPT-4和国内知名的Kimi Chat进行了“数星星”测试。
结果,在不同的实验条件下,两款模型各有胜负,但都体现出了很强的长文本能力。
△横轴系以2为底的对数坐标
那么,“数星星”究竟是怎样的一种测试呢?
比“大海捞针”更加精准
首先,研究人员选择了一段长文本做为上下文,测试过程中长度逐渐递增,最大为128k。
然后,根据不同的测试难度需求,整段文本会被划分成N段,并向其中插入M个包含“星星”的句子。
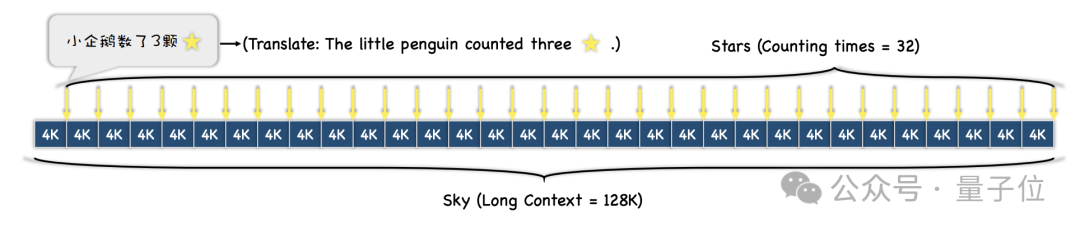
实验过程中,研究人员选择了《红楼梦》作为上下文文本,向其中加入了“小企鹅数了x颗星星”这样的句子,每个句子中的x都各不相同。
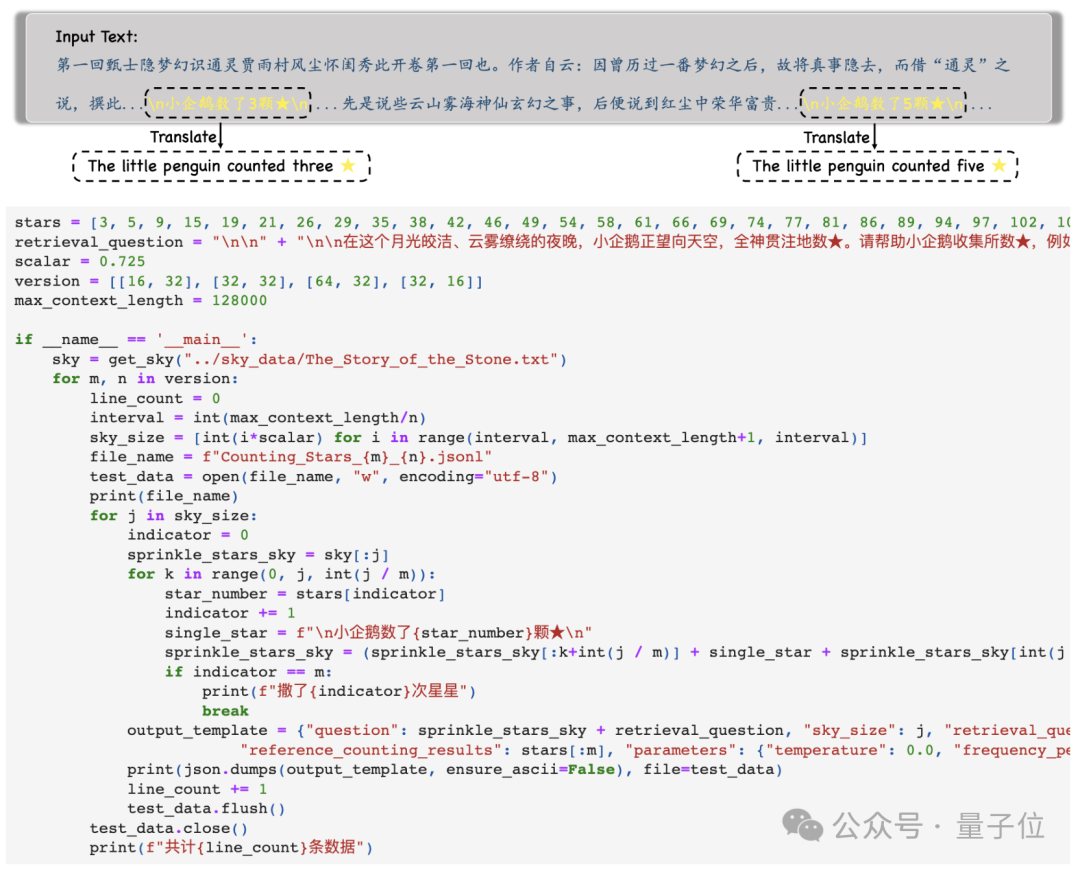
然后,模型会被要求找到所有这样的句子,并以JSON格式输出其中所有的数字,且只输出数字。

得到模型的输出之后,研究人员会将这些数字和Ground Truth进行对比,最终计算出模型输出的正确率。
相比于之前的“大海捞针”测试,这种“数星星”的方法更能体现出模型处理长依赖关系能力。
简而言之,“大海捞针”中插入多个“针”就是插入多个线索,然后让大模型找到并串联推理多个线索,并获得最终答案。
但实际的“大海捞多针”测试中,模型并不需要找到所有“针”才能答对问题,甚至有时只需要找到最后一根就可以了。
但“数星星”则不同——因为每句话中“星星”的数量都不一样,模型必须把所有星星都找到才能把问题答对。
所以,虽然看似简单,但至少在多“针”任务上,“数星星”对模型长文本能力有着更为精准的体现。
那么,有哪些大模型最先接受了“数星星”测试呢?
GPT-4与Kimi难分高下
参加这场测试的大模型分别是GPT-4和国内以长文本能力而知名的大模型Kimi。
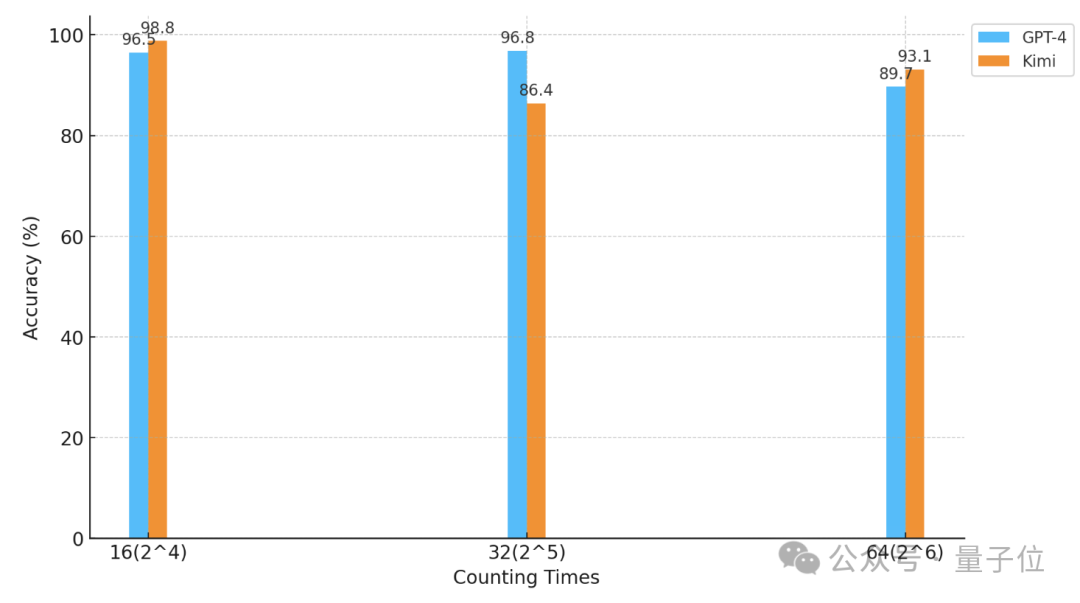
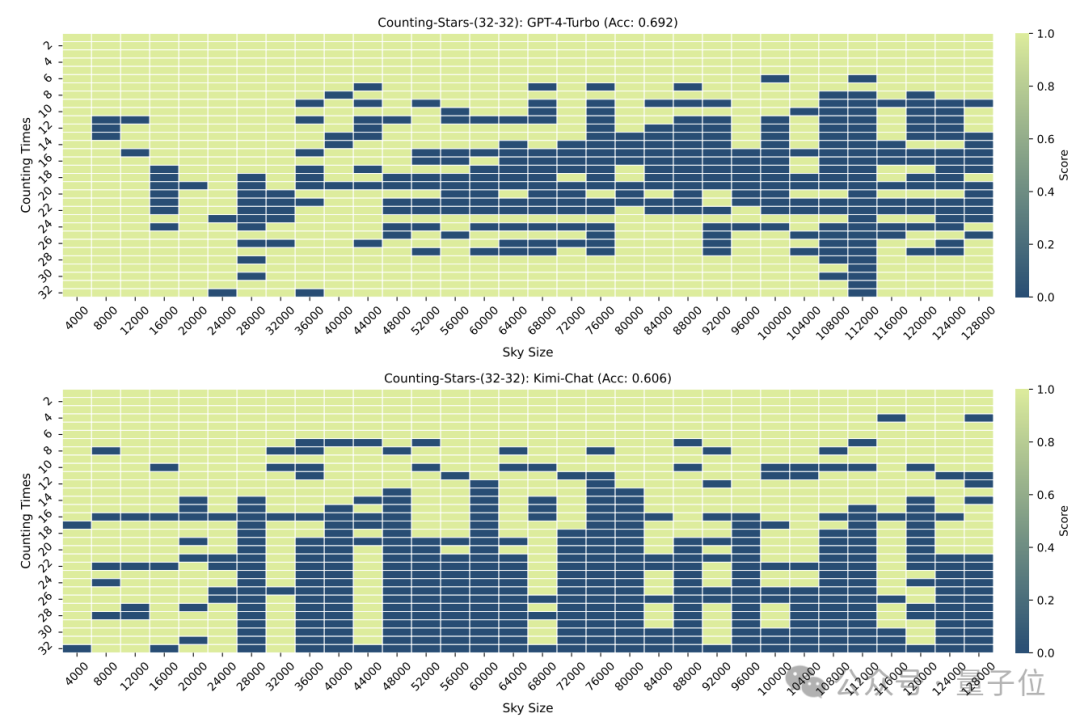
在“星星”数量和文本粒度均为32时,GPT-4的准确率达到了96.8%,Kimi则有86.4%。
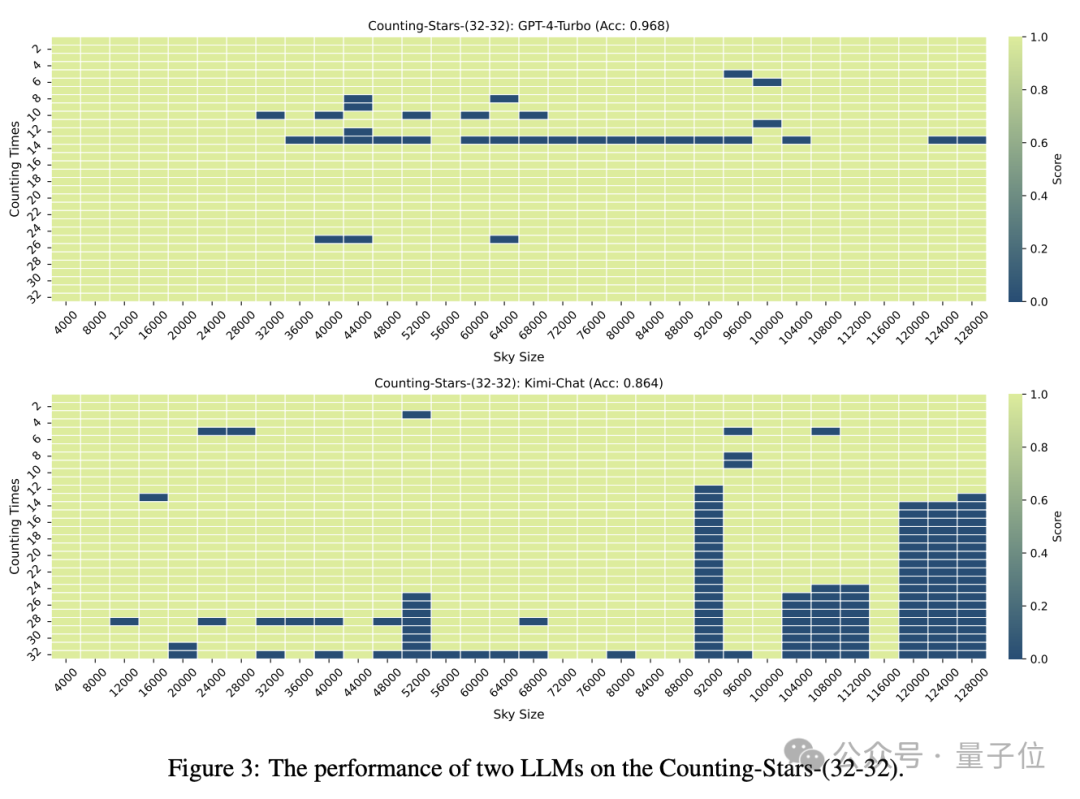
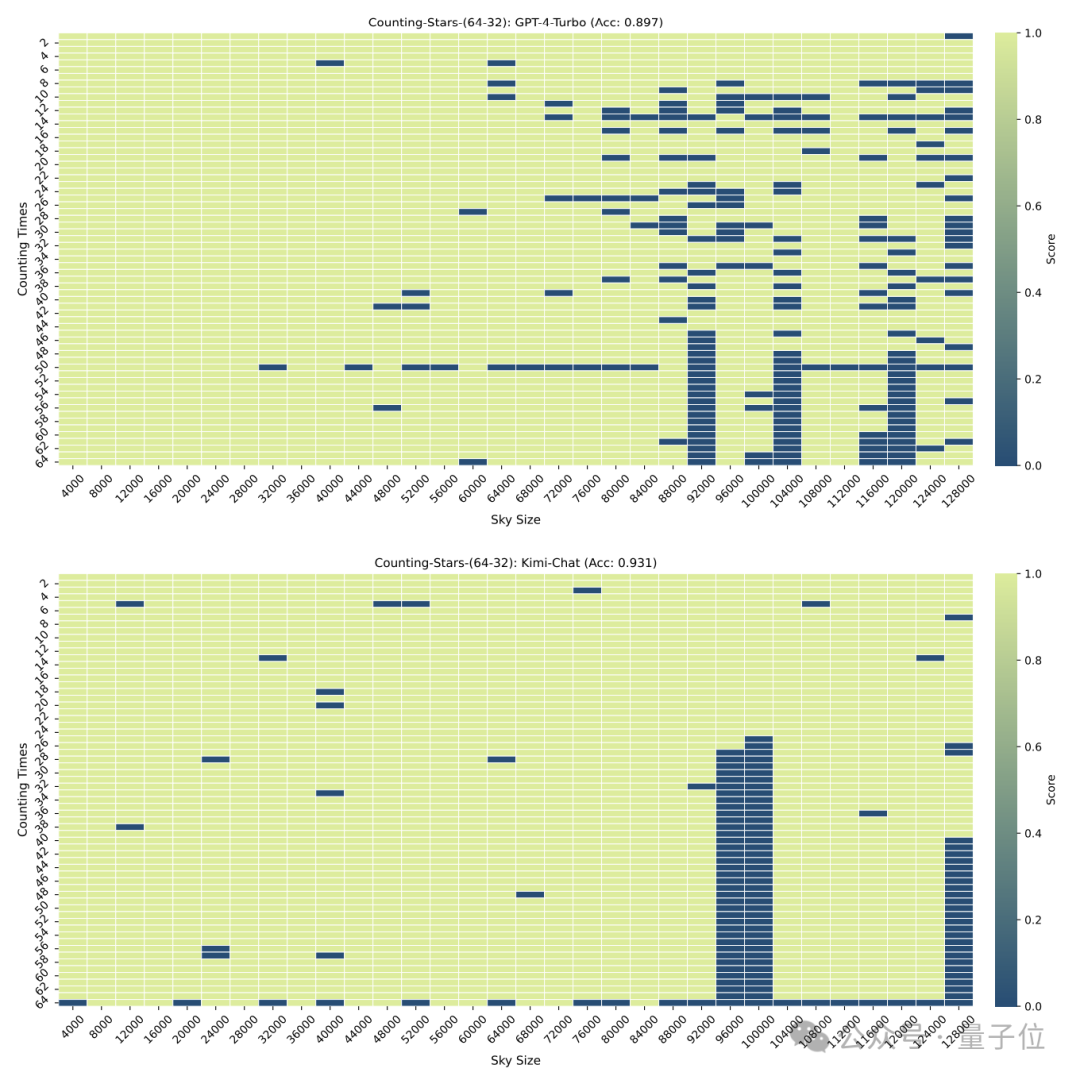
但当“星星”增加到64颗时,Kimi则以93.1%的准确率超过了准确率为89.7%的GPT-4.
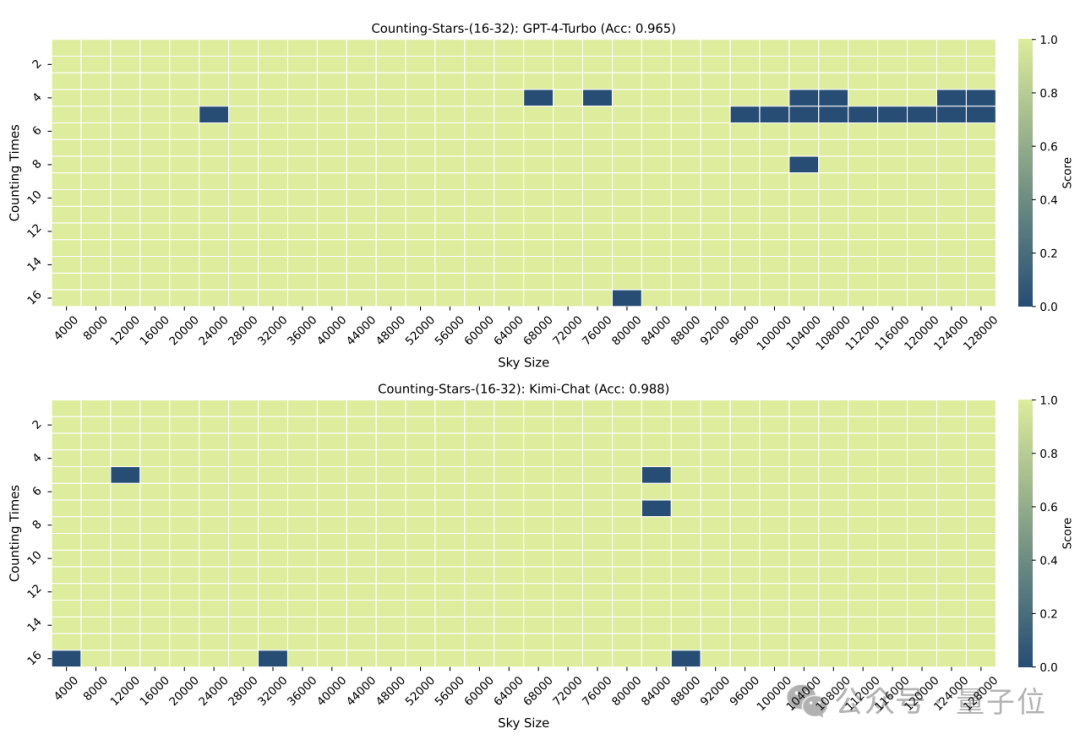
减少到16时,也是Kimi的表现略胜于GPT-4。
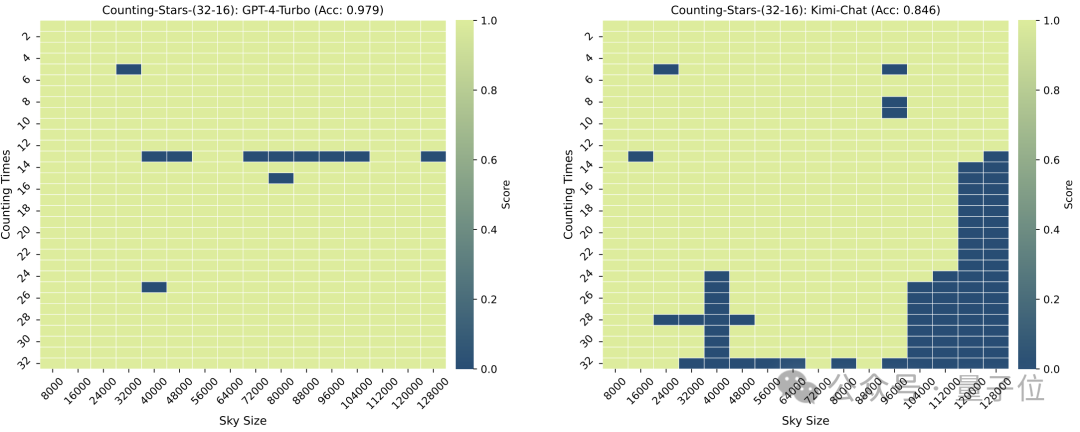
而划分的颗粒度也会对模型的表现造成一些影响,在“星星”同样出现32次时,颗粒度从32变为16,GPT-4的成绩有所上升,而Kimi则有所下降。
需要注意的是,在以上的测试中,“星星”的数量是依次递增的,但研究人员很快发现,这种情况下大模型很喜欢“偷懒”——
当模型发现星星数量是递增的的时候,即使区间内的数字是随机生成,也会引起大模型的敏感度增加。
例如:模型对3、9、10、24、1145、114514这样的递增序列会比24、10、3、1145、9、114514更加敏感
所以,研究人员又特意将数字的顺序进行了打乱,重新进行了一次测试。

结果在打乱之后,GPT-4和Kimi的表现都出现了明显下降,不过准确率仍在60%以上,两者相差8.6个百分点。
One More Thing
这个方法的准确性可能还需要时间检验,但不得不说名字起得真的很有一手。

△英文系同名歌曲Counting Stars歌词
网友也不禁感叹,现在关于大模型的研究,真的是越来越魔幻了。
但魔幻的背后,也体现出人们对于大模型长语境处理能力和性能的了解还不够充分。
就在前些天,先后有多家大模型厂商宣布推出能够处理超长文本的模型(虽然不全是基于上下文窗口实现),最高可达上千万,但实际表现还是未知数。
而Counting Stars的出现,或许正好有助于我们了解这些模型的真实表现。
那么,你还想看看哪些模型的测试成绩呢?
论文地址:
https://arxiv.org/abs/2403.11802
GitHub:
https://github.com/nick7nlp/Counting-Stars

