
- 1java 操作elasticsearch详细总结_elasticsearch java
- 2开发运营必看,跳出雷区必须知道的微信小程序平台运营规范_微信小程序 在采集用户数据之前,必须确保经过用户同意,并向用户如实披露数据用途
- 3<div></div>使用案例_div实例
- 4使用HTTP发送请求,本地没有问题,一到测试环境中就中文乱码_本地请求不乱吗
- 5关于适配不同分辨率的一些心得_设计稿1920怎么适配机型
- 6C程序设计_(3)在一个一维数组a中存放10个正整数,求其中所有的素数。(用数组元素作为函数
- 7关于SpringBoot的application.yml的相关配置(自定义,开发,测试,正式)切换_yml 如何控制测试配置和主配置的切换
- 8太强啦!!!ChatGPT 能上传文件了,能执行 Python 代码啦!_chatgpt file uploader extended
- 9Quartz 任务调度四种触发方式_任务调度的触发方式包括
- 10区块链的数据结构_学习区块链需要学习什么数据结构
预训练权重在不同下游任务中应用的学习笔记_如何保存权重作为预训练
赞
踩
目前在深度学习领域,有诸多通过大规模数据的进行预训练后的模型,如经ImageNet预训练的ResNet、ViT网络,之后在这些预训练模型的基础上迁移到下游任务如目标检测,变化检测,场景识别、语义分割等进行微调可以取得与从0开始训练相当,甚至更优异的效果。不仅省去了预训练时间,而且微调模型的收敛速度较快,所以,了解如何将这些预训练模型完整且有效的迁移是很重要的。
一、预训练权重的保存和加载
1.保存
在深度学习的Pytorch框架中,提供了用于保存模型的函数torch.save()。一般保存的形式有两种,一种仅保存权重文件,另一种包含模型权重和模型结构,如下代码参考所示,导入torchvision库中提供好的模型权重,仅保存模型权重时调用模型的state_dict()方法即可,当然在整个训练过程中,还可以保存优化器等的参数
import torch
import torch.nn as nn
import torchvision.models
models = torchvision.models.resnet18(pretrained=True)
save_path1 = 'D:/pretrained/resnet/model' # 模型和权重保存路径
save_path2 = 'D:/pretrained/resnet/state' # 经权重保存路径
torch.save(models,save_path1) # 保存模型结构和权重
torch.save(models.state_dict(),save_path2) # 保存模型权重
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.加载
通过torch.load()函数加载预训练模型,然后遍历预训练模型关键字将相同取出,最后通过load_state_dict()加载到模型中。
import torch
import torch.nn as nn
import torchvision.models
model_path = 'D:/pretrainedmodel'
model = torchvision.models.resnet18(pretrained=True)
state_dict = torch.load(model_path)
ckpt = {k:v for k,v in state_dict.item() if k in model.state_dict()}
# 遍历预训练模型关键字,如果出现,则保存参数到ckpt
model.load_state_dict(ckpt) # 加载预训练权重
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
一般来说,加载模型的部分通常在模型定义中包含,可以定义初始化权重函数
self.init_weight()
def inite_weight(self):
save_path = 'D:/pretrained'
state_dict = torch.load(save_path)
checkpoints = {k:v for k,v in state_dict.item() if k in model.state_dict()}
# 遍历预训练模型关键字,如果出现,则保存参数到checkpoints
self.load_state_dict(ckpt) # 加载预训练权重
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
二、下游任务上的微调
下游任务的微调主要是通过骨干网络backbone提取特征,然后将所得特征图送入到实现下游任务的网络框架里,训练以得到微调模型
1.变化检测
这里所用变化检测的框架为Bitemporal Image Transformer(BIT),整个BIT分为三部分,Backbone,Bitemporal Image Transformer和Prediction Head,如下图所示
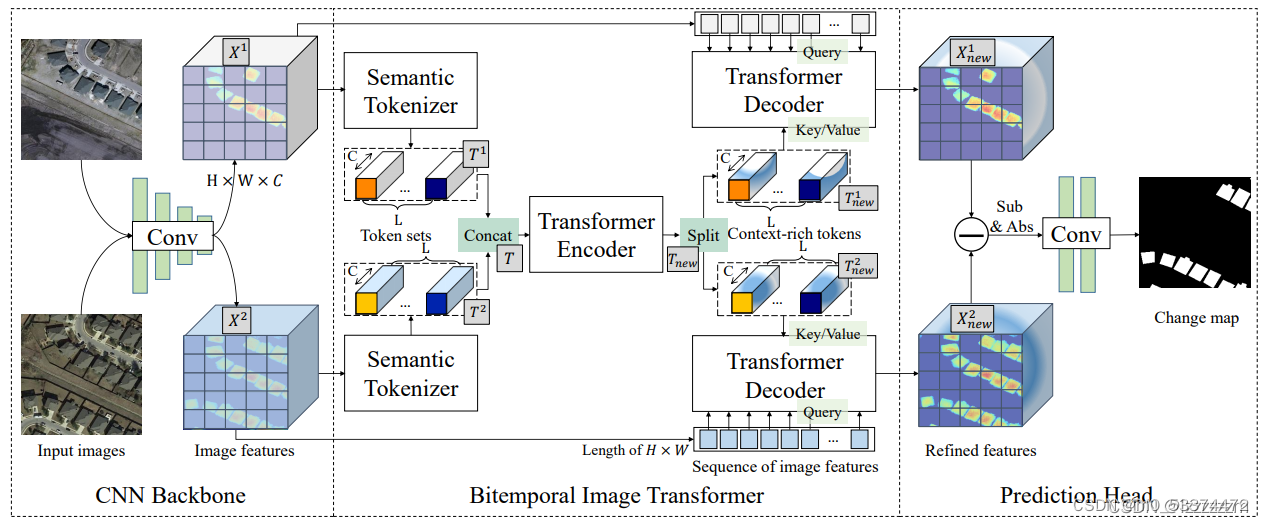
Backbone用于提取两张变化图片的相似特征图,Bitemporal Image Transformer则用于提取特征图之间的变化,Prediction Head则为利用Transormer decoder出来的特征,生成原尺寸的分割图像。
Semantic Tokenizer 实际是将多通道特征图分块,例如将通道数为32的特征图映射成通道数为4的Token,可用1*1的卷积核实现,用于表征实际图像中变化的部分。这里token的长度可调,可以在不同长度下测试模型的表征性能.
Transformer Encoder就是经典的特征提取,Transformer Decoder只是将原始特征图作为q,经Encoder编码的部分作为k,v,可以看做是翻译的过程,q为需要翻译的中文句子,k和v是以前所学到的英语知识。
Prediction Head 将解码出来的特征图取差值绝对值后上采样恢复到原始图像尺寸
如下代码是迁移的模型前向传播,注释解释了各模块
def forward(self, x1, x2): # forward backbone x1 = self.forward_single(x1) x2 = self.forward_single(x2) # 这里调用backbone得到特征图 # forward tokenzier if self.tokenizer: token1 = self._forward_semantic_tokens(x1) token2 = self._forward_semantic_tokens(x2) # 进行Semantic tokenizer else: token1 = self._forward_reshape_tokens(x1) token2 = self._forward_reshape_tokens(x2) # forward transformer encoder if self.token_trans: self.tokens_ = torch.cat([token1, token2], dim=1) self.tokens = self._forward_transformer(self.tokens_) # Transformer编码模块 token1, token2 = self.tokens.chunk(2, dim=1) # 在给定维度(轴)上将输入张量进行2分块 # forward transformer decoder if self.with_decoder: x1 = self._forward_transformer_decoder(x1, token1) x2 = self._forward_transformer_decoder(x2, token2) # Tranformer解码模块,输入为编码器得到的token和原始特征图x else: x1 = self._forward_simple_decoder(x1, token1) x2 = self._forward_simple_decoder(x2, token2) # feature differencing x = torch.abs(x1 - x2) # 差值绝对值 if self.if_upsample_2x: x = self.upsamplex2(x) x = self.upsamplex4(x) # 上采样恢复原始图像尺寸 # forward small cnn x = self.classifier(x) # 简单的两层卷积分类,最后输出特征图为B,2,img_size,img_size # 2个原始尺寸的特征图显示了像素的相似性和不同 if self.output_sigmoid: x = self.sigmoid(x) return x # 最后取得到2个特征图中每点的最大值或者最小值索引即可标注出变化区域

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
Semantic tokenizer模块实现函数
def _forward_semantic_tokens(self, x):
b, c, h, w = x.shape # 分别为Batch,Channel,height,width
spatial_attention = torch.nn.Conv2d(in_c,token_len,kernel_size=1)(x)
# 多通道特征图分块,token_len为分块后的长度
spatial_attention = spatial_attention.view([b, self.token_len, -1]).contiguous()
# 维度变化为 b,token_len,(h*w)
spatial_attention = torch.softmax(spatial_attention, dim=-1)
x = x.view([b, c, -1]).contiguous() # 维度变换为B,C,(h*w)
tokens = torch.einsum('bln,bcn->blc', spatial_attention, x)
# 进行矩阵乘积
return tokens
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

图一

图二

标签结果

模型预测结果
2.场景识别
同样是通过预训练的骨干网络得到特征图,由于大多数预训练的任务是图像分类,所学习的到的特征和场景识别任务很接近,故简单场景识别的方式直接通过线性映射得到结果
self.head = nn.Linear(in_dim, num_classes)
def forward(self, x):
x = self.forward_features(x)
# 通过backbone得到特征图
x = self.head(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
总结
通过上述对预训练模型权重在下游任务迁移的例子,逐渐可以尝试修改backbone,预训练自己的模型,并进一步可以尝试创新下游任务框架,进行更深入的探索。

