
热门标签
热门文章
- 1osg::Node osg::Group osg::Switch osg::MatrixTransform类接口说明_osg的group无法再套入transformer
- 2ChatGPT PLUS 团队版 和 ChatGPT PLUS 比较_gptplus团队版更便宜么
- 3机器学习导论:概念、分类与应用场景
- 4【BIM+GIS】Supermap加载实景三维倾斜摄影模型_supermap打开osgb
- 5STM32固件库点亮LED灯_include“led.h”找不到库
- 64、Yarn资源隔离_yarn 申请资源不被控制
- 7咱们程序员,能吵吵就别动手!现在靠说就可以编程,支持Java、Python等10种语言|免费...
- 8【Fitten Code】“吊打“Github Copilot的国内免费代码辅助插件
- 9推荐一款开源项目:SD-WebUI-ControlNet - 简单、高效的Web界面控制网络工具
- 10感知机与BP算法_bp神经网络与多层感知机制的关系
当前位置: article > 正文
NLP入门学习历程(1):TF-IDF及关键词提取应用改进_tfidf 需要语料库吗
作者:不正经 | 2024-04-07 07:23:21
赞
踩
tfidf 需要语料库吗
NLP 入门
TF-IDF
1.TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
2.计算公式:TF-IDF=tf*idf
TF-IDF=某文档中某词或字出现的次数/该文档的总字数 或总词数 * log(全部文档的个数/(包含该词或字的文档的篇数)+1)
TF(Term Frequency)-单词频率
- TF假设:单词再这部片文档中的的重要程度与单词在文档中出现的次数成正比。比如,“Car” 这个单词在文档 A 里出现了 5 次,而在文档 B 里出现了 20 次,那么 TF 计算就认为“Car”与文档 B 可能更相关。
- 仅有TF不能比较完整地描述文档的相关度。有一些单词可能会比较自然地在很多文档中反复出现,比如英语中的 “The”、“An”、“But” 等等。如果我们要搜索 “How to Build A Car” 这个关键词,其中的 “How”、“To” 以及 “A” 都极可能在绝大多数的文档中出现,这个时候 TF 就无法帮助我们区分文档的相关度了。
- TF计算公式

IDF(Inverse Document Frequency)-逆文档频率
- “惩罚”(Penalize)那些出现在太多文档中的单词。如果有太多文档都涵盖了某个单词,这个单词也就越不重要,或者说是这个单词就越没有信息量。
- 计算公式:某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。这里取了倒数,可以解释为数值越大(在总的语料库的各个文档(分类)出现次数越多,越不重要)

TF-IDF
1.很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况
2. 不足:没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的;按照传统TF-IDF,往往一些生僻词/的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键;对于文档中出现次数较少的重要人名、地名信息提取效果不佳
改进的TF-IDF关键词提取方法 ---- TF-IWF
1.改变词频求解方法:按照位置进行加权处理

统计词频,以三元组形式保存;计算相似度,并将相似度>0.85的以四元组保存,并搜索wj,将其在三元组删除

在三元组中搜索四元组中的wi,并将其词频进行替换。

2. 公式改进,针对于同类语料库中弊端很大的问题,一些同类文本的关键词往往会被掩盖,比如语料库中的文档都是关于医药的,那每篇文章确实应该出现很多医药的关键词,但此时通过逆文档频率(每一篇中关于医药的关键词都很多),将本应该作为关键词的词语的权重降低了。

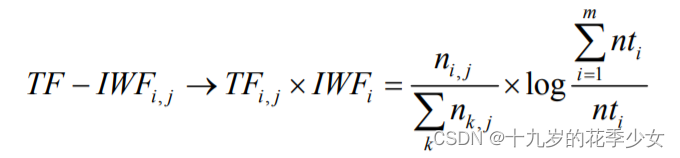
参考文献
TF-IDF 关键词提取改进论文
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/377208
推荐阅读
相关标签

