
- 1教你如何使用esp8266接入华为云物联网平台(IOTDA)(Arduino IDE开发)
- 2渗透测试-木马免杀的几种方式_渗透免杀方法
- 3#33 mystrcpy_实现字符串的拷贝。 void my_strcpy(char * destination,char *
- 4C++:类的封装_c++类封装
- 5感知喜怒哀乐:用深度学习构建声音情感传感器
- 6服务器的负载均衡_负载均衡服务器
- 7蓝桥杯重点(C/C++)_蓝桥杯c++帮助文档
- 8Linux:入门篇
- 9写一个Python程序计算身体质量指数BMI_p106 实例代码5.2, 计算bmi
- 10leetcode:84. 柱状图中最大的矩形面积_leetcode 84
Flink学习3-WordCount词频统计_flink统计文本中单词出现的次数
赞
踩
基于Flink开发环境,接下来我们将完成Flink版本的词频统计程序,主要内容如下:
- 需求描述
- 功能设计
- 功能开发
- 需求升级
针对以上几个步骤,下面将详细展开,读者可根据自身情况有选择阅读。
1. 需求描述
输入几行句子,统计并输出句子中每个单词出现的次数,词与词之间通过空格分割。
2. 功能设计
根据以上描述,词频统计程序主要包含数据读取、分词、统计和输出四个子模块。
3. 功能开发
正式开发前还需要选择Flink处理模式,Flink是流批一体的大数据计算引擎,既支持流处理,也支持批处理,区别在这里就不再赘述,具体到这个需求,很显然采用批处理模式更合适,不过也可以采用流处理模式,相关实现后续会给出。
3.1 新建WorkCount项目
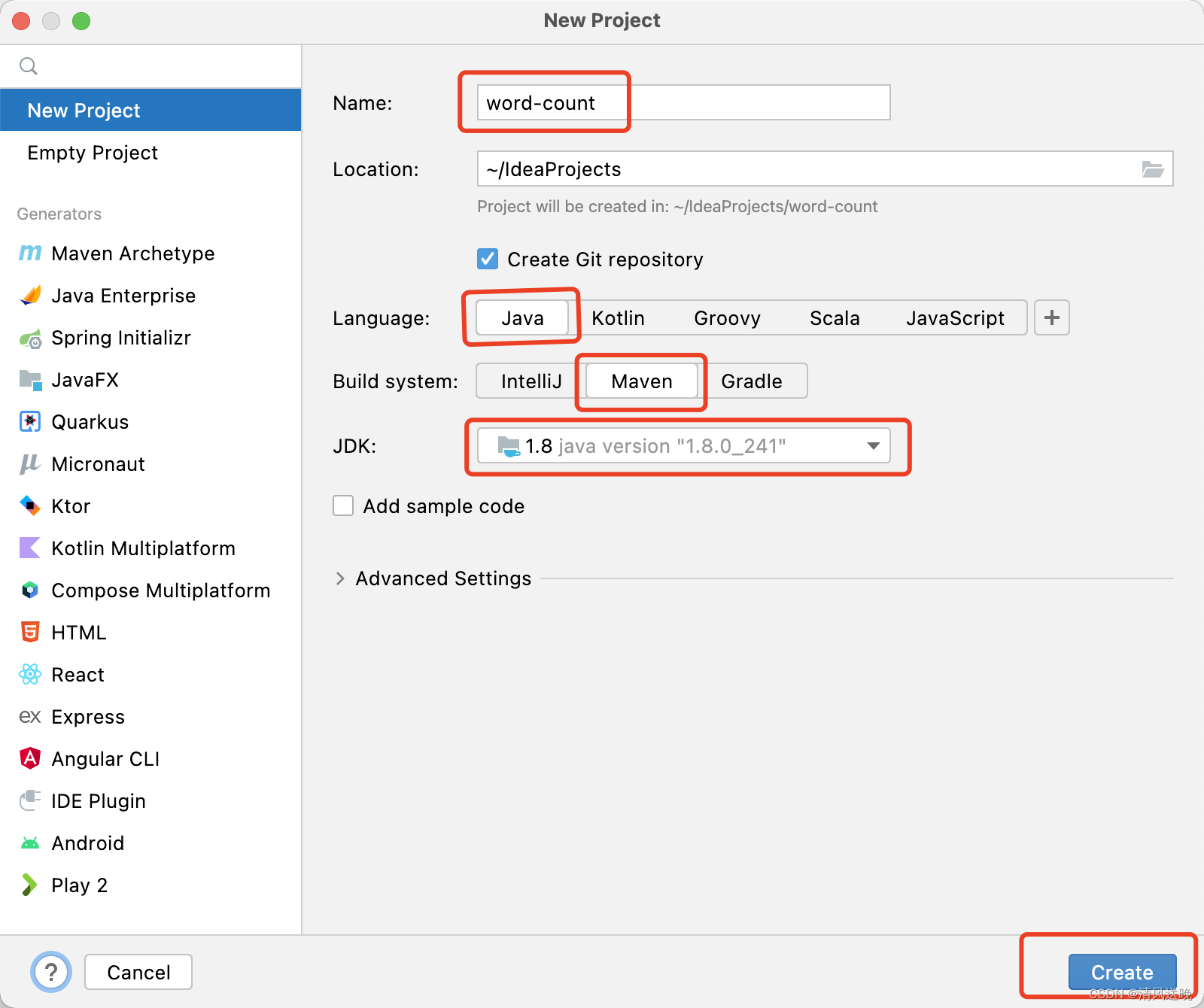
(1)打开IntelliJ IDEA,选择New Project,注意红框标识出来的地方,选择创建
(2)依次展开src/main/java,右键选择New Package, 输入自己想要的包名,多级包名中间用.分割,Idea支持一次性创建多级包名。
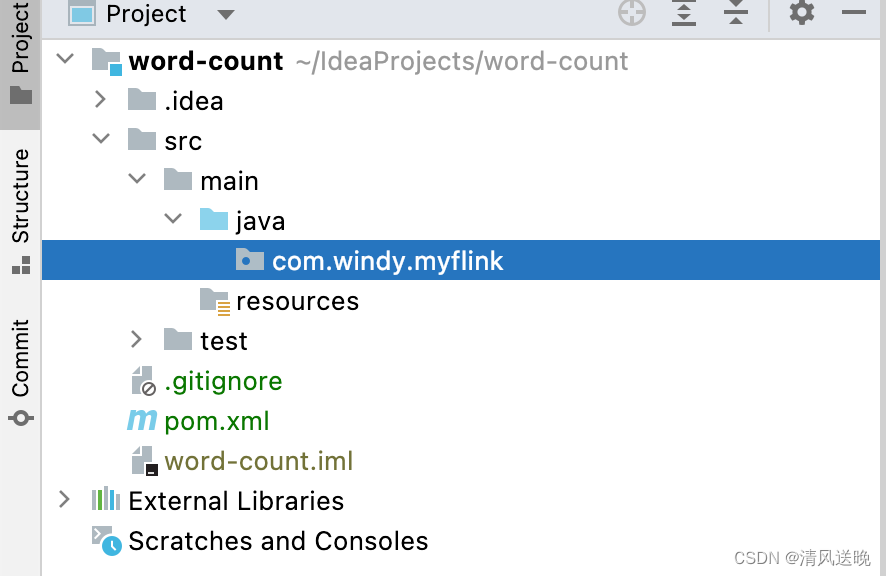 (3)在com.windy.myflink 包名上右键,新建WordCount类
(3)在com.windy.myflink 包名上右键,新建WordCount类

(4)双击打开WordCount.java文件,加入main方法,打印语句,源码如下:
- package com.windy.myflink;
-
- public class WordCount {
- public static void main(String[] args) {
- System.out.println("Hello, Flink");
- }
- }
(5) 打开pom.xml文件,配置参数如下
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
-
- <groupId>org.example</groupId>
- <artifactId>word-count</artifactId>
- <version>1.0-SNAPSHOT</version>
-
- <properties>
- <maven.compiler.source>8</maven.compiler.source>
- <maven.compiler.target>8</maven.compiler.target>
- </properties>
-
- <build>
- <sourceDirectory>${basedir}/src/main/java</sourceDirectory>
- <plugins>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-compiler-plugin</artifactId>
- <version>3.8.1</version>
- <configuration>
- <source>1.8</source>
- <target>1.8</target>
- <compilerVersion>1.8</compilerVersion>
- </configuration>
- </plugin>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-assembly-plugin</artifactId>
- <version>3.0.0</version>
- <configuration>
- <descriptorRefs>
- <descriptorRef>jar-with-dependencies</descriptorRef>
- </descriptorRefs>
- </configuration>
- <executions>
- <execution>
- <id>make-assembly</id>
- <phase>package</phase>
- <goals>
- <goal>single</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- </plugins>
- </build>
- </project>

(6)在当前工程目录下执行mvn package生成jar包,然后运行输出Hello, Flink
- java -cp target/word-count-1.0-SNAPSHOT.jar com.windy.myflink.WordCount
-
- // Output:Hello, Flink
3.2 基于Flink批处理的词频统计
(1)为了使用Flink框架,需要引入Flink相关Jar包,修改pom.xml,加入如下内容
- <dependencies>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>1.13.2</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.12</artifactId>
- <version>1.13.2</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients_2.12</artifactId>
- <version>1.13.2</version>
- </dependency>
- </dependencies>
(2)展开右上角Maven工具栏,执行maven package, 刷新即可在左侧出现依赖Jar包,这样我们就可以在代码中直接引入flink相关的组件了。
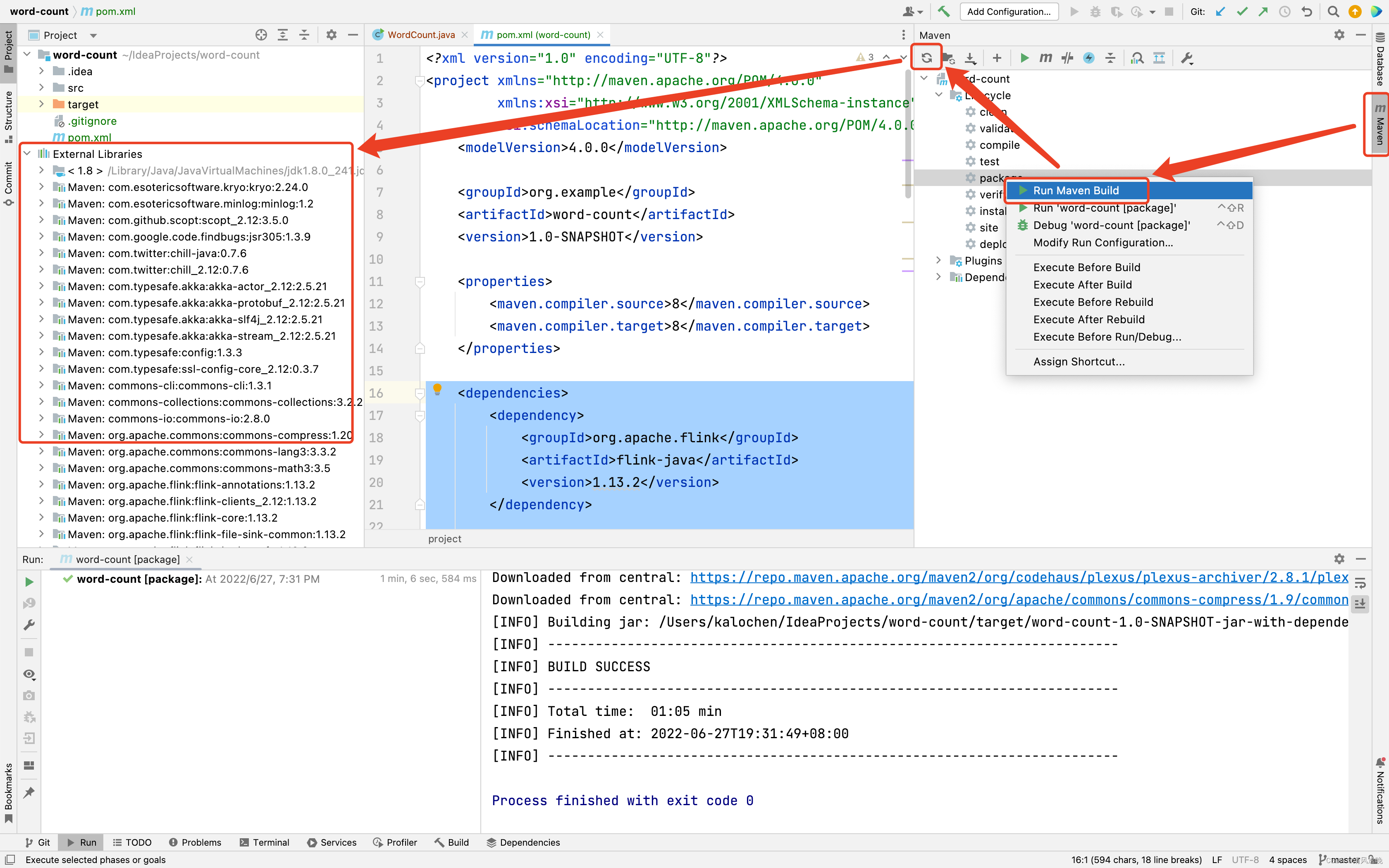
(3)打开WordCount.java,加入词频统计的核心逻辑,这里我直接选择fromElenents接口从字符串中读取句子进行词频统计,修改后的代码如下。
- package com.windy.myflink;
-
- import org.apache.flink.api.common.functions.FlatMapFunction;
- import org.apache.flink.api.java.DataSet;
- import org.apache.flink.api.java.ExecutionEnvironment;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.util.Collector;
-
- public class WordCount {
- public static void main(String[] args) throws Exception {
- ExecutionEnvironment setEnv = ExecutionEnvironment.getExecutionEnvironment();
- DataSet<String> dataSet = setEnv.fromElements("Hello world", "Hello flink");
- dataSet.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
- @Override
- public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
- String[] fields = s.toLowerCase().split("\\s");
- for (String field : fields) {
- collector.collect(new Tuple2<>(field, 1));
- }
- }
- }).groupBy(0).sum(1).print();
- }
- }
相关算子说明如下:
- flatMap:一对多转换操作,输入句子,输出分词后的每个词
- groupBy:按Key分组,0代表选择第1列作为Key
- sum:求和,1代表按照第2列进行累加
- print:打印最终结果
(4)打包运行,这里如果直接mvn package,运行生成的Jar包,会报如下错误:org.apache.flink.client.program.ProgramInvocationException: Neither a 'Main-Class', nor a 'program-class' entry was found in the jar file.
- flink run target/word-count-1.0-SNAPSHOT-jar-with-dependencies.jar
-
- ------------------------------------------------------------
- The program finished with the following exception:
-
- org.apache.flink.client.program.ProgramInvocationException: Neither a 'Main-Class', nor a 'program-class' entry was found in the jar file.
- at org.apache.flink.client.program.PackagedProgram.getEntryPointClassNameFromJar(PackagedProgram.java:437)
- at org.apache.flink.client.program.PackagedProgram.<init>(PackagedProgram.java:158)
- at org.apache.flink.client.program.PackagedProgram.<init>(PackagedProgram.java:65)
- at org.apache.flink.client.program.PackagedProgram$Builder.build(PackagedProgram.java:691)
- at org.apache.flink.client.cli.CliFrontend.buildProgram(CliFrontend.java:875)
- at org.apache.flink.client.cli.CliFrontend.getPackagedProgram(CliFrontend.java:272)
- at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:246)
- at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1078)
- at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1156)
- at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
- at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1156)
- KALOCHEN-MB0:word-count kalochen$
正确打包方式如下:
- 选择File => Project Structure => Artifacts => JAR => From modules with dependencies
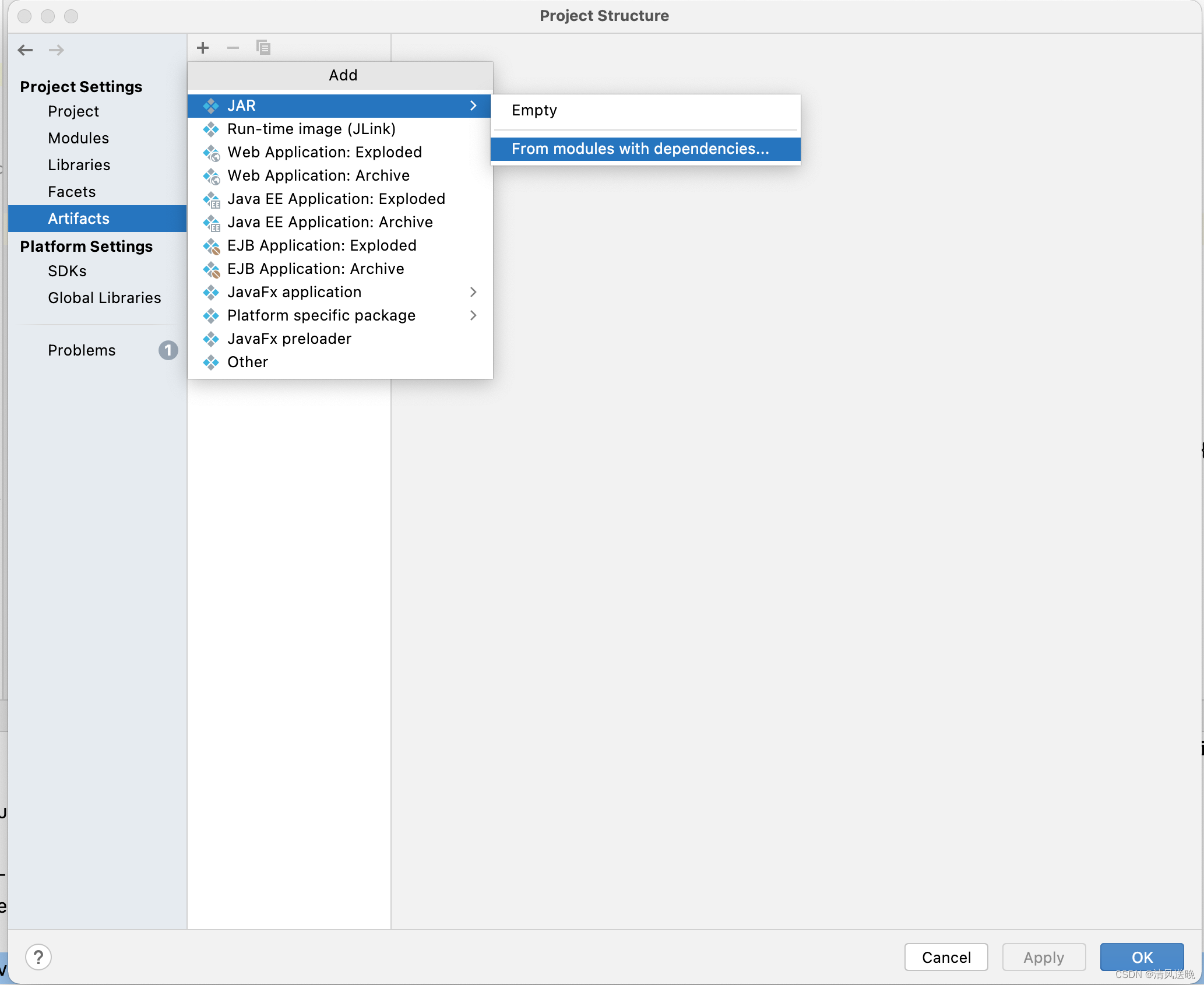
- 按照下图所示填写
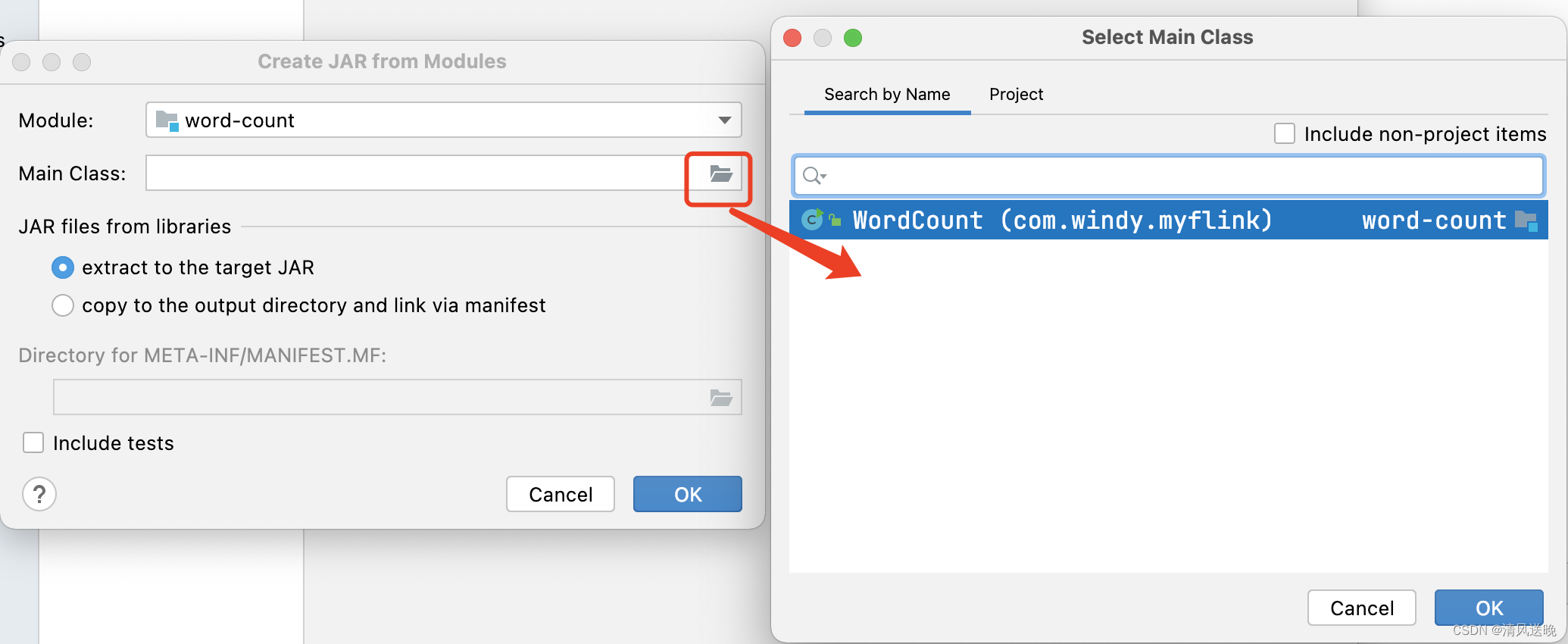
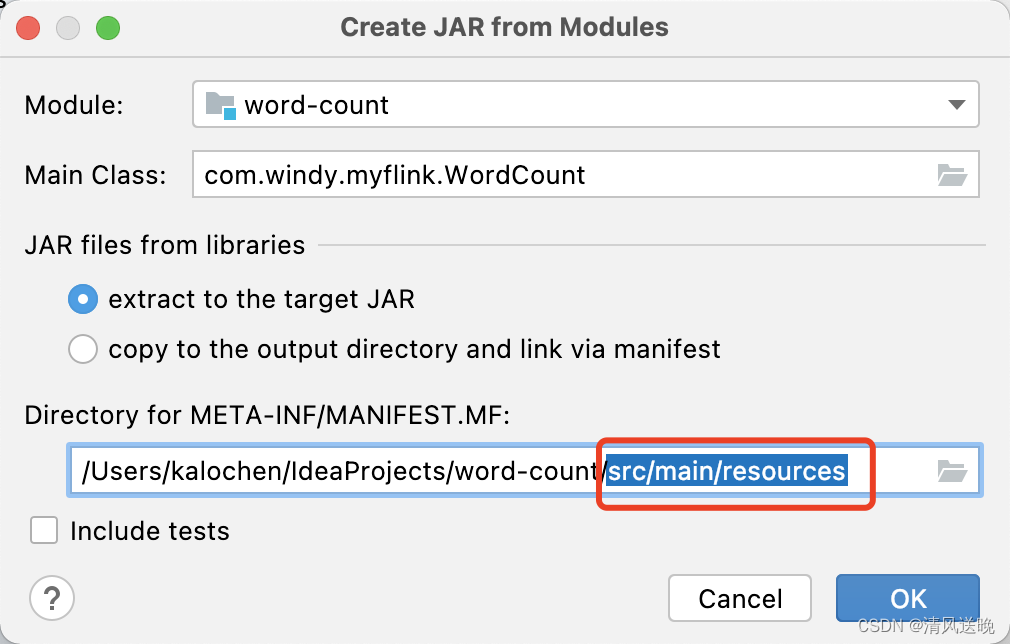
- 修改MANIFEST路径,去掉src/main/resources后缀,保存退出
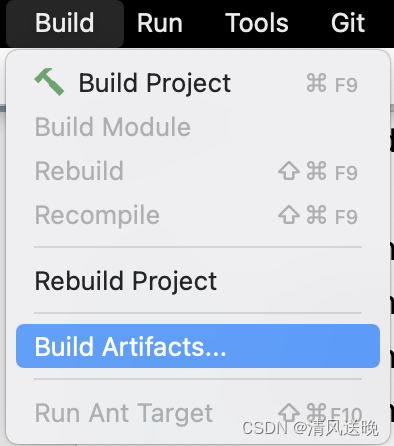
- 执行打包:Build => Build Artifacts => Build
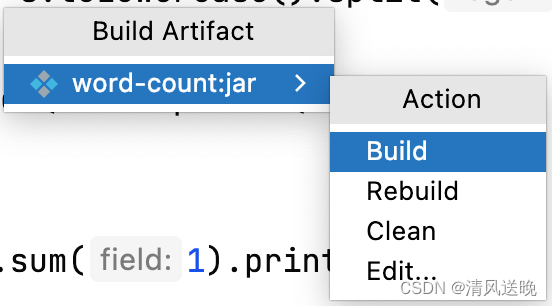
- build完成,会在当前工作目录下生成jar包文件
(5)运行jar包输出词频统计结果
flink run out/artifacts/word_count_jar/word-count.jar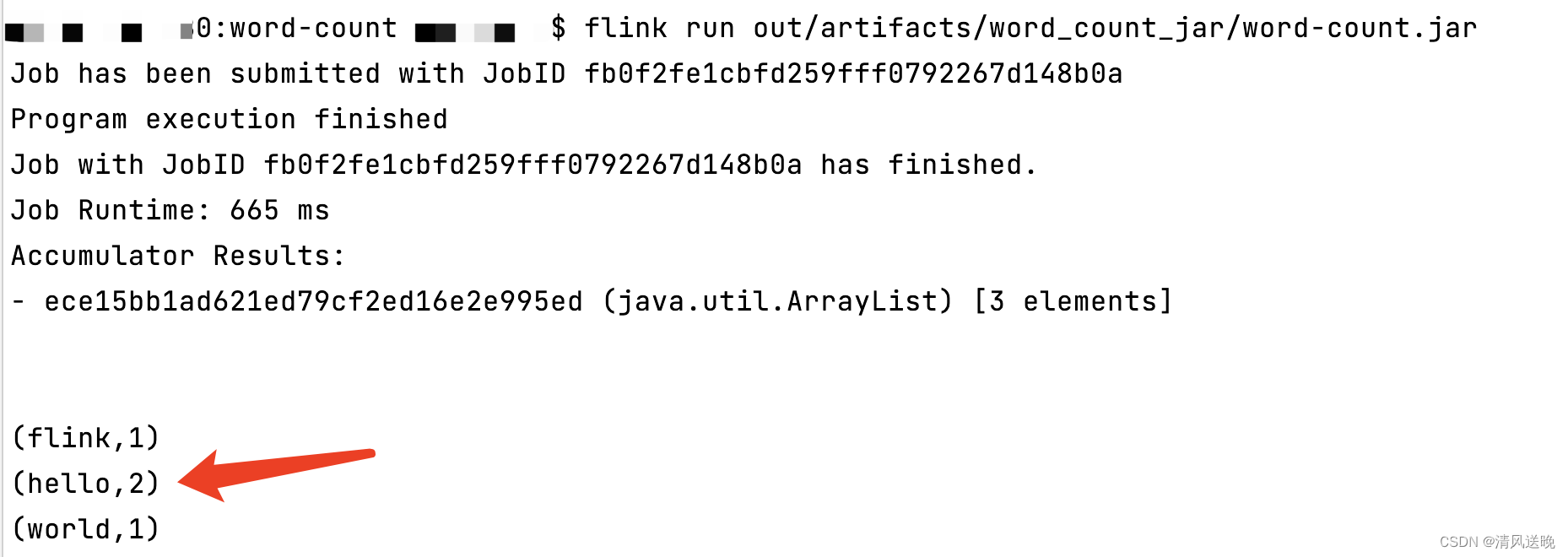
4. 需求升级
假设现在修改需求,从文本文件中读入句子,句子中包含连续空格、*等特殊字符,统计词频,按照词频由高到低的顺序输出。变更点如下:
- 读取文件:使用文件读取接口
- 过滤非法字符:加入Filter组件
- 排序:加入排序组件
升级后的词频统计程序如下:
- package com.windy.myflink;
-
- import org.apache.flink.api.common.functions.FlatMapFunction;
- import org.apache.flink.api.common.operators.Order;
- import org.apache.flink.api.java.DataSet;
- import org.apache.flink.api.java.ExecutionEnvironment;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.util.Collector;
-
- public class WordCount {
- public static void main(String[] args) throws Exception {
- ExecutionEnvironment setEnv = ExecutionEnvironment.getExecutionEnvironment();
- DataSet<String> dataSet = setEnv.readTextFile(
- "/Users/windy/IdeaProjects/word-count/src/main/resources/word.txt");
- dataSet.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
- @Override
- public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
- String[] fields = s.toLowerCase().split("\\s");
- for (String field : fields) {
- collector.collect(new Tuple2<>(field, 1));
- }
- }
- }).filter(x -> !x.f0.isEmpty() && !x.f0.contains("*"))
- .groupBy(0)
- .sum(1)
- .sortPartition(x -> x.f1, Order.DESCENDING)
- .print();
- }
- }
说明:flink没有全局排序算子,只有分区排序算子sortPartition,当我们把sortPartition的并行度设置为1,实现的就是全局排序效果,默认平行度就是1。
按照同样的方式打包并运行,执行结果如下:
- flink run out/artifacts/word_count_jar/word-count.jar
- Job has been submitted with JobID 6b562989adfc77104ff0a8d01d21b428
- Program execution finished
- Job with JobID 6b562989adfc77104ff0a8d01d21b428 has finished.
- Job Runtime: 629 ms
- Accumulator Results:
- - c06f16d3ec88909a3ed11492b22ca269 (java.util.ArrayList) [33 elements]
-
-
- (the,4)
- ({@code,3)
- (permits,2)
- (if,2)
- ((without,1)
- (acquires,1)
- (be,1)
- (been,1)
- (before,1)
- (can,1)
- (exceeding,1)
- (expired.,1)
- (false},1)
- (from,1)
- (given,1)
- (granted,1)
- (have,1)
- (immediately,1)
- (it,1)
- (number,1)
- (obtained,1)
- (of,1)
- (or,1)
- (ratelimiter},1)
- (returns,1)
- (specified,1)
- (this,1)
- (timeout,1)
- (timeout},,1)
- (waiting),1)
- (without,1)
- (would,1)
- (not,1)
感兴趣的读者可以再加入其他的flink算子,来进一步丰富这个例子。

