
- 1第六章:计算机视觉大模型实战6.3 图像分割与生成6.3.2 生成对抗网络(GAN)基础
- 2二、CentOS基础配置(1.网络与包管理)
- 3Linux下 VScode以sudo/root权限运行的最新方法_vscode root
- 4检测到远端X服务正在运行中(CVE-1999-0526)漏洞解决
- 5分享10个ai人工智能ppt生成软件,一键轻松搞定PPT制作!_ai智能ppt制作软件
- 6【华为OD机试真题 2022&2023】真题目录 已支持(C++&Java&python)100%通过率_华为od机试2022&2023(c++java js py)
- 7day03 51单片机
- 8spring boot 集成websocket + netty_netty-websocket-spring-boot-starter 与springboot集成
- 9基于智能家居c语言程序代码,基于单片机的智能家居系统设计(附程序代码)
- 10欧拉角微简介_欧拉角单位
初探强化学习(5)DDPG算法。包含逐行分析Pytorch代码和算法分析_ddpg算法流程图
赞
踩
这个博客适合老鸟来看,讲得很清楚。但是不详细。
有没有循环神经网络的感觉?这个博客都是这种图,很有意思
本文代码参考这个博客点击博客两字即可跳转。。
主要从这个博客搬来的https://zhuanlan.zhihu.com/p/111257402
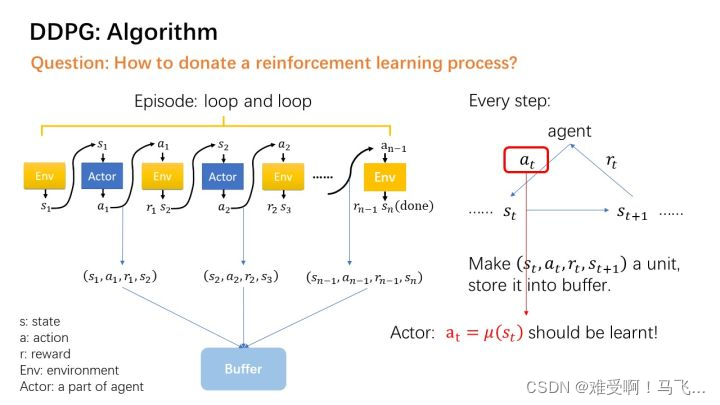
前言–如何快速搞懂一个算法
0.1 搞懂数据流向
只有弄明白数据流向,才能知道开发这个算法人的思想。
0.2 结合代码看如何实现
很多人实现代码的方式是不一样的,但是最终的数据流应该是一样的。
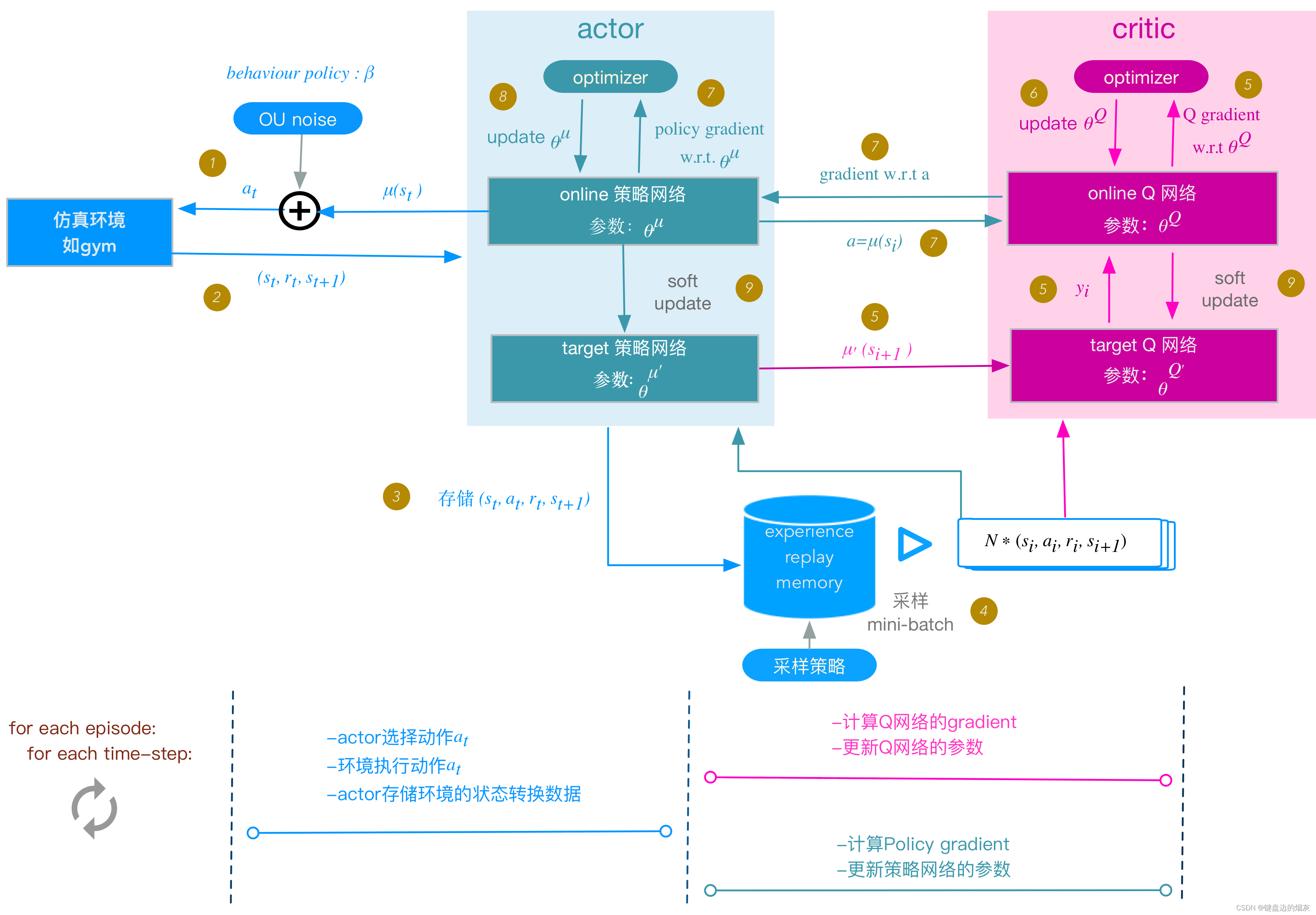
1. 我认为最清晰的图和算法流程分析
a t = μ ( s t ) a_{t} = \mu(s_{t}) at=μ(st)
DDPG算法流程如下:
初始化Actor\Critic的 online 神经网络参数:
θ
Q
\theta^{Q}
θQ和
θ
μ
\theta^{\mu}
θμ; 将online网 络 的 参 数 拷 贝 给 对 应 的target网 络 参 数 :
θ
Q
′
←
θ
Q
\theta{Q{\prime}} \leftarrow \theta^{Q}
θQ′←θQ,
θ
μ
′
←
θ
μ
\theta{\mu{\prime}} \leftarrow \theta^{\mu}
θμ′←θμ ;
初始化replay memory buffer R;
for each episode:
初始化UO随机过程;
for t = 1, T:
下面的步骤与DDPG实现框架图中步骤编号对应:
1. actor 根据behavior策略选择一个
a
t
a_{t}
at , 下达给gym执行该
a
t
a_{t}
at

behavior策略是一个根据当前online策略
μ
\mu
μ和随机UO噪声生成的随机过程, 从这个随机过程采样 获得
a
t
a_{t}
at的值。
2. gym执行
a
t
a_{t}
at,返回reward
r
t
r_{t}
rt 和新的状态
s
t
+
1
s_{t+1}
st+1
3. actor将这个状态转换过程(transition):
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
(s_{t}, a_{t}, r_{t},s_{t+1})
(st,at,rt,st+1) 存入replay memory buffer R中,作为训练online网络的数据集。
4. 从replay memory buffer R中,随机采样 N个 transition 数据,作为online策略网络、 online Q网络的一个mini-batch训练数据。我们用
(
s
i
,
a
i
,
r
i
,
s
i
+
1
)
(s_{i}, a_{i}, r_{i},s_{i+1})
(si,ai,ri,si+1)表示mini-batch中的单个transition数据。
5. 计算online Q网络的 gradient:
Q网络的loss定义:使用类似于监督式学习的方法,定义loss为MSE: mean squared error:
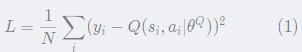
其中,
y
i
y_{i}
yi
可以看做"标签":
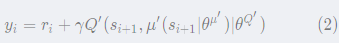
基于标准的back-propagation方法,就可以求得L针对
θ
Q
\theta^{Q}
θQ的gradient:
▽
θ
Q
L
\triangledown_{\theta^{Q}} L
▽θQL 。
有两点值得注意:
-
y
i
y_{i}
yi的计算,使用的是 target 策略网络
μ
′
\mu^{\prime}
μ′和 target Q 网络
Q
′
Q^{\prime}
Q′,
这样做是为了Q网络参数的学习过程更加稳定,易于收敛。 - 这个标签本身依赖于我们正在学习的target网络,这是区别于监督式学习的地方。
6. update online Q: 采用Adam optimizer更新
θ
Q
\theta^{Q}
θQ;
7. 计算策略网络的policy gradient:
policy gradient的定义:表示performance objective的函数
J
J
J针对
θ
μ
\theta^{\mu}
θμ的gradient。 根据2015 D.Silver 的DPG 论文中的数学推导,在采用off-policy的训练方法时,policy gradient算法如下:

也即,policy gradient是在s根据
ρ
β
\rho^{\beta}
ρβ分布时,
▽
a
Q
⋅
▽
θ
μ
μ
\triangledown_{a}Q\cdot \triangledown_{\theta^{\mu}} \mu
▽aQ⋅▽θμμ 的期望值。 我们用Monte-carlo方法来估算这个期望值:
在replay memory buffer中存储的(transition)
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

