
- 1按照Windows基线检查模板检查设置windows安全机制_windows基线配置核查脚本
- 2mcu比较器技巧和诀窍_如何准备技术面试-技巧和窍门,以帮助您表现最好
- 3Mysql 面试题_mysql一共有几种锁面试题
- 4linux总线、设备和驱动_linux总线设备驱动之间的关系
- 5SEO优化之浅谈蜘蛛日志
- 6【转载】绝对干货:互联网做流量的核心策略是什么?
- 7Spring Boot入门(26):让邮件飞:Spring Boot邮件发送实现攻略_springboot 邮件 html嵌入图片
- 8血族手游Lua脚本及资源文件解密_png解密工具 手游
- 9JavaSE - 数据类型与运算符(2)_public static void main(string[] args) {byte b1 =
- 10NOC Scratch真题、Python真题、NOC C++ 软件创意编程赛道_noc真题
逐行解读ACT:斯坦福Mobile Aloha之动作分块算法ACT的代码剖析、训练部署_斯坦福aloha 源代码 下载
赞
踩
前言
本文最早是属于《斯坦福Mobile ALOHA背后的关键技术:动作分块算法ACT的原理解析》的第二、第三部分(强调一下,如果想更好的看懂本文,则建议先看该篇ACT原理文章,原理懂了,再看代码事半功倍,否则原理没懂 直接看代码 事倍功半),涉及到动作分块ACT的代码剖析与部署训练

但因为想把ACT的代码逐行剖析的更细致些,加之为避免上一篇文章太过于长,故把动作分块ACT的代码剖析与部署实践这块独立出来成本文
而本文的成就有三个关键时间点
-
24年1.13日晚上7点,大模型线下营北京站2 周末两天结束后(我司七月在线大模型项目团队中每个项目组各自好几个人迭代好几个月的很多细节都拿出来讲了,所有人都收获很大)
10点回到酒店,在酒店里花了2-3个小时,理清了斯坦福mobile aloha的动作预测算法ACT代码的第一个1/3,核心是理清楚核心逻辑及各个函数的调用 -
24年1.14日下午2点,从北京回长沙的高铁上,理清ACT代码的第二个1/3,且把每行代码的解释说明逐行写到本文中
且考虑到我看过很多的源码解读,但大部分的可读性都比较差,造成这点的原因比较多,比如没有梳理好整个代码架构,其次,对于分析的每一段代码的长度都太长了
所以本文在写的过程中,特别注重梳理清楚其中的代码架构与其背后的逻辑调用关系,且被分析的每段代码的长度尽可能不超过20行,而对于较长的代码片段,能拆开的一定尽可能拆开 -
24年1.19日晚上8点,把ACT的全部代码梳理清楚,包括ACT的训练..
第一部分 imitate_episodes.py——ACT的训练与评估
关于ACT的代码,我们可以重点研究下这个仓库:GitHub - tonyzhaozh/act,我司同事杜老师也于24年1.10日跑通了这份代码(如何跑通的教程见本文最后)
- imitate_episodes.py,训练和评估 ACT
- policy.py,An adaptor for ACT policy
- detr,ACT 的模型定义 修改自 DETR
- sim_env.py,具有 joint space control的 Mujoco + DM_Control 环境
- ee_sim_env.py,具有EE space control的 Mujoco + DM_Control 环境
- scripted_policy.py,模拟环境的脚本化策略
- constants.py,跨文件共享的常量
- utils.py,数据加载和辅助函数等实用程序
- visualize_episodes.py,保存 .hdf5 数据集中的视频
关于dm_control这个库的学习资料比较少,包括这个资料也是一笔带过:https://colab.research.google.com/github/google-deepmind/dm_control/blob/main/tutorial.ipynb
好在我组建的mobile aloha复现小组里的刘博士推荐了一篇论文,即《dm_control: Software and Tasks for Continuous Control》可以好好看下,本文后续也会做下解读
1.1 主程序def main(涉及到对下文8个函数的综合调用)

1.1.1模型训练与评估的配置,及模型任务、模型参数的设置
从命令行参数中获取模型训练和评估的相关配置
- def main(args):
- set_seed(1) # 设置随机种子以保证结果可重现
- # 解析命令行参数
- is_eval = args["eval"] # 是否为评估模式的布尔标志
- ckpt_dir = args["ckpt_dir"] # 保存/加载checkpoint的目录
- policy_class = args["policy_class"] # 使用的策略类
- onscreen_render = args["onscreen_render"] # 是否进行屏幕渲染的标志
- task_name = args["task_name"] # 任务名称
- batch_size_train = args["batch_size"] # 训练批大小
- batch_size_val = args["batch_size"] # 验证批大小
- num_epochs = args["num_epochs"] # 训练的总周期数
- use_waypoint = args["use_waypoint"] # 是否使用航点
- constant_waypoint = args["constant_waypoint"] # 持续航点的设置
-
- # 根据是否使用航点打印相应信息
- if use_waypoint:
- print("Using waypoint") # 使用航点
- if constant_waypoint is not None:
- print(f"Constant waypoint: {constant_waypoint}") # 持续航点

根据任务名称和配置获取任务参数(例如数据集目录、任务类型等),比如如果是模拟任务,则从constants模块中导入SIM_TASK_CONFIGS
- # 获取任务参数
- is_sim = True # 硬编码为True以避免从aloha中查找常量
- # 如果是模拟任务,从constants导入SIM_TASK_CONFIGS
- if is_sim:
- from constants import SIM_TASK_CONFIGS
- task_config = SIM_TASK_CONFIGS[task_name]
- else:
- from aloha_scripts.constants import TASK_CONFIGS
- task_config = TASK_CONFIGS[task_name]
-
- # 从任务配置中获取相关参数
- dataset_dir = task_config["dataset_dir"]
- num_episodes = task_config["num_episodes"]
- episode_len = task_config["episode_len"]
- camera_names = task_config["camera_names"]
定义模型的架构和超参数,包括学习率、网络结构、层数等
- # 固定参数
- state_dim = 14 # 状态维度
- lr_backbone = 1e-5 # 主干网络的学习率
- backbone = "resnet18" # 使用的主干网络类型
1.1.2 创建训练策略及其对应的配置
根据`policy_class`的值来设置策略配置,这些配置将在后续的代码中用于创建和训练策略
- 比如,如果`policy_class`的值为'ACT',它会设置
`enc_layers`(编码层)为4
`dec_layers`(解码层)为7
`nheads`(头数)为8 - 然后创建一个名为`policy_config`的字典,包含了一些策略配置,如学习率、查询数、KL权重、隐藏维度、前馈维度、backbone学习率、backbone、编码层、解码层、头数和相机名称
- # 根据策略类别设置策略配置
- if policy_class == "ACT":
- # ACT策略的特定参数
- enc_layers = 4
- dec_layers = 7
- nheads = 8
- policy_config = {
- "lr": args["lr"],
- "num_queries": args["chunk_size"],
- "kl_weight": args["kl_weight"],
- "hidden_dim": args["hidden_dim"],
- "dim_feedforward": args["dim_feedforward"],
- "lr_backbone": lr_backbone,
- "backbone": backbone,
- "enc_layers": enc_layers,
- "dec_layers": dec_layers,
- "nheads": nheads,
- "camera_names": camera_names,
- }
- elif policy_class == "CNNMLP":
- # CNNMLP策略的特定参数
- policy_config = {
- "lr": args["lr"],
- "lr_backbone": lr_backbone,
- "backbone": backbone,
- "num_queries": 1,
- "camera_names": camera_names,
- }
- else:
- raise NotImplementedError
配置训练参数
- # 配置训练参数
- config = {
- "num_epochs": num_epochs,
- "ckpt_dir": ckpt_dir,
- "episode_len": episode_len,
- "state_dim": state_dim,
- "lr": args["lr"],
- "policy_class": policy_class,
- "onscreen_render": onscreen_render,
- "policy_config": policy_config,
- "task_name": task_name,
- "seed": args["seed"],
- "temporal_agg": args["temporal_agg"],
- "camera_names": camera_names,
- "real_robot": not is_sim,
- }
1.1.3 模型的具体评估(成功率与平均回报),与模型的保存
如果设置为评估模式,加载保存的模型权重并在验证集上评估模型性能,计算成功率和平均回报
- 如果`is_eval`为True,那么代码将进入评估模式。在这种模式下,它将加载名为`policy_best.ckpt`的模型检查点,并使用`eval_bc`函数对其进行评估。`eval_bc`函数的返回值是成功率和平均回报,这些值将被存储在`results`列表中
然后,代码将遍历`results`列表,并打印每个检查点的名称、成功率和平均回报 - 如果`is_eval`为False,那么代码将进入训练模式。在这种模式下,它将调用`load_data`函数来加载训练和验证数据
`load_data`函数的返回值是训练数据加载器、验证数据加载器、统计数据和一个布尔值,该布尔值表示是否为模拟任务
- # 如果为评估模式,执行评估流程
- if is_eval:
- ckpt_names = [f"policy_best.ckpt"]
- results = []
- for ckpt_name in ckpt_names:
- success_rate, avg_return = eval_bc(config, ckpt_name, save_episode=True)
- # `eval_bc`函数的主要任务是加载策略、统计数据和环境,然后在环境中执行策略,并收集回报。这个函数还处理了一些特殊情况,例如真实机器人和模拟环境的差异,以及是否在屏幕上渲染环境
- results.append([ckpt_name, success_rate, avg_return])
-
- for ckpt_name, success_rate, avg_return in results:
- print(f"{ckpt_name}: {success_rate=} {avg_return=}")
- print()
- exit()
-
- # 否则执行训练模式,先加载数据
- # `load_data`函数的主要任务是加载数据集,并将其分为训练集和验证集。它还计算了状态和动作的归一化统计数据,并使用这些统计数据创建了数据加载器
- train_dataloader, val_dataloader, stats, _ = load_data(
- dataset_dir,
- num_episodes,
- camera_names,
- batch_size_train,
- batch_size_val,
- use_waypoint,
- constant_waypoint,
- )
最后分别执行三个任务:保存数据集统计信息、训练模型、以及保存最佳模型检查点
- # 保存数据集统计信息
- if not os.path.isdir(ckpt_dir):
- os.makedirs(ckpt_dir)
- stats_path = os.path.join(ckpt_dir, f"dataset_stats.pkl")
- with open(stats_path, "wb") as f:
- pickle.dump(stats, f)
-
- # 训练并获取最佳检查点信息
- best_ckpt_info = train_bc(train_dataloader, val_dataloader, config)
- best_epoch, min_val_loss, best_state_dict = best_ckpt_info
-
- # 保存最佳检查点
- ckpt_path = os.path.join(ckpt_dir, f"policy_best.ckpt")
- torch.save(best_state_dict, ckpt_path)
- print(f"Best ckpt, val loss {min_val_loss:.6f} @ epoch{best_epoch}")
- 首先,它检查是否存在一个名为`ckpt_dir`的目录,如果不存在,它将创建这个目录。然后,它将数据集的统计信息`stats`保存到一个名为`dataset_stats.pkl`的文件中。这些统计信息可能包括数据集的一些特性,如平均值、标准差等
- 接着,它调用`train_bc`函数来训练模型。`train_bc`函数接受训练数据加载器、验证数据加载器和配置字典作为参数,并返回最佳检查点的信息,包括最佳周期、最小验证损失和最佳状态字典
- 最后,它将最佳状态字典保存到一个名为`policy_best.ckpt`的文件中,这个文件将被用于后续的模型评估或预测。然后,它打印出最佳检查点的验证损失和对应的周期
1.2 train_bc:训练行为克隆BC模型
这个函数用于训练行为克隆(Behavior Cloning)模型。它接受以下参数:
- train_dataloader:训练数据的数据加载器,用于从训练集中获取批次的数据
- val_dataloader:验证数据的数据加载器,用于从验证集中获取批次的数据
- config:包含训练配置信息的字典
1.2.1 初始化各种参数和配置、创建BC模型、定义优化器
初始化训练过程所需的各种参数和配置
从 `config` 中提取出一些参数,如
- def train_bc(train_dataloader, val_dataloader, config):
- num_epochs = config["num_epochs"]
- ckpt_dir = config["ckpt_dir"]
- seed = config["seed"]
- policy_class = config["policy_class"]
- policy_config = config["policy_config"]
- `num_epochs`(训练的轮数)
- `ckpt_dir`(检查点保存的目录)
- `seed`(随机种子)
- `policy_class`(策略类别)和
- `policy_config`(策略配置)
然后,依次进行如下操作
- set_seed(seed)
-
- policy = make_policy(policy_class, policy_config)
- policy.cuda()
- optimizer = make_optimizer(policy_class, policy)
- 使用 `set_seed` 函数设置随机种子,以确保实验的可重复性
- 使用 `make_policy` 函数创建一个策略,并将其移动到 GPU 上
- 使用 `make_optimizer` 函数为这个策略创建一个优化器
1.2.2 训练循环:验证、训练、保存权重
进行训练循环,每个循环迭代一个 epoch,包括以下步骤:
- 验证:在验证集上计算模型的性能,并记录验证结果。如果当前模型的验证性能优于历史最佳模型,则保存当前模型的权重
-
- train_history = []
- validation_history = []
- min_val_loss = np.inf
- best_ckpt_info = None
- for epoch in tqdm(range(latest_idx, num_epochs)):
- print(f"\nEpoch {epoch}")
-
- # 首先进行验证。将模型设置为评估模式,并对验证数据集进行遍历
- # 对于每一批数据,都会进行一次前向传播,并将结果添加到 `epoch_dicts` 列表中
- with torch.inference_mode():
- policy.eval()
- epoch_dicts = []
- for batch_idx, data in enumerate(val_dataloader):
- forward_dict = forward_pass(data, policy)
- epoch_dicts.append(forward_dict)
-
- # 然后,计算这个列表的平均值,并将其添加到 `validation_history` 中
- epoch_summary = compute_dict_mean(epoch_dicts)
- validation_history.append(epoch_summary)
-
- # 如果这个轮次的验证损失小于之前的最小验证损失,就更新最小验证损失,并保存当前的模型状态
- epoch_val_loss = epoch_summary["loss"]
- if epoch_val_loss < min_val_loss:
- min_val_loss = epoch_val_loss
- best_ckpt_info = (epoch, min_val_loss, deepcopy(policy.state_dict()))
-
- print(f"Val loss: {epoch_val_loss:.5f}")
- summary_string = ""
- for k, v in epoch_summary.items():
- summary_string += f"{k}: {v.item():.3f} "
- print(summary_string)
- 训练:在训练集上进行模型的训练,计算损失并执行反向传播来更新模型的权重
将模型设置为训练模式,并对训练数据集进行遍历。对于每一批数据,都会进行一次前向传播,然后进行反向传播,并使用优化器更新模型的参数
- # training
- policy.train()
- optimizer.zero_grad()
- for batch_idx, data in enumerate(train_dataloader):
- forward_dict = forward_pass(data, policy)
- # backward
- loss = forward_dict["loss"]
- loss.backward()
- optimizer.step()
- optimizer.zero_grad()
- train_history.append(detach_dict(forward_dict))
- e = epoch - latest_idx
- epoch_summary = compute_dict_mean(
- train_history[(batch_idx + 1) * e : (batch_idx + 1) * (epoch + 1)]
- )
- epoch_train_loss = epoch_summary["loss"]
- print(f"Train loss: {epoch_train_loss:.5f}")
- summary_string = ""
- for k, v in epoch_summary.items():
- summary_string += f"{k}: {v.item():.3f} "
- print(summary_string)
- 每隔一定周期,保存当前模型的权重和绘制训练曲线图
在每个轮次结束时,如果轮次数是 100 的倍数,就保存一次模型的状态。在所有轮次结束后,保存最后一次的模型状态,以及验证损失最小时的模型状态
-
- if epoch % 100 == 0:
- ckpt_path = os.path.join(ckpt_dir, f"policy_epoch_{epoch}_seed_{seed}.ckpt")
- torch.save(policy.state_dict(), ckpt_path)
- plot_history(train_history, validation_history, epoch, ckpt_dir, seed)
-
- ckpt_path = os.path.join(ckpt_dir, f"policy_last.ckpt")
- torch.save(policy.state_dict(), ckpt_path)
保存最佳模型的权重和绘制训练曲线图
-
- best_epoch, min_val_loss, best_state_dict = best_ckpt_info
- ckpt_path = os.path.join(ckpt_dir, f"policy_epoch_{best_epoch}_seed_{seed}.ckpt")
- torch.save(best_state_dict, ckpt_path)
- print(
- f"Training finished:\nSeed {seed}, val loss {min_val_loss:.6f} at epoch {best_epoch}"
- )
-
- # save training curves
- plot_history(train_history, validation_history, num_epochs, ckpt_dir, seed)
-
- return best_ckpt_info
1.3 forward_pass:前向传播以生成模型的输出
- def forward_pass(data, policy):
- image_data, qpos_data, action_data, is_pad = data
- image_data, qpos_data, action_data, is_pad = (
- image_data.cuda(),
- qpos_data.cuda(),
- action_data.cuda(),
- is_pad.cuda(),
- )
- return policy(qpos_data, image_data, action_data, is_pad)
这个函数用于执行前向传播(forward pass)操作,以生成模型的输出。它接受以下参数:
- data:包含输入数据的元组,其中包括图像数据、关节位置数据、动作数据以及填充标志
- policy:行为克隆模型
函数的主要步骤如下:
- 将输入数据转移到GPU上,以便在GPU上进行计算。
- 调用行为克隆模型的前向传播方法(policy),将关节位置数据、图像数据、动作数据和填充标志传递给模型
- 返回模型的输出,这可能是模型对动作数据的预测结果
1.4 make_policy:通过ACTPolicy获取policy
1.4.1 make_policy的定义:policy = ACTPolicy(policy_config)
根据指定的policy_class(策略类别,目前支持两种类型:"ACT"和"CNNMLP"),和policy_config(策略配置)创建一个策略模型对象
- def make_policy(policy_class, policy_config):
- if policy_class == 'ACT':
- policy = ACTPolicy(policy_config) # 如果策略类是 ACT,创建 ACTPolicy
- elif policy_class == 'CNNMLP':
- policy = CNNMLPPolicy(policy_config) # 如果策略类是 CNNMLP,创建 CNNMLPPolicy
- else:
- raise NotImplementedError # 如果不是以上两种类型,则抛出未实现错误
- return policy # 返回创建的策略对象
可以看到policy调用了act-main/policy.py中定义的ACTPolicy,那ACTPolicy则是基于CVAE实现的
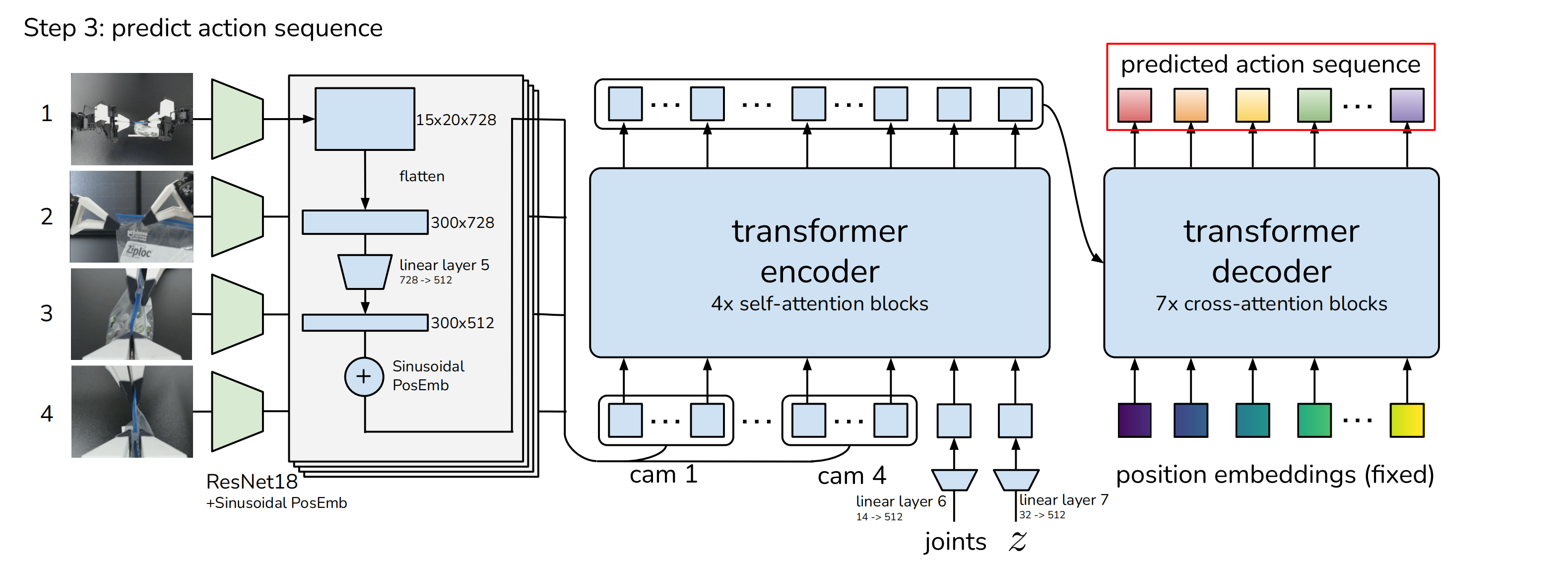
1.4.2 policy.py中ACTPolicy的实现
而act-main/policy.py中ACTPolicy的实现如下
- class ACTPolicy(nn.Module):
- def __init__(self, args_override):
- super().__init__()
- model, optimizer = build_ACT_model_and_optimizer(args_override)
- self.model = model # CVAE decoder
- self.optimizer = optimizer
- self.kl_weight = args_override['kl_weight']
- print(f'KL Weight {self.kl_weight}')
-
- def __call__(self, qpos, image, actions=None, is_pad=None):
- env_state = None
- normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
- std=[0.229, 0.224, 0.225])
- image = normalize(image)
- if actions is not None: # training time
- actions = actions[:, :self.model.num_queries]
- is_pad = is_pad[:, :self.model.num_queries]
-
- a_hat, is_pad_hat, (mu, logvar) = self.model(qpos, image, env_state, actions, is_pad)
- total_kld, dim_wise_kld, mean_kld = kl_divergence(mu, logvar)
- loss_dict = dict()
- all_l1 = F.l1_loss(actions, a_hat, reduction='none')
- l1 = (all_l1 * ~is_pad.unsqueeze(-1)).mean()
- loss_dict['l1'] = l1
- loss_dict['kl'] = total_kld[0]
- loss_dict['loss'] = loss_dict['l1'] + loss_dict['kl'] * self.kl_weight
- return loss_dict
- else: # inference time
- a_hat, _, (_, _) = self.model(qpos, image, env_state) # no action, sample from prior
- return a_hat
-
- def configure_optimizers(self):
- return self.optimizer
1.4.3 detr/main.py中build_ACT_model_and_optimizer的定义
由上可知,ACTPolicy则调用了act-main/detr/main.py中的build_ACT_model_and_optimizer
- def build_ACT_model_and_optimizer(args_override):
- parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
- args = parser.parse_args()
-
- for k, v in args_override.items():
- setattr(args, k, v)
-
- model = build_ACT_model(args)
- model.cuda()
-
- param_dicts = [
- {"params": [p for n, p in model.named_parameters() if "backbone" not in n and p.requires_grad]},
- {
- "params": [p for n, p in model.named_parameters() if "backbone" in n and p.requires_grad],
- "lr": args.lr_backbone,
- },
- ]
- optimizer = torch.optim.AdamW(param_dicts, lr=args.lr,
- weight_decay=args.weight_decay)
-
- return model, optimizer
1.4.4 detr/models/_init_.py中的build_ACT_model的定义
而build_ACT_model_and_optimizer中又通过调用了act-main/detr/models/_init_.py中的build_ACT_model(args)
- def build_ACT_model(args):
- return build_vae(args)
1.4.5 detr/models/detr_vae.py中build_vae的实现
而build_vae则在act-main/detr/models/detr_vae.py中实现
- def build(args):
- state_dim = 14 # TODO hardcode
-
- # From state
- # backbone = None # from state for now, no need for conv nets
- # From image
- backbones = []
- backbone = build_backbone(args)
- backbones.append(backbone)
-
- transformer = build_transformer(args)
-
- encoder = build_encoder(args)
-
- model = DETRVAE(
- backbones,
- transformer,
- encoder,
- state_dim=state_dim,
- num_queries=args.num_queries,
- camera_names=args.camera_names,
- )
-
- n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
- print("number of parameters: %.2fM" % (n_parameters/1e6,))
-
- return model
- 而build_encoder被定义如下
- def build_encoder(args):
- d_model = args.hidden_dim # 256
- dropout = args.dropout # 0.1
- nhead = args.nheads # 8
- dim_feedforward = args.dim_feedforward # 2048
- num_encoder_layers = args.enc_layers # 4 # TODO shared with VAE decoder
- normalize_before = args.pre_norm # False
- activation = "relu"
- encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
- dropout, activation, normalize_before)
- encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
- encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
- return encoder
- 而DETRVAE的定义详见下文第三部分
至于build_transformer在act-main/detr/models/transformer.py被定义如下
- def build_transformer(args):
- return Transformer(
- d_model=args.hidden_dim,
- dropout=args.dropout,
- nhead=args.nheads,
- dim_feedforward=args.dim_feedforward,
- num_encoder_layers=args.enc_layers,
- num_decoder_layers=args.dec_layers,
- normalize_before=args.pre_norm,
- return_intermediate_dec=True,
- )
1.5 make_optimizer
make_optimizer用于创建策略模型的优化器(optimizer),并返回创建的优化器对象。优化器的作用是根据策略模型的损失函数来更新模型的参数,以使损失函数尽量减小
- def make_optimizer(policy_class, policy):
- if policy_class == 'ACT':
- optimizer = policy.configure_optimizers() # 如果策略类是 ACT,配置优化器
- elif policy_class == 'CNNMLP':
- optimizer = policy.configure_optimizers() # 如果策略类是 CNNMLP,配置优化器
- else:
- raise NotImplementedError # 如果不是以上两种类型,则抛出未实现错误
- return optimizer # 返回配置的优化器
1.6 get_image
get_image的作用是获取一个时间步(ts)的图像数据。函数接受两个参数:ts和camera_names
-
`ts`是一个时间步对象,它包含了当前时间步的观察结果。`camera_names`是一个列表,包含了需要获取图像的摄像头的名称
函数首先创建一个空列表`curr_images`,用于存储从每个摄像头获取的图像
- def get_image(ts, camera_names):
- curr_images = []
-
然后,它遍历`camera_names`列表,对于每个摄像头名称,它从`ts.observation['images']`中获取对应的图像,并使用`rearrange`函数将图像的维度从'高度 宽度 通道数'重新排列为'通道数 高度 宽度'
然后将重新排列后的图像添加到`curr_images`列表中
- for cam_name in camera_names:
- curr_image = rearrange(ts.observation['images'][cam_name], 'h w c -> c h w') # 重排图像数组
- curr_images.append(curr_image) # 将处理后的图像添加到列表中
-
接着,它使用`np.stack`函数将`curr_images`列表中的所有图像堆叠在一起,形成一个新的numpy数组`curr_image`
curr_image = np.stack(curr_images, axis=0) # 将图像列表堆叠成数组-
然后,它将`curr_image`数组的数据类型转换为torch张量,并将其值归一化到0-1之间,然后将其转移到GPU上,并增加一个新的维度
最后,函数返回处理后的图像张量`curr_image` (包含时间步图像数据的PyTorch张量,这个图像数据可以被用于输入到神经网络模型中进行处理)
-
- curr_image = torch.from_numpy(curr_image / 255.0).float().cuda().unsqueeze(0) # 将数组转换为 PyTorch 张量
- return curr_image # 返回处理后的图像张量
总的来说,`get_image`函数的作用是从给定的时间步对象中获取指定摄像头的图像,并将其处理为适合模型输入的格式
1.7 plot_history
`plot_history`函数,接收五个参数:`train_history`、`validation_history`、`num_epochs`、`ckpt_dir`和`seed`
- 首先,函数通过遍历`train_history`中的每个键来创建并保存训练曲线。对于`train_history`中的每个键,它都会创建一个路径`plot_path`,该路径将图形保存在`ckpt_dir`目录下,并在文件名中包含键和种子值。
- 然后,函数创建一个新的图形,并从`train_history`和`validation_history`中提取对应键的值。这些值被用于绘制训练和验证的曲线。`np.linspace`函数用于生成x轴的值,它返回在指定间隔内均匀分布的数字。在这里,它用于生成从0到`num_epochs-1`的数字。
- 接下来,使用`plt.tight_layout`函数来自动调整子图参数,使得子图之间的空间适当,并且填充整个图形区域。然后,使用`plt.legend`函数来添加图例,`plt.title`函数来设置图形的标题,最后使用`plt.savefig`函数将图形保存到`plot_path`指定的路径。
- 最后,函数打印出已经保存图形的目录
总的来说,这个函数的目标是将训练和验证过程中的历史数据绘制为图形,并保存到指定的目录
// 待更
1.8 eval_bc:评估一个行为克隆(behavior cloning)模型
1.8.1 传参与配置信息
该函数用于评估给定的策略。它接受两个参数:`config`和`ckpt_name`
- def eval_bc(config, ckpt_name, save_episode=True):
- set_seed(1000) # 设置随机种子为 1000
`config`是一个字典,包含了评估过程中需要的各种配置信息,如策略类名称、摄像头名称、任务名称等
`ckpt_name`是一个字符串,表示要加载的策略的检查点文件的名称
函数首先从`config`中提取出各种配置信息,并设置随机种子以确保结果的可复现性
-
- # 从配置中获取参数
- ckpt_dir = config['ckpt_dir']
- state_dim = config['state_dim']
- real_robot = config['real_robot']
- policy_class = config['policy_class']
- onscreen_render = config['onscreen_render']
- policy_config = config['policy_config']
- camera_names = config['camera_names']
- max_timesteps = config['episode_len']
- task_name = config['task_name']
- temporal_agg = config['temporal_agg']
- onscreen_cam = 'angle'
1.8.2 加载checkpoint、加载环境(或真实环境,或模拟环境)
然后,它加载策略的检查点文件,并将策略模型转移到GPU上,并将其设置为评估模式
-
- # 加载策略和统计信息
- ckpt_path = os.path.join(ckpt_dir, ckpt_name)
- policy = make_policy(policy_class, policy_config)
- loading_status = policy.load_state_dict(torch.load(ckpt_path))
- print(loading_status)
- policy.cuda()
- policy.eval()
- print(f'Loaded: {ckpt_path}')
- stats_path = os.path.join(ckpt_dir, f'dataset_stats.pkl')
- with open(stats_path, 'rb') as f:
- stats = pickle.load(f)
-
- # 定义预处理和后处理函数
- pre_process = lambda s_qpos: (s_qpos - stats['qpos_mean']) / stats['qpos_std']
- post_process = lambda a: a * stats['action_std'] + stats['action_mean']
接着,函数加载环境
如果`real_robot`为True,那么它将加载真实机器人的环境;否则,它将加载模拟环境
- # 加载环境
- if real_robot:
- from aloha_scripts.robot_utils import move_grippers # 从 aloha_scripts.robot_utils 导入 move_grippers
- from aloha_scripts.real_env import make_real_env # 从 aloha_scripts.real_env 导入 make_real_env
- env = make_real_env(init_node=True) # 创建真实机器人环境
- env_max_reward = 0
- else:
- from sim_env import make_sim_env # 从 sim_env 导入 make_sim_env
- env = make_sim_env(task_name) # 创建模拟环境
- env_max_reward = env.task.max_reward
-
- # 设置查询频率和时间聚合参数
- query_frequency = policy_config['num_queries']
- if temporal_agg:
- query_frequency = 1
- num_queries = policy_config['num_queries']
-
- # 设置最大时间步数
- max_timesteps = int(max_timesteps * 1) # 可以根据实际任务调整最大时间步数
1.8.3 开始评估BC:两大循环——大循环50回合、每个回合下的小循环跑完时间步长
然后,函数开始进行评估,然有两个循环
先是大循环,对于每个回合,它首先重置环境
再是小循环,即内层循环,对于每个时间步,它先获取当前的观察结果,然后查询策略以获取动作,最后执行动作并获取奖励,最后将奖励添加到`rewards`列表中
首先开始大循环,它首先初始化一些变量,比如一个模拟环境的回合数(`num_rollouts`)为50,并初始化了两个空列表:`episode_returns`和`highest_rewards`,用于存储每个回合的回报和最高奖励
- # 设置回放次数和初始化结果列表
- num_rollouts = 50
- episode_returns = []
- highest_rewards = []
然后,它使用一个for循环来进行每个回合的模拟,且在每个回合开始时,它会根据任务名称(`task_name`)来设置任务的初始状态 如果任务名称中包含'sim_transfer_cube',那么它会调用`sample_box_pose`函数来随机生成一个立方体的位置和姿态,并将其赋值给全局变量`BOX_POSE[0]`,该变量表示盒子的位置或姿态信息
如果任务名称中包含'sim_insertion',那么它会调用`sample_insertion_pose`函数来随机生成一个插入任务的初始状态,包括插入物(peg)和插入孔(socket)的位置和姿态,并将其赋值给`BOX_POSE[0]`。这些初始状态将在模拟环境重置时被使用
最后,它调用`env.reset`函数来重置模拟环境,并将返回的时间步对象赋值给`ts`
- # 回放循环,学它个50回合
- for rollout_id in range(num_rollouts):
- rollout_id += 0
- # 设置任务
- if 'sim_transfer_cube' in task_name:
- BOX_POSE[0] = sample_box_pose() # 在模拟重置中使用的 BOX_POSE
- elif 'sim_insertion' in task_name:
- BOX_POSE[0] = np.concatenate(sample_insertion_pose()) # 在模拟重置中使用的 BOX_POSE
-
- ts = env.reset() # 重置环境
接下来,代码检查`onscreen_render`是否为True
如果为True,那么它将创建一个matplotlib的子图,并在子图上显示模拟环境的渲染结果。这里使用了`env._physics.render`方法来获取模拟环境的渲染图像,其中`height`和`width`参数指定了渲染图像的大小,`camera_id`参数指定了用于渲染的摄像头
然后,它调用`plt.ion`方法来开启交互模式,这样就可以在模拟过程中实时更新显示的图像
- ### onscreen render
- if onscreen_render:
- ax = plt.subplot()
- plt_img = ax.imshow(env._physics.render(height=480, width=640, camera_id=onscreen_cam))
- plt.ion()
接着,它检查`temporal_agg`是否为True
如果为True,那么它将创建一个全零的torch张量`all_time_actions`,用于存储所有时间步的动作
- # 评估循环
- if temporal_agg:
- all_time_actions = torch.zeros([max_timesteps, max_timesteps+num_queries, state_dim]).cuda()
这个张量的形状为`[max_timesteps, max_timesteps+num_queries, state_dim]`,其中
- `max_timesteps`是每个回合的最大时间步数
- `num_queries`是查询的数量
- `state_dim`是状态的维度
之后这个张量被转移到了GPU上
再往下,它创建了一个全零的torch张量`qpos_history`,用于存储每个时间步的机器人关节位置(`qpos`),这个张量的形状为`(1, max_timesteps, state_dim)`
- # 创建了一个全零的torch张量`qpos_history`,存储每个时间步的机器人关节位置(`qpos`)
- qpos_history = torch.zeros((1, max_timesteps, state_dim)).cuda()
接着,它创建了四个空列表:`image_list`、`qpos_list`、`target_qpos_list`和`rewards`
- image_list = [] # 用于可视化的图像列表
- qpos_list = []
- target_qpos_list = []
- rewards = []
- `image_list`用于存储每个时间步的图像
- `qpos_list`用于存储每个时间步的机器人关节位置
- `target_qpos_list`用于存储每个时间步的目标机器人关节位置
- `rewards`用于存储每个时间步的奖励
1.8.3.1 小循环:获取每个时间步的观察结果
再往下,便要进入小循环,即内层循环了:对于每个时间步,它先获取当前的观察结果(相当于获取每个时间步的观察结果,包括图像和机器人的关节位置,并将这些信息存储起来),然后查询策略以获取动作
且位于一个`torch.inference_mode()`上下文管理器中,这意味着在这个上下文中的所有PyTorch操作都不会跟踪梯度,这对于推理和测试非常有用,因为它可以减少内存使用并提高计算速度
- # 在不计算梯度的模式下执行
- with torch.inference_mode():
代码使用一个for循环来遍历每个时间步
-
- for t in range(max_timesteps):
- # 更新屏幕渲染和等待时间
- if onscreen_render:
- image = env._physics.render(height=480, width=640, camera_id=onscreen_cam)
- plt_img.set_data(image)
- plt.pause(DT)
在每个时间步中,如果`onscreen_render`为True,那么它会通过`env._physics.render`方法获取模拟环境的渲染图像(其中`height`和`width`参数指定了渲染图像的大小,`camera_id`参数指定了用于渲染的摄像头)
并使用`plt_img.set_data(image)`方法来更新显示的图像(它接受一个图像数组作为参数,并将其设置为图像的新数据)
然后,它调用`plt.pause(DT)`方法来暂停一段时间
接下来,要处理每个时间步的观察结果了
首先,它从`ts`(可能是一个时间步对象)中获取观察结果`obs`。然后,它检查`obs`中是否包含`images`键
如果包含,那么它将`obs['images']`添加到`image_list`中;
否则,它将一个包含`obs['image']`的字典添加到`image_list`中
- # 处理上一时间步的观测值以获取 qpos 和图像列表
- obs = ts.observation
- if 'images' in obs:
- image_list.append(obs['images'])
- else:
- image_list.append({'main': obs['image']})
接着
- qpos_numpy = np.array(obs['qpos'])
- qpos = pre_process(qpos_numpy)
- qpos = torch.from_numpy(qpos).float().cuda().unsqueeze(0)
- 从`obs`中获取机器人的关节位置`qpos`,并将其转换为numpy数组
- 使用之前定义的`pre_process`函数对`qpos`进行预处理,这个函数会将`qpos`标准化
- 将标准化后的`qpos`转换为torch张量,并将其转移到GPU上。这个张量的形状被增加了一个新的维度,这是通过`unsqueeze(0)`方法实现的
然后,它将处理后的`qpos`存储到`qpos_history`张量的对应位置。这里的`t`是当前的时间步,所以`qpos_history[:, t]`表示的是在第`t`个时间步的`qpos`
-
- qpos_history[:, t] = qpos
- curr_image = get_image(ts, camera_names)
最后,它调用`get_image`函数来获取当前时间步的图像。这个函数接受一个时间步对象和一个摄像头名称列表作为参数,它会从每个摄像头获取图像,然后将所有图像堆叠起来,并将其转换为torch张量
1.8.3.2 根据观察结果查询策略、获取动作
接下来,便得根据上面获取到的观察结果,去查询策略以获取动作了
首先,它检查配置中的`policy_class`是否为"ACT"
如果是,那么它会在每个`query_frequency`的时间步中,使用`policy`函数和当前的关节位置`qpos`以及图像`curr_image`来获取所有的动作`all_actions`
- # 查询策略
- if config['policy_class'] == "ACT":
- if t % query_frequency == 0:
- all_actions = policy(qpos, curr_image)
注意,这里的调用关系,即 all_actions = policy(qpos, curr_image)中的policy 是通过make_policy获取的:
policy = make_policy(policy_class, policy_config)而make_policy即是上文1.4中的make_policy
- 如果`temporal_agg`为True(相当于要做指数加权),那么它会将所有的动作存储到`all_time_actions`张量的对应位置,并从中获取当前步骤的动作`actions_for_curr_step`。然后,它检查`actions_for_curr_step`中的所有元素是否都不为0,如果是,那么它会保留这些动作
- if temporal_agg:
- all_time_actions[[t], t:t+num_queries] = all_actions
- actions_for_curr_step = all_time_actions[:, t]
- actions_populated = torch.all(actions_for_curr_step != 0, axis=1)
- actions_for_curr_step = actions_for_curr_step[actions_populated]
接着,它创建一个指数权重`exp_weights`,并将其转换为torch张量。最后,它使用这些权重对动作进行加权平均,得到`raw_action`
- k = 0.01
- exp_weights = np.exp(-k * np.arange(len(actions_for_curr_step)))
- exp_weights = exp_weights / exp_weights.sum()
- exp_weights = torch.from_numpy(exp_weights).cuda().unsqueeze(dim=1)
- raw_action = (actions_for_curr_step * exp_weights).sum(dim=0, keepdim=True)
- 如果`temporal_agg`为False(相当于不做指数加权),那么它会直接从`all_actions`中获取当前步骤的动作`raw_action`
-
- else:
- raw_action = all_actions[:, t % query_frequency]
如果配置中的`policy_class`为"CNNMLP",那么它会直接使用`policy`函数和当前的关节位置`qpos`以及图像`curr_image`来获取动作`raw_action`
如果配置中的`policy_class`既不是"ACT"也不是"CNNMLP",那么它会抛出一个"NotImplementedError"异常
- elif config['policy_class'] == "CNNMLP":
- raw_action = policy(qpos, curr_image)
- else:
- raise NotImplementedError
1.8.3.3 对动作的进一步处理
接下来,是对动作的进一步处理
-
- # 后处理动作
- raw_action = raw_action.squeeze(0).cpu().numpy()
- action = post_process(raw_action)
- target_qpos = action
-
- # 步进环境
- ts = env.step(target_qpos)
-
- # 用于可视化的列表
- qpos_list.append(qpos_numpy)
- target_qpos_list.append(target_qpos)
- rewards.append(ts.reward)
-
- plt.close() # 关闭绘图窗口
- if real_robot:
- move_grippers([env.puppet_bot_left, env.puppet_bot_right], [PUPPET_GRIPPER_JOINT_OPEN] * 2, move_time=0.5) # 打开夹持器
- pass
1.8.3.4 计算当前回合的总奖励,之后保存图像数据
在内层循环结束后,它计算当前回合的总奖励,并将其添加到`episode_returns`列表中
- # 计算回报和奖励
- rewards = np.array(rewards)
- episode_return = np.sum(rewards[rewards != None])
- episode_returns.append(episode_return)
- episode_highest_reward = np.max(rewards)
- highest_rewards.append(episode_highest_reward)
- print(f'Rollout {rollout_id}\n{episode_return=}, {episode_highest_reward=}, {env_max_reward=}, Success: {episode_highest_reward == env_max_reward}')
如果指定了保存评估过程中的图像数据,将每次评估的图像数据保存为视频
- # 保存视频
- if save_episode:
- save_videos(image_list, DT, video_path=os.path.join(ckpt_dir, f'video{rollout_id}.mp4'))
1.8.4 所有50个回合结束后,计算成功率与平均回报
在所有回合都结束后,函数计算成功率和平均回报,并将这些信息保存到文本文件中
-
- # 计算成功率和平均回报
- # 计算成功率,即最高奖励的次数与环境最大奖励相等的比率
- success_rate = np.mean(np.array(highest_rewards) == env_max_reward)
-
- # 计算平均回报
- avg_return = np.mean(episode_returns)
-
- # 创建一个包含成功率和平均回报的摘要字符串
- summary_str = f'\n成功率: {success_rate}\n平均回报: {avg_return}\n\n'
-
- # 遍历奖励范围,计算每个奖励范围内的成功率
- for r in range(env_max_reward + 1):
- # 统计最高奖励大于等于 r 的次数
- more_or_equal_r = (np.array(highest_rewards) >= r).sum()
-
- # 计算成功率
- more_or_equal_r_rate = more_or_equal_r / num_rollouts
-
- # 将结果添加到摘要字符串中
- summary_str += f'奖励 >= {r}: {more_or_equal_r}/{num_rollouts} = {more_or_equal_r_rate*100}%\n'
-
- # 打印摘要字符串
- print(summary_str)
-
- # 将成功率保存到文本文件
- result_file_name = 'result_' + ckpt_name.split('.')[0] + '.txt'
- with open(os.path.join(ckpt_dir, result_file_name), 'w') as f:
- f.write(summary_str) # 写入摘要字符串
- f.write(repr(episode_returns)) # 写入回报数据
- f.write('\n\n')
- f.write(repr(highest_rewards)) # 写入最高奖励数据
-
- # 返回成功率和平均回报
- return success_rate, avg_return
总的来说,`eval_bc`函数的作用是评估给定的策略在指定任务上的性能
第二部分 policy.py:根据输入的位置和图像来预测动作
2.1 ACTPolicy
这段代码定义了一个名为`ACTPolicy`的类,该类继承自`nn.Module`,是PyTorch中的基础模块类,用于构建神经网络
总的来说,这个类定义了一个策略,该策略使用一个模型来根据输入的位置和图像来预测动作,并在训练时计算损失
2.1.1 __init__:调用build_ACT_model_and_optimizer
在`ACTPolicy`类的`__init__`方法中
- class ACTPolicy(nn.Module):
- def __init__(self, args_override):
- super().__init__()
- model, optimizer = build_ACT_model_and_optimizer(args_override)
- self.model = model # CVAE decoder
- self.optimizer = optimizer
- self.kl_weight = args_override['kl_weight']
- print(f'KL Weight {self.kl_weight}')
- 首先调用了父类的初始化方法,然后调用了`build_ACT_model_and_optimizer`函数来构建模型和优化器
- 这个函数接收一个参数`args_override`,并返回一个模型和优化器。这个模型和优化器被保存在`self.model`和`self.optimizer`中
- 然后,从`args_override`字典中获取`kl_weight`并保存在`self.kl_weight`中
- 最后,打印出`kl_weight`的值
2.1.2 __call__
`__call__`方法是Python中的特殊方法,当实例被“调用”时会执行该方法。在这个方法中
- def __call__(self, qpos, image, actions=None, is_pad=None):
- env_state = None
- normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
- std=[0.229, 0.224, 0.225])
- image = normalize(image)
- if actions is not None: # training time
- actions = actions[:, :self.model.num_queries]
- is_pad = is_pad[:, :self.model.num_queries]
-
- a_hat, is_pad_hat, (mu, logvar) = self.model(qpos, image, env_state, actions, is_pad)
- total_kld, dim_wise_kld, mean_kld = kl_divergence(mu, logvar)
- loss_dict = dict()
- all_l1 = F.l1_loss(actions, a_hat, reduction='none')
- l1 = (all_l1 * ~is_pad.unsqueeze(-1)).mean()
- loss_dict['l1'] = l1
- loss_dict['kl'] = total_kld[0]
- loss_dict['loss'] = loss_dict['l1'] + loss_dict['kl'] * self.kl_weight
- return loss_dict
- else: # inference time
- a_hat, _, (_, _) = self.model(qpos, image, env_state) # no action, sample from prior
- return a_hat
- 首先定义了一个名为`env_state`的变量,并对输入的图像进行了归一化处理
- 然后,根据`actions`是否为`None`来判断是训练模式还是推理模式
- 在训练模式下,会计算出一系列的损失并返回一个包含这些损失的字典
- 在推理模式下,会从模型中获取预测的动作并返回
2.1.3 configure_optimizers
`configure_optimizers`方法返回在`__init__`方法中创建的优化器
2.2 CNNMLPPolicy
// 待更
2.3 kl_divergence
// 待更
第三部分 detr

关于什么是DETR,请查看此文的第三部分《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/Swin transformer》

3.1 main.py
3.1.1 get_args_parser
3.1.2 build_ACT_model_and_optimizer
3.1.3 build_CNNMLP_model_and_optimizer
3.2 models
3.2.1 __init__.py
3.2.2 backbone.py
3.2.3 detr_vae.py
3.2.4 position_encoding.py
3.2.5 transformer.py
第四部分 sim_env.py

4.1 make_sim_env:创建模拟机器人双手操作的环境(通过关节控制)
4.1.1 模拟环境中的动作空间与观察空间
名为`make_sim_env`的函数用于创建模拟机器人双手操作的环境(Environment for simulated robot bi-manual manipulation, with joint position control)
这个环境的动作空间包括以下4个方面
- Action space: [left_arm_qpos (6), # absolute joint position
- left_gripper_positions (1), # normalized gripper position (0: close, 1: open)
- right_arm_qpos (6), # absolute joint position
- right_gripper_positions (1),] # normalized gripper position (0: close, 1: open)
- 左臂的绝对关节位置
- 左手的标准化夹具位置
- 右臂的绝对关节位置
- 右手的标准化夹具位置
而观察空间包括上述动作空间的4个方面之外,还包括左臂和右臂的绝对关节速度、左手和右手的标准化夹具速度,以及一个主图像
- Observation space: {"qpos": Concat[ left_arm_qpos (6), # absolute joint position
- left_gripper_position (1), # normalized gripper position (0: close, 1: open)
- right_arm_qpos (6), # absolute joint position
- right_gripper_qpos (1)] # normalized gripper position (0: close, 1: open)
- "qvel": Concat[ left_arm_qvel (6), # absolute joint velocity (rad)
- left_gripper_velocity (1), # normalized gripper velocity (pos: opening, neg: closing)
- right_arm_qvel (6), # absolute joint velocity (rad)
- right_gripper_qvel (1)] # normalized gripper velocity (pos: opening, neg: closing)
- "images": {"main": (480x640x3)} # h, w, c, dtype='uint8'
4.1.2 make_sim_env的具体实现
- 函数首先检查任务名称中是否包含'sim_transfer_cube',如果是,它将创建一个用于模拟立方体转移任务的环境
这个环境使用了一个名为`TransferCubeTask`的任务,该任务在`TransferCubeTask`类中定义,这个任务的目标是让机器人的左手夹具抓住一个立方体,并将其转移到右手夹具
- if 'sim_transfer_cube' in task_name:
- xml_path = os.path.join(XML_DIR, f'bimanual_viperx_transfer_cube.xml')
- physics = mujoco.Physics.from_xml_path(xml_path)
-
- task = TransferCubeTask(random=False)
- env = control.Environment(physics, task, time_limit=20, control_timestep=DT,
- n_sub_steps=None, flat_observation=False)
- 如果任务名称中包含'sim_insertion',函数将创建一个用于模拟插入任务的环境。这个环境使用了一个名为`InsertionTask`的任务,该任务在`InsertionTask`类中定义。这个任务的目标是让机器人的右手夹具抓住一个插头,并将其插入左手夹具中的插座
- elif 'sim_insertion' in task_name:
- xml_path = os.path.join(XML_DIR, f'bimanual_viperx_insertion.xml')
- physics = mujoco.Physics.from_xml_path(xml_path)
- task = InsertionTask(random=False)
-
- # 在创建环境时,函数使用了`control.Environment`类
- # 这个类需要一个物理模型(在这里是从XML文件中加载的模型)
- # 一个任务、一个时间限制、一个控制时间步
- # 一个子步骤数(在这里没有指定,所以将使用默认值)
- # 以及一个标志来指示是否应该将观察结果扁平化(在这里设置为False,所以观察结果将保持其原始的嵌套结构)
- env = control.Environment(physics, task, time_limit=20, control_timestep=DT,
- n_sub_steps=None, flat_observation=False)
- 如果任务名称既不包含'sim_transfer_cube'也不包含'sim_insertion',函数将抛出一个`NotImplementedError`异常,最后,函数返回创建的环境
- else:
- raise NotImplementedError
- return env
4.2
// 待更
第五部分 ee_sim_env.py

5.1 make_ee_sim_env:通过末端执行器控制、操作相比make_sim_env更精细
5.1.1 模拟环境中的动作空间与观察空间
- Environment for simulated robot bi-manual manipulation, with end-effector control.
- Action space: [left_arm_pose (7), # position and quaternion for end effector
- left_gripper_positions (1), # normalized gripper position (0: close, 1: open)
- right_arm_pose (7), # position and quaternion for end effector
- right_gripper_positions (1),] # normalized gripper position (0: close, 1: open)
注意,上面这段make_ee_sim_env对动作的定义和make_sim_env中的动作定义不同
- make_sim_env中,动作空间包括每只手臂的6个关节位置和1个规范化抓手位置
- make_ee_sim_env中,动作空间包括每只手臂的末端执行器7个参数(位置和四元数)和1个规范化抓手位置
观察空间包括上面那些动作空间的元素,以及左臂和右臂的绝对关节速度、左手和右手的标准化夹具速度,以及一个主图像(和make_sim_env中的观察空间完全一致)
- Observation space: {"qpos": Concat[ left_arm_qpos (6), # absolute joint position
- left_gripper_position (1), # normalized gripper position (0: close, 1: open)
- right_arm_qpos (6), # absolute joint position
- right_gripper_qpos (1)] # normalized gripper position (0: close, 1: open)
- "qvel": Concat[ left_arm_qvel (6), # absolute joint velocity (rad)
- left_gripper_velocity (1), # normalized gripper velocity (pos: opening, neg: closing)
- right_arm_qvel (6), # absolute joint velocity (rad)
- right_gripper_qvel (1)] # normalized gripper velocity (pos: opening, neg: closing)
- "images": {"main": (480x640x3)} # h, w, c, dtype='uint8'
5.1.2 make_ee_sim_env的具体实现:文件名称中包含ee(代表末端执行器)
- 函数首先检查任务名称中是否包含'sim_transfer_cube'。如果是,它将创建一个用于模拟立方体转移任务的环境。这个环境使用了一个名为`TransferCubeEETask`的任务,该任务在`TransferCubeEETask`类中定义。这个任务的目标是让机器人的左手夹具抓住一个立方体,并将其转移到右手夹具
- if 'sim_transfer_cube' in task_name:
- xml_path = os.path.join(XML_DIR, f'bimanual_viperx_ee_transfer_cube.xml')
- physics = mujoco.Physics.from_xml_path(xml_path)
- task = TransferCubeEETask(random=False)
- env = control.Environment(physics, task, time_limit=20, control_timestep=DT,
- n_sub_steps=None, flat_observation=False)
- 如果任务名称中包含'sim_insertion',函数将创建一个用于模拟插入任务的环境。这个环境使用了一个名为`InsertionEETask`的任务,该任务在`InsertionEETask`类中定义。这个任务的目标是让机器人的右手夹具抓住一个插头,并将其插入左手夹具中的插座
- elif 'sim_insertion' in task_name:
- xml_path = os.path.join(XML_DIR, f'bimanual_viperx_ee_insertion.xml')
- physics = mujoco.Physics.from_xml_path(xml_path)
- task = InsertionEETask(random=False)
- env = control.Environment(physics, task, time_limit=20, control_timestep=DT,
- n_sub_steps=None, flat_observation=False)
- 如果任务名称既不包含'sim_transfer_cube'也不包含'sim_insertion',函数将抛出一个`NotImplementedError`异常,最后,函数返回创建的环境
- else:
- raise NotImplementedError
- return env
5.2 BimanualViperXEETask
定义了一个名为`BimanualViperXEETask`的类,它是`base.Task`的子类。这个类是用于强化学习的任务,特别是双手操作的任务
- `__init__`方法是类的构造函数,它接受一个可选的`random`参数,并将其传递给父类的构造函数。
- `before_step`方法在每一步动作之前被调用。它接受动作和物理模型作为参数。动作被分为左右两部分,分别对应左右手的动作。这些动作被用来设置模拟环境中的位置和方向
- `initialize_robots`方法用于初始化机器人的状态。它首先重置关节位置,然后设置模拟环境中的位置和方向,最后重置夹具控制
- `initialize_episode`方法在每个episode开始时被调用,它调用父类的同名方法
- `get_qpos`和`get_qvel`方法分别用于获取关节位置和关节速度。它们都接受物理模型作为参数,并返回一个包含了左右手臂和夹具的位置或速度的数组
- `get_env_state`方法是一个静态方法,它应该被子类实现,用于获取环境的状态
- `get_observation`方法用于获取观察结果。它接受物理模型作为参数,并返回一个包含了各种观察结果的字典
- `get_reward`方法是一个抽象方法,它应该被子类实现,用于计算每一步的奖励
// 待更
第六部分 record_sim_episodes:生成模拟环境中的演示数据
这段Python代码的主要目的是生成模拟环境中的演示数据
- 它首先在末端执行器(End-Effector)模拟环境中执行策略,获取关节轨迹
- 然后,它将夹具关节位置替换为命令关节位置
- 接着,它在模拟环境中重播这个关节轨迹(作为动作序列),并记录所有的观察结果
- 最后,它保存这个数据集,并继续下一个数据集的收集
在这个过程中,它使用了两个不同的环境:`make_ee_sim_env`和`make_sim_env`
- `make_ee_sim_env`创建的环境是用于模拟机器人双手操作的,其控制方式是末端执行器控制
- 而`make_sim_env`创建的环境可能是用于模拟机器人双手操作的,其控制方式是关节控制
这段代码还使用了一些策略类,如`PickAndTransferPolicy`和`InsertionPolicy`,这些策略类定义了如何在给定的环境中选择动作
此外,这段代码还使用了一些绘图功能,如`matplotlib.pyplot`,用于在屏幕上实时显示模拟环境的状态
最后,这段代码将收集的数据保存为HDF5格式的文件,这是一种用于存储大量数据的文件格式。这种格式的优点是可以高效地存储和读取大量的数据,而且支持多种数据类型,包括图像和数组等
第七部分 ACT的训练与部署
7.1 运行record_sim_episodes.py生成50集演示数据
- 首先安装一系列库(注意,在新版https://github.com/MarkFzp/act-plus-plus中明确了mujoco、dm_control版本的型号,老版https://github.com/tonyzhaozh/act中没有,建议以新版为准)
- conda create -n aloha python=3.8.10
- conda activate aloha
- pip install torchvision
- pip install torch
- pip install pyquaternion
- pip install pyyaml
- pip install rospkg
- pip install pexpect
- pip install mujoco==2.3.7
- pip install dm_control==1.0.14
- pip install opencv-python
- pip install matplotlib
- pip install einops
- pip install packaging
- pip install h5py
- pip install ipython
- cd act/detr && pip install -e .
- 设置新终端
- conda activate aloha
- cd <path to act repo>
- 针对方块转移这个任务sim_transfer_cube_scripted,可以先生成 50 集演示数据(To generated 50 episodes of scripted data),请运行:
- python3 record_sim_episodes.py \
- --task_name sim_transfer_cube_scripted \
- --dataset_dir <data save dir> \
- --num_episodes 50
python3 visualize_episodes.py --dataset_dir <data save dir> --episode_idx 0
注意,在跑这段代码的时候,注意相关库的版本号
从而顺利生成`TransferCubeTask`任务(让机器人的左手夹具抓住一个立方体,并将其转移到右手夹具)的演示数据
7.2 训练 ACT:运行本文的第一部分imitate_episodes.py
- # Transfer Cube task
- python3 imitate_episodes.py \
- --task_name sim_transfer_cube_scripted \
- --ckpt_dir <ckpt dir> \
- --policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 --batch_size 8 --dim_feedforward 3200 \
- --num_epochs 2000 --lr 1e-5 \
- --seed 0
第八部分 ACT算法的迭代发展史:从act到act-plus-plus
- 23年Q1,Tony Z. Zhao等人开发了Mobile Aloha的前身:Aloha系统,当时ACT算法便被提出来了,代码放在这个地址里:https://github.com/tonyzhaozh/act
- 24年1月,Zipeng Fu、Tony Z. Zhao等人在Aloha的基础上研发出Mobile Aloha,然后ACT的代码放到了这个地址:https://github.com/MarkFzp/act-plus-plus


