- 1【AIGC调研系列】llama 3与GPT4相比的优劣点
- 2TortoiseGit(Windows)使用方法汇总_windows 下的tortoise工具怎么使用
- 3手把手教你从零开始部署AI应用,医疗、金融、教育、零售等行业都用得上!...
- 4python在tkinter中使用ttk模块在窗口中添加按钮模块(Button)_ttk怎么创建可拖放按钮
- 510步Navicat for Mysql12.1.20破解激活方法(适用于Navica12.1系列软件)_navicat mysql密钥
- 6Co-Grounding Networks with Semantic Attention for Referring Expression Comprehension in Videos_refcoco数据集
- 7【论文阅读 WSDM‘21】PROP: Pre-training with Representative Words Prediction for Ad-hoc Retrieval_sentence pair和sentence order
- 8新人入职公司
- 9Pycharm个性化设置_pycharm界面设置
- 102021 年春招面试攻略来了。。。
机器学习基础_机器学习中的样本点和数据点的区别
赞
踩
什么是机器学习?
定义:系统通过学习如何组合输入信息来对从未见过的数据做出有用的预测
处理某个特定的任务,以大量的经验为基础。
- 对任务完成的好坏给予一定的评判标准。
- 通过分析经验数据,使任务完成的更好。

生活我们解决问题基本是靠发现一件事物的规律,然后来预测它未来呈现的结果
在机器学习中,我们用某一个模型来预测事物的属性。
基本术语:
- 数据集:数据记录的集合称为一个数据集
- 样本:数据集中每条记录是关于一个事件或对象的描述,称为"样本" ,简单来说,一行为一个样本
- 特征(属性):反映事件或对象在某方面的表现或性质的事项,例如"色泽","根蒂"等
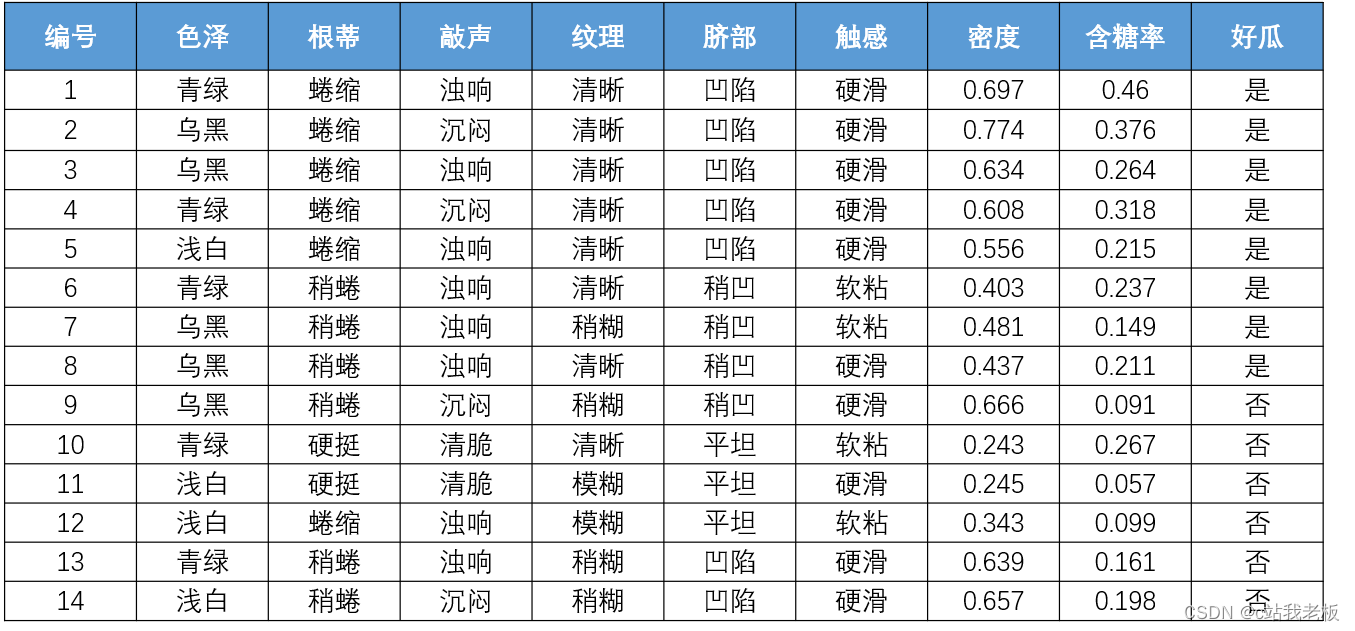
- 下图为一个数据集,数据集里面的除了特征皆是样本

样本:分为有标签和无标签
上图为无标签样本,有4个
下图的“好瓜”为标签,整体为有标签样本,有14个,一行为一个
- 属性空间:属性张成的空间称为“属性空间” 或”样本空间”
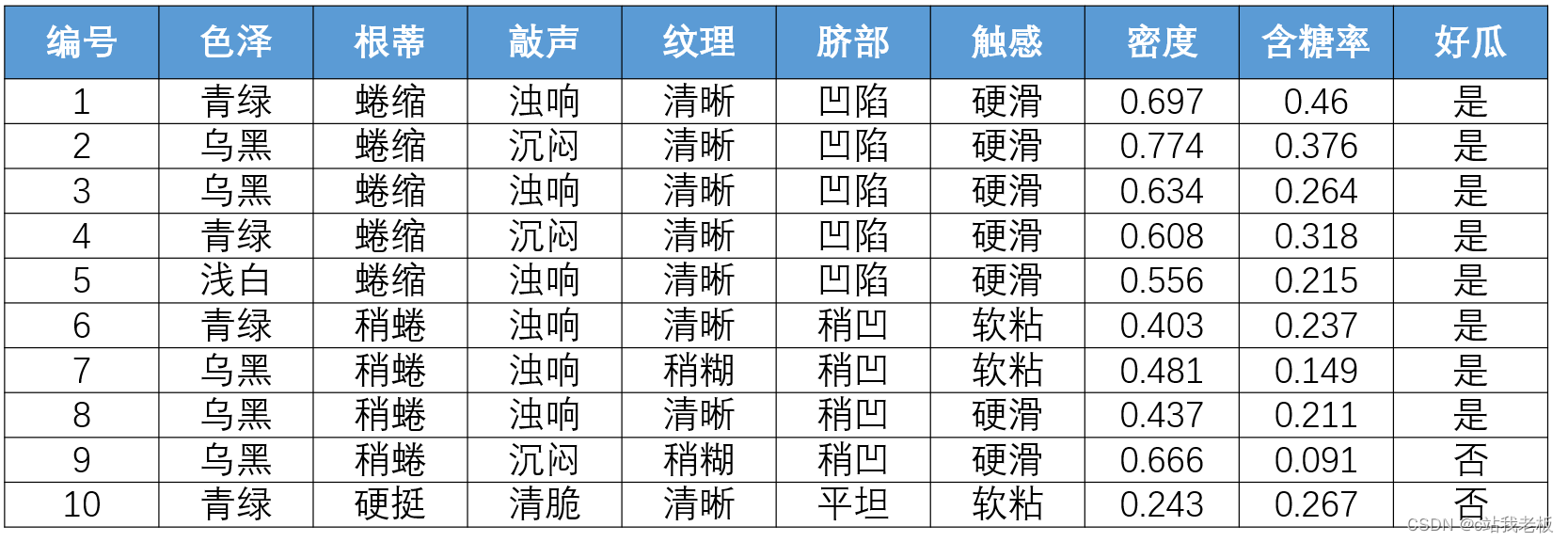
- 向量表示:一般地,令D = {x1 x2.. xm } 表示包含m 个示例的数据集,每个样本由d 个属性描述,则每个样本xi = (xi1; xi2; . . . ; xid) 是d 维样本空间X中的一个向量,d 称为样本Xi的“维数”。例如下图:具有3个特征,也就是3个维度,编号为1的样本,就是3维度空间的一个向量
- 训练集:含有标签的数据集
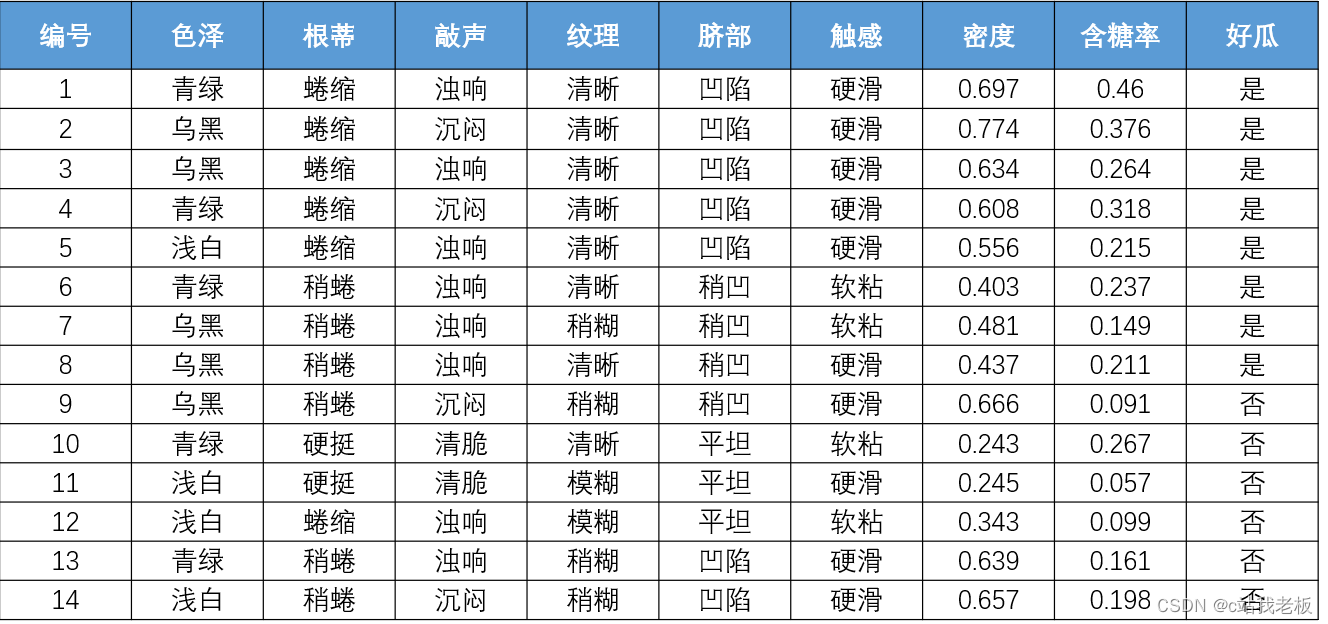
- 测试集:不含有标签的数据集 训练集:测试集一般为7:3或9:1(主要看数据集大小和波动程度,分情况来分,但训练集必须比测试集要多)
划分数据集:
1.尽可能保持数据分布的一致性。避免因数据划分过程引入的额外偏差而对最终结果产生影 响。在分类任务中,保留类别比例的采样方法称为“分层采样”。
2.采用若干次随机划分避免单次使用留出法的不稳定性

- 监督学习:由已知类别的样本调整分类器的参数,使其达到所要求性能的过程,监督学习的数据集由“正确答案”(标记)组成
- 无监督学习:提供数据集合但是不提供标记信息的学习过程
- 分类:机器学习模型输出的结果被限定为有限的一组值,即离散型数值。
- 回归:机器学习模型的输出可以是某个范围内的任何数值,即连续型数值。
集成学习:通过构建并结合多个学习器来完成学习任务。

模型评估与选择:分类错误的样本数占样本总数的比例称为"错误率"
精度:1-“错误率”
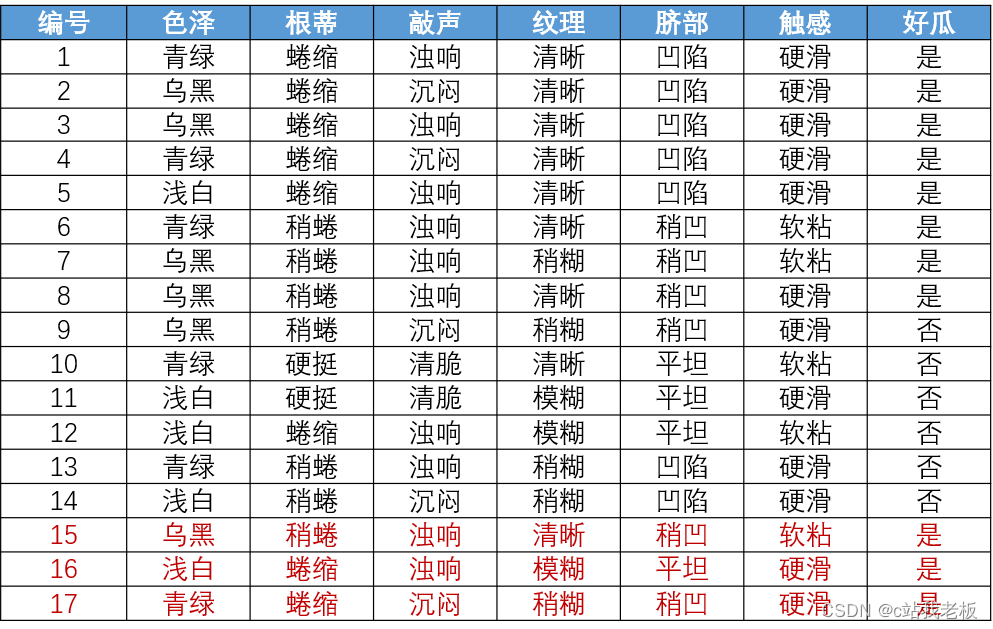
红色代表分类错误,错误率为3/17,精度就为14/17
-
残差:学习器的实际预测输出与样本的真实输出之间的差异
-
学习器在训练集上的误差称为“训练误差”或“经验误差”
-
学习器在新样本上的误差称为“泛化误差”
-
损失函数:用来衡量模型预测误差的大小的函数。样本点预测结果和真实结果之间会有偏差,我们就用一个损失函数来度量预测偏差的程度。损失函数是系统的函数,损失函数越小模型就越好。
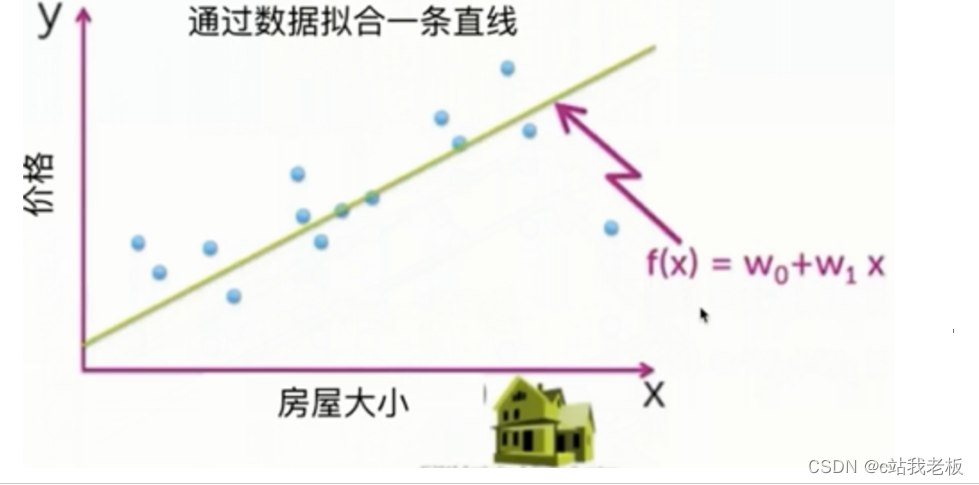
f(x)为损失函数
- 欠拟合:模型没有很好的捕捉到数据特征、特征集过小导致模型不能很好的拟合数据。欠拟合本质上是对数据特征学习的不够
- 过拟合:把训练数据学习的太彻底,以至于把噪声数据的特征也学习到了,特征集过大,这样就会导致在后期测试的时候不能够很好的识别数据,不能正确的分类,模型泛化能力太差。

上图是一个过拟合情况,训练集的数据远远超过测试集,测试集并不需要那么多的特征来验证。
过拟合的处理方式:
-
增加训练数据:更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响。
-
降维:即丢弃一些不能帮助我们正确预测的特征。例如序号等
-
.正则化(regularization)的技术,保留所有的特征,但是减少参数的大小(magnitude),它可以改善或者减少过拟合问题。
-
集成学习方法:集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险。
欠拟合的处理方式:
- 添加有用的新特征
- 增加模型复杂度:简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力
-
减小正则化系数:正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数。
选择模型的基本原则:
奥卡姆剃刀原理:“如无必要,勿增实体”,即“简单有效原理”

练习题:
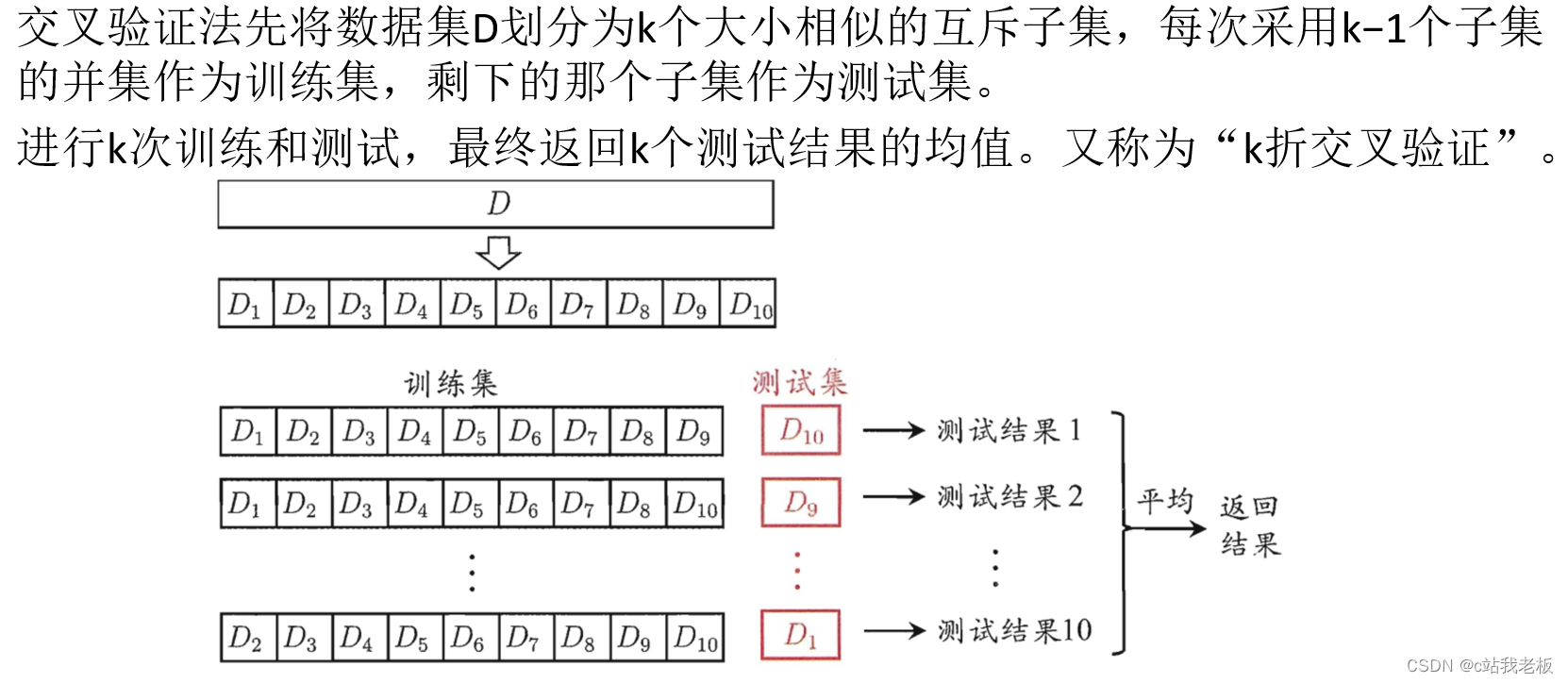
样本每组被分为8份(按特征分),例如样本一先选择含糖率作为测试集,样本2就选择其他的作为测试集,直到全部选择完当作测试集。
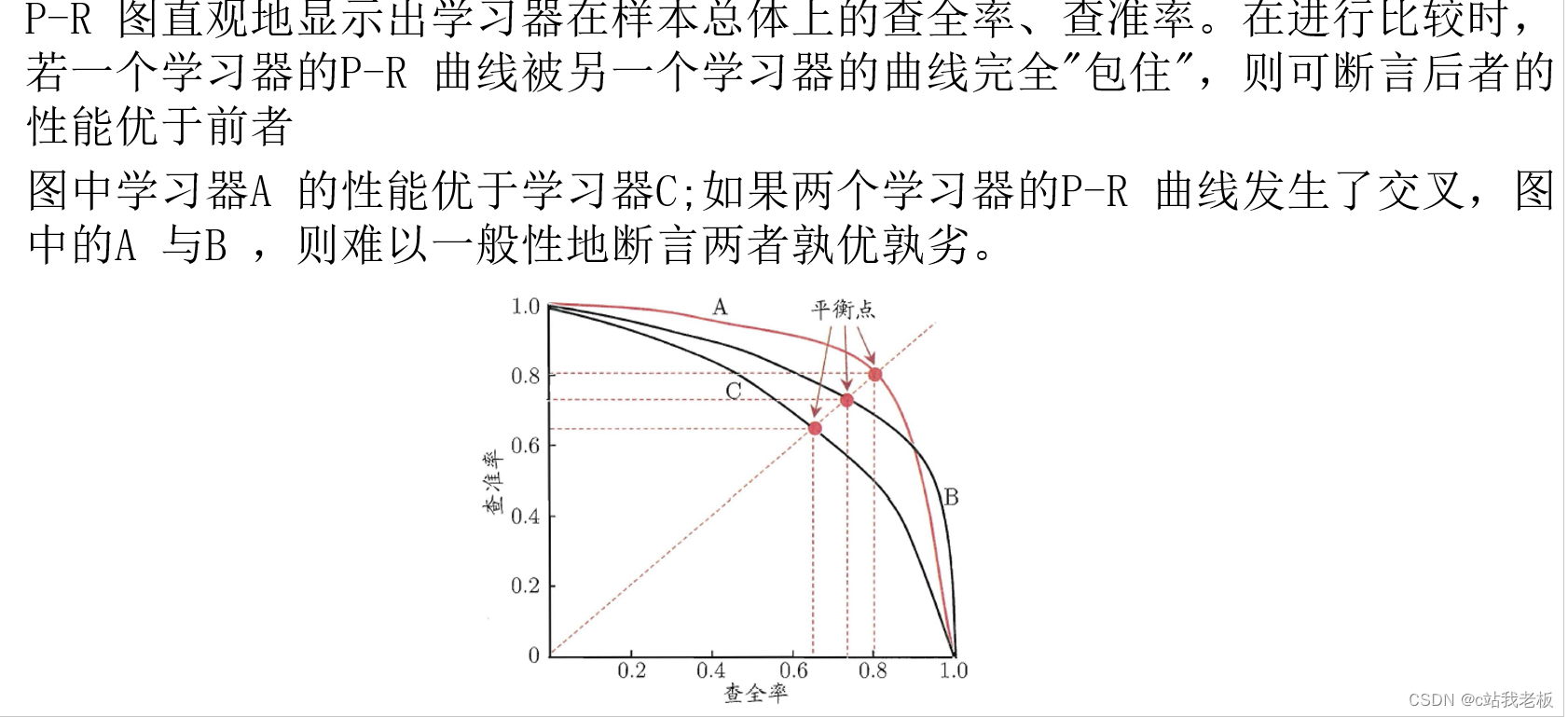
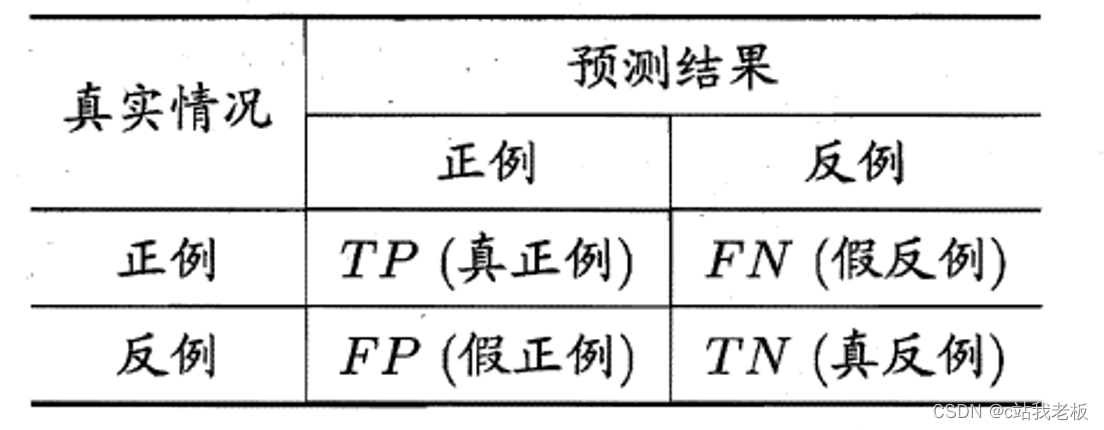
查准率(精确率)P和查全率(召回率)R:
TP(True positive,真正例)——将正类预测为正类数。
FP(False postive,假正例)——将反类预测为正类数。
TN(True negative,真反例)——将反类预测为反类数。
FN(False negative,假反例)——将正类预测为反类数。
先看训练集的预测结果,再看测试集
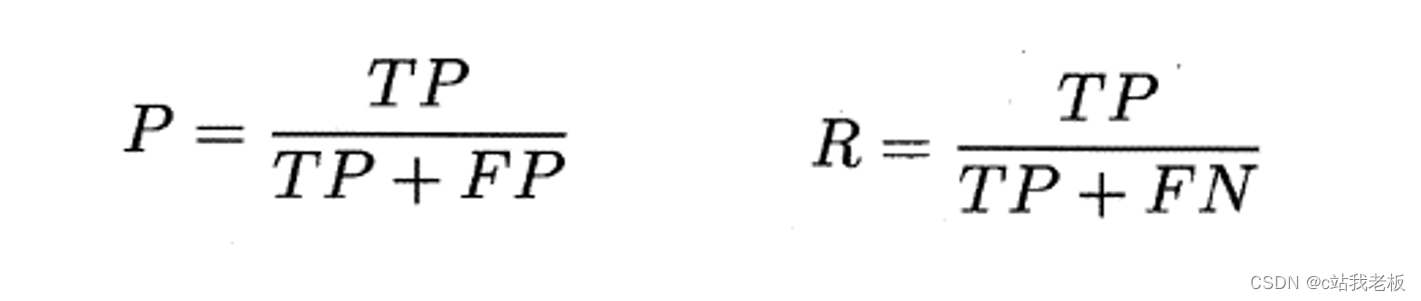
一般来说,查准率P高时,查全率R往往偏低;而查全率R高时,查准率P往往偏低.但是总体来说,二者当然是越大越好,说明模型对数据的准确率高。