
热门标签
热门文章
- 1【PostgreSQL】函数与操作符-时间/日期函数和操作符_pggresql 时间
- 2pytorch 基于sqs2sqs的中文聊天机器人_"enc_batch = batch[\"input_batch\"] src_mask = enc
- 3GitHub - 电脑无法访问GitHub_github进不去在前面加个什么
- 4Qt属性系统及其用法
- 5汽车开发项目经理要具备哪些素质?_汽车行业项目经理需要懂哪些
- 6「无线安全」WIFI安全-1之浅谈Wi-Fi
- 7centos7在线安装rabbitmq及其远程连接_centos rabbitmq 对外访问
- 8cuda 安装(windows)图解+指定版本cuda_cuda11.8安装
- 9python实现批量识别图片文字,生成对应的txt文件_python百度ai识别的文字怎么导出文件
- 10java3-5年面试题——框架篇_3-5年开发面试题
当前位置: article > 正文
Python写入Excel文件-多种实现方式(测试成功,附代码)
作者:不正经 | 2024-04-16 12:18:26
赞
踩
python写入excel
目录
xlsxwriter库储存数据到excel
简介
- 功能比较强:
支持字体设置、前景色背景色、border设置、视图缩放(zoom)、单元格合并、autofilter、freeze panes、公式、data validation、单元格注释、行高和列宽设置
- 支持大文件写入
- 不支持读取、修改、XLS文件、透视表(Pivot Table
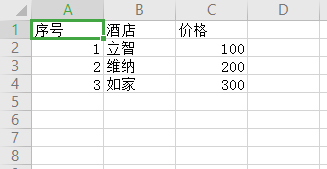
示例:写入excel
更多
添加工作表样式:
写入单元格数据
插入图片
写入超链接
worksheet1.write_url(row, col, "internal:%s!A1" % ("要关联的工作表表名"), string="超链接显示的名字")插入图表
- 获得当前excel文件的所有工作表:workbook.worksheets()
- 关闭excel文件: workbook.close()
pandas库储存数据到excel
简介
在Python中,pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
pandas有两个主要数据结构:Series和DataFrame。
- Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
- DataFrame
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)
示例:写入excel
openpyxl库储存数据到excel
- 安装:pip install openpyxl==2.2.6
示例:写入excel
更多
打开已有文件
根据数字得到字母,根据字母得到数字
删除工作表
查看表名和选择表(sheet)
设置单元格风格
更多python方法:
python入门-从安装环境配置(Anaconda)到做一个下班打卡提醒.exe小工具
python爬虫使用 requests-html爬取网页信息以及常用方法
Python爬虫之selenium(全套操作)常用的定位元素与常用方法

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/434152
推荐阅读

相关标签

