
- 1【数据结构与算法】:10道链表经典OJ
- 2runtimeerror什么原因_runtime error 解决方法
- 3CycleGAN(Cycle-Consistent Generative Adversarial Network)_cyclegan 变种
- 4《使用Unreal Engine Python插件进行UE4中的Python开发》学习笔记1_ue4 python
- 5二叉树和数据结构
- 6基于STM32单片机智能开关量检测控制舵机机械臂设计21-052_单片机机械臂设计
- 7将基于Centos下的Linux 中的man 汉化
- 8MySQL查询某个子节点的顶级节点(根节点)_nysql5.7查子节点的顶级父节点
- 9重启iis,提示帐户名与安全标示间无任何映射_iis 帐户名与安全标识间无任何映射完成
- 10大数据和人工智能概念全面解析_大数据人工智能是什么
RAG进阶之通用文档处理:从RAGFlow、TextMonkey到mPLUG-DocOwl 1.5_ragflow的使用
赞
踩
前言
我司RAG项目组每个月都会接到一些B端客户的项目需求,做的多了,会发现很多需求是大同小异的,所以我们准备做一个通用的产品,特别是对通用文档的处理
而在此之前,我们则想先学习一下目前市面上各种优秀的解决方法(且先只看开源的),于是便有了本文
第一部分 InfiniFlow开源RAGFlow
继InfiniFlow于去年年底正式开源 AI 原生数据库 Infinity 之后,InfiniFlow的的端到端 RAG 解决方案 RAGFlow 也于近期正式开源(项目地址:https://github.com/infiniflow/ragflow,在线Demo:https://demo.ragflow.io)
对于 RAG 来说,最终依赖于LLM和RAG系统本身
对于LLM而言,其最基础的能力包括:摘要能力、翻译能力、可控性(是否听话)
而对于RAG 系统本身,其包含:
-
数据库的问题。多路召回对于 RAG还挺重要的。哪怕最简易的知识库,没有多路召回,也很难表现好。因此,RAG 系统的数据库,需要具备多路召回能力,而非简易的向量数据库
对于这第一点,InfiniFlow提供了 RAG 专用的数据库 Infinity 来缓解 -
数据的问题。拿现有的开源软件栈,包括各种向量数据库 ,RAG 编排工具例如 LangChain, LlamaIndex 等,再搭配一个漂亮的 UI,就可以很容易的让一套 RAG 系统运行起来
类似的编排工具,在 Github 上已经有数万的 star, 然而,所有这些工具,都没有很好地解决数据本身的问题,这导致复杂格式的文档是以混乱的方式进入到数据库中,必然导致 Garbage In Garbage Out
对于这第二点,InfiniFlow提供一款专用的 RAG 工具——RAGFlow
下边我们来看看 RAGFlow 这款产品,相比目前市面上已有的各类开源方案,都有哪些特点
1.1 允许用户上传并管理自己的文档(文档类型可以是任意类型)
首先, RAGFlow 是一款完整的 RAG 解决方案,它允许用户上传并管理自己的文档,文档类型可以是任意类型,例如 PDF、Word、PPT、Excel、当然也包含 TXT,在完成智能解析之后,让数据以正确地格式进入到数据库,然后用户可以采用任意大模型对自己上传的文档进行提问。也就是说,包含了如下完整的端到端流程
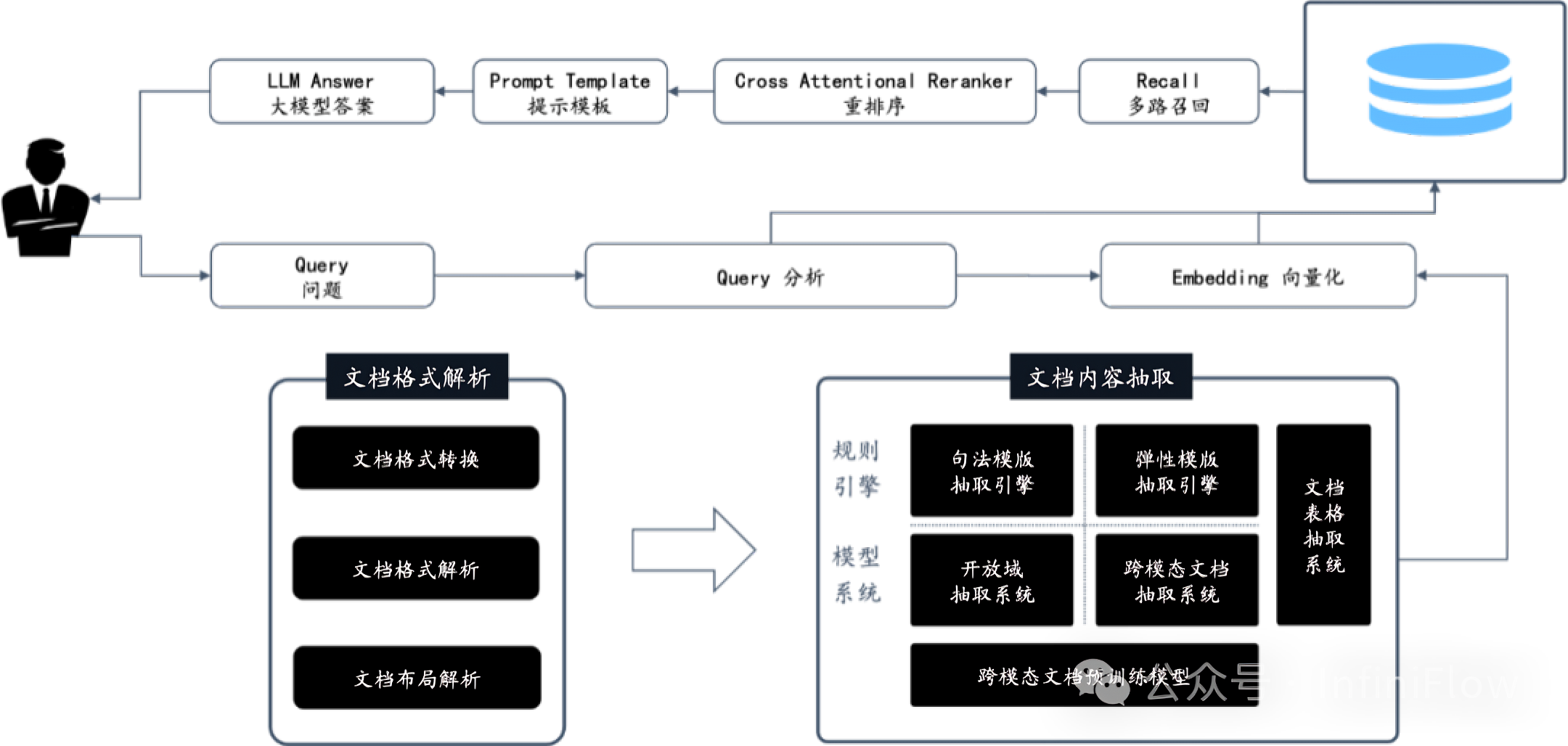
1.2 基于 AI 模型的智能文档处理系统
其次,RAGFlow 的最大特色,就是多样化的文档智能处理,保证用户的数据从 Garbage In Garbage Out 变为 Quality In Quality Out
为了做到这一点, RAGFlow 没有采用现成的 RAG 中间件,而是完全重新研发了一套智能文档理解系统,并以此为依托构建 RAG 任务编排体系
这个系统的特点包含以下4个点
1.2.1 AI 模型的智能文档处理系统
它是一套基于 AI 模型的智能文档处理系统:对于用户上传的文档,它需要自动识别文档的布局,包括标题,段落,换行等等,还包含难度很大的图片和表格。
对于表格来说,不仅仅要识别出文档中存在表格,还会针对表格的布局做进一步识别,包括内部每一个单元格,多行文字是否需要合并成一个单元格,等等,并且表格的内容还会结合表头信息处理,确保以合适的形式送到数据库,从而完成 RAG 针对这些细节数字的“大海捞针”
1.2.2 包含各种不同模板的智能文档处理系统
它是一套包含各种不同模板的智能文档处理系统:不同行业不同岗位所用到的文档不同,行文格式不同,对文档查阅的需求也不同。比如:
- 会计一般最常接触到的凭证,发票,Excel报表
查询的一般都是数字,如:看一下上月十五号发生哪些凭证,总额多少?上季度资产负债表里面净资产总额多少?合同台账中下个月有哪些应付应收? - 作为一个HR平时接触最庞杂的便是候选人简历
且查询最多的是列表查询,如:人才库中985/211的3到5年的算法工程师有哪些?985 硕士以上学历的人员有哪些?赵玉田的微信号多少?香秀哪个学校的来着? - 作为科研工作者接触到最多的可能是就是论文了,快速阅读和理解论文,梳理论文和引文之间的关系成了他们的痛点
这样看来凭证/报表、简历、论文的文档结构是不一样的,查询需求也是不一样的,那处理方式肯定是不一样。因此RAGFlow 在处理文档时,给了不少的选择:Q&A,Resume,Paper,Manual,Table,Book,Law,通用(当然,这些分类还在不断继续扩展中,处理过程还有待完善)...

1.2.3 智能文档处理的可视化和可解释性
智能文档处理的可视化和可解释性:用户上传的文档到底被处理成啥样了,如:分割了多少片,各种图表处理成啥样了,毕竟任何基于 AI 的系统只能保证大概率正确,作为系统有必要给出这样的空间让用户进行适当的干预,作为用户也有把控的需求,黑箱不敌白箱
特别是对于 PDF,行文多种多样,变化多端,而且广泛流行于各行各业,对于它的把控尤为重要,RAGFlow不仅给出了处理结果,而且可以让用户查看文档解析结果并一次点击定位到原文,对比和原文的差异,可增可减可改可查
1.2.4 让用户随时查看 LLM 是基于哪些原文来生成答案的
最后, RAGFlow 是一个完整的 RAG 系统,而目前开源的 RAG,大都忽视了 RAG 本身的最大优势之一:可以让 LLM 以可控的方式回答问题,或者换种说法:有理有据、消除幻觉
我们都知道,随着模型能力的不同,LLM 多少都会有概率会出现幻觉,在这种情况下, 一款 RAG 产品应该随时随地给用户以参考,让用户随时查看 LLM 是基于哪些原文来生成答案的,这需要同时生成原文的引用链接,并允许用户的鼠标 hover 上去即可调出原文的内容,甚至包含图表。如果还不能确定,再点一下便能定位到原文
// 待更
第二部分 通用文档理解:多模态大模型TextMonkey
// 待更
第三部分 阿里7B多模态文档处理系统:mPLUG-DocOwl 1.5
// 待更

