
热门标签
热门文章
- 1华为eNSP配置MSTP实验_ensp的mstp配置
- 2git rm --cached
- 3用pygame做一个小游戏,可以玩一整天(基础框架)_pygame小游戏
- 4git从【本地分支】直接推送到【远程主分支】了怎么办?
- 5python小游戏
- 6C语言实现一个趣味游戏_c 游戏
- 7flutter 面试题_flutter面试题
- 8string数组转string_一列转多列——Flink提供的Tuple25不够用该怎么办?
- 9关于树形结构建立过程中动态申请的节点空间_树的节点如何开辟空间
- 10基于双树复小波变换 (Dual-Tree Complex Wavelet Transforms,DTCWT) 的轴承故障诊断方面
当前位置: article > 正文
CLIP项目复现
作者:不正经 | 2024-04-17 08:47:57
赞
踩
CLIP项目复现
代码原址:
项目介绍:
image caption简单来说就是看图说话:给定一张图片,生成该图片对应的自然语言描述。图像描述任务涉及到了图像和自然语言两个模态,然而图像与自然语言空间本身就非常庞大,两者之间存在巨大的语义鸿沟。如何将两个庞大的语义空间对齐,是图像描述任务的重点。
ClipCap: CLIP Prefix for Image Captioning 这篇论文实现了图像到语义空间的转化,搭建了一种基于Mapping Network的Encoder-Decoder模型,其中Mapping Network扮演了图像空间与文本空间之间的桥梁。论文模型主要分为三部分:
- 图像编码器:采用CLIP模型,负责对输入的图像进行编码,得到一个图片向量。
- Mapping Network:扮演图像空间与文本空间之间的桥梁,负责将图片向量映射到文本空间中,得到一个文本提示向量序列。
- 文本解码器:采用GPT2模型,根据提示向量序列,生成最终的预测描述

CLIP算法核心:
CLIP算法本质上就是完成图像-文本对匹配。通过图像和文本编码器转化成向量,再进一步转化到同一个高维的向量空间中,计算图像和文本向量的相似度。实际就是在训练数据,让图像和文本完成一对一匹配,当输入预测图片时候,得到预测图片向量,去训练好的匹配库中,找出最相似的文本向量进行输出。
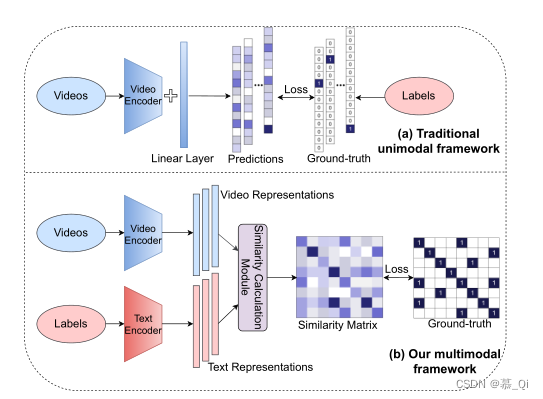
效果展示:
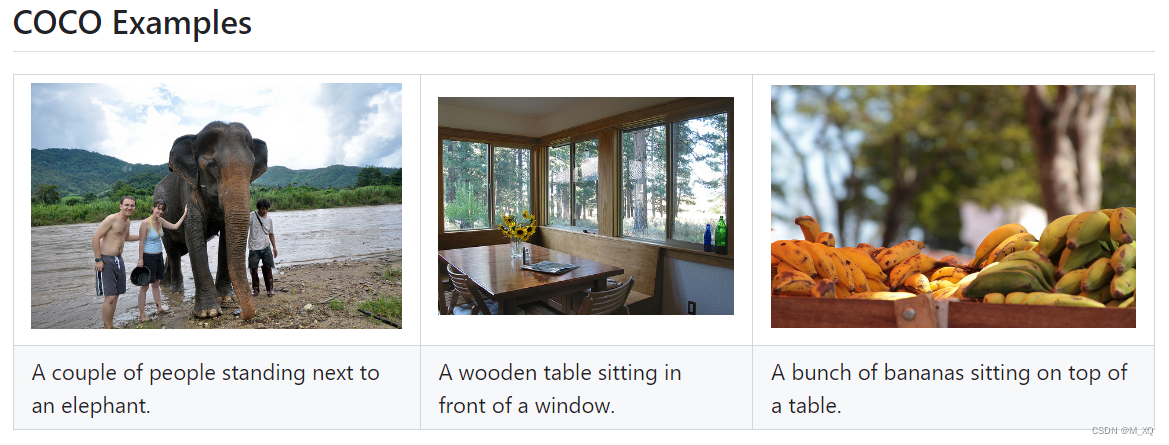
本人根据clip官网的代码,替换过数据集进行过训练和测试,包括中文数据和英文数据。英文数据测试效果如下:
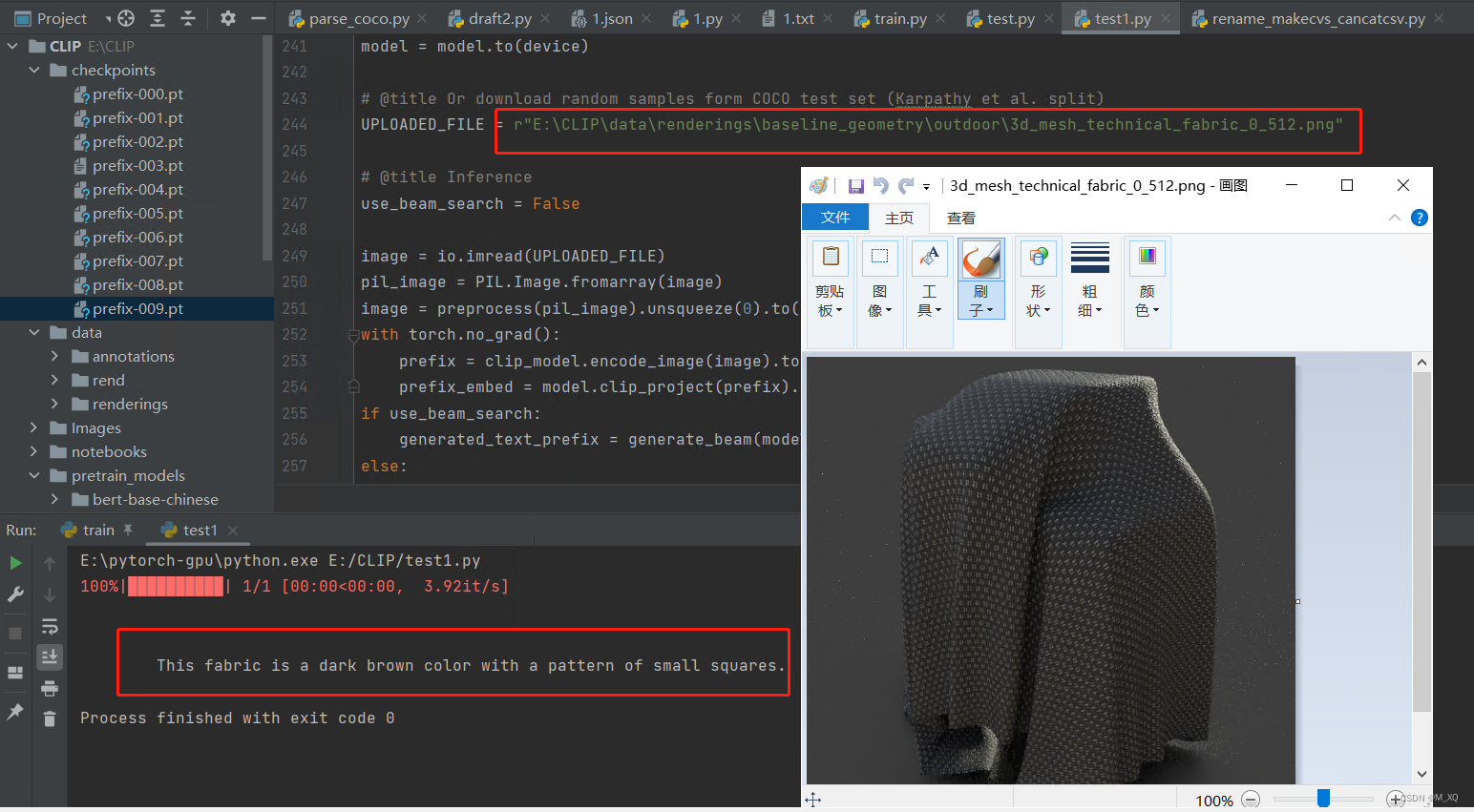
clip这个项目代码需要的环境很复杂,有点难调,我有搭好的环境和现成改好的代码,有需要替换自己数据集进行训练和测试的朋友,欢迎来私信我,有偿帮忙训练和讲解哦!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/439267
推荐阅读
相关标签

