
利用预训练模型的先验知识实现图像超分辨率的新途径——StableSR
赞
踩
随着扩散模型在图像生成任务中的长足发展,研究人员开始尝试将其应用于下游任务中。其中图像超分辨率是一个值得探索的方向。近期工作StableSR提供了一种新方法,即在不需从头训练的情况下,有效利用预训练文本到图像模型Stable Diffusion所含的强大生成先验知识,来实现图像的超分辨率。
StableSR的关键创新在于提出了时间感知编码器。它通过时间嵌入层生成与时间相关的特征,以自适应地调制固定的Stable Diffusion模型中的中间特征图。这样既提高了训练效率,也保留了原模型所包含的生成先验。时间感知编码器还可以在恢复过程中提供适应性指导,即在前期给予较强指导、后期指导较弱,从而在保真度和质量之间取得平衡。
为进一步提高保真度,StableSR还引入了可控特征装配模块。它允许用户通过简单调整一个系数,在质量和保真度之间实现平滑可控的权衡。此外,渐进聚合采样策略可以解决固定分辨率的限制,使模型可以处理任意大小的图像。
在合成和真实图像的测试中,StableSR都显示出比现有方法更好的性能。它只需要微调极少的参数,就可以发挥预训练模型所含的丰富先验知识,并解决固有的问题。未来可望在其基础上,继续探索如何更好地利用预训练模型的先验,来提升下游任务的性能。

1、StableSR是一个利用预训练文本到图像转换模型(Stable Diffusion)中的先验知识进行图像超分辨率的新方法。它通过微调一个时间感知编码器和几个特征调制层来实现,而不需要从头训练一个扩散模型。
2、StableSR的关键组成部分是一个时间感知编码器,它可以生成与时间相关的特征。这样就可以在不同的迭代中对扩散模型中的特征进行自适应调制。保持原始扩散模型固定可以更高效地训练,并保留生成先验。时间感知编码器也有助于在恢复过程中提供自适应指导,即在早期提供更强的指导,后期提供较弱的指导,以维持保真度。
3、与其他图像放大算法相比,StableSR具有以下优势:
(1) 更高效的训练,只需要微调一个轻量级的时间感知编码器,而不需要从头训练一个大型模型。
(2) 利用了预训练的Stable Diffusion中的丰富的生成先验知识,从而获得更好的性能。
(3) 提出了时间感知编码器,可以提供自适应的条件指导,这对于提高保真度和质量很关键。
(4) 提出了可控特征装配模块,可以在质量和保真度之间实现平衡。
(5) 提出了渐进聚合采样策略,可以处理任意分辨率的图像,扩大了实用性。
(6) 在合成和真实图像的基准测试中都显示出比现有方法更好的性能。
StableSR的框架包括以下几个要点:
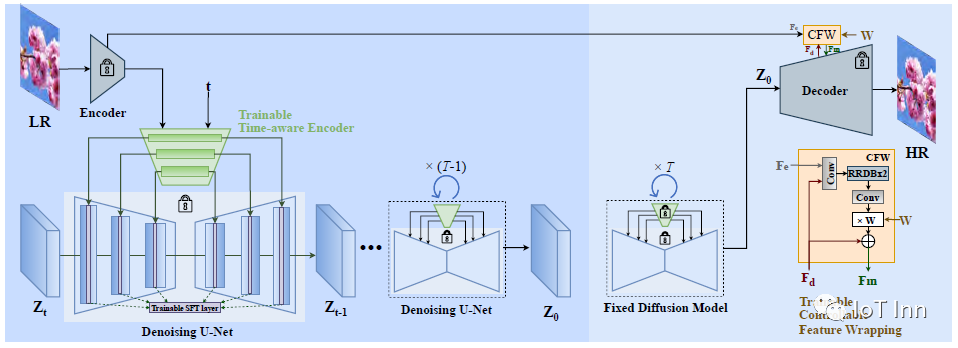
首先微调连接到固定的预训练Stable Diffusion模型上的时间感知编码器。特征与可训练的空间特征变换(SFT)层相结合。这种简单而有效的设计能够利用丰富的扩散先验进行图像超分辨率。然后,扩散模型固定,引入一个可控特征包装(CFW)模块,以残差的方式获得调谐特征Fm,给定来自LR特征的额外信息Fe和来自固定解码器的特征Fd。通过可调节的系数w,CFW可以在质量和保真度之间进行权衡。
1. 时间感知编码器(Time-aware Encoder)
- 微调连接在固定的预训练Stable Diffusion模型上的轻量级编码器
- 通过时间嵌入层生成与时间相关的特征,以对不同迭代中的特征进行自适应调制
- 提取LR图像的多尺度特征,经过SFT层与Stable Diffusion的特征结合
- 只训练编码器和SFT层的参数,固定Stable Diffusion模型的参数
2. 固定的Stable Diffusion模型(Fixed Stable Diffusion)
- 预训练好的文本到图像生成模型,提供强大的生成先验
- 参数固定,不修改原模型,以保留其包含的先验知识
3. 可控特征装配模块(Controllable Feature Wrapping, CFW)
- 借鉴CodeFormer,从编码器中获取LR图像特征,与解码器特征残差结合
- 通过调节系数w平衡质量和保真度
4. 渐进聚合采样策略(Progressive Aggregation Sampling)
- 将图像分割为重叠补丁,每步聚合处理,避免边界不一致
- 可处理任意大小的图像
以上模块协同工作,使StableSR可以有效利用Stable Diffusion的先验进行超分辨率,并处理关键问题如保真度、任意分辨率等。
现有模型也可以加载到Stable Diffusion中体验,常规操作,我们打开SD,然后选择扩展从网址安装https://github.com/pkuliyi2015/sd-webui-stablesr.git
需要注意的是,StableSR必须配合Stable Diffusion V2.1 768模型来使用 ,可以从stabilityai/stable-diffusion-2-1-base · Hugging Face来下载, 然后StableSR官方模型可以从webui_768v_139.ckpt · Iceclear/StableSR at main (huggingface.co)来进行下载,无法科学上网的同学,可以关注我后台回复StableSR获取下载链接
具体使用步骤:
在 WebUI 的顶部,选择你下载的 v2-1_512-ema-pruned 模型。
切换到 img2img 标签。在页面底部找到 "Scripts" 下拉列表。
选择 StableSR 脚本。
点击刷新按钮,选择你已下载的 StableSR 检查点。
选择一个放大因子。
上传你的图像并开始生成(无需提示也能工作)。
推荐使用 Euler a 采样器,CFG值=7,步数 >= 20。
尽管StableSR不需要提示词也能工作,我们发现负面提示词能显著增强细节。比如使用3d, cartoon, anime, sketches, (worst quality:2), (low quality:2)
点击查看有/没有prompt的对比
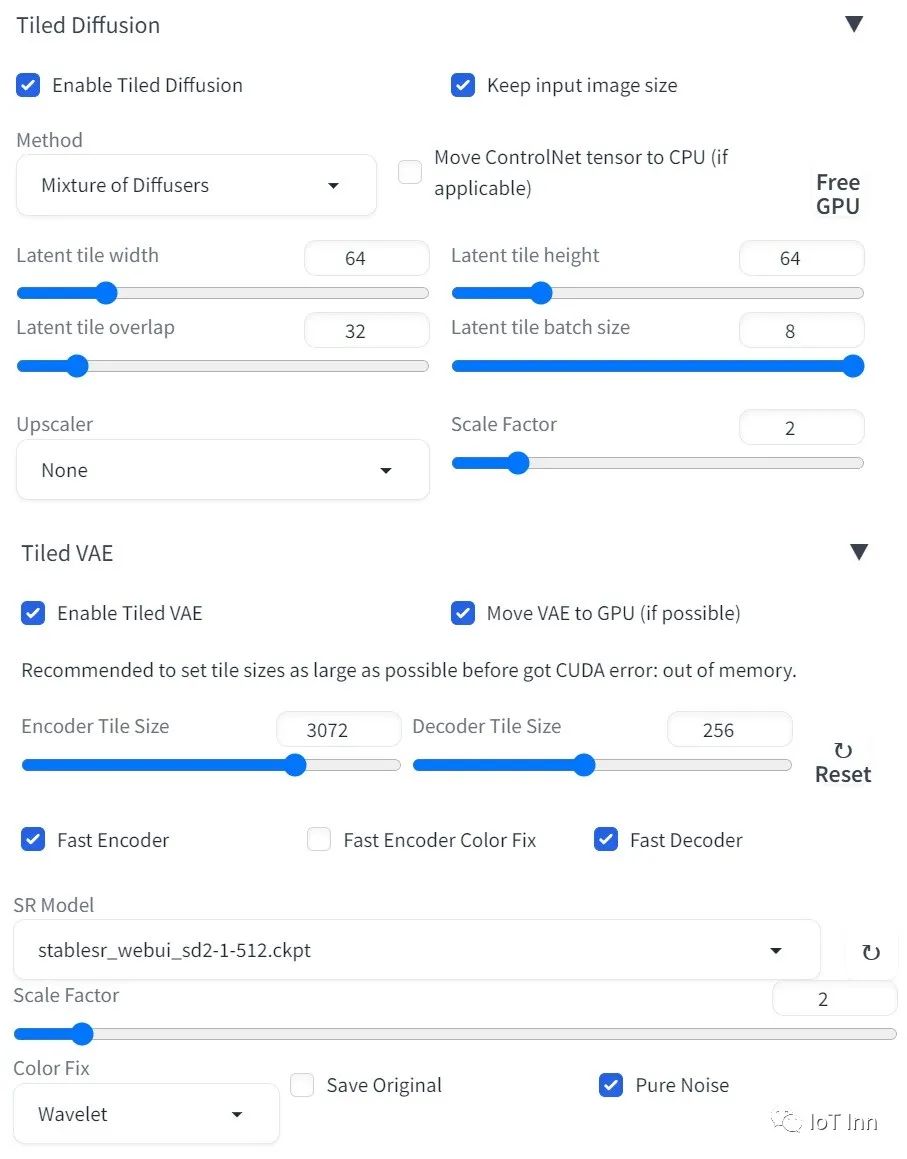
如果生成图像尺寸 > 512,我们推荐使用 Tiled Diffusion & VAE,否则,图像质量可能不理想,VRAM 使用量也会很大。
这里是官方推荐的 Tiled Diffusion 设置。
方法 = Mixture of Diffusers
隐空间Tile大小 = 64,隐空间Tile重叠 = 32
Tile批大小尽可能大,直到差一点点就炸显存为止。
Upscaler必须选择None。
下图是24GB显存的推荐设置。
对于4GB的设备,只需将Tiled Diffusion Latent tile批处理大小改为1,Tiled VAE编码器Tile大小改为1024,解码器Tile大小改为128。
SDP注意力优化可能会导致OOM(内存不足),因此推荐使用xformers。
除非你有深入的理解,否则你不要改变Tiled Diffusion & Tiled VAE中的其他设置。这些参数对于StableSR基本上是最优解
具体参数配置如下:
对比下试验结果


放大两倍后,效果还是比较明显,清晰度有了明显提升,细节也更丰富
想尝试的小伙伴,点个关注吧
- 1、Feature选取之选中样式[详细] -->
赞
踩

