
- 1java面试必备--JAVA算法(四) 之 高并发之限流令牌桶和漏桶算法_漏桶算法 java
- 2鸿蒙HarmonyOS应用开发从入门到实战_harmonyos应用开发实战
- 3【数据结构与算法】单链表的插入和删除_实现单向链表删除算法。
- 4Docker 笔记(六)--存储(Volumes、Bind mounts、tmpfs mounts)_docker --tmpfs
- 5在python中_python中%代表什么意思?
- 6动态规划之背包问题_背包问题 动态规划
- 7读书笔记-增强型分析:AI驱动的数据分析、业务决策与案例实践
- 8短 URL 系统是怎么设计的?
- 9算法之滑动窗口算法_滑动时间窗口算法
- 10完美解决huggingface问题:Failed to connect to huggingface.co port 443
Hotspot Oop模型——Java对象内存表示机制_markoopdesc
赞
踩
目录
在上一篇 《 Hotspot Klass模型——Java类内存表示机制》中已经讲到OopDesc用于保存类实例属性,包含每个实例独享的非静态属性和所有实例共享的静态属性,其中非静态属性由表示普通Java类的InstanceKlass对应的OopDesc保存,静态属性是表示特殊的java.lang.Class类的InstanceMirrorKlass对应的OopDesc保存的。数组的数据是由ArrayKlass对应的OopDesc保存,会按照维度记录每个数组元素的取值。OopDesc保存了一个指向InstanceKlass或者ArrayKlass的指针,Java类实例通过此指针可以调用Java方法或者获取静态属性。下面逐一探讨各Klass对应的OopDesc的类定义和内存结构。
1、类继承结构
oopDesc类是用于表示Java对象的基类,各种{name}Desc描述了Java对象的构成,这样C++可以访问Java对象的字段,注意oopDesc没有任何虚方法。其类继承结构如下图: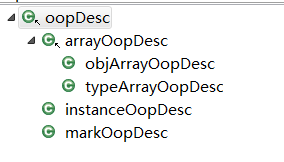
2、oopDesc
oopDesc包含的属性如下:
_mark:volatile markOopDesc指针,markOopDesc是oopDesc的子类,用于描述对象头,因为保证对象状态变更在各CPU种同步,所以加volatile修饰
_metadata:是一个union结构,用于表示该oopDesc关联的Klass,使用压缩指针时,就设置其中的_compressed_klass属性,如下图:
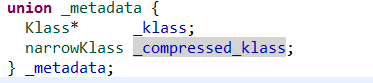
_bs:BarrierSet指针,BarrierSet提供了屏障实现和系统其它部分之间的接口,是静态属性,必须初始化
除属性相关的方法外,oopDesc定义了如下几类方法:
- 根据偏移量获取不同类型的Java字段的地址,如byte_field_addr,int_field_addr,obj_field_addr等
- 指针压缩和解压缩的方法,如decode_heap_oop,encode_heap_oop等
- 加载存储堆外对象的方法,如load_heap_oop,store_heap_oop等,堆外对象应该是指元空间中的对象
- 根据偏移量获取和设置不同类型的Java字段的方法,如byte_field,byte_field_put等
- 跟GC相关的方法,如age,incr_age,is_gc_marked等
3、markOopDesc
markOopDesc继承自oopDesc,用于描述对象头,oopDesc中的_mark属性引用的并不是一个真实存在的markOopDesc实例,只是一个字宽大小的无效内存地址罢了,对象状态不同,不同位数对应的含义各不相同,如下图:

红框中是对象状态,前面是不同位数的含义,注释不一定准确,以具体方法实现为准。其中hash表示对象的hash码,JVM规定了hash码最大不超过31位,所以32位和64位下hash码占的位数都是31;age记录垃圾回收时的对象年龄;biased_lock表示偏向锁的状态,0表示无锁,1表示有锁;lock表示锁的状态,00表示该对象加了轻量级锁如偏向锁,自旋锁等,此时前面的JavaThread指针指向当前线程栈的头部,01是无锁,10表示该对象加了重量级锁ObjectMonitor,比如synchronized同步用的对象,此时前面的JavaThread指针指向重量级锁对象ObjectMonitor,11是GC标志,用于标记对象;epoch是偏向锁使用的状态标识,
markOopDesc定义很多根据对象头获取对象状态信息的方法,如判断对象是否上锁的is_locked,判断对象是否有对象锁的has_monitor方法,如下图:


其中mask_bits是取指定位数的值,value()返回的就是this指针,如下图:

测试代码如下:
- package jvmTest;
-
- import java.lang.management.ManagementFactory;
- import java.lang.management.RuntimeMXBean;
-
-
- public class MarkTest implements Runnable{
-
- private static Object obj=new Object();
-
- @Override
- public void run() {
- synchronized (obj){
- try {
- Thread.sleep(600000);
- System.out.println("MarkTest,thread id="+Thread.currentThread().getId());
- } catch (InterruptedException e) {
-
- }
- }
- }
-
- public static void main(String[] args) {
- Thread a=new Thread(new MarkTest());
- a.start();
- Thread b=new Thread(new MarkTest());
- b.start();
- System.out.println("thread start");
- while (true) {
- try {
- System.out.println(getProcessID());
- Thread.sleep(600 * 1000);
- } catch (Exception e) {
-
- }
- }
- }
-
- public static final int getProcessID() {
- RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
- System.out.println(runtimeMXBean.getName());
- return Integer.valueOf(runtimeMXBean.getName().split("@")[0])
- .intValue();
- }
- }

先通过MarkTest对应的Klass的_java_mirror属性找到静态对象obj的地址,如下图:

然后用mem查看该obj对象的_mark属性的内存值,如下图:

根据_mark属性获取ObjectMonitor地址的方法如下图:

monitor_value的取值就是2,二进制就是10,进行异或运算后的地址是0x00000000177cab98,用printas命令查看该对象,如下图:
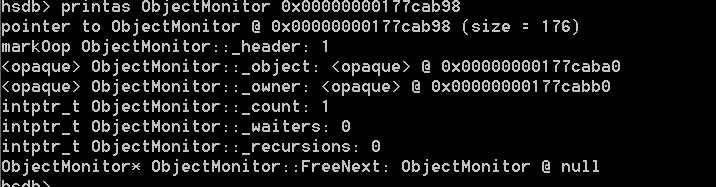
也可在Monitor Cache Dump中查看所有的ObjectMonitor,如下图:

4、InstanceOopDesc
instanceOopDesc继承自oopDesc,用于表示普通的Java对象,每次new一个Java对象就会创建一个新的instanceOopDesc实例。该类没有添加新的属性,只是新增了两个方法,base_offset_in_bytes()用于返回包含OopDesc自身属性的内存的偏移量,即该偏移量之后的内存用于保存Java对象实例属性,contains_field_offset(int offset, int nonstatic_field_size)用于判断是否包含指定偏移量的非静态属性。
instanceOopDesc是如何保存Java对象实例的属性了?可以从oopDesc定义的根据偏移量获取字段值和设置字段值的方法实现找答案。基本类型字段的实现都是在oopDesc的地址的基础上加上一个偏移量算出该字段的地址,偏移量的单位是字节,各字段的偏移量和初始值等属性都保存在InstanceKlass的_fields属性中,根据该地址可以直接获取或者设置字段值,以int为例,如下图:

int_field_addr就是获取该int类型字段的地址,其实现如下:
 现将this地址转换成char指针,因为[]的优先级高于&,即先对char指针执行[offset],最后取第offset个元素的地址,相当于把char指针指向的地址加上offset。
现将this地址转换成char指针,因为[]的优先级高于&,即先对char指针执行[offset],最后取第offset个元素的地址,相当于把char指针指向的地址加上offset。
对象类型的字段因为涉及指针压缩比较复杂,如下图:

obj_field_addr的实现同基本类型一样,如下图:
 如果是指针压缩则获取字段值时先对指针解压缩,更新字段值时先对指针压缩,否则直接对指针地址操作:
如果是指针压缩则获取字段值时先对指针解压缩,更新字段值时先对指针压缩,否则直接对指针地址操作:

指针压缩和解压缩的逻辑分别如下,其中Universe是表示Java堆内存的对象,代码位于oop.inline.hpp中:


注意指针压缩包含两种,Java对象类型字段的oop指针和oopDesc引用Klass的指针,分别对应两个参数UseCompressedOops和UseCompressedClassPointers,上图的代码是针对前一种指针,第二种指针的压缩和解压缩逻辑类似,如下,代码位于klass.inline.hpp中:

 测试代码如下:
测试代码如下:
- package jvmTest;
-
- import java.lang.management.ManagementFactory;
- import java.lang.management.RuntimeMXBean;
-
- class D{
- private String s="test";
- private int a=2;
- private long b=5;
-
- public D() {
- }
- }
-
- public class MainTest3 {
-
- public static void main(String[] args) {
- new D();
-
- while (true) {
- try {
- System.out.println(getProcessID());
- Thread.sleep(600 * 1000);
- } catch (Exception e) {
-
- }
- }
- }
-
- public static final int getProcessID() {
- RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
- System.out.println(runtimeMXBean.getName());
- return Integer.valueOf(runtimeMXBean.getName().split("@")[0])
- .intValue();
- }
- }
先从Stack Memory中找到对象D的地址,如下图:

然后在Inspect中查看属性值,如下图:

接着用mem命令查看其内存数据,如下图:

可以在Class Browser中查看各字段的偏移量,如下图:

字段b的偏移量是16,long占8个字节,所以b对应的内存就是第3个8字节;字段s的偏移量是24,因为对象按8字节对齐,所以s对应的oop指针没有压缩,对应的内存就是第4个8字节,将其地址复制到Inspect查看,如下图:

字段a的偏移量是12,应该是第二个8字节的后面4字节,为啥跑前面去了?答案是Intel按照little endian的方式存储,内存中实际存储的a和_compressed_klass的内存区域与上图是反过来的,Java在打印时做了一道转换。
把D的属性稍微调整下,以验证oop指针压缩,如下图:
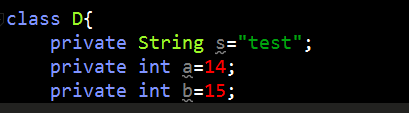
获取其内存结构如下:
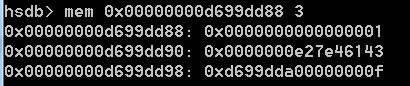
属性偏移量如下图:

同上,字段a和_compressed_klass,字段a和字段s的内存位置也是看起来反了,字段s这回压缩了。
5、arrayOopDesc
arrayOopDesc继承自oopDesc,该类是所有数组OopDesc的基类,同InstanceOopDesc,该类没有任何虚方法,为了避免在类实例中引入虚函数表。arrayOopDesc同InstanceOopDesc的内存布局是不一样的,除OopDesc定义的属性外还需保存数组的长度,数组元素的取值。
该类添加了几个跟数组相关的方法,如下:
- int base_offset_in_bytes(BasicType type):获取首元素的偏移量
- void* base(BasicType type): 获取首元素的地址
- bool is_within_bounds(int index):index是否数组越界
- int length():获取数组的长度
- void set_length(int length): 设置数组长度
- int32_t max_array_length(BasicType type): 获取数组的最大长度
其中获取和设置数组长度的方法实现如下:


从代码可知数组长度保存在_metadata属性的后面,类型为int,占4字节,这也决定了数组的最大长度不能超过int的最大值。
6、typeArrayOopDesc
typeArrayOopDesc继承自arrayOopDesc,用于表示数组元素是基本类型如int,long等的数组。跟InstanceOopDesc类似,该类定义了根据索引操作不同类型数组元素的方法,如下图:

int_at_addr是获取该索引处元素的地址,如下图:


T_INT是枚举BasicType中表示int类型的枚举值,base是arrayOopDesc中定义的,用于获取首元素的地址。
测试代码如下:
- public class MainTest3 {
-
- public static void main(String[] args) {
-
- int a[]={1,2,3,4};
-
- while (true) {
- try {
- System.out.println(getProcessID());
- Thread.sleep(600 * 1000);
- } catch (Exception e) {
-
- }
- }
- }
-
- public static final int getProcessID() {
- RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
- System.out.println(runtimeMXBean.getName());
- return Integer.valueOf(runtimeMXBean.getName().split("@")[0])
- .intValue();
- }
- }
先从Stack Memory中获取int数组变量a,如下图:

从Inspect 查看该地址,如下图:

使用mem查看其内存表示,如下图:

第二个8字节前4字节是数组长度4,后面4字节是_compressed_klass属性,第三个8字节前4字节是索引为1的元素,后4字节是索引为0的元素,第四个8字节前4字节是索引为3的元素,后4字节是索引为2的元素。同上因为Intel的little endian的存储方式,实际存储的顺序跟图中的顺序是反过来的,即数组元素在内存中是按照索引的顺序依次来存储的。
7、objArrayOopDesc
objArrayOopDesc继承自arrayOopDesc,用于表示元素是对象的数组,包括多维数组。同typeArrayOopDesc,该类增加了根据索引获取和设置数组的方法,同样需要根据配置对指针做压缩解压缩处理,如下图:

获取元素首地址的实现如下,跟获取基本类型的数组首元素地址基本一样:

测试用例如下:
- class D{
- private int a;
- private int b;
-
- public D(int a,int b) {
- this.a=a;
- this.b=b;
- }
- }
-
- public class MainTest3 {
-
- public static void main(String[] args) {
-
- D[] d={new D(1,2),new D(3,4)};
- D[][] d2={{new D(1,2),new D(3,4)},{new D(5, 6)}};
-
-
- while (true) {
- try {
- System.out.println(getProcessID());
- Thread.sleep(600 * 1000);
- } catch (Exception e) {
-
- }
- }
- }
-
- public static final int getProcessID() {
- RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
- System.out.println(runtimeMXBean.getName());
- return Integer.valueOf(runtimeMXBean.getName().split("@")[0])
- .intValue();
- }
- }
用Stack Memory找到D数组变量d和d2的地址,如下图:

三个ObjArray是按照变量入栈的顺序保存的,从上到下依次是d2,d和main方法的入参args,用Inspect查看变量d,如下图:

用mem查看变量d的内存表示,如下图:

第二个8字节分别是数组长度和_compressed_klass属性,第三个8字节分别是索引为1和0的两个压缩oop指针。
同样的方式查看二维数组d2,如下图:


变量d2对应的objArrayOopDesc的数组元素是一维数组的 objArrayOopDesc的压缩指针。从上面示例可以得出针对oopDesc的指针压缩实际就是把前面的8个0去掉而已。

