
万字梳理中国AIGC产业峰会激辩,大模型应用最全行业参考在此
赞
踩
编辑部 发自 凹非寺
量子位 | 公众号 QbitAI
有算力就有超越Sora的可能。
70%的代码问题,现在单纯靠基座模型解决不了。
基于垂直场景的大模型应用创新,只有两年的窗口期。
ROI是衡量AIGC应用价值的第一标准。
AI给了每个人一次突破自己的机会。……
在中国AIGC产业峰会的现场,20位大咖展开激辩。从软件应用、智能终端乃至具身智能等,AIGC正在全面席卷,「你好,新应用!」成为本届AIGC峰会主题。
来自AIGC底层基础设施、模型层、应用层的企业玩家,以及来自市场学术界的洞察者,畅谈大模型落地元年这个万亿市场的的机遇与挑战。
现场乌泱泱一片,500人的会场可以说是座无虚席(其实站也要没有席了)。

线上也有数百万网友围观并积极讨论,以及数十家行业知名媒体参与了大会的直播跟报道,全网总曝光量超千万。
为了让更多读者更全面、系统地了解本次AIGC峰会的内容,深入感知这股时代浪潮的发展,量子位联合各大模型做了万字梳理,希望能为大家提供一份有价值的行业参考。
(建议收藏再食用)
本次梳理主要围绕五个方面展开,分别是AIGC的模型层、应用层、基础设施层的参与者,以及行业洞察者的观点,最后是圆桌讨论的精彩观点。
AIGC模型层:微软阿里高通等玩家谈落地
微软李冕:AI应用已进入新阶段,微软助力企业级应用全球落地
微软大中华区Azure云事业部总经理李冕分享了微软Copilot与Azure AI平台如何助力企业级应用的全球落地。
李冕认为,过去12个月AI经历了数次迭代,现在AI应用已进入到一个新的阶段。企业如何打造自己的应用?怎么实现AI带来的真正价值?可以从四个方面来考虑应用落地:提升员工生产力,重塑与用户的互动关系,重塑企业内部流,加强产品和服务。

他强调了在企业打造自己的应用时微软可以为企业提供的一系列支持。
AI模型层面,李冕展开介绍了Azure平台支持的三类模型,分别是OpenAI系列模型、第三方开源模型和企业自研模型(BYOM)。同时,也讲述了小模型(SLM)在特定场景下的应用前景。
对于开发工具,李冕提到Azure提供低代码、无代码的Microsoft Copilot Studio工作台以及针对深度定制的Azure AI Studio,方便企业快速开发AI应用。
考虑到企业级应用需求,李冕还表示微软不仅在最上面的模型层为企业提供支持,还提供下面的调度层、硬件层、云数据中心等的一系列配套服务。
李冕在演讲最后重申了微软在数据隐私安全方面的承诺:
“客户的数据就是客户的数据,客户的数据不会被用来训练其它模型,所有客户数据均有企业级防护,受到全面的企业合规和安全控制的保护。”
昆仑万维方汉:天工SkyMusic音乐大模型将大大降低音乐创作的门槛和成本
昆仑万维董事长兼CEO方汉分享了“天工多模态大模型的演进落地”。大会当天,昆仑万维发布了「天工3.0」,这是中国音乐AIGC领域首个实现SOTA水平的模型。同时,他还宣布「天工3.0」基座大模型与「天工SkyMusic」音乐大模型正式开启公测。

「天工3.0」拥有4000亿参数,超越了3140亿参数的Grok-1,是全球最大的开源MoE大模型。在MMbench和MMbench-CN测试集上,「天工3.0」性能指标全面超越GPT-4V。
通过专项的Agent训练,目前大模型可以做到“能搜能写能读能聊能说能画能听能唱”,应对多种复杂的内容创作需求。例如,它可以准确识别“成都迪士尼”是个梗,并给出游玩攻略;可以自动总结文献,生成大纲、PPT和脑图;还可以通过非代码方式生成智能体。
方汉特别介绍了「天工SkyMusic」音乐大模型,得益于2000万首音乐的训练数据和独特的模型架构,「天工SkyMusic」在人声识别度、音质等方面已经超越Sora。「天工SkyMusic」支持根据音源和歌手特点生成音乐,并支持多种方言合成,大大降低了音乐创作的门槛和成本——
各行各业使用的歌曲都能通过AI生成,成本迅速从几万块钱降到几分钱。
最后,方汉分享了昆仑万维的愿景:“实现通用人工智能,让每个人更好地塑造和表达自我。”他认为,大模型的演进终将实现AGI,而AIGC能力普及则有助于打破强势文化的垄断,实现文化平权。作为一家全球化互联网企业,昆仑万维希望用AI技术为全球用户赋能。
阿里通义千问林俊旸:智能模型应融入对视觉/语音的理解
阿里通义千问开源负责人林俊旸,在现场分享了阿里通义千问大模型为“走向通用大模型”做出的努力。

林俊旸表示,自开源以来,通义千问Qwen(为了更方便英文发音,对“千问”的音译)系列模型受到了国内外开发者的广泛关注。
从去年8月开始,通义千问Qwen系列模型陆续开源上新。从7B、14B参数规模大小开始,直到开源了72B参数版本;最新动作,阿里通义千问家族还有一名“小成员”,是14B参数的MoE模型。而开发者社区的迫切需求,促使阿里快速开源了32B模型——这个模型的表现与72B参数模型表现接近,并且在某些方面相比,比MoE模型还具有优势。
林俊旸在现场强调,阿里通义千问同时十分专注打造大模型使用生态。
首先,通义千问的代码已经官方融入了抱抱脸的代码库,开发者可以更方便地使用通义千问的模型。
其次,通义千问在第三方框架支持方面有不少进展,包括ollama在内的平台,都能一键使用Qwen系列模型。
多语言、长序列、Post-training、Agent、多模态等能力相关问题,林俊旸也在现场做了分享。
多语言:通义千问模型本质上是多语言的,而非仅仅是中英双语的;并且,团队在多语言能力上进行了检测和优化。
长序列:Qwen系列模型一直没有卷长文本,这件事并不好做,不仅要保证“长”,同时要保证效果;目前32k版本表现已经比较稳定;大海捞针等评估发现长序列可以在Chatbot上落地实用功能。
Post-training:通过SAT等在数据等方面,优化post-training,让大模型的潜力爆发。
Agent:实现方式(之一)是做更多数据标注、研究to use agent相关。
多模态(Qwen-VL):非常智能的模型应该融入对视觉、语音方面的理解,今年会重点关注视频模态的研究,思考如何打造一个VL-Agent。

高通万卫星:具有异构计算系统的高通AI引擎可以充分满足生成式AI的多样性要求
高通公司AI产品技术中国区负责人万卫星在演讲中表示,作为芯片厂商,高通正通过提供领先的产品和解决方案,推动AIGC相关产业的规模化扩展。
他指出,高通认为终端侧生成式AI的时代已经到来。

高通在去年10月发布的第三代骁龙8和骁龙X Elite两款产品中,已经将大语言模型完整搬到了端侧,赋能了众多AI手机和AI PC。多模态趋势下,今年2月,高通也把多模态大模型完整地搬移到端侧。在发布的骁龙X Elite这款产品上,高通也演示了全球首个在Windows PC上运行的音频推理多模态大模型。
万卫星表示,不同领域的生成式AI用例具有多样化的要求,背后所需的AI模型也是千差万别,很难有一种处理器可以完美适用所有用例。
在这方面,高通推出了具有异构计算系统的高通AI引擎,包含多种处理器组件,可以充分满足生成式AI的多样性要求。其中重点讲了NPU。基于用户需求和终端用例的多年演进,高通NPU不断升级。第三代骁龙8的Hexagon NPU还集成了专门为生成式AI打造的Transformer加速模块,以及微架构升级、独立供电轨道、微切片推理等先进AI技术。
万卫星还透露高通今年会重点支持多模态模型端侧化,以及支持更高参数量大语言模型在端侧的部署。
说完硬件设计,万卫星介绍了高通的重要AI软件产品,包括跨平台、跨终端的统一解决方案高通AI软件栈(Qualcomm AI Stack)。
你只需要在高通一个平台上完成模型的优化部署工作,可以非常方便的把这部分工作迁移到其它高通产品线。
此外,高通还在今年的MWC巴塞罗那发布了高通AI Hub(Qualcomm AI Hub)。该产品面向第三方开发者和合作伙伴,可以帮助开发者更加充分的利用高通和骁龙底层芯片的硬件算力,开发出自己的创新AI应用。
最后他总结了高通在AI方面的优势,在于“无与伦比的硬件设计、顶尖的异构计算能力、可扩展的AI软件工具以及广泛的生态系统和模型支持”。
蚂蚁李建国:超70%代码问题单纯靠基座模型是解决不了的
超70%的问题需要端到端代码生成能力解决,目前单纯靠基座模型还远远不能满足。
在中国AIGC产业峰会上,蚂蚁代码大模型CodeFuse负责人李建国这样说道,他还指出,当前代码大模型虽然在基座模型和应用产品上演进飞速,但要在企业中真正实现研发效率的大幅提升,仍面临诸多挑战。

从软件研发全生命周期来看,从最初的需求设计到编码开发、测试构建、发布运维、数据洞察等环节,写代码可能只占1/5甚至更少的工作量。
李建国表示,蚂蚁集团希望打造一个“研发智能体”,通过智能Agents实现任务分发与衔接,将各环节连接起来,全面提升研发效能。
CodeFuse刚发布时,就明确提出“要做全生命周期的代码大模型”。CodeFuse目前已开源13个仓库,覆盖代码训练、测试、DevOps运维、程序分析、评测等8大软件开发领域。李建国表示,这是全方位的开源。
最后再来看整个领域,结合外部统计与蚂蚁实践,基座模型在实际运用过程中只能解决大约30%的问题,剩下70%的问题还需要端到端代码生成能力。除此之外,在Agent推理能力、需求需求拆解、跨模态交互等方面还需要持续演进。
李建国还重点提到,垂直场景中,比如金融场景,生成代码的安全、可信、可靠的要求,这也是蚂蚁正在重点攻克的难题。
虽然挑战不少、道阻且长,但李建国认为,蚂蚁将携手开源社区一起努力,在万物摩尔定律的牵引下,未来两三年可以一定程度解决这个问题。
小冰徐元春:市场真正的运营主体是非常朴素的
小冰公司联合创始人兼首席运营官、人工智能创造力实验室负责人徐元春的演讲主题是“数字人+大模型:打造商业应用新场景”。
“作为一家算法公司怎么挣钱和作为一家AIGC产业公司怎么赚钱,这是最后要回答的问题。最先要回答的问题是,大家用这个东西怎么赚钱?”,徐元春这样讲。

他通过几个特别具体的例子,展现了小冰是如何让大家赚到钱的。
第一个是一个美装美业个体博主,她利用小冰虚拟人和大模型平台,创作出了自己的数字人,在短视频平台用数字人分身分享创作服装穿搭内容。仅用40多天,她的单条视频播放量就达到200万,日均为线下门店引流6-8个意向客户。而这,已经能让她的生意更好地发展起来。
第二个是一家中小型的企业,一开始是做软件开发、技术赋能、后台的支持,现在使用小冰的技术平台做转型,成为AI服务商,4个月内为云南300家中小企业提供了AI赋能服务。
第三个是更大的行业领军企业,他们将小冰的数字人与大模型技术深度整合到了自家各类硬件产品中,实现“开箱即用”,每一个有屏的硬件设备都可以变成一个全新的交互载体。
在徐元春看来,真正能把产业化应用做得越来越深,不在于庙堂之高,而是在江湖之远:
你发现真正市场在运行的主体、市场从业者对AI没有那么多复杂的想法,他们非常朴素。
他进一步补充道,小冰将大模型和数字人更加深入地植入到了企业的工作流和任务系统中,数字员工相当于有了集合企业知识和数据闭环的大脑,可以让业务流程和客户沟通更加顺畅。
最后徐元春讲述了商业的闭环。有“云+端”这样的软件+硬件产品的闭环,也有交互+内容这样的形式上的闭环。而今天通过真实的企业、个体案例,使用技术去获得更多竞争力、让自己的生意变得更好这其实是所有闭环里最重要的节点。
“找到并激活每个关键节点,才能实现技术商业化的真正闭环。”
AIGC应用层:普通人可以怎么AI?
美图吴欣鸿:基于垂直场景的大模型应用创新,窗口期只有两年
美图公司创始人、董事长兼CEO吴欣鸿则分享了美图视频大模型的探索之路。

美图作为影像工具起家,经过16年的发展,现在主要聚焦在影像和设计产品,形成了图像、视频和设计三大AI产品品类。
吴欣鸿现场展示了一个仅用半天时间制作的60秒AI短片,运用了开拍、WHEE、Wink等一系列AI工具,相比传统动画工作流,大幅降低了制作门槛,提升了效率。
吴欣鸿预计今年下半年,将会有很多的国产Sora扎堆上市,美图也是其中的一家。
我们认为越来越激烈的竞争有三个点非常关键:第一、创意超越现实;第二、工作流的整合;第三、垂直场景的能力。
其中基于垂直模型的大模型应用创新,吴欣鸿认为有两年窗口期。
展望未来,吴欣鸿认为,视频大模型的标配除了文生视频,还将涌现图生视频、视频生视频、音频生视频等更多生成方式,应用场景非常广阔。
今年,以Sora为代表的视频生成只是个开始。随着视频大模型对物理世界理解的加深,有望实现剧情设计、分镜、转场等更专业的能力,与视频制作工作流深度结合,后续可以生成1-5分钟视频。
金山办公姚冬:WPS已不再是一个文档编辑器
金山办公副总裁、研发中台事业部总经理姚冬在本次大会上分享了金山办公在拥抱AI浪潮中的思考与实践。

作为一家办公软件公司,金山办公最近五年将“多屏、内容、云、协作、AI”作为战略重点,在AIGC浪潮下,最近两年尤其注重AI和协作这两点的发展。
就在前几日,金山办公发布企业级产品WPS 365。
姚冬表示,当前的WPS已经不再是一个文档的编辑器,而是包含企业数据协作、知识管理、通信以及各种跟算法相关的模型服务等多种功能于一体的办公平台。在最近WPS 365发布中,其包含的WPS AI企业版聚焦为客户打造企业大脑,主打三大类能力:AI Hub、AI Docs和Copilot Pro。
其中,AI Hub是企业使用AI能力的基座,提供了一个兼容市面上各种大模型的统一接口和开发体系,让企业可以灵活选择和切换适合自己的模型。
AI Docs是用来帮助企业盘活海量非结构化数据资产。
员工每天都在写文档,这些其实是企业非常重要的只是。但过去一直有个问题,这类知识无法再利用,因为非结构化。
传统的关键词搜索很难准确命中文档中的知识,而基于大模型和多模态技术,WPS 365实现了对企业内部各种格式文档的智能化阅读理解、搜索问答,并严格遵循文档权限管控。
Copilot Pro则是通过AI驱动自然语言交互式办公。比如做数据分析,传统方式需要写脚本、设计公式、绘制图表等,门槛很高。在Copilot Pro中,用户只需用自然语言表达需求,让AI自动执行全流程。
姚冬强调,文档数据在人和人之间没有传播其实一个数据孤岛,而今天的办公不再只是简单写写文档分析数据,更重要的是人和人、人和AI之间的协作。
印象笔记唐毅:AI驱动的“第二大脑”,既给用户自由,又降低信息管理焦虑
印象笔记董事长兼CEO唐毅,有科技创业、跨国企业管理以及投融资领域的丰富经验。
他带领的印象笔记,2018年成立印象研究院,开启了对AIGC的探索,去年3月起,利用自研印象大模型驱动“印象AI”产品和服务,落地赋能旗下全线软件和智能硬件产品。

唐毅的分享聚焦“知识管理”领域。在他看来,AIGC的发展仍处于早期繁荣阶段,挑战和机遇并存。
他认为,相比算力、数据集和模型规模的快速扩大,模型算法的进展则相对缓慢,且算力的投入和收益不成比例。此外,目前而言,随着模型训练对人类公共领域数据的穷尽,越来越多合成数据的加入也会导致模型输出效果下降。
与此同时,在实践和竞争中发现,特定数据驱动的模型能力的增长在不断加强,模型的小型化和高效化趋势也日益突出。
谈及印象笔记的大模型及产品进化方向,唐毅表示将从复合AI系统(Compound AI System)角度出发,提升自研印象大模型的能力,同时发挥用户、数据、场景、载体、交互等方面优势,打造真正的AI超级应用。
在AI驱动下,印象笔记将帮助用户智能汇聚信息、高效阅读吸收、辅助灵感记录与创作、自动完成知识整理与提炼,成为用户真正的、智能的“第二大脑”。
逐际动力张力:人形机器人未来将实现平台化应用
通用机器人初创公司逐际动力的联合创始人兼COO张力,在中国AIGC产业峰会现场分享了关于人形机器人发展及其与AGI关系的深刻见解。

目前,人形机器人的双腿移动能力已经有了实质性突破,而操作能力仍然受限,是因为AI还不能完全根据多模态场景形成自己的行为,如何利用多模态大模型生成机器人自主的运动和控制,是产业界和学术界都在追赶和研究的部分。
在硬件和软件算法方面,尤其是大脑和小脑的协同上,人形机器人仍需取得更多突破。
张力畅想,未来的人形机器人可以实现平台化的应用,就像今天的iPhone+APP一样。机器人通过安装不同的应用程序,利用自身的运动控制能力,执行对应的各种任务,从而极大地扩展应用范围。
从本质来讲,机器人就是一个类似或者超越人运动能力、计算能力和感知能力的机电系统。技术方面,事先规划好的运动控制这种是相对传统的技术;而如果需要跟外界产生更多的交互,如环境认知感知、物体检测、接触反馈等,就需要新的技术。在这方面,AGI对于机器人的影响非常大。
在不断研发迭代产品的过程中,逐际动力形成了通过模仿学习、深度强化学习以及基于感知的运动控制等关键的新技术,推出了人形机器人、双足机器人,以及四轮足机器人。
张力分享了他对人形机器人市场前景的看法:
无论tob还是toc,具身智能在未来有非常大的应用场景。
在技术边界不断扩大过程中,如何通过沿途下蛋,把相对成熟的技术和产品实现商业化;形成自主的移动能力和移动操作能力是关键;机器人与AGI、AIGC打通,加强场景的认知、理解,实现任务的分解,更好完成规划决策,这些都非常重要。
得到快刀青衣:AI给了很多人一个突破自己的机会
得到联合创始人、AI学习圈主理人快刀青衣的演讲主题是“六边形战士,AI 驱动下的个人能力革命”。
“六边”在快刀青衣这里指的是产品能力、输出能力、提效能力、创新能力、管理能力、设计能力。在他看来,AI技术的发展让他个人的六边能力得到全面提升。

他从创新和输出两方面分享了过去一年的心得。
首先,快刀青衣认为,AI创新的源泉可以从四个方面考虑:你自己也想用的产品、一个困扰你很久的痛点、你熟悉行业能预见到的巨大变化、你对它充满热情而又具有挑战性的事情:
如果四项占两项就可以干,占三项就非常值得你花很多时间去研究它。
以此为出发点,快刀青衣介绍了得到自主研发的AI陪练小程序“开始练练”,用来给员工进行AI实战陪练,收到AI的反馈。如此一来,练习后的员工再面对真人客户时就能轻松解答客户的问题。
接着他分享了开发这款小程序的初衷。一开始是想让自己公司的程序员用,后来程序员们都表示自己不是靠沟通干活的,是靠写代码。后来有一次发朋友圈,一个连锁美容院的老板发现这对他们一线美容师介绍产品特别管用……
快刀青衣由此感慨,“最初那个起点可能跟你想象的不一样,过程中可能会有很多不一样的东西”。
此外,他还强调了企业专有知识库、专有数据的重要性,并表示自己在做这个AI项目时给团队设置了几个限制:团队不超过3人,缺的能力用AI补;不碰硬件,不训大模型;只做提升用户能力的培训场景。
认清自己能力,做自己更擅长的事情,不能因为AI能力强就觉得啥都能干。
输出能力提升方面,快刀青衣分享了自己从公众号年更“保证号不被冻结”到365天日日更的转变,以及每周都要做一场和AI有关的直播聊一下别人都在做什么。这一切都是这波AI浪潮给他带来的输出能力的提升。
最后,快刀青衣引用了乔丹的一句话:“我可以接受失败,但不能接受不去尝试。”
AIGC基建层:如何支撑产业数字化转型?
亚马逊云科技王晓野:四个要点让企业抓住生成式AI机遇
生成式AI这个时代已经开始,它并不是未来将发生的事情。
亚马逊云科技大中华区产品部技术总监王晓野在演讲中表示,生成式AI将在18个月内颠覆所有产业,为全球带来高达4.4万亿美元的巨大市场商机。

对于企业如何抓住生成式AI机遇,王晓野总结了四大要点:选对场景、选对工具和合作伙伴、重视数据这一企业核心竞争力、关注人才培养与AI相关的监管与治理。
他指出生成式AI在跨语言沟通、商业决策以及洞察、智能服务和营销素材的生成、整体运营效率提升等六大场景大有可为。
王晓野指出,得益于模型能力和成本的优化,生成式AI正在从局限的文生图、营销、聊天机器人等初级应用,进化到更广泛的领域。比如在Claude等大模型支持下,语言翻译、情感陪伴、游戏内容审核等更多场景的落地正在悄然发生。他强调多模态交互将是大模型发展的重要趋势。
在助力企业应用生成式AI方面,亚马逊云科技提出了“三层原子能力”:底层基础设施加速层、利用基础模型构建生成式AI应用的工具比如Amazon Bedrock、顶层开箱即用的生成式AI应用。
从电商到云计算,亚马逊一直在用技术和AI颠覆和创新原有产业。王晓野最后表示,下一个亚马逊正在构建并且持续投入的地方,就是生成式AI的三层原子能力,希望能与客户共赢生成式AI时代。
商汤杨帆:打造AI基础设施生态是降低AI应用门槛的关键
“中国AI应用正在变得越来越多,越来越多新的场景被打开,今年下半年或是明年上半年,我们将看到中国生成式AI市场的爆发。”
商汤科技联合创始人、大装置事业群总裁杨帆在大会上做出了这样的判断。

杨帆分析道,当前尺度定律仍在主导AI的技术迭代,AI产业发展的核心问题在于“产业端的投入产出比不够好”。随着AI生产和应用成本的提高,用降低成本的方式降低使用门槛其实是必然趋势。
而AI基础设施的建设,正是破解这一难题的关键。
只有把这些通用能力,不管大规模的算力集群还是机器模型的API,甚至未来围绕超大规模数据完整的体系,把它做标准化、基础设施化、服务化,才有可能在未来让整个AI产业创新门槛更低、性价比更高,更多人进来,在上面赚到钱。
关于商汤在这方面的投入,杨帆先是介绍了商汤在临港投建的智算中心的最新的进展:
截至去年底,包括临港在内已经建成七八个节点形成连接,还有很多新的节点在建。连接算力超过12000P,领先单点算力接近10000P。同时,商汤在芯片层面也与产业链展开了广泛合作,临港智算中心已有超15%的国产芯片算力。
夯实算力基础之外,杨帆还讲述了商汤推出的不同层级的软件产品和服务体系,其中提到了降低模型调用成本的全套解决方案。
他还分享了商汤自家大模型的发展,除了去年看到比较多的语言类的任务,现在更多在图像、视频、三维重建不同领域提供不同基础模型的方案。
总的来讲,商汤还是更希望以基础设施平台化能力支撑更加繁荣的场景生态。
AIGC洞察者:Scaling Laws是关键
北大袁粒:大模型幻觉问题,我们几乎是公开最早提出检索增强来解决
北京大学深圳研究生院助理教授袁粒在大会上分享了他们团队在多模态模型垂直领域应用的实践经验。

他表示,用来闲聊的玩具并不能满足用户真正的需求,AI必须转化为实实在在的生产力,而生产力则是由垂直领域来转化。
袁粒教授介绍了他们团队基于鹏城的云脑和自建算力,基于通用和行业数据开发的几款代表性产品:
ChatExcel:一款面向数据表格处理的多模态AI助手,可用文字直接操纵表格,进行数据可视化和营销策略分析等。这项成果已经在某奢侈品巨头落地应用。开发这块应用的博士生也创办了元空AI。
ChatLaw:中文法律垂直领域应用,可为用户和律师提供信息分析、结构化抽取、生成法律文书等服务。该产品采用了检索增强技术,引入法律文本数据库参考,有效缓解了大模型的幻觉问题。
检索增强这一做法当时我们也是业内最早做出来的,只是我们没有把这个概念提出来,让大模型做大模型的事情,让检索做检索的事情。
最后袁粒教授介绍了他们同北大校友企业兔展智能联合发起的Sora复现开源计划Open-Sora Plan,目标是实现一个视觉版LLaMA。该项目分为三个技术部分:视频编解码器、Diffusion Transformer和条件注入。
目前已经开源了第一版预训练模型和CausalVideoVAE,在开源社区引起广泛关注,在GitHub上获得近万星。该框架最大特点是能够生成较长视频,得益于训练时压缩喂入的长视频片段。
接下来,该项目将分三个阶段实现更高的复现目标:第一阶段已开源;第二阶段争取开源支持20秒720P视频生成的模型;第三阶段希望借助产业界算力实现超越原版Sota的性能。
袁粒教授表示,开源推动了AI的繁荣,他们也希望通过开源回馈社区,让学术界和产业界都能共享技术成果。
硅谷Fusion Fund张璐:初创企业在现阶段都可走“鸡尾酒”模式
作为长期关注和布局AI领域的顶级投资人,硅谷Fusion Fund创始合伙人、斯坦福大学客座讲师张璐分享了她对全球尤其是硅谷AI技术与产业发展的深度洞察。
张璐指出,AI正在成为一项全产业的数字化转型工具,而海量高质量数据的涌现为AI的大规模应用奠定了基础。
在此背景下,AI将带来比互联网时代大10倍的机会,但其中只有三分之一会留给初创企业。
作为初创企业,找到对的工业界和对的应用场景,找到合适的切入点非常关键,数据是核心。怎样拿到高质量的数据?怎样让数据成为你的竞争优势点?
初创企业要想在AI浪潮中抓住先机,必须找准自身的创新切入点,充分利用大公司搭建的生态平台实现共同发展。
现阶段,初创企业基本上都可以做“鸡尾酒”模式,即调动最前沿大模型的API,在上面配套使用开源模型,再自己做些修改进行模型调优。
“在这个优化过程中,很快会发现两个特点。”张璐说,第一个特点是数据的质量比数据的数量更重要;第二是不需要一个模型去解决所有的问题。

在投资方向上,张璐表示,Fusion Fund聚焦AI的应用层和基础设施两个维度。
其中,应用层主要关注医疗、金融保险、机器人、太空等拥有海量高质量数据和广阔应用前景的领域;基础设施层则布局从芯片到云端的各个技术节点,旨在突破算力、能耗、隐私等AI发展的关键瓶颈。
张璐在演讲中谈到,随着开源社区的蓬勃发展,小模型、行业专属模型也将成为AI应用的重要趋势。
她强调,对于创业者而言,高质量数据的获取与应用比海量数据更为关键,定制化的小模型在特定场景下的效能甚至可以与通用大模型相媲美。
人大卢志武:有算力就有超越Sora的可能
中国人民大学高瓴人工智能学院教授卢志武分享主题为《VDT:基于Transformer的通用扩散视频生成》。
VDT是Video Diffusion Transformer的缩写。这是卢志武带队的项目,去年5月发布在arXiv上,并已被顶会ICLR接收。
它的创新之处是将Transformer应用于视频生成——这远在OpenAI发布Sora之前,以及在模型中引入统一的时空掩码建模。

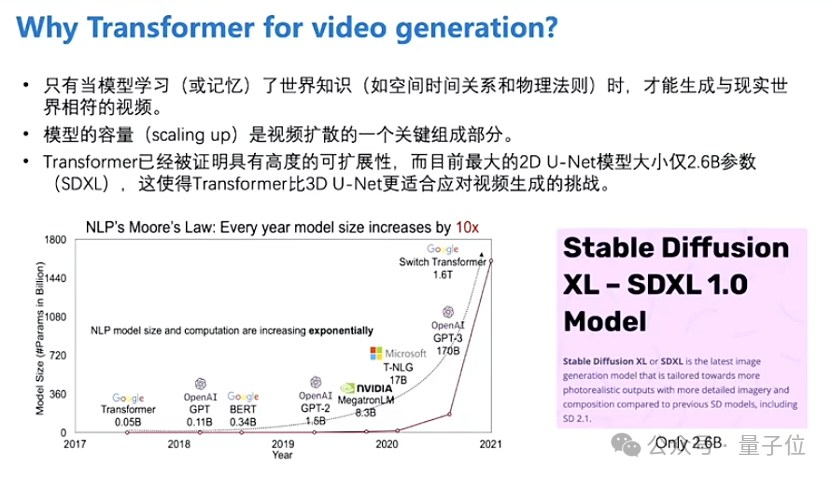
为什么要将视频生成从基于Diffusion模型转向基于Transformer模型?
卢志武表示,Transformer模型具有捕捉长期或不规则时间依赖性的优势,这在视频领域尤为重要;而Transformer模型的参数量可以根据需要增加,这为提高模型性能提供了灵活性。
在演讲中,卢志武提到了VDT模型中关键的时空Transformer block,并解释了其与现有模型如Sora的细微差别。他指出,由于算力限制,团队在设计时采取了空间和时间分开的处理方法,以提高效率。
那VDT与Sora这样的SOTA模型相比如何?卢志武分析,两者在时空Attention处理上有所不同,但这个差别并不是本质上的。
我们推测Sora强大的物理世界模拟能力,主要来自于统一的时空token化和Attention机制。
卢志武在最后表示,团队通过实验发现,VDT模型效果只和消耗的算力有关,这与OpenAI的图像生成模型DiT的结论一致。
“算力越大效果越好。拿到更多算力,超越Sora也不是不可能。”
圆桌对话:ROI是衡量AIGC应用价值的第一标准
“你好,新应用!”峰会设置了一场圆桌论坛,讨论的主题非常务实:怎么落地?如何赚钱?
——从ChatGPT问世到现在,一年半的时间里,AIGC有一个非常明显的趋势,就是从建设基础层逐步向“用起来”去发展。今年也被很多人认为是AIGC应用元年,在这个时间节点上,有必要坐下来聊一聊与AIGC相关的接地气的话题。
本次邀请到的三位代表性嘉宾分别是:
轻松集团技术副总裁高玉石,主导了该集团在健康保障领域的AI智能体系研发建设。

阿里云通义大模型业务负责人徐栋,在云原生、端云架构和AI大模型领域的深入实践。

在AI和企业服务领域积累了宝贵经验的澜码科技创始人兼CEO周健。

在量子位主编金磊的主持下,圆桌主要围绕3个话题展开:大模型应用用得怎么样了、AI赚钱之道各有招、百模大战利大于弊。
大模型应用用得怎么样了
高玉石表示,轻松问医Dr.GPT的升级给医患双方都带来很大便利。在医生端,临床研究的效率提升2倍;科普内容创作实现月产万篇规模;智能辅助诊疗的采纳率达86%,诊断时间从十分钟缩短为1-2分钟。患者端的健康顾问覆盖30多万用户,活跃率70%。
周健的澜码科技基于大语言模型打造企业级AI Agent,服务于企业日常办公场景下的增强自动化和创新业务的开展,在保险、银行、政务等行业和领域已实现专家知识赋能基层员工和管理增效的典型应用。
徐栋从通义大模型的视角给了两个维度的观点,目前看到第一类是大模型塑造了产业的核心商业模式,比如游戏行业的NPC、社交领域的角色扮演,以及像智能硬件端侧的应用;第二类是企业级市场,未必是对商业模式做了根本性重塑,但大模型突出体现在降本增效上,最典型的客服场景、知识库的问答等等,这些场景在企业内部提效帮助很大。
AI赚钱之道各有招
在AIGC商业化方面,徐栋表示目前AIGC应用尚未出现杀手级产品,未来可能出现基于订阅制的创新商业模式,可以拭目以待。
高玉石则表示他们主要通过为C端用户提供增值服务获利,如医疗健康类的保险、商城、科普付费等。对B端则主要是按需付费。
周健提到一种可能性是把AI Agent/基于大语言模型的数字员工按月收费。将专家知识、模型、算力等全新生产要素整合为一套服务,面向金融等行业按使用量收费分成。
对于如何评判一款AIGC产品的价值,三位嘉宾一致认为要看其能否提升ROI,包括降本增效、提高收入或改善用户体验等。但具体衡量方式要根据行业和场景特点而定。
百模大战利大于弊
针对去年百家争鸣的“百大模大战”是否有必要,高玉石认为从加速技术发展角度看是有价值的,但资源损耗问题需要注意。他预判最终可能在科技巨头及其投资的创企中展开洗牌。
周健提出,未来通用大模型可能只需要少数几家,但细分的垂直领域模型可能多达上百个,需要更多创业公司参与。
徐栋也认为,“百模大战”并非完全铺张浪费,它培养了人才队伍,积累了模型和数据方面的经验,我们也欢迎非同质化的模型的竞争,这些培养的人才、积累的经验也会帮助大模型落地到千行百业,对未来AIGC的商业化大有裨益。
后续还将有大会嘉宾更详细版内容分享,尽情关注!
— 完 —
点这里声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/471432

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

