
热门标签
热门文章
- 1项目经理--要具备的能力_项目经理需要具备哪些能力
- 2[FPGA]FPGA设计EtherCAT主站的方法和常见问题_ethercat fpga 延迟
- 3BARD COMMUNICATIONS PC104-DPIO DRL-DPM-BKF 过程监控冗余处理器
- 4Node.js 框架有哪些框架?(具体分析)_nodejs框架
- 5SPI接口的FPGA实现(一)——SPI接口的相关基础知识_fpga spi接口
- 6小程序获取用户手机号_小程序获取手机号
- 7Mac idea 添加git 拉取代码_mac idea git
- 8数据结构:循环队列(C语言实现)_数据结构循环队列c语言实现
- 9亚马逊开放个人卖家验证入口?亚马逊卖家验证到底怎么搞?_卖家身份验证 您正在请求批准注册。选择个人还是公司
- 10Spring Boot 学习记录笔记【 五 】之前端Vue_ant design vue官方文档
当前位置: article > 正文
正则表达式学习笔记
作者:不正经 | 2024-04-25 17:10:58
赞
踩
正则表达式学习笔记
正则匹配函数
1.1 re.compile
re.compile是将正则表达式转换为模式对象,这样可以更有效率匹配。
单独使用就没有任何意义,需要和findall(), search(), match()搭配使用。
1.2 re.match
从字符串的第一个字符开始匹配,未匹配到返回None,匹配到则返回一个对象
1.3 re.search
搜索整个字符串第一个匹配到指定的字符则返回值,未匹配到则返回None。
1.4 re.findall
匹配出字符串中所有跟指定值有关的值,并且以列表的形式返回。
未匹配到则返回一个空的列表。
import re
# compile配合findall
a = '0355-67796666'
b = re.compile(r'\d+-\d{8}')
r = re.findall(b,a)
# 或
r = b.findall(a)
print(r)
# 直接使用findall
import re
r = re.findall(r'\d+-\d{8}',a)
print(r)
# compile配合search
import re
正则 = re.compile(r'\d+-\d{8}')
r = re.search(正则,a)
print(r.group())
# compile配合match
import re
正则 = re.compile(r'\d+-\d{8}')
r = re.match(正则,a)
print(r.group())
# ['0355-67796666']
# ['0355-67796666']
# 0355-67796666
# 0355-67796666
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
简单的模式:字符匹配


2.1 元字符
[0-9]:所有数字;
[^0-9]:非数字;
x[d-f]z:字符串中间字母是d,e,f的单词
2.2 概括字符集
\d:所有的数字;\D:所有非数字;
\w:可以提取中文,英文,数字和下划线,不能提取特殊字符
\W:提取特殊字符、空格、\n、\t等
2.3 数量词
匹配0次或无限多次—— *号;
匹配1次或者无限多次 ——+号;
匹配0次或1次 ——?号
# 匹配0次或无限多次 *号,*号前面的字符出现0次或无限次
import re
a = 'exce0excell3excel3'
r = re.findall('excel*',a)
print(r)
# 匹配1次或者无限多次 +号,+号前面的字符至少出现1次
import re
a = 'exce0excell3excel3'
r = re.findall('excel+',a)
print(r)
# 匹配0次或1次 ?号,?号经常用来去重复
import re
a = 'exce0excell3excel3'
r = re.findall('excel?',a)
print(r)
# ['exce', 'excell', 'excel']
# ['excell', 'excel']
# ['exce', 'excel', 'excel']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
贪婪
# 贪婪
import re
a = 'Excel 12345Word23456PPT12Lr'
r = re.findall('[a-zA-Z]{3,5}',a)
print(r)
# 非贪婪
r = re.findall('[a-zA-Z]{3,5}?',a)
print(r)
r = re.findall('[a-zA-Z]{3}',a)
print(r)
# ['Excel', 'Word', 'PPT']
# ['Exc', 'Wor', 'PPT']
# ['Exc', 'Wor', 'PPT']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.4 边界匹配 ^和$
# 限制电话号码的位置必需是8-11位才能提取
import re
tel = '13811115888'
r = re.findall('^\d{8,11}$',tel)
print(r)
# ['13811115888']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.5 组 ( )
# 将abc打成一个组,{2}指的是重复几次,匹配abcabc
import re
a = 'abcabcabcxyzabcabcxyzabc'
r = re.findall('(abc){2}',a)
print(r)
#['abc', 'abc']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.6 匹配模式参数
1).re.I(re.IGNORECASE): 忽略大小写
2).re.M(MULTILINE): 多行模式,改变’^’和’$’的行为
3).re.S(DOTALL): 点任意匹配模式,改变’.’的行为
4).re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
5).re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
6).re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
- 1
- 2
- 3
- 4
- 5
- 6
# findall第三参数 re.I忽略大小写
import re
a = 'abcFBIabcCIAabc'
r = re.findall('fbi',a,re.I)
print(r)
# 多个模式之间用 | 连接在一起
import re
a = 'abcFBI\nabcCIAabc'
r = re.findall('fbi.{1}',a,re.I | re.S) # 匹配fbi然后匹配任意一个字符包括\n
print(r)
# 注:.句号,不匹配\n,但是使用re.S之后,匹配所有字符包括换行符
# ['FBI']
# ['FBI\n']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.7 re.sub替换字符串
# 把FBI替换成BBQ
import re
a = 'abcFBIabcCIAabc'
r = re.sub('FBI','BBQ',a)
print(r)
# 把FBI替换成BBQ,第4参数写1,证明只替换第一次,默认是0(无限替换)
import re
a = 'abcFBIabcFBIaFBICIAabc'
r = re.sub('FBI','BBQ',a,1)
print(r)
# abcBBQabcCIAabc
# abcBBQabcFBIaFBICIAabc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.8 把函数做为参数传递
# 拓展知识
import re
a = 'abcFBIabcFBIaFBICIAabc'
def 函数名(形参):
print(形参)
分段获取 = 形参.group() # group()在正则表达式中用于获取分段截获的字符串,获取到FBI
return '$' + 分段获取 + '$'
r = re.sub('FBI',函数名,a)
print(r)
# 将字符串中大于等于5的替换成9,小于5的替换成0
import re
a = 'C52730A52730D52730'
def 函数名(形参):
分段获取 = 形参.group()
if int(分段获取) >= 5:
return '9'
else:
return '0'
r = re.sub('\d',函数名,a)
print(r)
# <re.Match object; span=(3, 6), match='FBI'>
# <re.Match object; span=(9, 12), match='FBI'>
# <re.Match object; span=(13, 16), match='FBI'>
# abc$FBI$abc$FBI$a$FBI$CIAabc
# C90900A90900D90900
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.9 group分组
import re
a = "123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) #123abc456,返回整体
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) #123
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) #abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) #456
import re
a = 'life is short,i use python,i love python'
r = re.search('life(.*)python(.*)python',a)
print(r.group(0)) # 完整正则匹配
print(r.group(1)) # 第1个分组之间的取值
print(r.group(2)) # 第2个分组之间的取值
print(r.group(0,1,2)) # 以元组形式返回3个结果取值
print(r.groups()) # 返回就是group(1)和group(2)
# 123abc456
# 123
# abc
# 456
# life is short,i use python,i love python
# is short,i use
# ,i love
# ('life is short,i use python,i love python', ' is short,i use ', ',i love ')
# (' is short,i use ', ',i love ')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
正则表达式的一些建议
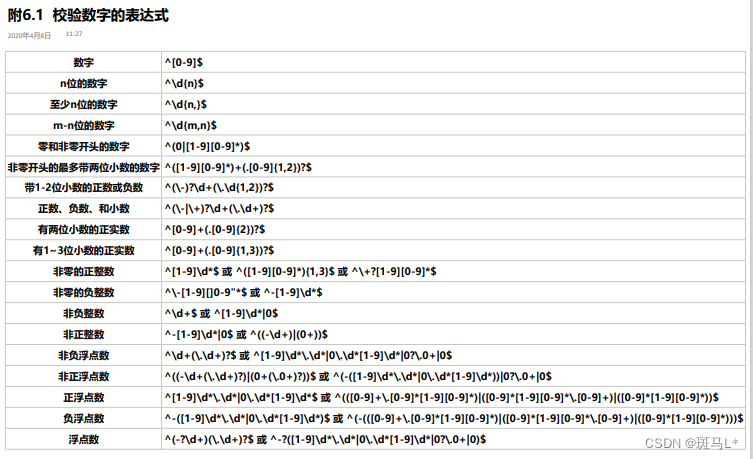
- 常用的正则表达式,不用自己写,在百度上搜索常用正则表达式
- 如果内置方法可以快速解决问题,建议不要化简为繁

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/486363
推荐阅读
相关标签

