
- 1【Linux更新驱动、cuda和cuda toolkit】_linux系统如何更新主机的cuda版本
- 2新能源汽车2022智能化,感知方案的终极答案是?
- 3使用rust学习基本算法(四)
- 4C# Stopwatch计时器 记录方法执行时间_stopwatch stopwatch = new stopwatch();
- 5blinker小白入门学习_esp32_#include
- 6每个私域运营者都必须掌握的 5 大关键流量运营核心打法!
- 7精准测试:代码覆盖率与测试覆盖率
- 8像素与分辨率_像素与分辨率对照表
- 9「iOS」怎么修改去掉Navigation Bar上的返回按钮文本颜色,箭头颜色以及导航栏按钮的颜色_消除颜色type_navigation_bar
- 10如何快速开发一个自己的微信小程序_小程序怎么开发
用selenium去爬取大麦网页面的演唱会信息_浏览器源代码查看大麦数据
赞
踩
实验目的:
利用selenium.webdriver爬取大麦网页面演唱会信息,信息包括:演唱会标题、时间、价钱、地点、图片、网址。
实验环境:
操作环境:
1. Window10; 2. python3.9; 3. PycharmIDE
第三方库版本:
1. selenium 4.1.1
2. requests 2.28.1
本实验主要利用Goggle chrome浏览器进行,其中浏览器版本为118开头,可在设置关于Chrome查看。

驱动下载网站:
Chrome for Testing availability (googlechromelabs.github.io)
注意下载win32 stable版本,我选择如下驱动器:
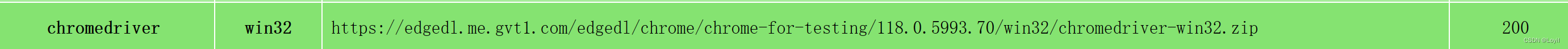
实验步骤:
1. 导入相关库:
- from selenium import webdriver # 用于网页自动化操作
- import requests # 用于发送HTTP请求
- from selenium.webdriver.common.by import By # 用于定位元素
- import os # 用于操作系统相关的功能
- import time # 用于控制代码的运行和等待时间
2. 初始化Chrome WebDriver:
为了解决“Chrome正受到自动测试软件的控制”和“请停用以开发者模式运行的扩展程序”情况,在创建WebDriver初始化前添加命令:
- # 创建ChromeOptions对象
- option = webdriver.ChromeOptions()
- # 添加实验选项,排除自动化标识
- option.add_experimental_option("excludeSwitches", ['enable-automation'])
同时为了结果网页出现闪退显示,同样再添加命令:
- # 添加实验选项,使浏览器在后台运行
- option.add_experimental_option("detach", True)
接下来就是初始化webdriver对象:
注意使用你安装的驱动位置。
- # 初始化Chrome WebDriver
- driver = webdriver.Chrome(r"E:\chromedriver-win32\chromedriver-win32\chromedriver.exe", options=option)
3. 使用WebDriver打开制定URL:
- # 使用WebDriver打开指定的URL
- driver.get("https://search.damai.cn/search.htm?spm=a2oeg.home.category.ditem_0.4e2523e1PJPX0w&ctl=%E6%BC%94%E5%94%B1%E4%BC%9A&order=1&cty=%E5%8C%97%E4%BA%AC")
爬取网页情况:

4. 初始化变量:
同时我们初始化相关变量items,用于存放每场演唱会的信息,同时使用变量"i"用以表示的爬取图片序号,同时规定爬取该网页前10的演唱会信息,及使用for循环执行。
除此之外,该网页中存在一些差异信息,比方如下:

其中对于第一个演唱会,其信息不包含“艺人”信息,而第二个演唱会中存在“艺人”信息,这对于执行循环爬取演唱会信息来说,则需要进行元素定位判断,毕竟“艺人”信息不是我们要爬取的。
下面采用XPATH方法进行元素定位。
5. 元素定位与判断:
我们首先利用XPATH查看“艺人”信息存在于不存在之间的差异。
在Chromel浏览器中选中存在“艺人”信息的演唱会,右击在弹出的方框中选择检查:
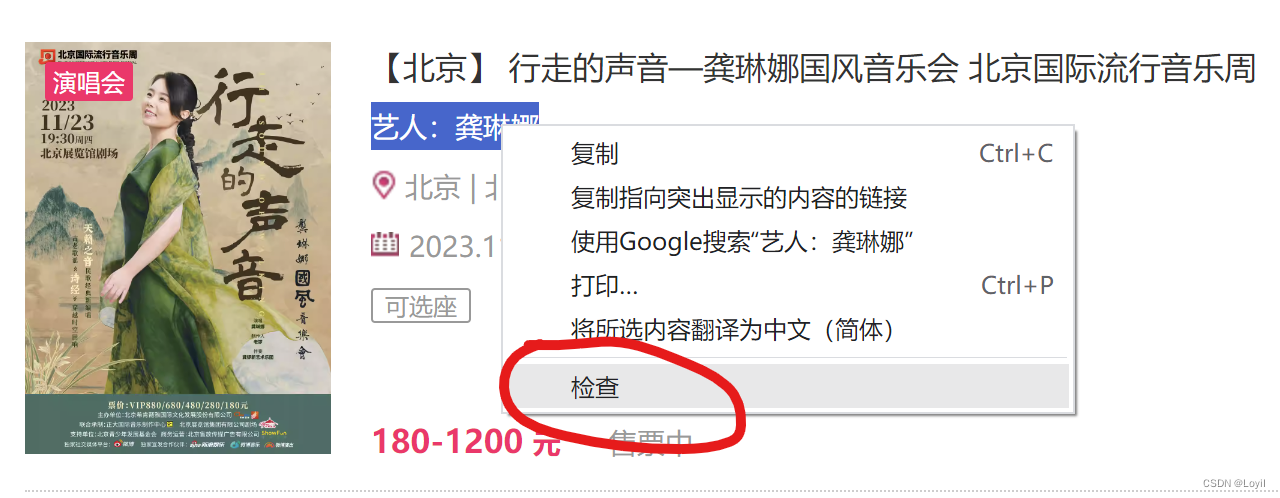
在右侧显示蓝色位置同样右键,选择Copy,选择Copy ful xpath:

full xpath 路径:
/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[2]/div/div[2]而对于没有存在“艺人”信息的演唱会,同样的full xpath路径显示的我们需要爬取的演唱会地址信息。下面就对于此差异影响下存在“艺人”信息和不存在“艺人”信息的演唱会xpath路径的差异。
其中对于没有“艺人”信息的演唱会,其xpath路径信息差异仅仅存在倒数第三或第一个div的位置索引上。对于如何查看差异,可以对不存在“艺人”信息的演唱会采用如上xpath查看方法查看其演唱会标题、时间、价钱、地点、图片、网址的xpath在div的具体差异。
最终发现存在差异的仅仅是时间、价钱、地点信息由于“艺人”信息存在而导致div不同。
下面举时间为例,给出xpath信息:
- # 不存在艺人信息的演唱会时间xpath
- /html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[1]/div/div[3]
-
- # 存在艺人信息的演唱会时间xpath
- /html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[2]/div/div[4]
以上可以看出倒数第三个div信息索引存在差异,其原因是不同演唱会引起的,此为我们要循环遍历的位置索引。
同时存在倒数第一个div差异,其原因就是因为存在“艺人”信息,通过观察xpath路径不难发现由于“艺人”信息的div存在于时间、价格、地点之前,而导致其位置索引向后移动一位。因此我们需要根据是否存在“艺人”信息来改变时间、价格、地点的位置索引。
这里使用flag列表变量作为以上元素的索引存在处,如果判断不存在“艺人”信息则使用索引位置为[3,2,5]位置,否则使用[4,3,6],由于我爬取的信息是先时间、地点、价格的顺序进行的,因此对于索引在列表的位置可能与你想的不太一样,具体希望你能针对以上差异信息进行逐一查看xpath信息的差异。
同时为了让每个演唱会的信息一一对应这里常用了字典生成式,方便将每个演唱会信息加到到总的爬取信息items列表存放位置中。
判断信息如下:
- items = [] # 存放演唱会对象数据
- for j in range(1, 11):
- flag = None
- # 判断元素的文本是否以'艺'开头
- if driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(i + 1) + "]/div/div[2]").text[0] != '艺':
- flag = [3, 2, 5]
- else:
- flag = [4, 3, 6]
注意我的selenium版本,因为此版本中不存在find_element_by_xpath方法了,所以采用find_element方法代替,利用By库的XPATH确定爬取的方法,最后将爬取内容使用text()属性转为文本信息进行判断。
其余信息的定位:
- item = {
- 'title': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[1]/a").text,
- 'time': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[" + str(flag[0]) + "]").text,
- 'place': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[" + str(flag[1]) + "]").text,
- 'amount': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[" + str(flag[2]) + "]/span").text,
- 'href': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/a").get_attribute('href')}
- img = driver.find_element(by=By.XPATH,value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(i + 1) + "]/a/img")
注意对于href,即演唱会网址,其存在于演唱会信息的第一个a标签里,及如图:

对于Img,演唱会的图片,我们采用其他方法进行存入,而不放入演唱会信息item中。注意href对象的获取,最后不是采用text()属性而是get_attribute()属性,其原因是href信息存在如爬取的元素之中,详细看上图。
6. 信息写入和图片存入:
1)图片存入
由于在执行爬取时经常发现图片没加载完成就爬取,因此参看了其他人的代码,使用time.sleep()函数,其能够等待页面加载完毕后,再爬取,如果你发现你的图片没加载就爬取,可改变其参数值,这里设5s。并使用get_attribute('src')爬取图片url,并利用requests.get()方法获取图片资源。最后利用with open()语句将图片载入,具体代码如下:
- time.sleep(5) # 程序暂停5秒,等待页面加载完毕
- i += 1 # 图片序号计数器
- t = img.get_attribute('src') # 获取图片的src属性,即图片的URL
- path = r"D:\demo\图{}.jpg".format(i) # 存入图片位置
- r = requests.get(t) # 发送GET请求获取图片资源
- r.raise_for_status() # 发送GET请求获取图片资源
-
- # 图片存入
- with open(path, 'wb') as f: # 写入并保存
- f.write(r.content)
- f.close()
- print('保存成功')
结果如下:

2)演唱会信息存入
这里使用os库的getcwd()方法获取当前工作目录路径,将存放信息的文件命名为damai.txt,同样使用with open()语句将信息写入该文件中,具体代码如下:
- base_dir = os.getcwd() # 获取当前工作目录的路径
- filename = base_dir + r'\damai.txt' # 获取当前工作目录的路径
-
- with open(filename, 'a+') as f: # 追加
- f.write(str(i) + ':\ntitle:' + item['title'] + '\n')
- f.write('time:' + item['time'] + '\n')
- f.write('place:' + item['place'] + '\n')
- f.write('amount:' + item['amount'] + '\n')
- f.write('href:' + item['href'] + '\n\n')
结果如下:

7. 全部代码:
注意最后使用.quit()方法关闭webdriver,关闭浏览器进程。其位于循环外。
- # 导入相关库
- from selenium import webdriver # 用于网页自动化操作
- import requests # 用于发送HTTP请求
- from selenium.webdriver.common.by import By # 用于定位元素
- import os # 用于操作系统相关的功能
- import time # 用于控制代码的运行和等待时间
-
-
- # 设置Selenium的选项和初始化WebDriver
- option = webdriver.ChromeOptions() # 创建ChromeOptions对象
- option.add_experimental_option("excludeSwitches", ['enable-automation']) # 添加实验选项,排除自动化标识
- option.add_experimental_option("detach", True) # 添加实验选项,使浏览器在后台运行
- # 初始化Chrome WebDriver
- driver = webdriver.Chrome(r"E:\chromedriver-win32\chromedriver-win32\chromedriver.exe",
- options=option)
- # 设置初始值和打开网页
- i = 0 # 初始化变量i,用于后续图片循环计数
- # 使用WebDriver打开指定的URL
- driver.get("https://search.damai.cn/search.htm?spm=a2oeg.home.category.ditem_0.4e2523e1PJPX0w&ctl=%E6%BC%94%E5%94%B1"
- "%E4%BC%9A&order=1&cty=%E5%8C%97%E4%BA%AC")
-
- items = [] # 存放演唱会对象数据
- for j in range(1, 11):
- flag = None
- # 判断元素的文本是否以'艺'开头
- if driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[2]").text[0] != '艺':
- flag = [3, 2, 5]
- else:
- flag = [4, 3, 6]
-
- # 通过XPath定位元素,获取文本信息并存储到字典中
- item = {
- 'title': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[1]/a").text,
- 'time': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[" + str(flag[0]) + "]").text,
- 'place': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[" + str(flag[1]) + "]").text,
- 'amount': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/div/div[" + str(flag[2]) + "]/span").text,
- 'href': driver.find_element(by=By.XPATH, value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(
- i + 1) + "]/a").get_attribute('href')}
- img = driver.find_element(by=By.XPATH,
- value="/html/body/div[2]/div[2]/div[1]/div[3]/div[1]/div/div[" + str(i + 1) + "]/a/img")
-
- time.sleep(5) # 程序暂停5秒,等待页面加载完毕
- i += 1 # 图片序号计数器
- t = img.get_attribute('src') # 获取图片的src属性,即图片的URL
- path = r"D:\demo\图{}.jpg".format(i) # 存入图片位置
- r = requests.get(t) # 发送GET请求获取图片资源
- r.raise_for_status() # 发送GET请求获取图片资源
-
- # 图片存入
- with open(path, 'wb') as f:
- f.write(r.content)
- f.close()
- print('保存成功')
-
- items.append(item) # 将抓取的演唱会数据项添加到总信息列表中
-
- base_dir = os.getcwd() # 获取当前工作目录的路径
- filename = base_dir + r'\damai.txt' # 获取当前工作目录的路径
-
- with open(filename, 'a+') as f:
- f.write(str(i) + ':\ntitle:' + item['title'] + '\n')
- f.write('time:' + item['time'] + '\n')
- f.write('place:' + item['place'] + '\n')
- f.write('amount:' + item['amount'] + '\n')
- f.write('href:' + item['href'] + '\n\n')
-
- driver.quit() # 关闭WebDriver,结束浏览器进程
-
- print(items)


