
- 1XP使用技巧
- 2C++基础与技巧【顺序容器】 (三大顺序容器~vector, list, deque)_顺序寻址 vector list
- 3spyder下报错ModuleNotFoundError: No module named_它没有 spyder kernels 模块或没有安装正确的版本 (>= 2.4.0 并 < 2.5.
- 4Python基础知识总结(期末复习精简版)_华中农业大学python考试
- 5微信开发者工具使用git提交项目至gitee远程仓库(保姆级)_微信开发者工具 gitee
- 6精选力扣500题 第31题 LeetCode 69. x 的平方根【c++ / java 详细题解】_69. x 的平方根 c++
- 7数据结构-栈
- 8cfg是什么
- 9自定义幂等注解_自定义注解实现幂等
- 10猿创征文|2022年前端之路——我的前端开发好帮手_csdn前端征文
知识抽取-实体及关系抽取_关系提取 pipeline cnn
赞
踩
知识抽取涉及的“知识”通常是 清楚的、事实性的信息,这些信息来自不同的来源和结构,而对不同数据源进行的知识抽取的方法各有不同,从结构化数据中获取知识用 D2R,其难点在于复杂表数据的处理,包括嵌套表、多列、外键关联等;从链接数据中获取知识用图映射,难点在于数据对齐;从半结构化数据中获取知识用包装器,难点在于 wrapper 的自动生成、更新和维护,这一篇主要讲从文本中获取知识,也就是我们广义上说的信息抽取。
1. 信息抽取三个最重要/最受关注的子任务:
- 实体抽取
也就是命名实体识别,包括实体的检测(find)和分类(classify) - 关系抽取
通常我们说的三元组(triple) 抽取,一个谓词(predicate)带 2 个形参(argument),如 Founding-location(IBM,New York) - 事件抽取
相当于一种多元关系的抽取
篇幅限制,这一篇主要整理实体抽取和关系抽取,下一篇再上事件抽取。
2. 相关竞赛与数据集
信息抽取相关的会议/数据集有 MUC、ACE、KBP、SemEval 等。其中,ACE (Automated Content Extraction) 对 MUC 定义的任务进行了融合、分类和细化,KBP (Knowledge Base Population) 对 ACE 定义的任务进一步修订,分了四个独立任务和一个整合任务,包括
- Cold Start KB (CSKB)
端到端的冷启动知识构建 - Entity Discovery and Linking (EDL)
实体发现与链接 - Slot Filling (SF)
槽填充 - Event
事件抽取 - Belief/Sentiment (BeSt)
信念和情感
至于 SemEval 主要是词义消歧评测,目的是增加人们对词义、多义现象的理解。
ACE 的 17 类关系
具体的应用实例
常用的 Freebase relations
- people/person/nationality,
- people/person/profession,
- biology/organism_higher_classification,
- location/location/contains
- people/person/place-of-birth
- film/film/genre
还有的一些世界范围内知名的高质量大规模开放知识图谱,如包括 DBpedia、Yago、Wikidata、BabelNet、ConceptNet 以及 Microsoft Concept Graph等,中文的有开放知识图谱平台 OpenKG……
3. 实体抽取
实体抽取或者说命名实体识别(NER)在信息抽取中扮演着重要角色,主要抽取的是文本中的原子信息元素,如人名、组织/机构名、地理位置、事件/日期、字符值、金额值等。实体抽取任务有两个关键词:find & classify,找到命名实体,并进行分类。
主要应用:
- 命名实体作为索引和超链接
- 情感分析的准备步骤,在情感分析的文本中需要识别公司和产品,才能进一步为情感词归类
- 关系抽取(Relation Extraction)的准备步骤
- QA 系统,大多数答案都是命名实体
3.1 传统机器学习方法
3.1.1 标准流程:
Training:
- 收集代表性的训练文档
- 为每个 token 标记命名实体(不属于任何实体就标 Others O)
- 设计适合该文本和类别的特征提取方法
- 训练一个 sequence classifier 来预测数据的 label
Testing:
- 收集测试文档
- 运行 sequence classifier 给每个 token 做标记
- 输出命名实体
3.1.2 编码方式
看一下最常用的两种 sequence labeling 的编码方式,IO encoding 简单的为每个 token 标注,如果不是 NE 就标为 O(other),所以一共需要 C+1 个类别(label)。而 IOB encoding 需要 2C+1 个类别(label),因为它标了 NE boundary,B 代表 begining,NE 开始的位置,I 代表 continue,承接上一个 NE。如果连续出现两个 B,自然就表示上一个 B 已经结束了。
在 Stanford NER 里,用的其实是 IO encoding,有两个原因,一是 IO encoding 运行速度更快,二是在实践中,两种编码方式的效果差不多。IO encoding 确定 boundary 的依据是,如果有连续的 token 类别不为 O,那么类别相同,同属一个 NE;类别不相同,就分割,相同的 sequence 属同一个 NE。而实际上,两个 NE 是相同类别这样的现象出现的很少,如上面的例子,Sue,Mengqiu Huang 两个同是 PER 类别,并不多见,更重要的是,在实践中,虽然 IOB encoding 能规定 boundary,而实际上它也很少能做对,它也会把 Sue Mengqiu Huang 分为同一个 PER,这主要是因为更多的类别会带来数据的稀疏。
3.1.3 特征选择
Features for sequence labeling:
- • Words
- Current word (essentially like a learned dictionary)
- Previous/next word (context)
- • Other kinds of inferred linguistic classification
- Part of speech tags
- Dependency relations
- • Label context
- Previous (and perhaps next) label
再来看两个比较重要的 features:
(1) Word substrings
Word substrings (包括前后缀)的作用是很大的,以下面的例子为例,NE 中间有 ‘oxa’ 的十有八九是 drug,NE 中间有 ‘:’ 的则大多都是 movie,而以 field 结尾的 NE 往往是 place。
(2) Word shapes
可以做一个 mapping,把 单词长度(length)、大写(capitalization)、数字(numerals)、希腊字母(Greek eltters)、单词内部标点(internal punctuation) 这些字本身的特征都考虑进去。
如下表,把所有大写字母映射为 X,小写字母映射为 x,数字映射为 d…
3.1.4 序列模型
NLP 的很多数据都是序列类型,像 sequence of characters, words, phrases, lines, sentences,我们可以把这些任务当做是给每一个 item 打标签,如下图:
常见的序列模型有 有向图模型 如 HMM,假设特征之间相互独立,找到使得 P(X,Y) 最大的参数,生成式模型;无向图模型 如 CRF,没有特征独立的假设,找到使得 P(Y|X) 最大的参数,判别式模型。相对而言,HMM 优化的是联合概率(整个序列,实际就是最终目标),而不是每个时刻最优点的拼接,一般而言性能比 CRF 要好,在小数据上拟合也会更好。
(1) 整个流程如图所示(构造模型的过程):
(2) 讨论下最后的 inference
最基础的是 “decide one sequence at a time and move on”,也就是一个 greedy inference,比如在词性标注中,可能模型在位置 2 的时候挑了当前最好的 PoS tag,但是到了位置 4 的时候,其实发现位置 2 应该有更好的选择,然而,greedy inference 并不会 care 这些。因为它是贪婪的,只要当前最好就行了。除了 greedy inference,比较常见的还有 beam inference 和 viterbi inference。
a. Greedy Inference
优点:
- 速度快,没有额外的内存要求
- 非常易于实现
- 有很丰富的特征,表现不错
缺点:
- 贪婪
b. Beam Inference
- 在每一个位置,都保留 top k 种可能(当前的完整序列)
- 在每个状态下,考虑上一步保存的序列来进行推进
优点:
- 速度快,没有额外的内存要求
- 易于实现(不用动态规划)
缺点:
- 不精确,不能保证找到全局最优
c. Viterbi Inference
- 动态规划
- 需要维护一个 fix small window
优点:
- 非常精确,能保证找到全局最优序列
缺点:
- 难以实现远距离的 state-state interaction
3.2 深度学习方法
LSTM+CRF
最经典的 LSTM+CRF,端到端的判别式模型,LSTM 利用过去的输入特征,CRF 利用句子级的标注信息,可以有效地使用过去和未来的标注来预测当前的标注。
3.3 评价指标
评估 IR 系统或者文本分类的任务,我们通常会用到 precision,recall,F1 这种 set-based metrics,见信息检索评价的 Unranked Boolean Retrieval Model 部分,但是在这里对 NER 这种 sequence 类型任务的评估,如果用这些 metrics,可能出现 boundary error 之类的问题。因为 NER 的评估是按每个 entity 而不是每个 token 来计算的,我们需要看 entity 的 boundary。
以下面一句话为例
First Bank of Chicago announced earnings...正确的 NE 应该是 First Bank of Chicago,类别是 ORG,然而系统识别了 Bank of Chicago,类别 ORG,也就是说,右边界(right boundary)是对的,但是左边界(left boundary)是错误的,这其实是一个常见的错误。
- 正确的标注:
- ORG - (1,4)
-
- 系统:
- ORG - (2,4)
而计算 precision,recall 的时候,我们会发现,对 ORG - (1,4) 而言,系统产生了一个 false negative,对 ORG - (2,4) 而言,系统产生了一个 false positive!所以系统有了 2 个错误。F1 measure 对 precision,recall 进行加权平均,结果会更好一些,所以经常用来作为 NER 任务的评估手段。另外,专家提出了别的建议,比如说给出 partial credit,如 MUC scorer metric,然而,对哪种 case 给多少的 credit,也需要精心设计。
4 实体链接
实体识别完成之后还需要进行归一化,比如万达集团、大连万达集团、万达集团有限公司这些实体其实是可以融合的。
主要步骤如下:
- 实体识别
命名实体识别,词典匹配 - 候选实体生成
表层名字扩展,搜索引擎,查询实体引用表 - 候选实体消歧
图方法,概率生成模型,主题模型,深度学习
补充一些开源系统:
- http://acube.di.unipi.it/tagme
- https://github.com/parthatalukdar/junto
- http://orion.tw.rpi.edu/~zhengj3/wod/wikify.php
- https://github.com/yahoo/FEL
- https://github.com/yago-naga/aida
- http://www.nzdl.org/wikification/about.html
- http://aksw.org/Projects/AGDISTIS.html
- https://github.com/dalab/pboh-entity-linking
5. 关系抽取
关系抽取 需要从文本中抽取两个或多个实体之间的语义关系,主要方法有下面几类:
- 基于模板的方法(hand-written patterns)
- 基于触发词/字符串
- 基于依存句法
- 监督学习(supervised machine learning)
- 机器学习
- 深度学习(Pipeline vs Joint Model)
- 半监督/无监督学习(semi-supervised and unsupervised)
- Bootstrapping
- Distant supervision
- Unsupervised learning from the web
5.1 基于模板的方法
5.1.1 基于触发词/字符串
首先是基于字符串的 pattern,举一个 IS-A 的关系
Agar is a substance prepared from a mixture of red algae, **such as** Gelidium, for laboratory or industrial use通过 such as 可以判断这是一种 IS-A 的关系,由此可以写的规则是:
- “Y such as X ((, X)* (, and|or) X)”
- “such Y as X”
- “X or other Y”
- “X and other Y”
- “Y including X”
- “Y, especially X”
另一个直觉是,更多的关系是在特定实体之间的,所以可以用 NER 标签来帮助关系抽取,如
- • located-in (ORGANIZATION, LOCATION)
- • founded (PERSON, ORGANIZATION)
- • cures (DRUG, DISEASE)
也就是说我们可以把基于字符串的 pattern 和基于 NER 的 pattern 结合起来,就有了下面的例子。
对应的工具有 Stanford CoreNLP 的 tokensRegex。
5.1.2 基于依存句法
通常可以以动词为起点构建规则,对节点上的词性和边上的依存关系进行限定。流程为:
小结
手写规则的 优点 是:
- 人工规则有高准确率(high-precision)
- 可以为特定领域定制(tailor)
- 在小规模数据集上容易实现,构建简单
缺点:
- 低召回率(low-recall)
- 特定领域的模板需要专家构建,要考虑周全所有可能的 pattern 很难,也很费时间精力
- 需要为每条关系来定义 pattern
- 难以维护
- 可移植性差
5.2 监督学习-机器学习
5.2.1 研究综述
漆桂林,高桓,吴天星.知识图谱研究进展[J].情报工程,2017,3(1):004-025
Zhou[13] 在 Kambhatla 的基础上加入了基本词组块信息和 WordNet,使用 SVM 作为分类器,在实体关系识别的准确率达到了 55.5%,实验表明实体类别信息的特征有助于提高关系抽取性能; Zelenko[14] 等人使用浅层句法分析树上最小公共子树来表达关系实例,计算两颗子树之间的核函数,通过训练例如 SVM 模型的分类器来对实例进行分。但基于核函数的方法的问题是召回率普遍较低,这是由于相似度计算过程匹配约束比较严格,因此在后续研究对基于核函数改进中,大部分是围绕改进召回率。但随着时间的推移,语料的增多、深度学习在图像和语音领域获得成功,信息抽取逐渐转向了基于神经模型的研究,相关的语料被提出作为测试标准,如 SemEval-2010 task 8[15]。基于神经网络方法的研究有,Hashimoto[16] 等人利用 Word Embedding 方法从标注语料中学习特定的名词对的上下文特征,然后将该特征加入到神经网络分类器中,在 SemEval-2010 task 8 上取得了 F1 值 82.8% 的效果。基于神经网络模型显著的特点是不需要加入太多的特征,一般可用的特征有词向量、位置等,因此有人提出利用基于联合抽取模型,这种模型可以同时抽取实体和其之间的关系。联合抽取模型的优点是可以避免流水线模型存在的错误累积[17-22]。其中比较有代表性的工作是[20],该方法通过提出全新的全局特征作为算法的软约束,进而同时提高关系抽取和实体抽取的准确率,该方法在 ACE 语料上比传统的流水线方法 F1 提高了 1.5%,;另一项工作是 [22],利用双层的 LSTM-RNN 模型训练分类模型,第一层 LSTM 输入的是词向量、位置特征和词性来识别实体的类型。训练得到的 LSTM 中隐藏层的分布式表达和实体的分类标签信息作为第二层 RNN 模型的输入,第二层的输入实体之间的依存路径,第二层训练对关系的分类,通过神经网络同时优化 LSTM 和 RNN 的模型参数,实验与另一个采用神经网络的联合抽取模型[21]相比在关系分类上有一定的提升。但无论是 流水线方法还是 联合抽取方法, 都属于有监督学习,因此需要大量的训练语料,尤其是对基于神经网络的方法,需要大量的语料进行模型训练,因此这些方法都不适用于构建大规模的 Knowledge Base。
[13] Guodong Z, Jian S, Jie Z, et al. ExploringVarious Knowledge in relation Extraction.[c]// acl2005, Meeting of the Association for ComputationalLinguistics, Proceedings of the Conference, 25-30 June, 2005, University of Michigan, USA. DBLP.2005:419-444.
[14] Zelenko D, Aone C, Richardella A. KernelMethods for relation Extraction[J]. the Journal ofMachine Learning Research, 2003, 1083-1106.
[15] Hendrickx I, Kim S N, Kozareva Z, et al.semEval-2010 task 8: Multi-way classification ofsemantic relations between Pairs of nominals[c]//the Workshop on semantic Evaluations: recentachievements and Future Directions. association forComputational Linguistics, 2009:94-99.
[16] Hashimoto K, Stenetorp P, Miwa M, et al. Task-oriented learning of Word Embeddings for semanticRelation Classification[J], Computer Science,2015:268-278.
[17] Singh S, Riedel S, Martin B, et al. JointInference of Entities, Relations, and Coreference[C]//the Workshop on automated Knowledge baseConstruction ,San Francisco, CA, USA, October27-november 1. 2013:1-6.
[18] Miwa M, Sasaki Y. Modeling Joint Entity andrelation Extraction with table representation[c]//conference on Empirical Methods in naturalLanguage Processing. 2014:944-948.
[19] Lu W, Dan R. Joint Mention Extraction andclassification with Mention Hypergraphs[c]//conference on Empirical Methods in naturallanguage Processing. 2015:857-867.
[20] Li Q, Ji H. Incremental Joint Extraction of EntityMentions and relations[c]// annual Meeting of theAssociation for Computational Linguistics. 2014:402-412.
[21] Kate R J, Mooney R J. Joint Entity andrelation Extraction using card-pyramid Parsing[c]//conference on computational natural languagelearning. 2010:203-212.
[22] Miwa M, Bansal M. End-to-End Relation Extraction using lstMs on sequences and tree structures[c]// annual Meeting of the association for computational linguistics. 2016:1105-1116.
5.2.2 分类器
标准流程:
- - 预先定义好想提取的关系集合
- - 选择相关的命名实体集合
- - 寻找并标注数据
- 选择有代表性的语料库
- 标记命名实体
- 人工标注实体间的关系
- 分成训练、开发、测试集
- - 设计特征
- - 选择并训练分类器
- - 评估结果
为了提高 efficiency,通常我们会训练两个分类器,第一个分类器是 yes/no 的二分类,判断命名实体间是否有关系,如果有关系,再送到第二个分类器,给实体分配关系类别。这样做的好处是通过排除大多数的实体对来加快分类器的训练过程,另一方面,对每个任务可以使用 task-specific feature-set。
可以采用的分类器可以是 MaxEnt、Naive Bayes、SVM 等。
5.2.3 特征
直接上例子:
E.g., American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said
Mention 1: American Airlines
Mention 2: Tim Wagner
用到的特征可以有:
Word features
- Headwords of M1 and M2, and combination
- M1: Airlines, M2: Wagner, Combination: Airlines-Wagner
- Bag of words and bigrams in M1 and M2
- {American, Airlines, Tim, Wagner, American Airlines, Tim Wagner}
- Words or bigrams in particular positions left and right of M1/M2
- M2: -1 spokesman
- M2: +1 said
- Bag of words or bigrams between the two entities
- {a, AMR, of, immediately, matched, move, spokesman, the, unit}
Named Entities Type and Mention Level Features
- Named-entities types
M1: ORG
M2: PERSON - Concatenation of the two named-entities types
ORG-PERSON - Entity Level of M1 and M2 (NAME, NOMINAL, PRONOUN)
M1: NAME [it or he would be PRONOUN]
M2: NAME [the company would be NOMINAL]
Parse Features
- Base syntactic chunk sequence from one to the other
NP NP PP VP NP NP - Constituent path through the tree from one to the other
NP ↑ NP ↑ S ↑ S ↓ NP - Dependency path
Airlines matched Wagner said
Gazetteer and trigger word features
- Trigger list for family: kinship terms
parent, wife, husband, grandparent, etc. [from WordNet] - Gazetteer:
List of useful geo or geopolitical words
Country name list
Other sub-entities
或者从另一个角度考虑,可以分为
- 轻量级
实体的特征,包括实体前后的词,实体类型,实体之间的距离等 - 中等量级
考虑 chunk,如 NP,VP,PP 这类短语 - 重量级
考虑实体间的依存关系,实体间树结构的距离,及其他特定的结构信息
5.3 监督学习-深度学习
深度学习方法又分为两大类,pipeline 和 joint model
- Pipeline
把实体识别和关系分类作为两个完全独立的过程,不会相互影响,关系的识别依赖于实体识别的效果 - Joint Model
实体识别和关系分类的过程共同优化。
深度学习用到的特征通常有:
- Position embeddings
- Word embeddings
- Knowledge embeddings
模型通常有 CNN/RNN + attention,损失函数 ranking loss 要优于交叉熵。
5.3.1 Pipeline
(1) CR-CNN
Santos et. al Computer Science 2015
输入层 word embedding + position embedding,用 6 个卷积核 + max pooling 生成句子向量表示,与关系(类别)向量做点积求相似度,作为关系分类的结果。
损失函数用的是 pairwise ranking loss function
训练时每个样本有两个标签,正确标签 y+ 和错误标签 c-,m+ 和 m- 对应了两个 margin,用来缩放,希望
越大越好,
越小越好。
另外还有一些 tips:
- 负样本选择
最大的标签,便于更好地将比较类似的两种 label 分开
- 加了一个 Artifical Class,表示两个实体没有任何关系,可以理解为 Other/拒识,训练时不考虑这一类,损失函数的第一项直接置 0,预测时如果其他 actual classes 的分数都为负,那么就分为 Other,对于整体的 performance 有提升
- position feature 是每个 word 与两个 entity 的相对距离,强调了两个实体的作用,认为距离实体近的单词更重要,PE 对效果的提升明显,但实际上只用两个实体间的 word embedding 作为输入代替整个句子的 word embedding+position embedding,也有相近效果,且输入更少实现更简单。
(2) Attention-CNN
Relation Classification via Multi-Level Attention CNNs
用了两个层面的 Attention,一个是输入层对两个 entity 的注意力,另一个是在卷积后的 pooling 阶段,用 attention pooling 代替 max pooling 来加强相关性强的词的权重。
输入特征还是 word embedding 和 position embedding,另外做了 n-gram 的操作,取每个词前后 k/2 个词作为上下文信息,每个词的 embedding size 就是。这个滑动窗口的效果其实和卷积一样,但因为输入层后直接接了 attention,所以这里先做了 n-gram。
第一层 input attention 用两个对角矩阵分别对应两个 entity,对角线各元素是输入位置对应词与实体间的相关性分数,通过词向量內积衡量相关性,然后 softmax 归一化,每个词对两个实体各有一个权重
,然后进行加权把权重与输入
融合,有三种融合方法, 求平均、拼接、相减(类似 transE 操作,把 relation 看做两个权重的差)。这一层的 attention 捕捉的是句中单词与实体的词向量距离,但其实有些线索词如 caused 与实体的相似度不高但很重要。
接着做正常卷积,然后第二层用 attention pooling 代替 max-pooling,bilinear 方法计算相关度,然后归一化,再做 max pooling 得到模型最后的输出。
另外,这篇 paper 还改进了 Santos 提出的 Ranking loss,Ranking loss 里的 distance function 直接用了网络的输出,而这里定义了新的 distance function 来衡量模型输出 和正确标签对应的向量 relation embedding
的距离:
用了 L2 正则,然后基于这一距离定义了目标函数:
两个距离分别为网络输出与正例和与负例的距离,负例照例用了所有错误类别中与输出最接近的,margin 设置的 1。
这应该是目前最好的方法,SemEval-2010 Task 8 上的 F1 值到了 88。
(3) Attention-BLSTM 模型
CNN 可以处理文本较短的输入,但是长距离的依赖还是需要 LSTM,这一篇就是中规中矩的 BiLSTM+Attn 来做关系分类任务。
(4) 评测
各方法在 SemEval-2010 Task 8 上的评测:
5.3.2 Joint Model
Pipeline 的方法会导致误差的传递,端到端的方法直觉上会更优。
(1) LSTM-RNNs
用端到端的方式进行抽取,实体识别和关系分类的参数共享,不过判断过程并没有进行交互。
三个表示层
- Embedding layer (word embeddings layer)
用到了词向量、词性 POS tags
、依存句法标签 Dependency types
、实体标签 entity labels
- Sequence layer (word sequence based LSTM-RNN layer)
负责实体识别
BiLSTM 对句子进行编码,输入是 word embedding 和 POS embedding 的拼接,输出是两个方向的隐层单元输出的拼接
然后进行实体识别,还是序列标注任务,两层 NN 加一个 softmax 输出标签。打标签的方法用 BILOU(Begin, Inside, Last, Outside, Unit),解码时考虑到当前标签依赖于上一个标签的问题,输入在 sequence layer 层的输出上还加了上一时刻的 label embedding,用 schedule sampling 的方式来决定用 gold label 还是 predict label
- Dependency layer (dependency subtree based LSTM-RNN layer )
负责关系分类
用 tree-structured BiLSTM-RNNs 来表示 relation candidate,捕捉了 top-down 和 bottom-up 双向的关系,输入是 sequence layer 的输出,dependency type embedding
,以及 label embedding
,输出是
关系分类主要还是利用了依存树中两个实体之间的最短路径(shortest path)。主要过程是找到 sequence layer 识别出的所有实体,对每个实体的最后一个单词进行排列组合,再经过 dependency layer 得到每个组合的,然后同样用两层 NN + softmax 对该组合进行分类,输出这对实体的关系类别。
不同模型在 SemEval-2010 Task 8 数据集上的效果比较:
与我们的直觉相反,joint model 不一定能起正作用。不过上面的比较能得到的另一个结论是:外部资源可以来优化模型。
5.3 监督学习-评价指标
最常用的 Precision, Recall, F1
5.4 监督学习-小结
如果测试集和训练集很相似,那么监督学习的准确率会很高,然而,它对不同 genre 的泛化能力有限,模型比较脆弱,也很难扩展新的关系;另一方面,获取这么大的训练集代价也是昂贵的。
6. 半监督学习
6.1 研究综述
漆桂林,高桓,吴天星.知识图谱研究进展[J].情报工程,2017,3(1):004-025
Brin[23]等人通过少量的实例学习种子模板,从网络上大量非结构化文本中抽取新的实例,同时学习新的抽取模板,其主要贡献是构建了 DIPRE 系统;Agichtein[24]在 Brin 的基础上对新抽取的实例进行可信度的评分和完善关系描述的模式,设计实现了 Snowball 抽取系统;此后的一些系统都沿着 Bootstrap 的方法,但会加入更合理的对 pattern 描述、更加合理的限制条件和评分策略,或者基于先前系统抽取结果上构建大规模 pattern;如 NELL(Never-EndingLanguage Learner)系统[25-26],NELL 初始化一个本体和种子 pattern,从大规模的 Web 文本中学习,通过对学习到的内容进行打分来提高准确率,目前已经获得了 280 万个事实。
[23] brin s. Extracting Patterns and relations fromthe World Wide Web[J]. lecture notes in computerScience, 1998, 1590:172-183.
[24] Agichtein E, Gravano L. Snowball : Extractingrelations from large Plain-text collections[c]// acMConference on Digital Libraries. ACM, 2000:85-94.
[25] Carlson A, Betteridge J, Kisiel B, et al. Toward anarchitecture for never-Ending language learning.[c]// twenty-Fourth aaai conference on artificialIntelligence, AAAI 2010, Atlanta, Georgia, Usa, July.DBLP, 2010:529-573.
[26] Mitchell T, Fredkin E. Never-ending Languagelearning[M]// never-Ending language learning.Alphascript Publishing, 2014.
6.2 Seed-based or bootstrapping approaches
半监督学习主要是利用少量的标注信息进行学习,这方面的工作主要是基于 Bootstrap 的方法以及远程监督方法(distance supervision)。基于 Bootstrap 的方法 主要是利用少量实例作为初始种子(seed tuples)的集合,然后利用 pattern 学习方法进行学习,通过不断迭代从非结构化数据中抽取实例,然后从新学到的实例中学习新的 pattern 并扩充 pattern 集合,寻找和发现新的潜在关系三元组。远程监督 方法主要是对知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。
6.2.1 Relation Bootstrapping
- • Gather a set of seed pairs that have relation R
- • Iterate:
- 1. Find sentences with these pairs
- 2. Look at the context between or around the pair and generalize the context to create patterns
- 3. Use the patterns for grep for more pairs
看一个完整的例子
从 5 对种子开始,找到包含种子的实例,替换关键词,形成 pattern,迭代匹配,就为(author, book) 抽取到了 relation pattern,x, by y, 和 x, one of y’s
优点:
- 构建成本低,适合大规模构建
- 可以发现新的关系(隐含的)
缺点:
- 对初始给定的种子集敏感
- 存在语义漂移问题
- 结果准确率较低
- 缺乏对每一个结果的置信度的计算
6.2.2 Snowball
对 Dipre 算法的改进。Snowball 也是一种相似的迭代算法,Dipre 的 X,Y 可以是任何字符串,而 Snowball 要求 X,Y 必须是命名实体,并且 Snowball 对每个 pattern 计算了 confidence value
- Group instances w/similar prefix, middle, suffix, extract patterns
- • But require that X and Y be named entites
- • And compute a confidence for each pattern
-
- ORGANIZATION {'s, in, headquaters} LOCATION
- LOCATION {in, based} ORGANIZATION
6.3 Distant Supervision
基本假设:两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
具体步骤:
- 从知识库中抽取存在关系的实体对
- 从非结构化文本中抽取含有实体对的句子作为训练样例,然后提取特征训练分类器。
Distant Supervision 结合了 bootstrapping 和监督学习的长处,使用一个大的 corpus 来得到海量的 seed example,然后从这些 example 中创建特征,最后与有监督的分类器相结合。
与监督学习相似的是这种方法用大量特征训练了分类器,通过已有的知识进行监督,不需要用迭代的方法来扩充 pattern。
与无监督学习相似的是这种方法采用了大量没有标注的数据,对训练语料库中的 genre 并不敏感,适合泛化。
6.3.1 PCNN + Attention
- PCNN
单一池化难以刻画不同上下文对句向量的贡献,而进行分段池化,根据两个实体把句子分成三段然后对不同部分分别进行池化,刻画更为精准。
另见 Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks - Sentence-level attention
远程监督常用的 multi-instance learning,只选取最有可能的一个句子进行训练预测,丢失了大部分信息,句子层面的 attention 对 bag 里所有句子进行加权作为 bag 的特征向量,保留尽可能多的信息,能动态减少噪声句的权重,有利于解决错误标记的问题。
另见 Neural Relation Extraction with Selective Attention over Instances
这里对两个实体向量作差来表示 relation 向量,如果一个实例能表达这种关系,那么这个实例的向量表达应该和
] 表示垂直级联,
是 PCNN 得到的特征输出,softmax 归一化再进行加权,最后再过softmax 进行分类。
3. Entity representation
引入了实体的背景知识(Freebase 和 Wikipedia 提供的实体描述信息),增强了实体表达(entity representation),D 是 (entity, description) 的集合表示, 是实体表示,
通过另一个传统 CNN 对收集到的实体的描述句抽特征得到
希望 和
尽可能相似,定义两者间的误差:
最后的损失函数是交叉熵和实体描述误差的加权和:
6.4 小结
优点:
- 可以利用丰富的知识库信息,减少一定的人工标注
缺点:
- 假设过于肯定,引入大量噪声,存在语义漂移现象
- 很难发现新的关系
7. 无监督学习
7.1 研究综述
Bollegala[27]从搜索引擎摘要中获取和聚合抽取模板,将模板聚类后发现由实体对代表的隐含语义关系; Bollegala[28]使用联合聚类(Co-clustering)算法,利用关系实例和关系模板的对偶性,提高了关系模板聚类效果,同时使用 L1 正则化 Logistics 回归模型,在关系模板聚类结果中筛选出代表性的抽取模板,使得关系抽取在准确率和召回率上都有所提高。
无监督学习一般利用语料中存在的大量冗余信息做聚类,在聚类结果的基础上给定关系,但由于聚类方法本身就存在难以描述关系和低频实例召回率低的问题,因此无监督学习一般难以得很好的抽取效果。
[27] Bollegala D T, Matsuo Y, Ishizuka M. Measuringthe similarity between implicit semantic relationsfrom the Web[J]. Www Madrid! track semantic/dataWeb, 2009:651-660.
[28] Bollegala D T, Matsuo Y, Ishizuka M. RelationalDuality: Unsupervised Extraction of semantic relations between Entities on the Web[c]//International Conference on World Wide Web, WWW 2010, Raleigh, North Carolina, Usa, April. DBLP, 2010:151-160.
7.2 Open IE
Open Information Extraction 从网络中抽取关系,没有训练数据,没有关系列表。过程如下:
- 1. Use parsed data to train a “trustworthy tuple” classifier
- 2. Single-pass extract all relations between NPs, keep if trustworthy
- 3. Assessor ranks relations based on text redundancy
-
- E.g.,
- (FCI, specializes in, sobware development)
- (Tesla, invented, coil transformer)
8. 半监督/无监督学习-评价指标
因为抽取的是新的关系,并不能准确的计算 precision 和 recall,所以我们只能估计,从结果集中随机抽取一个关系的 sample,然后人工来检验准确率
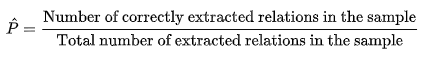
也可以计算不同 recall level 上的 precision,比如说分别计算在前 1000,10,000,100,000 个新的关系中的 precision,在各个情况下随机取样。
然而,并没有方法来计算 recall。

