
- 1C语言使用第三方库编译报错错误排查_evp_sm4_gcm
- 2免费的发票查验接口平台 PHP开发示例
- 3OPPO A72/A55/K7X/A53真我Q3S等手机ROOT刷机后广电卡没信号不读卡解决办法_oppo a53 升级后基带不变
- 4大数据毕业设计Hadoop+Spark知识图谱电影推荐系统 电影用户画像系统 电影评论情感分析 电影爬虫 电影可视化 电影大数据 电影数据分析 计算机毕业设计 机器学习 深度学习 人工智能
- 5vue2版本+TS(typescript)+封装api_ts封装api
- 6Spark-Scala语言实战(5)_scala创建spark对象
- 7图机器学习(CS224W)-第1课_图计算是机器学习吗?
- 8基于Python电商用户行为的数据分析、机器学习、可视化研究_用户行为数据可视化大屏
- 9球从楼梯弹起的数学原理 用数学建模运动的美妙之处(教程含R语言源码)
- 10经验分享:一个 30 岁的人是如何转行做程序员,进入IT行业的?_30岁程序员找不到工作想转行了
无人驾驶算法学习(九):LeGo-LOAM激光雷达定位算法_基于loam的无人车
赞
踩
1.文章解读
1.1引言
代码下载
论文下载
LeGo-LOAM是一种轻型、地面优化的激光雷达测程测图方法,用于实时六自由度姿态估计。LeGO-LOAM是轻量级的,因为它可以在低功耗的嵌入式系统上实现实时的姿态估计。

系统接收来自3D激光雷达的输入并输出6个DOF姿势估计。 整个系统分为五个模块。 首先是segmentation,使用单次扫描的点云,并将其投影到范围图像上进行分段(线)。 然后将分段的点云发送到feature extraction模块。 然后,激光雷达测距仪使用从前一模块中提取的特征来找到与连续扫描相关的变换。 这些特征在lidar mapping中进一步处理,将它们注册到全局点云图。 最后,transform integration模块融合了激光雷达测距和激光雷达测绘的姿态估计结果,并输出最终的姿态估计,整体流程如下图所示:

1.2分割点云(Segmentation)
1)首先将收到的一帧点云投影到一副1800*16的图像上(水平精度0.2°,16线lidar),每一个收到的点代表图像的一个像素,像素的值 r i r_{i} ri表示相应的点 p i p_{i} pi到sensor的欧式距离。
2)完成图像化之后得到一个矩阵,对矩阵的每一列进行估计(即完成对地面的估计),在分割之前进行地面点的提取。可能代表地面的点被标记为地面点而不用于分割。
3)将基于图像的分割方法应用于距离图像以将点分组为多个聚类。同一类的点具有相同的一个标签(地面是较为特殊的一类);同时,为了快速可靠地完成特征提取,忽略少于30个点的类。
完成这一步之后,图像里只保留了可能代表大物体的点,然后记录下点的三个值:
(1)类的标签;(2)点在矩阵中的坐标(x,y);(3)点的值即 r i r_{i} ri在接下来的模块里使用。如下图所示:

1.3特征提取(Feature Extraction)
这个模块的原理与LOAM类似,先在水平方向上将深度图均分成许多子图像,然后计算每个点的曲率,然后在每个子图(submap)的每一行根据曲率的大小选择若干个角点(edge points)和若干个平面点(planar points)。
为了从所有方向均匀地提取特征,作者将图像水平划分为几个相等的子图像。 然后我们基于它们的平滑度c对子图像的每一行中的点进行排序。然后通过设定的阈值 c t h c_{th} cth来判定平面点或者角点。效果如下图:
接下来进行了LOAM中没有的操作,即作者认为子图像中的每一行具有最大c值的edge特征点,其不属于地面; 类似地,子图像中的每一行具有最小c值的平面特征点一定是地面点。处理之后效果如下:


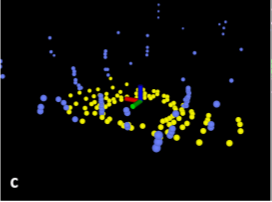
1.4雷达里程记(Lidar Odometry)
Lidar Odometry模块估计两次连续扫描之间的传感器运动。 通过执行point-edge和point-plane扫描匹配找到两次扫描之间的转换。具体方法采用的与LOAM中一致。主要区别如下:
1)Label matching
由于前面Segmentation已经知道了每个点的Label property,在配准过程中,对任意一点的配准只在标签相同的点里进行匹配。例如,平面点只考虑标记为地面点的点,边缘点只考虑其他标记为大物体的点。
2)Two-step L-M Optimization
(1)通过配准平面点来得到 [ t z , θ r o l l , θ p i t c h ] [t_{z},\theta _{roll},\theta_{pitch}] [tz,θroll,θpitch](2)然后在以 [ t z , θ r o l l , θ p i t c h ] [t_{z},\theta _{roll},\theta_{pitch}] [tz,θroll,θpitch]为约束的情况下,通过配准边缘点来来估计 [ t x , t y , θ y a w ] [t_{x},t_{y},\theta_{yaw}] [tx,ty,θyaw]。虽然在第一步中也能估计 [ t x , t y , θ y a w ] [t_{x},t_{y},\theta_{yaw}] [tx,ty,θyaw],但它们不够准确而且不用在第二步。通过使用两步优化方法,可以实现类似的精度,同时计算时间减少约35%。
匹配算法如下:

1.5雷达建图(Lidar Mapping)
Lidar Mapping模块中,将特征点与周围点云图进行配准,以进一步优化姿势变换,但以较低频率运行。具体细节与LOAM相似。LeGO-LOAM的主要不同之处在于如何存储最终点云图。LeGO-LOAM选择存储每一个特征点集,而不是单一的点云图。
1)设 M t − 1 M^{t-1} Mt−1是保存所有先前特征点集的集合。在进行扫描时, M t − 1 M^{t-1} Mt−1中的每个特征集也与传感器的位姿相关联。这样,我们可以根据 M t − 1 M^{t-1} Mt−1来得到周围点云图(surrounding point cloud map) Q ˉ t − 1 \bar{Q}^{t-1} Qˉt−1:第一种方法,通过选择通过选择传感器视场中的特征点集来获得 Q ˉ t − 1 \bar{Q}^{t-1} Qˉt−1;为了简单起见,选择特征点集关联的传感器位姿在传感器当前位置100米范围内的特征点集。然后将所选择的特征点集转换并融合到单个周围的地图中,从而得到 Q ˉ t − 1 \bar{Q}^{t-1} Qˉt−1。
2)作者还将位姿图SLAM集成到LeGO-LOAM中。 每个特征点集的传感器位姿可以被建模为位姿图中的节点。特征点集可以视为此节点的传感器测量值。由于Lidar Mapping模块的姿态估计漂移非常低,假设在短时间内没有漂移。通过这种方式,可以通过选择最近的一组特征点集来形成 Q ˉ t − 1 \bar{Q}^{t-1} Qˉt−1。然后,可以使用在L-M优化之后获得的变换来添加新节点与 Q ˉ t − 1 \bar{Q}^{t-1} Qˉt−1中的所选节点之间的空间约束。可以通过执行闭环检测来进一步消除该模块的漂移。在这种情况下,如果在当前特征点集与使用ICP的先前特征点集之间找到匹配,则会添加新约束。然后通过将位姿图发送到优化系统来更新传感器的估计位姿。
建图效果演示:

2.安装运行
2.1编译运行

2.2保存地图
3.代码实战
未完待续
参考:
https://blog.csdn.net/qq_21842097/article/details/88319580
https://blog.csdn.net/learning_tortosie/article/details/86527542

