
- 1.net 论坛大全_百万综合文字论文坛高手论坛
- 2地表最强,接口调试神器Postman ,写得太好了!_接口测试工具 postman
- 3微信canvas画一个进度条刻度扇形_微信小程序 canvas.arc 扇形图
- 4Java系列:Java8 新特性:强大的 Stream API(创建 Stream、中间操作、终止操作)_java8 api
- 5如何修复 Ubuntu 上的“E Unable to locate package package_name”错误_e: unable to locate package tunctl
- 6Web前端最全Swift 开源项目精选(3),前端开发培训中心
- 7RabbitMQ从入门到精通(详细)_rabbitmq学习
- 8A星算法浅析_为什么a星算法和宽度优先搜索都能找到最优解,即搜索步数都是最少,但它的性能,
- 9Vue+element-ui项目中 根据URL生成二维码_elementui 二维码
- 10某程旅行安全工程师一面
【手把手带你学习神经机器翻译--模型篇】_cnn翻译指令
赞
踩
1、深度神经网络
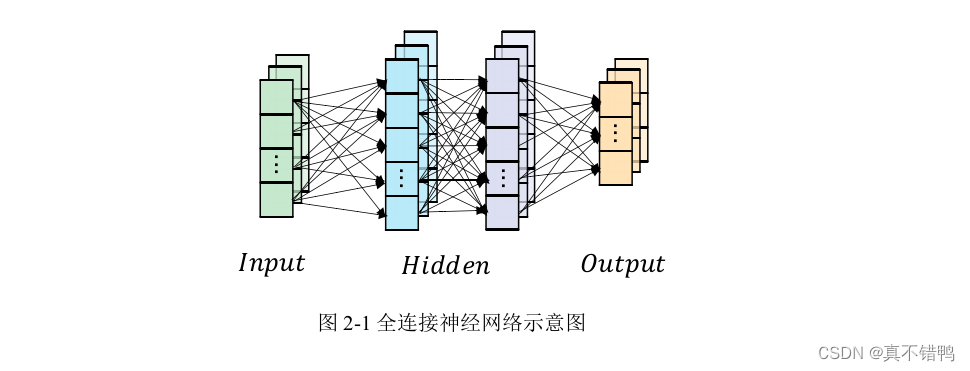
1.1、全连接神经网络
全连接神经网络(FullyConnected Neural Network,FCNN),是深度神经网络中最基本的一种结构,如图所示。按照神经元所处的位置划分,全连接网络由输入层,隐藏层和输出层组成,通常第一层为输入层,最后一层为输出层,中间部分全为隐藏层。顾名思义,全连接神经网络中每一个神经元都与下一层的神经元全部连接,因而每个层又称为全连接层。网络中同层次的神经元之间无连接,层次间的神经元关系由下述公式得出:
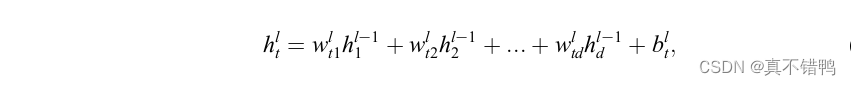
其中,当l=1时,h0t=xt即为输入。显然,公式21的计算过程是线性的,若每个神经元由该线性计算得出,无论网络的层数有多少,模型解决问题的能力仅限于线性划分问题。为了使神经网络可以处理任意非线性问题,引入了非线性激活函数(Nonlinear Activeation Function,下简称为激活函数),用以增强神经网络的泛化性。常用的激活函数有sigmoid,tanh和ReLU。
引入激活函数后层次间神经元关系计算为:
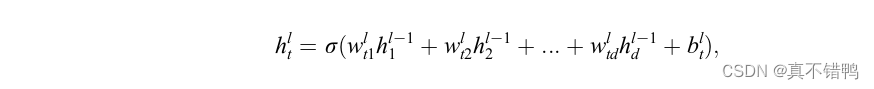
其中,σ代表激活函数。
全连接网络通过对每一个神经元进行计算,得出输出层神经元的结果。近年来,随着各种特异的网络结构的 出,纯粹由全连接层组成的全连接网络并不多见,通常全连接层和其他结构搭配出现,作为一个线性或非线性的映射层。
1.2、循环神经网络
在实际场景中,许多问题的建模都是和时间序列信息有关系的。尤其是在自然语言处理的许多任务中,数据间的上下文的依赖性很高。考虑到对这类问题进行建模,Elman出循环神经网络(Recurrent Neural Network,RNN),其结构如图所示。显然,循环神经网络的输入和输出之间有一个循环过程,将循环过程展开后可以发现,循环神经网络的隐藏层节点关系建立在两个输入之上,一是当前时刻的标准输入,另一个是上一个节点的隐藏层信息,体现为:
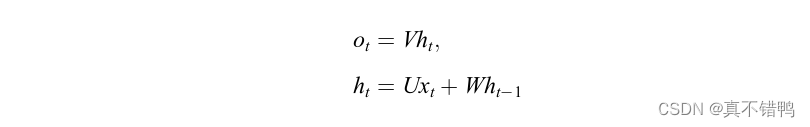
其中,o代表循环神经单元的输出值,h代表循环神经单元的隐藏层值。显然,和全连接网络不同的是,循环神经元有两个输出。此外,循环神经网络中的参数是所有输入共享的,也就是说,同一层输入所使用的参数是相同的。这样的参数共享不仅能够使得模型的参数量大大减少,同时还能增强模型的泛化能力,尤其是在自然语言处理的相关问题上,当模型接收到超过训练样本长度的输入时,模型仍然能够 取到输入的特征,但这样的参数共享同时也为模型误差传播带来了一定的障碍。目前,对RNN的训练采用的是时序方向传播方法(BackpropagationThrough Time,BPTT),从图22右边的展开式中可以看出,展开后的RNN在时序上的深度取决于序列的长度,而BPTT算法的求导链和这个长度息息相关。因此当序列变长时,BPTT面临两个问题:梯度消失和梯度爆炸。梯度消失是指BPTT反馈到一定长度之后,出现梯度趋近于零无法学习的问题,梯度爆炸则正好相反,它表示梯度呈现很大的值导致长程神经元学习无用的情况。无论BPTT出现哪一种问题,都会使得序列中的上下文关系无法被体现,背离了RNN结构建模序列关系的初衷。目前解决这两个问题的主流方案是在RNN的神经元上增加门控机制来控制数据流向,保证有用数据的传递,其中最著名的是长短期记忆单元(longshortTerm Memory,LSTM)和门控循环单元(Gated Recurrent Units,GRU)。
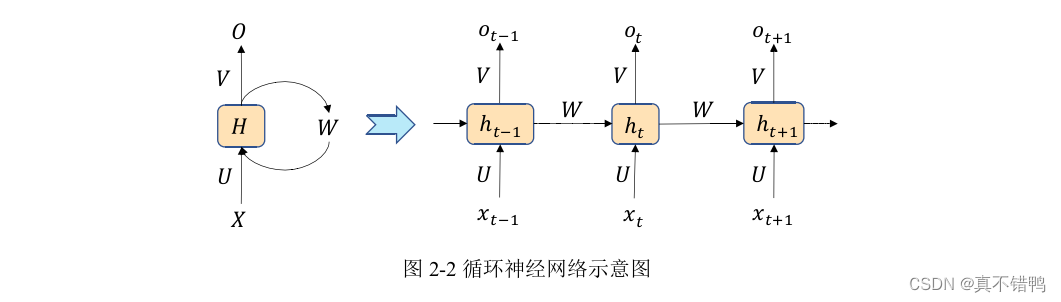
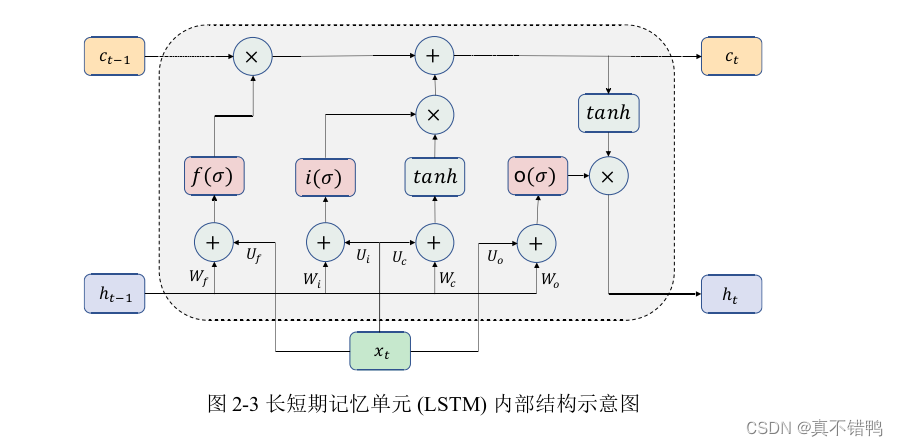
长短期记忆单元LSTM在普通的RNN神经元内增加了三个门控单元来控制数据流向,可以形象的将其称为输入门、遗忘门和输出门,三个门分别对应了三个并列的全连接层。最后,输出由三个门的结果和前一个神经元的状态融合产生,具体公式如下:
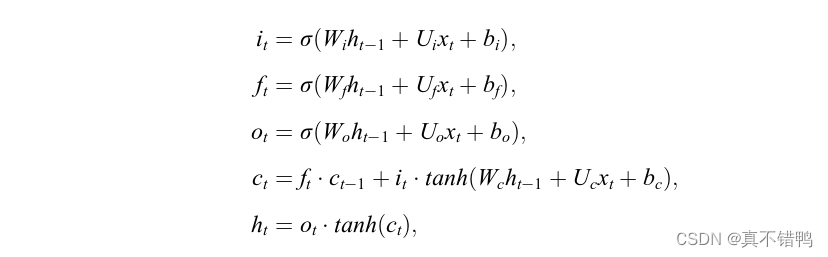
其中,i,f,o分别对应输入门、遗忘门和输出门,c表示神经元的细胞态,h为当前神经元隐藏状态值,也是当前神经元的输出,它融合了三个门的结果和前一个神经元的状态信息。W{i,f,o,c},U{i,f,o,c},b{i,f,o,c}对应不同门的可学习参数,同时,和普通的RNN一样,这些参数也是所有神经元共享的。
因此,当序列通过采用LSTM单元作为基础单元的RNN时,序列信息流的传播会由门控单元来进行控制,保证有用信息的传递,在一定程度上减少模型学习无用的问题。但LSTM在神经元内部进行的一系列全连接计算也导致了模型效率的降低。Cho等人在基于LSTM的基础上,对门控单元进行简化后 出了一种变体结构:门控循环单元GRU。在GRU中,门控单元被减少到了两个:重置门®和更新门(z),其结构由图给出,计算如下:
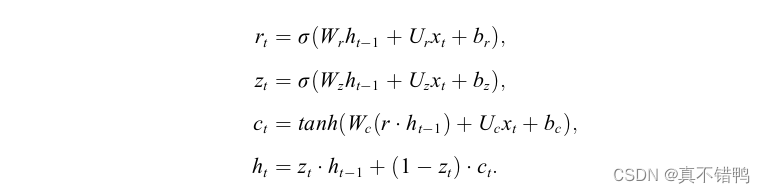
不难发现,GRU直接使用重置门对前一时刻神经元隐藏状态进行刷新,随后融合该状态和当前输入值得到一个新的细胞态,而更新门则根据该细胞态和前一时刻神经元的隐藏状态来控制数据的传递。由于GRU显式的减少了一个门控单元,因此GRU所需的参数量较LSTM更少,在序列任务上的计算效率也比LSTM更高,性能鲜有损失。
1.2.1、RNN模型代码
from __future__ import absolute_import from recurrentshop import LSTMCell, RecurrentSequential from .cells import LSTMDecoderCell, AttentionDecoderCell from keras.models import Sequential, Model from keras.layers import Dense, Dropout, TimeDistributed, Bidirectional, Input def SimpleSeq2Seq(output_dim, output_length, hidden_dim=None, input_shape=None, batch_size=None, batch_input_shape=None, input_dim=None, input_length=None, depth=1, dropout=0.0, unroll=False, stateful=False): ''' Simple model for sequence to sequence learning. The encoder encodes the input sequence to vector (called context vector) The decoder decodes the context vector in to a sequence of vectors. There is no one on one relation between the input and output sequence elements. The input sequence and output sequence may differ in length. Arguments: output_dim : Required output dimension. hidden_dim : The dimension of the internal representations of the model. output_length : Length of the required output sequence. depth : Used to create a deep Seq2seq model. For example, if depth = 3, there will be 3 LSTMs on the enoding side and 3 LSTMs on the decoding side. You can also specify depth as a tuple. For example, if depth = (4, 5), 4 LSTMs will be added to the encoding side and 5 LSTMs will be added to the decoding side. dropout : Dropout probability in between layers. ''' if isinstance(depth, int): depth = (depth, depth) if batch_input_shape: shape = batch_input_shape elif input_shape: shape = (batch_size,) + input_shape elif input_dim: if input_length: shape = (batch_size,) + (input_length,) + (input_dim,) else: shape = (batch_size,) + (None,) + (input_dim,) else: # TODO Proper error message raise TypeError if hidden_dim is None: hidden_dim = output_dim encoder = RecurrentSequential(unroll=unroll, stateful=stateful) encoder.add(LSTMCell(hidden_dim, batch_input_shape=(shape[0], shape[-1]))) for _ in range(1, depth[0]): encoder.add(Dropout(dropout)) encoder.add(LSTMCell(hidden_dim)) decoder = RecurrentSequential(unroll=unroll, stateful=stateful, decode=True, output_length=output_length) decoder.add(Dropout(dropout, batch_input_shape=(shape[0], hidden_dim))) if depth[1] == 1: decoder.add(LSTMCell(output_dim)) else: decoder.add(LSTMCell(hidden_dim)) for _ in range(depth[1] - 2): decoder.add(Dropout(dropout)) decoder.add(LSTMCell(hidden_dim)) decoder.add(Dropout(dropout)) decoder.add(LSTMCell(output_dim)) _input = Input(batch_shape=shape) x = encoder(_input) output = decoder(x) return Model(_input, output) def Seq2Seq(output_dim, output_length, batch_input_shape=None, input_shape=None, batch_size=None, input_dim=None, input_length=None, hidden_dim=None, depth=1, broadcast_state=True, unroll=False, stateful=False, inner_broadcast_state=True, teacher_force=False, peek=False, dropout=0.): ''' Seq2seq model based on [1] and [2]. This model has the ability to transfer the encoder hidden state to the decoder's hidden state(specified by the broadcast_state argument). Also, in deep models (depth > 1), the hidden state is propogated throughout the LSTM stack(specified by the inner_broadcast_state argument. You can switch between [1] based model and [2] based model using the peek argument.(peek = True for [2], peek = False for [1]). When peek = True, the decoder gets a 'peek' at the context vector at every timestep. [1] based model: Encoder: X = Input sequence C = LSTM(X); The context vector Decoder: y(t) = LSTM(s(t-1), y(t-1)); Where s is the hidden state of the LSTM (h and c) y(0) = LSTM(s0, C); C is the context vector from the encoder. [2] based model: Encoder: X = Input sequence C = LSTM(X); The context vector Decoder: y(t) = LSTM(s(t-1), y(t-1), C) y(0) = LSTM(s0, C, C) Where s is the hidden state of the LSTM (h and c), and C is the context vector from the encoder. Arguments: output_dim : Required output dimension. hidden_dim : The dimension of the internal representations of the model. output_length : Length of the required output sequence. depth : Used to create a deep Seq2seq model. For example, if depth = 3, there will be 3 LSTMs on the enoding side and 3 LSTMs on the decoding side. You can also specify depth as a tuple. For example, if depth = (4, 5), 4 LSTMs will be added to the encoding side and 5 LSTMs will be added to the decoding side. broadcast_state : Specifies whether the hidden state from encoder should be transfered to the deocder. inner_broadcast_state : Specifies whether hidden states should be propogated throughout the LSTM stack in deep models. peek : Specifies if the decoder should be able to peek at the context vector at every timestep. dropout : Dropout probability in between layers. ''' if isinstance(depth, int): depth = (depth, depth) if batch_input_shape: shape = batch_input_shape elif input_shape: shape = (batch_size,) + input_shape elif input_dim: if input_length: shape = (batch_size,) + (input_length,) + (input_dim,) else: shape = (batch_size,) + (None,) + (input_dim,) else: # TODO Proper error message raise TypeError if hidden_dim is None: hidden_dim = output_dim encoder = RecurrentSequential(readout=True, state_sync=inner_broadcast_state, unroll=unroll, stateful=stateful, return_states=broadcast_state) for _ in range(depth[0]): encoder.add(LSTMCell(hidden_dim, batch_input_shape=(shape[0], hidden_dim))) encoder.add(Dropout(dropout)) dense1 = TimeDistributed(Dense(hidden_dim)) dense1.supports_masking = True dense2 = Dense(output_dim) decoder = RecurrentSequential(readout='add' if peek else 'readout_only', state_sync=inner_broadcast_state, decode=True, output_length=output_length, unroll=unroll, stateful=stateful, teacher_force=teacher_force) for _ in range(depth[1]): decoder.add(Dropout(dropout, batch_input_shape=(shape[0], output_dim))) decoder.add(LSTMDecoderCell(output_dim=output_dim, hidden_dim=hidden_dim, batch_input_shape=(shape[0], output_dim))) _input = Input(batch_shape=shape) _input._keras_history[0].supports_masking = True encoded_seq = dense1(_input) encoded_seq = encoder(encoded_seq) if broadcast_state: assert type(encoded_seq) is list states = encoded_seq[-2:] encoded_seq = encoded_seq[0] else: states = None encoded_seq = dense2(encoded_seq) inputs = [_input] if teacher_force: truth_tensor = Input(batch_shape=(shape[0], output_length, output_dim)) truth_tensor._keras_history[0].supports_masking = True inputs += [truth_tensor] decoded_seq = decoder(encoded_seq, ground_truth=inputs[1] if teacher_force else None, initial_readout=encoded_seq, initial_state=states) model = Model(inputs, decoded_seq) model.encoder = encoder model.decoder = decoder return model def AttentionSeq2Seq(output_dim, output_length, batch_input_shape=None, batch_size=None, input_shape=None, input_length=None, input_dim=None, hidden_dim=None, depth=1, bidirectional=True, unroll=False, stateful=False, dropout=0.0,): ''' This is an attention Seq2seq model based on [3]. Here, there is a soft allignment between the input and output sequence elements. A bidirection encoder is used by default. There is no hidden state transfer in this model. The math: Encoder: X = Input Sequence of length m. H = Bidirection_LSTM(X); Note that here the LSTM has return_sequences = True, so H is a sequence of vectors of length m. Decoder: y(i) = LSTM(s(i-1), y(i-1), v(i)); Where s is the hidden state of the LSTM (h and c) and v (called the context vector) is a weighted sum over H: v(i) = sigma(j = 0 to m-1) alpha(i, j) * H(j) The weight alpha[i, j] for each hj is computed as follows: energy = a(s(i-1), H(j)) alpha = softmax(energy) Where a is a feed forward network. ''' if isinstance(depth, int): depth = (depth, depth) if batch_input_shape: shape = batch_input_shape elif input_shape: shape = (batch_size,) + input_shape elif input_dim: if input_length: shape = (batch_size,) + (input_length,) + (input_dim,) else: shape = (batch_size,) + (None,) + (input_dim,) else: # TODO Proper error message raise TypeError if hidden_dim is None: hidden_dim = output_dim _input = Input(batch_shape=shape) _input._keras_history[0].supports_masking = True encoder = RecurrentSequential(unroll=unroll, stateful=stateful, return_sequences=True) encoder.add(LSTMCell(hidden_dim, batch_input_shape=(shape[0], shape[2]))) for _ in range(1, depth[0]): encoder.add(Dropout(dropout)) encoder.add(LSTMCell(hidden_dim)) if bidirectional: encoder = Bidirectional(encoder, merge_mode='sum') encoder.forward_layer.build(shape) encoder.backward_layer.build(shape) # patch encoder.layer = encoder.forward_layer encoded = encoder(_input) decoder = RecurrentSequential(decode=True, output_length=output_length, unroll=unroll, stateful=stateful) decoder.add(Dropout(dropout, batch_input_shape=(shape[0], shape[1], hidden_dim))) if depth[1] == 1: decoder.add(AttentionDecoderCell(output_dim=output_dim, hidden_dim=hidden_dim)) else: decoder.add(AttentionDecoderCell(output_dim=output_dim, hidden_dim=hidden_dim)) for _ in range(depth[1] - 2): decoder.add(Dropout(dropout)) decoder.add(LSTMDecoderCell(output_dim=hidden_dim, hidden_dim=hidden_dim)) decoder.add(Dropout(dropout)) decoder.add(LSTMDecoderCell(output_dim=output_dim, hidden_dim=hidden_dim)) inputs = [_input] decoded = decoder(encoded) model = Model(inputs, decoded) return model

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
1.3、卷积神经网络
和循环神经网络 出的原因一样,卷积神经网络(Convolutional Neural Network,CNN) 出也是为了针对性的处理问题。与循环神经网络的 出是针对序列关系建模不同的是,卷积神经网络最初的 出是为了高效处理非序列数据问题,例如取图像中的特征问题。具体地,图像由于其具有空间三维性且包含的数据量过大,使用全连接网络会导致网络庞大且效率低下,为了 高神经网络对图像等类似数据的高效处理,基于局部特征取的卷积神经网络被出。它通过模拟生物捕捉图像特征的方法,对输入进行局部特征的 取,再依靠深度网络对高层特征的捕捉能力实现对图像的特征取。后来卷积神经网络被证明也可应用于自然语言处理任务,并且效率更高。一个完整的卷积神经网络包含三个部分,卷积层、池化层、全连接层。
卷积层是卷积神经网络的核心计算层,用于取输入的特征。一个卷积层由多个卷积核(Kernel)组成,每个卷积核负责取输入的一部分局部特征,其深度和输入相同,但高度和宽度都远小于输入。一次卷积计算,卷积核仅能和在其视野内,也就是在其高度和宽度范围内的输入数据交互,这个视野也被称之为感受野,是由人为设定的。通过滑动,卷积核的感受野不断变换,从而完成和输入的所有数据交互。感受野滑动的幅度称之为步长,是一个人为设定的经验值,一般设为1。卷积的计算过程用公式表示如下:
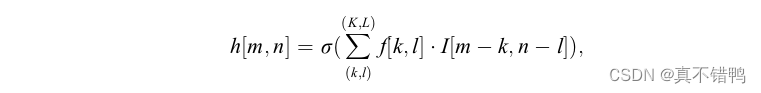
其中,h[m,n]代表尺寸为m×n的输入经过卷积后得到的隐藏层输出值,卷积核集合为K×L,一次卷积从中取出一个k×l的卷积核进行操作,I为输入数据,可以是输入源数据,也可以是前一隐藏层的输出数据。σ代表激活函数。图演示了一个卷积核尺寸为3×3的一次卷积计算示例。
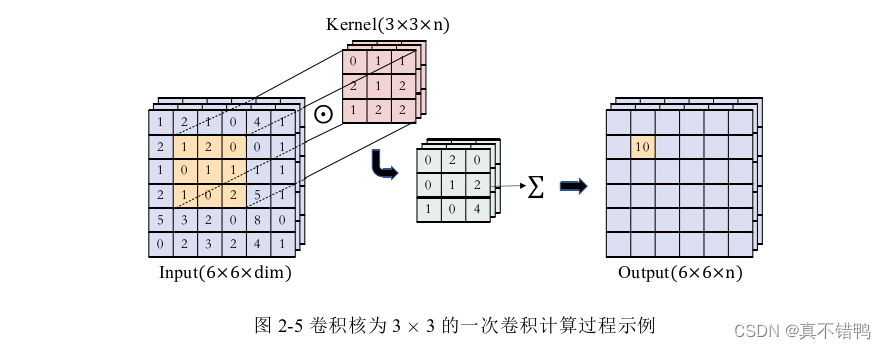
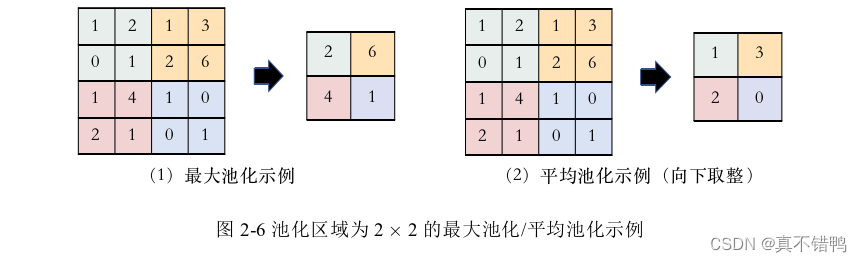
显然,若想获得输入的更多特征,则需要设定多种不同的卷积核去捕捉输入,这样仍然会使得模型庞大。为了减少网络的参数量,卷积神经网络引入下采样操作周期性的在卷积层之后进行操作,被称为池化层。池化层的计算方法一般有两种,最大池化(Max Pooling)和平均池化(Average Pooling),顾名思义,最大池化即是在池化区域中取最大值作为输出,而平均池化是取池化区域中的平均值作为输出。同卷积层操作一样,池化层也需要人工设定工作区域和移动步长,图2演示了一个池化区域为2×2,在步长为2时的最大池化/平均池化示例。
卷积神经网络通过堆叠卷积层和池化层获取到输入的特征,再将该特征拉伸为向量后通过一个全连接层后输出整个网络的结果。
1.4、基于循环神经网络的深度神经序列模型
对深度神经序列模型的追溯,最早可到2013年,由Kalchbrenner等人出采用编码解码的思想解决自然语言生成问题,它为后续序列模型结构奠定了基础,该思想为:将给定输入文本通过一个编码器网络重构成一个新的表示,再采用一个解码器网络解构这个表示并根据解构后的信息生成目标文本。具体地,Kalchbrenner等人在文中采用卷积神经网络作为编码器对输入进行重构,采用循环神经网络作为解码器进行生成。该模型当时虽并未取得非常理想的结果,但却引发了领域内众人的热烈讨论。考虑到模型采用卷积神经网络作为编码器并不能完全切合语言的特点,同时解码器采用的循环神经单元未做门控处理会有梯度消失/爆炸的问题,Sutckever等人将LSTM单元引入该模型替换了原模型中的基本循环神经单元,同时将编码器中的卷积神经网络替换为更贴合语言特点的循环神经网络,该模型如图所示,其在机器翻译任务上取得的成功验证了深度神经网络模型在自动机器翻译任务上的可行性。几乎同时,Cho等人对此种序列到序列的模型归纳为编码解码模型,并通过对上下文表示的强调进一步升该模型的性能,如图所示。
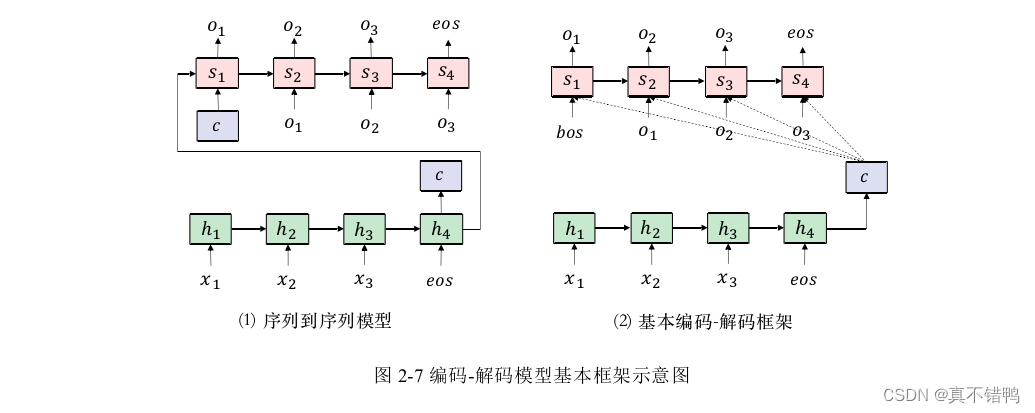
自此,序列到序列模型在自然语言处理生成问题上奠定了基础,任何可建模为“序列映射到序列”的问题都可采用该框架,并且采用LSTM或GRU的循环神经网络也成为自然语言处理任务的标准结构。计算过程一般分为3步,首先编码器对输入文本X=(x1,x2,…,xm)进行重构,其中xi表示输入文本中第i个最小组成部分,也就是一个标记。对于中文来说,如果是基于中文词语的模型,一个标记就代表一个词语,如果是基于中文分字的模型,一个标记就代表一个字符;对于英文或其它类似西文来说,一个标记代表一个单词。编码器重构的方式为:
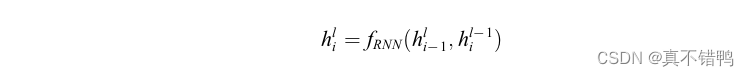
其中fRNN代表采用了LSTM或GRU的循环神经单元,h为循环神经单元的隐藏值,l代表层数,此处定义i代表当前编码时序,显然i−1是前一个时序。根据循环神经网络的特点,一般采用最后一层最后一个时序计算后的输出作为重构后的向量表示,定义为c,该向量由于融合了前序序列经门控后的特征,被认为是输入文本的高层语义表示。接下来解码器使用c作为上下文语义表示进行解码计算,定义为:
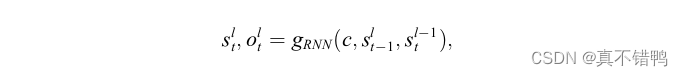
其中,gRNN代表采用了LSTM或GRU的循环神经单元,s为循环神经单元的隐藏值,t代表当前解码时序,o为循环神经单元的输出值,y为当前时刻解码器的输入,同时它也是前一时序模型的预测输出,这种模式被称为自回归解码模式,即每一时刻解码器的预测值都是基于前一时刻解码器的预测值计算的。模型的输出部分采用一个线性层对解码器的输出进行线性转换并映射到词表上进行选词:
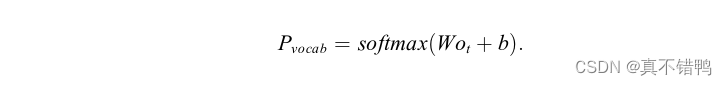 值得一 的是,目前在文本生成技术中广泛采用teacherforcing学习算法,该算法在模型训练阶段采用右移标签作为解码器输入,即丢弃训练阶段模型的预测值,转而使用t−1时刻的标签值作为解码器的输入以帮助模型尽快学习。到模型预测阶段时,才真正使用前一时刻的预测值来预测输出。由于这个学习算法能加快模型拟合,因此该方法也是目前自然语言处理任务的标准有监督学习方法。
值得一 的是,目前在文本生成技术中广泛采用teacherforcing学习算法,该算法在模型训练阶段采用右移标签作为解码器输入,即丢弃训练阶段模型的预测值,转而使用t−1时刻的标签值作为解码器的输入以帮助模型尽快学习。到模型预测阶段时,才真正使用前一时刻的预测值来预测输出。由于这个学习算法能加快模型拟合,因此该方法也是目前自然语言处理任务的标准有监督学习方法。
1.4.1 Lstm模型实现代码
# Copyright (c) Facebook, Inc. and its affiliates. # # This source code is licensed under the MIT license found in the # LICENSE file in the root directory of this source tree. from typing import Dict, List, Optional, Tuple import torch import torch.nn as nn import torch.nn.functional as F from fairseq import utils from fairseq.models import ( FairseqEncoder, FairseqEncoderDecoderModel, FairseqIncrementalDecoder, register_model, register_model_architecture, ) from fairseq.modules import AdaptiveSoftmax, FairseqDropout from torch import Tensor DEFAULT_MAX_SOURCE_POSITIONS = 1e5 DEFAULT_MAX_TARGET_POSITIONS = 1e5 @register_model("lstm") class LSTMModel(FairseqEncoderDecoderModel): def __init__(self, encoder, decoder): super().__init__(encoder, decoder) @staticmethod def add_args(parser): """Add model-specific arguments to the parser.""" # fmt: off parser.add_argument('--dropout', type=float, metavar='D', help='dropout probability') parser.add_argument('--encoder-embed-dim', type=int, metavar='N', help='encoder embedding dimension') parser.add_argument('--encoder-embed-path', type=str, metavar='STR', help='path to pre-trained encoder embedding') parser.add_argument('--encoder-freeze-embed', action='store_true', help='freeze encoder embeddings') parser.add_argument('--encoder-hidden-size', type=int, metavar='N', help='encoder hidden size') parser.add_argument('--encoder-layers', type=int, metavar='N', help='number of encoder layers') parser.add_argument('--encoder-bidirectional', action='store_true', help='make all layers of encoder bidirectional') parser.add_argument('--decoder-embed-dim', type=int, metavar='N', help='decoder embedding dimension') parser.add_argument('--decoder-embed-path', type=str, metavar='STR', help='path to pre-trained decoder embedding') parser.add_argument('--decoder-freeze-embed', action='store_true', help='freeze decoder embeddings') parser.add_argument('--decoder-hidden-size', type=int, metavar='N', help='decoder hidden size') parser.add_argument('--decoder-layers', type=int, metavar='N', help='number of decoder layers') parser.add_argument('--decoder-out-embed-dim', type=int, metavar='N', help='decoder output embedding dimension') parser.add_argument('--decoder-attention', type=str, metavar='BOOL', help='decoder attention') parser.add_argument('--adaptive-softmax-cutoff', metavar='EXPR', help='comma separated list of adaptive softmax cutoff points. ' 'Must be used with adaptive_loss criterion') parser.add_argument('--share-decoder-input-output-embed', default=False, action='store_true', help='share decoder input and output embeddings') parser.add_argument('--share-all-embeddings', default=False, action='store_true', help='share encoder, decoder and output embeddings' ' (requires shared dictionary and embed dim)') # Granular dropout settings (if not specified these default to --dropout) parser.add_argument('--encoder-dropout-in', type=float, metavar='D', help='dropout probability for encoder input embedding') parser.add_argument('--encoder-dropout-out', type=float, metavar='D', help='dropout probability for encoder output') parser.add_argument('--decoder-dropout-in', type=float, metavar='D', help='dropout probability for decoder input embedding') parser.add_argument('--decoder-dropout-out', type=float, metavar='D', help='dropout probability for decoder output') # fmt: on @classmethod def build_model(cls, args, task): """Build a new model instance.""" # make sure that all args are properly defaulted (in case there are any new ones) base_architecture(args) if args.encoder_layers != args.decoder_layers: raise ValueError("--encoder-layers must match --decoder-layers") max_source_positions = getattr( args, "max_source_positions", DEFAULT_MAX_SOURCE_POSITIONS ) max_target_positions = getattr( args, "max_target_positions", DEFAULT_MAX_TARGET_POSITIONS ) def load_pretrained_embedding_from_file(embed_path, dictionary, embed_dim): num_embeddings = len(dictionary) padding_idx = dictionary.pad() embed_tokens = Embedding(num_embeddings, embed_dim, padding_idx) embed_dict = utils.parse_embedding(embed_path) utils.print_embed_overlap(embed_dict, dictionary) return utils.load_embedding(embed_dict, dictionary, embed_tokens) if args.encoder_embed_path: pretrained_encoder_embed = load_pretrained_embedding_from_file( args.encoder_embed_path, task.source_dictionary, args.encoder_embed_dim ) else: num_embeddings = len(task.source_dictionary) pretrained_encoder_embed = Embedding( num_embeddings, args.encoder_embed_dim, task.source_dictionary.pad() ) if args.share_all_embeddings: # double check all parameters combinations are valid if task.source_dictionary != task.target_dictionary: raise ValueError("--share-all-embeddings requires a joint dictionary") if args.decoder_embed_path and ( args.decoder_embed_path != args.encoder_embed_path ): raise ValueError( "--share-all-embed not compatible with --decoder-embed-path" ) if args.encoder_embed_dim != args.decoder_embed_dim: raise ValueError( "--share-all-embeddings requires --encoder-embed-dim to " "match --decoder-embed-dim" ) pretrained_decoder_embed = pretrained_encoder_embed args.share_decoder_input_output_embed = True else: # separate decoder input embeddings pretrained_decoder_embed = None if args.decoder_embed_path: pretrained_decoder_embed = load_pretrained_embedding_from_file( args.decoder_embed_path, task.target_dictionary, args.decoder_embed_dim, ) # one last double check of parameter combinations if args.share_decoder_input_output_embed and ( args.decoder_embed_dim != args.decoder_out_embed_dim ): raise ValueError( "--share-decoder-input-output-embeddings requires " "--decoder-embed-dim to match --decoder-out-embed-dim" ) if args.encoder_freeze_embed: pretrained_encoder_embed.weight.requires_grad = False if args.decoder_freeze_embed: pretrained_decoder_embed.weight.requires_grad = False encoder = LSTMEncoder( dictionary=task.source_dictionary, embed_dim=args.encoder_embed_dim, hidden_size=args.encoder_hidden_size, num_layers=args.encoder_layers, dropout_in=args.encoder_dropout_in, dropout_out=args.encoder_dropout_out, bidirectional=args.encoder_bidirectional, pretrained_embed=pretrained_encoder_embed, max_source_positions=max_source_positions, ) decoder = LSTMDecoder( dictionary=task.target_dictionary, embed_dim=args.decoder_embed_dim, hidden_size=args.decoder_hidden_size, out_embed_dim=args.decoder_out_embed_dim, num_layers=args.decoder_layers, dropout_in=args.decoder_dropout_in, dropout_out=args.decoder_dropout_out, attention=utils.eval_bool(args.decoder_attention), encoder_output_units=encoder.output_units, pretrained_embed=pretrained_decoder_embed, share_input_output_embed=args.share_decoder_input_output_embed, adaptive_softmax_cutoff=( utils.eval_str_list(args.adaptive_softmax_cutoff, type=int) if args.criterion == "adaptive_loss" else None ), max_target_positions=max_target_positions, residuals=False, ) return cls(encoder, decoder) def forward( self, src_tokens, src_lengths, prev_output_tokens, incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None, ): encoder_out = self.encoder(src_tokens, src_lengths=src_lengths) decoder_out = self.decoder( prev_output_tokens, encoder_out=encoder_out, incremental_state=incremental_state, ) return decoder_out class LSTMEncoder(FairseqEncoder): """LSTM encoder.""" def __init__( self, dictionary, embed_dim=512, hidden_size=512, num_layers=1, dropout_in=0.1, dropout_out=0.1, bidirectional=False, left_pad=True, pretrained_embed=None, padding_idx=None, max_source_positions=DEFAULT_MAX_SOURCE_POSITIONS, ): super().__init__(dictionary) self.num_layers = num_layers self.dropout_in_module = FairseqDropout( dropout_in * 1.0, module_name=self.__class__.__name__ ) self.dropout_out_module = FairseqDropout( dropout_out * 1.0, module_name=self.__class__.__name__ ) self.bidirectional = bidirectional self.hidden_size = hidden_size self.max_source_positions = max_source_positions num_embeddings = len(dictionary) self.padding_idx = padding_idx if padding_idx is not None else dictionary.pad() if pretrained_embed is None: self.embed_tokens = Embedding(num_embeddings, embed_dim, self.padding_idx) else: self.embed_tokens = pretrained_embed self.lstm = LSTM( input_size=embed_dim, hidden_size=hidden_size, num_layers=num_layers, dropout=self.dropout_out_module.p if num_layers > 1 else 0.0, bidirectional=bidirectional, ) self.left_pad = left_pad self.output_units = hidden_size if bidirectional: self.output_units *= 2 def forward( self, src_tokens: Tensor, src_lengths: Tensor, enforce_sorted: bool = True, ): """ Args: src_tokens (LongTensor): tokens in the source language of shape `(batch, src_len)` src_lengths (LongTensor): lengths of each source sentence of shape `(batch)` enforce_sorted (bool, optional): if True, `src_tokens` is expected to contain sequences sorted by length in a decreasing order. If False, this condition is not required. Default: True. """ if self.left_pad: # nn.utils.rnn.pack_padded_sequence requires right-padding; # convert left-padding to right-padding src_tokens = utils.convert_padding_direction( src_tokens, torch.zeros_like(src_tokens).fill_(self.padding_idx), left_to_right=True, ) bsz, seqlen = src_tokens.size() # embed tokens x = self.embed_tokens(src_tokens) x = self.dropout_in_module(x) # B x T x C -> T x B x C x = x.transpose(0, 1) # pack embedded source tokens into a PackedSequence packed_x = nn.utils.rnn.pack_padded_sequence( x, src_lengths.cpu(), enforce_sorted=enforce_sorted ) # apply LSTM if self.bidirectional: state_size = 2 * self.num_layers, bsz, self.hidden_size else: state_size = self.num_layers, bsz, self.hidden_size h0 = x.new_zeros(*state_size) c0 = x.new_zeros(*state_size) packed_outs, (final_hiddens, final_cells) = self.lstm(packed_x, (h0, c0)) # unpack outputs and apply dropout x, _ = nn.utils.rnn.pad_packed_sequence( packed_outs, padding_value=self.padding_idx * 1.0 ) x = self.dropout_out_module(x) assert list(x.size()) == [seqlen, bsz, self.output_units] if self.bidirectional: final_hiddens = self.combine_bidir(final_hiddens, bsz) final_cells = self.combine_bidir(final_cells, bsz) encoder_padding_mask = src_tokens.eq(self.padding_idx).t() return tuple( ( x, # seq_len x batch x hidden final_hiddens, # num_layers x batch x num_directions*hidden final_cells, # num_layers x batch x num_directions*hidden encoder_padding_mask, # seq_len x batch ) ) def combine_bidir(self, outs, bsz: int): out = outs.view(self.num_layers, 2, bsz, -1).transpose(1, 2).contiguous() return out.view(self.num_layers, bsz, -1) def reorder_encoder_out( self, encoder_out: Tuple[Tensor, Tensor, Tensor, Tensor], new_order ): return tuple( ( encoder_out[0].index_select(1, new_order), encoder_out[1].index_select(1, new_order), encoder_out[2].index_select(1, new_order), encoder_out[3].index_select(1, new_order), ) ) def max_positions(self): """Maximum input length supported by the encoder.""" return self.max_source_positions class AttentionLayer(nn.Module): def __init__(self, input_embed_dim, source_embed_dim, output_embed_dim, bias=False): super().__init__() self.input_proj = Linear(input_embed_dim, source_embed_dim, bias=bias) self.output_proj = Linear( input_embed_dim + source_embed_dim, output_embed_dim, bias=bias ) def forward(self, input, source_hids, encoder_padding_mask): # input: bsz x input_embed_dim # source_hids: srclen x bsz x source_embed_dim # x: bsz x source_embed_dim x = self.input_proj(input) # compute attention attn_scores = (source_hids * x.unsqueeze(0)).sum(dim=2) # don't attend over padding if encoder_padding_mask is not None: attn_scores = ( attn_scores.float() .masked_fill_(encoder_padding_mask, float("-inf")) .type_as(attn_scores) ) # FP16 support: cast to float and back attn_scores = F.softmax(attn_scores, dim=0) # srclen x bsz # sum weighted sources x = (attn_scores.unsqueeze(2) * source_hids).sum(dim=0) x = torch.tanh(self.output_proj(torch.cat((x, input), dim=1))) return x, attn_scores class LSTMDecoder(FairseqIncrementalDecoder): """LSTM decoder.""" def __init__( self, dictionary, embed_dim=512, hidden_size=512, out_embed_dim=512, num_layers=1, dropout_in=0.1, dropout_out=0.1, attention=True, encoder_output_units=512, pretrained_embed=None, share_input_output_embed=False, adaptive_softmax_cutoff=None, max_target_positions=DEFAULT_MAX_TARGET_POSITIONS, residuals=False, ): super().__init__(dictionary) self.dropout_in_module = FairseqDropout( dropout_in * 1.0, module_name=self.__class__.__name__ ) self.dropout_out_module = FairseqDropout( dropout_out * 1.0, module_name=self.__class__.__name__ ) self.hidden_size = hidden_size self.share_input_output_embed = share_input_output_embed self.need_attn = True self.max_target_positions = max_target_positions self.residuals = residuals self.num_layers = num_layers self.adaptive_softmax = None num_embeddings = len(dictionary) padding_idx = dictionary.pad() if pretrained_embed is None: self.embed_tokens = Embedding(num_embeddings, embed_dim, padding_idx) else: self.embed_tokens = pretrained_embed self.encoder_output_units = encoder_output_units if encoder_output_units != hidden_size and encoder_output_units != 0: self.encoder_hidden_proj = Linear(encoder_output_units, hidden_size) self.encoder_cell_proj = Linear(encoder_output_units, hidden_size) else: self.encoder_hidden_proj = self.encoder_cell_proj = None # disable input feeding if there is no encoder # input feeding is described in arxiv.org/abs/1508.04025 input_feed_size = 0 if encoder_output_units == 0 else hidden_size self.layers = nn.ModuleList( [ LSTMCell( input_size=input_feed_size + embed_dim if layer == 0 else hidden_size, hidden_size=hidden_size, ) for layer in range(num_layers) ] ) if attention: # TODO make bias configurable self.attention = AttentionLayer( hidden_size, encoder_output_units, hidden_size, bias=False ) else: self.attention = None if hidden_size != out_embed_dim: self.additional_fc = Linear(hidden_size, out_embed_dim) if adaptive_softmax_cutoff is not None: # setting adaptive_softmax dropout to dropout_out for now but can be redefined self.adaptive_softmax = AdaptiveSoftmax( num_embeddings, hidden_size, adaptive_softmax_cutoff, dropout=dropout_out, ) elif not self.share_input_output_embed: self.fc_out = Linear(out_embed_dim, num_embeddings, dropout=dropout_out) def forward( self, prev_output_tokens, encoder_out: Optional[Tuple[Tensor, Tensor, Tensor, Tensor]] = None, incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None, src_lengths: Optional[Tensor] = None, ): x, attn_scores = self.extract_features( prev_output_tokens, encoder_out, incremental_state ) return self.output_layer(x), attn_scores def extract_features( self, prev_output_tokens, encoder_out: Optional[Tuple[Tensor, Tensor, Tensor, Tensor]] = None, incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None, ): """ Similar to *forward* but only return features. """ # get outputs from encoder if encoder_out is not None: encoder_outs = encoder_out[0] encoder_hiddens = encoder_out[1] encoder_cells = encoder_out[2] encoder_padding_mask = encoder_out[3] else: encoder_outs = torch.empty(0) encoder_hiddens = torch.empty(0) encoder_cells = torch.empty(0) encoder_padding_mask = torch.empty(0) srclen = encoder_outs.size(0) if incremental_state is not None and len(incremental_state) > 0: prev_output_tokens = prev_output_tokens[:, -1:] bsz, seqlen = prev_output_tokens.size() # embed tokens x = self.embed_tokens(prev_output_tokens) x = self.dropout_in_module(x) # B x T x C -> T x B x C x = x.transpose(0, 1) # initialize previous states (or get from cache during incremental generation) if incremental_state is not None and len(incremental_state) > 0: prev_hiddens, prev_cells, input_feed = self.get_cached_state( incremental_state ) elif encoder_out is not None: # setup recurrent cells prev_hiddens = [encoder_hiddens[i] for i in range(self.num_layers)] prev_cells = [encoder_cells[i] for i in range(self.num_layers)] if self.encoder_hidden_proj is not None: prev_hiddens = [self.encoder_hidden_proj(y) for y in prev_hiddens] prev_cells = [self.encoder_cell_proj(y) for y in prev_cells] input_feed = x.new_zeros(bsz, self.hidden_size) else: # setup zero cells, since there is no encoder zero_state = x.new_zeros(bsz, self.hidden_size) prev_hiddens = [zero_state for i in range(self.num_layers)] prev_cells = [zero_state for i in range(self.num_layers)] input_feed = None assert ( srclen > 0 or self.attention is None ), "attention is not supported if there are no encoder outputs" attn_scores: Optional[Tensor] = ( x.new_zeros(srclen, seqlen, bsz) if self.attention is not None else None ) outs = [] for j in range(seqlen): # input feeding: concatenate context vector from previous time step if input_feed is not None: input = torch.cat((x[j, :, :], input_feed), dim=1) else: input = x[j] for i, rnn in enumerate(self.layers): # recurrent cell hidden, cell = rnn(input, (prev_hiddens[i], prev_cells[i])) # hidden state becomes the input to the next layer input = self.dropout_out_module(hidden) if self.residuals: input = input + prev_hiddens[i] # save state for next time step prev_hiddens[i] = hidden prev_cells[i] = cell # apply attention using the last layer's hidden state if self.attention is not None: assert attn_scores is not None out, attn_scores[:, j, :] = self.attention( hidden, encoder_outs, encoder_padding_mask ) else: out = hidden out = self.dropout_out_module(out) # input feeding if input_feed is not None: input_feed = out # save final output outs.append(out) # Stack all the necessary tensors together and store prev_hiddens_tensor = torch.stack(prev_hiddens) prev_cells_tensor = torch.stack(prev_cells) cache_state = torch.jit.annotate( Dict[str, Optional[Tensor]], { "prev_hiddens": prev_hiddens_tensor, "prev_cells": prev_cells_tensor, "input_feed": input_feed, }, ) self.set_incremental_state(incremental_state, "cached_state", cache_state) # collect outputs across time steps x = torch.cat(outs, dim=0).view(seqlen, bsz, self.hidden_size) # T x B x C -> B x T x C x = x.transpose(1, 0) if hasattr(self, "additional_fc") and self.adaptive_softmax is None: x = self.additional_fc(x) x = self.dropout_out_module(x) # srclen x tgtlen x bsz -> bsz x tgtlen x srclen if not self.training and self.need_attn and self.attention is not None: assert attn_scores is not None attn_scores = attn_scores.transpose(0, 2) else: attn_scores = None return x, attn_scores def output_layer(self, x): """Project features to the vocabulary size.""" if self.adaptive_softmax is None: if self.share_input_output_embed: x = F.linear(x, self.embed_tokens.weight) else: x = self.fc_out(x) return x def get_cached_state( self, incremental_state: Dict[str, Dict[str, Optional[Tensor]]], ) -> Tuple[List[Tensor], List[Tensor], Optional[Tensor]]: cached_state = self.get_incremental_state(incremental_state, "cached_state") assert cached_state is not None prev_hiddens_ = cached_state["prev_hiddens"] assert prev_hiddens_ is not None prev_cells_ = cached_state["prev_cells"] assert prev_cells_ is not None prev_hiddens = [prev_hiddens_[i] for i in range(self.num_layers)] prev_cells = [prev_cells_[j] for j in range(self.num_layers)] input_feed = cached_state[ "input_feed" ] # can be None for decoder-only language models return prev_hiddens, prev_cells, input_feed def reorder_incremental_state( self, incremental_state: Dict[str, Dict[str, Optional[Tensor]]], new_order: Tensor, ): if incremental_state is None or len(incremental_state) == 0: return prev_hiddens, prev_cells, input_feed = self.get_cached_state(incremental_state) prev_hiddens = [p.index_select(0, new_order) for p in prev_hiddens] prev_cells = [p.index_select(0, new_order) for p in prev_cells] if input_feed is not None: input_feed = input_feed.index_select(0, new_order) cached_state_new = torch.jit.annotate( Dict[str, Optional[Tensor]], { "prev_hiddens": torch.stack(prev_hiddens), "prev_cells": torch.stack(prev_cells), "input_feed": input_feed, }, ) self.set_incremental_state(incremental_state, "cached_state", cached_state_new), return def max_positions(self): """Maximum output length supported by the decoder.""" return self.max_target_positions def make_generation_fast_(self, need_attn=False, **kwargs): self.need_attn = need_attn def Embedding(num_embeddings, embedding_dim, padding_idx): m = nn.Embedding(num_embeddings, embedding_dim, padding_idx=padding_idx) nn.init.uniform_(m.weight, -0.1, 0.1) nn.init.constant_(m.weight[padding_idx], 0) return m def LSTM(input_size, hidden_size, **kwargs): m = nn.LSTM(input_size, hidden_size, **kwargs) for name, param in m.named_parameters(): if "weight" in name or "bias" in name: param.data.uniform_(-0.1, 0.1) return m def LSTMCell(input_size, hidden_size, **kwargs): m = nn.LSTMCell(input_size, hidden_size, **kwargs) for name, param in m.named_parameters(): if "weight" in name or "bias" in name: param.data.uniform_(-0.1, 0.1) return m def Linear(in_features, out_features, bias=True, dropout=0.0): """Linear layer (input: N x T x C)""" m = nn.Linear(in_features, out_features, bias=bias) m.weight.data.uniform_(-0.1, 0.1) if bias: m.bias.data.uniform_(-0.1, 0.1) return m @register_model_architecture("lstm", "lstm") def base_architecture(args): args.dropout = getattr(args, "dropout", 0.1) args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 512) args.encoder_embed_path = getattr(args, "encoder_embed_path", None) args.encoder_freeze_embed = getattr(args, "encoder_freeze_embed", False) args.encoder_hidden_size = getattr( args, "encoder_hidden_size", args.encoder_embed_dim ) args.encoder_layers = getattr(args, "encoder_layers", 1) args.encoder_bidirectional = getattr(args, "encoder_bidirectional", False) args.encoder_dropout_in = getattr(args, "encoder_dropout_in", args.dropout) args.encoder_dropout_out = getattr(args, "encoder_dropout_out", args.dropout) args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 512) args.decoder_embed_path = getattr(args, "decoder_embed_path", None) args.decoder_freeze_embed = getattr(args, "decoder_freeze_embed", False) args.decoder_hidden_size = getattr( args, "decoder_hidden_size", args.decoder_embed_dim ) args.decoder_layers = getattr(args, "decoder_layers", 1) args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 512) args.decoder_attention = getattr(args, "decoder_attention", "1") args.decoder_dropout_in = getattr(args, "decoder_dropout_in", args.dropout) args.decoder_dropout_out = getattr(args, "decoder_dropout_out", args.dropout) args.share_decoder_input_output_embed = getattr( args, "share_decoder_input_output_embed", False ) args.share_all_embeddings = getattr(args, "share_all_embeddings", False) args.adaptive_softmax_cutoff = getattr( args, "adaptive_softmax_cutoff", "10000,50000,200000" ) @register_model_architecture("lstm", "lstm_wiseman_iwslt_de_en") def lstm_wiseman_iwslt_de_en(args): args.dropout = getattr(args, "dropout", 0.1) args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 256) args.encoder_dropout_in = getattr(args, "encoder_dropout_in", 0) args.encoder_dropout_out = getattr(args, "encoder_dropout_out", 0) args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 256) args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 256) args.decoder_dropout_in = getattr(args, "decoder_dropout_in", 0) args.decoder_dropout_out = getattr(args, "decoder_dropout_out", args.dropout) base_architecture(args) @register_model_architecture("lstm", "lstm_luong_wmt_en_de") def lstm_luong_wmt_en_de(args): args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 1000) args.encoder_layers = getattr(args, "encoder_layers", 4) args.encoder_dropout_out = getattr(args, "encoder_dropout_out", 0) args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 1000) args.decoder_layers = getattr(args, "decoder_layers", 4) args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 1000) args.decoder_dropout_out = getattr(args, "decoder_dropout_out", 0) base_architecture(args)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
- 648
- 649
- 650
- 651
- 652
- 653
- 654
- 655
- 656
- 657
- 658
- 659
- 660
- 661
- 662
- 663
- 664
- 665
- 666
- 667
- 668
- 669
- 670
- 671
- 672
- 673
- 674
- 675
- 676
- 677
- 678
- 679
- 680
- 681
- 682
- 683
- 684
- 685
- 686
- 687
- 688
- 689
- 690
- 691
- 692
- 693
- 694
- 695
- 696
- 697
- 698
- 699
- 700
- 701
- 702
- 703
- 704
- 705
- 706
- 707
- 708
- 709
- 710
- 711
- 712
- 713
- 714
- 715
- 716
- 717
- 718
- 719
- 720
- 721
- 722
- 723
- 724
- 725
- 726
- 727
- 728
- 729
- 730
- 731
- 732
- 733
- 734
- 735
- 736
- 737
- 738
- 739
- 740
- 741
- 742
- 743
- 744
- 745
- 746
- 747
- 748
- 749
- 750
- 751
- 752
- 753
- 754
- 755
- 756
1.5、基于卷积神经网络的深度神经网络模型
如前所述,编码解码模型在如机器翻译这种序列到序列任务上得到了很好的效果,很长一段时间内,模型的基本神经元都由LSTM或GRU主宰。但循环神经单元也有其固有的问题,尤其是时间消耗高、计算效率低。一些学者们发现,人类在处理语言理解时,小范围的语序混乱并不妨碍语义的理解。因此,是否能使用更高效的并行处理单元来替换严格时序的循环神经单元成为研究热点。
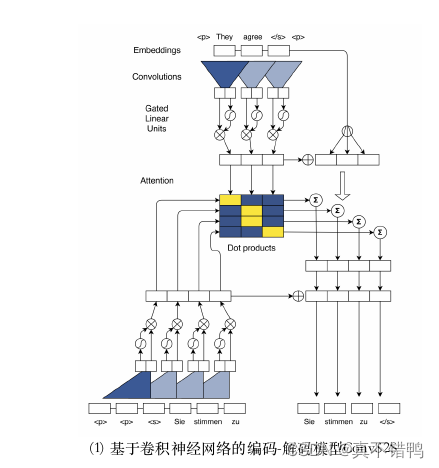
此前的并行处理模型受限于自然语言生成时的自回归方案,仅仅将卷积神经网络应用到编码器端。Gehring等人出了ConvS2S模型,这是一个解码器编码器均建立在卷积神经网络结构上的模型,如图所示。这个模型采用了由Dauphin等人出的门控线性单元(Gated Linear Units,GLU)来并行化建模标记之间的关系,如下式所示:
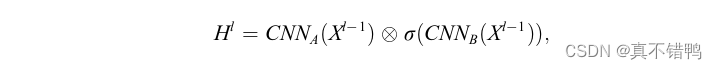
即对输入文本X进行两次卷积操作,其中卷积B操作使用sigmoid函数进行非线性激活,因此输出可以看作是经过一次门控后的数据,由卷积B决定卷积A中的数据哪些可以流入下一层。采用了门控线性单元的ConvS2S模型证明,在一个卷积核感受野范围内的标记无序并不会影响对一整句话语义的理解。并且,根据卷积神经网络的特点,长距离标记之间的关系可以由堆叠卷积层来达到。例如,堆叠6卷积核为5的卷积层,就能捕获到25个标记之间的关系.因此,序列到序列的问题完全可以由并行化程度更高的卷积神经网络来完成。
1.5.1、CNN(fconv)模型代码
由fairseq工具箱提供
# Copyright (c) Facebook, Inc. and its affiliates. # # This source code is licensed under the MIT license found in the # LICENSE file in the root directory of this source tree. import math import torch import torch.nn as nn import torch.nn.functional as F from fairseq import utils from fairseq.models import ( FairseqEncoder, FairseqEncoderDecoderModel, FairseqIncrementalDecoder, register_model, register_model_architecture, ) from fairseq.modules import ( AdaptiveSoftmax, BeamableMM, FairseqDropout, GradMultiply, LearnedPositionalEmbedding, LinearizedConvolution, ) @register_model("fconv") class FConvModel(FairseqEncoderDecoderModel): """ A fully convolutional model, i.e. a convolutional encoder and a convolutional decoder, as described in `"Convolutional Sequence to Sequence Learning" (Gehring et al., 2017) <https://arxiv.org/abs/1705.03122>`_. Args: encoder (FConvEncoder): the encoder decoder (FConvDecoder): the decoder The Convolutional model provides the following named architectures and command-line arguments: .. argparse:: :ref: fairseq.models.fconv_parser :prog: """ @classmethod def hub_models(cls): def moses_subword(path): return { "path": path, "tokenizer": "moses", "bpe": "subword_nmt", } return { "conv.wmt14.en-fr": moses_subword( "https://dl.fbaipublicfiles.com/fairseq/models/wmt14.v2.en-fr.fconv-py.tar.bz2" ), "conv.wmt14.en-de": moses_subword( "https://dl.fbaipublicfiles.com/fairseq/models/wmt14.en-de.fconv-py.tar.bz2" ), "conv.wmt17.en-de": moses_subword( "https://dl.fbaipublicfiles.com/fairseq/models/wmt17.v2.en-de.fconv-py.tar.bz2" ), } def __init__(self, encoder, decoder): super().__init__(encoder, decoder) self.encoder.num_attention_layers = sum( layer is not None for layer in decoder.attention ) @staticmethod def add_args(parser): """Add model-specific arguments to the parser.""" # fmt: off parser.add_argument('--dropout', type=float, metavar='D', help='dropout probability') parser.add_argument('--encoder-embed-dim', type=int, metavar='N', help='encoder embedding dimension') parser.add_argument('--encoder-embed-path', type=str, metavar='STR', help='path to pre-trained encoder embedding') parser.add_argument('--encoder-layers', type=str, metavar='EXPR', help='encoder layers [(dim, kernel_size), ...]') parser.add_argument('--decoder-embed-dim', type=int, metavar='N', help='decoder embedding dimension') parser.add_argument('--decoder-embed-path', type=str, metavar='STR', help='path to pre-trained decoder embedding') parser.add_argument('--decoder-layers', type=str, metavar='EXPR', help='decoder layers [(dim, kernel_size), ...]') parser.add_argument('--decoder-out-embed-dim', type=int, metavar='N', help='decoder output embedding dimension') parser.add_argument('--decoder-attention', type=str, metavar='EXPR', help='decoder attention [True, ...]') parser.add_argument('--share-input-output-embed', action='store_true', help='share input and output embeddings (requires' ' --decoder-out-embed-dim and --decoder-embed-dim' ' to be equal)') # fmt: on @classmethod def build_model(cls, args, task): """Build a new model instance.""" # make sure that all args are properly defaulted (in case there are any new ones) base_architecture(args) encoder_embed_dict = None if args.encoder_embed_path: encoder_embed_dict = utils.parse_embedding(args.encoder_embed_path) utils.print_embed_overlap(encoder_embed_dict, task.source_dictionary) decoder_embed_dict = None if args.decoder_embed_path: decoder_embed_dict = utils.parse_embedding(args.decoder_embed_path) utils.print_embed_overlap(decoder_embed_dict, task.target_dictionary) encoder = FConvEncoder( dictionary=task.source_dictionary, embed_dim=args.encoder_embed_dim, embed_dict=encoder_embed_dict, convolutions=eval(args.encoder_layers), dropout=args.dropout, max_positions=args.max_source_positions, ) decoder = FConvDecoder( dictionary=task.target_dictionary, embed_dim=args.decoder_embed_dim, embed_dict=decoder_embed_dict, convolutions=eval(args.decoder_layers), out_embed_dim=args.decoder_out_embed_dim, attention=eval(args.decoder_attention), dropout=args.dropout, max_positions=args.max_target_positions, share_embed=args.share_input_output_embed, ) return FConvModel(encoder, decoder) class FConvEncoder(FairseqEncoder): """ Convolutional encoder consisting of `len(convolutions)` layers. Args: dictionary (~fairseq.data.Dictionary): encoding dictionary embed_dim (int, optional): embedding dimension embed_dict (str, optional): filename from which to load pre-trained embeddings max_positions (int, optional): maximum supported input sequence length convolutions (list, optional): the convolutional layer structure. Each list item `i` corresponds to convolutional layer `i`. Layers are given as ``(out_channels, kernel_width, [residual])``. Residual connections are added between layers when ``residual=1`` (which is the default behavior). dropout (float, optional): dropout to be applied before each conv layer """ def __init__( self, dictionary, embed_dim=512, embed_dict=None, max_positions=1024, convolutions=((512, 3),) * 20, dropout=0.1, ): super().__init__(dictionary) self.dropout_module = FairseqDropout( dropout, module_name=self.__class__.__name__ ) self.num_attention_layers = None num_embeddings = len(dictionary) self.padding_idx = dictionary.pad() self.embed_tokens = Embedding(num_embeddings, embed_dim, self.padding_idx) if embed_dict: self.embed_tokens = utils.load_embedding( embed_dict, self.dictionary, self.embed_tokens ) self.embed_positions = PositionalEmbedding( max_positions, embed_dim, self.padding_idx, ) convolutions = extend_conv_spec(convolutions) in_channels = convolutions[0][0] self.fc1 = Linear(embed_dim, in_channels, dropout=dropout) self.projections = nn.ModuleList() self.convolutions = nn.ModuleList() self.residuals = [] layer_in_channels = [in_channels] for _, (out_channels, kernel_size, residual) in enumerate(convolutions): if residual == 0: residual_dim = out_channels else: residual_dim = layer_in_channels[-residual] self.projections.append( Linear(residual_dim, out_channels) if residual_dim != out_channels else None ) if kernel_size % 2 == 1: padding = kernel_size // 2 else: padding = 0 self.convolutions.append( ConvTBC( in_channels, out_channels * 2, kernel_size, dropout=dropout, padding=padding, ) ) self.residuals.append(residual) in_channels = out_channels layer_in_channels.append(out_channels) self.fc2 = Linear(in_channels, embed_dim) def forward(self, src_tokens, src_lengths): """ Args: src_tokens (LongTensor): tokens in the source language of shape `(batch, src_len)` src_lengths (LongTensor): lengths of each source sentence of shape `(batch)` Returns: dict: - **encoder_out** (tuple): a tuple with two elements, where the first element is the last encoder layer's output and the second element is the same quantity summed with the input embedding (used for attention). The shape of both tensors is `(batch, src_len, embed_dim)`. - **encoder_padding_mask** (ByteTensor): the positions of padding elements of shape `(batch, src_len)` """ # embed tokens and positions x = self.embed_tokens(src_tokens) + self.embed_positions(src_tokens) x = self.dropout_module(x) input_embedding = x # project to size of convolution x = self.fc1(x) # used to mask padding in input encoder_padding_mask = src_tokens.eq(self.padding_idx).t() # -> T x B if not encoder_padding_mask.any(): encoder_padding_mask = None # B x T x C -> T x B x C x = x.transpose(0, 1) residuals = [x] # temporal convolutions for proj, conv, res_layer in zip( self.projections, self.convolutions, self.residuals ): if res_layer > 0: residual = residuals[-res_layer] residual = residual if proj is None else proj(residual) else: residual = None if encoder_padding_mask is not None: x = x.masked_fill(encoder_padding_mask.unsqueeze(-1), 0) x = self.dropout_module(x) if conv.kernel_size[0] % 2 == 1: # padding is implicit in the conv x = conv(x) else: padding_l = (conv.kernel_size[0] - 1) // 2 padding_r = conv.kernel_size[0] // 2 x = F.pad(x, (0, 0, 0, 0, padding_l, padding_r)) x = conv(x) x = F.glu(x, dim=2) if residual is not None: x = (x + residual) * math.sqrt(0.5) residuals.append(x) # T x B x C -> B x T x C x = x.transpose(1, 0) # project back to size of embedding x = self.fc2(x) if encoder_padding_mask is not None: encoder_padding_mask = encoder_padding_mask.t() # -> B x T x = x.masked_fill(encoder_padding_mask.unsqueeze(-1), 0) # scale gradients (this only affects backward, not forward) x = GradMultiply.apply(x, 1.0 / (2.0 * self.num_attention_layers)) # add output to input embedding for attention y = (x + input_embedding) * math.sqrt(0.5) return { "encoder_out": (x, y), "encoder_padding_mask": encoder_padding_mask, # B x T } def reorder_encoder_out(self, encoder_out, new_order): if encoder_out["encoder_out"] is not None: encoder_out["encoder_out"] = ( encoder_out["encoder_out"][0].index_select(0, new_order), encoder_out["encoder_out"][1].index_select(0, new_order), ) if encoder_out["encoder_padding_mask"] is not None: encoder_out["encoder_padding_mask"] = encoder_out[ "encoder_padding_mask" ].index_select(0, new_order) return encoder_out def max_positions(self): """Maximum input length supported by the encoder.""" return self.embed_positions.max_positions class AttentionLayer(nn.Module): def __init__(self, conv_channels, embed_dim, bmm=None): super().__init__() # projects from output of convolution to embedding dimension self.in_projection = Linear(conv_channels, embed_dim) # projects from embedding dimension to convolution size self.out_projection = Linear(embed_dim, conv_channels) self.bmm = bmm if bmm is not None else torch.bmm def forward(self, x, target_embedding, encoder_out, encoder_padding_mask): residual = x # attention x = (self.in_projection(x) + target_embedding) * math.sqrt(0.5) x = self.bmm(x, encoder_out[0]) # don't attend over padding if encoder_padding_mask is not None: x = ( x.float() .masked_fill(encoder_padding_mask.unsqueeze(1), float("-inf")) .type_as(x) ) # FP16 support: cast to float and back # softmax over last dim sz = x.size() x = F.softmax(x.view(sz[0] * sz[1], sz[2]), dim=1) x = x.view(sz) attn_scores = x x = self.bmm(x, encoder_out[1]) # scale attention output (respecting potentially different lengths) s = encoder_out[1].size(1) if encoder_padding_mask is None: x = x * (s * math.sqrt(1.0 / s)) else: s = s - encoder_padding_mask.type_as(x).sum( dim=1, keepdim=True ) # exclude padding s = s.unsqueeze(-1) x = x * (s * s.rsqrt()) # project back x = (self.out_projection(x) + residual) * math.sqrt(0.5) return x, attn_scores def make_generation_fast_(self, beamable_mm_beam_size=None, **kwargs): """Replace torch.bmm with BeamableMM.""" if beamable_mm_beam_size is not None: del self.bmm self.add_module("bmm", BeamableMM(beamable_mm_beam_size)) class FConvDecoder(FairseqIncrementalDecoder): """Convolutional decoder""" def __init__( self, dictionary, embed_dim=512, embed_dict=None, out_embed_dim=256, max_positions=1024, convolutions=((512, 3),) * 20, attention=True, dropout=0.1, share_embed=False, positional_embeddings=True, adaptive_softmax_cutoff=None, adaptive_softmax_dropout=0.0, ): super().__init__(dictionary) self.register_buffer("version", torch.Tensor([2])) self.dropout_module = FairseqDropout( dropout, module_name=self.__class__.__name__ ) self.need_attn = True convolutions = extend_conv_spec(convolutions) in_channels = convolutions[0][0] if isinstance(attention, bool): # expand True into [True, True, ...] and do the same with False attention = [attention] * len(convolutions) if not isinstance(attention, list) or len(attention) != len(convolutions): raise ValueError( "Attention is expected to be a list of booleans of " "length equal to the number of layers." ) num_embeddings = len(dictionary) padding_idx = dictionary.pad() self.embed_tokens = Embedding(num_embeddings, embed_dim, padding_idx) if embed_dict: self.embed_tokens = utils.load_embedding( embed_dict, self.dictionary, self.embed_tokens ) self.embed_positions = ( PositionalEmbedding( max_positions, embed_dim, padding_idx, ) if positional_embeddings else None ) self.fc1 = Linear(embed_dim, in_channels, dropout=dropout) self.projections = nn.ModuleList() self.convolutions = nn.ModuleList() self.attention = nn.ModuleList() self.residuals = [] layer_in_channels = [in_channels] for i, (out_channels, kernel_size, residual) in enumerate(convolutions): if residual == 0: residual_dim = out_channels else: residual_dim = layer_in_channels[-residual] self.projections.append( Linear(residual_dim, out_channels) if residual_dim != out_channels else None ) self.convolutions.append( LinearizedConv1d( in_channels, out_channels * 2, kernel_size, padding=(kernel_size - 1), dropout=dropout, ) ) self.attention.append( AttentionLayer(out_channels, embed_dim) if attention[i] else None ) self.residuals.append(residual) in_channels = out_channels layer_in_channels.append(out_channels) self.adaptive_softmax = None self.fc2 = self.fc3 = None if adaptive_softmax_cutoff is not None: assert not share_embed self.adaptive_softmax = AdaptiveSoftmax( num_embeddings, in_channels, adaptive_softmax_cutoff, dropout=adaptive_softmax_dropout, ) else: self.fc2 = Linear(in_channels, out_embed_dim) if share_embed: assert out_embed_dim == embed_dim, ( "Shared embed weights implies same dimensions " " out_embed_dim={} vs embed_dim={}".format(out_embed_dim, embed_dim) ) self.fc3 = nn.Linear(out_embed_dim, num_embeddings) self.fc3.weight = self.embed_tokens.weight else: self.fc3 = Linear(out_embed_dim, num_embeddings, dropout=dropout) def forward( self, prev_output_tokens, encoder_out=None, incremental_state=None, **unused ): if encoder_out is not None: encoder_padding_mask = encoder_out["encoder_padding_mask"] encoder_out = encoder_out["encoder_out"] # split and transpose encoder outputs encoder_a, encoder_b = self._split_encoder_out( encoder_out, incremental_state ) if self.embed_positions is not None: pos_embed = self.embed_positions(prev_output_tokens, incremental_state) else: pos_embed = 0 if incremental_state is not None: prev_output_tokens = prev_output_tokens[:, -1:] x = self._embed_tokens(prev_output_tokens, incremental_state) # embed tokens and combine with positional embeddings x += pos_embed x = self.dropout_module(x) target_embedding = x # project to size of convolution x = self.fc1(x) # B x T x C -> T x B x C x = self._transpose_if_training(x, incremental_state) # temporal convolutions avg_attn_scores = None num_attn_layers = len(self.attention) residuals = [x] for proj, conv, attention, res_layer in zip( self.projections, self.convolutions, self.attention, self.residuals ): if res_layer > 0: residual = residuals[-res_layer] residual = residual if proj is None else proj(residual) else: residual = None x = self.dropout_module(x) x = conv(x, incremental_state) x = F.glu(x, dim=2) # attention if attention is not None: x = self._transpose_if_training(x, incremental_state) x, attn_scores = attention( x, target_embedding, (encoder_a, encoder_b), encoder_padding_mask ) if not self.training and self.need_attn: attn_scores = attn_scores / num_attn_layers if avg_attn_scores is None: avg_attn_scores = attn_scores else: avg_attn_scores.add_(attn_scores) x = self._transpose_if_training(x, incremental_state) # residual if residual is not None: x = (x + residual) * math.sqrt(0.5) residuals.append(x) # T x B x C -> B x T x C x = self._transpose_if_training(x, incremental_state) # project back to size of vocabulary if not using adaptive softmax if self.fc2 is not None and self.fc3 is not None: x = self.fc2(x) x = self.dropout_module(x) x = self.fc3(x) return x, avg_attn_scores def reorder_incremental_state(self, incremental_state, new_order): super().reorder_incremental_state(incremental_state, new_order) encoder_out = utils.get_incremental_state( self, incremental_state, "encoder_out" ) if encoder_out is not None: encoder_out = tuple(eo.index_select(0, new_order) for eo in encoder_out) utils.set_incremental_state( self, incremental_state, "encoder_out", encoder_out ) def max_positions(self): """Maximum output length supported by the decoder.""" return ( self.embed_positions.max_positions if self.embed_positions is not None else float("inf") ) def upgrade_state_dict(self, state_dict): if utils.item(state_dict.get("decoder.version", torch.Tensor([1]))[0]) < 2: # old models use incorrect weight norm dimension for i, conv in enumerate(self.convolutions): # reconfigure weight norm nn.utils.remove_weight_norm(conv) self.convolutions[i] = nn.utils.weight_norm(conv, dim=0) state_dict["decoder.version"] = torch.Tensor([1]) return state_dict def make_generation_fast_(self, need_attn=False, **kwargs): self.need_attn = need_attn def _embed_tokens(self, tokens, incremental_state): if incremental_state is not None: # keep only the last token for incremental forward pass tokens = tokens[:, -1:] return self.embed_tokens(tokens) def _split_encoder_out(self, encoder_out, incremental_state): """Split and transpose encoder outputs. This is cached when doing incremental inference. """ cached_result = utils.get_incremental_state( self, incremental_state, "encoder_out" ) if cached_result is not None: return cached_result # transpose only once to speed up attention layers encoder_a, encoder_b = encoder_out encoder_a = encoder_a.transpose(1, 2).contiguous() result = (encoder_a, encoder_b) if incremental_state is not None: utils.set_incremental_state(self, incremental_state, "encoder_out", result) return result def _transpose_if_training(self, x, incremental_state): if incremental_state is None: x = x.transpose(0, 1) return x def extend_conv_spec(convolutions): """ Extends convolutional spec that is a list of tuples of 2 or 3 parameters (kernel size, dim size and optionally how many layers behind to look for residual) to default the residual propagation param if it is not specified """ extended = [] for spec in convolutions: if len(spec) == 3: extended.append(spec) elif len(spec) == 2: extended.append(spec + (1,)) else: raise Exception( "invalid number of parameters in convolution spec " + str(spec) + ". expected 2 or 3" ) return tuple(extended) def Embedding(num_embeddings, embedding_dim, padding_idx): m = nn.Embedding(num_embeddings, embedding_dim, padding_idx=padding_idx) nn.init.normal_(m.weight, 0, 0.1) nn.init.constant_(m.weight[padding_idx], 0) return m def PositionalEmbedding(num_embeddings, embedding_dim, padding_idx): m = LearnedPositionalEmbedding(num_embeddings, embedding_dim, padding_idx) nn.init.normal_(m.weight, 0, 0.1) nn.init.constant_(m.weight[padding_idx], 0) return m def Linear(in_features, out_features, dropout=0.0): """Weight-normalized Linear layer (input: N x T x C)""" m = nn.Linear(in_features, out_features) nn.init.normal_(m.weight, mean=0, std=math.sqrt((1 - dropout) / in_features)) nn.init.constant_(m.bias, 0) return nn.utils.weight_norm(m) def LinearizedConv1d(in_channels, out_channels, kernel_size, dropout=0.0, **kwargs): """Weight-normalized Conv1d layer optimized for decoding""" m = LinearizedConvolution(in_channels, out_channels, kernel_size, **kwargs) std = math.sqrt((4 * (1.0 - dropout)) / (m.kernel_size[0] * in_channels)) nn.init.normal_(m.weight, mean=0, std=std) nn.init.constant_(m.bias, 0) return nn.utils.weight_norm(m, dim=2) def ConvTBC(in_channels, out_channels, kernel_size, dropout=0.0, **kwargs): """Weight-normalized Conv1d layer""" from fairseq.modules import ConvTBC m = ConvTBC(in_channels, out_channels, kernel_size, **kwargs) std = math.sqrt((4 * (1.0 - dropout)) / (m.kernel_size[0] * in_channels)) nn.init.normal_(m.weight, mean=0, std=std) nn.init.constant_(m.bias, 0) return nn.utils.weight_norm(m, dim=2) @register_model_architecture("fconv", "fconv") def base_architecture(args): args.dropout = getattr(args, "dropout", 0.1) args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 512) args.encoder_embed_path = getattr(args, "encoder_embed_path", None) args.encoder_layers = getattr(args, "encoder_layers", "[(512, 3)] * 20") args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 512) args.decoder_embed_path = getattr(args, "decoder_embed_path", None) args.decoder_layers = getattr(args, "decoder_layers", "[(512, 3)] * 20") args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 256) args.decoder_attention = getattr(args, "decoder_attention", "True") args.share_input_output_embed = getattr(args, "share_input_output_embed", False) @register_model_architecture("fconv", "fconv_iwslt_de_en") def fconv_iwslt_de_en(args): args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 256) args.encoder_layers = getattr(args, "encoder_layers", "[(256, 3)] * 4") args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 256) args.decoder_layers = getattr(args, "decoder_layers", "[(256, 3)] * 3") args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 256) base_architecture(args) @register_model_architecture("fconv", "fconv_wmt_en_ro") def fconv_wmt_en_ro(args): args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 512) base_architecture(args) @register_model_architecture("fconv", "fconv_wmt_en_de") def fconv_wmt_en_de(args): convs = "[(512, 3)] * 9" # first 9 layers have 512 units convs += " + [(1024, 3)] * 4" # next 4 layers have 1024 units convs += " + [(2048, 1)] * 2" # final 2 layers use 1x1 convolutions args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 768) args.encoder_layers = getattr(args, "encoder_layers", convs) args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 768) args.decoder_layers = getattr(args, "decoder_layers", convs) args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 512) base_architecture(args) @register_model_architecture("fconv", "fconv_wmt_en_fr") def fconv_wmt_en_fr(args): convs = "[(512, 3)] * 6" # first 6 layers have 512 units convs += " + [(768, 3)] * 4" # next 4 layers have 768 units convs += " + [(1024, 3)] * 3" # next 3 layers have 1024 units convs += " + [(2048, 1)] * 1" # next 1 layer uses 1x1 convolutions convs += " + [(4096, 1)] * 1" # final 1 layer uses 1x1 convolutions args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 768) args.encoder_layers = getattr(args, "encoder_layers", convs) args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 768) args.decoder_layers = getattr(args, "decoder_layers", convs) args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 512) base_architecture(args)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
- 648
- 649
- 650
- 651
- 652
- 653
- 654
- 655
- 656
- 657
- 658
- 659
- 660
- 661
- 662
- 663
- 664
- 665
- 666
- 667
- 668
- 669
- 670
- 671
- 672
- 673
- 674
- 675
- 676
- 677
- 678
- 679
- 680
- 681
- 682
- 683
- 684
- 685
- 686
- 687
- 688
- 689
- 690
- 691
- 692
- 693
- 694
- 695
- 696
- 697
- 698
- 699
- 700
- 701
- 702
- 703
- 704
- 705
- 706
- 707
- 708
- 709
- 710
- 711
- 712
- 713
- 714
- 715
- 716
- 717
- 718
- 719
- 720
- 721
- 722
- 723
- 724
- 725
- 726
- 727
- 728
- 729
- 730
- 731
- 732
- 733
- 734
- 735
- 736
- 737
- 738
- 739
- 740
- 741
- 742
- 743
- 744
- 745
- 746
- 747
- 748
- 749
- 750
- 751
- 752
- 753
- 754
- 755
- 756
- 757

