
- 1ngrok验证auth_使用Auth0可以轻松进行React身份验证
- 2用flutter实现类似startActivityForResult和onActivityResult功能
- 3Python字符串和列表相互转换_python 列表字符串转列表
- 4Cache -Control缓存_iis cache control
- 5探索UML类图:软件建模的关键概念和Visual Paradigm的优势
- 6跑得好好的Java进程,怎么突然就瘫痪了?
- 7Stata中一些令人困扰的易错函数——sum()和total()_stata total函数
- 82024年甘肃省职业院校技能大赛信息安全管理与评估任务书卷①—网络安全渗透、理论技能与职业素养_漏洞发现 学习 素质目标
- 9数据资产入表及估值实践与操作指南、中国数据交易市场研究分析报告(2023年)、数据交易PDCA模型、数据交易安全港白皮书、数据要素市场发展指数2023、全国数商产业发展报告2023、全球数据跨境流动
- 10【PTA】【数据结构与算法】队列_循环顺序队列中是否可以插入下一个元素
数据仓库相关概念_tmp ods dw
赞
踩
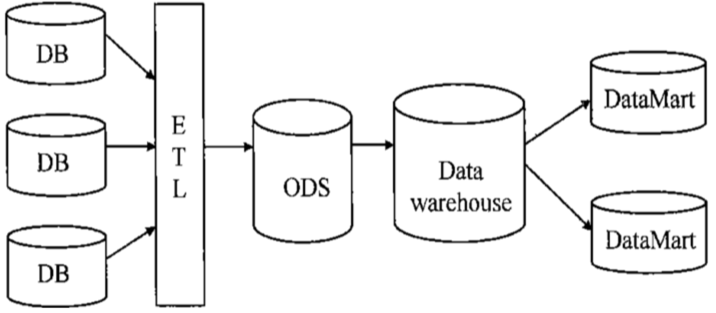
数据仓库的整理架构,各个系统的元数据通过ETL同步到操作性数据仓库ODS中,对ODS数据进行面向主题域建模形成DW(数据仓库),DM是针对某一个业务领域建立模型,具体用户(决策层)查看DM生成的报表。



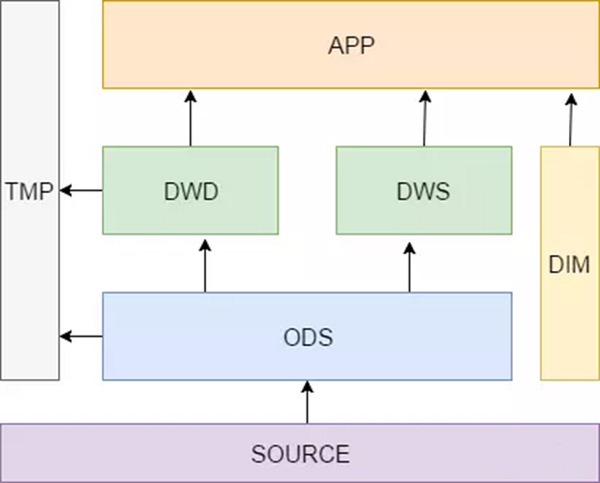
- 数据明细层 DWD(Data Warehouse Detail):这一层主要解决一些数据质量问题和数据的完整度问题。比如用户的资料信息来自于很多不同表,而且经常出现延迟丢数据等问题,为了方便各个使用方更好的使用数据,我们可以在这一层做一个屏蔽。DWD 主要是对 ODS 层做一些数据清洗和规范化的操作,DWS主要是对 ODS 层数据做一些轻度的汇总。
- 数据中间层 DWM(Data WareHouse Middle):可看作中间过渡层。轻度综合层与DWD的主要区别在于二者的应用领域不同,DWD的数据来源于生产型系统,并未满意一些不可预见的需求而进行沉淀;轻度综合层则面向分析型应用进行细粒度的统计和沉淀
- 数据服务层 / 主题层 DWS(Data WareHouse Servce):从ODS层中对用户的行为做一个初步的汇总,抽象出来一些通用的维度:时间、ip、id,并根据这些维度做一些统计值,比如用户每个时间段在不同登录ip购买的商品数等。这里做一层轻度的汇总会让计算更加的高效,在此基础上如果计算仅7天、30天、90天的行为的话会快很多。我们希望80%的业务都能通过我们的DWS层计算,而不是ODS。
-
维表层(Dimension):比如国家代码和国家名、地理位置、中文名、国旗图片等信息就存在DIM层中。主要包含两部分数据:
高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
-
TMP:每一层的计算都会有很多临时表,专设一个DWTMP层来存储我们数据仓库的临时表。
-
应用层(APP):
数据产品层(APP),这一层是提供为数据产品使用的结果数据。
主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、Mysql 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。
如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
-
概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql中使用。
-
数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。
-
日志存储方式:使用impala内表,parquet文件格式。
-
日志删除方式:长久存储。
-
表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
-
库与表命名。库名:暂定apl,另外根据业务不同,不限定一定要一个库。(其实就叫app_)就好了
-
旧数据更新方式:直接覆盖。
-
-
数仓思维图
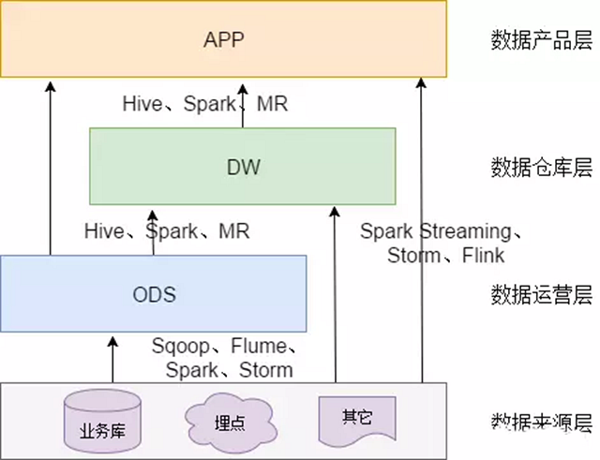


数据主要会有两个大的来源:
业务库,这里经常会使用 Sqoop 来抽取
我们业务库用的是databus来进行接收,处理kafka就好了。
在实时方面,可以考虑用 Canal 监听 Mysql 的 Binlog,实时接入即可。(有机会补一下这个canal)
埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用 Flume 定时抽取,也可以用用 Spark Streaming 或者 Storm 来实时接入,当然,Kafka 也会是一个关键的角色。
还有使用filebeat收集日志,打到kafka,然后处理日志
注意: 在这层,理应不是简单的数据接入,而是要考虑一定的数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等,一般这些很容易会被忽略,但是却至关重要。特别是后期我们做各种特征自动生成的时候,会十分有用。
- 每日定时任务型:比如我们典型的日计算任务,每天凌晨算前一天的数据,早上起来看报表。 这种任务经常使用 Hive、Spark 或者生撸 MR 程序来计算,最终结果写入 Hive、Hbase、Mysql、Es 或者 Redis 中。
- 实时数据:这部分主要是各种实时的系统使用,比如我们的实时推荐、实时用户画像,一般我们会用 Spark Streaming、Storm 或者 Flink 来计算,最后会落入 Es、Hbase 或者 Redis 中。

