
- 1成为比开发硬气的测试人,我都经历了什么?_大佬说开发和测试吵架
- 2kylin os auditd问题解决_audit-3.0-5.se.08.ky10
- 3HarmonyOS 应用开发之ExtensionAbility组件(2),阿里P7大牛亲自教你
- 4学业水平考试网登录_2019山东高中学业水平考试报名系统入口http://xysp.sdzk.cn
- 5路径规划:基于kinodynamic的路径搜索
- 6如何使用python来进行回归分析_python 回归分析
- 7云计算文献综述
- 8【EduCoder实训答案】二维数组_根据提示,在右侧编辑器 begin-end 区间补充代码,根据定义好的结构体类型,依次输出 6 个结
- 9Spring boot和Flink整合_springboot整合flink
- 10PHICOMM(斐讯)N1盒子 - Armbian5.77(Debian 9)配置自动连接WIFI无线网络_n1 armbian wifi
OpenAI全新发布的Sora,究竟厉害在哪里?
赞
踩
最近爆火的sora模型究竟是何方神圣?
作为OpenAI的新一代产品,让我们先来问问它的大哥GPT-4:

看来做大哥的消息确实灵通,不妨让我们去Sora的官网一探究竟。
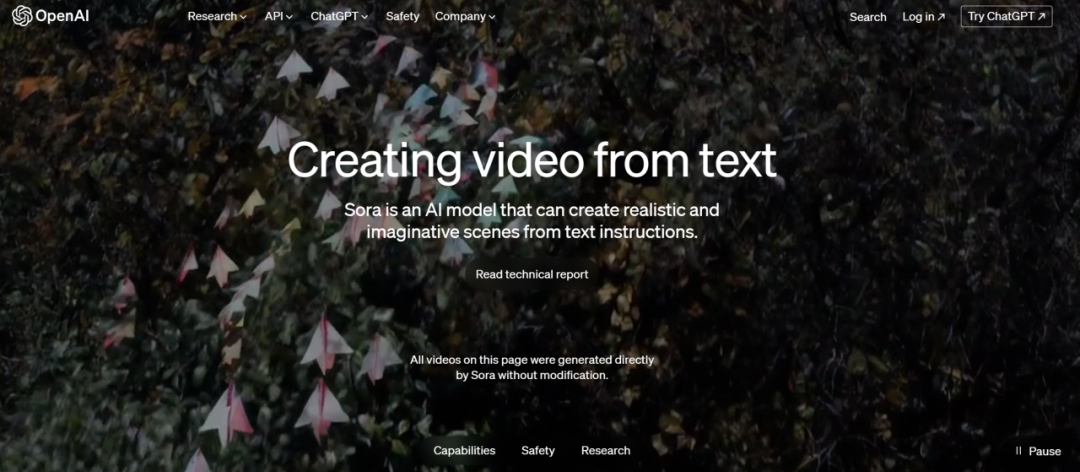
进入sora的官网,映入眼帘的就是Sora的个人简介,来让GPT-4重新认识一下小弟:

看来,Sora是一种利用文本生成视频的AI模型。但是在众多AI模型中,为什么只有Sora火出圈了?Sora究竟厉害在哪里?

下面让我们一起来阅读一下Sora的技术报告:

标题就是:作为世界模拟器的视频生成模型。
换句话说,Sora模型可以通过生成虚拟视频,来模拟现实世界中的各种情境、场景和事件,是不是还挺科幻的,有点意思!

接着我们来看看摘要:
该研究尝试在大量视频数据上训练视频生成模型。他们使用了不同长度、分辨率和长宽比的视频和图像来共同训练一种名为“文本条件扩散模型”的模型。
他们使用了一种名为Transformer的架构来处理视频和图像的潜在代码。他们最大的模型名为Sora,能够生成一分钟的高质量视频。研究结果表明,扩展视频生成模型是建立通用物理世界模拟器的一个很有前途的方法。

我们先简单地理解一下这段话,看完下面的视频或许会有更深的理解和思考。
先来看一下最近刷屏的一段视频,根据下面这段文本生成:“一位时尚的女士走在东京的街道上,街道上充满了温暖的霓虹灯和生动的城市标志。她穿着黑色皮夹克、红色长裙和黑色靴子,手里拿着一个黑色钱包。她戴着太阳镜和红色口红。她走路自信而随意。街道潮湿且反光,形成了彩色灯光的镜面效果。许多行人走来走去。”
可以看出来,这段长达一分钟的高清视频几乎完美呈现了文字中所描述的内容!
视频中不仅有多角度的镜头,分镜切换也符合逻辑。视频中的女人在移动时,与后面的街道背景一直保持高度稳定和流畅;而且视频中对光影反射、运动方式、镜头移动等细节都处理得更好,让观众看起来跟真实拍摄的一样。
对比其他的AI模型,Pika是3秒,Runway是4秒,Sora生成的视频目前可以达到一分钟,可谓一骑绝尘,而且分辨率十分高,视频中基本物理现象也比较吻合,仿佛真的可以以假乱真!

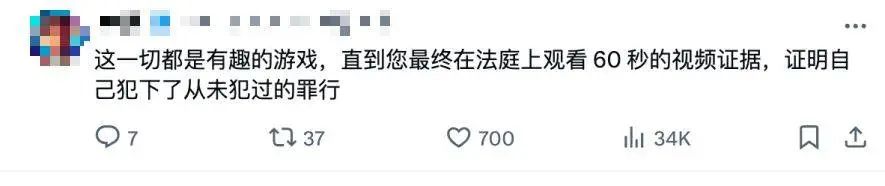
怪不得有网友担忧这样逼真的技术会被用来伪造视频,甚至被用来在法庭上作伪证:

但上面的视频没有展示出来Sora的全部实力,看完整个报告之后,小编确确实实地感觉到:“魔法”世界可能真的存在!
首先,根据OpenAI给出的这篇非完全技术报告,我们可以大致知道:Sora模型是怎么把文本转化为视频的。
简单来说,Sora整合了自家的GPT和DALL-E模型。其中,GPT-4就是基于Transformer架构的大型神经网络,目前在自然语言处理领域独树一帜,而最新的DALL-E 3是基于文本提示生成图像的图像生成模型。
Sora使用了DALL·E 3中的重新标注技术,准备了大量带有文本标题的视频数据,通过训练一个高度描述性的标题模型,为所有视频生成文本标题,来提高文本准确性,改善了视频质量。同时,Sora利用GPT将用户简短的提示转化为更长、更详细的标题,指导视频的生成过程,从而使Sora能够生成高质量的视频,并准确地遵循用户的指示。
比如下面的案例:

根据横线上的文本提示词,Sora可以连接成一段完整的话,或者增加相关的语义信息,从而生成下面的视频:
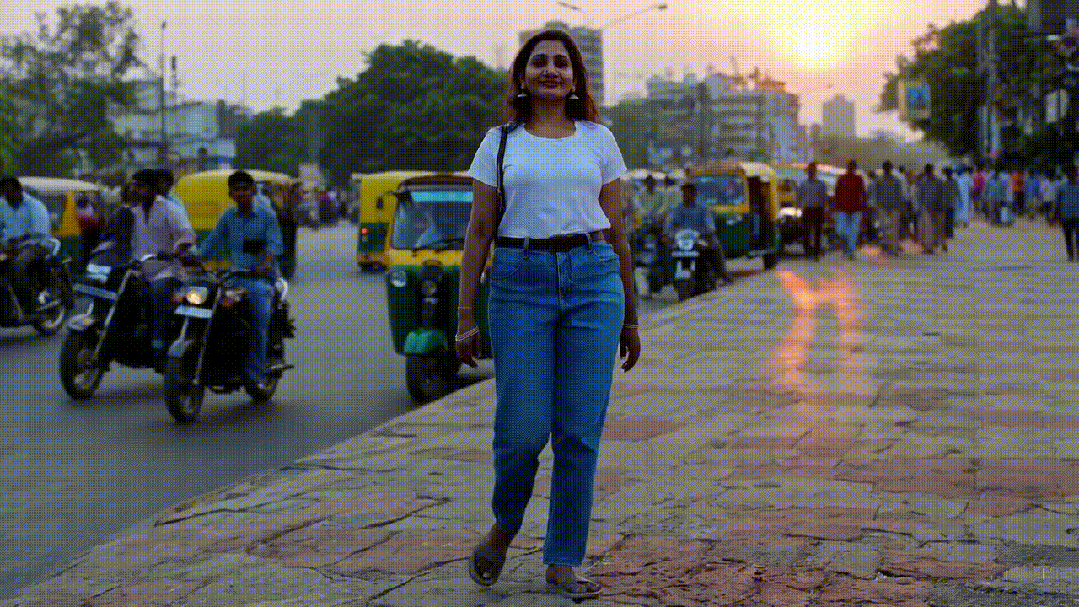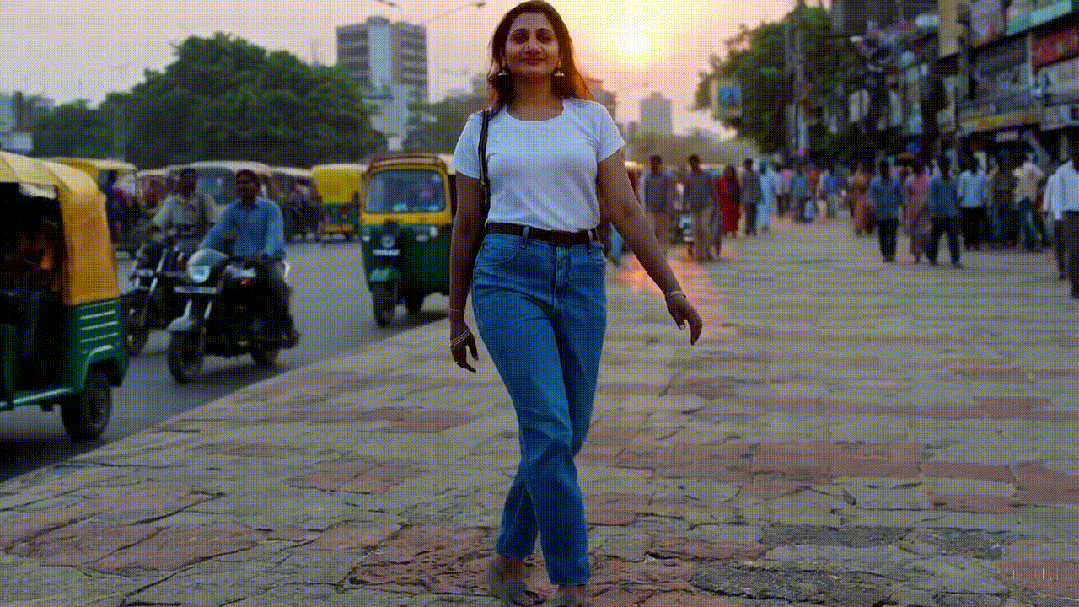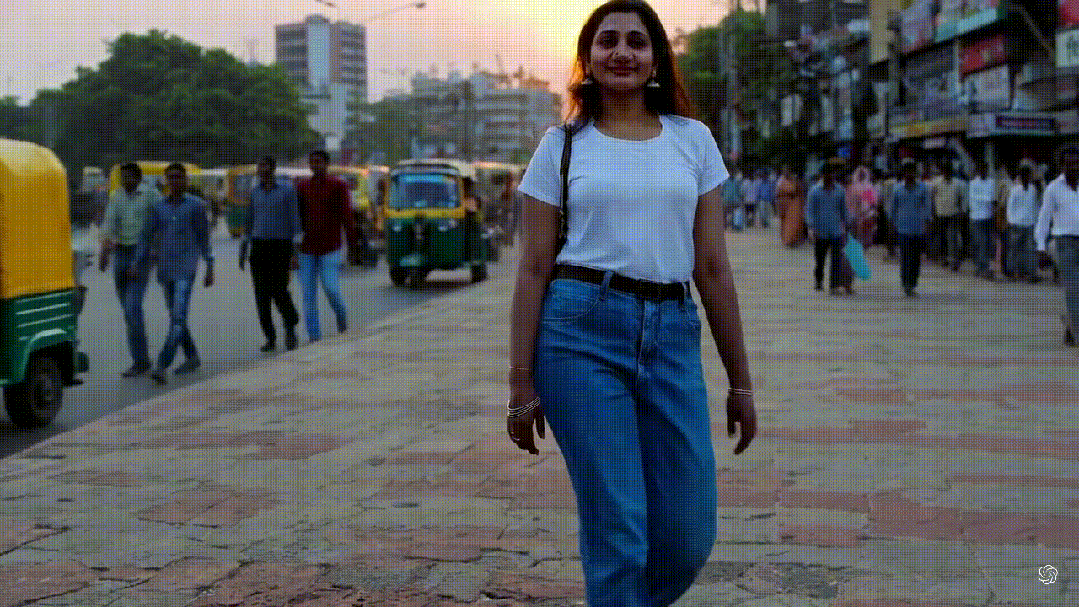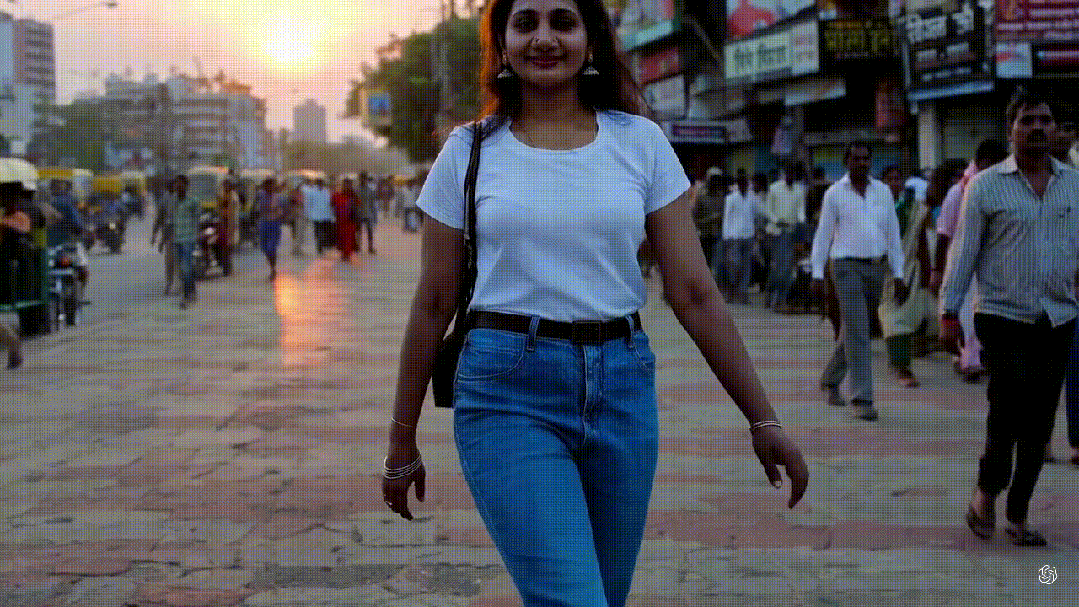
这视频真的是看不出什么毛病啊,连女生的面部表情都有点惟妙惟肖了。
除了从文本到视频,Sora还可以使用其他输入格式进行提示,比如图像,或视频。
比如将静态图像转换为动画,下面是:一只穿着贝雷帽和黑色高领衫的柴犬 。
。

我们输入这张图片,就可以让狗狗动起来。
是不是在哪儿见过,《哈利波特》里面,墙壁画像里的人可以活过来和人类互动,或者是神奇的魔法报纸,照片上的人物能动起来。
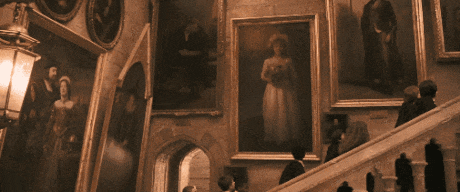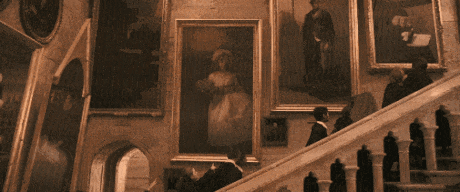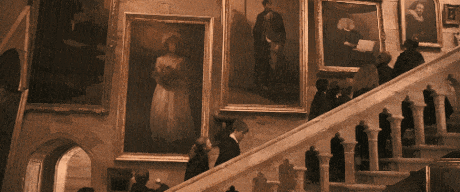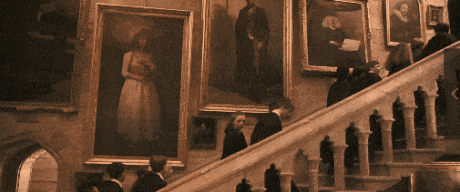
以前以为麻瓜的世界不可能看到魔法,现在有了Sora,加上最近的Vision Pro,让照片里的人重获新生,也不再只是一句玩笑话了。
再比如下面的照片:“在一座华丽的、历史悠久的大厅中,一股巨大的海啸达到了顶峰,并开始下降。两名冲浪者抓住机会,熟练地驾驶着浪头。”

如果只是静态的图片可能无法重现当时的紧张感,换成视频,可就真的代入感十足了。
除了照片输入,Sora还可以基于原视频来扩展视频,向前还是向后都可以。
下面的视频,是由一个视频片段向前扩展得到的。两个视频前面的两种情景,过渡到最后同一个原视频片段:
有趣的是,sora可以使用这种方法向前和向后扩展视频,生成一个无缝的无限循环。比如下面的环山骑行,你根本无法分清哪里是片头还是片尾。


这还没完,Sora下面的功能,才是真的让视频从业者汗流浃背。
Sora利用SDEdit技术,可以零样本地转换输入视频的风格和环境,进而编辑视频!
比如下面的案例,可以对主题内容(赛车,跑道),环境背景,风格等元素进行替换。
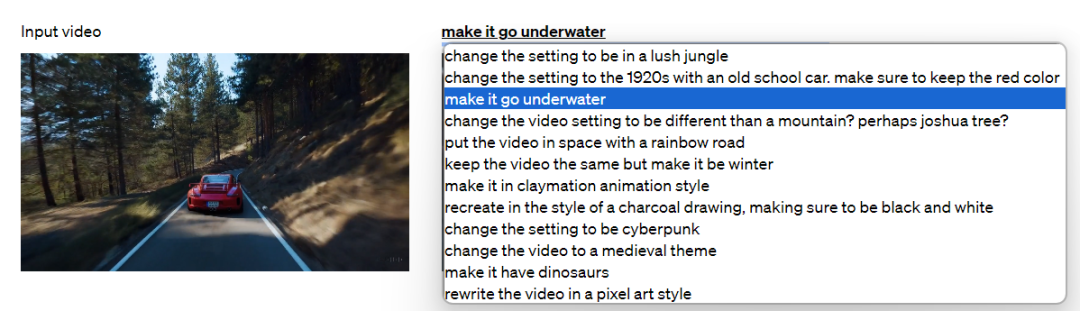
我们选中“让视频变成水下驾驶”,看一下效果:
不仅是视频编辑,Sora还可以在完全不同的主题和场景之间创建无缝的转场。虽然还没那么丝滑,但是这脑洞和技术,已经可以让视频小白直接上手了。
从编辑,到转场,震惊小编的是,Sora竟然会自己运镜“拍电影”,属实是力大砖飞,类似于前面的“东京女人”视频,Sora还可以模拟摄像机视角,比如航拍的运镜,由远及近,环绕拍摄等等拍摄技巧,保证人物和场景元素在三维空间中移动一致。
此外,Sora生成的视频具有长距离的一致性和物体永恒性。换句人话就是:可以在人、动物和物体被遮挡或离开画面时保持它们的持续存在,比如:当路人经过时,下面的狗狗一直完整地存在视频中。同样,可以在单个样本中生成同一角色的多个镜头,保持他们在整个视频中的外观。
甚至,视频中可以存在类似于真实世界的互动。例如,一位画家可以在画布上留下持续一段时间的新笔触,这真的看不出来是真画师还是假画师了。

类似于DALL-E,作为三维的视频生成模型的Sora也可以根据文本提示生成图像。
简直就是降维打击,Sora可以把照片的空间感塑造很逼真。
比如:一张女性的特写肖像,拍摄于秋季,呈现出极致的细节和浅景深。

这照片的质量,立省一套相机+大光圈镜头。加上AI换脸,足不出户就可以体验全世界拍大片,人像摄影直接get!
再比如下面的提示词:一幅雪山村庄的画面,温暖的小木屋和北极光在天空中舞动,采用高细节和逼真的单反相机拍摄,使用50mm f/1.2镜头。

u1s1,见过极光的都觉着你真见到极光了,属实有模有样,风光摄影顺便拿下。

不过,看完上述报告,震撼之余还有些小确幸(最后的一丝倔强了),身为物理专业的小编对Sora模型的原理虽然不是特别明白,但是Sora的物理好像学的也不是很好。
例如,它不能准确地模拟许多基本交互的物理现象,比如玻璃破碎。

还有一些基本的物理现象,目前Sora还无法准确地呈现。但是,Sora强大的视频生成模型已经足够颠覆了。连著名的五星上将麦克阿瑟都评论说:Sora,将给视频行业带来巨大的冲击!

总之,Sora通过对现实世界的学习,已经开始模拟人类去观察世界、描绘世界和表现世界。当有了足够的数据和算力,Sora可能会开始对现实世界的物理、因果关系和物体持久性有更深刻的理解。
借用大佬的评论:“Sora表面上是一个文生视频的工具,实际上是一个现实世界模拟器。它也不仅仅是用来模拟现实世界,它意味着通用人工智能对这个世界的理解能力又一次得到了突破。
GPT对人类语言和知识的理解达到了一个突破点,而除了人类的语言和这个世界的人类之间做交互的知识之外,这个世界还有很多规律,人工智能对物理世界的规律缺乏理解的话,那么它是残缺的,不可能真正变成通用人工智能。”
不仅是sora(现在还未对外完全开放),像GPT、DALL-E等生成式的AI产品已经在潜移默化地改变我们的生活、工作方式。
或许,每一个人都应该开始思考,AI如何更好地为我们服务,让AI变成我们的第三只手,助力我们的生活和工作。
所以,让我们拭目以待吧…
以上文本提示输入时,均是以英文的形式;
以上数据均源自OpenAI官方网站。
编辑:TT

我们是谁:
MatheMagician,中文“数学魔术师”,原指用数学设计魔术的魔术师和数学家。既取其用数学来变魔术的本义,也取像魔术一样玩数学的意思。文章内容涵盖互联网,计算机,统计,算法,NLP等前沿的数学及应用领域;也包括魔术思想,流程鉴赏等魔术内容;以及结合二者的数学魔术分享,还有一些思辨性的谈天说地的随笔。希望你能和我一起,既能感性思考又保持理性思维,享受人生乐趣。欢迎扫码关注和在文末或公众号留言与我交流!


扫描二维码
关注更多精彩
魔术《4 Kings 折纸》的三重境界(四)——魔术效果的突破

点击阅读原文,往期精彩不错过!

