
- 1软考计算机英语考题,《全国计算机软考网管英语试题及答案.doc
- 2利用Android Studio 上传项目到 github(1)
- 3Study--Oracle-02-单实例部署Oracle19C
- 4队列的顺序、链式表示与实现_1. 创建队列的接口。 2. 队列的顺序实现。 3. 队列的链式实现。 4. 用队列求解素
- 52020数据结构-图之基本概念_弧结点
- 6Java基于微信小程序+uniapp的校园失物招领小程序(V3.0)_使用的语言是java吗
- 7第五章(1.5)深度学习——卷积神经网络简介_权值共享隐含的原理则是什么?
- 8Python机器学习零基础理解K近邻算法_python k近邻 预测 趋势
- 9rabbitmq延时队列相关配置_rabbitmq x-delayed-message和topic
- 10Spark面试整理-Spark和Flink的区别
Stable Diffusion Windows本地部署超详细教程(手动+自动+整合包三种方式)_windows部署stable difussion
赞
踩
一、 Stable Diffusion简介
2022年作为AIGC(Artificial Intelligence Generated Content)时代的元年,各个领域的AIGC技术都有一个迅猛的发展,给工业界、学术界、投资界甚至竞赛界都注入了新的“AI活力”与“AI势能”。
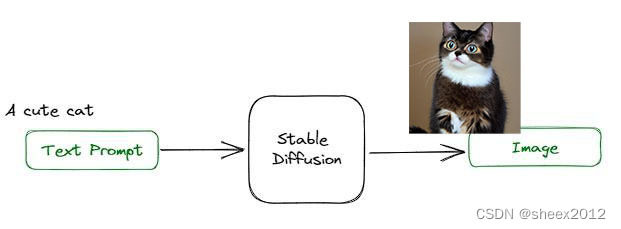
其中在AI绘画领域,Stable Diffusion当仁不让地成为了开源社区中持续繁荣的AI绘画核心模型,并且快速破圈,让AIGC的ToC可能性比肩移动互联网时代的产品,每个人都能感受到AI带来的力量与影响。Stable Diffusion由CompVis研究人员创建的主要用于文本生成图像的深度学习模型,与初创公司StabilityAI、Runway合作开发,并得到EleutherAI和LAION的支持,它主要用于根据文本的描述产生详细图像,也就是常说的txt2img的应用场景中:通过给定文本提示词(text prompt),该模型会输出一张匹配提示词的图片。例如输入文本提示词:A cute cat,Stable Diffusion会输出一张带有可爱猫咪的图片(如下图)。
Stable Diffusion(简称SD)是AI绘画领域的一个核心模型,与Midjourney不同的是,Stable Diffusion是一个完全开源的项目(模型、代码、训练数据、论文、生态等全部开源),可拓展性强、 出图效率高、 数据安全保障,这使得其能快速构建强大繁荣的上下游生态,并且吸引了越来越多的AI绘画爱好者加入其中,与AI行业从业者一起推动AIGC领域的发展与普惠。可以说,AI绘画的ToC普惠在AIGC时代的早期就已经显现,这是之前的传统深度学习时代从未有过的。
Stable Diffusion模型基于一个扩散过程,逐步从噪声中恢复出图像信息。在训练阶段,模型会学习如何逐步将噪声转化为真实的图像数据;而在生成阶段,模型则可以从随机噪声出发,通过反向的扩散过程,生成出与训练数据分布相似的图像。Stable Diffusion主要由变分自编码器(VAE)、U-Net和一个文本编码器三个部分组成。在前向扩散过程中,高斯噪声被迭代地应用于压缩的潜在表征。每个去噪步骤都由一个包含残差神经网络(ResNet)的U-Net架构完成,通过从前向扩散往反方向去噪而获得潜在表征。最后,VAE解码器通过将表征转换回像素空间来生成输出图像。

我们可以通过官方网站 Stability AI,以及Dream Studio、Replicate、Playground AI、Baseten等网站在线体验Stable Diffusion的巨大威力。但是,一方面国外的网站访问毕竟还是不方便(经常需要科学上网,你懂的),另一方面也不想让自己的一些“幼稚”想法被他们“窃取”。相比于集成在网络平台的SD或者其他AI绘画平台来说,自部署平台没有生成数量的限制,不用花钱,不用被NSFW约束,生成时间快,不用排队,自由度高,而且功能完整,插件丰富,可以调试和个性化的地方也更多;更稳定,也更容易让SD变成生产力或者商业化使用。既然这样,那就自力更生,在本机上自己部署一个,可以随心所欲地玩图、玩图...。
二、Stable Diffusion v2安装
1. 安装前的准备
现有深度学习训练和部署环境在硬件上一般基于Nvidia GPU,在底层需要显卡驱动和CUDA工具包(需要包含配套版本的cuDNN),在应用软件层面需要Python编译和解释器,以及基于Python的深度学习框架(如Pytorch、TensorFlow等)。同时,为了方便代码自动下载和程序模块化管理,通常还需要安装git和conda软件。笔者(Sheex2012)主机配备了RTX 4070Ti 12G显卡,并事先安装了CUDA 12.1,Python 3.11.6,git 2.44,Pytorch 2.1.2,能够满足Stable Diffusion环境要求。本文重点聚焦Stable Diffusion推理程序的部署,硬件需求确认和基础软件的安装这里不再赘述。
2. 下载和部署Stable Diffusion
我们从Stability.AI的github官方开源Stability.AI Stablediffusion下载源码:
git clone https://github.com/Stability-AI/stablediffusion.git当然,也可以从网页上以下载源码ZIP包,解压缩到本地。
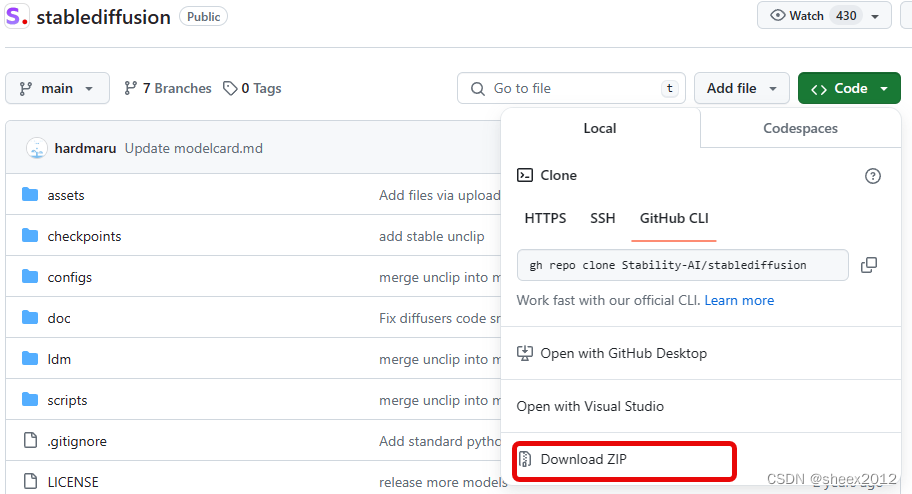
源码下载完成后,接下来需要安装项目的依赖项:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 然后从huggingface下载预训练模型v2-1_768-ema-pruned.ckpt,并存放到checkpoints文件夹中。
3. 运行Stable Diffusion
部署完成后,运行下述脚本,生成图片:
python ./scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt ./checkpoints/v2-1_768-ema-pruned.ckpt --config ./configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768可是,报错了:
No module named 'ldm'这个应该是目录结构的问题,将ldm拷贝/移动到script文件夹,再来一次,不出意外,还是有点小意外,内存不够了:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 9.49 GiB. GPU 0 has a total capacty of 11.99 GiB of which 0 bytes is free. Of the allocated memory 14.77 GiB is allocated by PyTorch, and 9.52 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF那就把图像的尺寸调整成512x512,问题解决了。

这是生成的图片(存放在outputs\txt2img-samples文件夹中):

三、 Stable Diffusion WebUI 安装
Stable Diffusion只是提供一个模型,提供基础的文本分析、特征提取、图片生成这些核心功能,但自身是没有可视化UI的,用起来就是各种文件加命令行。原始的Stable Diffusion程序(脚本)只能以命令行的方式进行,参数设置很不方便,而且每次调用时,需要事先加载预训练模型,图像生成完成后会释放内存中的模型并结束进程,运行效率低,交互操作极其麻烦。
开源的 Stable Diffusion 社区受到了广泛民间开发者大力支持,众多为爱发电的程序员自告奋勇的为其制作方便操控的 GUI 图形化界面。其中流传最广、功能最强也是被公认最为方便的,就是由越南超人 AUTOMATIC1111 开发的 WebUI,即大名鼎鼎的Stable Diffusion WebUI。可以看到github上的start已经超过130k了,真是神一样的存在。

PS,大神的头像直接使用了越南盾中胡志明头像。

Stable Diffusion WebUI集成了大量代码层面的繁琐应用,将 Stable Diffusion 的各项绘图参数转化成可视化的选项数值和操控按钮,用户可以直接通过 Web 页面使用 Stable Diffusion。如今各类开源社区里 90%以上的拓展应用都是基于它而研发的。
Stable Diffusion WebUI是一个最流行的开源 Stable Diffusion 整合程序,其核心功能是 文生图 和 图生图,这也是 Stable Diffusion 的核心能力。Stable Diffusion WebUI 的其它功能,比如ControlNet、高清放大、模型训练等等都是其它第三方开发的,有的已经内置到 WebUI 中,随着 WebUI 的发布而发布,有的还需要用户手动安装。
当然,除了 WebUI 还有一些其他的 GUI 应用,比如 ComfyUI 和 Vlad Diffusion 等,不过它们的应用场景更为专业和小众,感兴趣的可以点击下面的 GitHub 链接了解,这里就不再赘述了。
1. 手动安装
我们先手动方式一步一步安装,从中体验一下其中的繁琐(其实,这对于从事深度学习的相关技术人员来说是常规操作)。
首先,从github上下载源码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git其次,下载安装Stable Diffusion WebUI的依赖项:
- cd stable-diffusion-webui
- pip install -r requirements_versions.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

 依赖项成功安装后,还是从huggingface下载v1-5-pruned-emaonly.safetensors预训练模型,放置到models\Stable-diffusion文件夹。
依赖项成功安装后,还是从huggingface下载v1-5-pruned-emaonly.safetensors预训练模型,放置到models\Stable-diffusion文件夹。
好了,开始魔法吧。
python webui.py命令行窗口显示了模型加载运行过程,这里一共花了49.2秒。

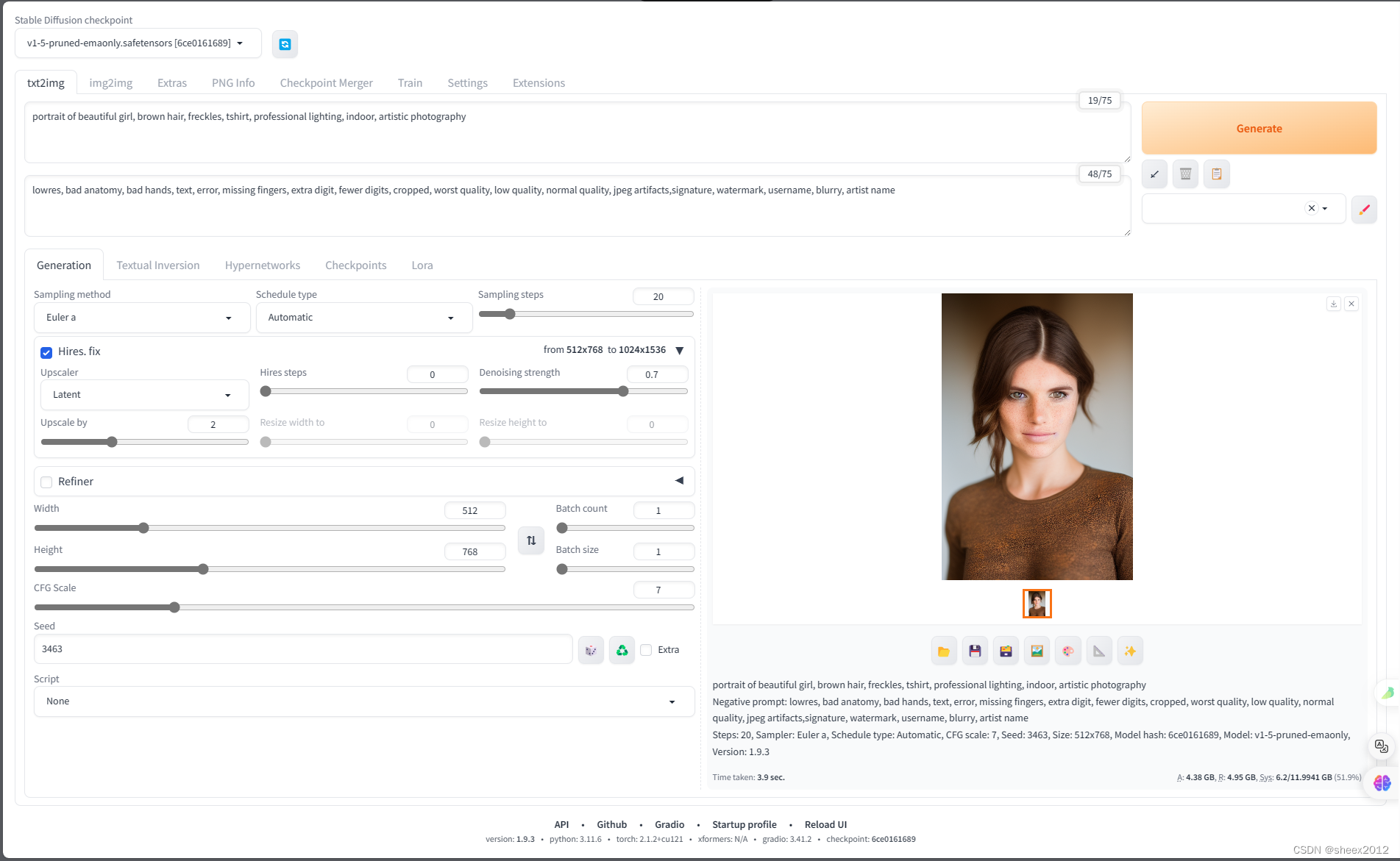
进入 http://127.0.0.1:7860网站,输入提示词:
portrait of beautiful girl, brown hair, freckles, tshirt, professional lighting, indoor, artistic photography反向提示词:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name点击,Generate按钮,3.9秒后,生成一幅女孩肖像画。GPU占用3.8G左右。

如果觉得全是英文的界面操作起来不够方便,可以:
1)从Stable-diffusion-webui 的汉化扩展下载汉化语言包,把"localizations"文件夹内的"Chinese-All.json"和"Chinese-English.json"复制到"stable-diffusion-webui\localizations"目录中;
2)点击"Settings",左侧点击"User interface"界面,在界面里最下方的"Localization (requires restart)",选择"Chinese-All"或者"Chinese-English";
3)点击界面最上方的黄色按钮"Apply settings",再点击右侧的"Reload UI"即可完成汉化。

不过,个人觉得汉化后的文字有点拥挤。
2. 自动安装
事实上,Stable Diffusion WebUI官方网站中不再有手动安装的步骤,我的理解是作者鼓励大家采用自动安装方式,而自动安装的确非常方便的。当我们下载完成Stable Diffusion WebUI源码后,在确保已经安装了Python 3.10.6和git后,双击批处理文件webui-user.bat即可。

从命令行窗口输出,我们看到,批处理命令自动下载安装了Pytorch等依赖项:

从github clone 并安装Clip Open_Clip等依赖程序,而且,由于众所周知的原因,从github clone 源码会经常报错:

没关系,接着多运行几遍即可。然后,再从 从huggingface下载预训练模型v1-5-pruned-emaonly.safetensors(当然,还是会报错):
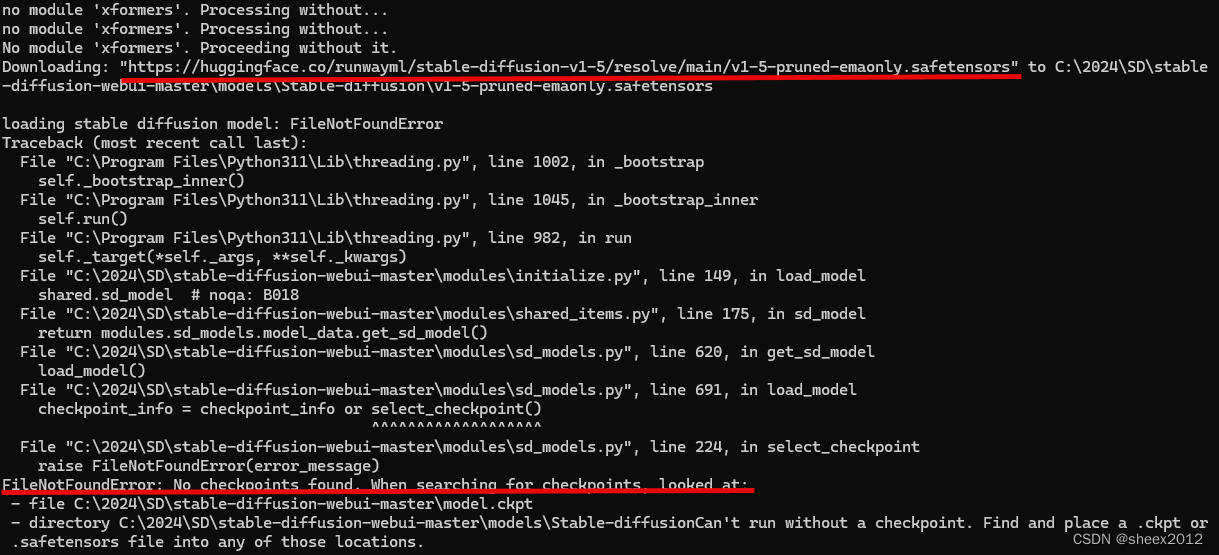
当所有的问题都解决之后,批处理文件webui-user.bat,将和前述的一样,将开放http://127.0.0.1:7860网站,后续处理过程不再赘述。

3. 自动安装过程分析
1) webui-user.bat 分析
自动安装和手动安装在结果上是没有区别的,都是下载源码、下载安装依赖项(包括二进制和github源码)、下载预训练模型,然后按照配置参数运行程序。自动安装过程把上述过程全部放到批处理文件中webui-user.bat,让我们来看看它到底做了啥。
- @echo off
-
- set PYTHON=
- set GIT=
- set VENV_DIR=
- set COMMANDLINE_ARGS=
-
- call webui.bat
webui-user.bat只有短短几行,首先将四个环境变量置空,然后调用webui.bat,所以webui.bat默默承担了所有。
2) webui.bat 简要分析
- 7. if not defined PYTHON (set PYTHON=python)
- 8. if defined GIT (set "GIT_PYTHON_GIT_EXECUTABLE=%GIT%")
- 9. if not defined VENV_DIR (set "VENV_DIR=%~dp0%venv")
首先,webui.bat在7-9行设置了PYTHON、GIT、VENV_DIR 三个环境变量,其中VENV_DIR 在当前目录中新建venv文件夹;其次,在16行测试调用Python程序;然后在第22行测试pip命令可用性。
- 16. %PYTHON% -c "" >tmp/stdout.txt 2>tmp/stderr.txt
- 17. if %ERRORLEVEL% == 0 goto :check_pip
- 18. echo Couldn't launch python
- 19. goto :show_stdout_stderr
- 21. :check_pip
- 22. %PYTHON% -mpip --help >tmp/stdout.txt 2>tmp/stderr.txt
- 23. if %ERRORLEVEL% == 0 goto :start_venv
接下来的37-40行是创建虚拟环境的关键,37行获得当前系统的缺省Python路径,39行利用 -m venv参数,运行此命令将创建目标目录venv,并使用home键将pyvenv.cfg文件放置在其中,该文件指向运行该命令的 Python 安装(目标目录的通用名称为.venv)。
- 37. for /f "delims=" %%i in ('CALL %PYTHON% -c "import sys; print(sys.executable)"') do set PYTHON_FULLNAME="%%i"
- 38. echo Creating venv in directory %VENV_DIR% using python %PYTHON_FULLNAME%
- 39. %PYTHON_FULLNAME% -m venv "%VENV_DIR%" >tmp/stdout.txt 2>tmp/stderr.txt
- 40. if %ERRORLEVEL% == 0 goto :activate_venv
基于venv的虚拟环境创建完成后,先激活该虚拟环境,再调用launch.py。至此,批处理文件的任务基本完成,并将控制权交给launch.py脚本。
- 44. :activate_venv
- 45. set PYTHON="%VENV_DIR%\Scripts\Python.exe"
- 46. echo venv %PYTHON%
-
-
- 57. :launch
- 58. %PYTHON% launch.py %*
3) launch.py 脚本简要分析
- start = launch_utils.start
-
-
- def main():
- if args.dump_sysinfo:
- filename = launch_utils.dump_sysinfo()
-
- print(f"Sysinfo saved as {filename}. Exiting...")
-
- exit(0)
-
- launch_utils.startup_timer.record("initial startup")
-
- with launch_utils.startup_timer.subcategory("prepare environment"):
- if not args.skip_prepare_environment:
- prepare_environment()
-
- if args.test_server:
- configure_for_tests()
-
- start()
-
-
- if __name__ == "__main__":
- main()

可以看到,有个prepare_environment函数,显然是它在负责环境初始化工作。
4) prepare_environment函数分析
- def prepare_environment():
- torch_index_url = os.environ.get('TORCH_INDEX_URL', "https://download.pytorch.org/whl/cu121")
- torch_command = os.environ.get('TORCH_COMMAND', f"pip install torch==2.1.2 torchvision==0.16.2 --extra-index-url {torch_index_url}")
-
- requirements_file = os.environ.get('REQS_FILE', "requirements_versions.txt")
-
- xformers_package = os.environ.get('XFORMERS_PACKAGE', 'xformers==0.0.23.post1')
- clip_package = os.environ.get('CLIP_PACKAGE', "https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip")
- openclip_package = os.environ.get('OPENCLIP_PACKAGE', "https://github.com/mlfoundations/open_clip/archive/bb6e834e9c70d9c27d0dc3ecedeebeaeb1ffad6b.zip")
-
- assets_repo = os.environ.get('ASSETS_REPO', "https://github.com/AUTOMATIC1111/stable-diffusion-webui-assets.git")
- stable_diffusion_repo = os.environ.get('STABLE_DIFFUSION_REPO', "https://github.com/Stability-AI/stablediffusion.git")
- stable_diffusion_xl_repo = os.environ.get('STABLE_DIFFUSION_XL_REPO', "https://github.com/Stability-AI/generative-models.git")
- k_diffusion_repo = os.environ.get('K_DIFFUSION_REPO', 'https://github.com/crowsonkb/k-diffusion.git')
- blip_repo = os.environ.get('BLIP_REPO', 'https://github.com/salesforce/BLIP.git')
-
- # 安装Pytorch
- if args.reinstall_torch or not is_installed("torch") or not is_installed("torchvision"):
- run(f'"{python}" -m {torch_command}', "Installing torch and torchvision", "Couldn't install torch", live=True)
-
- # 分别利用pip安装clip、open_clip、xformers、ngrok
- if not is_installed("clip"):
- run_pip(f"install {clip_package}", "clip")
-
- if not is_installed("open_clip"):
- run_pip(f"install {openclip_package}", "open_clip")
-
- if (not is_installed("xformers") or args.reinstall_xformers) and args.xformers:
- run_pip(f"install -U -I --no-deps {xformers_package}", "xformers")
-
- if not is_installed("ngrok") and args.ngrok:
- run_pip("install ngrok", "ngrok")
-
- os.makedirs(os.path.join(script_path, dir_repos), exist_ok=True)
-
- # 分别利用git安装assets、Stable Diffusion、Stable Diffusion XL、K-diffusion、BLIP
- git_clone(assets_repo, repo_dir('stable-diffusion-webui-assets'), "assets", assets_commit_hash)
- git_clone(stable_diffusion_repo, repo_dir('stable-diffusion-stability-ai'), "Stable Diffusion", stable_diffusion_commit_hash)
- git_clone(stable_diffusion_xl_repo, repo_dir('generative-models'), "Stable Diffusion XL", stable_diffusion_xl_commit_hash)
- git_clone(k_diffusion_repo, repo_dir('k-diffusion'), "K-diffusion", k_diffusion_commit_hash)
- git_clone(blip_repo, repo_dir('BLIP'), "BLIP", blip_commit_hash)
-
- startup_timer.record("clone repositores")
-
- # 利用pip安装requirements.txt文件指定的依赖项
- if not requirements_met(requirements_file):
- run_pip(f"install -r \"{requirements_file}\"", "requirements")
prepare_environment函数(上述代码是简化后的核心代码),基本上就是利用pip和git下载和安装依赖项(作者一直强调事先需要部署好git的原因就在这儿),和手动安装过程对应了起来。
四、 秋叶整合包安装
Stable Diffusion秋叶整合包是中国大神秋叶(bilibili@秋葉aaaki)基于Stable Diffusion WebUI内核开发的整合包,内置了与电脑本身系统隔离的Python环境和Git(包含了第三部分需要下载和安装的依赖项、github依赖包、预训练模型以及相当多的插件)。可以忽略网络需求和Python环境的门槛,让更多人轻松地使用Stable Diffusion WebUI。超简单一键安装,无任何使用门槛,完全免费使用,支持Nvdia全系列显卡,近期发布了Stable Diffusion整合包v4.8版本(整合包v4.8)。
1) 确认配置:
系统:Windows 10及以上系统
显卡:建议在本机安装Nvidia独立显卡,并且显存要达到6G以上,6G只能出图,如果要做训练建议12G以上。
2)下载文件
下载到本地,最好不要有中文目录,最新版下载链接: https://pan.quark.cn/s/2c832199b09b
3)点击“A绘世启动器”
4)点击“一键启动”

5)进入网站
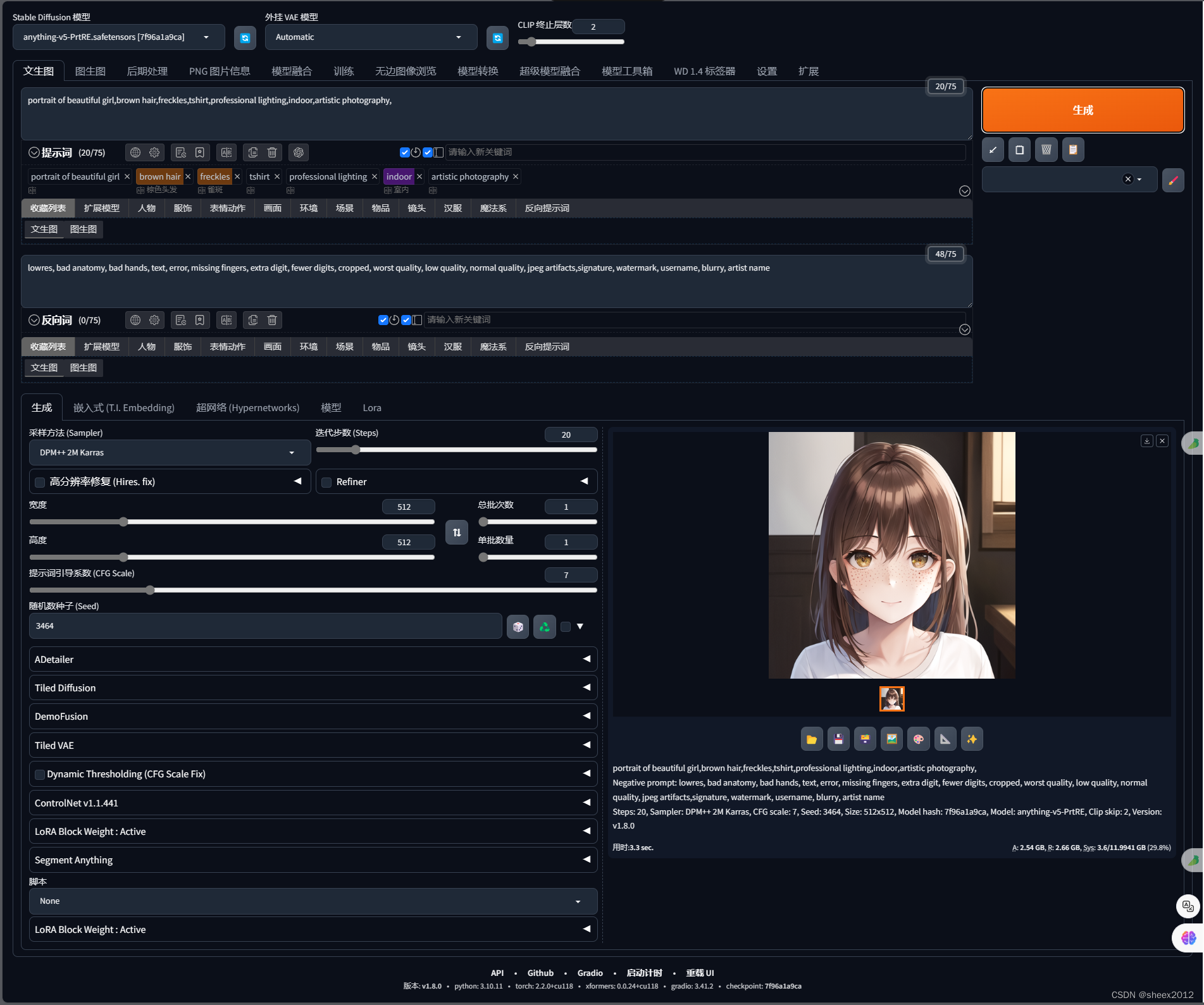
这个界面比原始的炫多了。我们看到了类似的命令行输出:

五、推理程序安装方式讨论
1. 整合包需要做什么
Python+深度学习框架是当前基于深度学习的训练和部署的主流模式,要在一台新的主机上部署推理模型,一般而言必须安装整套的软件框架、辅助工具包和相关的底层驱动,这使得这个过程非常繁琐。特别地,不同的(开源)软件往往依赖不同版本的软件包,而不同版本的软件包之间往往存在接口不兼容的问题,给软件运行带来不可估量的隐患。因此,虚拟环境成为Python环境的一个重要手段,这使得不同的软件版本可以互相隔离。
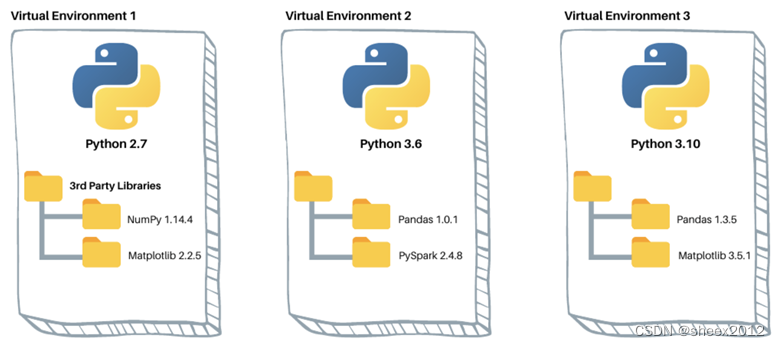
因此,要完整地安装一套基于深度学习的应用程序,通常来讲有虚拟环境创建、程序及依赖项下载安装、预训练模型等运行数据下载等重要步骤。对于一个从事深度学习的研究者来说,这些步骤不难,缺什么就补充安装什么。但对于普通的爱好者来说,这个过程就太过于复杂了,因此自动安装要把上述步骤全部在后台一步步下载安装和验证,建立起一个独立的虚拟运行环境;而整合包则更进一步,直接就是一个“绿色版”。
2. 为什么是Python3.10 ?
WebUI的作者AUTOMATIC1111在页面中,强调了Python的版本,需采用3.10.6版本,给出的理由是担心新版本的Python不支持Pytorch。

笔者的主机先前已经成功安装了Python 3.11.6和Pytorch 2.1.2,觉得作者的担心有点多余,就在主机环境中继续安装部署。

而且运行时,反正警告我们Python版本不兼容:

经过仔细比对,我们发现即便已经成功安装了xformers包,系统还是提示no module 'xformers',让我们颇感意外。

经分析,xformers依赖一个'triton'包:

而'triton'包没有编译好的适合于Windows的wheel,自然也就无法安装。而有人针对Python 3.10编译好好了一个版本,而这个包在Python 3.11版本下安装时失败的。我猜测,这可能是作者反复强调使用Python 3.10的原因。

六、小结
近年来,随着AIGC技术的飞速发展,深度学习模型的本地化部署和应用技术也得到了充分重视,各种一键式安装程序层出不穷,大大降低了模型的部署复杂性,进一步促进了AIGC的普惠应用。将虚拟环境创建、程序下载部署、数据下载部署等复杂过程一步步地串联起来,并将常用运行环节和数据整合成一体,实现一键直达,方便“小白”使用,成为一种流行而有效的方法。
本文仅仅安装部署了Stable Diffusion WebUI的主要成分,SDXL,以及其丰富的插件尚未涉及,后续一要将各个插件系统用起来,二要深入Stable Diffusion原理,并与Stable Diffusion使用结合,探索出更加有意思的东东。而对于具备极客精神的 AI 绘画爱好者来说,使用 Stable Diffusion 过程中可以学到很多关于模型技术的知识,理解了 Stable Diffusion 等于就掌握了 AI 绘画的精髓,可以更好的向下兼容其他任意一款低门槛的绘画工具。
参考文献
How to install Stable Diffusion on Windows


