
- 1js设计模式--观察者模式
- 2java forEach循环list、获取list中的指定数据_java foreach遍历集合并输出某一个特定值
- 3Electron上Macos平台的编译、签名和公证_electron 打dmg 如何进行签名和公证
- 4SequoiaDB分布式数据库2022.11月刊
- 5el-select下拉框只回显value不回显label的原因以及解决方法_el-select选择后不回显
- 6软件测试 | 人工智能:优势与挑战
- 7PostgreSQL教程
- 8百川智能发布 Baichuan 2,号称全面领先 LLaMA 2_百川2 7b微调显存
- 9java数字大小排序_怎么用java给数字排大小?
- 10多图详解VSCode搭建Java开发环境_vscode java开发
面试题整理_{"code":1,"message":"service codec unmarshal: unma
赞
踩
整理就是怕忘记,以后用来复习。如有错误,欢迎指正。
1、 ++1,1++
public class Test { public static void main(String[] args) { int i = 2; int k = ++i; // i=i+1=3 k=i=3 int t = i+ ++i + i++; // t = 3+(3+1)+4 //++i 已经对i加一操作 所以后面是4 ------计算完成后i再加1 System.out.println(i);// 5 System.out.println(k);// 3 System.out.println(t);// 11 System.out.println("***************"); int a = 2; int b = a++; int u = i+ ++i + i++; System.out.println(a);// 3 System.out.println(b);// 2 System.out.println(u);// 17 System.out.println("***************"); int e = 2; System.out.println(e++);// 2 System.out.println(e);// 3 System.out.println("***************"); int r = 2; System.out.println(++r);// 3 System.out.println(r);// 3 } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2、写一个Singleton实例
常用的设计模式之一-单例模式
整个类的系统中只能有一个实例对象可被获取和使用的代码模式
例如java运行的Rintime类
要点:
1:只能有一个实例:构造器的私有化
2:必须自行创建这个实例:含有一个该类的静态变量来保存这个唯一的实例
3:必须向整个系统提供这个实例:对外提供获取该实例对象的方式
恶汉式:都是线程安全的,在类初始化时直接创建这个对象
//最简单的单例模式:1 // ************************************************************** class Singleton1{ public static final Singleton1 INSTANCE = new Singleton1(); private Singleton1(){} } //枚举实现:2 // ************************************************************** enum Singleton2{ INSTANCE; } //静态代码块:3 // ************************************************************** class Singleton3{ public static final Singleton3 INSTANCE ; //如果类的构造器中有复杂的操作,比如从配置文件中读取属性值赋给构造器,可以使用静态代码块 static { INSTANCE = new Singleton3(); } private Singleton3(){} } //**************************************************************
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
懒汉式:延迟创建这个对象
//************************************************************** class Singleton4{ private static Singleton4 INSTANCE; private Singleton4(){} public Singleton4 getINSTANCE(){ if (INSTANCE == null){ synchronized (Singleton4.class){ //需要加锁保证线程安全 if (INSTANCE == null){ INSTANCE = new Singleton4(); } } } return INSTANCE; } } //***************************************************************** /** * 在内部类被加载和初始化时,才加载INSTANCE对象 * 静态内部类不会随着外部类的加载和初始化而初始化,而是调用的时候单独去加载和初始化的 * 线程安全的!!! */ class Singleton5{ private Singleton5(){} private static class Inner{ private static final Singleton5 INSTANCE = new Singleton5(); } public static Singleton5 getInstance(){ return Inner.INSTANCE; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
4、类实例化和实例初始化
父类的静态变量赋值和静态代码块的执行->子类的静态变量赋值和静态代码块的执行->父类的构造代码块的执行->父类的构造方法->子类的构造代码块执行->子类的构造方法->
class Animal{ public Animal(){ System.out.println("这是父类的--构造方法"); } { System.out.println("这是父类的--构造代码块"); } static { System.out.println("这是父类的--静态代码块"); } } class Cat extends Animal{ public Cat(){ System.out.println("这是子类--猫的--构造方法"); } { System.out.println("这是子类--猫的--构造代码块"); } static { System.out.println("这是子类--猫的--静态代码块"); } } class Dog extends Animal{ public Dog(){ System.out.println("这是子类--狗的--构造方法"); } { System.out.println("这是子类--狗的--构造代码块"); } static { System.out.println("这是子类--狗的--静态代码块"); } } public class Test1 { public static void main(String[] args) { Cat cat = new Cat(); Dog dog = new Dog(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
输出:
这是父类的--静态代码块
这是子类--猫的--静态代码块
这是父类的--构造代码块
这是父类的--构造方法
这是子类--猫的--构造代码块
这是子类--猫的--构造方法
这是子类--狗的--静态代码块
这是父类的--构造代码块
这是父类的--构造方法
这是子类--狗的--构造代码块
这是子类--狗的--构造方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5、Java 重写(Override)与重载(Overload)
public class OverLoad_override { /** * 重载(Overload) * 被重载的方法必须改变参数列表(参数个数或类型不一样); * 被重载的方法可以改变返回类型; * 被重载的方法可以改变访问修饰符; * 被重载的方法可以声明新的或更广的检查异常; * 方法能够在同一个类中或者在一个子类中被重载。 */ public int fun(int a){ return 1; } protected int fun(int a,int b){ // return a; } /** * 重写(Override) * 重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写! * 重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。 * * 参数列表必须完全与被重写方法的相同; * 返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类(java5 及更早版本返回类型要一样,java7 及更高版本可以不同); * 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。 * 父类的成员方法只能被它的子类重写。 * 声明为final的方法不能被重写。 * 声明为static的方法不能被重写,但是能够被再次声明。 */ class Son extends OverLoad_override{ @Override public int fun(int a) { return super.fun(a); } @Override // 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。 public int fun(int a, int b) { return super.fun(a, b); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
6、方法的参数传递机制
1、形参是基本数值类型:传递数据值
2、实参是引用数据类型:传递地址值
String、Integer等包装类对象不可变性
class MyData{ int a = 10; } public class Test { public static void main(String[] args) { int b = 1; Integer c = 1; String d = "hello"; int[] e = {1,2,3,4,5}; MyData myData = new MyData(); change(b,c,d,e,myData); System.out.println(b); // 1 System.out.println(c); // 1 System.out.println(d); // hello System.out.println(Arrays.toString(e)); //[9,2,3,4,5] System.out.println(myData.a);// 11 } private static void change(int b, Integer c, String d, int[] e, MyData myData) { b+=1; c+=1; d+="world"; e[0] = 9; myData.a += 1; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
输出:
1
1
hello
[9, 2, 3, 4, 5]
11
- 1
- 2
- 3
- 4
- 5
- 6
7、成员变量与局部变量的区别
-
1.
声明位置
- 局部变量:方法体中{},形参,代码块中{}中。
- 成员变量:类中方法外:类变量(static),实例变量。 2. 修饰符
- 局部变量:final
- 成员变量:public,protected,private,final.static,volatile,transient 3. 修饰符
- 局部变量:栈
- 实例变量:堆
- 类变量:方法区
public class Test1 { static int s; int i; int j; { int i = 1; i++; j++; s++; } public void test(int j){ j++; i++; s++; } public static void main(String[] args) { Test1 t1 = new Test1();// 构造代码块sij=000+101=101 Test1 t2 = new Test1();// 构造代码块sij=100+101=201 t1.test(10); //t1->test方法sij=201+110=311 t1.test(20); //t1->test方法sij=311+110=421 t2.test(30); //t2->test方法sij=401+110=511 -->此时静态变量s变为5->t1->sij=521 System.out.println(s+" "+t1.i+" "+t1.j); System.out.println(s+" "+t2.i+" "+t2.j); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
输出
5 2 1
5 1 1
- 1
- 2
- 3
8、Spring Bean的作用域
| 类型 | 说明 |
|---|---|
| singleton | 在spring IOC容器中仅存在一个Bean实例,Bean以单例的模式存在 |
| prototype | 每次调用getBean()都会返回一个新的实例 |
| request | 每次HTTP请求都会创建一个新的Bean,该作用域仅适用于WebApplicationContext环境 |
| session | 同一个HTTP Session 共享一个Bean,不同的HTTP Session使用不同的Bean, 该作用域仅适用于WebApplicationContext环境 |
9、Spring支持的常用数据库事物传播属性和事物隔离级别
| 事物传播属性 Propagation | 解释 |
|---|---|
| Propagation.REQUIRED(required)默认 | 支持当前事务,如果当前有事务, 那么加入事务, 如果当前没有事务则新建一个(默认情况) |
| Propagation.NOT_SUPPORTED(not_supported) | 以非事务方式执行操作,如果当前存在事务就把当前事务挂起,执行完后恢复事务(忽略当前事务); |
| Propagation.SUPPORTS (supports) | 如果当前有事务则加入,如果没有则不用事务。 |
| Propagation.MANDATORY (mandatory) | 支持当前事物,如果当前没有事务,则抛出异常。(当前必须有事务) |
| PROPAGATION_NEVER (never) | 以非事务方式执行,如果当前存在事务,则抛出异常。(当前必须不能有事务) |
| Propagation.REQUIRES_NEW (requires_new) | 支持当前事务,如果当前有事务,则挂起当前事务,然后新创建一个事务,如果当前没有事务,则自己创建一个事务。 |
| Propagation.NESTED (nested 嵌套事务) | 如果当前存在事务,则嵌套在当前事务中。如果当前没有事务,则新建一个事务自己执行(和required一样)。嵌套的事务使用保存点作为回滚点,当内部事务回滚时不会影响外部事物的提交;但是外部回滚会把内部事务一起回滚回去。(这个和新建一个事务的区别) |
事物并发可能存在的问题:脏读,不可重复读,幻读
| 事物隔离级别 Isolation | 解释 |
|---|---|
| . ISOLATION_READ_UNCOMMITTED | 这是事务最低的隔离级别,它充许另外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读。 |
| ISOLATION_READ_COMMITTED Oracle默认 | 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据,可解决脏读。 |
| ISOLATION_REPEATABLE_READ MySql默认 | 确保事物可以多次从一个字段中读取到相同的值,即事物运行执行期间禁止其他事物对这个字段进行更新,可解决脏读,不可重复读 |
| ISOLATION_SERIALIZABLE | 确保事物可以多次从一个表中读取到相同的行,在事物执行期间,禁止其他事物对这个表进行更新操作,可以避免任何并发问题,但性能低下。 |
9、SSM:简单的谈一下SpringMVC的工作流程
10、SSM:MyBatis中当实体类中的属性名和表中的字段不一致?
- 写sql 语句时起别名
- 在MyBatis的全局配置文件中开启驼峰命名规则(例如last_name可以映射为lastName)
- 在Mapper映射文件中使用resultMap来自定义映射规则
11、Linux操作总结
https://blog.csdn.net/weixin_44346035/article/details/97540450
12、Redis持久化
| 方式 | 详细 | 优点 | 缺点 |
|---|---|---|---|
| RDB (Redis DataBase) | 在指定的时间间隔将内存中的数据写入磁盘,也就是Snapshot快照,恢复时是将快照文件直接读到内存里,备份如何进行:Redis会单独fork一个子进程来进行持久化,先将数据写入到一个临时文件中,待持久化都结束了,再用这个临时文件替换上次持久化好的文件,整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要大规模数据的恢复,且对于数据恢复的完整性不是非常敏感那RDB要比AOF方式更加的高效,RDB的缺点是最后一次持久化后的数据可能丢失。 | 节省磁盘空间, 恢复速度快 | 虽然在fork时使用了写时拷贝技术,但数据量庞大时还是比较消耗性能,在一次间隔内做一次备份,如果Redis意外down掉的话,就可能丢失最后一次快照后的所有修改。 |
| AOF(Append Of File) | 以日志的形式记录每个写操作,将Redis执行过的所有写指令记录下来,只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复的恢复工作。 | 备份机制更稳健,丢失数据概率更低,可读的日志文件,可以处理误操作。 | 比起RDB需要更多的磁盘空间,恢复备份速度要慢,每次读写都同步的话,有一定的性能压力,存在个别BUG,可能不能恢复。 |
13、MySql什么时候建索引
| 索引(Index) | 帮助Mysql高效获取数据的数据结构(排好序的快速查找数据结构) |
|---|---|
| 优势 | 提高检索效率,降低数据库的IO成本 通过索引对数据进行排序,降低排序成本,降低CPU的消耗 |
| 劣势 | 降低了更新表的速度,更新数据的同时还得更新索引 |
| 哪些情况需要创建索引 | 主键自动建立唯一索引 频繁作为查询条件的字段硬建立索引 查询中与其他表关联的字段,外键关系建立索引 单键/组合索引的选择问题:组合索引性价比更高 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度 查询中统计或分组字段 |
| 哪些情况不要创建索引 | 表记录太少 经常增删改的字段或表 筛选条件用不到的字段 过滤性不好的字段不适合建索引,例如性别字段 |
14、JVM垃圾回收机制,GC发生在JVM哪部分,有几种GC,它们的算法是什么?

| GC发生在JVM哪部分 | 堆 |
|---|---|
| Minor GC | 一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Minor GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。 |
| Full GC | 对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个堆进行回收,所以比Minor GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。有如下原因可能导致Full GC. |
| GC四大算法 | |
|---|---|
| 引用计数法 | 每次对象赋值时要维护计数器,且计数器本身也有一定消耗;较难处理循环引用,JVM一般不采用这种方式 |
| 复制算法 | 年轻代中Minor GC,采用的就是复制算法,从GC Roots开始,通过Tracing从From中找到存活对象,拷贝到To中,From,To交换身份。没有标记和清除的过程,效率高,没有内存碎片,但是需要双倍空间。 |
| 标记清除 | 老年代一般是由标记清除与标记整理色混合实现,标记(从根集合开始扫描,对存活的对象进行标记),清除(扫描整个内存空间,回收未被标记的对象。不需要额外的空间,但两次扫描,耗时严重,会产生内存碎片。 |
| 标记压缩 | 老年代一般是由标记清除与标记整理色混合实现,标记(从根集合开始扫描,对存活的对象进行标记),压缩(再次扫描,并往一端滑动存活对象,没有内存碎片,但需要移动对象的成本 |
15、Redis在项目中的使用场景
| 数据类型 | 使用场景 |
|---|---|
| String | String类型是二进制安全的 可用来存储JSON格式的字符串或一些转化的二进制码 |
| Hash | 存储对象类数据, |
| List | 最新消息的排行,还可以利用List的push命令,将任务存在list集合,使用pop命令将任务从集合中取出来 模拟消息队列–电商中的秒杀 |
| Set | 可以自动排重, 比如微博中两个人的共同好友,跟踪一下具有唯一性的数据,比如唯一IP信息 |
| Zset | 以某一个条件为权重,进行排序 根据好友亲密度显示好友列表 |
16、Elasticsearch与solr的区别
背景:都是基于Lucene搜索服务器基础之上开发,一款优秀的,高性能的企业级搜索服务器【是因为他们都是基于分词技术构建的倒排索引的方式进行排序】。
开发语言:java语言
诞生时间:Es :2010(功能更强大); Solr:2004
| 区别: |
|---|
| 当建立索引的时候,solr会产生阻塞,而es不会,es查询性能要高于solr。 |
| 在不断动态添加数据的时候,solr的检索效率会变得低下,而es没有什么变化 |
| solr利用zookeeper进行分布式管理,而es自身带有分布式系统管理功能,Solr一般都要部署到Web服务器上[Sole本质是一个动态Web项目】 |
| solr支持更多的格式数据【XML,JSON,CSV】等,但是es仅支持JSON格式 |
| solr是传统搜索应用的有效解决方案,但是es适用于新兴的实时搜索应用 单纯对已有数据进行检索的时候,solr效率更好,高于es |
| solr官网提供的功能更多,而es本身更注重于核心功能,高级功能多有第三方插件 |
17、单点登录Single Sign On的过程
单点登录:一处登录,多处使用 https://yq.aliyun.com/articles/636281
18、购物车的实现
购物车的实现步骤文字总结
- 用户添加商品至购物车时,会携带参数商品id和商品的count。
- 服务端首先会获取客户端cookie中的购物车,
- 如果cookie没有对应的购物车,则创建一个新的购物车,并将此商品的id和count添加到购物车,
- 如果有,则将此商品的id和count添加到从cookie获得的购物车中。
- 然后检查用户的登陆状态,
- 如果已登陆,则将此购物车的内容合并到该用户的购物车中(该用户的购物车保存在数据库中,比如redis),然后在响应中将客户端的cookie中的购物车清空。
- 如果未登陆,则在响应中将添加完此商品的购物车重新写回到客户端的cookie中
19、消息队列在项目中的应用
20、面向对象的特征
| 有四大特征 | 封装、抽象、继承、多态 |
|---|---|
| 封装 | 即将一个对象封装成一个高度自治和相对封闭的个体,对象状态(属性)由这个对象的行为(方法)来读取和改变 |
| 抽象 | 抽象就是找出一些事物的相似和共性之处,这个类只考虑这些事物的相似和共性之处,并且会忽略掉与当前主题和目标无关的那些方面,将注意力放在在与当前目标有关的方面 |
| 继承 | 在定义和实现一个类的时候,可以在一个已经存在的类的基础上进行,把这个已经存在的类所定义的内容作为自己的内容,并可以加入若干新的内容,或修改原来的方法适用于自己特殊的需要 |
| 多态 | 多态是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即该引用变量指向哪个类的实例对象,该引用变量发出的方法调用就是这个类实现的方法,在程序运行期间才能确定。 多态有四种体现形式:1. 接口和接口的继承。2. 类和类的继承。3. 重载。4. 重写。 |
21、有了基本数据类型,为什么还要有基本数据类型的包装类
之所以需要包装类型,就是因为java是一个面向对象的语言,然而基本数据类型不具备面向对象的特性,当我们把基本数据类型包装成包装类型之后,它就具有了面向对象的特性。
Java 中预定义了八种基本数据类型,包括:byte,short ,int,long,double,float,boolean,char。基本类型与对象类型最大的不同点在于,基本类型基于数值,对象类型基于引用。
基本类型的变量在栈的局部变量表中直接存储的具体数值,而对象类型的变量则存储的堆中引用。
显然,相对于基本类型的变量来说,对象类型的变量需要占用更多的内存空间。
基本类型基于数值,所以基本类型是没有类而言的,是不存在类的概念的,也就是说,变量只能存储数值,而不具备操作数据的方法。对象类型则截然不同,变量实际上是某个类的实例,可以拥有属性方法等信息,不再单一的存储数值,可以提供各种各样对数值的操作方法,但代价就是牺牲一些性能并占用更多的内存空间。
装箱:Integer a = 2;实际上在编译时会调用Integer.valueOf()来进行装箱。
拆箱:int b = a; 实际上在编译时会调用Integet.intValue方法来进行拆箱 。
自 jdk 1.5 以后,sun 加入了这个缓存类用于复用指定范围内的 Integer 实例,把内容相同的对象缓存起来,减少内存开销。 默认可以缓存数值在 [-128,127] 之间的实例。一旦该Integer的值位于我们缓存的值区间,那么将直接从缓存池中返回直接引用,否则将会实际创建一个 Integer 实例返回。
当然你可以通过启动虚拟机参数 -XX:AutoBoxCacheMax 指定缓存区间的最大数值。
理论上,我们可以缓存最大到 Integer.MAX_VALUE ,但是实际上是做不到的,因为 Integer[] 数组可定义的最大长度就是
Integer.MAX_VALUE,而我们还有 128 个负数待缓存,显然数组容量是不够的。
22、== 和 equals的区别
- “==” 如果是基本数据类型比较,则比较的是值是否相等,如果是引用类型,则比较的是引用指向的内存地址
- equils 对于基本数据类型的包装类,则直接是判断两个同包装类的值是否一致,对于引用类型的equals方法,默认调用的也是==判断,所有默认也是比较内存地址,一般要进行equals方法的重写。如果重写equals方法需要注意的是也要重写hashcode方法,保证数据的一致性,这是一种规范。
顺便说一下hashcode方法,hashCode()方法返回的就是一个数值,从方法的名称上就可以看出,其目的是生成一个hash码。hash码的主要用途就是在对对象进行散列的时候作为key输入,据此很容易推断出,我们需要每个对象的hash码尽可能不同,这样才能保证散列的存取性能。事实上,Object类提供的默认实现确实保证每个对象的hash码不同(在对象的内存地址基础上经过特定算法返回一个hash码)。 哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。初学者可以这样理解,hashCode方法实际上返回的就是对象存储的物理地址
//Object的equils方法内部实现 public boolean equals(Object obj) { return (this == obj); } //Integer的equils方法内部实现 public boolean equals(Object obj) { if (obj instanceof Integer) { return value == ((Integer)obj).intValue(); } return false; } //Integer的hashcode方法内部实现:结论:整型包装类的hashcode码是它的数值。 public int hashCode() { return Integer.hashCode(value); } public static int hashCode(int value) { return value; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
23、String的intern方法
24、String、StringBuffer、StringBulider
在java中提供了这三个类来操作字符串,字符串就是多个字符的数组String是内容不可变的字符串,String底层使用了一个不可变的字符数组。
//String中存取值的不可变的字符数组
// The value is used for character storage.
private final char value[];
- 1
- 2
- 3
- 4
- 5
而StringBuilder、StringBuffer是内容可以改变的字符串,底层使用的是一个可变的字符数组。
//StringBulder、StringBuffer中存取值的可变的字符数组
//The value is used for character storage.
char[] value;
- 1
- 2
- 3
- 4
字符串拼接
https://baijiahao.baidu.com/s?id=1629804867201303563&wfr=spider&for=pc
String进行拼接,String c = “a” + “b” ,这个过程创建多个String的中间对象。
StringBuilder、StringBuffer, 对象的实例.append(“a”).append(“b”),这个过程不需要创建中间对象。
所以拼接字符串不能用String拼接,而是要使用StringBuilder或StringBuffer.
StringBuilder是线程不安全的,而StringBuffer是线程安全的
//StringBuffer的append方法是带synchronized关键字修饰的
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
25、 HashTable和HashMap的区别
https://www.cnblogs.com/williamjie/p/9099141.html
| 区别 | HashTable | HashMap |
|---|---|---|
| 继承的父类不同 | Hashtable继承自Dictionary类 public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable. | 而HashMap继承自AbstractMap类 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable. 但二者都实现了Map接口。 |
| 线程安全性不同 | 使用synchronized关键字保证了线程安全性 | 不保证 |
| 是否提供contains方法 | Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。 | HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey |
| key和value是否允许null值 | Hashtable中,key和value都不允许出现null值。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常 | HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null |
| hash值不同 | Hashtable直接用key的hashCode() Hashtable在求hash值对应的位置索引时,用取模运算 :int index = (hash & 0x7FFFFFFF) % tab.length; | 而HashMap重新计算了key的hash值 (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 而HashMap在求位置索引时 n = tab.length i = (n - 1) & hash 确定索引 |
| 内部实现使用的数组初始化和扩容方式不同 | HashTable在不指定容量的情况下的默认容量为11,最大容量为MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 Hashtable不要求底层数组的容量一定要为2的整数次幂 Hashtable扩容时,将容量变为原来的2倍加1 int newCapacity = (oldCapacity << 1) + 1; | HashMap默认容量为16,最大容量为230 而HashMap则要求底层数组的容量一定为2的整数次幂。 而HashMap扩容时,将容量变为原来的2倍。 newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY |
HashMap的容量为什么是2的整数次幂?
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。 看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面annegu的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。

26、实现拷贝文件的一个工具类使用字符流还是使用字节流?
拷贝的文件不确定只包含字符流,也有可能有字节流(图片,声音,图像等),为考虑到通用性,要使用字节流.
27、实现线程的四种方法
import java.util.concurrent.*; //class Thread implements Runnable class T1 extends Thread { @Override public void run() { System.out.println("我是T1的run方法"); } } class T2 implements Runnable { @Override public void run() { System.out.println("我是T2的run方法"); } } class T3 implements Callable<Integer> { @Override public Integer call() throws Exception { System.out.println("我是T3的call方法,我有返回值"); return 99; } } class T4 implements Runnable { @Override public void run() { System.out.println("我是线程池调用的run方法"); } } public class MyThread { public static void main(String[] args) throws ExecutionException, InterruptedException { /** * 创建线程的四种方法 */ // 1--继承Thread类,Thread实现了Runnable接口,但由于一类一继承制,并不推荐使用 Thread t1 = new Thread(new T1(), "T1"); t1.start(); // 2--直接实现Runnable接口,推荐使用,并且可以创建线程的时候使用Lamda表达式 Thread t2 = new Thread(new T2(), "T2"); t2.start(); // interface RunnableFuture<V> extends Runnable, Future<V> // class FutureTask<V> implements RunnableFuture<V> // 3--实现Callable接口,该方法有返回值,可抛出异常 // 适用场景:1:对于一个比较消耗CPU时间的计算任务,主线程启动一个FutureTask子线程去执行,主线程继续执行其他任务,当主线程需要子线程的计算结果时,再异步获取子线程的执行结果 // 2: FutureTask确保即使调用了多次run方法,它只会执行一次Runnable或Callable任务,或者通过cancel取消执行。执行一次后就保持在运算完成的状态而不会回滚。 FutureTask<Integer> futureTask = new FutureTask<Integer>(new T3()); futureTask.run(); System.out.println("返回值为:" + futureTask.get()); // 4--线程池 ExecutorService executorService = new ThreadPoolExecutor(1, 1, 2, TimeUnit.SECONDS, new LinkedBlockingDeque<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.DiscardOldestPolicy()); Future<Integer> submit = executorService.submit(new T3()); System.out.println("我是线程池调用的实现Callable接口的方法的返回结果:" + submit.get()); executorService.shutdown(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
输出:
我是T1的run方法
我是T3的call方法,我有返回值
返回值为:99
我是T2的run方法
我是T3的call方法,我有返回值
我是线程池调用的实现Callable接口的方法的返回结果:99
- 1
- 2
- 3
- 4
- 5
- 6
- 7
28、线程池的submit方法和execute方法的区别
1.对返回值的处理不同:execute方法没有返回值。submit方法有返回值Future<>。
2.对异常的处理不同:excute方法会抛出异常。sumbit方法不会抛出异常。除非你调用Future.get()。
3. 接受的参数不一样,都可以是Runnable,但submit也可以是Callable
参考:https://blog.csdn.net/abountwinter/article/details/78123422
28.1、submit
当我们调用submit方法时,其实是调用了AbstractExecutorService.submit方法
注意FutureTask的future是null
直接看源码:
public Future<?> submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null); execute(ftask); return ftask; } public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; } public <T> Future<T> submit(Callable<T> task) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task); execute(ftask); return ftask; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
无论传入的是Runnable还是Callable,方法中的第二行都对 task进行了一次封装,封装成为FutureTask ->RunnableFuture
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
- 1
- 2
- 3
RunnableFuture 继承 Runnable,Future
public interface RunnableFuture<V> extends Runnable, Future<V>
- 1
然后看ThreadPoolExecutor的execute方法
public void execute(Runnable command) {
//省略
addWorker(null, false);
//省略
}
- 1
- 2
- 3
- 4
- 5
addWorker之后就是runWorker
final void runWorker(Worker w) {
//省略
task.run();
//省略
}
- 1
- 2
- 3
- 4
- 5
对于FutureTask,执行的当然是FutureTask的run方法
setException把抛出的异常赋值给了outcome,outcome就是Futer.get() 的返回结果。
所以就有了开始的结论,submit提交任务时不会有异常,因为异常被当作结果返回了,只有通过get才能获得返回的异常。
public void run() { if (state != NEW || !UNSAFE.compareAndSwapObject(this, runnerOffset, null, Thread.currentThread())) return; try { Callable<V> c = callable; if (c != null && state == NEW) { V result; boolean ran; try { result = c.call(); ran = true; } catch (Throwable ex) { result = null; ran = false; setException(ex); } if (ran) set(result); } } finally { int s = state; if (s >= INTERRUPTING) handlePossibleCancellationInterrupt(s); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
28.1、execute
对于execute,只能传入Runnable类型的参数,执行run方法的时候,并没有捕获并处理异常,所以当run方法中执行出现错误时,异常会被直接抛出。
29、线程池的使用及线程并发库
线程池的使用优势:
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大线程数量,超过数量的线程排队等候,其他线程执行完毕,再从队列中取出任务来执行。
主要特点:线程复用,控制最大并发数,管理线程。
- 降低资源消耗,通过重复利用已创建的线程降低线程的创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到创建新的线程就可以执行任务。
- 提高线程的可管理性,线程是稀缺资源,如果无限制的创建线程,不仅消耗资源,也造成了系统的不稳定性,使用线程池可以进行统一的分配,调优和监控。
| Java通过 Executors提供四个静态方法创建四种线程池 | |
|---|---|
| newCachedThreadPool() | 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 |
| newFixedThreadPool(int)) | 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 |
| newScheduledThreadPool() | 创建一个定长线程池,支持定时及周期性任务执行。 |
| newSingleThreadExecutor() | 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行 |
| Executors.newWorkStealingPool(int) | java8新增,使用目前机器上可用的处理器作为它的并行级别。 |
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理让更能明确线程池的运行规则,规避资源耗尽的风险.
Executors的弊端如下:
- FixedThreadPool和SingleThreadPool
运行的请求队列长度为Integer.MAX_VALUE,可能会堆积大量请求,从而导致OOM。- CachedThreadPool和ScheduledThreadPool
允许创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
线程池的七大参数
| 参数 | 作用 |
|---|---|
| corePoolSize | 线程池中的常驻线程数 |
| maximumPoolSize | 线程池中能够容纳同时执行的最大线程数,此值必须大于1。 |
| keepAliveTime | 多余的空闲线程的存活时间当前线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁只剩下corePoolSize个线程为止。 |
| Unit | keepAliveTime的单位 |
| workQueue | 任务队列,被提交尚未执行的任务。 |
| threadFactory | 表示生成线程池中的工作线程的线程工厂,用于创建线程一般用默认的即可。 |
| handle | 拒绝策略,表示当队列满了并且工作线程大于等于线程池的最大线程数(maximumPoolSize)。 |
线程池的参数的确定
https://www.cnblogs.com/waytobestcoder/p/5323130.html
线程池的工作原理流程

手写一个线程池
https://blog.csdn.net/weixin_44346035/article/details/96430009
线程池配置合理线程数:
Runtime.getRuntime.availableProcessors() ;得到本机CPU的核数
CPU密集型:
是指任务需要大量的运算,而没有阻塞,CPU一直全速运行。
CPU密集型任务只有在真正的多核CPU上才能得到加速(通过多线程)
CPU密集型任务配置尽可能少的线程数量:CPU核数+1个线程的线程池
IO密集型:
1、由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如CPU核数*2;
2、在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待,所以使用多线程可以加速程序运行,这种加速主要是利用了被浪费掉的阻塞时间。
参考公式:CPU核数/(1-阻塞系数) 阻塞系数在0.8–0.9之间。
30、什么是设计模式,常用的设计模式
设计模式(Design Pattern)是前辈们对代码开发经验的总结,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。
| 常见的六种设计模式以及应用场景 | |
|---|---|
| 单例模式 | 是一种常用的软件设计模式,在它的核心结构中值包含一个被称为单例的特殊类。即一个类只有一个对象实例。 |
| 工厂模式 | 根据需要返回我们的对象。是通过专门定义一个类来负责创建其他类的实例,简单工厂模式就是通过一个"全能类",根据外界传递的信息来决定创建哪个具体类的对象。应用比较熟悉的场景就是spring配置文件了。 |
| 适配器模式 | 将一个类的接口转换成客户希望的另外一个接口。通俗地讲,就是在2个类之间做了一个衔接。比如你在调用A类的doSomething方法,实际上内部实现调用了B类的doSomething方法。 |
| 代理模式 | 它的定义是:代理模式给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用。Java的反射机制,很多地方就用了代理模式来实现。例如spring的AOP。 |
| 监听模式 | 组件(事件源)不处理自己的事件,而是将事件处理托付给外部的处理实体(监听器,这样的事件处理模型称为事件的 授权处理模型。不同的事件,能够交由不同类型的监听器去处理 |
| 装饰器模式 | 简单说就是不改变现有类的结构前提下,扩展它的功能。用别的类来增加原有类的功能。 |
31、谈一谈spring的控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection)
32、GET和POST 的区别
GET 和 POST 只是 HTTP 协议中两种请求方式,而 HTTP 协议是基于 TCP/IP 的应用层协议,无论 GET 还是 POST,用的都是同一个传输层协议,所以在传输上,没有区别。get是从服务器上获取数据,post是向服务器传送数据。
区别

其他http请求方法

get和post也可以完成put和delete操作,为什么还要有PUT和DELETE请求方法?
- 请求URI路径命名与请求方式type混乱
每个人都有自己命名的一套规则与请求方式,导致http协议显得混乱,甚至完全忽略了其他请求方式如put、delete等,如果不是因为get请求uri长度限制(一般为2kb),所有的操作get请求都可以完成。如果有一种规范标准来约束每次请求的操作,语义性会更好。- 混乱的URI命名与Type类型导致资源的来源复杂多样
混乱的URI命名导致一个独立的URI地址,无法对应一个独一无二的资源。一个资源,对应了多样来源;如果一个独立的URI地址,对应一个独一无二的资源(RESTful风格):/hairStyle/{customer_id},一个顾客就对应一套理发流程;如/hairStyle/mark,表示我现在需要为mark做一整套理发流程。现在再想想我们之前常用的命名方式
wash/hairStyle/mark,为mark顾客洗头
cut/hairStyle/mark,为mark顾客剪头
dry/hairStyle/mark,为mark顾客吹头
如果我们可以用/hairStyle/mark表示一整套流程,(已经定义了各种type)
如果你要为顾客洗头,追加type=wash;
如果你要为顾客剪头,追加type=cut;
如果你要为顾客剪头,追加type=dry;
这就是RESTful风格之一了
33、REST 与REST ful
REST( REpresentational State Transfer ),State Transfer 为 “状态传输” 或 "状态转移 “,Representational 中文有人翻译为"表征”、“具象”,合起来就是 “表征状态传输” 或 “具象状态传输” 或 “表述性状态转移”。REST指的是一组以网络为基础的应用架构约束条件和原则。" 如果一个架构符合REST的约束条件和原则,我们就称它为RESTful架构。
理解RESTful
| 关键概念 | 解释 |
|---|---|
| 资源与URI | 资源可以是实体(例如手机号码),也可以只是一个抽象概念(例如价值) 。要让一个资源可以被识别,需要有个唯一标识,在Web中这个唯一标识就是URI(Uniform Resource Identifier)。URI既可以看成是资源的地址,也可以看成是资源的名称。URI的设计应该遵循可寻址性原则,具有自描述性,需要在形式上给人以直觉上的关联。 |
| 统一资源接口 | RESTful架构应该遵循统一接口原则,统一接口包含了一组受限的预定义的操作,不论什么样的资源,都是通过使用相同的接口进行资源的访问。接口应该使用标准的HTTP方法如GET,PUT和POST和DELETE,并遵循这些方法的语义。如果按照HTTP方法的语义来暴露资源,那么接口将会拥有安全性和幂等性的特性。 |
| 资源的表述 | 客户端通过HTTP方法可以获取资源,确切的说,客户端获取的只是资源的表述而已。 资源在外界的具体呈现,可以有多种表述(或成为表现、表示)形式,在客户端和服务端之间传送的也是资源的表述,而不是资源本身。 例如文本资源可以采用html、xml、json等格式,图片可以使用PNG或JPG展现出来。资源的表述包括数据和描述数据的元数据,例如,HTTP头"Content-Type" 就是这样一个元数据属性。那么客户端如何知道服务端提供哪种表述形式呢?答案是可以通过HTTP内容协商,客户端可以通过Accept头请求一种特定格式的表述,服务端则通过Content-Type告诉客户端资源的表述形式。 |
| 资源的链接 | REST是使用标准的HTTP方法来操作资源的,但仅仅因此就理解成带CURD的Web数据库架构就太过于简单了。这种反模式忽略了一个核心概念:“超媒体即应用状态引擎(hypermedia as the engine of application state)”。 超媒体是什么?当你浏览Web网页时,从一个连接跳到一个页面,再从另一个连接跳到另外一个页面,就是利用了超媒体的概念:把一个个把资源链接起来.要达到这个目的,就要求在表述格式里边加入链接来引导客户端。 |
| 状态的转移 | 实际上,状态应该区分应用状态和资源状态,客户端负责维护应用状态,而服务端维护资源状态。客户端与服务端的交互必须是无状态的,并在每一次请求中包含处理该请求所需的一切信息。服务端不需要在请求间保留应用状态,只有在接受到实际请求的时候,服务端才会关注应用状态。这种无状态通信原则,使得在多次请求中,同一客户端也不再需要依赖于同一服务器,方便实现高可扩展和高可用性的服务端。状态转移到这里已经很好理解了, "会话"状态不是作为资源状态保存在服务端的,而是被客户端作为应用状态进行跟踪的。客户端应用状态在服务端提供的超媒体的指引下发生变迁。服务端通过超媒体告诉客户端当前状态有哪些后续状态可以进入。这些类似"下一页"之类的链接起的就是这种推进状态的作用——指引你如何从当前状态进入下一个可能的状态。 |
34、HTTP 状态消息
当浏览器从 web 服务器请求服务时,可能会发生错误。 因此,我们使用3位数字代码 HTTP 状态码(HTTP Status
Code)来表示 HTTP 响应状态。
更详细的状态码解释 https://www.w3cschool.cn/htmltags/html-httpmessages.html
| 状态码 | 信息 |
|---|---|
| 1xx:信息 | 该状态码属于临时响应类型,代表请求已被接受,需要继续处理。该类状态码只包含状态行和某些可选的响应头信息,并以空行结束。 |
| 2xx: 成功 | 该类型的状态码,表示请求已成功被服务器接收、理解、并接受。 |
| 3xx: 重定向 | 该类状态码完成请求的要求是需要客户端采取进一步的操作。它通常用来重定向,后续的请求地址(重定向目标)在本次响应的 Location 域中指明 |
| 4xx: 客户端错误 | 该类的状态码表示客户端看起来可能发生了错误,妨碍了服务器的处理。 |
| 5xx: 服务器错误 | 该类状态码表示服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器无法使用当前的软硬件资源完成对请求的处理。 |
35、请求转发与重定向
参考 https://blog.csdn.net/xybelieve1990/article/details/49486751
调用方式
request.getRequestDispatcher("new.jsp").forward(request, response);//转发到new.jsp
response.sendRedirect("new.jsp");//重定向到new.jsp
- 1
- 2
- 3
- 4
| 过程 | 特点 | |
|---|---|---|
| 转发过程 | 客户浏览器发送http请求---->web服务器接受此请求–>调用内部的一个方法在容器内部完成请求处理和转发动作---->将目标资源发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客户。浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。 | 这个过程是共享相同的request对象和response对象,它们属于同一个访问请求和响应过程。如果创建RequestDispatcher对象时指定的相对URL以“/”开头,它是相对于当前WEB应用程序的根目录。 |
| 重定向过程: | 客户浏览器发送http请求---->web服务器接受后发送302状态码响应及对应新的location给客户浏览器–>客户浏览器发现是302响应,则自动再发送一个新的http请求,请求url是新的location地址---->服务器根据此请求寻找资源并发送给客户。在这里location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。 | 这个过程第一次请求和转发后的请求是各自的request对象和response对象,它们属于两个独立的访问请求和响应过程。不仅可以重定向到当前应用程序中的其他资源,还可以重定向到同一个站点上的其他应用程序中的资源,甚至是使用绝对URL重定向到其他站点的资源。方法的相对URL以“/”开头,它是相对于整个WEB站点的根目录 |
转发和重定向的应用场景
转发是要比重定向快,因为重定向需要经过客户端,而转发没有。有时候,采用重定向会更好,若需要重定向到另外一个外部网站,则无法使用转发。另外,重定向还有一个应用场景:避免在用户重新加载页面时两次调用相同的动作。
例如,当提交产品表单的时候,执行保存的方法将会被调用,并执行相应的动作;这在一个真实的应用程序中,很有可能将表单中的所有产品信息加入到数据库中。但是如果在提交表单后,重新加载页面,执行保存的方法就很有可能再次被调用。同样的产品信息就将可能再次被添加,为了避免这种情况,提交表单后,你可以将用户重定向到一个不同的页面,这样的话,这个网页任意重新加载都没有副作用; 但是,使用重定向不太方便的地方是,使用它无法将值轻松地传递给目标页面。而采用转发,则可以简单地将属性添加到Model,使得目标视图可以轻松访问。由于重定向经过客户端,所以Model中的一切都会在重定向时丢失。但幸运的是,在Spring3.1版本以后,我们可以通过Flash属性,解决重定向时传值丢失的问题。
要使用Flash属性,必须在Spring
MVC的配置文件中添加一个。然后,还必须再方法上添加一个新的参数类型:org.springframework.web.servlet.mvc.support.RedirectAttributes。
@RequestMapping(value="saveProduct",method=RequestMethod.POST)
public String saveProduct(ProductForm productForm,RedirectAttributes redirectAttributes){
//执行产品保存的业务逻辑等
//传递参数
redirectAttributes.addFlashAttribute("message","The product is saved successfully");
//执行重定向
return "redirect:/……";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
35、Java Servlet
Servlet(Server Applet),全称Java Servlet,是用Java编写的服务器端程序。Servlet运行于支持Java的应用服务器中。处理Http请求。其主要功能在于交互式地浏览和修改数据,生成动态Web内容。狭义的Servlet是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的类,一般情况下,人们将Servlet理解为后者。
35.1、Tomcat工作流程
当客户端通过浏览器向服务器发送一个请求时,如果此时请求的servlet未被初始化,tomcat将从磁盘中加载此servlet到tomcat服务器中,tomcat解析http请求为request对象,转发request至相应的servlet处理,servlet处理后返回response,tomcat将response转化成HTTP响应,将HTTP响应返回给客户端。
35.2、Servlet主要相关组件
官方下载地址: https://download.oracle.com/otndocs/jcp/servlet-2.5-mrel-oth-JSpec/

35.3、Servlet 的工作原理
Servlet容器将Servlet类载入内存,并产生Servlet实例和调用它具体的方法。但是要注意的是,在一个应用程序中,每种Servlet类型只能有一个实例。
用户请求致使Servlet容器调用Servlet的Service()方法,并传入一个ServletRequest对象和一个ServletResponse对象。ServletRequest中封装了当前的Http请求,ServletResponse表示当前用户的Http响应,只需直接操作ServletResponse对象就能把响应的发回给用户。ServletRequest对象和ServletResponse对象都是由Servlet容器(例如TomCat)封装好的,开发者可以直接使用这两个对象。
对于每一个应用程序,Servlet容器还会创建一个ServletContext对象。这个对象中封装了应用程序上下文的环境详情。每个应用程序只有一个ServletContext。每个Servlet对象也都有一个封装Servlet配置的ServletConfig对象。
35.4、Servlet 的生命周期
其中,init( ),service( ),destroy()是Servlet生命周期的方法。代表了Servlet从“出生”到“工作”再到“死亡 ”的过程。Servlet容器(例如TomCat)会根据下面的规则来调用这三个方法:
- init( ),当Servlet第一次被请求时,Servlet容器就会开始调用这个方法来初始化一个Servlet对象出来,但是这个方法在后续请求中不会在被Servlet容器调用,就像人只能“出生”一次一样。我们可以利用init()方法来执行相应的初始化工作。调用这个方法时,Servlet容器会传入一个ServletConfig对象进来从而对Servlet对象进行初始化。
- service( )方法,每当请求Servlet时,Servlet容器就会调用这个方法。就像人一样,需要不停的接受老板的指令并且“工作”。第一次请求时,Servlet容器会先调用init(> )方法初始化一个Servlet对象出来,然后会调用它的service(> )方法进行工作,但在后续的请求中,Servlet容器只会调用service方法了。
- destory,当要销毁Servlet时,Servlet容器就会调用这个方法,就如人一样,到时期了就得死亡。在卸载应用程序或者关闭Servlet容器时,就会发生这种情况.
35.5、探究实现细节
进入HttpServlet的service方法
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException {
HttpServletRequest request;
HttpServletResponse response;
try {
request = (HttpServletRequest)req;
response = (HttpServletResponse)res;
} catch (ClassCastException var6) {
throw new ServletException("non-HTTP request or response");
}
this.service(request, response);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们发现,HttpServlet中的service方法把接收到的ServletRequsest类型的对象转换成了HttpServletRequest类型的对象,把ServletResponse类型的对象转换成了HttpServletResponse类型的对象。
转换之后,service方法把两个转换后的对象传入了另一个service方法,那么我们再来看看这个方法是如何实现的:
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String method = req.getMethod(); long lastModified; if (method.equals("GET")) { lastModified = this.getLastModified(req); if (lastModified == -1L) { this.doGet(req, resp); } else { long ifModifiedSince = req.getDateHeader("If-Modified-Since"); if (ifModifiedSince < lastModified / 1000L * 1000L) { this.maybeSetLastModified(resp, lastModified); this.doGet(req, resp); } else { resp.setStatus(304); } } } else if (method.equals("HEAD")) { lastModified = this.getLastModified(req); this.maybeSetLastModified(resp, lastModified); this.doHead(req, resp); } else if (method.equals("POST")) { this.doPost(req, resp); } else if (method.equals("PUT")) { this.doPut(req, resp); } else if (method.equals("DELETE")) { this.doDelete(req, resp); } else if (method.equals("OPTIONS")) { this.doOptions(req, resp); } else if (method.equals("TRACE")) { this.doTrace(req, resp); } else { String errMsg = lStrings.getString("http.method_not_implemented"); Object[] errArgs = new Object[]{method}; errMsg = MessageFormat.format(errMsg, errArgs); resp.sendError(501, errMsg); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
我们发现,这个service方法的参数是HttpServletRequest对象和HttpServletResponse对象,刚好接收了上一个service方法传过来的两个对象。接下来我们再看看service方法是如何工作的,我们会发现在service方法中还是没有任何的服务逻辑,但是却在解析HttpServletRequest中的方法参数,并调用以下方法之:doGet,doPost,doHead,doPut,doTrace,doOptions和doDelete。这7种方法中,每一种方法都表示一个Http方法。然后我们根据可以根据自己的Http方法重写相关方法,实现自己的业务。
35.6、 HttpServletRequest接口
HTTP报文格式

通过HttpServletRequest自带的方法就完全可以获取请求行和请求头的数据,post方式提交的表单数据,通过HttpServletRequest.getParameter(name)即可获得其他的值,但对于放入请求体中的其他数据,借助HttpServletRequest的其他方法可以间接获得。
在Body中写入一下数据,然后进行测试

此次请求的报文格式

测试的servlet中重写的service方法,当请求至此方法中,之前填入Body的 【i am data】 会被打印出来。
当然你可以传入各种格式的数据,在服务端的代码解析后执行相应的业务即可。
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse resp) throws ServletException, IOException {
BufferedReader reader = request.getReader();
String readerStr = "";
String line;
while ((line = reader.readLine()) != null){
readerStr = readerStr.concat(line);
}
System.out.println(readerStr); // i am data
request.getRequestDispatcher("return.jsp").forward(request,resp);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
解决乱码问题
如果客户端的请求传入的数据有中文汉字,则会导致乱码问题
//在获取数据之前,将request的编码的设置为utf-8
request.setCharacterEncoding("utf-8");
//或者将获取到的数据先用服务端的编码类型iso8859-1 解码成字节数组,然后再用utf-8编码,得到正确格式的中文
String ch_data = new String(data.getBytes("iso8859-1"),"utf-8");
- 1
- 2
- 3
- 4
35.7、HttpServletResponse接口
在Service API中,定义了一个HttpServletResponse接口,它继承自ServletResponse接口,专门用来封装HTTP响应消息。 HTTP请求消息分为状态行,响应消息头,响应消息体三部分,响应行分为协议版本,状态码,状态码描述。

HttpServletResponse中定义了向客户端发送响应状态码,响应消息头,响应消息体的方法。
发送响应消息体有以下两种方式
- PrintWriter getWriter() 获得字符流,通过字符流的write(String s)方法可以将字符串设置到response
缓冲区中,随后Tomcat会将response缓冲区中的内容组装成Http响应返回给浏览器端。


- ServletOutputStream getOutputStream()
获得字节流,通过该字节流的write(byte[]
bytes)可以向response缓冲区中写入字节,再由Tomcat服务器将字节内容组成Http响应返回给浏览器。
下段代码的作用是将本机的一张图片通过resopnse的OutOfStream响应给页面
@Override protected void doGet(HttpServletRequest request, HttpServletResponse resp) throws ServletException, IOException { resp.setContentType("image/jpg"); File localFile = new File("C:\\Users\\ASUS-PC\\Desktop\\新建文件夹\\1.jpg"); FileInputStream in = new FileInputStream(localFile); ServletOutputStream out = resp.getOutputStream(); byte[] b = new byte[1024]; int length = in.read(b); while (length != -1) { out.write(b); length = in.read(b); } out.flush(); out.close(); in.close(); resp.flushBuffer(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
注意:虽然response对象的getOutSream()和getWriter()方法都可以发送响应消息体,但是他们之间相互排斥,不可以同时使用,否则会发生异常。
Response的乱码问题
如果服务端的响应中有中文汉字,则会导致乱码问题
//设置响应的字符集
response.setCharacterEncoding("UTF-8");
//告诉客户端字符集是什么
response.setContentType("text/html;charset=UTF-8");
- 1
- 2
- 3
- 4
35、泛型
所谓泛型,就是允许在定义类,接口时通过一个标识表示类中某个属性的类型或者是某个方法的返回值及参数类型,这个类型参数在创建对象时确定。
泛型的设计背景
集合容器在设计阶段/声明阶段不能确定这个容器中到底实际上存的是什么类型的对象,JDK1.5之前使用Object,以后就都采用泛型,把元素的类型设置成一个参数,这个类型参数就是泛型。
36、Java IO
内容过多,单独整理了一篇 https://blog.csdn.net/weixin_44346035/article/details/99287179
37、Java socket 简单编程
内容过多,单独整理了一篇 https://blog.csdn.net/weixin_44346035/article/details/99340874
38、网络知识总结
内容过多,单独整理了一篇 https://blog.csdn.net/weixin_44346035/article/details/99427602
39、 JSP(Java Server Pages) 和 Servlet (Server Applet)
Servlet是一种独立于平台和协议的服务器端的Java应用程序,可以生成动态的web页面。,JSP是Servlet技术的扩展。
39.1、 JSP和servlet的区别和联系:
JSP是Servlet技术的扩展,本质上就是Servlet的简易方式。JSP编译后是“类servlet”。Servlet和JSP最主要的不同点在于,Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。JSP侧重于视图,Servlet主要用于控制逻辑
39.2、 Servlet的生命周期
- 根据时机,Web容器加载对应的Servlet类,加载后进行init()初始化。
设置了容器启动时初始化(< load-on-startup>标记web容器是否在启动的时候就加载这个servlet 当值为0或者大于0时,表示web容器在应用启动时就加载这个servlet; 当是一个负数时或者没有指定时,则指示容器在该servlet被选择时才加载; 正数的值越小,启动该servlet的优先级越高)
请求第一次请求此Servlet时初始化
Servlet类文件被更新后,重新装载Servlet- 接收到请求,容器根据XML配置将请求交给对应的Servlet,同时创建HttpServletRequest 和 HttpServletResponse 对象,一并交给Servlet。
- 在service()中根据HttpServletRequest得请求类型等信息,调用doGet\doPost 进行业务处理。(
- 处理后通过HttpServletResponse获得相应信息,返回给Web容器。
- Web容器再将响应返回给客户端。
- WEB容器关闭时执行destroy()方法销毁实例。
39.3、 JSP的生命周期
参考 https://www.cnblogs.com/future-liu1121/p/7208392.html
- 客户浏览器给服务器发送一个HTTP请求test.jsp;
- Web服务器识别出这是一个JSP网页的请求,并且将该请求传递给JSP引擎。
- JSP引擎 test.jsp 转译成 test_jsp.java 源文件。同时将 test_jsp.java 源文件编译成 test_jsp.class。编译执行showdate_jsp.class 类,调用_jspInit()方法进行初始化,创建servlet实例
- 执行阶段:调用与jsp对应的servlet实例的_jspService()方法。该方法生成响应HttpServletResponse ,Web服务器将响应返回给浏览器。
- WEB容器关闭时执行_jspDestroy()方法销毁实例。
测试jsp生命周期一段非常典型的代码
<%@ page contentType="text/html;charset=UTF-8" language="java" import="java.util.*" %> <%@ page import="java.text.*" %> <html> <head> <title>我的个人主页</title> </head> <body> <%! private int initVar = 0; private int serviceVar = 0; private int destroyVar = 0; %> <%! public void jspInit(){ initVar++; System.out.println("初始化了"+initVar+"次"); } public void jspDestroy(){ destroyVar++; System.out.println("销毁了"+destroyVar+"次"); } %> <% serviceVar++; System.out.println("请求了多少次"+serviceVar+"次"); String content1 = "初始化的次数:"+initVar; String content2 = "请求的次数:"+serviceVar; String content3 = "销毁的次数:"+destroyVar; %> <h1>测试jsp的生命周期</h1> <p><%=content1%></p> <p><%=content2%></p> <p><%=content3%></p> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
一个简单的JSP转化的Servlet的源码
https://blog.csdn.net/weixin_44346035/article/details/99619903
39.4、 service() 与多线程
servlet 是单例的,当多个请求请求同一个servlet时,需要主要注意线程安全,不过也存在可以不必考虑线程安全的情况。
- 线程安全情况
如果service()方法没有访问Servlet的成员变量也没有访问全局的资源比如静态变量、文件、数据库连接等,而是只使用了当前线程自己的资源,比如非指向全局资源的临时变量、request和response对象等。该方法本身就是线程安全的,不必进行任何的同步控制。
如果service()方法访问了Servlet的成员变量,但是对该变量的操作是只读操作,该方法本身就是线程安全的,不必进行任何的同步控制。- 线程不安全情况
如果service()方法访问了全局的静态变量,如果同一时刻系统中也可能有其它线程访问该静态变量,如果既有读也有写的操作,通常需要加上同步控制语句。
如果service()方法访问了全局的资源,比如文件、数据库连接等,通常需要加上同步控制语句。
39.5、 JSP 内置对象(隐式对象)
参考 https://www.cnblogs.com/liuyangv/p/8059848.html
| 序号 | 对象 | 描述 |
|---|---|---|
| 1 | request对象 | request 对象是 javax.servlet.httpServletRequest类型的对象。 该对象代表了客户端的请求信息,主要用于接受通过HTTP协议传送到服务器的数据。(包括头信息、系统信息、请求方式以及请求参数等)。request对象的作用域为一次请求。 |
| 2 | response对象 | response 代表的是对客户端的响应,主要是将JSP容器处理过的对象传回到客户端。response对象也具有作用域,它只在JSP页面内有效。 |
| 3 | session对象 | session 对象是由服务器自动创建的与用户请求相关的对象。服务器为每个用户都生成一个session对象,用于保存该用户的信息,跟踪用户的操作状态。session对象内部使用Map类来保存数据,因此保存数据的格式为 “Key/value”。 session对象的value可以使复杂的对象类型,而不仅仅局限于字符串类型。 |
| 4 | application对象 | application 对象可将信息保存在服务器中,直到服务器关闭,否则application对象中保存的信息会在整个应用中都有效。与session对象相比,application对象生命周期更长,类似于系统的“全局变量”。 |
| 5 | out 对象 | out对象用于向浏览器输出数据,预制对应的是Servlet的PrintWriter对象,但是这个out对象的类型不是PrintWriter类型,而是JspWriter。jsp输出底层使用的是response.getWriter(),这里需要讲解一下JSP缓存和Servlet缓存,JSP页面转换为Servlet后,使用的out对象是JspWriter类型的,所以是会先将要发送的数据存入JSP输出缓存中,然后,等JSP输出缓存满了在自动刷新到servlet输出缓存,等serlvet输出缓存满了,或者程序结束了,就会将其输出到浏览器上。除非手动out.flush()。 |
| 6 | pageContext 对象 | pageContext 对象的作用是取得任何范围的参数,通过它可以获取 JSP页面的out、request、reponse、session、application 等对象。pageContext对象的创建和初始化都是由容器来完成的,在JSP页面中可以直接使用 pageContext对象。 |
| 7 | config 对象 | config 对象的主要作用是取得服务器的配置信息。通过 pageConext对象的 getServletConfig() 方法可以获取一个config对象。当一个Servlet 初始化时,容器把某些信息通过 config对象传递给这个 Servlet。 开发者可以在web.xml 文件中为应用程序环境中的Servlet程序和JSP页面提供初始化参数。 |
| 8 | page 对象 | page 对象代表JSP本身,只有在JSP页面内才是合法的。 page隐含对象本质上包含当前 Servlet接口引用的变量,类似于Java编程中的 this 指针。 |
| 9 | exception 对象 | exception 对象的作用是显示异常信息,只有在包含 isErrorPage=“true” 的页面中才可以被使用,在一般的JSP页面中使用该对象将无法编译JSP文件。excepation对象和Java的所有对象一样,都具有系统提供的继承结构。exception 对象几乎定义了所有异常情况。在Java程序中,可以使用try/catch关键字来处理异常情况; 如果在JSP页面中出现没有捕获到的异常,就会生成 exception 对象,并把 exception 对象传送到在page指令中设定的错误页面中,然后在错误页面中处理相应的 exception 对象。 |
JSP四大作用域:
request对象、pageContext对象、session对象、application对象
可以通过jstl从作用于中获取值
JSP传递值:
request对象、session对象、application对象 、cookie
page和pageContext区别:
final java.lang.Object page = this;
final javax.servlet.jsp.PageContext pageContext;
- 1
- 2
page对象有点类似于Java编程中的this指针,就是指当前JSP页面本身。page是java.lang.Object类的对象。

pageContext可以获取JSP九大内置对象,相当于使用该对象调用getxxx()方法,
在jsp中可以使用pageContext来设定属性,并指定属性的作用范围,而不用使用个别的pageContext、request、session、
getAttribute(String name, int scope) ,setAttribute(String name, Object value, int scope) , removeAttribute(String name, int scope) , 其中的scope可以使用以下的常数来进行指定:pageContext.PAGE_SCOPE、pageContext.REQUEST_SCOPE、pageContext.SESSION_SCOPE、pageContext.APPLICATION_SCOPE,常数的名称已经直接指明属性范围

40、session cookie
区别和联系:
Cookie和Session都是会话技术,Cookie是运行在客户端,Session是运行在服务器端。
Cookie有大小限制以及浏览器在存cookie的个数也有限制,Session是没有大小限制和服务器的内存大小有关。
Cookie有安全隐患,通过拦截或本地文件可以找得到你的cookie。
Session是保存在服务器端上会存在一段时间才会消失,Cookie也是可以通过在服务端设置它的expires到期时间,
Session的实现Cookie有是有依赖的,到服务端执行Session机制时候会生成Session的id值,这个id值会发送给客户端,客户端会保存在Cookie中,每次请求都会携带Sessionid。
对于sessionid这个Cookie,我试过对于谷歌浏览器关闭浏览器后这个cookie还是会存在,所以关闭当前窗口重新打开一个窗口,这个Cookie还是存在的,还能找到上一个窗口的会话,而IE浏览器关闭这个窗口后,这个Cookie会直接失效。
当客户端禁掉浏览器的Cookie的时候,可以使用URL地址重写,将该用户Session的id信息重写到URL地址中。服务器能够解析重写后的URL获取Session的id。这样即使客户端不支持Cookie,也可以使用Session来记录用户状态。
应用场景:
cookie:
- 当用户在某个网站登录后,服务端可以返回一个登录信息的Cookie,用户下一次访问该应用时,携带此cookie,服务端检查这个cookie后直接将用户的状态改为登录状态,或者每次登录过后,服务端存放一个该用户的session信息,然后返回一个访问这个session的cookie钥匙,用户下一次访问的时候直接拿cookie去找session,找到session就可以切换用户状态了。
- 用户没有登录的购物车信息可以放在cookie中,以便关闭浏览器后购物车里的东西并不会消失。
- 网站可以使用cookie记录用户的意愿。对于页面的设置可以存储在cookie中完成定制。然后下一次访问的时候服务端发现携带了此cookie,就可以返回你曾经定制的页面。
session:
- 在保存用户登录信息,用户登录之后,在服务端生成专属于此用户的一个session。
- 将某些数据放入session中,供同一用户的不同页面使用。
- 用户注销之后,可以将对于的session置空,用户下一次登录的时候只能重新登录

| cookie属性 | 解释 |
|---|---|
| name | 一个cookie的名称。 |
| value | 一个cookie的值。 |
| domain | 可以访问此cookie的域名。 |
| path | 可以访问此cookie的页面路径。 比如domain是abc.com,path是/test,那么只有/test路径下的页面可以读取此cookie。 |
| expires/Max-Age | 此cookie超时时间。若设置其值为一个时间,那么当到达此时间后,此cookie失效。不设置的话默认值是Session,意思是cookie会和session一起失效。当浏览器关闭(不是浏览器标签页,而是整个浏览器) 后,此cookie失效。 |
| Size | 此cookie大小。 |
| http | cookie的httponly属性。若此属性为true,则只有在http请求头中会带有此cookie的信息,而不能通过document.cookie来访问此cookie。 |
| secure | 字段 设置是否只能通过https来传递此条cookie |
41、什么是MVC
MVC-Model-Vew-Controller-模型-视图-控制器
一种软件设计的规范,将数据,显示界面,业务逻辑分离的方式组织代码,这样开发就可以层次分明,专注于一个方面,简化了分组开发,软件的更新修改也会更加简洁方便。
- Model(模型):处理应用程序中数据逻辑的部分,通常就是操作数据库的一些逻辑。
- View(视图):是应用程序中显示处理过的数据的部分,也是程序和用户交互的界面。
- Controller(控制器):是应用程序中处理用户交互的部分。根据所进入的控制器,决定所指向的业务,所处理的数据逻辑。
框架和设计模式的区别
框架是代码重用,设计模式是设计重用。
设计模式是对某种环境中反复出现的问题解决方案的描述,它比框架更抽象。
一个框架往往含有多个设计模式,框架是针对某一特定的应用,组织和构建一个应用。
41、MySQL 数据库
41.1、数据库的分类及常用的数据库
数据库分为关系型数据库和非关系型数据库
- 关系型:MySql、Oracle、SqlServe等。
- 非关系型数据库:Redis、Memcache、mogoDB、Hadoop
41.2、关系数据库的三大范式
什么是范式:为了优化对数据库中数据的操作,数据库设计必须遵循的规范
- 第一范式:是指数据库的每一列都是不可分割的基本数据项,即每一列不能有多个属性或多个列不能有相同的属性。
- 第二范式:要求数据库的每个行必须可以被唯一地区分,属性完全依赖于主键,如果存在部分依赖,需要分离出新表。
比如一个一个订单表:订单号,商品号,订单金额,订单时间,如果保证主键的特性,只能选择主键(订单+商品号),但是这时订单价格和订单时间就对主键只产生部分依赖,就需要分离出新表。- 第三范式:任何非主属性不依赖于其它非主属性,需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如学生表中包含学生基本信息,如果和包括老师,后面又缀加的老师电话,地址等这些属性和学生表的主键学号不是直接相关,那么就需要分离出教师表,使用外键关联两个表。
巴斯-科德范式(BCNF)在3NF基础上,任何非主属性不能对主键子集依赖
反三范式,有时候为了效率,可以设置重复或者可以推导出的字段的字段。
41.3、数据库五大约束
- primary KEY:设置主键约束;
- UNIQUE:设置唯一性约束,不能有重复值;
- DEFAULT 默认值约束
- NOT NULL:设置非空约束,该字段不能为空;
- FOREIGN key :设置外键约束。
41.4、事务的ACID特性
事务是并发控制的单位,是用户定义的一个操作序列,这些操作的集合是不可分割的,要么全部都做,要么一个都不做
| 特性 | 描述 |
|---|---|
| 原子性 Atomicity | 表示事务内操作不可分割,要么都成功,要么都失败 |
| 一致性 Consistency | 要么都成功,要么都失败,失败了要对事务内前面的操作要回滚,保证关系数据的完整性以及业务逻辑上的一致性。 |
| 隔离性 Isolation | 一个事务开始后,不能被其他事物干扰,这里就涉及到隔离级别。 |
| 持久性 Durabuility | 意味着在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。 |
41.5、事务的隔离级别
事物并发的相互影响:脏读,不可重复读,幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交:Read Uncommited | √ | √ | √ |
| 读已提交:Read commited | × | √ | √ |
| 可重复读:Repeatable Read | × | × | √ |
| 可串行化:Serializable | × | × | × |
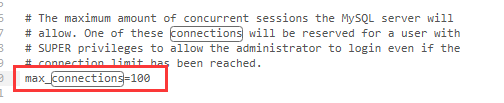
41.6、MySql数据库的默认最大连接数
41.7、MySql触发器
触发器-trigger
触发器:监视某种情况,并触发某种操作。
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询
创建触发器的代码
create
trigger trigger_name
trigger_time trigger_event
on tbl_name for each row
triggrr_body #主体,就是在触发器里干什么事
trigger_time:{ before | after}
trigger_event:{insert | update | delete}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
使用场景:
比如现在有一个订单系统,订单表中一条记录被用户删除,则订单项表中的属于此订单的商品也需要删除,则可以在订单表中记录删除之后执行一个删除订单项的触发器,简化操作。
41.7、MySQL 存储过程
一组预先编译好的SQL语句的集合,可以理解成批处理语句
好处:
- 存储过程只在创建时进行编译,一次创建,重复使用,每次执行不会重复编译,而一般sql语句执行一次编译一次,这样就提高了数据库的执行速度。
- 复杂的业务需要执行多条sql语句,如果一个一个完整的sql执行,势必对网络资源消耗严重,如果放在一个存储过程中,那么传输的数据自然会减少很多,降低了网络负载
- 安全性好,屏蔽了对底层数据库对象的直接访问。
语法
#创建 #******************************************************************** create procedure 存储过程名(参数列表) begin 存储过程体 end #******************************************************************** #调用 #******************************************************************** call 存储过程 (实参列表) #******************************************************************** #参数说明:参数列表包含三部分:参数模式 参数名 参数类型 #参数模式: in:该参数可以作为输入 # out:该参数可以作为输出,也就是作为返回值 # inout:该参数即可以作为输入也可以作为返回值 #******************************************************************** #示例 #声明结束标记为$ #********************************************************************+ delimiter $ #创建存储过程logincheck create procedure logincheck(in username varchar(20),in password varchar(20)) begin declare result int default 0; select count(*)into result from admin where admin.username=username and admin.password=password; select if(result>0,"成功","失败"); end $ #调用 call logincheck("张飞","123456")$
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
42、 JDBC
42.1、 JDBC是什么?
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。
42.2、写一个简单的JDBC程序
加载驱动–获取连接–设置参数–执行–释放连接
import java.sql.*; import static java.sql.DriverManager.getConnection; public class MySQLConnection { public static void main(String[] args) { // 1.导入mysql-connector-java-version.jar 官方下载地址 https://dev.mysql.com/downloads/connector/j/********************************* // 2.加载驱动类com.mysql.jdbc.Driver try { Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundException e) { e.printStackTrace(); } Connection connection = null; PreparedStatement statement = null; ResultSet resultSet = null; try { // 3.获得连接******************************************************************************************************************** connection = getConnection("jdbc:mysql://127.0.0.1:3306/iot", "root", "root"); //执行查询 statement = connection.prepareStatement("select * from test where id = ?"); statement.setInt(1, 1); resultSet = statement.executeQuery(); // 4.从结果集中取出数据*********************************************************************************************************** while (resultSet.next()) { System.out.println(resultSet.getString("name")); } } catch (SQLException e) { e.printStackTrace(); } // 5. 释放资源*********************************************************************************************************************** if (resultSet != null) { try { resultSet.close(); } catch (SQLException e) { e.printStackTrace(); } } if (statement != null) { try { statement.close(); } catch (SQLException e) { e.printStackTrace(); } } if (connection != null) { try { connection.close(); } catch (SQLException e) { e.printStackTrace(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
42.3、 Statement和PreparedStatement的区别
- PreparedStatement中的SQL语句是可以带参数的,避免了拼接SQL语句,代码的可读性和可维护性更高;
- PreparedStatement尽最大可能提高性能,由于数据库可以将编译优化后的SQL语句缓存起来,下次执行相同结构的语句时就会很快。
- 尽大可能的避免了sql注入,极大地提高了安全性,使用预编译语句,你传入的任何内容就不会和原来的语句发生任何匹配的关系.只要全使用预编译语句,你就用不着对传入的数据做过多考虑
42.4、 excute、excuteUpdate、excuteQuery 的使用区别
- excuteQuery:用于查询select语句,返回ResultSet
- excuteUpdate:通常用于update表数据和执行DDL语言,当然insert,delete也可以使用,返回值是int,意义是影响的行数,对于 CREATE TABLE 或 DROP TABLE 等不操作行的语句,executeUpdate 的返回值总为零。
- excute: 可用于执行任何SQL语句,返回一个boolean值,表明执行该SQL语句是否返回了ResultSet。
42.5、 批量操作
PreparedStatement.addBatch()
PreparedStatement.executeBach()
虽然是批量执行,但真实的是一条一条的把SQL发送到SQL服务器执行,而不是把batch的SQL批量发送到服务器
rewriteBatchedStatements的作用:有了这个参数才是真正的批量执行。
使用方式:在jdbcUrl后添加参数rewriteBatchedStatements=true
如果是insert语句,会整合成形如:"insert into xxx_table values (xx),(yy),(zz)…"这样的语句
如果是update\delete语句,满成条件情况下,会整合成形如:"update t set … where id = 1; update t set … where id = 2; …"这样的语句
然后分批次发送给MySQL(会有一次发送的package大小受maxAllowedPacket限制,所以需要拆分批次)
43、数据库连接池的作用
- 限定数据库连接的个数,不会导致由于数据库连接过多导致系统运行缓慢或崩溃。
- 数据库连接不需要每次都去创建或销毁,资源复用。
- 数据库连接不需要每次都去创建,响应时间更快。
在Java中使用得比较流行的数据库连接池主要有:DBCP,c3p0,druid。
使用c3p0连接池写一段示例
import com.mchange.v2.c3p0.ComboPooledDataSource; import java.beans.PropertyVetoException; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; public class C3P0Test { public static void main(String[] args) { //导入c3po-0.9.5.2.jar 和 mchange-commons-java-0.2.11.jar 下载地址:https://sourceforge.net/projects/c3p0/ Connection connection = null; try { /** * c3p0的配置方式分为三种,分别是 * 1.setters一个个地设置各个配置项(不推荐) * 2.类路径下提供一个c3p0.properties文件 * 3.类路径下提供一个c3p0-config.xml文件 */ ComboPooledDataSource dataSource = new ComboPooledDataSource(); dataSource.setDriverClass("com.mysql.jdbc.Driver"); dataSource.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/iot"); dataSource.setUser("root"); dataSource.setPassword("root"); connection = dataSource.getConnection(); PreparedStatement preparedStatement = connection.prepareStatement("select * from test"); ResultSet resultSet = preparedStatement.executeQuery(); while (resultSet.next()) { System.out.println(resultSet.getString("name")); } } catch (SQLException e) { e.printStackTrace(); } catch (PropertyVetoException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
44、Spring MVC的执行流程
整个处理过程从一个HTTP请求开始:
- Tomcat在启动时加载解析web.xml,找到spring mvc的前端总控制器DispatcherServlet,并且通过DispatcherServlet来加载相关的配置文件信息。
- DispatcherServlet接收到客户端请求,找到HandlerMapping,根据映射规则,获得对应的 HandleExecutionChain对象,然后获得 HandlerAdapter对象。
- 调用相应处理器中的处理方法,处理该请求后,会返回一个 ModelAndView。
- DispatcherServlet根据得到的ModelAndView中的视图对象,找到一个合适的 ViewResolver(视图解析器),根据视图解析器的配置,渲染视图,最后显示给用户。
45、Spring 的两大核心
spring是J2EE应用程序框架,是轻量级的IOC和AOP的容器框架,主要针对javaBean的生命周期进行管理的轻量级容器,可以单独使用,也可以和其他框架组合使用
- IOC(Inversion of version) 或 DI (Dependency Injection)
控制反转:它把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”概念就是对组件对象控制权的转移,
核心原理:它是基于工厂设计模式的
Spring IOC的注入
- 通过属性进行注入,通过构造函数进行注入,
- 注入对象数组 注入List集合
- 注入Map集合 注入Properties类型
Spring IOC 自动绑定模式: 可以设置autowire按以下方式进行绑定
- 按byType只要类型一致会自动寻找,
- 按byName自动按属性名称进行自动查找匹配.
- AOP (Aspect Oriented Programming)
面向切面编程:针对业务处理过程中的切面进行提取,处理过程中的某个步骤或阶段,以降低程序的耦合度。主要用在事务处理,权限控制,日志等方面
核心原理:使用动态代码的方式在执行前后或出现异常时做相应处理
46、反射
单独整理了一篇 https://blog.csdn.net/weixin_44346035/article/details/99701073
47、动态代理
单独整理了一篇 https://blog.csdn.net/weixin_44346035/article/details/99709781
48、Stream API
单独整理了一篇 https://blog.csdn.net/weixin_44346035/article/details/99747365
49、ORM是什么
对象关系映射(Object Relational Mapping),为了解决面向对象与关系数据库存在的互不匹配的技术,通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
常用:iBatis(mybatis) , Hibernate
49、iBatis(mybatis) , Hibernate有什么不同
相同点:
都是java的ORM框架,屏蔽jdbc 的底层访问细节,不与jdbc打交道,就可完成对数据库的持久化操作
iBatis的好处:屏蔽jdbc 的底层访问细节,将sql语句与java代码进行了分离,提供了将结果集自动封装为实体对象和对象的集合的功能,提供了自动将实体对象的属性传递给sql语句的参数
Hibernate:全自动的ORM映射工具,它可以自动生成sql语句,并执行并返回结果
不同点:
Hibernate要比iBatis强大很多,因为Hibernate自动生成sql语句
MyBatis需要我们自己在XML配置文件中写sql语句,hibernate我们无法控制该语句,我们就无法写出特定的高效率的sql,对于一些不太复杂的sql查询,Hibernate可以很好的帮我们完成,当时对于特别复杂的查询,Hibernate就很难适应了,这时候iBatis就是很好的选择,因为iBatis是我们自己写的sql语句
iBatis要比Hibernate简单的多,iBatis是面向sql的,不用考虑对象间一些复杂的隐射关系
50 、简单说一下webservice使用的场景
51 、简单介绍一下activity
52、数据库优化
定位:查找,定位慢查询
优化手段
- 创建索引:创建合适的索引,提升数据库的查询速度
- 分表:当一张表的数据比较多或者一张表的某些字段的值比较多并且很少使用,采用水平分表和垂直分表来优化
- 读写分离:当一台服务器不能满足需求时,采用读写分离的方式进行集群
- 缓存:使用redis来进行缓存
- sql优化
52.1、查找慢查询并定位慢查询
- 开启慢查询日志
mysql提供的一种日志记录它用来记录在Mysql中响应时间超过阙值的语句,具体指运行时间超过long_query_time(默认是10秒)的sql,则会被记录到查询日志中。
开启:set global slow_query_log=1;或修改配置文件- mysqldumpslow 慢日志分析工具
使用此工具对日志中的sql进一步筛选- Explain
使用Explain关键字可以模拟优化器执行SQL查询语句,从而知道Mysql是如何处理你的SQL语句。分析你的查询查询语句或是表结构的性能瓶颈。
52.1 优化:数据库设计遵循规范
三范式
52.2 优化:选择合适的存储引擎
各存储引擎的对比

关于常用的myisam/innodb/memory存储引擎的介绍及使用场景
MyISAM和InnoDB对比
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,操作一条记录也会锁住整个表 | 行锁,操作时只锁某一行,适合高并发操作 |
| 缓存 | 只缓存索引,不缓存其他真实数据 | 不仅缓存索引还缓存真实数据,对内存要求较高 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
52.2 优化:选择合适的索引
索引是什么:
索引(index)是帮助MySQL高效获取数据的数据结构
分类:
- 普通索引: index 允许重复的值出现
- 唯一索引:UNIQUE 不能有重复的记录
- 主键索引:PRIMARY KEY 是随着设定主键而创建的,也就是把,某个列设为主键的时候,数据库就会给列创建索引
- 全文索引:FULLTEXT用来对表中的文本域(char varchar text)进行索引
索引的优势和劣势:
| 索引 | 优势和劣势 |
|---|---|
| 优势 | 提高检索的效率,降低数据库的IO成本。 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗 |
| 劣势 | 实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引也是要占用空间的。 虽然索引提高了检索效率,但同时会降低更新表的速度,因为更新表时,Mysql不仅要保存数据,还要保证一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。 |
使用场景
适合建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段
- 查询中与其他表关联的字段,外键关系建立索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或分组字段
不适合建索引
- 表记录太少
- 经常增删改查的表
- 数据重复且分布平均的表字段(比如性别、国籍)
- 频繁更新的字段
- where条件里用不到的字段
索引使用技巧:防止索引失效
| 防止索引失效 | |
|---|---|
| 1.全值匹配我最爱 | |
| 2.最佳左前缀法则 | 如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列(想象成火车头) |
| 3.不在索引列上做任何操作 | 计算、函数、自动或手动类型转换,会导致索引失效而转向全表扫描 |
| 4.存储引擎不能使用索引中范围条件右边的列 | 范围之后全失效 |
| 5.尽量使用覆盖索引 | 只访问索引的查询(索引列和查询列一致)减少select |
| 6.mysql在使用不等于的时候无法使用索引会导致全表扫描 | |
| 7.is null 、is not null也无法使用索引 | |
| 8.like以通配符开头索引也会失效 | 通配符只放like字符串右边可以使用索引解决%字符串%索引不被使用的放方法:覆盖索引 |
| 9.字符串不加单引号索引失败 | 如果不加引号,会隐式进行类型转换 |
| 10.少用or,用or也会导致索引失效 |
52.3、 优化:数据库分表
52.4、优化:数据库读写分离

一主对从或者一主一从,主节点负责读写操作,从节点负责读操作。
主从分离的实现:
- 数据库搭建主从集群,一主多从或者一主一从
- 主机负责读写操作,从机负责读操作
- 主机通过复制将数据同步到从机,从而使每一个数据库都保证数据的一致性
主从同步的具体原理:
- 将主机的数据复制到多个从机(slaves)中,同步过程中,主机将数据库的操作写到二进制日志(binary log)中,从机打开一个io线程,打开和主机的连接,并将主机的更新日志写入从机的中继日志中,
- 从机开一个sql线程读取中继日志中的数据,进行更新,从而保证数据的主从数据的一致。
52.5、 优化:数据库缓存
53 、mysql 使用存储过程批量插数据
54、redis的使用场景
| 应用场景 | |
|---|---|
| 缓存 | 缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以,现在Redis用在缓存的场合非常多。 |
| 排行榜 | 很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。 |
| 计数器 | 什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。 |
| 分布式会话 | 集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。 |
| 分布式锁 | 在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应用中要考虑的细节要更多。 |
| 社交网络 | 点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。 |
| 最新列表 | Redis列表结构,LPUSH可以在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,这样列表永远为N个ID,无需查询最新的列表,直接根据ID去到对应的内容页即可。 |
| 消息系统 | 消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。 |
55、redis对象保存方式
- Json字符串:
需要把对象转换为 json字符串,当做字符串处理。直接使用 set get来设置或者或。
优点:设置和获取比较简单
缺点:没有提供专门的方法,需要把把对象转换为 json。(jsonlib)- 字节:
需要做序列号,就是把对象序列化为字节保存。
如果是担心 JSON转对象会消耗资源的情况,这个问题需要考量几个地方,
第一点:就是使用的 JSON转换 lib是否就会存在性能问题。
第二点:就是数据的数据量级别,如果是存储百万级的大数据对象,建议采用存储序列化对象方式。如果是少量的数据级对象,或者是数据对象字段不多,还是建议采用 JSON转换成String方式。毕竟 redis对存储字符类型这部分优化的非常好。
Redis存取java对象,用hash哈希命令保存对象的各个属性和采用String字符串命令保存序列化后的对象之开销对比
56、redis数据淘汰机制
57、redis集群
Redis的复制(Master/Slave)
| 是什么 | 行话:只从复制,主机数据更新后根据配置和策略,自动同步的复制到备机的master/slaver机制,Master以写为主,Slave以读为主 |
| 能干嘛 | 读写分离 容灾恢复 |
| 怎么玩 | 配从库不配主库 从库配置:slaveof 主库ip 主库端口:每次与master断开之后,需要重写连接,除非你配置进redis.conf文件 info replication 查看身份状态master/sla ve,slave不能写只能读。 |
| 常用三招 | 一主二仆:如果主机down掉,备机保持原来的saver身份 薪火相传:上一个slave可以是下一个slave的master,slave同时可以接受其他slaves的连接和同步请求,那么该slave作为子链条中下一个slave的master,可以有效减轻master的写压力。中途变更转向会清除之前的数据,重写建立拷贝最新的slaveof新主库ip新主库端口。 反客为主:slaveof no one 使当前数据库停止与其他数据库的同步,转成主数据库 |
| 复制原理 | slave启动成功连接到master后会发送一个sync命令 master接到命令后启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台全部执行完毕之后,master将传送整个数据文件到slave,完成一次完全同步 全量复制:slave服务在接受到数据库文件数据后,将其存盘并加载到内存中。 增量复制:master继续将新的所有收集到的修改命令一次传送给slave,完成同步 但是只要是重新连接master,一次完全同步(全量复制)将自动执行。 |
| 哨兵模式(sentinel) | 自定义sentinel.conf文件 名字绝不能错。 sentinel.conf文件中填写内容:sentinel monitor 被监控数据库名字(自己起一个名字) host port 1(1是票数,表示主机挂掉后slave投票看谁接替成为主机,得票数多少后成为主角。 启动哨兵:redis-sentinal sentinel.conf 如果之前的master重启回来,会成为新master的slave sentinel能同时监控多个master |
| 缺点 | 复制延时:由于所有的写操作都现在master上操作,然后同步更新到slave上,所以从master同步到slave机器有一定的延迟,当系统很忙的时候,或slave机器数量增加,这个问题就会更加严重 |
58、XML和Json的特点
Xml特点: 1、有且只有一个根节点; 2、数据传输的载体 3、所有的标签都需要自定义 4、是纯文本文件
Json(JavaScript Object Notation)特点:json分为两种格式:
json对象(就是在{}中存储键值对,键和值之间用冒号分隔,键值对之间用逗号分隔);
json数组(就是[]中存储多个json对象,json对象之间用逗号分隔) (两者间可以进行相互嵌套)数据传输的载体之一
区别:
- 传输同样格式的数据,xml需要使用更多的字符进行描述,
- 流行的是基于json的数据传输。
- xml的层次结构比json更清晰。
共同点:
- xml和json都是数据传输的载体,并且具有跨平台跨语言的特性。
59、Java的基本数据类型
String不是基本数据类型,大小有所限制。
String内部使用一个char[]数组来存放字符串的内容,数组下标是整型(也可以参考String的构造方法String(char value[], int offset, int count) ,可以知道字符数量是用整型表示),整型(Java规定32位)表示范围是2G,也就是说,Java数组最大的长度是2G,即字符串不能超过2G个字符。
Java的数组大小还有没有别的限制?事实上数组大小不能超过Java堆的大小,而Java堆的最大尺寸可以通过启动参数指定,如果Java堆开得足够大,数组的最大长度是可以不断增大的。
所以,理论上,字符串不能超过2G个字符,少于2G个字符都有可能。
但编码时有需要注意的地方,采用明文的方式,如果超过65534个字节,可能报编译错误。
60、排序算法
单独整理的 https://blog.csdn.net/weixin_44346035/article/details/98526726
61、AJAX
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。

原生ajax(XMLHttpRequest、XMLHttpResponse) https://www.runoob.com/ajax/ajax-xmlhttprequest-create.html
使用jquery的ajax
$.ajax({ type:"post",//type可以为post也可以为get url:"/demo2", data:{"username":username},//这行不能省略,如果没有数据向后台提交也要写成data:{}的形式 dataType:"json",//这里要注意如果后台返回的数据不是json格式,那么就会进入到error:function(data){}中 success:function(data){ $("#username-info").css("display","block"); if(data.availiable==="0"){ $("#username-info").css("color","green"); }else{ $("#username-info").css("color","red"); } $("#username-info").val(data.info); }, error:function(data){ alert("用户名提交出现了错误!"); } });
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
62、java Exception体系结构
java异常是程序运行过程中出现的错误。Java把异常当作对象来处理,并定义一个基类java.lang.Throwable作为所有异常的超类。
在JavaAPI中定义了许多异常类,分为两大类,错误Error和异常Exception。
其中异常类Exception又分为运行时异常(RuntimeException)和非运行时异常(非runtimeException),也称之为不检查异常(Unchecked Exception)和检查异常(Checked Exception)。
Error与Exception
继承结构:Error和Exception都是继承于Throwable,RuntimeException继承自Exception。
Error和RuntimeException及其子类称为未检查异常(Unchecked exception),其它异常成为受检查异常(Checked Exception)。
Error是程序无法处理的错误,比如OutOfMemoryError、StackOverFlowError、ThreadDeath等。
这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
Exception是程序本身可以处理的异常,这种异常分两大类运行时异常和非运行时异常。程序中应当尽可能去处理这些异常。
运行时异常和非运行时异常
- 运行时异常: 都是RuntimeException类及其子类异常:这些异常是不检查异常(Unchecked Exception),程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,如
- IndexOutOfBoundsException 索引越界异常
- ArithmeticException:数学计算异常
- NullPointerException:空指针异常
- ArrayOutOfBoundsException:数组索引越界异常
- ClassNotFoundException:类文件未找到异常
- ClassCastException:造型异常(类型转换异常)
- 非运行时异常:是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如:
- IOException、文件读写异常
- FileNotFoundException:文件未找到异常
- EOFException:读写文件尾异常
- MalformedURLException:URL格式错误异常
- SocketException:Socket异常
- SQLException:SQL数据库异常
throw与throws的比较
- throws出现在方法函数头;而throw出现在函数体。
- throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常。
- 两者只是抛出或者可能抛出异常,但是不会去处理异常,真正的处理异常由函数的上层调用处理。
try、catch、finall经典题
public class Test { /** * 在try{}中,在执行 a = 2/0 语句时,发生异常,跳到catch{}中,执行a++,之后a变为1, * 执行return语句之前,catch{}中会把当前a值保存起来,然后跳到finally{}中,执行完finally之后,再回到catch{}中取出a,再执行return语句。 * 因此,即使finally中对变量a进行了改变,也不会影响返回结果。 */ public static int f() { int a = 0; try { a = 2 / 0; return a; } catch (Exception e) { a++; return a + 1; } finally { System.out.println(a);// 输出 1 a = 5; } } public static void main(String[] args) { System.out.println(f()); //输出 2 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
63、 接口和抽象类的区别
| 参数 | Abstract类 | 接口 |
|---|---|---|
| 默认的方法实现 | 可以有默认的方法实现 | 根本不存在方法的实现,除default外 |
| 实现 | 子类通过extends继承抽象类,如果父类是abstract方法,子类必须重写该方法(子类非抽象类的情况) | 子类通过implements来实现接口,必须实现接口的所有方法(子类非抽象类的情况) |
| 构造器 | 抽象类可以有构造器 | 无 |
| 变量 | 没有限制 | 隐式为public static finall |
| 访问修饰符 | public、protected、default(final一定不能使用) | public |
| main方法 | 有,可以运行 | 无 |
| 多继承 | 抽象类可以继承一个类,实现多个接口 | 接口可以实现多个接口 |
| 添加方法 | 你可以提供默认的实现,不需要修改实现类 | 需要修改所有实现该接口的接口或类,并在其中重写该方法 |
抽象类可以没有抽象方法,但是有抽象方法的类必须定义为抽象类,如果子类继承一个抽象类且子类不为抽象类,那么必须重写抽象类的abstract方法。
Java 8中引入了一个新的概念,叫做default方法,也可以称为Defender方法,或者虚拟扩展方法(Virtual extension methods)。default方法是指,在接口内部包含了一些默认的方法实现(也就是接口中可以包含方法体),从而使得接口在进行扩展的时候,不会破坏与接口相关的实现类代码
如果一个类实现了两个接口,这两个接口又同时包含了一个相同名字的default方法,那么当这个类必须重写这个同名方法,否则会报错。
什么时候用抽象类,什么时候用接口?
使用抽象类更多是为了代码的复用,使用接口更多为了多态性
64、 Java访问控制符和修饰符
1. Java访问控制符的含义和使用情况
| 类内部 | 同包 | 子类 | 外包 | |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | |
| default(friendly) | √ | √ | √仅限于同包子类) | |
| private | √ |
2. 类
| 修饰符 | 描述 |
|---|---|
| public | 公共的,对所有包可见 |
| default | 同包可以访问 —除了以上两个,在类的修饰符中还可以加入以下二个 |
| abstract | 抽象类,需要继承,不能直接实例 |
| final | 最终类,不能被继承 |
3. 变量
| 修饰符 | 描述 |
|---|---|
| public | 可以被任何类访问 |
| protected | 可以被所有子类或同包下的类访问 |
| 缺省 | 只能被当前类的方法访问 |
| private | 只允许自己的类访问 |
| static | 类变量,可以被类的所有实例共享,并不需要创建类的实例就可以访问 |
| final | 值只能够分配一次,不可更改 |
| volatile | 多线程修改使用(可见性,不可重排性) |
| transient | 告诉编译器,在该对象序列化的时候,此变量不需要长久保存 |
4. 方法
| 修饰符 | 描述 |
|---|---|
| public | 共有的 |
| protected | 同包可以访问 |
| private | 私有,本类使用 |
| 缺省 | (无访问修饰符) 同包可以访问(子类如不在同一包下,也不能访问) |
| static | 静态方法又称为类方法 提供不依赖于类实例的服务 |
| final | 阻止任何子类重写该方法 |
| abstract | 抽象方法 声明而不实现,不能将static final方法或者类的构造器声明为abstract |
| native | 在类中没有实现,大多数的情况下是由C、C++编写的(JNI提供了运行时加载一个native 方法的实例,并将其于一个Java类关联) |
| synchronized | 异步调用 |

65、内部类
1、大部分时候,类被定义成一个独立的程序单元。在某些情况下,也会把一个类放在另一个类的内部定义,这个定义在其他类内部的类就被称为内部类(有些地方也叫做嵌套类),包含内部类的类也被称为外部类(有些地方也叫做宿主类)
2、每个类会产生一个.class文件,文件名即为类名。同样,内部类也会产生这么一个.class文件,但是它的名称却不是内部类的类名,而是有着严格的限制:外围类的名字,加上$,再加上内部类名字。
1. 成员内部类

虽然成员内部类可以无条件地访问外部类的成员,而外部类想访问成员内部类的成员却不是这么随心所欲了。在外部类中如果要访问成员内部类的成员,必须先创建一个成员内部类的对象,再通过指向这个对象的引用来访问
2. 静态内部类
1、静态类和方法只属于类本身,并不属于该类的对象,更不属于其他外部类的对象。
2、静态的内部类中不能访问外部类中非静态的变量和方法。因为在没有外部类的对象的情况下,可以创建静态内部类的对象,如果允许访问外部类的非static成员就会产生矛盾,因为外部类的非static成员必须依附于具体的对象。
3、在非静态内部类中不可以声明静态成员,只有将某个内部类修饰为静态类,然后才能够在这个类中定义静态的成员变量与成员方法。
4、对于静态内部类我们可能在平时的编程环境中不多见,但是在某些项目中,很多都使用了静态内部类,这种场景一般针对于静态内部类不需要外部类的资源,而外部类需要使用内部类的时候。


3. 局部内部类
局部内部类就像是方法里面的一个局部变量一样,是不能有public、protected、private以及static修饰符的。

4. 匿名内部类
1、使用匿名内部类能够在实现父类或者接口中的方法情况下同时产生一个相应的对象,但是前提是这个父类或者接口必须先存在才能这样使用
2、匿名内部类在编译的时候由系统自动起名为Outter$1.class。一般来说,匿名内部类用于继承其他类或是实现接口,并不需要增加额外的方法,只是对继承方法的实现或是重写。

66、switch参数类型
JDK1.7 数据类型接受 byte short int char enum(枚举),String 六种类型
switch挖掘底层 https://www.jianshu.com/p/c46f6fff17cb
67、mysql数据导入导出
- 导出整个数据库
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
mysqldump -u dbuser -p dbname > dbname.sql- 导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u dbuser -p dbname users> dbname_users.sql- 导出一个数据库结构
mysqldump -u dbuser -p -d dbname >d:/dbname_db.sql- 导入数据库
常用source 命令
进入mysql数据库控制台,如
mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source dbname.sql
57、线程概述

线程的状态以及状态之间的相互转换:
- 新建状态(New):新创建了一个线程对象。
- 就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
- 运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
- 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
(一)、等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。
(二)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
(三)、其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。- 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
wait和sleep的区别:
| wait | sleep |
|---|---|
| 在java.lang.Thread类中,提供了sleep() | 而java.lang.Object类中提供了wait(), 还有notify()和notifyAll()方法来操作线程 |
| 调用sleep 不会释放对象锁 | 调用wait失去了对象锁 |
| 必须要采用notify()和notifyAll()方法唤醒该进程,或者指定的时间已过 | 表示让一个线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可运行状态,不会马上进入运行状态,因为线程调度机制恢复线程的运行也需要时间 |
| 不需要捕获异常 | 需要捕获异常 |
| wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用 | sleep可以在任何地方使用 |
| void wait() void wait(long timeout) | sleep(long millis) sleep(long millis, int nanos) |
Thread的join方法:
当我们调用某个线程的这个方法时,这个方法会挂起调用线程,直到被调用线程结束执行,调用线程才会继续执行。
public class Test3 { public static void main(String[] args) { Thread smart = new Thread(() -> { try { Thread.sleep(3000);} catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + " start"); }, "smart"); Thread big = new Thread(() -> { try { smart.join(2000); } catch (InterruptedException e) { e.printStackTrace(); } //try { smart.join(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + " start"); }, "big"); smart.start(); big.start(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:
big start
smart start
public class Test3 { public static void main(String[] args) { Thread smart = new Thread(() -> { try { Thread.sleep(3000);} catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + " start"); }, "smart"); Thread big = new Thread(() -> { //try { smart.join(2000); } catch (InterruptedException e) { e.printStackTrace(); } try { smart.join(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + " start"); }, "big"); smart.start(); big.start(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出:
smart start
big start
线程与进程的区别:
- 线程(Thread)与进程(Process)
进程定义的是应用程序与应用程序之间的边界,通常来说一个进程就代表一个与之对应 的应用程序。不同的进程之间不能共享代码和数据空间,而同一进程的不同线程可以共享代码和数据空间。- 一个进程可以包括若干个线程,同时创建多个线程来完成某项任务,便是多线程。
58、synchronized和与Lock的区别
| 特征 | 描述 |
|---|---|
| 层次 | Lock是一个接口,而synchionized是java中的关键字 |
| 用法 | synchionized既可以加在方法上,也可以加在特定的代码块上,括号中表示锁的对象,而Lock需要显示的指定起始位置和终止位置 |
| 可重入锁 | 都是可重入锁 |
| 可中断锁 | synchionized不是可中断锁,而Lock是可中断锁 |
| 非公平锁 | synchionized是非公平锁,无法保证等待的线程获取锁的顺序,Lock默认是非公平的,但是可以构造成公平锁。 |
| 锁的机制 | synchionized获得锁和释放锁的方式都是在快结构中,而且是自动释放锁,而Lock需要开发人员手动去释放,而且必须在finally块中释放,否则会引起死锁问题的产生 |
| 异常 | synchionized在发生异常时,会自动释放线程占有的锁,而Lock在发生异常时,不会自动释放锁,必须手动释放 |
59、什么是面向对象?
现实世界中的对象是客观存在的实体和主观抽象的概念,一件事情的发展或者解决事情的途径都是依赖于各个元素。如果我们能把从事的操作附着在对象之上并能够设置或改变对象的状态。任何问题域都对应一系列的对象,因此解决问题的基本方式是让这些对象之间相互驱动、相互调用。
| 面向对象的特征 | 描述 |
|---|---|
| 抽象 | 抽象就是找出一些事物的相似和共性之处,然后将这些事物归为一个类,这些类只考虑这些事物的相似和共性之处,而且会忽略掉与当前主题和目标无关的那些方面。包括两种抽象:第一种是数据抽象,也就是对象的属性。第二种是过程抽象,也就是对象的行为特征 |
| 继承 | 继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。提高了软件的可重用性和可扩展性。 |
| 封装 | 封装是指将某个实体的属性和行为封装在一个模块中,对外隐藏了内部特征和行为,外界对实体私有属性或方法的访问只能通过提供的用户接口实现,使得对象高度封闭,高度自治。 |
| 多态 | 多态性是指允许相同或不同子类型的对象对同一消息作出不同响应,程序中定义的引用变量所指向的具体类型并不确定,即一个引用变量指向不同的类的实例对象,就可能赋予不同的属性和行为。即程序可以选择多种运行状态。提高了可替换、可扩充、灵活的接口特性。 |
60、 面向对象和面向过程的区别?
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了;面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
蛋炒饭和盖浇饭,细细体会(*▽*)
61、什么是编译器常量?使用它有什么风险?
public static final int a = 10就是一个编译时常量,在编译后的符号中找不到a,所有对a的引用都被替换成了20;它是不依赖于类的,在编译时就可以确定值。
public static final int b = “hello”.length()就是一个运行时常量;它是依赖于类的,它的赋值会引起类的初始化。
风险:
编译时常量,在使用时会被直接写成值,而不会再从原来的类中读取。这样就会导致问题的产生:如果A类定义了常量,B类使用了常量,并且都进行了编译。当A类的源码被改动了,常量的值发生了变化。我们对A类进行了重新编译,但是没有对B类进行重新编译;那么B类中用到的是原来A类中的常量值,即旧值。这就导致了风险的发生。
62、泛型
泛型,即“参数化类型”。就是将类型由原来的具体的类型参数化,此时类型也定义成参数形式(可以称之为类型形参),
然后在使用/调用时传入具体的类型(类型实参)。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
63、什么是迭代器(Iterator)
就是提供一种方法对一个容器对象中的各个元素进行访问,而又不暴露该对象容器的内部细节。
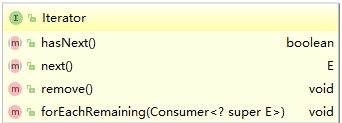
1.java.util.Iterator
2.java.util.Iterable
Java中还提供了一个Iterable接口,Iterable接口实现后的功能是‘返回’一个迭代器,我们常用的实现了该接口的子接口有:Collection、List、Set等。该接口的iterator()方法返回一个标准的Iterator实现。实现Iterable接口允许对象成为Foreach语句的目标。就可以通过foreach语句来遍历你的底层序列。
3.Iterator遍历时不可以删除集合中的元素问题
在使用Iterator的时候禁止对所遍历的容器进行改变其大小结构的操作。例如: 在使用Iterator进行迭代时,如果直接对集合进行了add、remove操作就会出现ConcurrentModificationException异常。只能使用迭代器进行删除。
通过查看源码发现原来检查并抛出异常的是checkForComodification()方法。在ArrayList中modCount是当前集合的版本号,每次修改(增、删)集合都会加1;expectedModCount是当前迭代器的版本号,在迭代器实例化时初始化为modCount。我们看到在checkForComodification()方法中就是在验证modCount的值和expectedModCount的值是否相等,所以当你在调用了ArrayList.add()或者ArrayList.remove()时,只更新了modCount的状态,而迭代器中的expectedModCount未同步,因此才会导致再次调用Iterator.next()方法时抛出异常。但是为什么使用Iterator.remove()就没有问题呢?通过源码的第32行发现,在Iterator的remove()中同步了expectedModCount的值,所以当你下次再调用next()的时候,检查不会抛出异常。
使用该机制的主要目的是为了实现ArrayList中的快速失败机制(fail-fast),在Java集合中较大一部分集合是存在快速失败机制的。
快速失败机制:是java集合(Collection)中的一种错误检测机制。当多个线程对Collection进行操作时,若其中某一个线程通过Iterator遍历集合时,该集合的内容发生改变,则会抛出ConcurrentModificationException异常。
顺便说一下fafail-safe:采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先copy原有集合内容,在拷贝的集合上进行遍历.由于迭代时是对原集合的拷贝的值进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以出现并发修改异常。
所以要保证在使用Iterator遍历集合的时候不出错误,就应该保证在遍历集合的过程中不会对集合产生结构上的修改。
使用Foreach时对集合的结构进行修改会出现异常:
上面我们说了实现了Iterable接口的类就可以通过Foreach遍历,那是因为foreach要依赖于Iterable接口返回的Iterator对象,所以从本质上来讲,Foreach其实就是在使用迭代器,在使用foreach遍历时对集合的结构进行修改,和在使用Iterator遍历时对集合结构进行修改本质上是一样的。所以同样的也会抛出异常,执行快速失败机制。
4.List的安全删除
import org.junit.Test; import java.util.ArrayList; import java.util.Collections; import java.util.Iterator; import java.util.List; public class ListTest { @Test public void test1() { List<Integer> intList = new ArrayList<Integer>(); Collections.addAll(intList, 1, 2, 3, 5, 6); for (int i = 0; i < intList.size(); i++) { Integer value = intList.get(i); // 符合条件,删除元素 if (value == 3 || value == 5) { intList.remove(i); } } System.out.println(intList); } /** * 输出:[1, 2, 5, 6],漏掉了5这个元素, * 当i=2的时候,值为3,删除后,后面的元素往前补一位, * 这时i=3的时候,值为6,跳过了5,这样也不行 */ @Test public void test2() { List<Integer> intList = new ArrayList<Integer>(); Collections.addAll(intList, 1, 2, 3, 5, 6); // for循环优化写法,只获取一次长度 for (int i = 0, size = intList.size(); i < size; i++) { Integer value = intList.get(i); // 符合条件,删除元素 if (value == 3 || value == 5) { intList.remove(i); } } System.out.println(intList); } /** * 执行后,会抛出IndexOutOfBoundsException, * 因为集合中存在符合条件的元素,删除后,集合长度动态改变, * 由于长度只获取一次,发生越界, */ @Test public void test3() { List<Integer> intList = new ArrayList<Integer>(); Collections.addAll(intList, 1, 2, 3, 5, 6); //使用增强for循环 for (Integer value : intList) { // 符合条件,删除元素 if (value == 3 || value == 5) { intList.remove(value); } } System.out.println(intList); } /** * 执行后,会抛出ConcurrentModificationException,字面意思是并发修改异常 * 可以大概看出是执行到AbstractList中内部类Itr的 checkForComodification 方法抛出的异常 * 原因在上面第三小节有所陈述 */ @Test public void test4() { List<Integer> intList = new ArrayList<Integer>(); Collections.addAll(intList, 1, 2, 3, 5, 6); //使用迭代器 Iterator<Integer> it = intList.iterator(); while (it.hasNext()) { Integer value = it.next(); if (value == 3 || value == 5) { it.remove(); } } System.out.println(intList); } /** * 输出正确结果:[1, 2, 6]。 */ @Test public void test5() { List<Integer> intList = new ArrayList<Integer>(); Collections.addAll(intList, 1, 2, 3, 5, 6); //还有种取巧的方式是从最后一个元素开始遍历,符合条件的删除 for (int i = intList.size() - 1; i >= 0; i--) { Integer value = intList.get(i); if (value == 3 || value == 5) { intList.remove(i); } } System.out.println(intList); } /** * 输出正确结果:[1, 2, 6]。 */ }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
64、Java中Runnable和Callable
- 相同点:
两者都可用来编写多线程程序的接口;
两者都需要调用Thread.start()启动线程;- 不同点:
两者最大的不同点是:实现Callable接口的任务线程能返回执行结果;而实现Runnable接口的任务线程不能返回结果;
Callable接口的call()方法允许抛出异常;而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛;- 注意点:
Callable接口支持返回执行结果,此时需要调用FutureTask.get()方法实现,此方法会阻塞主线程直到获取‘将来’结果;当不调用此方法时,主线程不会阻塞!
65、Future和FutureTask
Future是一个接口,代表可以取消的任务,并可以获得任务的执行结果
实现了Future和runnable接口
实现runnable接口,说明可以把FutureTask实例传入到Thread中,在一个新的线程中执行。
实现Future接口,说明可以从FutureTask中通过get取到任务的返回结果,也可以取消任务执行(通过interreput中断)
构造方法
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
//对于传入的Runnable,会转化为Callable
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
FutureTask可用于异步获取执行结果或取消执行任务的场景。通过传入Runnable或者Callable的任务给FutureTask,直接调用其run方法或者放入线程池执行,之后可以在外部通过FutureTask的get方法异步获取执行结果,因此,FutureTask非常适合用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。另外,FutureTask还可以确保即使调用了多次run方法,它都只会执行一次Runnable或者Callable任务,或者通过cancel取消FutureTask的执行等
import java.util.concurrent.ExecutionException; import java.util.concurrent.FutureTask; public class FutureTaskTest { public static void main(String[] args) { FutureTask futureTask = new FutureTask(() -> { System.out.println(Thread.currentThread().getName()); }, 1); new Thread(futureTask).start(); new Thread(futureTask).start(); try { System.out.println(futureTask.get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } /** * 输出 * Thread-0 * 1 */ }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
66、多线程中的死锁
1. 什么是死锁
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
2. 产生原因
- 竞争有限资源引起进程死锁
- 进程推进顺序不当引起死锁
3. 死锁的产生条件
- 互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
- 请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
- 不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
- 环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
4. 可剥夺资源和不可剥夺资源
- 可剥夺资源,是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺。例如,优先权高的进程可以剥夺优先权低的进程的处理机。又如,内存区可由存储器管理程序,把一个进程从一个存储区移到另一个存储区,此即剥夺了该进程原来占有的存储区,甚至可将一进程从内存调到外存上,可见,CPU和主存均属于可剥夺性资源。
- 不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
5. 临时资源
上面所说的打印机资源属于可顺序重复使用型资源,称为永久资源。还有一种所谓的临时资源,这是指由一个进程产生,被另一个进程使用,短时间后便无用的资源,故也称为消耗性资源,如硬件中断、信号、消息、缓冲区内的消息等,它也可能引起死锁。
6. 预防死锁
只要打破四个必要条件之一就能有效预防死锁的发生:
- 打破互斥条件:改造独占性资源为共享资源,这是由资源本身的属性决定的,没有实用价值。
- 打破请求与保持条件:采用资源预先分配策略,即进程运行前申请全部资源,满足则运行,不然就等待。运行过程中逐步释放已经使用完毕的资源。
- 打破不可剥夺条件:已持有资源的进程在提出新的资源请求没有得到满足时,它必须释放已经保持的所有资源,以后需要使用时重新申请。
- 打破循环等待条件:实现资源有序分配策略,对所有设备实现分类编号,所有进程只能采用按序号递增的形式申请资源。
7. 解决办法
- 死锁预防。
这是一种较简单和直观的事先预防的方法。方法是通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或者几个,来预防发生死锁。如5所示。- 死锁避免。
系统对进程发出的每一个系统能够满足的资源申请进行动态检查,并根据检查结果决定是否分配资源;如果分配后系统可能发生死锁,则不予分配,否则予以分配。这是一种保证系统不进入死锁状态的动态策略。
银行家算法 https://blog.csdn.net/jianbai_/article/details/91358114- 死锁检测。
先检测:通过系统所设置的检测机构,及时地检测出死锁的发生,并精确地确定与死锁有关的进程和资源。- 死锁解除
1、抢占资源:从一个或多个进程中抢占足够数量的资源分配给死锁进程,以解除死锁状态。
2、终止(或撤销)进程:终止或撤销系统中的一个或多个死锁进程,直至打破死锁状态。

