- 1windows 查看端口占用并删除_netstat -ano | findstr 端口清空
- 2org.apache.poi Excel列与行都是动态生成的_99%的人不知道怎么利用Excel里的函数和技巧来偷懒...
- 3AAAI 2020 | 多模态基准指导的生成式多模态自动文摘_多模态多输出摘要生成
- 4力扣 在LR字符串中交换相邻字符(双指针)
- 5XTuner 大模型单卡低成本微调实战笔记_xtuner 单卡低成本微调大模型
- 6基于stm32智能取药柜物联网嵌入式软硬件开发单片机毕业源码案例设计_stm32自动取药系统
- 7navicat oracle调试器,Oracle PL/SQL 调试器 - Navicat 15 for Linux 产品手册
- 8Android 抛弃IMEI改用ANDROID_ID_android10 imei取消
- 9docker 部署带有界面的registry仓库_registry ui
- 10C++箴言:理解typename的两个含义_c++中typename是啥意思
OpenAI 最近发布的 GPT-4o 模型,作为其自然语言处理技术的最新突破,标志着人工智能领域的一个新纪元。
赞
踩
2024年5月14日,OpenAI推出了其最新的旗舰模型——**GPT-4o**。不同于传统的AI搜索引擎或预期中的GPT-5,GPT-4o在功能上取得了重大突破,将文本、视觉和音频理解融合在一个模型中。让我们深入了解这一革命性的AI。
“o”代表什么?
GPT-4o中的“o”代表“omni”,象征其全能的能力。与以往的模型相比,GPT-4o在视觉和音频理解方面表现尤为突出。它可以实时处理文本、音频和视觉输入,接受这些模态的任意组合,并生成相应的输出。令人惊叹的是,它的响应时间仅为232毫秒,接近人类的对话速度。
从Voice Mode到GPT-4o
在GPT-4o之前,用户可以使用Voice Mode与ChatGPT进行交互,但平均延迟为2.8秒(对于GPT-3.5)和5.4秒(对于GPT-4)。这个过程包括将音频转录为文本,由GPT-3.5或GPT-4处理文本,然后再将输出转换回音频。然而,这种方法会丢失关键信息,如音调、多个说话者、背景噪音以及细微的表情,比如笑声或歌唱。
GPT-4o:端到端解决方案
GPT-4o是一个端到端的解决方案,将文本、视觉和音频处理无缝集成在一起。现在,所有输入和输出都通过一个神经网络处理。这是一个重要的里程碑——首个结合这些模态的模型。OpenAI继续探索模型的功能和局限性。
发布会要点
新款 GPT-4o 模型:实现了任何文本、音频和图像输入的无缝对接,可直接生成相应的输出,无需中间转换。
GPT-4o 的语音延迟显著降低,能在 232 毫秒内回应音频输入,平均响应时间为 320 毫秒,这与人类对话的响应时间相似。
GPT-4 向所有用户免费开放。
GPT-4o API,比 GPT-4 Turbo 快 2 倍,价格低 50%。
惊艳的实时语音助手演示:对话更加拟人化、能实时翻译,识别表情,并能通过摄像头识别画面、编写代码、分析图表。
ChatGPT 新 UI,更加简洁。
新的 ChatGPT 桌面应用程序,适用于 macOS,Windows 版本将在今年晚些时候推出。
这些功能在预热阶段已被 Altman 形容为“感觉像魔法”。既然全球的 AI 模型都在“赶超 GPT-4”,OpenAI 也要展示其真正的实力。
免费的 GPT-4o 来了,但这不是其最大的亮点
实际上在发布会前一天,我们发现 OpenAI 已经悄悄地将 GPT-4 的描述从“最先进的模型”修改为“先进的”。
这是为了迎接 GPT-4o 的到来。GPT-4o 的强大之处在于它可以接受任何文本、音频和图像的组合输入,并直接生成这些媒介的输出。
这意味着人机交互将更接近于自然的人与人之间的交流。
GPT-4o 可以在 232 毫秒内回应音频输入,平均响应时间为 320 毫秒,这接近于人类对话的反应时间。此前,使用语音模式与 ChatGPT 交流的平均延迟为 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)。
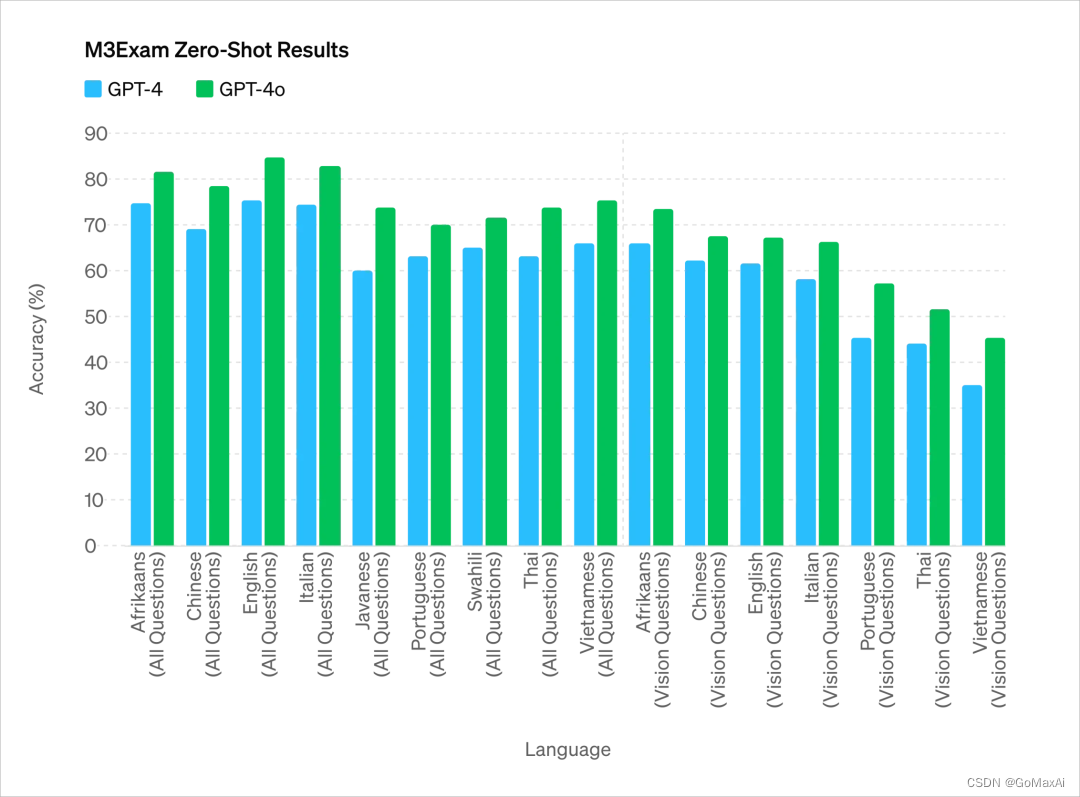
在英文和代码文本上,GPT-4o 的性能与 GPT-4 Turbo 相当,而在非英语语言文本上有显著改进,同时其 API 更加快速且价格便宜 50%。
而与现有模型相比,GPT-4o 在视觉和音频理解方面表现尤为出色。
你在对话时可以随时打断
它能够根据场景生成多种音调,带有类似人类的情绪和情感
可以通过与 AI 进行视频通话,直接在线解答各种问题
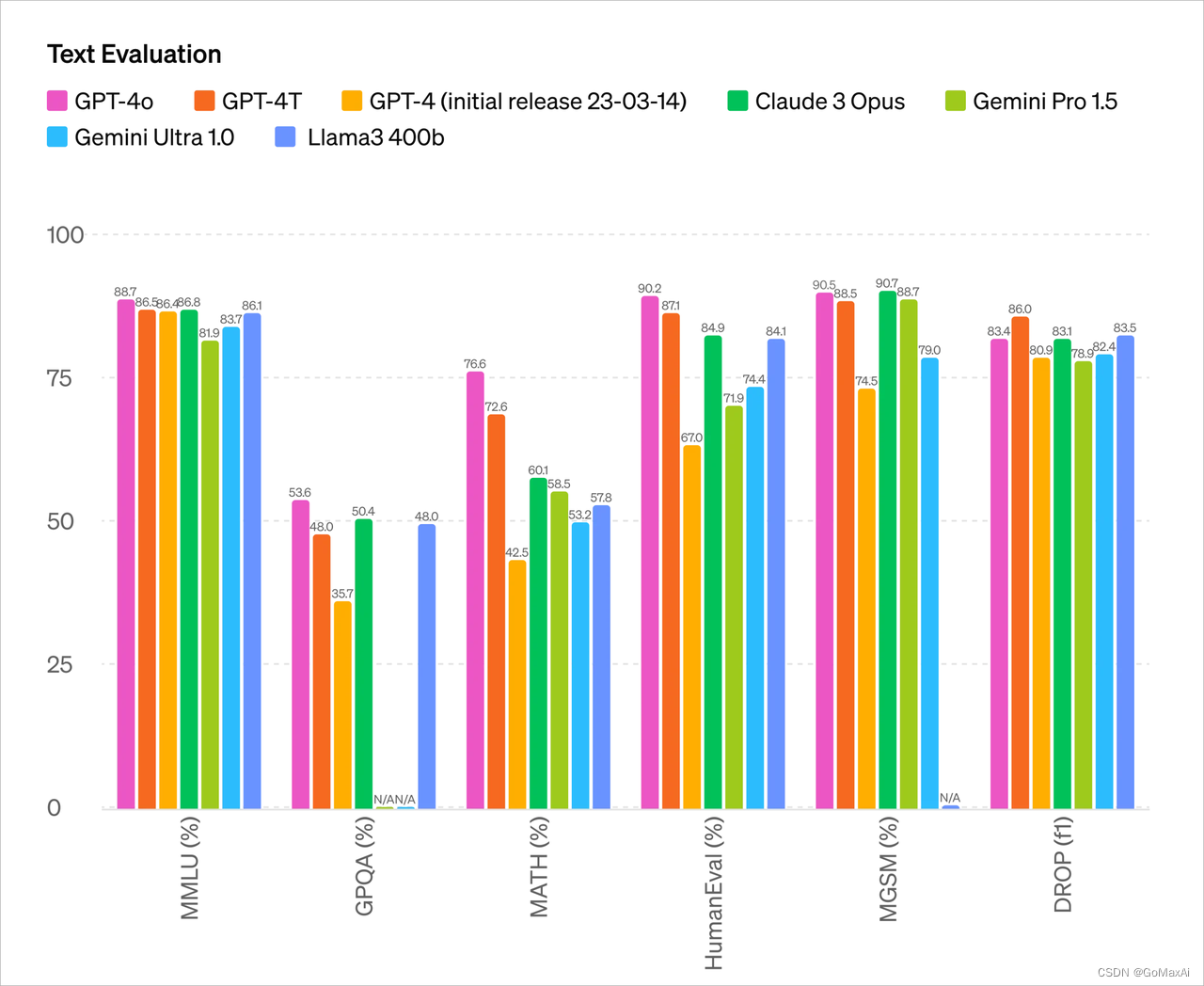
从测试参数来看,GPT-4o 的主要能力基本与目前最强的 OpenAI 模型 GPT-4 Turbo 相当
过去,我们使用 Siri 或其他语音助手的体验并不理想,主要原因是语音助手对话要经历三个阶段:
语音识别或“ASR”:将音频转换为文本,类似于 Whisper;
大型语言模型(LLM)规划下一步要说什么:将文本 1 转换为文本 2;
语音合成或“TTS”:将文本 2 转换为音频,可以想象成 ElevenLabs 或 VALL-E。
然而,我们日常的自然对话却是这样的:
在听和说的同时,考虑下一步要说什么;
在适当的时刻插入“是的,嗯,嗯”;
预测对方讲话结束的时间,并立即接话;
自然地决定打断对方的谈话,而不会引起反感;
优雅地处理并打断对方的谈话。
之前的 AI 语言助手无法很好地处理这些问题。在对话的三个阶段中,每一步都有较大延迟,因此体验不佳。同时,在这个过程中会丢失很多信息,比如无法直接观察语调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。

当音频能够直接生成音频、图像、文字、视频时,整个体验将会有质的飞跃。
GPT-4o 是 OpenAI 专门为此训练的全新模型,实现了文本、视频和音频之间的直接转换,这要求所有的输入和输出都由同一个神经网络处理。
更令人惊喜的是,ChatGPT 免费用户现在可以体验以下功能:
- GPT-4 级别的智能
- 从模型和网络获取响应
- 数据分析和图表创建
- 与上传的照片进行交流
- 上传文件以获取摘要、写作或分析帮助
- 使用 GPTs 和 GPT Store
- 通过 Memory 构建更加有帮助的体验
当您观看了 GPT-4o 下面这些演示后,您的感受可能会更加复杂:
- ChatGPT 版「贾维斯」,人人都有
- ChatGPT 不仅能说、能听、还能看,这已经不是什么新鲜事了,但「全新版本」的 ChatGPT 仍然令我感到惊艳。
- **睡觉搭子**:以一个具体的生活场景为例,让 ChatGPT 讲述一个关于机器人和爱的睡前故事,它几乎不用太多思考,就能够口若悬河地说出一个带有情感和戏剧性的睡前故事。甚至它还能以唱歌的形式来讲述故事,简直可以充当用户的睡眠搭子。
- **做题高手**:ChatGPT 不仅仅是一个聊天机器人,它还可以成为您的学习助手。

或者,在发布会现场,通过演示解决线性方程 3X+1=4 的求解过程,GPT-4o 能够一步步耐心地引导用户,最终给出正确的答案。
当然,这些还只是一些基本功能,“小儿科”而已。真正的挑战是现场的编程难题。但即使面对这些复杂问题,GPT-4o 也能在短时间内轻松找到解决方案。
借助 ChatGPT 的「视觉」功能,它能够查看电脑屏幕上的所有内容,例如与代码库交互并查看代码生成的图表。咦,这样一来,我们的隐私岂不是也会被看得一清二楚了?
在实时翻译方面,ChatGPT 在现场演示中表现出色。无论是从英语翻译到意大利语,还是从意大利语翻译回英语,这款 AI 语音助手都应对自如,让观众印象深刻。看来,未来可能不需要花重金购买翻译机,因为 ChatGPT 可能会成为比现有实时翻译机还更可靠的选择。
▲ 实时翻译(官网案例)
此外,感知语言情绪只是起步阶段,ChatGPT 还能解读人类的面部情绪。

在发布会现场,当面对摄像头拍摄的人脸时,ChatGPT 一开始将其“误认为”是桌子,这让在场的观众误以为程序将要出错。原因是最初开启的前置摄像头正好对准了桌子。
然而,随后它正确地描述了自拍面部的情绪,并准确识别出了脸上的“灿烂”笑容。
有趣的是,在发布会结束时,发言人也特别提到了英伟达及其创始人老黄的“鼎力支持”,显示出对人情世故的理解。
对话语言界面的概念展现了令人难以置信的前瞻性。
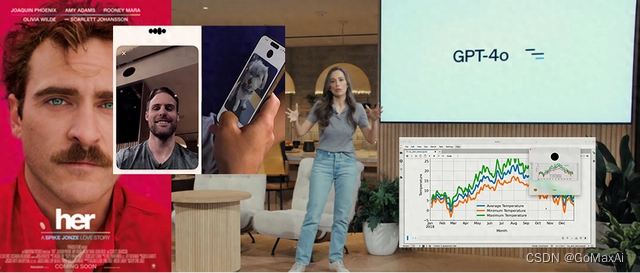
Altman 在之前的采访中表达了希望最终开发出一种类似于电影《Her》中的 AI 助理,而今天 OpenAI 发布的语音助手似乎确实在向这个方向迈进。

OpenAI 的首席运营官 Brad Lightcap 不久前曾预测,未来我们将与 AI 聊天机器人进行对话,就像与人类交谈一样,并将其视为团队的一部分。
这一预测不仅为今天的发布会铺平了道路,同时也为我们未来十年的生活注入了活力。
苹果在 AI 语音助手领域花费了长达十三年的时间,仍未走出困境,而 OpenAI 则迅速找到了解决方案。可以预见,不久的将来,钢铁侠的“贾维斯”将不再是幻想。
OpenAI联合创始人兼首席执行官山姆·奥特曼表示,他在5月15日的说明中提到,虽然GPT-4o的文本模式已经发布,但语音模式还未发布。