
- 1如何在iPhone上安装IPA文件?完整方法汇总!_ios微信ipa文件
- 2SpringBoot + Poi-tl实现word模板导出数据表格_poi-tl官网
- 3论文阅读笔记
- 4【从零开始AI绘画7】拓展使用#1Multidiffusion upscaler的使用
- 5Android开发之——性能剖析器Profiler,一文详解
- 6尚硅谷Hadoop3.x学习笔记_尚硅谷hadoop3笔记
- 7哈工大2021算法设计与分析期末试题_2021 秋哈工大算法设计与分析期末考试题(回忆版)
- 82020-08-31_package后代选择器
- 9蓝桥杯竞赛的含金量如何?什么是白名单赛事?一文将清楚!_蓝桥杯 白名单
- 10Android Windows 显示层次_android window 层级相同 不显示
分布式系统共识机制:一致性算法设计思想_分布式系统一致性设计
赞
踩
这次以一个宏观的角度去总结 自己学习过的一致性算法。一致性算法的目标就是让分布式系统里的大部分节点 保持数据一致。
区块链中的共识算法,pow、pos这类就属于这个范围,但他们仅仅是在区块链领域内应用的,下面介绍一致性算法是在分布式系统中 应用广泛的,当然也肯定适用于区块链,并且最后我总结了他们的设计思想,其实是有一定套路的。
Paxos 算法
首先是paxos算法,他是在大量工程实践中得到检验的,google很多项目和大数据组件zookeeper中都用它。他是实现是很复杂的,但是基本思想不难理解。
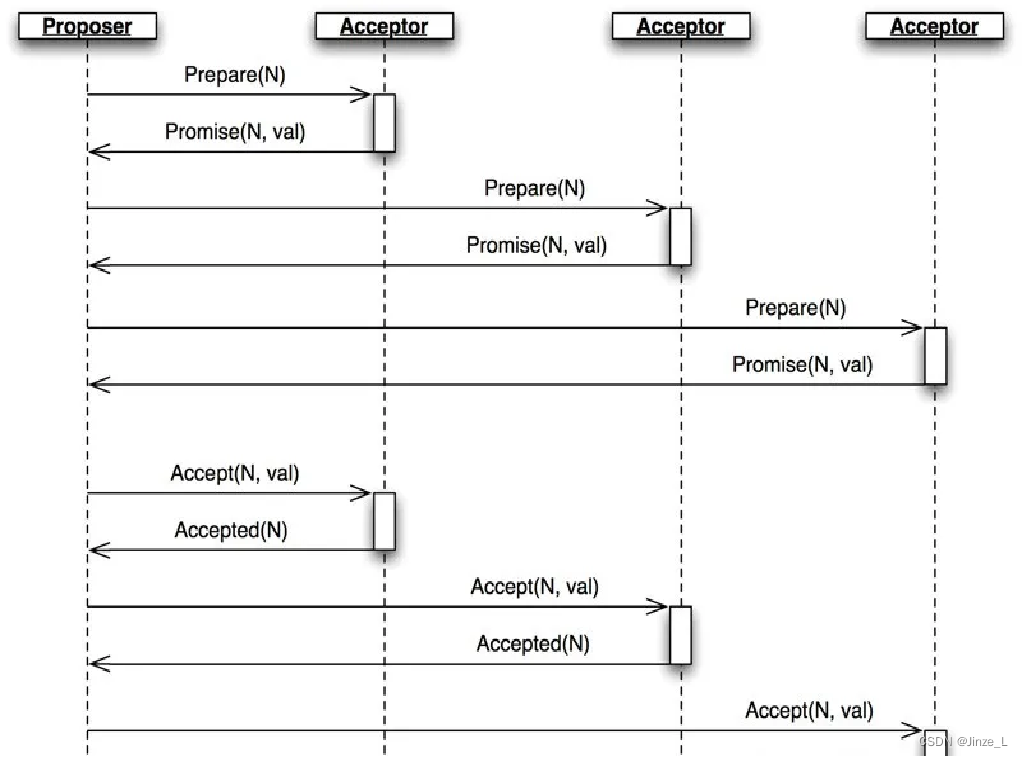
节点角色
paxos的节点有三种角色,分别是:
第一类是提案者,负责提出议案,也就是要同步的数据。
第二类 批准者,提案者提出的提案 必须获得超过半数的 批准者的投票后才能通过。
第三类 学习者。不参与提案,只负责接收已确定的提案,一般用于提高集群对外提供 读 服务的能力。
算法流程
算法具体流程主要有三个阶段:
首先是 Prepare阶段,提案者选择一个提案编号N,向批准者们发送 这个编号的Prepare请求。批准者收到请求后,判断N是不是大于 本地已经响应的Prepare请求的编号,是的话就将这个编号反馈给提案者,同时不会再批准 编号小于N的提案。
然后是 Accept阶段,如果提案者收到 超过半数批准者的响应,就发送一个针对[N,val]提案的Accept请求 给批准者,val是提案值。然后批准者接受对应值并返回给提案者一个响应。
到这时候,批准者和提案者都达成了共识。
最后就进入Learn阶段,这个阶段不属于选定提案的过程,提案者将通过的提案 同步到所有的学习者。
最终大部分节点就会达成共识。
很明显,这个算法不适用于存在拜占庭节点的分布式系统,只能适用于普通的分布式系统。
Raft 算法
虽然Paxos的原理比较容易理解,但是它在工程上的实现是非常复杂的,所以出现了Raft算法,是Paxos算法的一种简化实现。基本思路也差不多。
节点角色
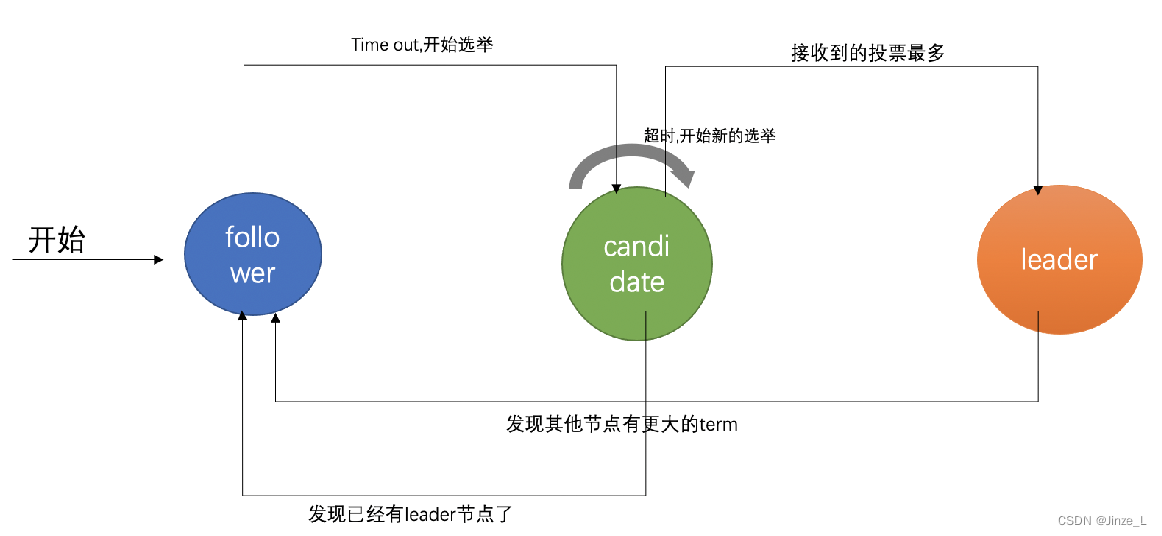
同样的,节点有三种角色:
首先是 follower追随者,是集群的初始状态,节点在加入时默认是追随者,也就是从节点。
然后是 candidate候选人,是在选举的时候,被投票者的称谓。这是一个中间角色,比如followerA投票给followerB,那followerB的角色就是candidate。
最后是 leader主节点,用来接收用户请求,进行数据同步。
核心机制
RAFT算法分为两个阶段:Leader选举和日志复制。
首先看leader是如何选出来的。
leader选举
算法刚开始时,所有结点都是Follower,每个结点都会有一个定时器,在收到Leader 的消息时就会重置定时器。如果定时器超时,说明一段时间内没有收到 Leader 的消息,那么就认为 Leader不存在了,那么该结点就会转变成 Candidate,准备竞争Leader。
成为 Candidate 后,节点会向其他结点发送 请求投票的请求,其他结点在收到请求后 会判断是否投给他并返回结果。Candidate如果收到了半数以上的投票 就可以成为Leader,成为之后会在任期内 定期发送心跳消息 通知其他结点 新的 Leader 信息,用来重置其他节点的定时器,避免其他结点成为 Candidate。
日志复制
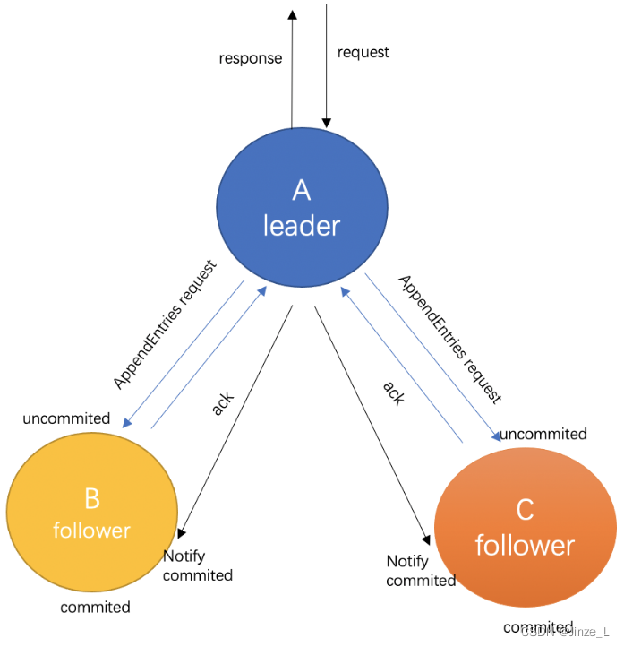
leader选举出来后,就要开始同步数据。
由leader收到客户端的请求,会将请求包装成日志包的形式发到其它节点,这个过程叫做日志复制。其它节点接收到数据后向主节点响应ACK。
leader等待集群中超过一半的节点响应后, 再向客户端回复数据已接收。此时进入 数据已提交的状态。
最后 Leader 节点再向其它节点 告知数据状态已提交,其它节点开始commit自己的数据,此时集群达到主节点和从节点的一致。
raft算法和刚才介绍的paxos算法,都假设不存在拜占庭将军问题,只考虑节点宕机、网络分区、消息不可靠等问题。下面这类算法就考虑到节点作恶的情况。最经典实用的是pbft,之前也多次介绍过这个算法的实现细节,但这次以另一种的角度去解读
PBFT
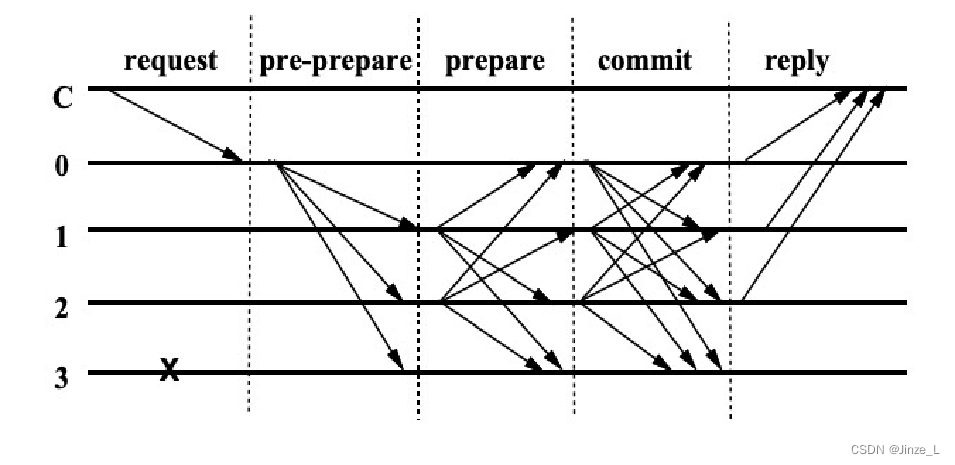
首先,也是分为不同店节点角色,分别是:
主节点,负责将交易打包成区块,每轮共识过程只能有一个主节点。
副本节点,负责共识投票,每轮共识过程中有多个副本节点。
流程:
客户端发送请求给主节点
主节点广播请求给其它节点,节点执行PBFT算法的三阶段共识流程。
三阶段流程后,返回消息给客户端。
客户端收到来自 f+1 个节点的相同消息后,代表共识已经正确完成。
基于投票的共识算法 其实基本就是一个套路:确定一个leader提出提案,其他节点负责投票。根据投票结果来确定提案是否通过。当主节点提出提案后,其他节点的 投票和收集投票 都由各个节点单独完成的,这是因为有拜占庭节点的存在,节点只相信自己获取到的投票信息,每一个节点 基于自己收集的消息来确定 该提案是否形成了共识。
所以就设计了四个阶段:
首先pre-prepare阶段 就是主节点向副本节点发送提案,副本节点接收提案并进行验证,但并不知道其它节点的状态。
在prepare阶段,每个合法的节点都接收到至少2/3的投票数,我们将一个节点接收到至少2/3的投票数 称为事件A,显然至少2/3节点都发生了事件A,但是节点之间 不知道彼此是否发生了事件A;
所以就有commit阶段,每个节点都将 自己发生了事件A的消息 广播给其他节点,同时也收集其他节点 关于事件A的广播,我们把收集到至少2/3个节点的事件A 称作事件B。此时,每个节点都知道 至少有2/3节点都发生了事件A,那么大部分节点达成了共识。但是,客户端还不知道结果呢。
最后,在reply阶段中,每个节点都将事件B返回给客户端,此时客户端只要收集到至少f+1个节点的 事件B的广播,就可以判断系统已经形成共识。我们将收集到至少f+1个节点的事件B的广播 称作事件C。
所以,pbft设置了四个阶段就是为了保证这三个事件的发生。
Hotstuff
根据刚才的介绍,PBFT中的关键点在于 每个节点都独立做 收集投票的工作,这就导致了整个算法中 节点的工作量是重复的。而PBFT之所以这么做的原因是 节点只相信自己获取到的投票信息,如果能解决这个信任问题,那么就省去这些重复工作。HotStuff所进行的优化也就是基于此,通过使用门限签名,确保投票结果不能被伪造。
门限签名
节点角色和PBFT的角色一样,分为主节点和副本节点。
门限签名 简单介绍下:一个(k,n)门限签名方案指 由n个成员组成的签名群体,所有成员共同拥有一个公共密钥,每个成员拥有各自的私钥。只要收集到k个成员的签名,且生成一个完整的签名,这个签名可以通过公钥进行验证。
这里不去详细探讨门限签名的技术细节,主要聚焦在算法是怎样应用的。在HotStuff中,leader除了提出提案以外,还需要收集其他节点的投票,并将投票结果整合成一个 容易检查合法性但又无法伪造的证据。门限签名的特点就是,当且仅当 对同一个数据具备了足够多的子签名,才能合成一个签名,而其他人只需要验证最终的签名 就能确保整个签名构建过程是合法的。门限签名的使用,使得所有节点都可以将 收集投票信息的工作委派给leader,并可以确保leader无法作假。因此,HotStuff最终的算法复杂度是直接降低了一个量级。
核心机制
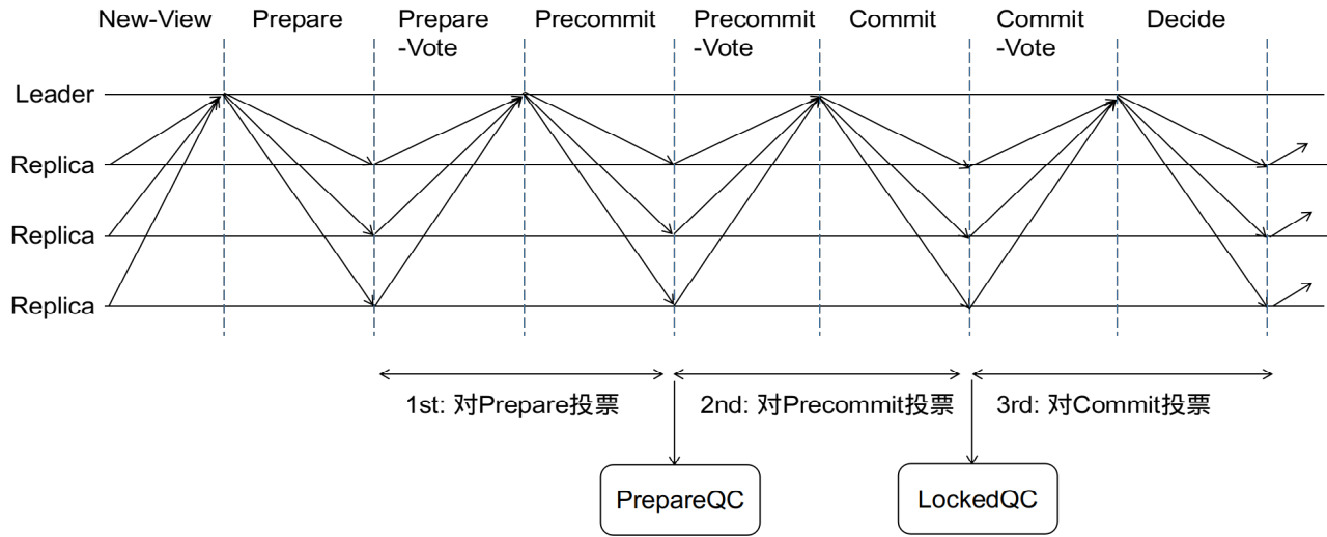
HotStuff主要是将**“leader负责收集每一轮的投票信息”**思想融合到pbft中。pbft中出现了2轮所有节点广播以及收集投票+1轮客户端收集投票。如果换成leader收集投票,需要3轮来保证这三个事件的发生。
第一阶段,收集至少2/3节点的投票,即leader节点发生了事件A,此时leader节点把这个时间点的证据保留下来,广播给其他节点。其他节点也就相当于发生了事件A;但是不知道 其他节点是否接收到leader广播的事件A;
第二阶段,所以收到事件A的节点 会发送消息给leader;leader会收集这些投票,即leader发生了事件B,同理,将这个事件B广播给其他节点,其他的节点在收到 时也相当于发生了事件B,但是还是不知道 其他节点是否有收到事件B;
第三阶段,跟第2步一样,收到事件B的节点也会发送投票给leader,leader收集,此时leader发生了事件C,同理,将这个事件广播给其他节点,其他节点收到后,就确认了共识已经达成。
总结以上几种一致性算法的设计思想,可以分成二阶段提交协议和三阶段提交协议。
二阶段提交协议
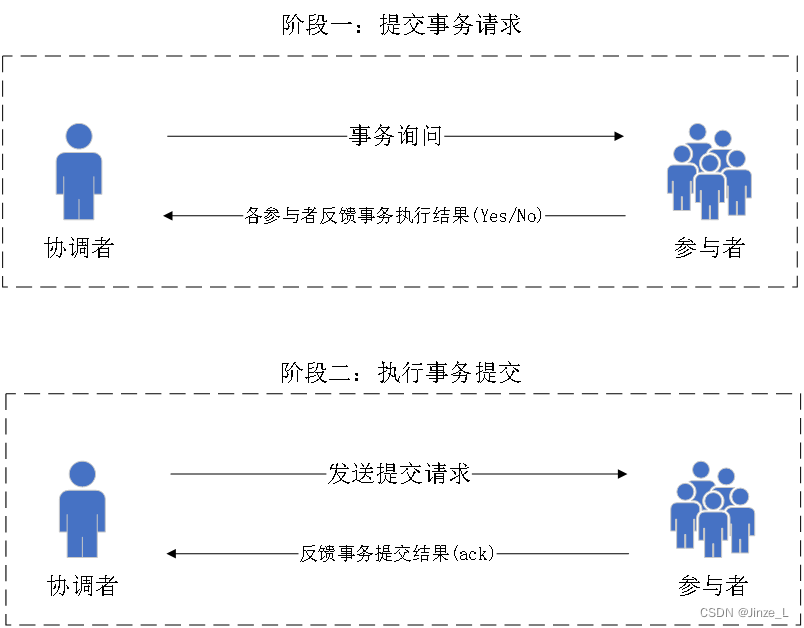
二阶段主要采取:先尝试,后提交。
可以分成两个角色:协调者和参与者。
第一阶段是提交事务请求。
协调者向参与者发送事务内容,询问是否可以执行事务提交操作,等待响应;
参与者执行事务操作,并回复协调者,执行成功则回Yes否则No。
第二阶段是执行事务提交。
如果参与者都回复Yes,那么协调者向参与者发送 提交请求,否则发送回滚请求。
参与者根据协调者的请求 执行事务提交或回滚,并向协调者发送Ack消息。
协调者收到所有的Ack消息后,判断分布式系统事务的结果是完成还是失败。
刚才介绍的paxos和raft都是基于二阶段提交的思想实现的。
二阶段优点:
- 原理简单;
- 保证了分布式事务的原子性,要么全部执行成功,要么全部执行失败。
二阶段缺点:
- 同步阻塞:在提交执行过程中,各个参与者都在等待 其他参与者响应的过程,无法执行其他操作。
- 单点问题:只有一个协调者,协调者挂掉,整个二阶段提交流程无法执行;更严重的是,在阶段二时,协调者出现问题,那参与者会一直处于锁定事务状态中,无法继续完成事务操作。
- 数据不一致:在阶段二,协调者发送了Commit请求后,如果发生了网络故障,导致只有部分参与者收到commit请求,并执行提交操作,就导致数据不一致问题。
三阶段提交协议
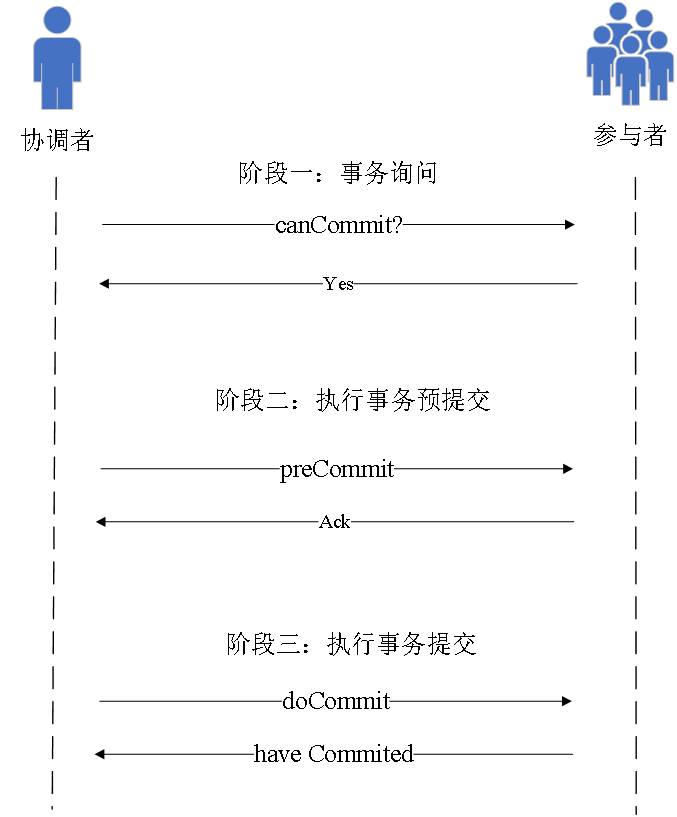
因为二阶段提交有很多问题,所以出现了三阶段提交
主要的改进点是 将第一阶段分为两个阶段,先发起事务询问,再执行事务。
同时在协调者和参与者中引入超时机制。
第一阶段 事务询问
协调者向参与者发送 包含事务内容的询问请求,询问是否可以执行事务;
参与者根据自己状态判断并回复yes或no;
第二阶段 执行事务预提交
如果协调者收到大部分节点的yes,就发送preCommit请求,否则发布abort请求;
参与者如果收到preCommit,就执行事务然后返回Ack。如果收到abort或者超时,就中断事务;
第三阶段是 执行事务提交
如果协调者收到大部分节点是Ack,就发送doCommit请求;
参与者收到doCommit就提交事务并返回响应;
协调者收到响应后,判断是完成事务还是中断事务;
pbft和hotstuf这类算法的基本思想就是三阶段提交协议。
三阶段的优点:
- 降低了二阶段的同步阻塞范围,在第二阶段,只要参与者收到preCommit请求,就会执行事务,不会一直阻塞。
- 解决单点问题:进入阶段三会出现两种情况: 1:协调者出现问题; 2:协调者与参与者之间出现网络故障; 都会导致参与者无法收到doCommit请求,但参与者在超时之后都会提交事务。
三阶段的缺点
- 还是会存在数据分区问题:参与者收到preCommit请求,此时如果出现网络分区,协调者与参与者之间无法进行正常网络通信,参与者在超时之后还是会进行事务提交,就会出现数据不一致。当然,这是分布式系统的通病,要保持一致性和可用性,就必然要牺牲分区容错性,这是分布式系统的不可能三角,也就是cap理论。所以不管是二阶段提交还是三阶段提交,数据分区是不可避免的。


