
- 1力扣第92题——反转链表 II(C语言题解)_力扣反转链表2
- 2gitlab 更新子模块_gitlab更新子模块
- 3Chrome浏览器:Your Connection is not private 您的连接不是私密连接
- 4Dofbot机械臂从零部署笔记(3)——ROS之Moveit下实现顺向运动学规划+实机同步运动_dofbot虚拟机movit驱动真机
- 5macbookpro强制重启方法及CleanMyMac怎么清理mac缓存
- 6工具栏QToolBar-样式_qtoolbar样式
- 7matplotlib绘制多张图、多子图、多例图_matplotlib同时绘制8个图
- 8Docker 安装mysql Mac 环境下
- 9Web前端开发技术、详细文章、(例子)html 列表、有序列表、无序列表、列表嵌套
- 10引用实战学习
视觉学习之注意力机制(SE、ECA、CBAM)_解读注意力集中机制se结构含义
赞
踩
前言
注意力机制的灵感来源于人类视觉系统的工作原理,即我们通常会集中注意力于视野中的关键元素,而忽略其他不相关的信息。在深度学习领域,这种机制被形式化为可学习的模型组件,它能够告诉模型在分析数据时应该“看”哪里。这不仅提高了模型处理高维数据的效率,还增强了其在解决复杂问题上的能力。
本文将重点介绍三种著名的注意力框架:Squeeze-and-Excitation (SE)、Efficient Channel Attention (ECA) 和 Convolutional Block Attention Module (CBAM)。这些机制各自以其独特的方式改善了视觉学习任务的性能,从图像分类到物体检测,再到图像分割等各个领域都展现了其强大的影响力。
一、SENet注意力机制
原文地址:SENet论文地址
当以往的架构注意点放在网络的深度和宽度的时候,SENet将关注点放在了网络的通道维度上,对特征通道间的相互依赖关系进行了建模,即获取特征图的每个通道的重要程度,然后用这个重要程度去给每个通道赋予一个权重值,从而让神经网络重点关注某些特征通道。提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道 ,从而提高网络的表现力
SE基本结构如下:
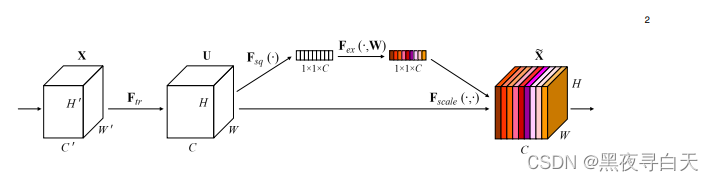
实现过程
(1)Squeeze(Fsq):通过全局平均池化,将每个通道的二维特征(H*W)压缩为1个实数,将特征图从 [h, w, c] ==> [1,1,c]
(2)excitation:给每个特征通道生成一个权重值,论文中通过两个全连接层构建通道间的相关性,输出的权重值数目和输入特征图的通道数相同。[1,1,c] ==> [1,1,c]
(3)Scale:将前面得到的归一化权重加权到每个通道的特征上。论文中使用的是乘法,逐通道乘以权重系数。[h,w,c]*[1,1,c] ==> [h,w,c]
【深度学习】(1) CNN中的注意力机制(SE、ECA、CBAM),附Pytorch完整代码_se注意力机制_立Sir的博客-CSDN博客

