
- 1【计算机网络实验】实验三 IP网络规划与路由设计(头歌)_头歌 静态路由配置 ping 命令测试
- 2Mysql 数据库APi 编程(c/c++)-1.0_mysql数据表 api
- 3RuntimeError: Failed to allocate graph: MYRIAD device is not opened
- 4vue跳转,v-model 双向绑定,-vuex的使用cookie:,视频第三方播放
- 5微软官宣:Windows11将成为第一个全局AI辅助的操作系统_win11有自带的ai工具吗
- 6git知识点以及git常见错误_hint: 'git pull ...') before pushing again. hint:
- 7微信小程序页面传递参数方法_微信小程序navigateto传参
- 8键盘上各按键对应的英文名(转载)_numplus是哪个键
- 9python输出自己的名字_使用Python实现自我介绍
- 10【PHP】PHP代码审计基础知识
OpenMMLab/MMDetection3D Pointpillars点云目标检测_三维目标检测真值标签
赞
踩
坐标中间的转换
1 齐次坐标概念
概念:齐次坐标就是将一个原本是n维的向量用一个n+1维向量来表示,是指一个用于投影几何里的坐标系统。

引入齐次坐标的目的就是合并矩阵运算中的乘法和加法,即它提供了用矩阵运算把二维、三维甚至高维空间中的一个点集从一个坐标系变换到另一个坐标系的有效方法。
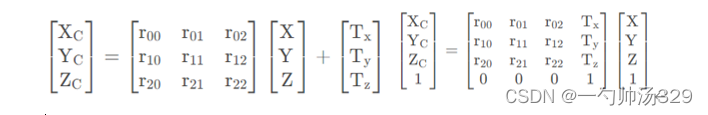
2.把雷达坐标系看成世界坐标系,则世界坐标系中任意一点W,其世界坐标为:
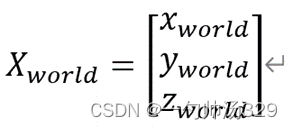
其世界齐次坐标为:

又假设雷达坐标系到相机坐标系的转换矩阵为E,(该矩阵即是外参矩阵,取其英文Extrinsic首字母E),假设其逆矩阵为:

设点W在相机坐标系下的坐标表示为:

其在相机坐标系下的齐次坐标为:

则有:
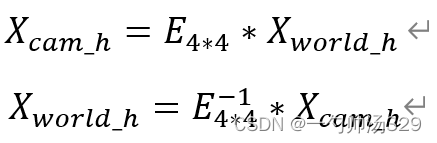
即:
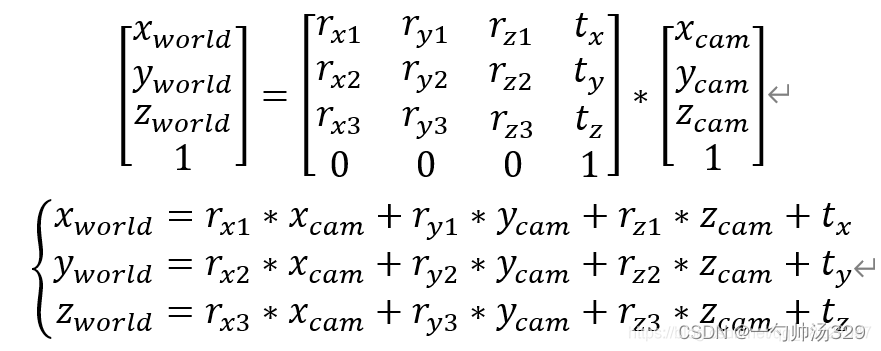
为消除齐次坐标、简化计算,特令:

则公式变为:

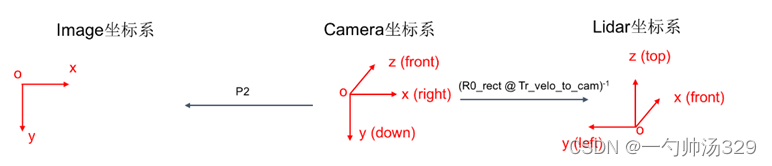
坐标系说明
1)Lidar坐标系
激光雷达坐标系可以描述物体与激光雷达的相对位置,表示为[XL, YL, ZL],其中原点为激光雷达几何中心,XL轴水平向前,YL轴水平向左,ZL轴竖直向上,符合右手坐标系规则。
2)相机坐标系
相机坐标系可以描述物体与相机的相对位置,表示为[XC, YC, ZC],其中原点为相机光心 O 点,XC 轴与 x 轴平行,YC 轴与 y轴平行,ZC轴与摄像机光轴平行,与图像平面垂直。
3)图像坐标系
图像坐标系指在图像像素坐标系下建立以物理单位(如毫米)表示的坐标系,使像素尺度具有物理意义,表示为[x, y],其中原点为相机主点,即相机光轴与图像平面的交点,一般位于图像平面中心,x 轴与 u 轴平行,y 轴与 v 轴平行;
4)像素坐标系
像素坐标系表示为[u, v],其中原点为图像左上角,u 轴水平向右,v 轴竖直向下;
内参矩阵
设空间中有一点P,若世界坐标系与相机坐标系重合,则该点在空间中的坐标为(X, Y, Z),其中Z为该点到相机光心的垂直距离。设该点在像面上的像为点p,像素坐标为(x, y)。
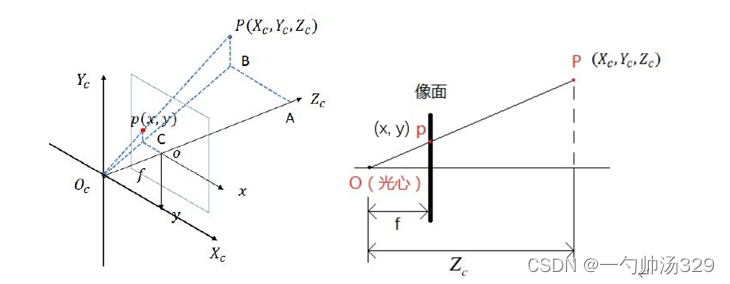
f为相机的焦距,相机坐标系下点p与图像坐标系下投影点p(x, y)的坐标关系为:

最终的转换关系为:
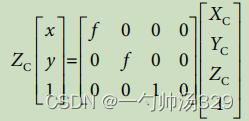
图像坐标系与像素坐标系的转换
图像坐标系与像素坐标系为平移转换关系,O1->像素坐标系原点,O->图像坐标系原点 ;示意图如下:
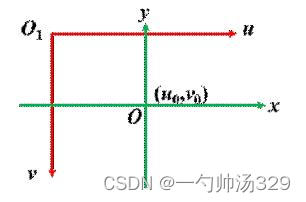
点O在像素坐标系下的坐标为(Uo,Vo),变换公式为:
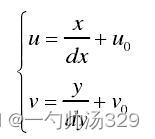
式中 dx 和 dy 分别为单个像素在像平面的长和宽,转换为矩阵:
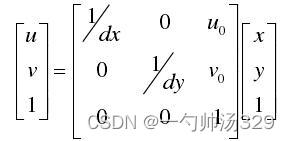
相机到图像
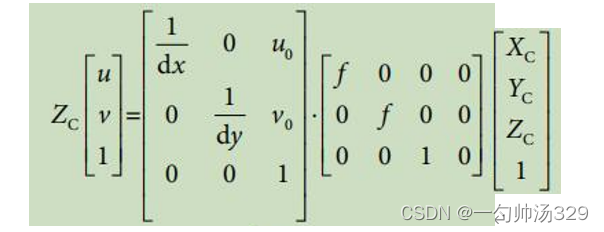
外参矩阵

点云到相机的坐标转换
KITTI点云数据转到图像上的点
y = P2 * R0_rect * Tr_velo_to_cam * x
1. Tr_imu_to_vel为点云上的点到相机坐标系下的点,矩阵大小为3x4,包含了旋转矩阵R和平移向量t,也就是上面提到的外参矩阵。

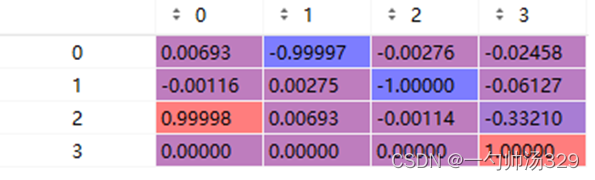
2. 之后利用0号相机的修正矩阵进行修正:R0修正矩阵3x3;主要是随着时间的偏移,0号相机的坐标可能会有偏差,将其校准,然后后面的投影即可通过内参矩阵和位移完成

3.P2就是相机到图像上点的内参
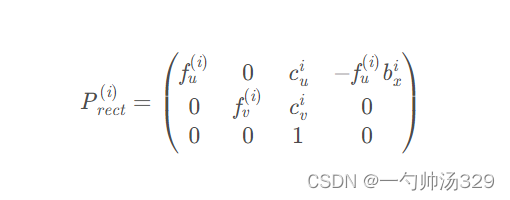

其中的45.7=0.06f=0.06*707=45,上面的最后一列是相机坐标系的偏移,主要是x轴,y和z轴稍微有点误差。
角度的转换:
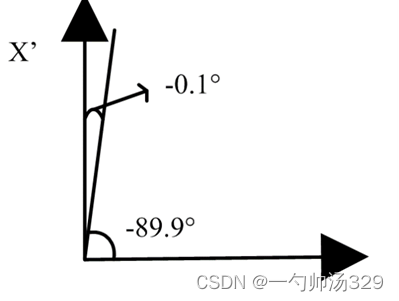
在标签文件(label)中,最后一个值为物体前进方向与x轴夹角的弧度值(在相机坐标系下)且以顺时针为正,逆时针为负

举个例子:如上图第一个car数据为例,其前进方向与x轴夹角(也称为yaw角)为-89.9°(-1.57*180/pi)
那么坐标系向雷达坐标系转换后,其raw角就变成了-(r_y + pi/2) ,且在雷达坐标系下,以x轴到y轴方向为正(即逆时针为正,顺时针为负)。则接上一个例子,如图所示,其在雷达坐标系下的yaw角度为-0.1°。
点云相机的坐标转换以及联合标定 - 灰信网(软件开发博客聚合)
激光雷达坐标系、相机坐标系与到图像坐标系之间的转换_灰灰子衿的博客-CSDN博客_雷达相机配准中,因为雷达坐标系转移到相机坐标系后图像怎么配准的
处理点云数据(五):坐标系的转换_听说你爱吃芒果的博客-CSDN博客_怎么把点云图像转换成坐标轴
kitti数据集在3D目标检测中的入门(二)可视化详解_Studying_swz的博客-CSDN博客_kitti可视化
Kitti数据集标签中yaw角在不同坐标系的转换_噗噗噗蒲的博客-CSDN博客_kitti yaw
https://blog.csdn.net/zhulf0804/article/details/125020578
标注

1.标注框移动:
QWEASD 控制框上下、左右、前后移动;
2.标注框转动:
X/Y控制标注框转动,标注时尽量将标注框内显示的箭头指向车头朝向位置;
3.标注框(单面)尺寸调节:
鼠标停留在标注框某个面上后,移动滚轮可调节当前标注框鼠标所在面的大小(前后移动);
4.标注视野移动:
鼠标点击长按右键并拖动鼠标,能够移动视野区域;
5.标注视野分辨率改变:
鼠标只在标注视野内滚动滚轮则为改变视野分辨率(放大或缩小);
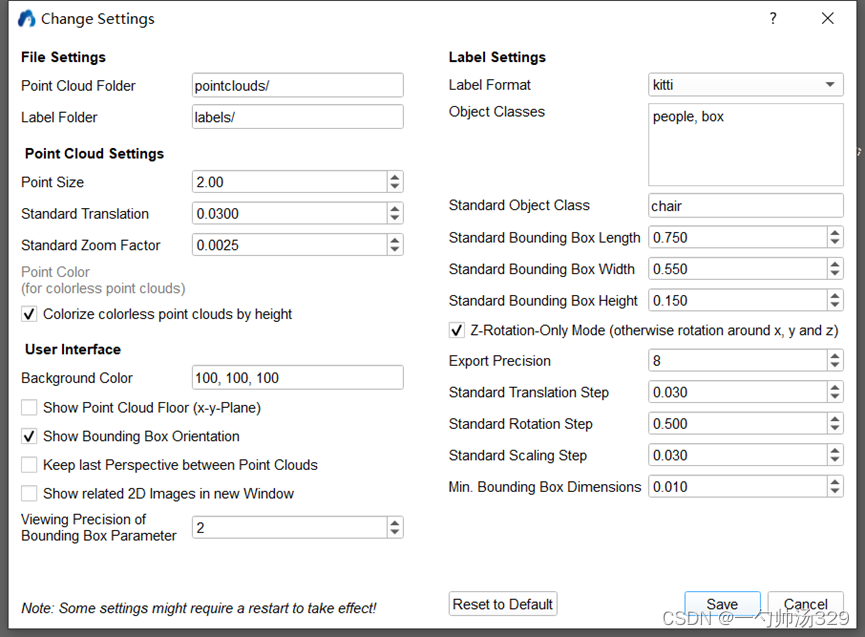
6.标注设置:
在顶栏找到“Setting==>Change Setting”按钮可对标注内容进行设置(框初始大小,类别数量,标注格式)。
labelCloud 开源三维点云工具标注自制点云数据集(以.bin格式点云为例)_Shawn_1223的博客-CSDN博客
https://blog.csdn.net/jin15203846657/article/details/122949271
视锥
计算近平面和远平面的中心点
计算近平面和远平面的宽度和高度
计算近平面和远平面的角点
从平面的任意三个角计算每个平面,顺时针或逆时针缠绕到指向内(取决于坐标系)

https://www.coder.work/article/6670253
配置文件
https://www.bilibili.com/video/BV14M41167Ct/?spm_id_from=333.788&vd_source=8a6043a22d94a87da35299c0731405
1.Create_data.py
Mmdetection3d支持多个数据集和网络,其数据的主要流程是差不多的,本文档主要选择数据集—KITTI和网络—PointPillars为主介绍数据生成的流程:
- 根据数据集为KITTI,判断进入KITTI数据集处理的通道;
- 将KITTI数据集中的图像的路径大小、点云的路径、label等信息生成.pkl文件;
- 获取相机视角里的点云数据,将数据保存在velodyne_reduced文件中,由于本文档中的数据是使用双目采集的点云信息,因此点云都在相机的视角范围内;
- 生成3D目标检测真值,也就是将你标注的数据拿出来,比如你在点云中标注了一个人,就将你标注框中的对象拿出来保存至kitti_gt_database文件中;
1.1获取数据集中点云图像路径——kitti.create_kitti_info_file
本文档主要将训练集信息生成pkl,其他训练集,验证集的生成方式大体相同。
1. 传入参数:(root_path:数据集的路径;info_prefix:数据集的类型,是kitti还是lyft数据集,还是s3dis数据等,本文档是kitti数据格式;with_plane=false)
2. 进入kitti.create_kitti_info_file函数后,然后按行读取数据下的ImageSets下存储的训练集、测试集里面的数据,保存list。
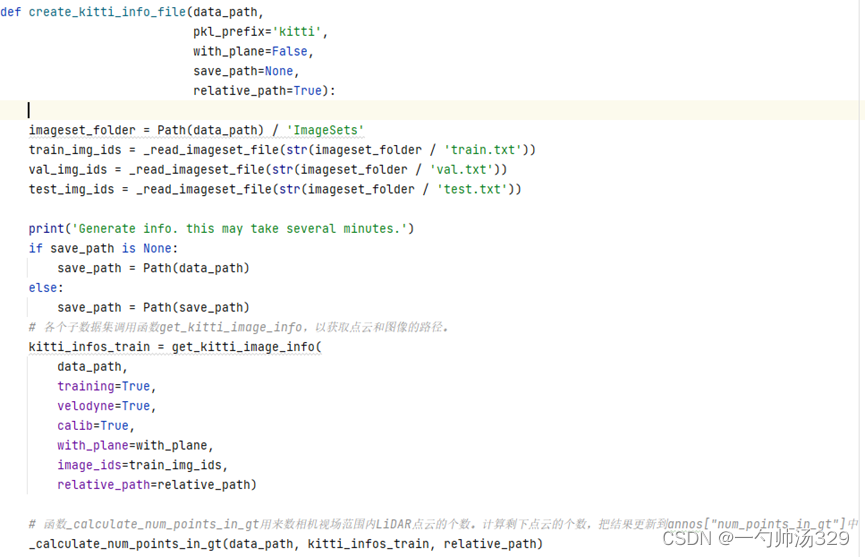
3. get_kitti_image_info(data_path:kitti的路径;training=True训练集;velodyne=True使用点云信息;calib=True坐标转换信息;with_plane=with_plane;image_ids=train_img_ids 第2步中获取的训练集ID;relative_path=relative_path是否使用相对路径,是True)获取图像的路径大小、点云的路径、label等信息。
4. 多线程 第17章:使用 concurrent.futures 模块处理并发-ThreadPoolExecutor 多线程并发和 Future 介绍_waitan2018的博客-CSDN博客
使用一个多线程的方式,通过使用image_ids 从map_func取东西,也就是根据image_ids生成每一个image,label等路径,然后使用map_func函数读取路径,获取信息。
map_func:(idx:训练集中的ID)
image_info:image_idx,path,shape
pc_info: (num_feature:4(x,y,z,r强度),path)
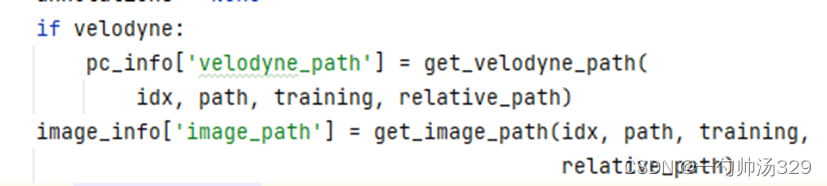
Annotations:获取label信息:get_label_anno(path)name、bbox等8个信息。

calib_info:p0,p1,p2,p3, R0_rect, Tr_velo_to_cam,Tr_imu_to_velo;将image_info、pc_info、Annotations和calib_info放入info中。
5.函数_calculate_num_points_in_gt(data_path:数据的路径;kitti_infos_train:刚刚保存的info信息)用来计算相机视场范围内LiDAR点云的个数。计算剩下点云的个数,把结果更新到annos["num_points_in_gt"]中,后去除数据的时候会用到,设置一个阈值,大于它将点云保存下来。将 Velodyne 坐标中的点 x 投影到左侧的彩色图像中 y,使用公式 y = P2 * R0_rect * Tr_velo_to_cam * x。读取点云以及上面公式需要的数据输入到box_np_ops.remove_outside_points函数中去除图像范围外的点云,保留图像内的点云。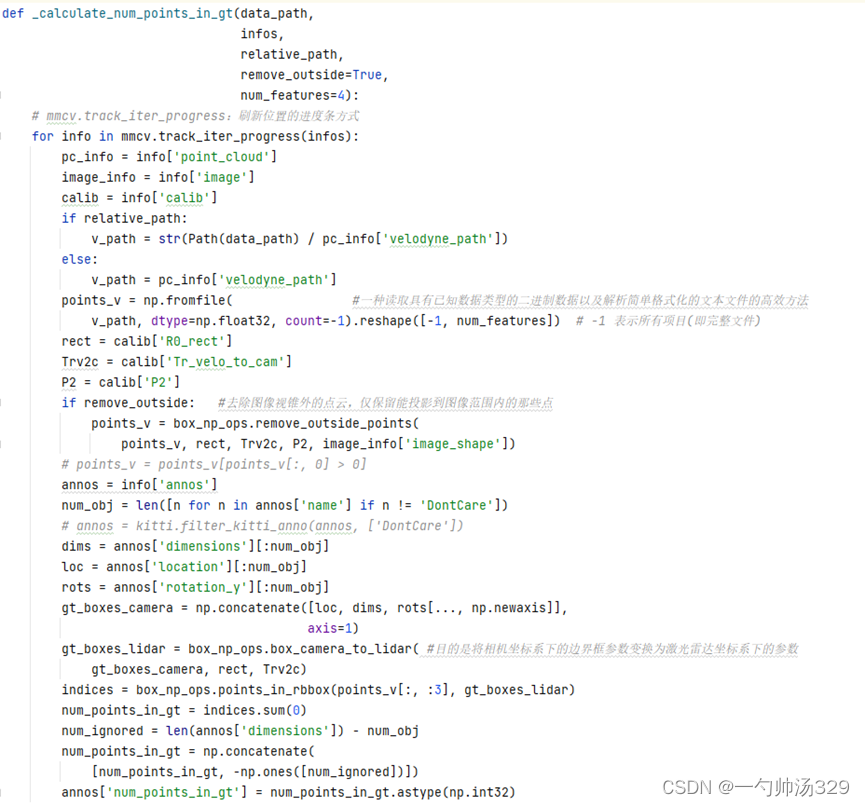

1.2获取相机视场内的点云——kitti.create_reduced_point_cloud
1.读取原先保存的pkl信息
2. _create_reduced_point_cloud(data_path:数据路径; train_info_path:刚刚读取的训练集的pkl路径; save_path) 读取点云后操作和1.1中的第5点相似,保留图像范围内的点云到velodyne_reduced
1.3获取3D目标检测的真值——create_groundtruth_database
判断KittiDataset,形成dataset_cfg的配置文件获取dataset = build_dataset(dataset_cfg)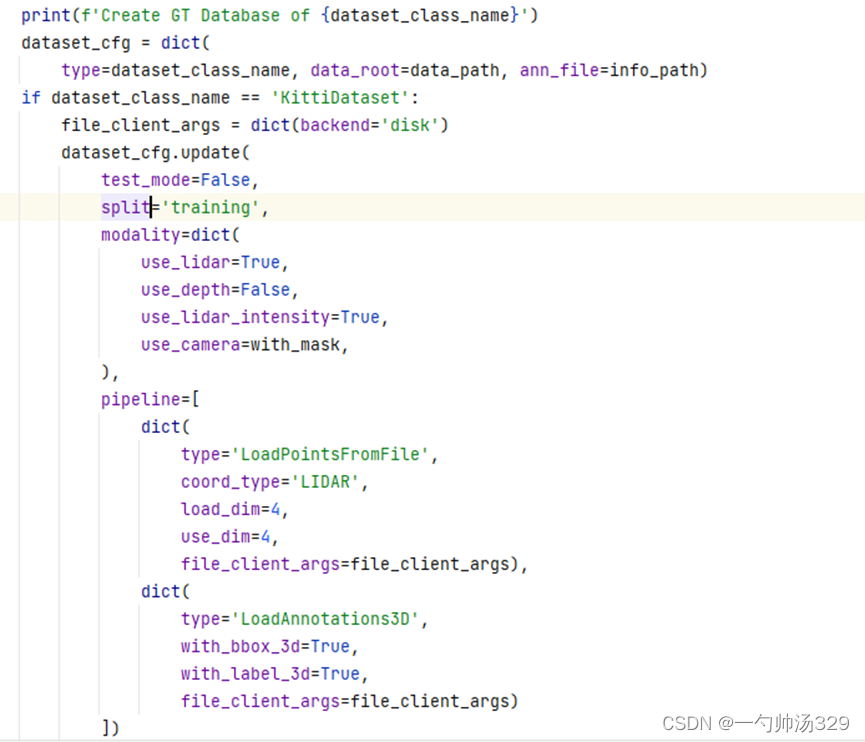

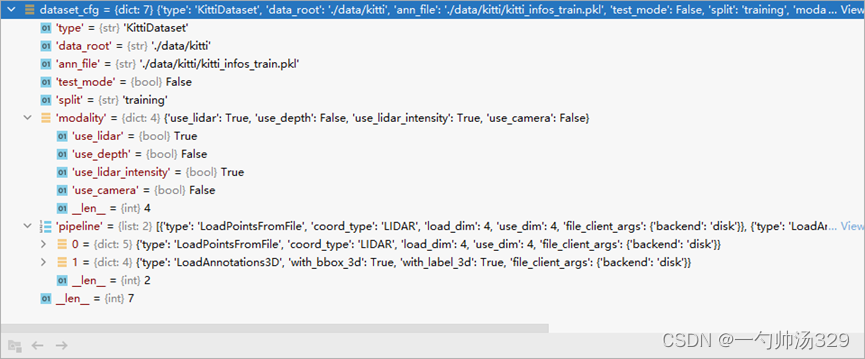
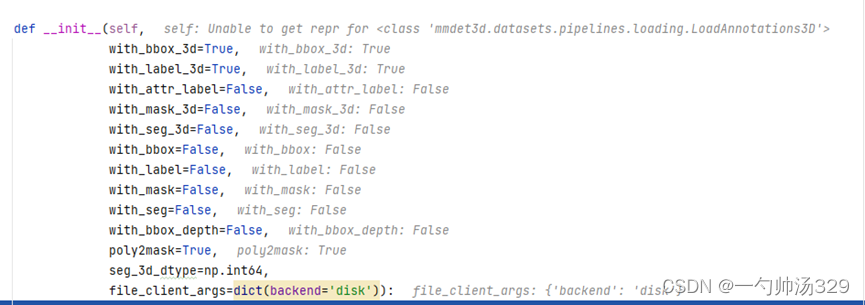
Compose类根据pipeline读取数据。
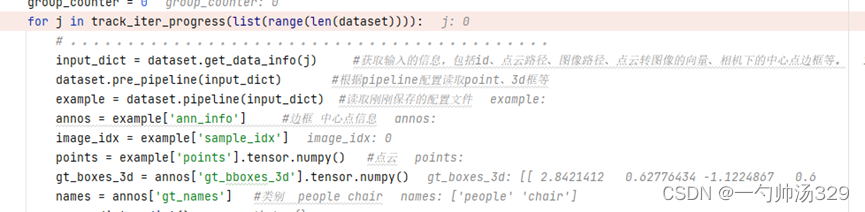

2 model主要模块解析
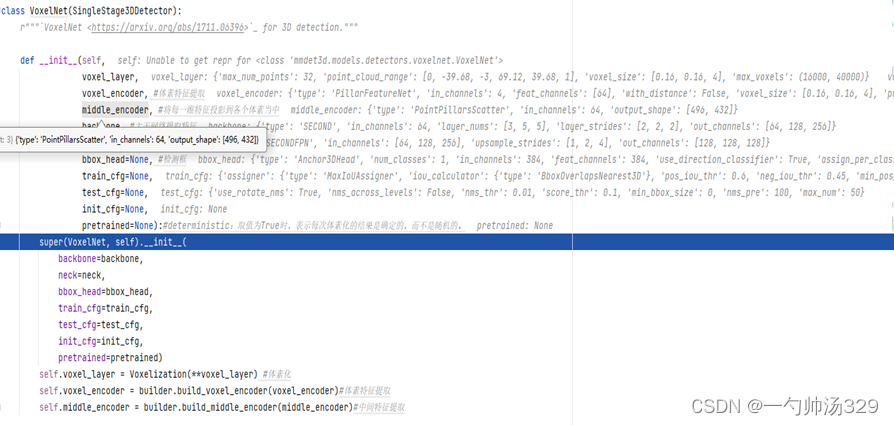
2.1 体素化
函数:self.voxelize(points)
Voxelization(voxel_size=[0.16, 0.16, 4], point_cloud_range=[0, -39.68, -3, 69.12, 39.68, 1], max_num_points=32, max_voxels=(16000, 40000), deterministic=True)
输入:
(1)points,Nx4,原始点云,N表示点云数量,4表示特征维度,特征为坐标x、y、z与反射强度r。
(2)voxel_size:单位体素的尺寸,x、y、z方向上的尺度分别为0.16m、0.16m、4m。
(3)point_cloud_range:x、y、z方向的距离范围,结合(2)中体素尺寸可以得到总的体素数量为432x496x1,可以看到Z方向上只有一个体素。所有体素均表现为柱状。
(4)max_num_points:定义每个体素中取值点的最大数量,默认为32。
(5)max_voxels:表示含有点云的体素最大数量,默认为16000。当数量超过16000时,仅保留16000,当数量不足16000时,则保留全部体素。
(6)deterministic:取值为True时,表示每次体素化的结果是确定的,而不是随机的。
输出:
(1)voxels:Mx32x4,体素中各个点的原始坐标和反射强度,M(M≤16000)个体素
(2)num_points:Mx1,每个体素中点的数量。
(3)coors:体素自身坐标,Mx4,[batch_id, z, y, x]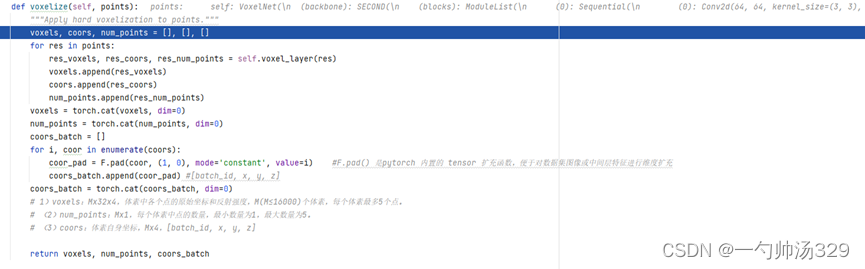
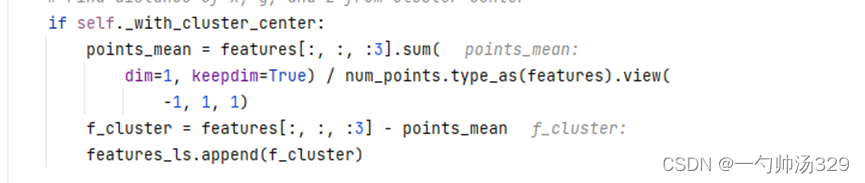
2.2 体素特征提取VFE(voxel_encoder)
在voxelnet中,体素特征通过SVFE层提取,即连续两层VFE,其中VFE层提取体素特征用的是PointNet网络。而在该Pointpillars源码中,VFE层被进行了简化。
(1)对voxels(Mx32x4)中各个体素的坐标求均值,然后用体素中各个点的坐标减去均值,f_cluster,Mx32x3。
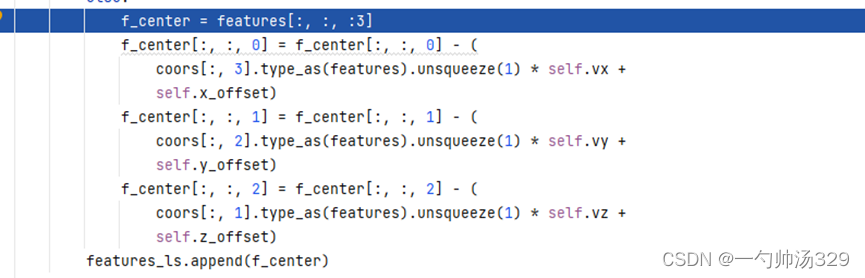
(2)将体素中点的坐标减去体素中心的坐标得到,f_center,Mx32x3。
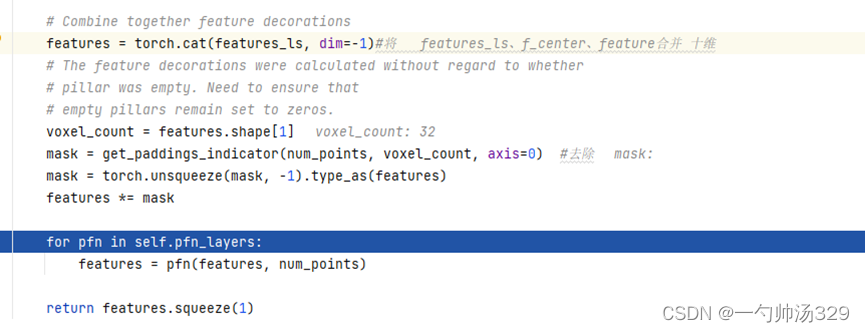
(3)将上述voxels、f_cluster、f_center进行拼接,features,Mx32x10,并且将体素中没有点的位置的10维特征置为0。每个体素中默认设置了点的数量为32,但是不是所有的体素都有32个点,不足32个点的位置特征用0进行填充。
(4)PFNLayer:features经全连接FC(10, 64)得到Mx32x64维特征x,在体素点云数量上进行最大值池化提取体素的全局特征features,Mx64。
2.3 中间特征提取 middle_encoder
Pointpillars的中间特征提取层将features (Mx64)每一维特征投影到各个体素当中,类似于二维图像,Mx64->432x496x4,即Mx64->214272x64,没有取值的地方像素值取为0。Canvas,64x496x432。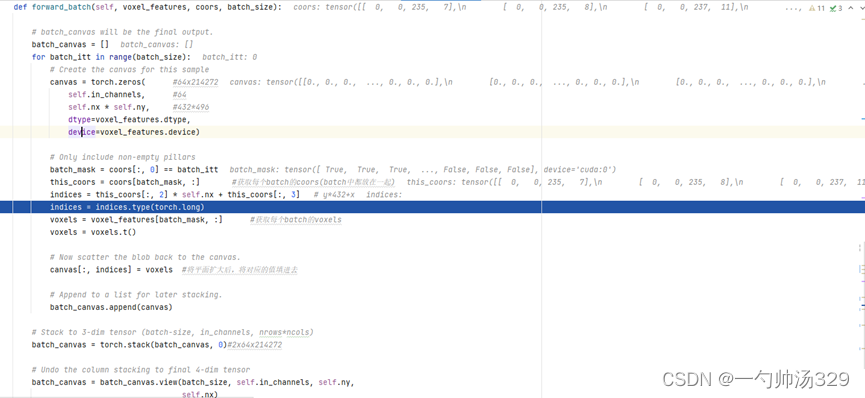
2.4主干网络特征提取
backbone:SECOND
(1) 2.3中out 64x496x432经连续4个3x3卷积(第一个步长为2):64x248x216,out1
(2) out1 64x248x216经连续6个3x3卷积(第一个步长为2):128x124x108,out2
(3) out2 128x124x108经连续6个3x3卷积(第一个步长为2):256x62x54,out3



2.5 上采样拼接 self.neck
分别对out1、out2、out3进行上采样:
out1:64x248x216 -> 128x248x216
out2:128x124x108 -> 128x248x216
out3:256x62x54 -> 128x248x216
拼接out:128x248x216、128x248x216、128x248x216 ->384x248x216 (self.extract_feat
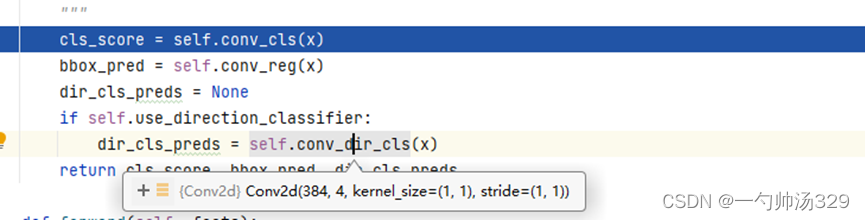
2.6 检测头 self.bbox_head
PointPillars共有3个不同尺寸的anchors(详情见2.2小节), 每个尺寸的anchor有2个角度, 因此共有6个anchors。网络训练了3个类别: Pedestrian, Cyclist和Car。
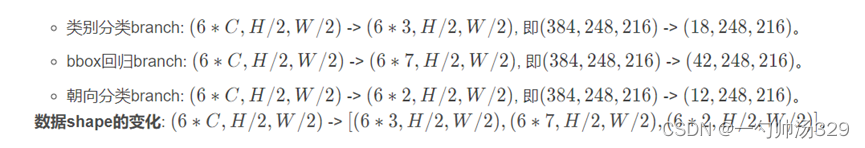
Anchor3DHead(
(loss_cls): FocalLoss()
(loss_bbox): SmoothL1Loss()
(loss_dir): CrossEntropyLoss(avg_non_ignore=False)
(conv_cls): Conv2d(384, 18, kernel_size=(1, 1), stride=(1, 1))
(conv_reg): Conv2d(384, 42, kernel_size=(1, 1), stride=(1, 1))
(conv_dir_cls): Conv2d(384, 12, kernel_size=(1, 1), stride=(1, 1))
2.7 损失函数
Head的3个分支基于anchor分别预测了类别, bbox框(相对于anchor的偏移量和尺寸比)和旋转角度的类别


分类损失:FocalLoss。
三维目标框回归损失:SmoothL1Loss。
方向损失:CrossEntropyLoss。
【三维目标检测】Pointpillars(二)_Coding的叶子的博客-CSDN博客_pointpillars的backbone secfpn的意思是啥
3D点云 (Lidar)检测入门篇 - PointPillars PyTorch实现_zhulf0804的博客-CSDN博客_lidar入门

