
- 1MySQL行锁、表锁、悲观锁、乐观锁的特点与应用_数据库行锁使用场景举例
- 2智能家居真正的大玩家 阿里拥抱 碧桂园买单
- 3Android R 新特性分析及适配指南_安卓r
- 4分享32个高质量的自学网站_oeasy自学网
- 5C++ 取整_c++ 整除
- 6AndroidStudio报错:have you declared this activity in your AndroidManifest.xml?
- 7什么是虚拟机管理程序hypervisor,什么是hypervisor type 1, hypervisor type 2_type 1和type 2的hypervisor
- 8人工智能_大模型041_模型微调001_ChatGLM函数调用功能测试_微调前后功能对比_lora微调_HuggingFace模型训练利器_模型训练流程---人工智能工作笔记0176
- 9RN的安卓和iOS打包步骤(软件托管平台推荐)
- 10AI绘画Stable DIffusion教程 | 如何利用 Stable Diffusion webui 将图片变得更清晰?全方位对比4种放大方法!_stable diffusion 放大图片
论文阅读:Whole slide images classification model based on self-learning sampling_whole slide image classification
赞
踩
论文介绍
这是一篇发表在BSPC(Biomedical Signal Processing and Control)上的关于WSI分类的文章, 作者是上海科技大学的学生/老师。
论文链接为:https://www.sciencedirect.com/science/article/pii/S1746809423012594
代码:暂未开源
摘要
深度学习与计算病理学的结合的增加放大了整个WSI在现代临床诊断中的应用。然而,整个WSI的直接加载经常受到内存限制的阻碍。传统的将WSI分割成图像补丁进行随机抽样策略引入了冗余病理信息,无法实现端到端训练。为了解决这个问题,我们引入了一个以自学习采样为中心的WSIS分类模型。首先,我们为病理图像引入了一个自学习采样模块,将选定的关键补丁嵌入到Transformer编码器中,得到补丁之间的相关性信息,可以实现整个网络的端到端训练。我们还实现了一个组合的焦点和采样损失函数来解决病理图像样本的不平衡分布和采样冗余。在TCGA-LUSC数据集和协作医院结肠癌数据集上测试,证明了我们的模型能够与先进的TransMIL方法的准确性和AUC相媲美。值得注意的是,与 TransMIL 相比,我们的模型减少了 WSI 推理时间,从而在各自的数据集上提高了 15.1% 和 22.4%。
引言
文章在引言部分介绍如下:
- 介绍了一下WSI的重要性(金标准)以及使用计算机来辅助分类的原因。
- 指出因为WSI的分辨率通常比较大而导致不能使用例如GooleNet以及DenseNet等模型进行端到端训练的问题。针对这个问题,现有的一些研究,如DSMIL等关于WSI分类的方法是将整个WSI切分成不重叠,大小相等的子图片(patch)来进行处理。但是这种方法有一些问题在里面:
- 第一, 由于现有的计算和存储能力有限,不可能会对所有的patch来进行网络训练,从而实现WSI分类。
- 第二,不是每一个patch都可以提供有效的信息。例如, WSI中的脂肪组织区域的patch。
针对上面的两个问题,对patch进行下采样处理是一种有效的手段。因此,如何对WSI进行下采样处理以尽可能地保留有意义的内容是非常有意义的。但这个领域至今还很少人关注。
- 针对上面提出的对WSI进行下采样处理进行论述。指出直接下采样会丢失重要信息,而现有的方法都是先将WSI进行切块处理(也就是切成256×256大小的图片),再对这些子图片进行下采样处理。当前下采样处理的技术主要有随机采样以及聚类采样。但是这些采样方法需要尽可能多的patch来表示整个WSI的特征。且它们不可微,也就是说它们不能使用深度学习来处理。针对这个情况,引出了点云下采样,并介绍了一些点云下采样的方法。最终引出自己的目的:使用可微的自学习采样方法代替不可微的采样方法,通过少量的关键patch来平衡分类任务的性能以及计算效率,确保任务性能的同时减少资源的消耗。随机采样与自学习采样的比较如下表1.

- 本文的贡献如下:
- 提出了一种新的基于自学习采样的WSI分类模型,使网络可以实现端到端训练,解决了当前WSI下采样研究方法中不可微的问题。
- 在框架中构建了一个自学习采样模块,实现了网络的反向传播。
- 制定了一个综合损失函数,由focal损失以及采样损失组成。解决病例图像中样本比例不平衡和采样冗余的挑战
- 方法在所比较的数据集上具有优势。
相关工作
首先介绍了组织病理图像分类的相关工作。在这一部分中,先大致介绍了全监督的组织病理图像分类,并指出它需要标注好数据,且这种详细的标注会给病理专家带来负担。针对这个问题,进一步介绍了基于MIL的WSI分类方法,如ABMIL, TransMIL等。其次,介绍了组织病理学采样的方法。
方法
问题定义
想预测每张WSI属于哪一个类别,正常的为0,否则为1。介绍了采样方法,先裁剪成同样大小的不重叠的patch,然后每个WSI都进行随机采样,从而得到一个等长的patch集合P。采样后的子集大小为k( k ≤ n k \le n k≤n, n为P的大小)。随后用一个分类任务网络T来对这些patch进行分类,找到最小的k个patch组合成的子集,使得总损失 L t o t a l L_{total} Ltotal最小。如此,问题就转变成了一个最优化问题。
模型结构
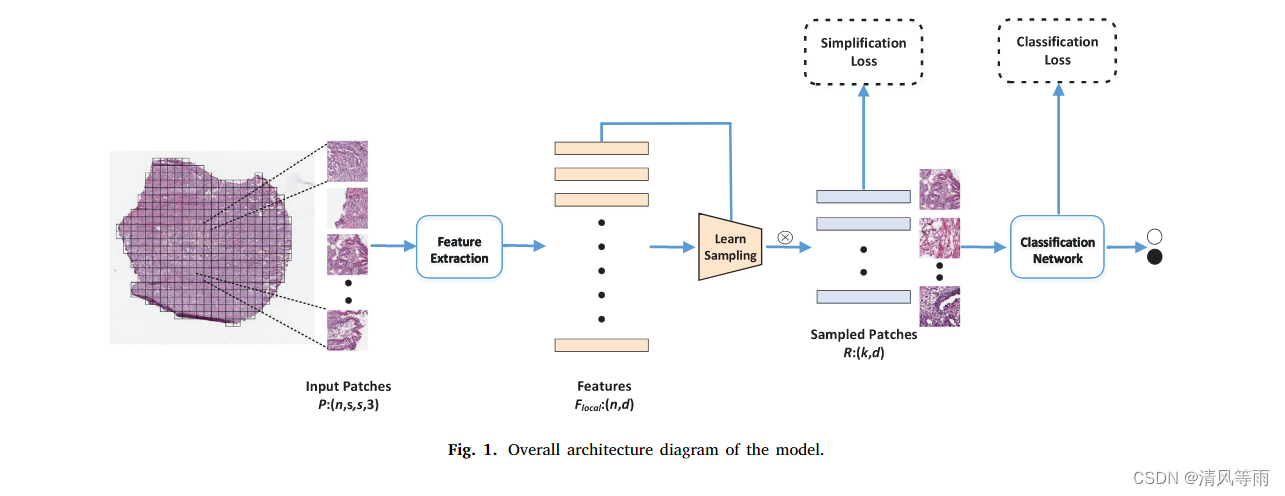
整体模型结构如图所示,整体模型包括特征提取模块、自学习采样模块以及基于Transformer的特征编码和分类模块三个模块。在特征提取之后,将特征集
F
l
o
c
a
l
F_{local}
Flocal输入到自学习采样模块,并得到一个采样矩阵S,将其与
F
l
o
c
a
l
F_{local}
Flocal相乘之后得到一个集合R,这个R包含了k个patch。随后将这个R集合和分类标签输入到Transformer中去获取patch之间的空间联系,并最终由全连接层进行分类。
同时,从图中可以看到整个网络框架由两个损失,其中
L
s
a
m
p
l
i
n
g
L_{sampling}
Lsampling是让采样的patch与子集P相似,而
L
c
l
a
s
s
i
f
i
c
a
t
i
o
n
L_{classification}
Lclassification则是让分类性能越高越好的一个损失。
特征提取
这一部分与之前的方法一样,首先先对WSI进行缩略图检测,从而得到具有组织病理的部分并对这部分进行裁剪。之后,对得到的patch使用resnet进行特征提取。裁剪的方法为:1.使用颜色阈值移除非组织区域,并以此得到一个二进制掩码,对于组织部分,值为1,否则为0。第二,对二进制掩码进行划分,使用最小阈值方法过滤掉部分patch。文中设置的阈值为50%,即每个patch中组织部分面积与背景的比例大于50%,则认为其有效,否则无效。
自学习采样模块
首先指出当前WSI采样方法存在的问题:不可微。这个问题会导致下游分类任务无法生成与任务相关的关键patch。并根据这个说明引出自学习采样方法(受LSNet的启发),流程图如下:

图中,
F
l
o
c
a
l
F_{local}
Flocal是输入,也就是经过resnet得到的特征表达,而
F
g
l
o
b
a
l
F_{global}
Fglobal则是对
F
l
o
c
a
l
F_{local}
Flocal进行最大池化操作之后得到的特征,随后将全局特征和局部特征进行拼接,对拼接之后的特征送入到两层全连接层的MIL网络层和Sigmoid激活函数之中,得到
S
ˉ
\bar{S}
Sˉ,之后,在利用带有
τ
\tau
τ的softmax函数得到sampling matrix,文中
τ
\tau
τ设置为0.001。
最后,使用公式证明输入图像的顺序对结果是没有影响的。
基于Transformer的特征编码
这一部分其实就是讲述了一下TransMIL的网络组成
损失函数
L
c
l
a
s
s
i
f
i
c
a
t
i
o
n
L_{classification}
Lclassification为focal loss:

L
s
a
m
p
l
i
n
g
L_{sampling}
Lsampling是为了调节采样效率,尽可能保留更多的特征表达。其公式为:

因此整个损失函数的计算为,其中
β
\beta
β为自定义系数,用于调节两个损失函数,保持平衡:

实验分析和结论
使用的数据集:TCGA-LUSC数据集以及私有数据集。
实验细节:对LUSC裁剪成256×256, 自己的数据集裁剪成512×512。但最终都会被resize成256×256的大小,送到网络中。数据划分是65:10:25的比例划分,采用5次测试的平均结果当做最终结果。
使用的指标:AUC Acc
其他细节: SCD优化,学习率为0.001,batchsize为1。focal loss中
α
\alpha
α以及
γ
\gamma
γ分别设置为0.25和2。总共有200次迭代,使用不同的种子进行5次实验,但数据集的划分不变。
实验结果如下:


总结
这篇文章引入了点云采样技术来对实例特征进行采样,从而提高了对WSI分类的效率。从实验结果上来看,在更少的采样次数以及更少的时间里,得到的结果与当前最好的结果相似。算是一个不错的引入。
但有几个问题。第一,只显示了在20次的时候结果差不多,但是往后,结果会不会提高,会提高多少,文中没有展示,而从结果上来看,总的结果和TransMIL差不多,20次时,结果比TransMIL低一些,速度比TransMIL快,且采样次数更少,但没有更有利的证据说服。第二,文中的可视化结果只是比较了随机采样和作者提出的自学习采样,但并没有给出自己的框架的最终可视化结果和其他方法的对比。第三,文中对比的方法比较少,最新的是TransMIL,而本文发表的时间是在2023年,这之中还有着其他的方法可以得到更好的结果,这篇文章没有对比。
更多关于多实例WSI分类的文章阅读,请关注公众号:


