- 1MongoDB 覆盖索引查询:提升性能的完整指南
- 2linux的ollama卸载_ollama 停止运行
- 3达梦DMHS-Manager工具日常操作_达梦管理工具
- 4git干获,从安装到上传项目(详细)_安装git 项目
- 5Java面试常见的面试题(持续更新版)_java面试题
- 6qmt教程2----订阅单股行情,提供源代码_qmt交易代码
- 7android RadioButton自定义图片样式_安卓radiobutton增加图片
- 8YOLO_V8训练自己的数据集_yolov8训练自己的数据集
- 9输入n个字符串,进行排序,然后从小到大输出_一行内输入n个字符串,按字典序从小到大进行排序后输出。
- 10《软件安装与使用教程》— Git 在Windows的安装教程_windows安装git
6D姿态估计算法汇总_6dof算法论文
赞
踩
介绍
6D目标检测,和传统的目标检测类似,都是从图像(包括点云)中去识别物体的位置。
传统的2D目标检测,像是SSD、YOLO等,识别的结果是一个边界框(bounding box)
而3D目标检测的结果则是一个3D的边界框。
6D目标检测的输出结果包括两个部分:
物体的空间坐标:x, y, z
物体的三个旋转角: pitch, yaw, roll
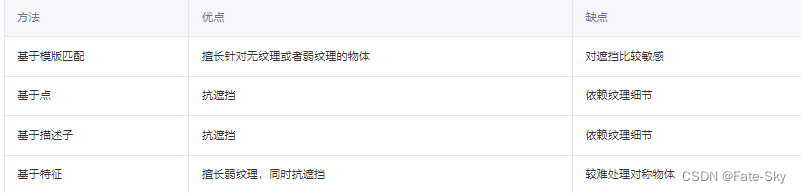
传统的6D目标检测可以被分类成以下几种:
基于模版匹配
基于点
基于描述子
基于特征
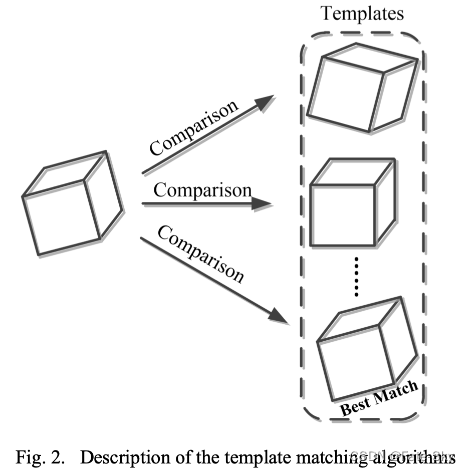
基于模版匹配的算法
基于模版匹配的算法,其思路就是: 生成尽可能多的模版,每一个模版表示不同的旋转姿态,同原图进行相似度的计算
由于实际环境会受到光照、遮挡的影响,这类算法在这种情况下表现较差。
同时,由于需要生成多的模版,所以算法的计算代价也较高。
较为经典的模版匹配算法,比如 linemod
使用了图像的色彩梯度(Color Gradient) 来抵抗光照和噪声等影响,同时引入了深度信息来构建数个表面垂直向量来作为特征模版匹配
 基于点的算法
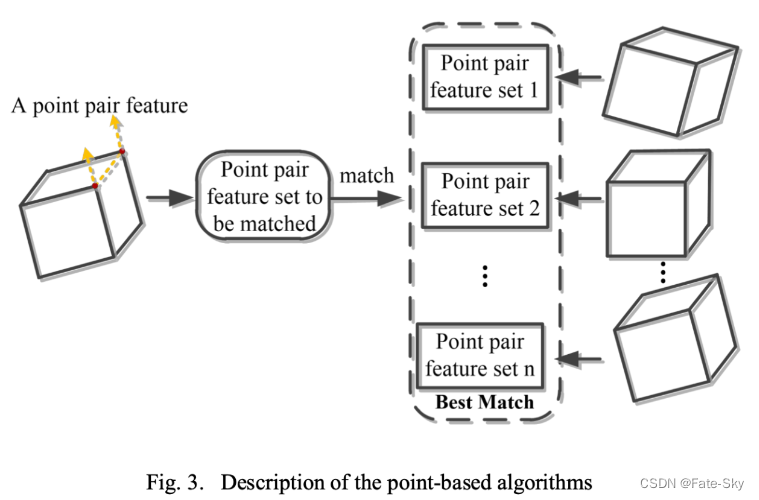
基于点的算法
这里所说的点,其实是空间中的点。基于点的算法,其本质是: 利用点云之间的匹配来实现姿态估计
和模版匹配类似,通过构造一些点的特征,边的特征,然后生成不同姿态下的特征集合,通过特征匹配进而实现点云的匹配。
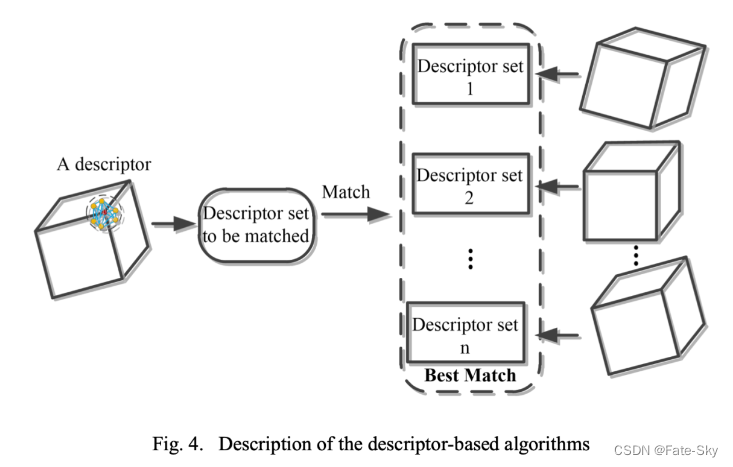
基于描述子的算法
描述子通常是用来刻画点周围的一些几何特征,比如说:点坐标的特点,法向量或者是曲线
该方法和基于点的方法类似,都对纹理特征依赖比较严重
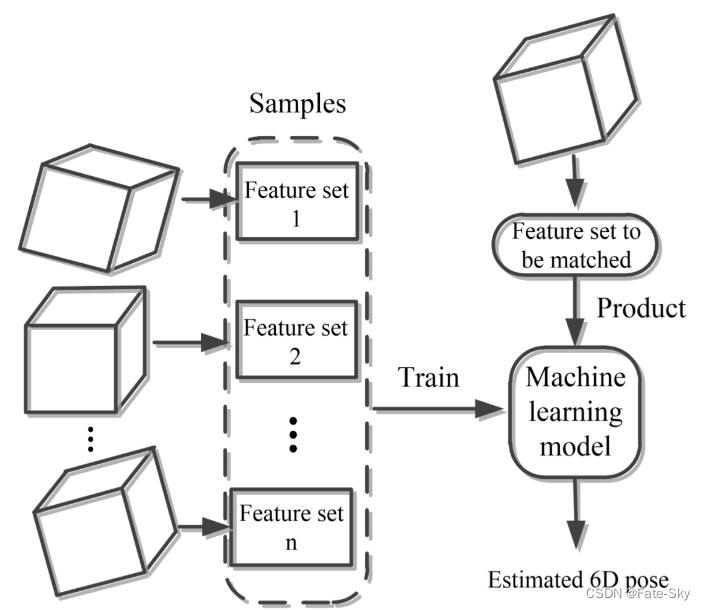
基于特征的算法
同样的,我们需要生成一系列特征集合,进行模型的训练,如下图所示:
基于深度学习的6D姿态估计
这里,我们将所有的基于深度学习的方法分成两类:
基于RGB图像的方法
基于RGB-D图像的方法
RGB-D图像即是在原本的图像通道上,加了一个深度通道,代表像素点的深度信息
基于RGB图像的深度学习方法
这里给出一些相关的方法的总结表格
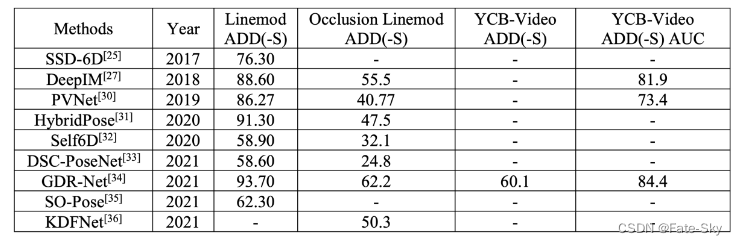
1、DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion (CVPR2019)
原文链接:https://arxiv.org/abs/1901.04780
代码链接:https://github.com/j96w/DenseFusion
主要思想:用于从RGB-D图像中估计一组已知对象的6D位姿,分别处理两个数据源,并使用一种新的dense fusion network来提取像素级的 dense feature embedding,并从中估计姿态。实验结果表明,该方法在YCB-Video和Linemod两种数据集上均优于现有的方法。论文还将所提出的方法应用到一个真实的机器人上,根据所估计的姿态来抓取和操纵物体。
本文主要有两点贡献:
1、提出了一种将RGB-D输入的颜色和深度信息融合起来的基础方法。利用嵌入空间中的2D信息来增加每个3D点的信息,并使用这个新的颜色深度空间来估计6D位姿。
2、在神经网络架构中集成了一个迭代的微调过程,消除了之前后处理ICP步骤的依赖性。
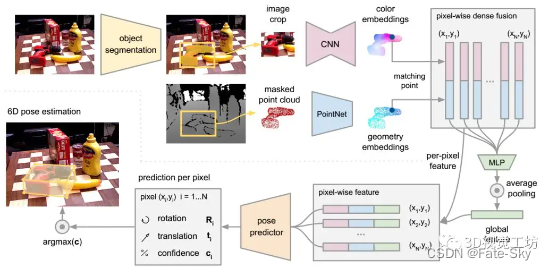

实验结果:
2、PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation
论文链接:https://arxiv.org/pdf/1812.11788.pdf
代码链接:https://github.com/zju3dv/pvnet
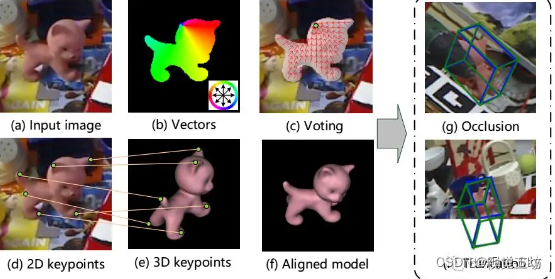
本文提出采用Pixel-wise Voting Network (PVNet)来回归指向关键点的像素单位向量,并通过这些向量使用RANSAC对关键点位置进行投票,从而可以抗遮挡或截断。进一步地,这种表示提供了关键点位置的不确定性,PNP解算器又可以进一步利用这些不确定性。
主要贡献点:
1、提出了PVNet(pixel-wise voting network),它可以学习到一个指向2D keypoint的向量场表示,即便在遮挡和截断的情况下;作者的创新之处–能够学习到十分robust的2D keypoints。
2、基于PVNet得到的稠密预测,作者用了一种基于关键点分布的PnP算法来从2D keypoints分布求取(R,t)位姿。
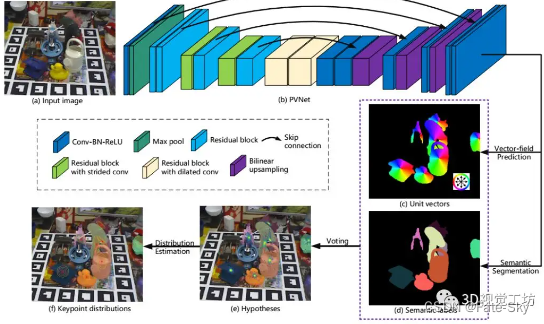
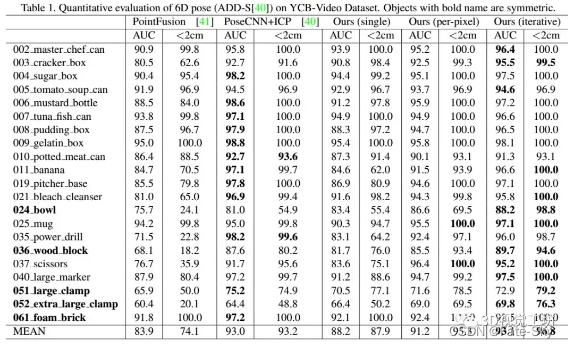
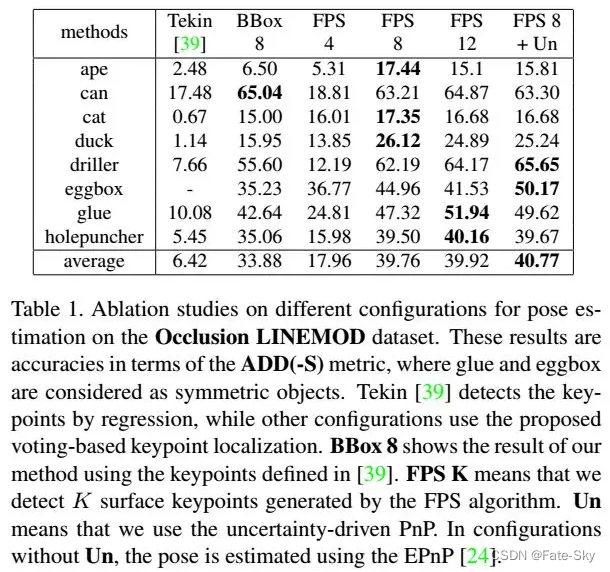
实验结果

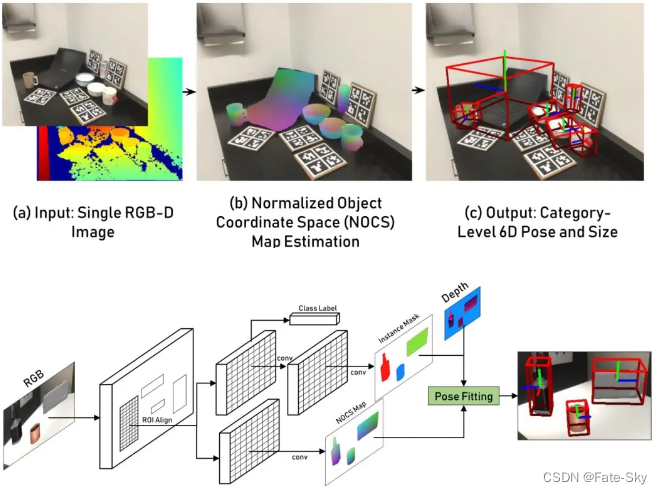
3、Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation(CVPR2019)
论文链接:https://arxiv.org/abs/1901.02970
代码链接:https://github.com/hughw19/NOCS_CVPR2019
本文的目标是估计RGB-D图像中从未见过的物体实例的6D位姿和尺寸。与“实例级”6D位姿估计任务相反,作者假设在训练或测试期间没有精确的CAD模型可用。为了处理给定类别中不同的和从未见过的物体实例,作者引入了标准化物体坐标空间(简称NOCS),即同一个类别中的所有物体实例使用一个共享的标准模型来表示。然后,通过训练神经网络来推断观察到的像素与共享标准模型的对应关系以及其他信息,例如类别标签和mask。通过将预测图像与深度图相结合,共同估计杂乱场景中多个物体的6D位姿和尺寸。为了训练网络,作者提出了一种新的上下文感知技术来生成大量带注释的混合现实数据。为了进一步改进模型并评估它在真实数据上的性能,作者还提供了一个完全注释的真实场景下的数据集。大量实验表明,该方法能够鲁棒地估计真实场景中从未见过物体的位姿和大小。
主要贡献:
1、使用一个共享的标准坐标空间(NOCS)作为参考系来表示同一类别中的所有物体实例。
2、提出一个可以同时预测物体类别标签、mask和NOCS图的CNN,将NOCS图与深度图进行对应来估计从未见过物体的位姿和大小。
3、使用空间上下文感知的混合现实方法来自动生成大量数据用来训练和测试。
实验结果:

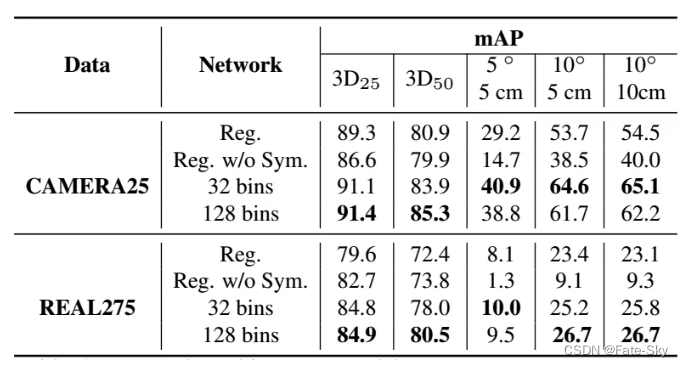
4、Pix2Pose: Pixel-Wise Coordinate Regression of Objects for 6D Pose Estimation(ICCV2019)
论文链接:https://arxiv.org/abs/1908.07433
主要思想:由于遮挡和对称性等问题,仅使用RGB图像估计物体的6D姿态仍然具有挑战性。如果没有专家知识或专业的扫描设备,也很难构建具有精确纹理的三维模型。为了解决这些问题,我们提出了一种新的位姿估计方法Pix2Pose,它可以在没有纹理模型的情况下预测每个目标像素的三维坐标。设计了一种自动编码器结构来估计三维坐标和每个像素的期望误差。然后将这些像素级预测用于多个阶段,形成2D-3D对应关系,用RANSAC迭代的PnP算法直接计算姿态。我们的方法通过利用最近在生成性对抗训练中的成果来精确地恢复被遮挡的部分,从而对遮挡具有鲁棒性。此外,提出了一种新的损耗函数变压器损耗,通过将预测引导到最接近的对称姿态来处理对称目标,对包含对称和遮挡目标的三个不同基准数据集的计算表明,我们的方法优于仅使用RGB图像的最新方法。
本文的主要贡献:
1、提出了一种新的6D姿态估计框架Pix2Pose,该框架在训练过程中使用无纹理的3D模型从RGB图像中稳健地回归出目标的像素级3D坐标。
2、一种新的损耗函数:transformer loss,用于处理具有有限个模糊视图的对称对象。
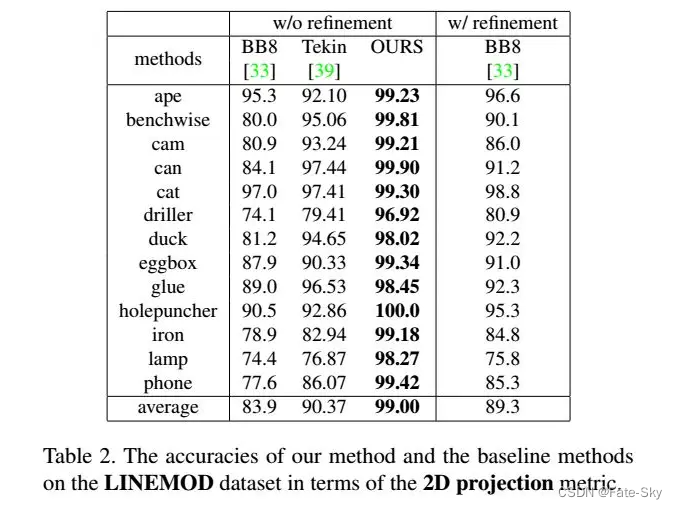
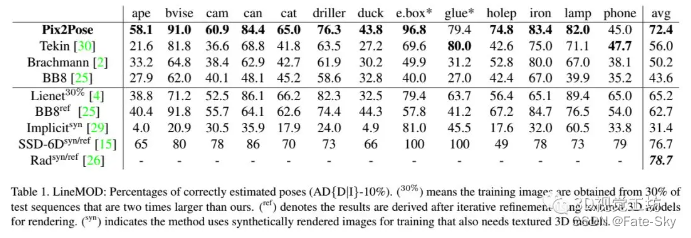
3、在LineMOD、LineMOD Occlusion和TLess三个不同数据集上的实验结果表明,即使对象是被遮挡或对称的,Pix2Pose也优于最新的方法。
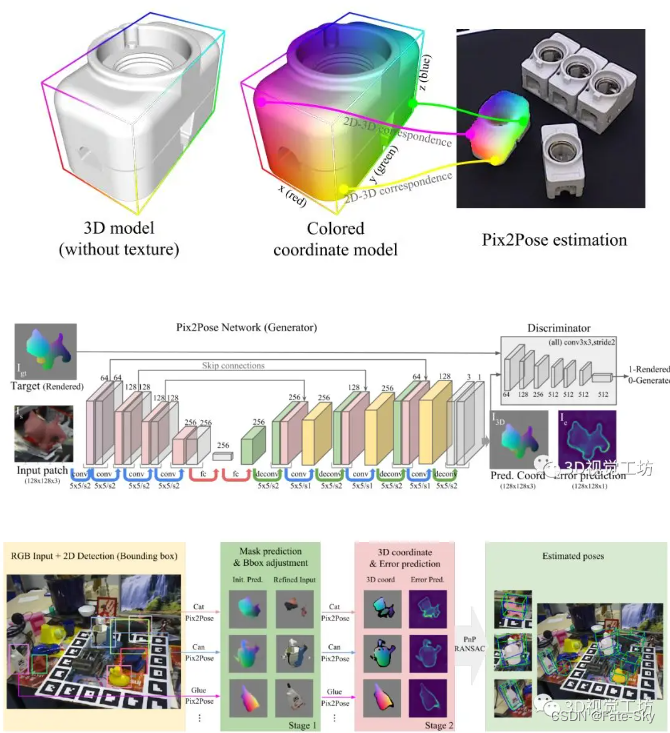
实验结果
5、Deep-6DPose: Recovering 6D Object Pose from a Single RGB Image
论文链接:https://arxiv.org/abs/1802.10367v1
主要思想:仅从RGB图像中检测物体及其6D姿态是许多机器人应用的重要任务。虽然深度学习方法在视觉目标检测和分割方面取得了显著的进展,但目标姿态估计任务仍然具有挑战性。本文介绍了一个端到端的深度学习框架deep-6DPose,它可以从单个RGB图像中联合检测、分割和恢复对象实例的6D姿态。特别地,我们将最新的实例分割网络Mask R-CNN扩展到一个新的姿态估计分支,直接回归6D目标姿态,而不需要任何后处理。我们的关键技术贡献是将姿态参数解耦为平移和旋转,以便通过李代数表示来回归旋转。由此产生的姿态回归损失是微分的,不受约束的,使训练变得容易处理。在两个标准位姿基准数据集上的实验表明,我们提出的方法与目前最先进的基于RGB的多阶段位姿估计方法相比,具有更好的性能。重要的是,由于端到端的架构,Deep-6DPose比竞争对手的多阶段方法快得多,提供了10 fps的推理速度,非常适合机器人应用。
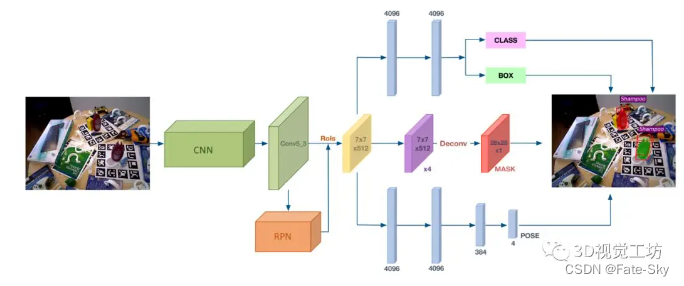
实验结果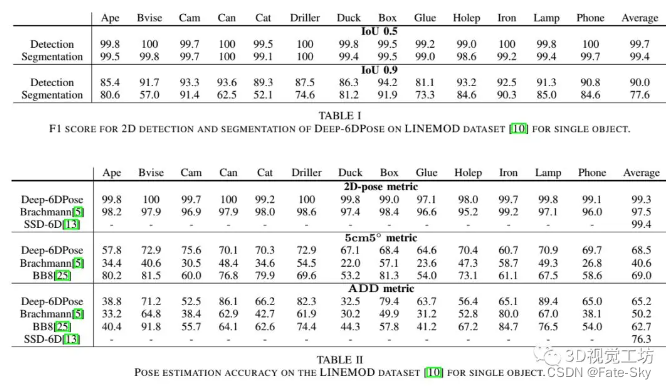

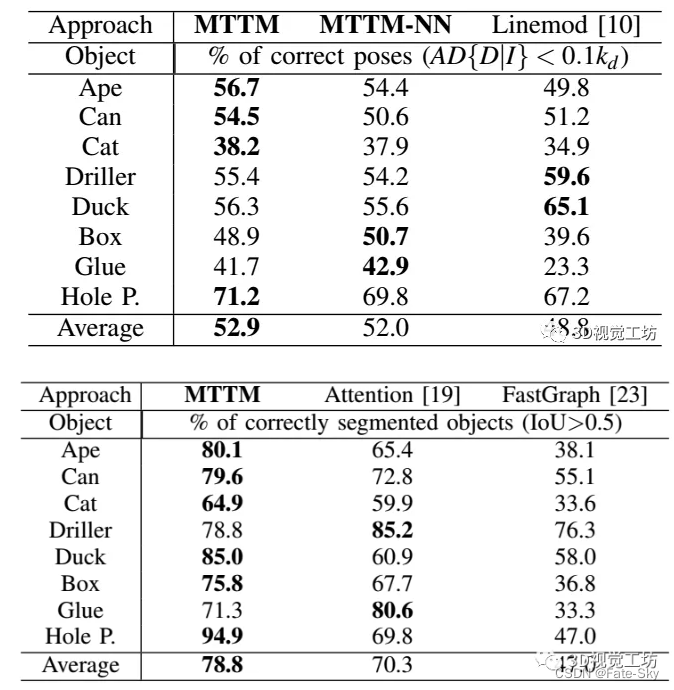
6、Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images(ICRA2019)
论文链接:https://ieeexplore.ieee.org/document/8794448
主要思想:在有限样本数下,模板匹配可以准确估计新目标的姿态。然而,遮挡物体的姿态估计仍然是一个挑战。此外,许多机器人应用领域遇到深度图像比颜色图像更适合的无纹理对象。本文提出了一种新的多任务模板匹配(MTTM)框架,该框架在预测分割掩模的同时,从深度图像中找到目标物体最近的模板,并利用目标区域的相同特征映射实现模板与被检测物体在场景中的位姿变换。提出的特征比较网络通过比较模板的特征映射和场景的裁剪特征来计算分割遮罩和姿态预测。该网络的分割结果通过排除不属于目标的点,提高了姿态估计的鲁棒性。实验结果表明,尽管MTTM方法仅使用深度图像,但在分割和姿态估计方面优于基线方法。
主要创新点:
1、提出一个新的基于深度的框架:MTTM,通过与模板进行近邻匹配,使用共享的特征图来预测分割mask和物体的位姿。
2、不需要将物体与场景对齐来生成mask。
3、这种方法优于使用RGB的baseline方法。

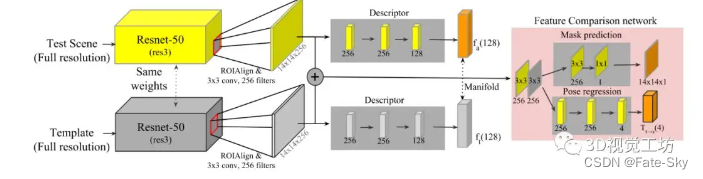
实验结果

7、Real-Time Seamless Single Shot 6D Object Pose Prediction(CVPR2018)
论文链接:https://arxiv.org/abs/1711.08848
代码链接:https://github.com/Microsoft/singleshotpose
主要思想:我们提出了一种单阶段方法来同时检测RGB图像中的一个物体并预测其6D姿态,不需要多个阶段或检查多个假设。不像最近提出的一些单阶段技术,它只预测一个近似6D的姿势,然后必须细化,我们是足够精确的,不需要额外的后处理。它的速度非常快,在Titan X(帕斯卡)GPU上每秒50帧,因此更适合实时处理。我们的方法的关键部分是一个新的CNN架构,直接预测对象的3D边界框的投影顶点的2D图像位置,然后用PnP算法估计物体的6D姿态。
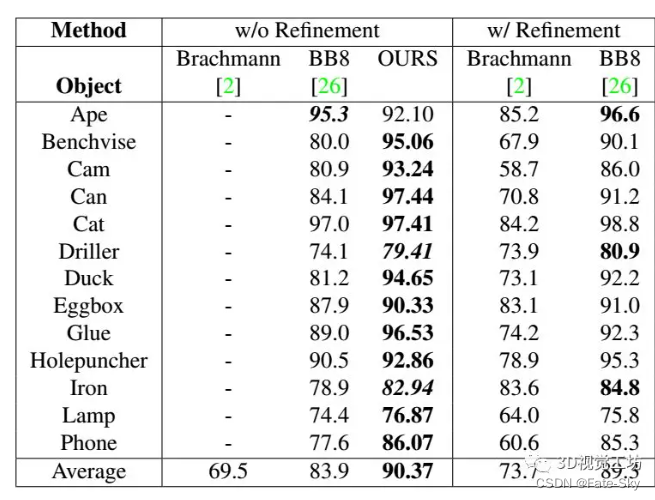
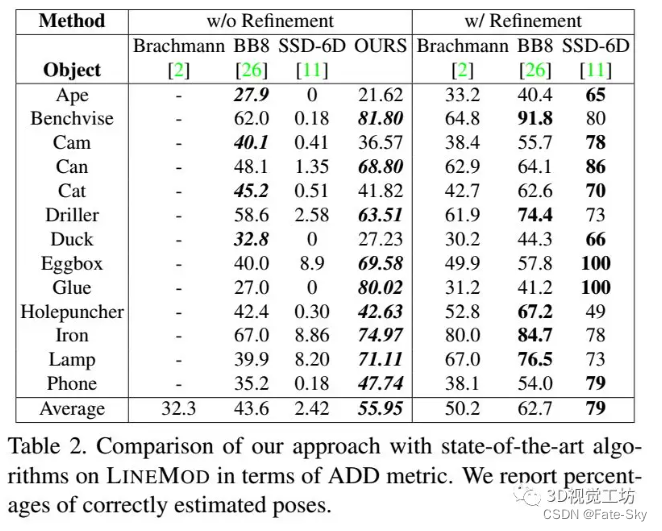
我们的单目标和多目标姿态估计方法在LINEMOD和OCCLUSION数据集上明显优于其他最近基于CNN的方法。
主要贡献:论文的主要贡献是一个新的网络架构,即一个快速和准确的单阶段6D姿势预测网络,不需要任何后处理。它以无缝和自然的方式扩展了用于二维检测的单阶段CNN结构去执行6D检测任务。实现基于YOLO,但该方法适用于其他单阶段检测器,如SSD及其变体。
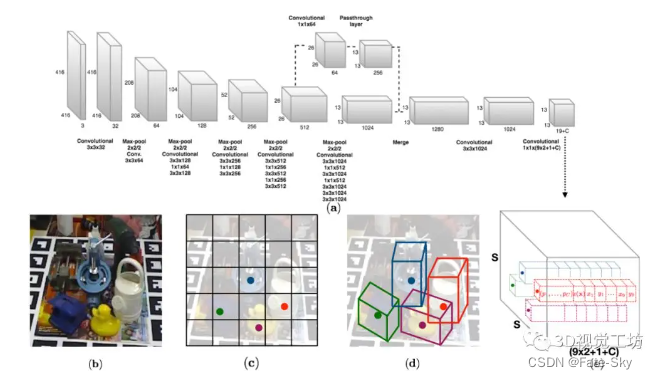
8、SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again
论文链接:https://arxiv.org/abs/1711.10006v1
代码链接:https://github.com/wadimkehl/ssd-6d
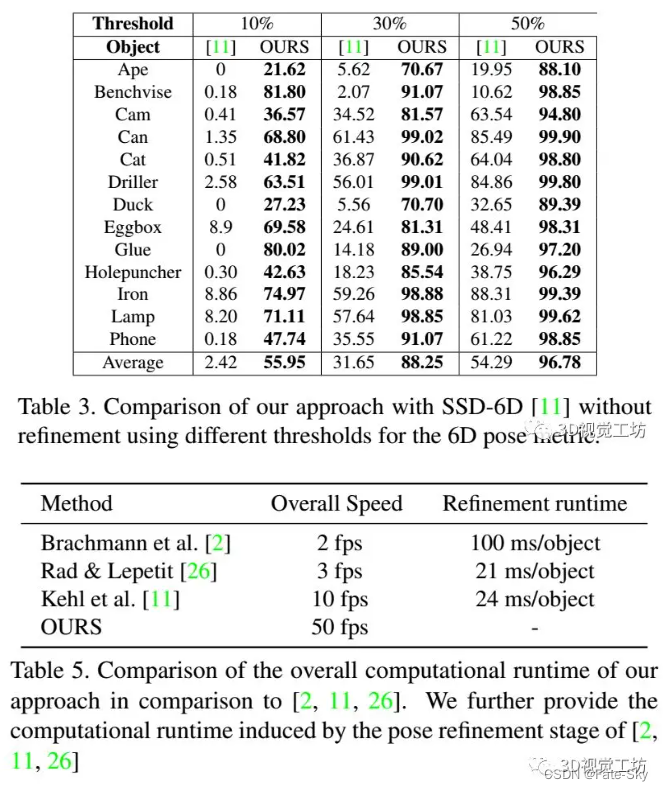
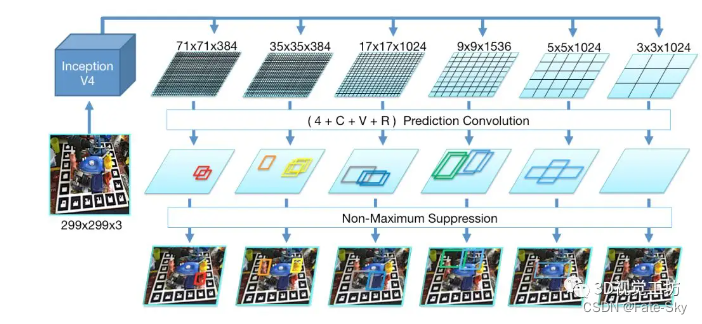
主要思想:提出了一种新的基于RGB数据的三维模型实例检测和6D姿态估计方法。为此,我们扩展了流行的SSD范式,以覆盖完整的6D姿势空间,并仅对合成模型数据进行训练。我们的方法可以与当前最先进的方法在多个具有挑战性的RGBD数据集上竞争或超越。此外,我们的方法在10Hz左右,要比相关的其它方法快很多倍。
主要贡献:
(1) 一个仅利用合成三维模型信息的训练阶段
(2) 模型位姿空间的分解,便于对称性的训练和处理
(3) SSD的一种扩展,产生2D检测并推断出正确的6D姿势

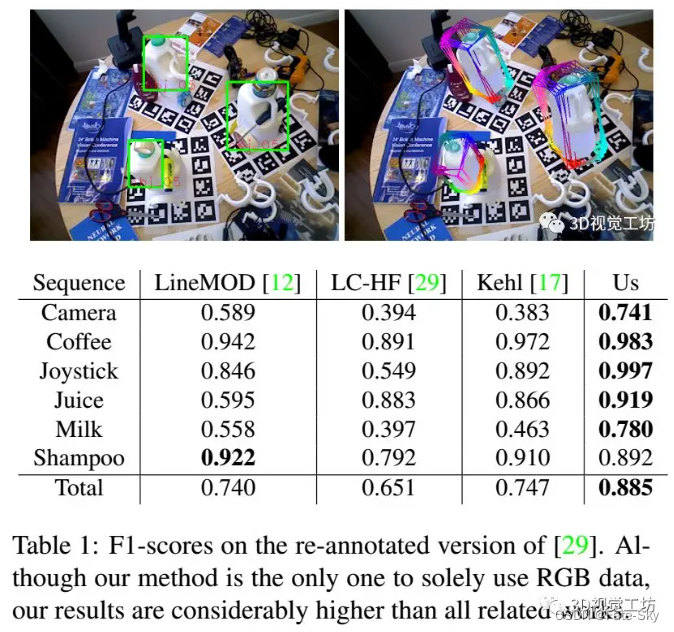
9、Pose-RCNN: Joint object detection and pose estimation using 3D object proposals
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7795763
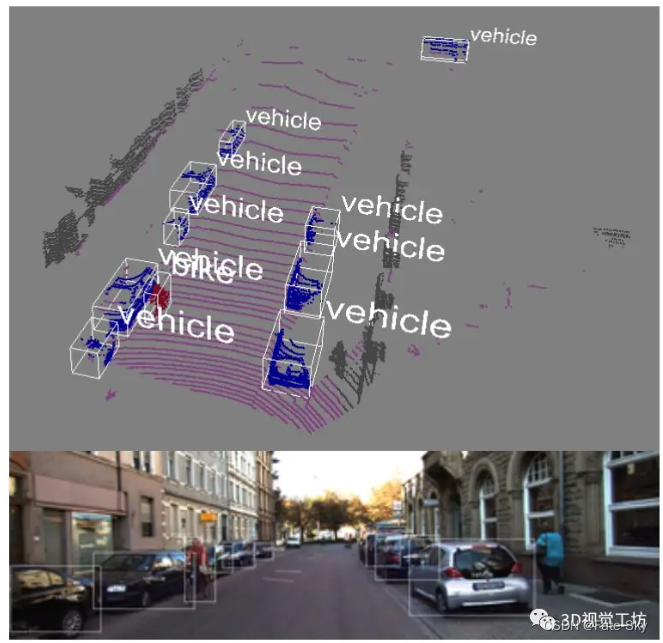
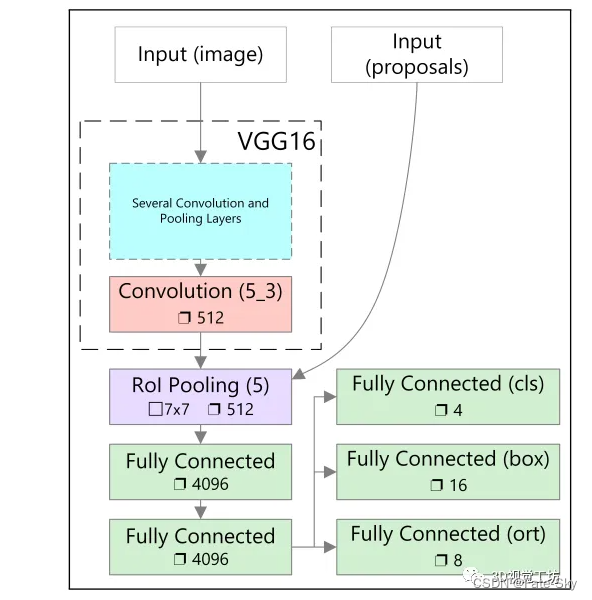
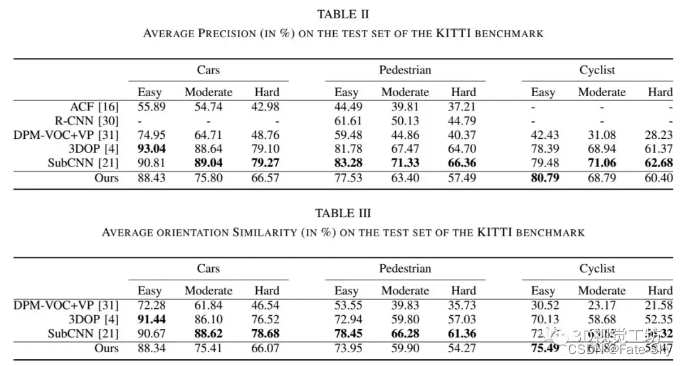
主要思想:本文提出了一种利用三维数据计算出的方案在单阶段深层卷积神经网络中进行联合目标检测和方向估计的新方法。对于方位估计,我们通过几个精心设计的层来扩展R-CNN结构。介绍了两种新的目标proposals方法,即利用立体数据和激光雷达数据。我们在KITTI数据集上的实验表明,通过合并两个领域的proposal,可以在保持低proposal数量下的同时实现高召回率。此外,在KITTI测试数据集的cyclists简单测试场景中,我们的联合检测和方向估计方法优于最新方法。

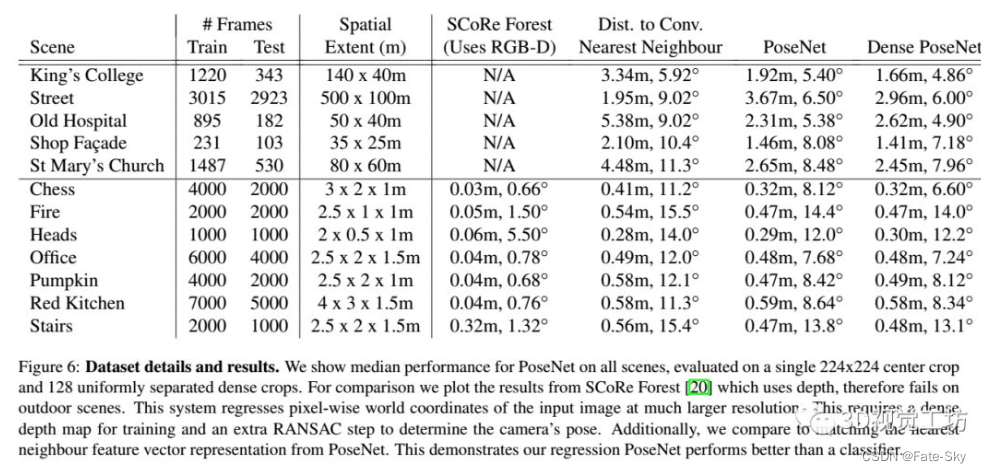
10、PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization
论文链接:
https://arxiv.org/abs/1505.07427
代码链接:
http://mi.eng.cam.ac.uk/projects/relocalisation/
主要思想:本文提出了一个鲁棒且可以实时运行的重定位系统,该系统利用一个CNN实现了输入为RGB图像输出为相机位姿的端到端定位系统。该系统在室内和室外都能够以每帧5ms的计算速度实时运行。其在室外场景的定位精度为2m&3°,在室内场景的定位精度为0.5m&5°。除此之外,提出了23层深度卷积网络PoseNet,利用迁移学习将分类问题的数据库用于解决复杂的图像回归问题。其训练得到的特征相较于传统局部视觉特征,对不同的光照、运动模糊以及不同的相机内参等具有更强的鲁棒性。同时,该论文展示了PoseNet基于已有的分类数据库可以在很少训练样本的情况下取得很好的性能。
主要贡献:
1、提出了一种自动标注方法,利用SfM自动生成训练样本的标注(相机位姿),可以仅利用视频生成用于训练PoseNet的训练样本和标注,不需要人工标注每一幅图像的位姿信息,极大地节约了人力成本。
2、提出迁移学习,利用训练好的分类器(classifier)以及少量的训练样本训练得到用于重定位的回归器(regressor),可以有效解决训练样本不足的问题。

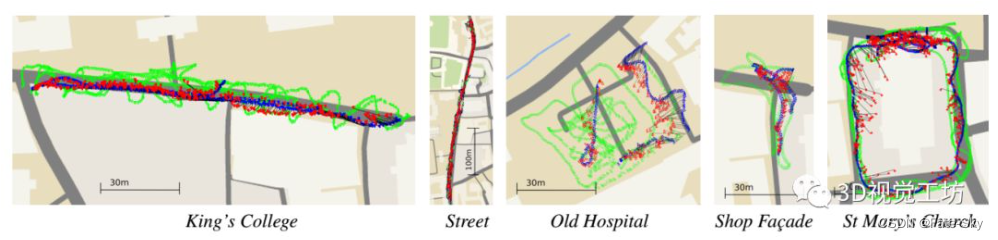
实验结果

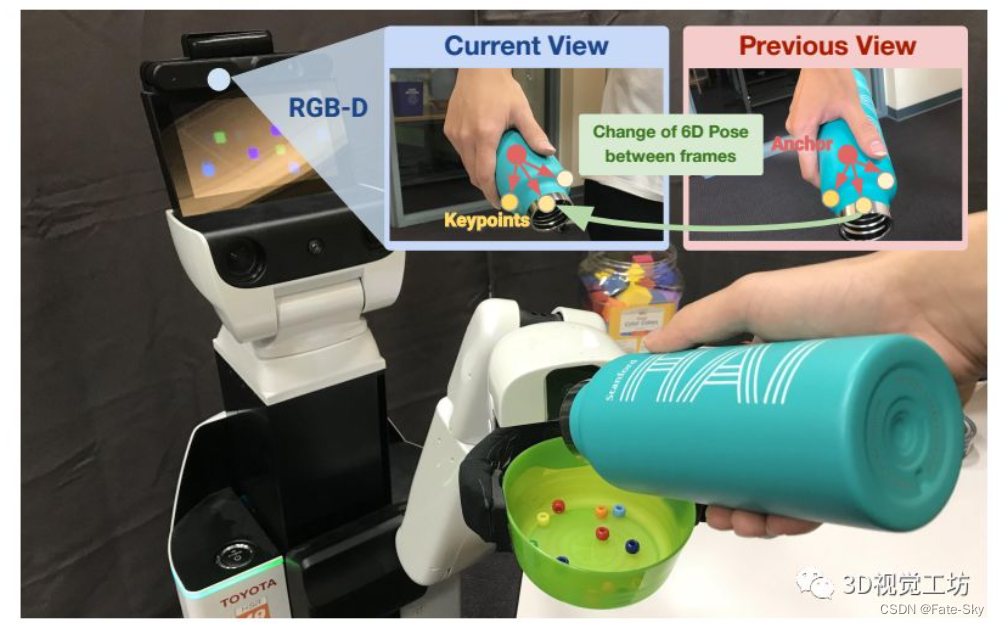
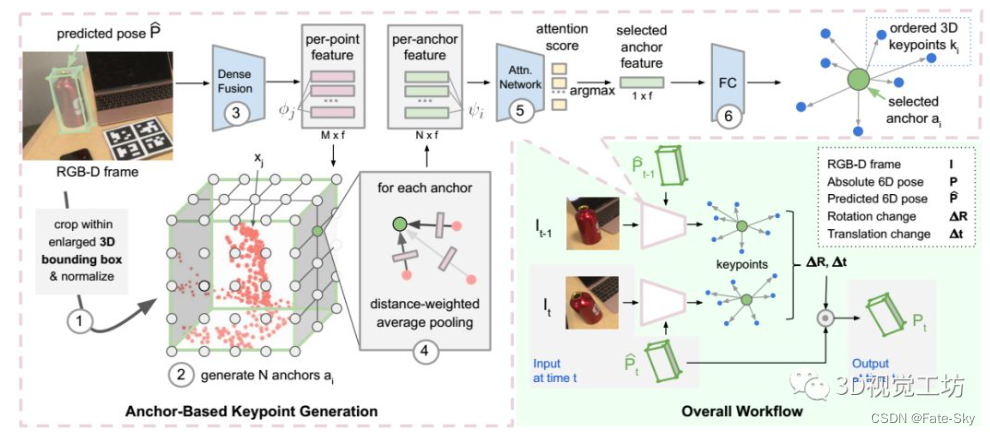
11、6-PACK: Category-level 6D Pose Tracker with Anchor-Based Keypoints
论文链接:https://arxiv.org/abs/1910.10750v1
代码链接:
https://sites.google.com/view/6packtracking
主要思想:本文提出了一种基于RGB-D数据的类别级6D目标姿态跟踪的深度学习方法-6-PACK算法。论文中的方法可以实时跟踪已知对象类别(如碗、笔记本电脑和杯子)的新对象实例。6-PACK学习通过少量的3D关键点来紧凑地表示对象,在此基础上通过关键点匹配来估计对象实例的帧间运动。这些关键点在没有人工监控的情况下端到端学习,以便最有效地跟踪。实验表明,这种方法大大优于现有方法上的NOCS类别6D姿态估计基准,并支持物理机器人执行简单的基于视觉的闭锁循环操作任务。
主要贡献:
1、这种方法不需要已知的三维模型。相反,它避免了通过类似于2D对象检测中使用的proposals方法的新anchor机制来定义和估计绝对6D姿势的需要。
2、这些anchor为生成三维关键点提供了基础。与以往需要手动标注关键点的方法不同,提出了一种无监督学习方法,该方法可以发现用于跟踪的最佳三维关键点集。
3、这些关键点用作对象的紧凑表示,从中可以有效地估计两个相邻帧之间的姿态差。这种基于关键点的表示方法可以实现鲁棒的实时6D姿态跟踪。
实验结果
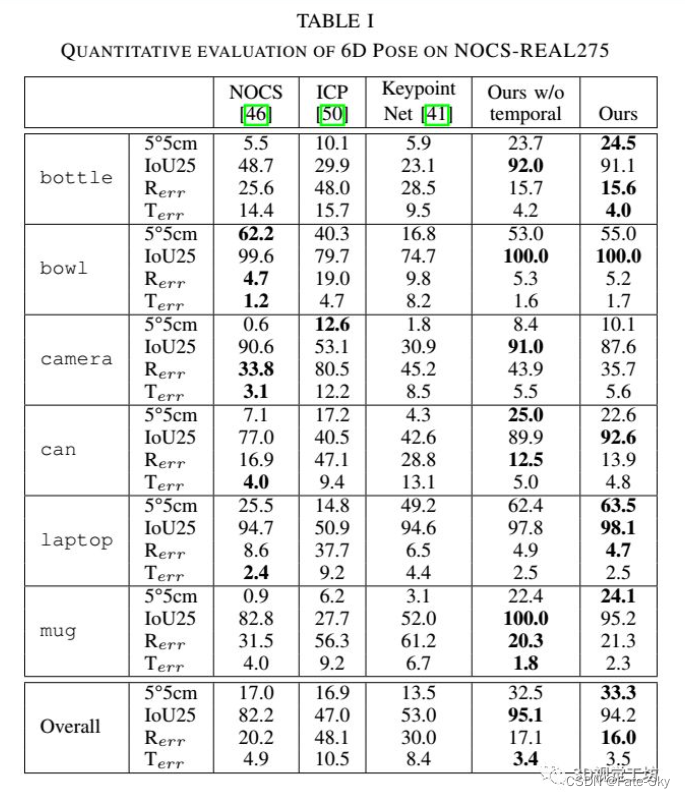

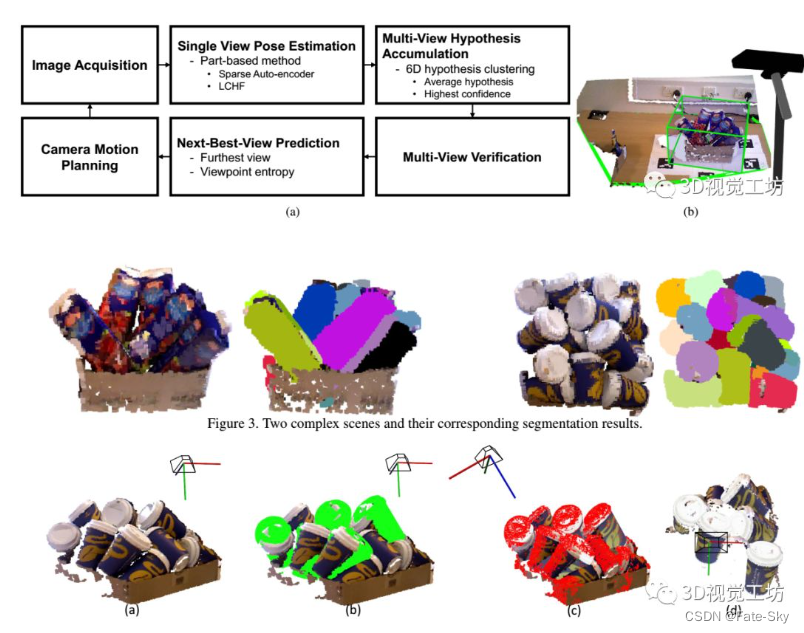
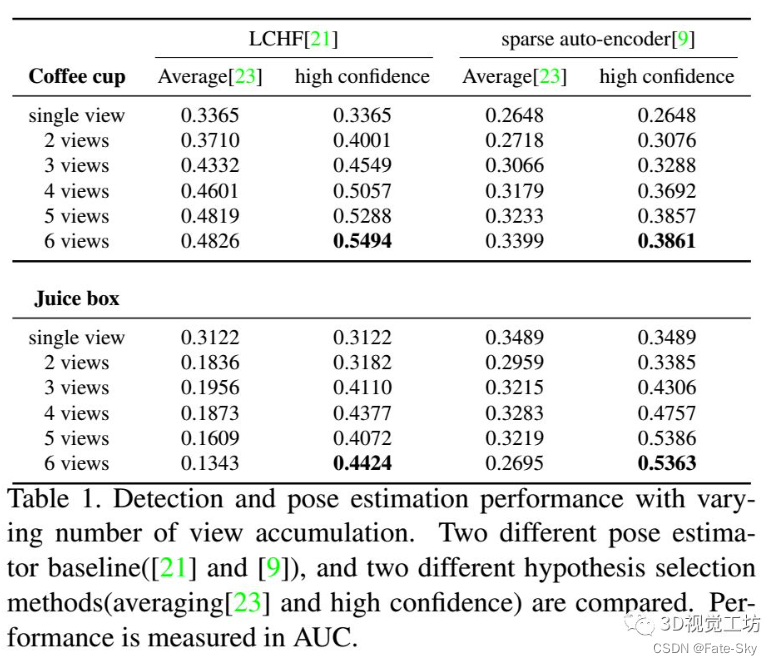
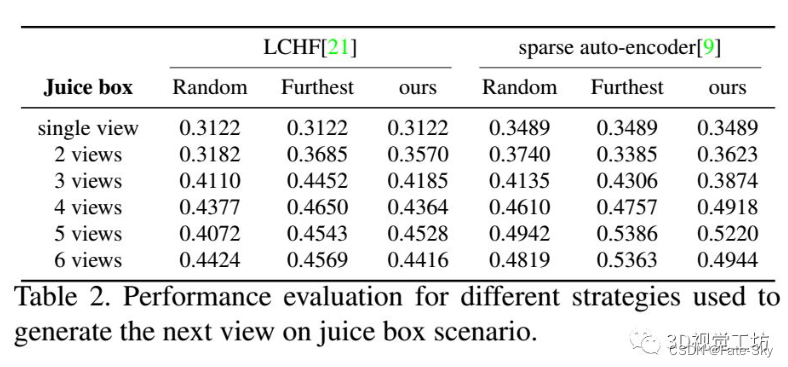
12、Multi-view 6D Object Pose Estimation and Camera Motion Planning using RGBD Images
论文链接:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8265470
主要思想:在主动场景中,当观察者无法从当前视点恢复目标的姿态时,观察者可以确定下一个视点的位置,并从另一个视点捕获新的场景,以提高对环境的认识,从而降低6D姿态估计的不确定性。我们提出了一个完整的主动多视图框架来识别拥挤场景中多个物体实例的6自由度姿态。我们在主动视觉设置中加入了几个部分以提高准确性:假设积累和验证结合了先前观点估计的基于单镜头的假设,并提取了最可能的假设集;基于熵的次优视角预测生成下一个摄像机位置以捕获新数据以提高性能;摄像机运动规划基于视角熵和运动代价规划摄像机的运动轨迹。对每个组件的不同方法进行了实现和评估,以显示性能的提高。
主要贡献:
我们的贡献是:
1、集成不同的组件,建立一个完整的主动系统,对多个目标进行检测和姿态估计。
2、无监督下一个最佳视图(NBV)预测算法,通过基于当前对象假设的场景渲染来预测下一个最佳摄像机姿态,用于目标检测和姿态估计。
3、使用物理引擎生成具有真实多对象配置的合成数据集。
 实验结果
实验结果
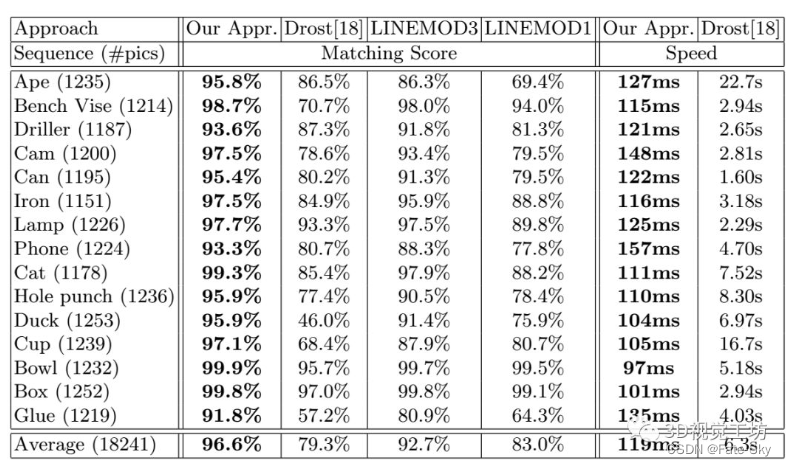
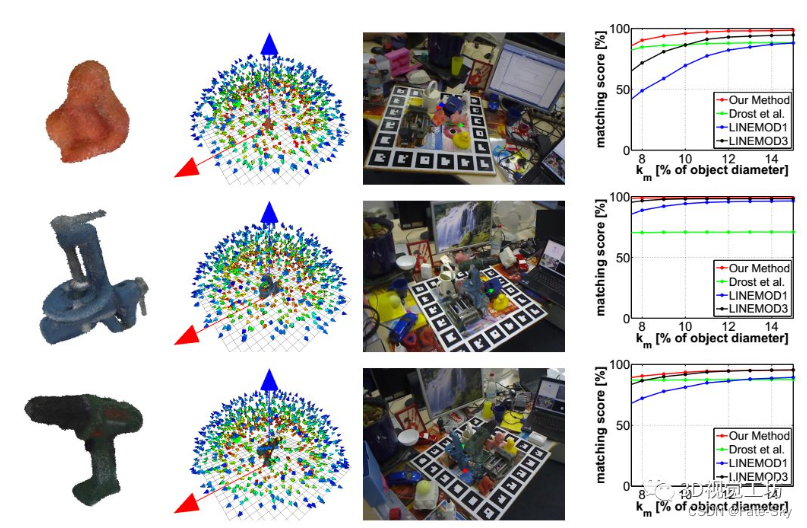
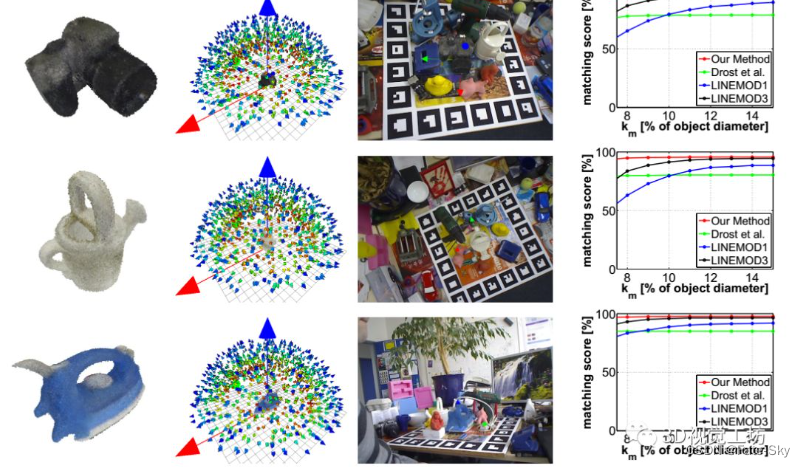
13、Going further with point pair features
论文链接:http://arxiv.org/abs/1711.04061
主要思想:点对特征是一种广泛应用的点云三维目标检测方法,但在存在传感器噪声和背景杂波的情况下容易失效。我们引入了新的采样和投票方案,大大减少了杂波和传感器噪声的影响。实验表明,随着我们的改进,PPF变得比最先进的方法更具竞争力,因为它在一些具有挑战性的基准测试对象上的性能优于它们,而且计算成本较低。
主要贡献:
提出了一种更好、更有效的抽样策略,加上对前处理和后处理步骤的小修改,使得文中的方法与最先进的方法相比具有竞争力:它以较低的计算成本,在最近具有挑战性的数据集上击败了它们。

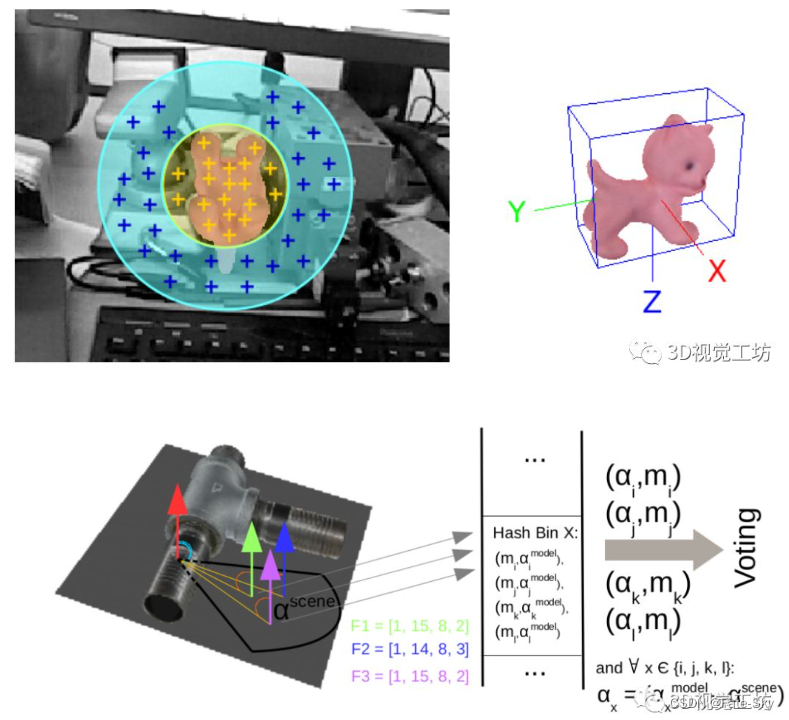
实验结果
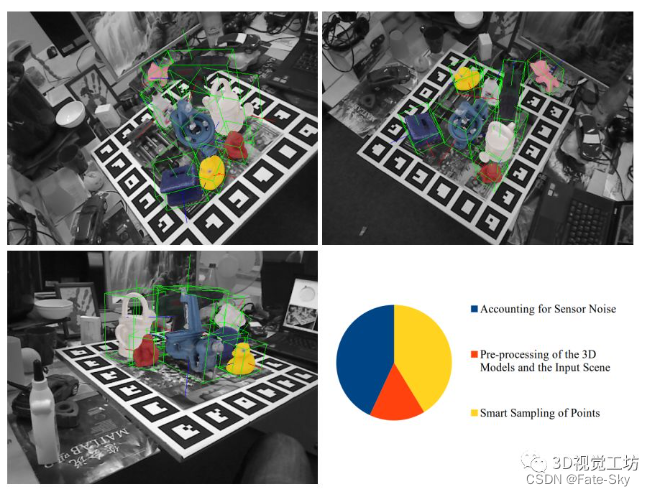
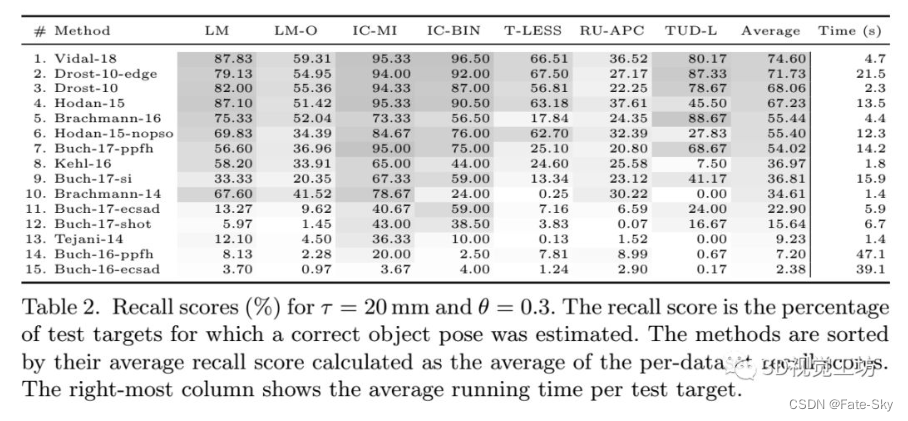
14、BOP: Benchmark for 6D Object Pose Estimation
论文链接:https://arxiv.org/abs/1808.08319
代码链接:https://bop.felk.cvut.cz/home/
主要思想:提出了一种基于单RGB-D输入图像的刚体6D姿态估计基准。训练数据由一个纹理映射的三维物体模型或已知6D姿势的物体图像组成。该基准包括:i)8个统一格式的数据集,涵盖不同的实际情况,包括两个新的数据集,侧重于不同的照明条件;ii)一个具有姿势误差函数的评估方法,处理姿势模糊性,iii)对15种不同的近期方法进行综合评估,以了解该领域的现状;iv)一个在线评估系统,可随时提交新的结果。评估结果表明,基于点对特征的方法目前表现最好,优于模板匹配方法、基于学习的方法和基于三维局部特征的方法。

 实验结果
实验结果
15、 Multimodal Templates for Real-Time Detection of Texture-less Objects in Heavily Cluttered Scenes (ICCV), 2011.
论文链接:
http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6126326
主要思想:提出了一种多模式检测三维物体的方法。虽然它是通用的,但论文将它演示在图像和提供互补对象信息的稠密深度图的组合上。这种方法可以实时工作,在繁杂的杂波环境下,不需要耗时的三位一体阶段,并且可以处理不受约束的对象。论文基于对捕获不同模式的模板的有效表示,并且在商品硬件上的许多实验中表明,该方法显著地超过了单模式的最新方法。
主要贡献:
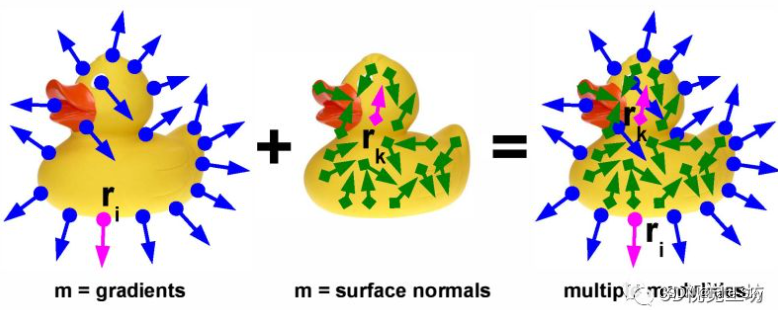
1、提出一种有效的方法,同时利用多个采集模式的信息来定义一个模板,从而在复杂的环境中可靠地检测已知对象。
2、每个模态的数据被离散到存储箱中,使用 “线性化响应图”来最小化缓存未命中并允许大量并行化。
3、重点研究了彩色图像和稠密深度图的结合。
4、方法是非常通用的,可以很容易地整合其他模式,只要提供的测量与图像可以量化对齐。


实验结果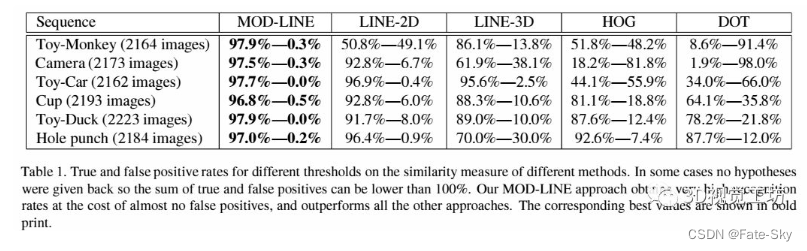

16、Gradient Response Maps for Real-Time Detection of Texture-Less Objects.
论文链接:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6042881
主要思想:本文提出了一种实时三维物体实例检测的方法,该方法不需要耗时的训练阶段,并且能够处理未加纹理的物体。该方法的核心是一种新的模板匹配图像表示方法,该方法对小图像变换具有鲁棒性。这种稳健性基于扩展图像梯度方向,允许在分析图像时只测试所有可能像素位置的一小部分,并用有限的模板集表示三维对象。此外,本文还提出,如果有密集深度传感器,同时考虑到三维表面法向,可以扩展该方法以获得更好的性能。论文展示了如何利用现代计算机的体系结构来构建一个有效但非常有鉴别力的输入图像表示,该表示可用于实时考虑数千个模板。在大量的实际数据实验中,我们证明了我们的方法比目前最先进的方法在背景杂波方面要快得多,并且更具鲁棒性。

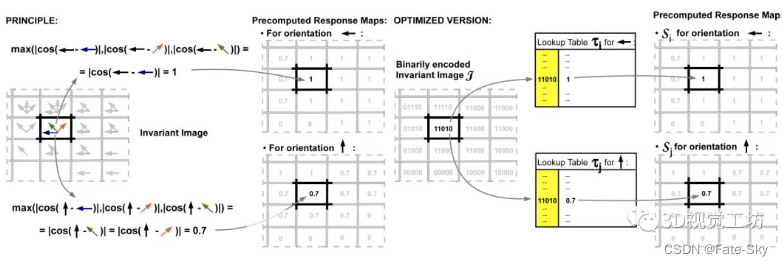
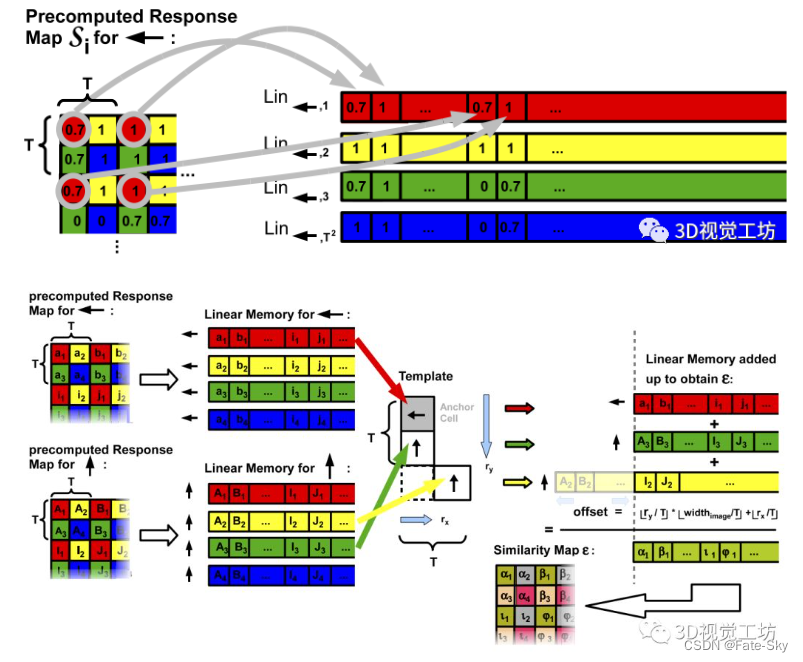 实验结果
实验结果

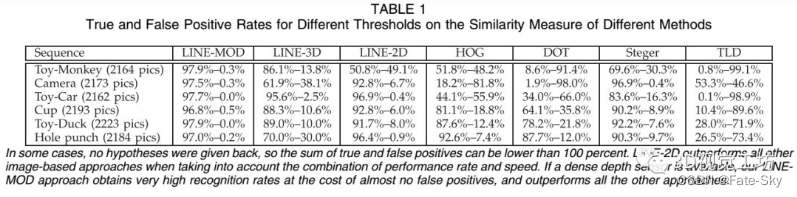
17、Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes.
论文链接:https://link.springer.com/content/pdf/10.1007%2F978-3-642-37331-2.pdf
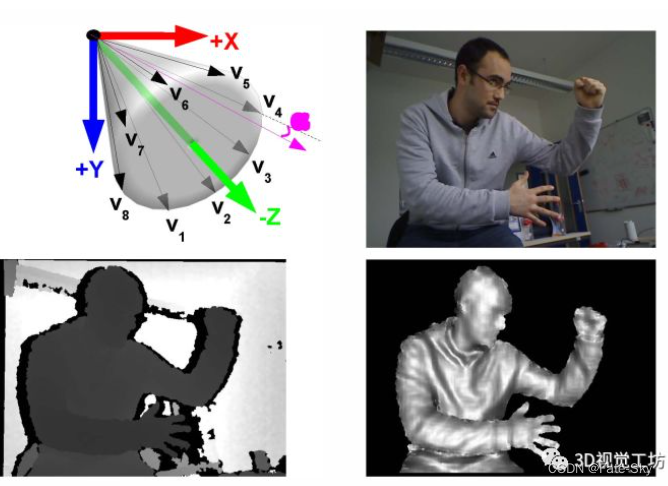
主要思想:文章提出了一个使用Kinect体感相机(RGBD sensors),实现对3D目标自动建模、检测和跟踪的构架。基于LINEMOD法(其目标检测部分主要运用基于模板的LINEMOD方法,通过改进,提升13%检测正确率),利用RGBD信息,完成多视角模板匹配,提供姿态粗估计,具有可在线实时学习3D模型能力,可处理大量杂波和中度遮挡场景,能同时检测多目标。
主要贡献:
1、以色彩梯度和表面法线自动减少特征冗余,自动学习3D模型的模板,此外,在保证探测速度和稳定性的同时,提供了特征空间的采样方案。
2、提供了新的高效的后处理方法,表明姿态估计和色彩信息可验证特测假设,并提升13%探测正确率。
3、提供新的数据集,新数据集的主要特点为:对每一幅图像和序列提供3D模型和真实姿态;每一个序列均匀的覆盖了姿态空间;每幅图像包含了远近距离的2D和3D杂波。

 实验结果
实验结果