
- 1如何破解滑动验证码?
- 2SPI数据传输_dsp spi通讯从机发不出数据
- 3python包导入原理解析_from ..utils.data_process_utils import load_pretra
- 4【附源码】Java计算机毕业设计餐馆点餐管理系统(程序+LW+部署)_javaee餐饮管理系统
- 5Nexus3.x批量导入本地库(☆)_nexus批量导入本地仓库
- 6前端超好用的web调试抓包工具——whistle的安装及pc端和移动端真机使用_霸霸最棒
- 7红黑树简介与C++应用_c++算法中什么时候使用红黑树
- 8leetcode3_给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集
- 9《实战AI模型》——赶上GPT3.5的大模型LLaMA 2可免费商用,内含中文模型推理和微调解决方案_《实战ai大模型》
- 10DRF-序列化器_drf serializer 一对一关联
Spring面试
赞
踩
Spring
1 基础
使用Spring框架的好处是什么?
- 轻量:Spring 是轻量的,基本的版本大约2MB
- 控制反转:Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们
- 面向切面的编程(AOP):Spring支持面向切面的编程,并且把应用业务逻辑和系统服务分开
- 容器:Spring 包含并管理应用中对象的生命周期和配置
- MVC框架:Spring的WEB框架是个精心设计的框架,是Web框架的一个很好的替代品
- 事务管理:Spring 提供一个持续的事务管理接口,可以扩展到上至本地事务下至全局事务(JTA)
- 异常处理:Spring 提供方便的API把具体技术相关的异常(比如由JDBC,Hibernate or JDO抛出的)转化为一致的unchecked 异常。
为什么要用SpringBoot?
在使用Spring框架进行开发的过程中,需要配置很多Spring框架包的依赖,如spring-core、spring-bean、spring-context等,而这些配置通常都是重复添加的,而且需要做很多框架使用及环境参数的重复配置,如开启注解、配置日志等。Spring Boot致力于弱化这些不必要的操作,提供默认配置,当然这些默认配置是可以按需修改的,快速搭建、开发和运行Spring应用。
以下是使用SpringBoot的一些好处:
- 自动配置,使用基于类路径和应用程序上下文的智能默认值,当然也可以根据需要重写它们以满足开发人员的需求。
- 创建Spring Boot Starter 项目时,可以选择选择需要的功能,Spring Boot将为你管理依赖关系。
- SpringBoot项目可以打包成jar文件。可以使用Java-jar命令从命令行将应用程序作为独立的Java应用程序运行。
- 在开发web应用程序时,springboot会配置一个嵌入式Tomcat服务器,以便它可以作为独立的应用程序运行。(Tomcat是默认的,当然你也可以配置Jetty或Undertow)
- SpringBoot包括许多有用的非功能特性(例如安全和健康检查)。
Spring,Spring MVC,Spring Boot 之间什么关系
Spring 包含了多个功能模块,其中最重要的是 Spring-Core(主要提供 IoC 依赖注入功能的支持) 模块, Spring 中的其他模块(比如 Spring MVC)的功能实现基本都需要依赖于该模块。
**Spring MVC 是 Spring 中的一个很重要的模块,主要赋予 Spring 快速构建 MVC 架构的 Web 程序的能力。**MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
使用 Spring 进行开发各种配置过于麻烦,比如开启某些 Spring 特性时,需要用 XML 或 Java 进行显式配置。Spring Boot 旨在简化 Spring 开发(减少配置文件,开箱即用)。
Spring Boot 只是简化了配置,如果你需要构建 MVC 架构的 Web 程序,你还是需要使用 Spring MVC 作为 MVC 框架,只是说 Spring Boot 帮你简化了 Spring MVC 的很多配置,真正做到开箱即用。
Spring 框架中用到了哪些设计模式
- **工厂设计模式:**Spring 使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。 - **代理设计模式:**Spring AOP 功能的实现。
- **单例设计模式:**Spring 中的 Bean 默认都是单例的。
- **模板方法模式:**Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 - **包装器设计模式:**我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- **观察者模式:**Spring 事件驱动模型就是观察者模式很经典的一个应用。
- **适配器模式:**Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。
什么是 spring 装配?
当 bean 在 Spring 容器中组合在一起时,它被称为装配或 bean 装配。 Spring 容器需要知道需要什么 bean 以及容器应该如何使用依赖注入来将 bean 绑定在一起,同时装配 bean。
Spring 容器能够自动装配 bean。也就是说,可以通过检查 BeanFactory 的内容让 Spring 自动解析 bean 的协作者。
自动装配的不同模式:
- no:这是默认设置,表示没有自动装配。应使用显式 bean 引用进行装配。
- byName:它根据 bean 的名称注入对象依赖项。它匹配并装配其属性与 XML 文件中由相同名称定义的 bean。
- byType:它根据类型注入对象依赖项。如果属性的类型与 XML 文件中的一个 bean 名称匹配,则匹配并装配属性。
- 构造函数:它通过调用类的构造函数来注入依赖项。它有大量的参数。
- autodetect:首先容器尝试通过构造函数使用 autowire 装配,如果不能,则尝试通过 byType 自动装配。
什么是自动装配?
自动装配可以简单理解为:通过注解或一些简单的配置就能在 Spring Boot 的帮助下实现某块功能。
**没有 Spring Boot 的情况下,如果我们需要引入第三方依赖,需要手动配置,非常麻烦。但是,Spring Boot 中,我们直接引入一个 starter 即可。**比如你想要在项目中使用 redis 的话,直接在项目中引入对应的 starter 即可。引入 starter 之后,我们通过少量注解和一些简单的配置就能使用第三方组件提供的功能了。
SpringBoot 定义了一套接口规范,这套规范规定:SpringBoot 在启动时会扫描外部引用 jar 包中的META-INF/spring.factories文件,将文件中配置的类型信息加载到 Spring 容器(此处涉及到 JVM 类加载机制与 Spring 的容器知识),并执行类中定义的各种操作。对于外部 jar 来说,只需要按照 SpringBoot 定义的标准,就能将自己的功能装置进 SpringBoot。
SpringBoot 是如何实现自动装配的?
Spring Boot 通过@EnableAutoConfiguration开启自动装配,通过 SpringFactoriesLoader 最终加载META-INF/spring.factories中的自动配置类实现自动装配,自动配置类其实就是通过@Conditional按需加载的配置类,想要其生效必须引入spring-boot-starter-xxx包实现起步依赖。
spring boot的启动流程
- 首先从main找到run()方法,在执行run()方法之前new一个SpringApplication对象
- 进入run()方法,创建应用监听器SpringApplicationRunListeners开始监听
- 然后加载SpringBoot配置环境(ConfigurableEnvironment),然后把配置环境(Environment)加入监听对象中
- 然后加载应用上下文(ConfigurableApplicationContext),当做run方法的返回对象
- 最后创建Spring容器,refreshContext(context),实现starter自动化配置和bean的实例化等工作。
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是**@SpringBootApplication**,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置:@SpringBootApplication(exclude={DataSourceAutoConfiguration.class})。
- @ComponentScan:Spring组件扫描。
如何理解 Spring Boot 中的 Starters?
Starters可以理解为启动器,它包含了一系列可以集成到应用里面的依赖包,你可以一站式集成 Spring 及其他技术,而不需要到处找示例代码和依赖包。如你想使用 Spring JPA 访问数据库,只要加入 spring-boot-starter-data-jpa 启动器依赖就能使用了。
Starters包含了许多项目中需要用到的依赖,它们能快速持续的运行,都是一系列得到支持的管理传递性依赖。
Spring Boot Starter 的工作原理是什么?
Spring Boot 在启动的时候会干这几件事情:
- Spring Boot 在启动时会去依赖的 Starter 包中寻找 resources/META-INF/spring.factories 文件,然后根据文件中配置的 Jar 包去扫描项目所依赖的 Jar 包。
- 根据 spring.factories 配置加载 AutoConfigure 类
- 根据 @Conditional 注解的条件,进行自动配置并将 Bean 注入 Spring Context
总结一下,其实就是 Spring Boot 在启动的时候,按照约定去读取 Spring Boot Starter 的配置信息,再根据配置信息对资源进行初始化,并注入到 Spring 容器中。这样 Spring Boot 启动完毕后,就已经准备好了一切资源,使用过程中直接注入对应 Bean 资源即可。
2 IoC
什么是IOC?
IoC即控制反转,是一种设计思想,而不是一个具体的技术实现。**IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。**不过, IoC 并非 Spirng 特有,在其他语言中也有应用。
- 控制:指的是对象创建(实例化、管理)的权力
- 反转:控制权交给外部环境(Spring 框架、IoC 容器)
在 Spring 中, IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉得 XML 文件来配置不太好,于是 SpringBoot 注解配置就慢慢开始流行起来。
什么是DI?可以通过多少种方式完成依赖注入?
DI就是依赖注入,组件之间依赖关系由IOC容器在运行期决定,形象的说,即由IOC容器动态的将某个依赖关系注入到组件之中(DI可以理解为IOC在Spring中的实现方式)。
依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
依赖注入的方式?
- 构造器注入
- 属性注入(setter注入也归属于此)
@Service public class HelloService { /** * 属性注入 */ @Autowired private BeanFactory beanFactory; /** * 构造器注入 */ public HelloService(ApplicationContext applicationContext) { } /** * 属性注入 * */ @Autowired public void setEnvironment(Environment environment) { System.out.println(""); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
BeanFactory和ApplicationContext的优缺点
BeanFactory的优缺点:
- 优点:应用启动的时候占用资源很少,对资源要求较高的应用,比较有优势;
- 缺点:运行速度会相对来说慢一些。而且有可能会出现空指针异常的错误,而且通过Bean工厂创建的Bean生命周期会简单一些。
ApplicationContext的优缺点:
- 优点:所有的Bean在启动的时候都进行了加载,系统运行的速度快;在系统启动的时候,可以发现系统中的配置问题。
- 缺点:把费时的操作放到系统启动中完成,所有的对象都可以预加载,缺点就是内存占用较大。
spring 提供了哪些配置方式?
- 基于 xml 配置
-
bean 所需的依赖项和服务在 XML 格式的配置文件中指定。这些配置文件通常包含许多 bean 定义和特定于应用程序的配置选项。它们通常以 bean 标签开头。例如:
-
<bean id="studentbean" class="org.edureka.firstSpring.StudentBean"> <property name="name" value="Edureka"></property> </bean>- 1
- 2
- 3
-
- 基于注解配置
-
通过在相关的类,方法或字段声明上使用注解,将 bean 配置为组件类本身,而不是使用 XML 来描述 bean 装配。默认情况下,Spring 容器中未打开注解装配。因此需要在使用它之前在 Spring 配置文件中启用它。例如:
-
<beans> <context:annotation-config/> <!-- bean definitions go here --> </beans>- 1
- 2
- 3
- 4
-
通过使用 @Bean 和 @Configuration 来实现。
-
@Bean 注解扮演与
<bean />元素相同的角色。 -
@Configuration 类允许通过简单地调用同一个类中的其他 @Bean 方法来定义 bean 间依赖关系。
-
例如:
-
@Configuration public class StudentConfig { @Bean public StudentBean myStudent() { return new StudentBean(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
bean 的作用域有哪些(支持几种 bean scope)?
- singleton:唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype:每次请求都会创建一个新的 bean 实例。
- request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session:在一个HTTP Session中,一个Bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
如何配置 bean 的作用域呢?
xml 方式:
<bean id="..." class="..." scope="singleton"></bean>
- 1
注解方式:
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
- 1
- 2
- 3
- 4
- 5
将一个类声明为 bean 的注解有哪些?
我们一般使用 @Autowired 注解自动装配 bean,要想把类标识成可用于 @Autowired 注解自动装配的 bean 的类,采用以下注解:
- @Component :通用的注解,可标注任意类为 Spring 组件。如果一个Bean不知道属于哪个层,可以使用@Component 注解标注。
- @Repository : 对应持久层即 Dao 层,主要用于数据库相关操作。
- @Service : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao层。
- @Controller : 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
- @Configuration:声明该类为一个配置类,可以在此类中声明一个或多个 @Bean 方法。
@Autowired 和 @Resource 的区别是什么?
- @Autowired 是 Spring 提供的注解,@Resource 是 JDK 提供的注解。
- @Autowired 默认的注入方式为byType(根据类型进行匹配),@Resource默认注入方式为 byName(根据名称进行匹配)。
- 当一个接口存在多个实现类的情况下,@Autowired 和@Resource都需要通过名称才能正确匹配到对应的 Bean。Autowired 可以通过 @Qualifier 注解来显示指定名称,@Resource可以通过 name 属性来显示指定名称。
Bean 的生命周期
Spring bean的生命周期只有四个主要阶段,其他都是在这四个主要阶段前后的扩展点,这四个阶段是:
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
其中实例化和属性赋值分别对应构造方法和setter方法的注入。
两个最重要的接口:
- InstantiationAwareBeanPostProcessor
- BeanPostProcessor
实现这两个接口的bean,会自动切入到相应的生命周期中,其中InstantiationAwareBeanPostProcessor是作用于实例化阶段的前后,BeanPostProcessor是作用于初始化阶段的前后。
Spring 怎么解决循环依赖问题?
spring对循环依赖的处理有三种情况: ①构造器的循环依赖:这种依赖spring是处理不了的,直接抛出异常。 ②单例模式下的setter循环依赖:通过“三级缓存”处理循环依赖。 ③非单例循环依赖:无法处理。
下面分析单例模式下的setter循环依赖如何解决。
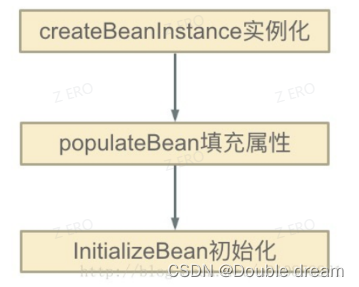
Spring的单例对象的初始化主要分为三步:
- createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
- populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
- initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一、第二步,也就是构造器循环依赖和field循环依赖。

- 解决循环依赖问题(一):没有代理对象
-
解决循环依赖问题的方法非常简单。先理解spring中为什么会有循环依赖的问题。比如如下的代码:
-
public class A { private B b; //getter and setter } public class B { private A a; //getter and setter }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
<beans> <bean id="a" class="org.springframework.test.bean.A"> <property name="b" ref="b"/> </bean> <bean id="b" class="org.springframework.test.bean.B"> <property name="a" ref="a"/> </bean> </beans>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
A依赖B,B又依赖A,循环依赖。容器加载时会执行依赖流程:
-
实例化A,发现依赖B,然后实例化B
-
实例化B,发现依赖A,然后实例化A
-
实例化A,发现依赖B,然后实例化B
-
…
-
死循环直至栈溢出。
-
解决该问题的关键在于何时将实例化后的bean放进容器中,设置属性前还是设置属性后。现有的执行流程,bean实例化后并且设置属性后会被放进singletonObjects单例缓存中。如果我们调整一下顺序,当bean实例化后就放进singletonObjects单例缓存中,提前暴露引用,然后再设置属性,就能解决上面的循环依赖问题,执行流程变为:
-
步骤一:getBean(a),检查singletonObjects是否包含a,singletonObjects不包含a,实例化A放进singletonObjects,设置属性b,发现依赖B,尝试getBean(b)
-
步骤二:getBean(b),检查singletonObjects是否包含b,singletonObjects不包含b,实例化B放进singletonObjects,设置属性a,发现依赖A,尝试getBean(a)
-
步骤三:getBean(a),检查singletonObjects是否包含a,singletonObjects包含a,返回a
-
步骤四:步骤二中的b拿到a,设置属性a,然后返回b
-
步骤五:步骤一种的a拿到b,设置属性b,然后返回a
-
可见调整bean放进singletonObjects(人称一级缓存)的时机到bean实例化后即可解决循环依赖问题。但为了和spring保持一致,我们增加一个二级缓存earlySingletonObjects,在bean实例化后将bean放进earlySingletonObjects中(这样singletonObjects中就都是完全实例化的bean),getBean()时检查一级缓存singletonObjects和二级缓存earlySingletonObjects中是否包含该bean,包含则直接返回。
-
**增加二级缓存,不能解决有代理对象时的循环依赖。**原因是放进二级缓存earlySingletonObjects中的bean是实例化后的bean,而放进一级缓存singletonObjects中的bean是代理对象,两个缓存中的bean不一致。比如上面的例子,如果A被代理,那么B拿到的a是实例化后的A,而a是被代理后的对象,即b.getA() != a。
-
- 解决循环依赖问题(二):有代理对象
-
解决有代理对象时的循环依赖问题,需要提前暴露代理对象的引用,而不是暴露实例化后的bean的引用。
-
spring中用singletonFactories(一般称第三级缓存)解决有代理对象时的循环依赖问题。在实例化后提前暴露代理对象的引用。
-
getBean()时依次检查一级缓存singletonObjects、二级缓存earlySingletonObjects和三级缓存singletonFactories中是否包含该bean。如果三级缓存中包含该bean,则挪至二级缓存中,然后直接返回该bean。
-
最后将代理bean放进一级缓存singletonObjects。
-
Spring 中的单例 bean 的线程安全问题?
当多个用户同时请求一个服务时,容器会给每一个请求分配一个线程,这时多个线程会并发执行该请求对应的业务逻辑(成员方法),此时就要注意了,如果该处理逻辑中有对单例状态的修改(体现为该单例的成员属性),则必须考虑线程同步问题。 线程安全问题都是由全局变量及静态变量引起的。 若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则就可能影响线程安全.
无状态bean和有状态bean
- 有状态就是有数据存储功能。有状态对象(Stateful Bean),就是有实例变量的对象,可以保存数据,是非线程安全的。在不同方法调用间不保留任何状态。
- 无状态就是一次操作,不能保存数据。无状态对象(Stateless Bean),就是没有实例变量的对象 .不能保存数据,是不变类,是线程安全的。
**在spring中无状态的Bean适合用不变模式,就是单例模式,这样可以共享实例提高性能。有状态的Bean在多线程环境下不安全,适合用Prototype原型模式。 Spring使用ThreadLocal解决线程安全问题。**如果你的Bean有多种状态的话(比如 View Model 对象),就需要自行保证线程安全 。
3 AoP
什么是AOP?
AOP即面向切面编程,能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
AOP 有哪些实现方式?
实现 AOP 的技术,主要分为两大类:
- 静态代理 - 指使用 AOP 框架提供的命令进行编译,从而在编译阶段就可生成 AOP 代理类,因此也称为编译时增强;
- 编译时编织(特殊编译器实现)
- 类加载时编织(特殊的类加载器实现)。
- 动态代理 - 在运行时在内存中“临时”生成 AOP 动态代理类,因此也被称为运行时增强。
JDK动态代理:**通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口 。**JDK 动态代理的核心是 InvocationHandler 接口和 Proxy 类 。CGLIB动态代理: 如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类 。CGLIB( Code Generation Library ),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 基于动态代理,属于运行时增强。如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
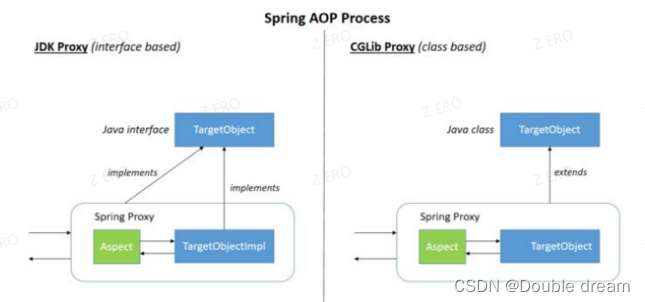
AspectJ 基于静态代理方式实现,是编译时增强。
AspectJ 定义的通知类型有哪些?
- Before(前置通知):目标对象的方法调用之前触发
- After (后置通知):目标对象的方法调用之后触发
- AfterReturning(返回通知):目标对象的方法调用完成,在返回结果值之后触发
- AfterThrowing(异常通知):目标对象的方法运行中抛出 / 触发异常后触发。AfterReturning 和 AfterThrowing 两者互斥。如果方法调用成功无异常,则会有返回值;如果方法抛出了异常,则不会有返回值。
- Around:(环绕通知)编程式控制目标对象的方法调用。环绕通知是所有通知类型中可操作范围最大的一种,因为它可以直接拿到目标对象,以及要执行的方法,所以环绕通知可以任意的在目标对象的方法调用前后搞事,甚至不调用目标对象的方法
4 MVC
Spring MVC 的核心组件有哪些?
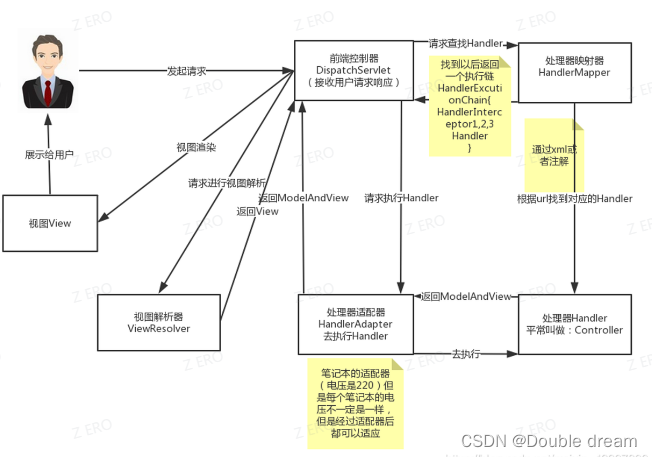
DispatcherServlet:核心的中央处理器,负责接收请求、分发,并给予客户端响应。HandlerMapping:处理器映射器,根据 uri 去匹配查找能处理的Handler,并会将请求涉及到的拦截器和Handler一起封装。HandlerAdapter:处理器适配器,根据HandlerMapping找到的Handler,适配执行对应的Handler**。**因为处理器Handler的类型是 Object 类型,需要有一个调用者来实现Handler是怎么被执行。Spring 中的处理器的实现多变,比如用户处理器可以实现 Controller 接口、HttpRequestHandler 接口,也可以用@RequestMapping注解将方法作为一个处理器等,这就导致 Spring MVC 无法直接执行这个处理器。所以这里需要一个处理器适配器,由它去执行处理器。Handler:请求处理器,处理实际请求的处理器。ViewResolver:视图解析器,根据Handler返回的逻辑视图 / 视图,解析并渲染真正的视图,并传递给DispatcherServlet响应客户端。
SpringMVC 工作原理
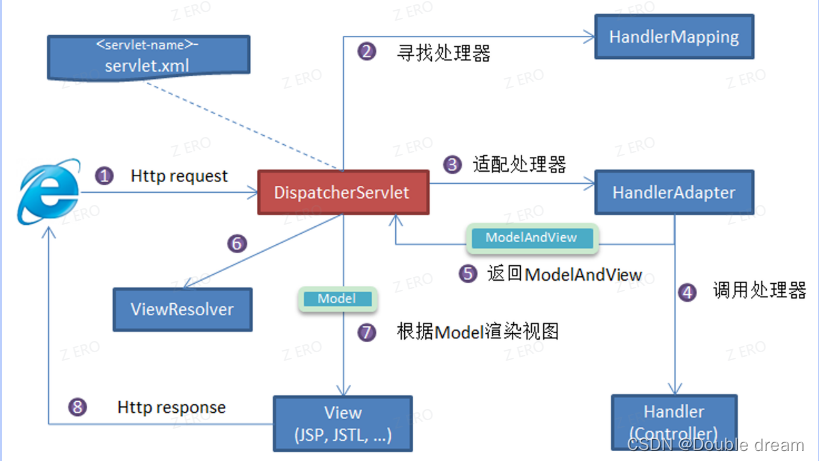
- 客户端(浏览器)发送请求, **
DispatcherServlet**拦截请求。 DispatcherServlet根据请求信息调用HandlerMapping。****HandlerMapping根据 uri 去匹配查找能处理的Handler****(也就是我们平常说的Controller控制器) ,并会将请求涉及到的拦截器和Handler一起封装。DispatcherServlet调用 **HandlerAdapter**适配执行Handler。Handler完成对用户请求的处理后,会返回一个ModelAndView对象给**DispatcherServlet****,**ModelAndView顾名思义,包含了数据模型以及相应的视图的信息。Model是返回的数据对象,View是个逻辑上的View。ViewResolver会根据逻辑View查找实际的View****。DispaterServlet把返回的Model传给View****,根据Model进行视图渲染。- 把
View返回给请求者(浏览器)
Servlet
Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层。
Servlet容器主要是JavaWeb应用提供运行时环境,所以也可以称之为JavaWeb应用容器,或者Servlet/JSP容器。Servlet容器主要负责管理Servlet、JSP的生命周期以及它们的共享数据。目前最流行的Servlet容器软件包括:Tomcat、Jetty、Jboss等。
Servlet容器把客户端的消息解析,封装成ServletRequest,交给Servlet处理。
Servlet 生命周期可被定义为从创建直到毁灭的整个过程。以下是 Servlet 遵循的过程:
- Servlet 初始化后调用 init () 方法。
- Servlet 调用 service() 方法来处理客户端的请求。
- Servlet 销毁前调用 destroy() 方法。
- 最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的。
controller是单例模式还是多例模式?
controller默认是单例的,不要使用非静态的成员变量,否则会发生数据逻辑混乱。正因为单例所以不是线程安全的。
- 不要在controller中定义成员变量。
- 万一必须要定义一个非静态成员变量时候,则通过注解@Scope(“prototype”),将其设置为多例模式。
- 在Controller中使用ThreadLocal变量。
拦截器
拦截器它是链式调用,一个应用中可以同时存在多个拦截器Interceptor, 一个请求也可以触发多个拦截器 ,而每个拦截器的调用会依据它的声明顺序依次执行。
首先编写一个简单的拦截器处理类,请求的拦截是通过 HandlerInterceptor 来实现,看到HandlerInterceptor 接口中也定义了三个方法。
- preHandle() :这个方法将在请求处理之前进行调用。注意:如果该方法的返回值为false ,将视为当前请求结束,不仅自身的拦截器会失效,还会导致其他的拦截器也不再执行。
- postHandle():只有在 preHandle() 方法返回值为true 时才会执行。会在Controller 中的方法调用之后,DispatcherServlet 返回渲染视图之前被调用。 有意思的是:postHandle() 方法被调用的顺序跟 preHandle() 是相反的,先声明的拦截器 preHandle() 方法先执行,而postHandle()方法反而会后执行。
- afterCompletion():只有在 preHandle() 方法返回值为true 时才会执行。在整个请求结束之后, DispatcherServlet 渲染了对应的视图之后执行。
拦截器依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。在实现上,基于Java的反射机制,属于面向切面编程(AOP)的一种运用,就是在service或者一个方法前,调用一个方法,或者在方法后,调用一个方法,比如动态代理就是拦截器的简单实现,在调用方法前打印出字符串(或者做其它业务逻辑的操作),也可以在调用方法后打印出字符串,甚至在抛出异常的时候做业务逻辑的操作。由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI)进行一些业务操作,同时一个拦截器实例在一个controller生命周期之内可以多次调用。拦截器可以对静态资源的请求进行拦截处理。
过滤器
过滤器的配置比较简单,直接实现 Filter 接口即可,也可以通过@WebFilter注解实现对特定URL拦截,看到Filter 接口中定义了三个方法。
- init() :该方法在容器启动初始化过滤器时被调用,它在 Filter 的整个生命周期只会被调用一次。注意:这个方法必须执行成功,否则过滤器会不起作用。
- doFilter() :容器中的每一次请求都会调用该方法, FilterChain 用来调用下一个过滤器 Filter。
- destroy(): 当容器销毁过滤器实例时调用该方法,一般在方法中销毁或关闭资源,在过滤器 Filter 的整个生命周期也只会被调用一次
**过滤器依赖于servlet容器。它可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次。**使用过滤器的目的,是用来做一些过滤操作,获取我们想要获取的数据,比如:在Javaweb中,对传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者Controller进行业务逻辑操作。通常用的场景是:在过滤器中修改字符编码(CharacterEncodingFilter)、在过滤器中修改HttpServletRequest的一些参数(XSSFilter(自定义过滤器)),如:过滤低俗文字、危险字符等。
拦截器和过滤器的区别
-
实现原理不同
- 过滤器是基于函数回调的,拦截器则是基于Java的反射机制(动态代理)实现的。
-
使用范围不同
-
过滤器实现的是 javax.servlet.Filter 接口,而这个接口是在Servlet规范中定义的,也就是说过滤器Filter 的使用要依赖于Tomcat等容器,导致它只能在web程序中使用。
-
而拦截器是一个Spring组件,并由Spring容器管理,并不依赖Tomcat等容器,是可以单独使用的。拦截器不仅能应用在web程序中,也可以用于Application、Swing等程序中。
-
-
触发时机不同
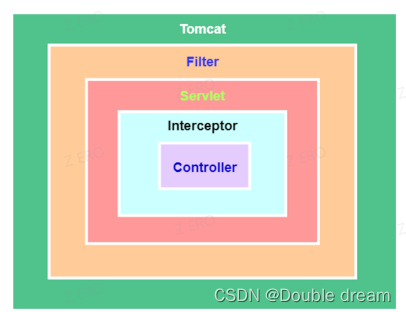
- 过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
-
拦截的请求范围不同
- 过滤器几乎可以对所有进入容器的请求起作用,而拦截器只会对Controller中请求或访问static目录下的资源请求起作用。
RESTful API
RESTful API 经常也被叫做 REST API,它是基于 REST 构建的 API。
REST 是 REpresentational State Transfer 的缩写。这个词组的翻译过来就是“表现层状态转化”。直白地翻译过来就是 “资源”在网络传输中以某种“表现形式”进行“状态转移” 。
- **资源(Resource):我们可以把真实的对象数据称为资源。**一个资源既可以是一个集合,也可以是单个个体。比如我们的班级 classes 是代表一个集合形式的资源,而特定的 class 代表单个个体资源。每一种资源都有特定的 URI(统一资源标识符)与之对应,如果我们需要获取这个资源,访问这个 URI 就可以了,比如获取特定的班级:
/class/12。另外,资源也可以包含子资源,比如/classes/classId/teachers:列出某个指定班级的所有老师的信息。 - 表现形式(Representational):"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式比如
json,xml,image,txt等等叫做它的"表现层/表现形式"。 - 状态转移(State Transfer) :大白话来说 REST 中的状态转移更多地描述的服务器端资源的状态,比如通过增删改查(通过 HTTP 动词实现)引起资源状态的改变。ps:互联网通信协议 HTTP 协议,是一个无状态协议,所有的资源状态都保存在服务器端。
综合上面的解释,我们总结一下什么是 RESTful 架构:
- 每一个 URI 代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现形式比如
json,xml,image,txt等等; - 客户端通过特定的 HTTP 动词,对服务器端资源进行操作,实现"表现层状态转化"。
REST API 是无状态的吗?
是的,REST API 应该是无状态的,因为它是基于无状态的 HTTP 的。
REST API 中的请求应该包含处理它所需的所有细节。它不应该依赖于以前或下一个请求或服务器端维护的一些数据,例如会话。
REST 规范为使其无状态设置了一个约束,在设计 REST API 时,你应该记住这一点。
5 事务
Spring 管理事务的方式有几种?
- 编程式事务 : 在代码中硬编码(不推荐使用):通过
TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。 - 声明式事务 : 在 XML 配置文件中配置或者直接基于注解(推荐使用):实际是通过 AOP 实现(基于
@Transactional的全注解方式使用最多)
Spring 事务的原理
Spring对事务的支持依赖的是底层的数据库。也就是说你的程序是否支持事务首先取决于数据库 ,比如使用 MySQL 的话,如果你选择的是 innodb 引擎,那么是可以支持事务的,但如果使用的是 myisam 引擎就不支持事务。
Spring 主要依靠 TransactionInterceptor 来拦截执行方法体,判断是否开启事务,然后执行事务方法体,方法体中catch住异常,接着判断是否需要回滚,如果需要回滚就委托真正的 TransactionManager 比如JDBC中的DataSourceTransactionManager来执行回滚逻辑。提交事务也是同样的道理。
由此可以看出,这里的事务指的是数据库中的事务,也就是说,如果在Spring事务中除了操作数据库之外,还进行了其他操作导致某些变量发生了变化,那么Spring的事务是无法将其回滚的。
Spring 事务中哪几种事务传播行为?
Spring的API设计很不错,基本上根据英文翻译就能知道作用。
- required:必须的。说明必须要有事务,没有就新建事务。
- supports:支持。说明仅仅是支持事务,没有事务就非事务方式执行。
- mandatory:强制的。说明一定要有事务,没有事务就抛出异常。
- required_new:必须新建事务。如果当前存在事务就挂起。
- not_supported:不支持事务,如果存在事务就挂起。
- never:绝不有事务。如果存在事务就抛出异常。
- nested:嵌套。如果当前存在事务就嵌套一个新事务,没有就新建事务(嵌套事务出错回滚不会影响到主事务,这和required不同)。

6 常见注解
@Autowired
@Autowired默认按类型匹配的方式,在容器查找匹配的Bean,当有且仅有一个匹配的Bean时,Spring将其注入@Autowired标注的变量中。如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。
@Qualifier
配合@Autowired使用。如果容器中有一个以上匹配的Bean,则可以通过@Qualifier注解限定Bean的名称。
@Resource
@Resource注解与@Autowired注解作用非常相似,@Resource的装配顺序:
- @Resource后面没有任何内容,默认通过name属性去匹配bean,找不到再按type去匹配
- 指定了name或者type则根据指定的类型去匹配bean
- 指定了name和type则根据指定的name和type去匹配bean,任何一个不匹配都将报错
@Autowired和@Resource的区别
- @Autowired默认按照byType方式进行bean匹配,@Resource默认按照byName方式进行bean匹配
- @Autowired是Spring的注解,@Resource是J2EE的注解。Spring属于第三方的,J2EE是Java自己的东西,因此,建议使用@Resource注解,以减少代码和Spring之间的耦合。
@Service
向Spring容器注册Bean,对应的是业务层Bean。
@Service(“userService”)注解是告诉Spring,当Spring要创建UserServiceImpl的的实例时,bean的名字必须叫做"userService",这样当Action需要使用UserServiceImpl的的实例时,就可以由Spring创建好的"userService",然后注入给Action:在Action只需要声明一个名字叫"userService"的变量来接收由Spring注入的"userService"即可。
@Repository
@Component, @Repository, @Service的区别
对应数据访问层Bean。注解了@Repository的类上如果数据库操作中抛出了异常,就能对其进行处理,转而抛出的是翻译后的spring专属数据库异常,方便我们对异常进行排查处理。
@Controller
用于标注控制层组件。分发处理器会扫描使用该注解的类的方法,并检测该方法是否使用了@RequestMapping 注解。根据注解信息,为这个方法生成一个对应的处理器对象。
@Component
@Component就是跟一样,可以托管到Spring容器进行管理。
@Service, @Controller , @Repository = {@Component + 一些特定的功能}。
@Configuration 和 @Component 区别
Spring @Configuration 和 @Component 区别_
@Configuration 中所有带 @Bean 注解的方法都会被动态代理,因此调用该方法返回的都是同一个实例。
@RestController
@RestController注解是@Controller和@ResponseBody的合集,表示这是个控制器 bean,并且是将函数的返回值直接填入 HTTP 响应体中,是 REST 风格的控制器。
@Scope
声明 Spring Bean 的作用域。
四种常见的 Spring Bean 的作用域:
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
- session : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
@PathVariable 和 @RequestParam
@PathVariable 用于获取路径参数,@RequestParam 用于获取查询参数。
@RequestBody
@requestBody 与@requestparam;@requestBody的加与不加的区别
用于读取 Request 请求(可能是 POST/PUT/DELETE/GET 请求)的 body 部分并且Content-Type 为 application/json 格式的数据,接收到数据之后会自动将数据绑定到 Java 对象上去。
@RequestBody 与@Requestparam
在GET请求中,不能使用@RequestBody。
在POST请求,可以使用@RequestBody和@RequestParam,但是如果使用@RequestBody,对于参数转化的配置必须统一。
可以使用多个@RequestParam获取数据,@RequestBody不可以
@GetMapping
@GetMapping(“users”) 等价于@RequestMapping(value=“/users”,method=RequestMethod.GET)
@ConfigurationProperties
@ConfigurationProperties和@Value注解用于获取配置文件中的属性定义并绑定到Java Bean或属性中。
@RequestMapping
用来标识 http 请求地址与 Controller 类的方法之间的映射。
可作用于类和方法上,方法匹配的完整是路径是 Controller 类上 @RequestMapping 注解的 value 值加上方法上的 @RequestMapping 注解的 value 值。
@Slf4j、@Data(Lombok)
@Slf4j:该注解的作用主要是操作在idea中的控制台中打印的日志信息。该注解相当于代替了以下的代码:private final Logger logger = LoggerFactory.getLogger(当前类名.class);
@Data:@Data注解的主要作用是提高代码的简洁,使用这个注解可以省去实体类中大量的get()、 set()、 toString()等方法。
@ResponseBody
作用:将方法的返回值,以特定的格式写入到response的body区域,进而将数据返回给客户端。
当方法上面没有写ResponseBody,底层会将方法的返回值封装为ModelAndView对象。在使用此注解之后不会再走视图处理器,而是直接将数据写入到输入流中,他的效果等同于通过response对象输出指定格式的数据。
@ResponseBody并不是以json返回。不加@ResponseBody,是将方法返回的值作为视图名称,并自动匹配视图去显示,而加上@ResponseBody就仅仅是将方法返回值当作内容直接返回到客户端,并且会自适应响应头的content-type,返回的字符串符合json,那么content-type就是application/json,如果是普通字符串,就是text/plain,但是加上注解属性produces=application/json,那么不管内容是什么格式,响应头的content-type就一直是application/json,不再去做自适应,至于内容是不是json都不重要了。
自定义注解
Springboot过滤器和拦截器详解及使用场景 - 知乎 (zhihu.com)
主要是配合拦截器使用,进行token的验证。
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface UserLoginToken {
boolean required() default true;
}
- 1
- 2
- 3
- 4
- 5
通过反射获取到方法上的注解
// 通过反射判断方法上面是否有UserLoginToken注解
if (method.isAnnotationPresent(UserLoginToken.class)) {
UserLoginToken userLoginToken = method.getDeclaredAnnotation(UserLoginToken.class);
if (userLoginToken.required()) {
//执行认证
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
7 应用实例
springboot连接数据库及查询数据完整流程
操作redis
**spring整合redis:**总的来说就是引依赖、编写RedisUtil、编写redis.properties、在spring-redis.xml中配置,最后在需要使用的地方用注解就行了。
**spring boot整合redis:**总的来说就是引依赖、在application.properties中配置、在启动类上加@EnableCaching注解,然后在需要使用的地方用注解就行了。
在实际开发中一般我们不会使用注解,spring提供了两个模板,一个redisTemplate,一个stringRedisTemplate,自己可以基于这两个再次封装。
- 引入依赖:spring-boot-starter-data-redis
- 配置Redis
- 配置数据库参数
- 编写配置类,构造RedisTemplate
- 访问Redis
- redisTemplate.opsForValue() String
- redisTemplate.opsForHash() Hash
- redisTemplate.opsForList() List
- redisTemplate.opsForSet() Set
- redisTemplate.opsForZSet() Zset
导包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
配置Redis
application.properties中

其中database=11表示使用第12个库。
因为RedisTemplate是<String,Object>类型的不利于我们操作所以要写一个配置类:
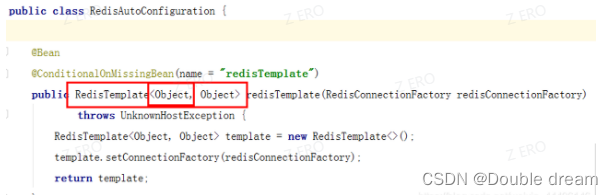
RedisConfig 配置类
@Configuration public class RedisConfig { @Bean public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory factory){ RedisTemplate<String,Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); //设置key的序列化方式 template.setKeySerializer(RedisSerializer.string()); //设置value的序列化方式 template.setValueSerializer(RedisSerializer.json()); //设置hash的key序列化方式 template.setHashKeySerializer(RedisSerializer.string()); //设置hash的value的序列化方式 template.setHashValueSerializer(RedisSerializer.json()); template.afterPropertiesSet(); return template; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
RedisTemplate访问redis
在Redis事务执行过程中不要进行查询,否则会返回空数据!
@SpringBootTest @ContextConfiguration(classes = CommunityApplication.class) public class RedisTest { @Autowired private RedisTemplate redisTemplate; @Test public void testStrings() { String redisKey = "test:count"; redisTemplate.opsForValue().set(redisKey, 1); System.out.println(redisTemplate.opsForValue().get(redisKey)); System.out.println(redisTemplate.opsForValue().increment(redisKey)); System.out.println(redisTemplate.opsForValue().decrement(redisKey)); } @Test public void testHashes() { String redisKey = "test:user"; redisTemplate.opsForHash().put(redisKey, "id", 1); redisTemplate.opsForHash().put(redisKey, "username", "zhangsan"); System.out.println(redisTemplate.opsForHash().get(redisKey, "id")); System.out.println(redisTemplate.opsForHash().get(redisKey, "username")); } @Test public void testLists() { String redisKey = "test:ids"; redisTemplate.opsForList().leftPush(redisKey, 101); redisTemplate.opsForList().leftPush(redisKey, 102); redisTemplate.opsForList().leftPush(redisKey, 103); System.out.println(redisTemplate.opsForList().size(redisKey)); System.out.println(redisTemplate.opsForList().index(redisKey, 0)); System.out.println(redisTemplate.opsForList().range(redisKey, 0, 2)); System.out.println(redisTemplate.opsForList().leftPop(redisKey)); System.out.println(redisTemplate.opsForList().leftPop(redisKey)); System.out.println(redisTemplate.opsForList().leftPop(redisKey)); } @Test public void testSets() { String redisKey = "test:teachers"; redisTemplate.opsForSet().add(redisKey, "刘备", "关羽", "张飞", "赵云", "诸葛亮"); System.out.println(redisTemplate.opsForSet().size(redisKey)); System.out.println(redisTemplate.opsForSet().pop(redisKey)); System.out.println(redisTemplate.opsForSet().members(redisKey)); } @Test public void testSortedSets() { String redisKey = "test:students"; redisTemplate.opsForZSet().add(redisKey, "唐僧", 80); redisTemplate.opsForZSet().add(redisKey, "悟空", 90); redisTemplate.opsForZSet().add(redisKey, "八戒", 50); redisTemplate.opsForZSet().add(redisKey, "沙僧", 70); redisTemplate.opsForZSet().add(redisKey, "白龙马", 60); System.out.println(redisTemplate.opsForZSet().zCard(redisKey)); System.out.println(redisTemplate.opsForZSet().score(redisKey, "八戒")); System.out.println(redisTemplate.opsForZSet().reverseRank(redisKey, "八戒")); System.out.println(redisTemplate.opsForZSet().reverseRange(redisKey, 0, 2)); } @Test public void testKeys() { redisTemplate.delete("test:user"); System.out.println(redisTemplate.hasKey("test:user")); redisTemplate.expire("test:students", 10, TimeUnit.SECONDS); } // 多次访问同一个key @Test public void testBoundOperations() { String redisKey = "test:count"; BoundValueOperations operations = redisTemplate.boundValueOps(redisKey); operations.increment(); operations.increment(); operations.increment(); operations.increment(); operations.increment(); System.out.println(operations.get()); } //声明式事务作用于整个方法,方法中需要查询时就不合适了,所以演示编程式事务 // 编程式事务 @Test public void testTransactional() { Object obj = redisTemplate.execute(new SessionCallback() { @Override public Object execute(RedisOperations operations) throws DataAccessException { String redisKey = "test:tx"; operations.multi(); operations.opsForSet().add(redisKey, "zhangsan"); operations.opsForSet().add(redisKey, "lisi"); operations.opsForSet().add(redisKey, "wangwu"); //显示为[],所以一定不要在redis事务中做查询。 System.out.println(operations.opsForSet().members(redisKey)); return operations.exec(); } }); //这里会显示所有的操作结果 System.out.println(obj); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
jar包的运行原理
当使用java -jar命令执行Spring Boot应用的可执行jar文件时,该命令引导标准可执行的jar文件,读取在jar中META-INF/MANIFEST.MF文件的Main-Class属性值,该值代表应用程序执行入口类也就是包含main方法的类。
Main-Class这个属性定义了org.springframework.boot.loader.JarLauncher,JarLauncher就是对应Jar文件的启动器。而我们项目的启动类MainApplication定义在Start-Class属性中,JarLauncher会将BOOT-INF/classes下的类文件和BOOT-INF/lib下依赖的jar加入到classpath下,然后调用META-INF/MANIFEST.MF文件Start-Class属性完成应用程序的启动。
- Spring Boot 可执行 Jar 包的入口点是 JarLauncher 的 main 方法;
- 这个方法的执行逻辑是先创建一个 LaunchedURLClassLoader,这个加载器加载类的逻辑是:先判断根类加载器和扩展类加载器能否加载到某个类,如果都加载不到就从 Boot-INF 下面的 class 和 lib 目录下去加载;
- 读取**
Start-Class**属性,通过反射机制调用启动类的 main 方法,这样就顺利调用到我们开发的 Spring Boot 主启动类的 main 方法了。
过滤器和拦截器
实现拦截器可以通过继承 HandlerInterceptorAdapter类也可以通过实现HandlerInterceptor这个接口。另外,如果preHandle方法return true,则继续后续处理。首先我们实现拦截器类:
@Slf4j public class AuthenticationInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o) throws Exception { ... } @Override public void postHandle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, ModelAndView modelAndView) throws Exception { ... } @Override public void afterCompletion(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, Exception e) throws Exception { ... } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
我们需要实现HandlerInterceptor这个接口,这个接口包括三个方法,preHandle是请求执行前执行的,postHandler是请求结束执行的,但只有preHandle方法返回true的时候才会执行,afterCompletion是视图渲染完成后才执行,同样需要preHandle返回true,该方法通常用于清理资源等工作。除了实现上面的接口外,我们还需对其进行配置:
@Configuration @Profile("prod")//区分环境 public class InterceptorConfig implements WebMvcConfigurer { // addInterceptor:需要一个实现HandlerInterceptor接口的拦截器实例 // addPathPatterns:用于设置拦截器的过滤路径规则;addPathPatterns("/")对所有请求都拦截 // excludePathPatterns:用于设置不需要拦截的过滤规则 // 拦截器主要用途:进行用户登录状态的拦截,日志的拦截等。 @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(authenticationInterceptor()) .addPathPatterns("/block/", "/center/", "/file/", "/passport/", "/user/") .excludePathPatterns("/test/**", "/center/notify"); } @Bean public AuthenticationInterceptor authenticationInterceptor() { return new AuthenticationInterceptor(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里我们继承了WebMVCConfigurerAdapter,这里我们重写了addInterceptors这个方法,进行拦截器的配置,主要配置项就两个,一个是指定拦截器,第二个是指定拦截的URL。
8 设计模式
工厂设计模式
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
Spring使用工厂模式可以通过 BeanFactory 或 ApplicationContext 创建 bean 对象。
两者对比:
- BeanFactory :延迟注入(使用到某个 bean 的时候才会注入),相比于 BeanFactory 来说会占用更少的内存,程序启动速度更快。
- ApplicationContext :容器启动的时候,不管你用没用到,一次性创建所有 bean 。
BeanFactory 仅提供了最基本的依赖注入支持,ApplicationContext 扩展了 BeanFactory ,除了有BeanFactory的功能还有额外更多功能,所以一般开发人员使用ApplicationContext会更多。
单例设计模式
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
Spring 中 bean 的默认作用域就是 singleton(单例)的。 除了 singleton 作用域,Spring 中 bean 还有下面几种作用域:
- prototype:每次请求都会创建一个新的 bean 实例。
- request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session:每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效。
Spring 实现单例的方式:
xml:<bean id="userService" class="top.snailclimb.UserService" scope="singleton"/>- 注解:@Scope(value = “singleton”)
Spring 通过 ConcurrentHashMap 实现单例注册表的特殊方式实现单例模式。
代理设计模式
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用Cglib ,这时候Spring AOP会使用 Cglib 生成一个被代理对象的子类来作为代理。
当然你也可以使用 AspectJ,Spring AOP 已经集成了AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
使用 AOP 之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样大大简化了代码量。我们需要增加新功能时也方便,这样也提高了系统扩展性。日志功能、事务管理等等场景都用到了 AOP 。
模板方法模式
模板方法模式是一种行为设计模式,它定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。 模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤的实现方式。
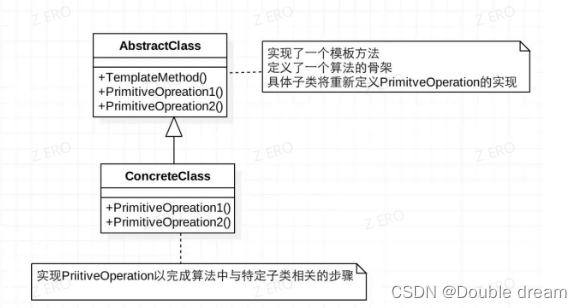
**Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。**一般情况下,我们都是使用继承的方式来实现模板模式,但是 Spring 并没有使用这种方式,而是使用 Callback 模式与模板方法模式配合,既达到了代码复用的效果,同时增加了灵活性。
观察者模式
观察者模式是一种对象行为型模式。它表示的是一种对象与对象之间具有依赖关系,当一个对象发生改变的时候,这个对象所依赖的对象也会做出反应。
**Spring 事件驱动模型就是观察者模式很经典的一个应用。**Spring 事件驱动模型非常有用,在很多场景都可以解耦我们的代码。比如我们每次添加商品的时候都需要重新更新商品索引,这个时候就可以利用观察者模式来解决这个问题。
Spring 的事件流程总结
- 定义一个事件:实现一个继承自
ApplicationEvent,并且写相应的构造函数; - 定义一个事件监听者:实现
ApplicationListener接口,重写onApplicationEvent()方法; - 使用事件发布者发布消息:可以通过
ApplicationEventPublisher的publishEvent()方法发布消息。
// 定义一个事件,继承自ApplicationEvent并且写相应的构造函数 public class DemoEvent extends ApplicationEvent{ private static final long serialVersionUID = 1L; private String message; public DemoEvent(Object source,String message){ super(source); this.message = message; } public String getMessage() { return message; } } // 定义一个事件监听者,实现ApplicationListener接口,重写onApplicationEvent()方法; @Component public class DemoListener implements ApplicationListener<DemoEvent>{ //使用onApplicationEvent接收消息 @Override public void onApplicationEvent(DemoEvent event) { String msg = event.getMessage(); System.out.println("接收到的信息是:"+msg); } } // 发布事件,可以通过ApplicationEventPublisher的publishEvent()方法发布消息。 @Component public class DemoPublisher { @Autowired ApplicationContext applicationContext; public void publish(String message){ //发布事件 applicationContext.publishEvent(new DemoEvent(this, message)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
当调用 DemoPublisher的 publish() 方法的时候,比如 demoPublisher.publish(“你好”),控制台就会打印出:“接收到的信息是:你好”。
适配器模式
适配器模式将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。
spring AOP中的适配器模式
Spring AOP 的增强或通知(Advice)使用到了适配器模式,与之相关的接口是AdvisorAdapter 。Advice 常用的类型有:BeforeAdvice、AfterAdvice、AfterReturningAdvice等等。每个类型Advice都有对应的拦截器:MethodBeforeAdviceInterceptor、AfterReturningAdviceInterceptor。Spring需要将每个Advice都封装成对应的拦截器类型,返回给容器,通过执行拦截器中的内容实现AOP,所以需要使用适配器模式对Advice进行转换。
spring MVC中的适配器模式
HandlerAdapter 主要是为了解决在 DispatchServlet 中对不同实现方式的 Handler 的调用。
为什么要在 Spring MVC 中使用适配器模式?
处理器的类型不同,有多重实现方式,那么调用方式就不是确定的,假设现在还没有什么适配器模式,那么我们在DispatchServlet中直接调用handler方法,在调用的时候就得不断是使用if else来进行判断是哪一种子类然后执行,如果后面还要扩展handler,对于新增的handler就要新增条件语句,这样违背了开闭原则。
为了解决这个问题Spring创建了一个适配器接口(HandlerAdapter)使得每一种处理器有一种对应的适配器实现类,让适配器代替handler执行相应的方法。这样在扩展handler时,只需要增加一个适配器类就完成了SpringMVC的扩展了。
装饰者模式
装饰者模式可以动态地给对象添加一些额外的属性或行为。相比于使用继承,装饰者模式更加灵活。简单点儿说就是当我们需要修改原有的功能,但我们又不愿直接去修改原有的代码时,设计一个Decorator套在原有代码外面。
其实在 JDK 中就有很多地方用到了装饰者模式,比如 InputStream 家族,InputStream 类下有 FileInputStream (读取文件)、BufferedInputStream (增加缓存,使读取文件速度大大提升)等子类都在不修改 InputStream 代码的情况下扩展了它的功能。
Spring 中配置 DataSource 的时候,DataSource 可能是不同的数据库和数据源。我们能否根据客户的需求在少修改原有类的代码下动态切换不同的数据源?这个时候就要用到装饰者模式。Spring 中用到的包装器模式在类名上含有 Wrapper或者 Decorator。这些类基本上都是动态地给一个对象添加一些额外的职责。


