
- 1EVE-NG使用教程_eveng默认密码
- 2GPT-5:人工智能的新篇章,未来已来_gpt5创新点
- 3C++ 编译运行opencv4代码踩坑及解决_undefined reference to `cv::mat::zeros(int, int, i
- 4只需30分钟,微调阿里 Qwen2-7B,搭建专属 AI 客服_qwen2 agent
- 5Mysql简述
- 6利用gitee构建jenkins项目_jenkins结合gitee
- 7one-api采用docker-compose离线部署找不到cl100k_base.tiktoken解决办法_oneapi无法获取gpt-3.5-turbo令牌编码器
- 8网络安全人士必备的30个安全工具_在网络安全方面,有哪些必备的安全软件和工具_网络安全中要掌握哪些常用的工具
- 92023人工智能大模型产业创新价值研究报告.pdf(附下载链接)
- 10RabbitMQ并发消费者关键参数prefetch,concurrency_rabbitmq concurrency
数据仓库与数据挖掘c5-c7基础知识
赞
踩
chapter5 分类
内容
| 分类的基本概念 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 决策树分类器 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 贝叶斯分类器 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 集成 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 不平衡分类器 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 模型评估和选择 |
|



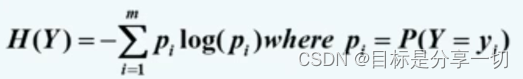






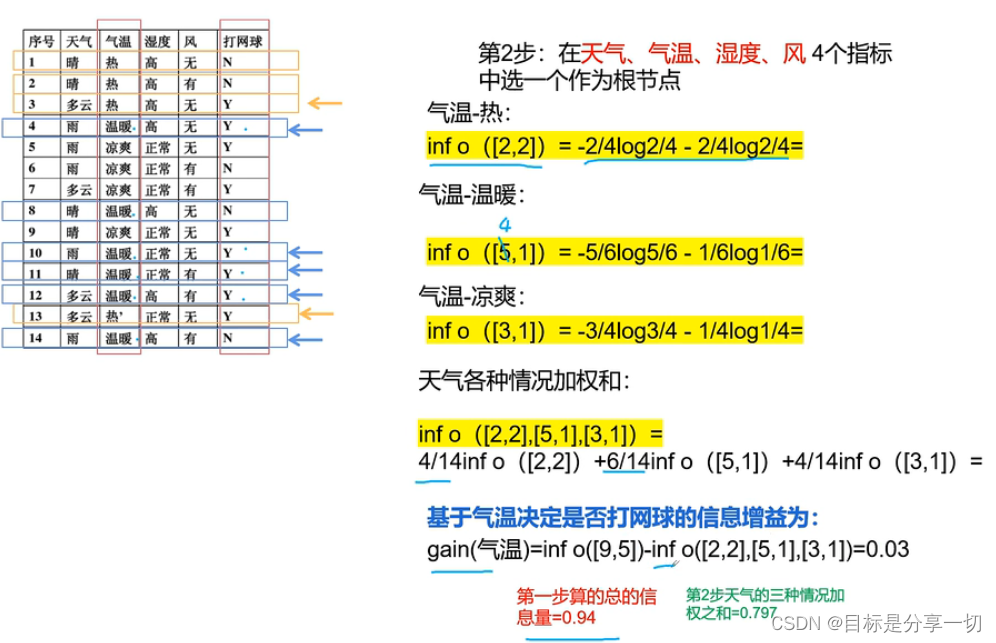
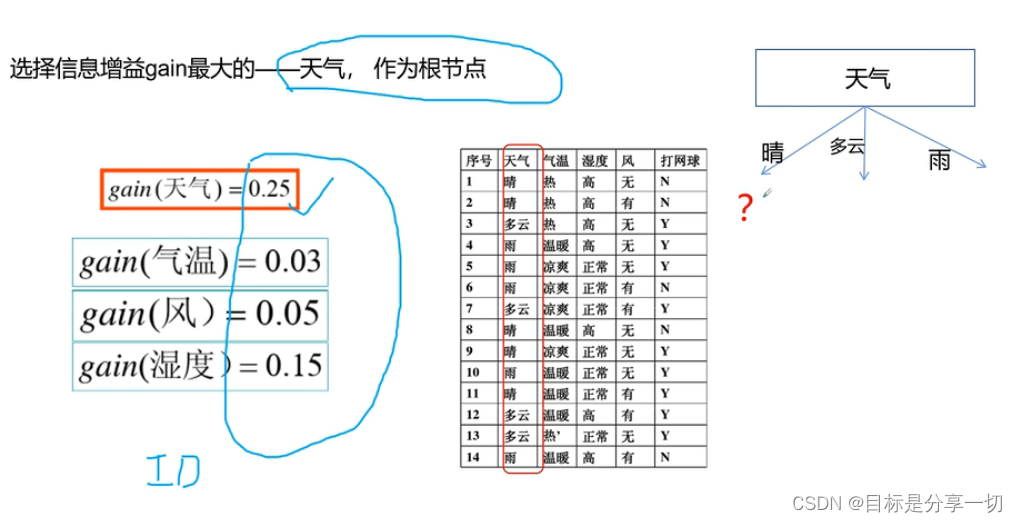
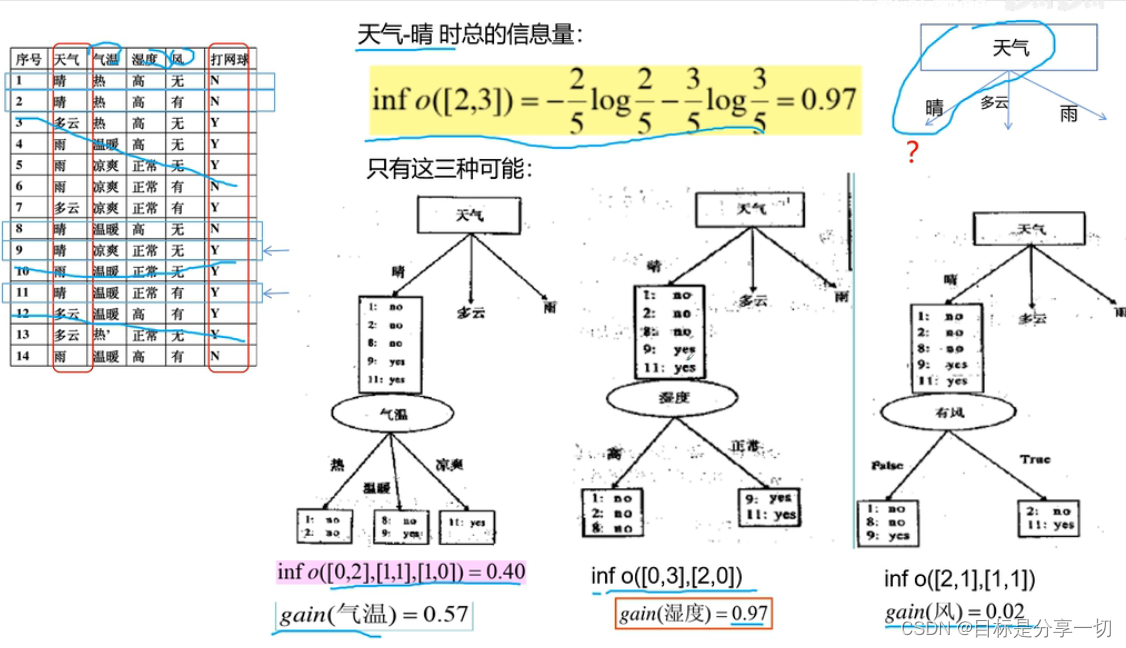





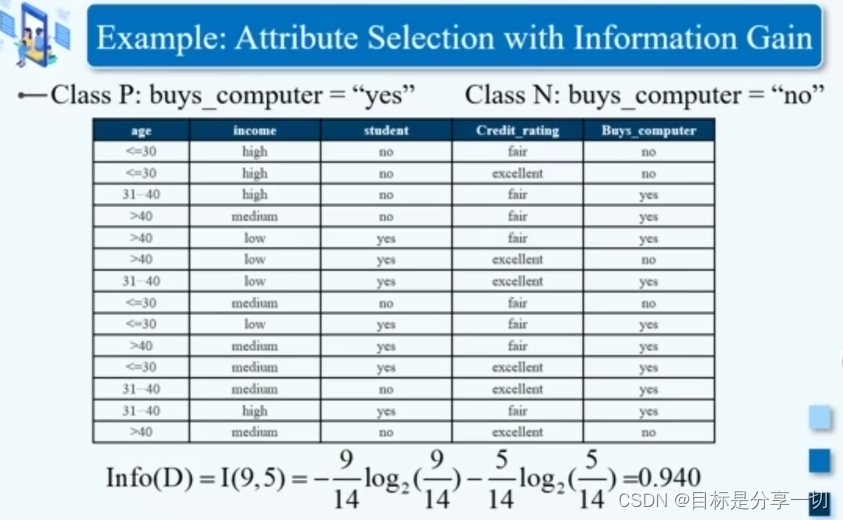


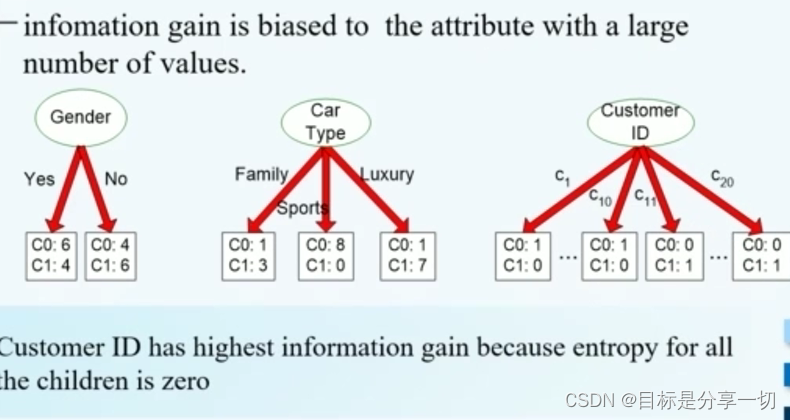





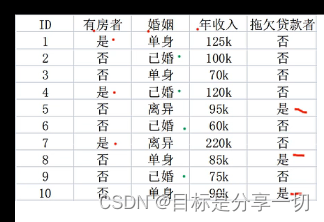




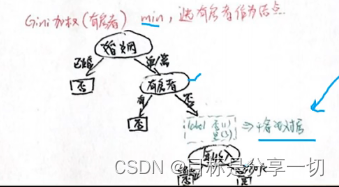














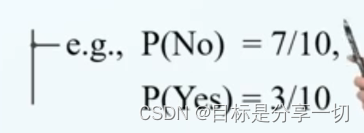


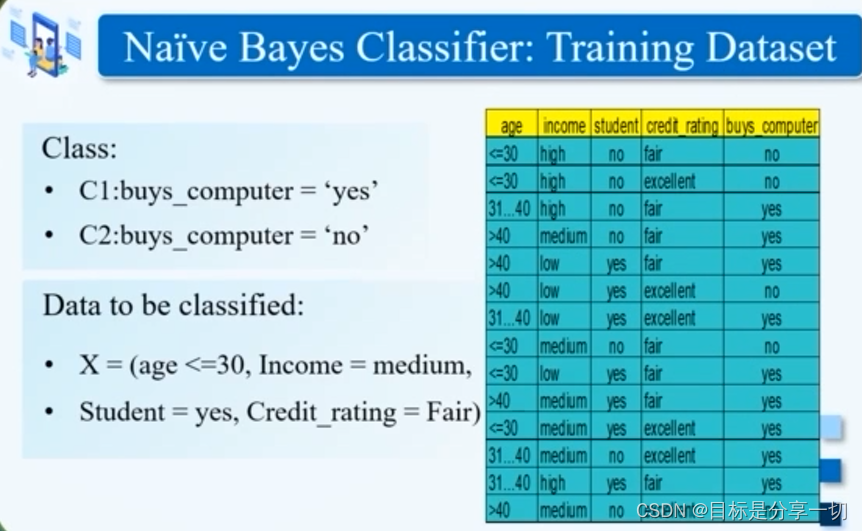








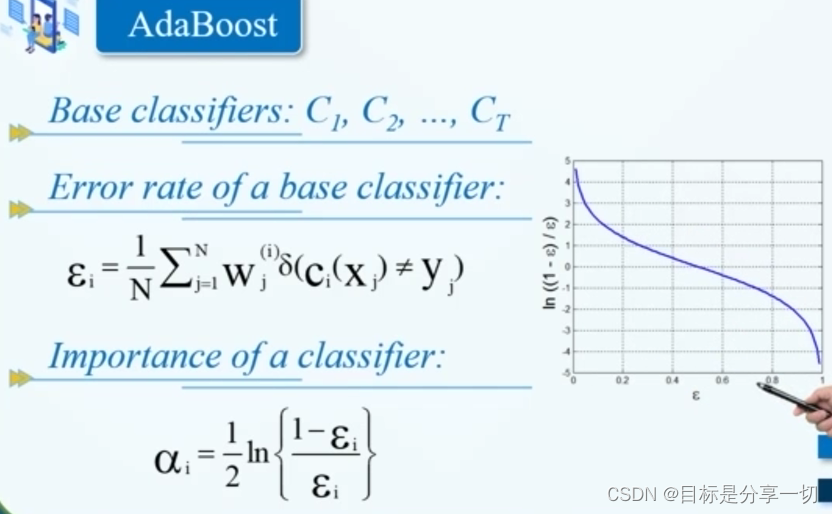




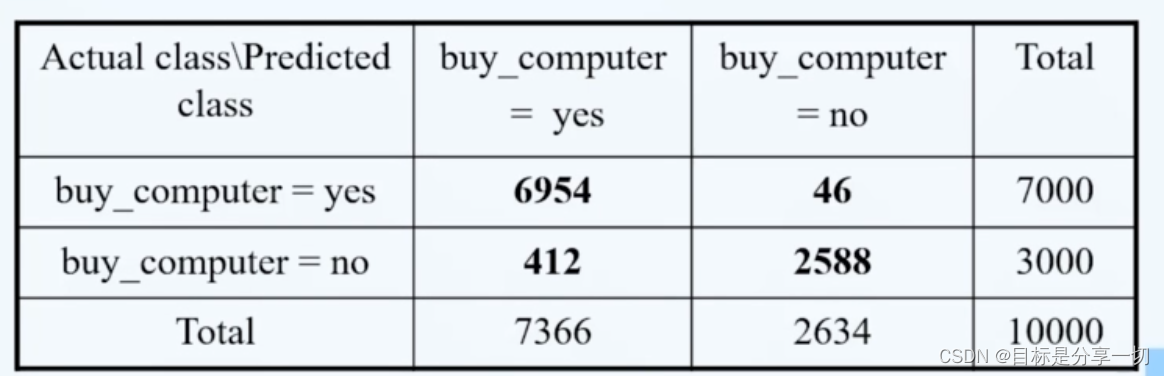





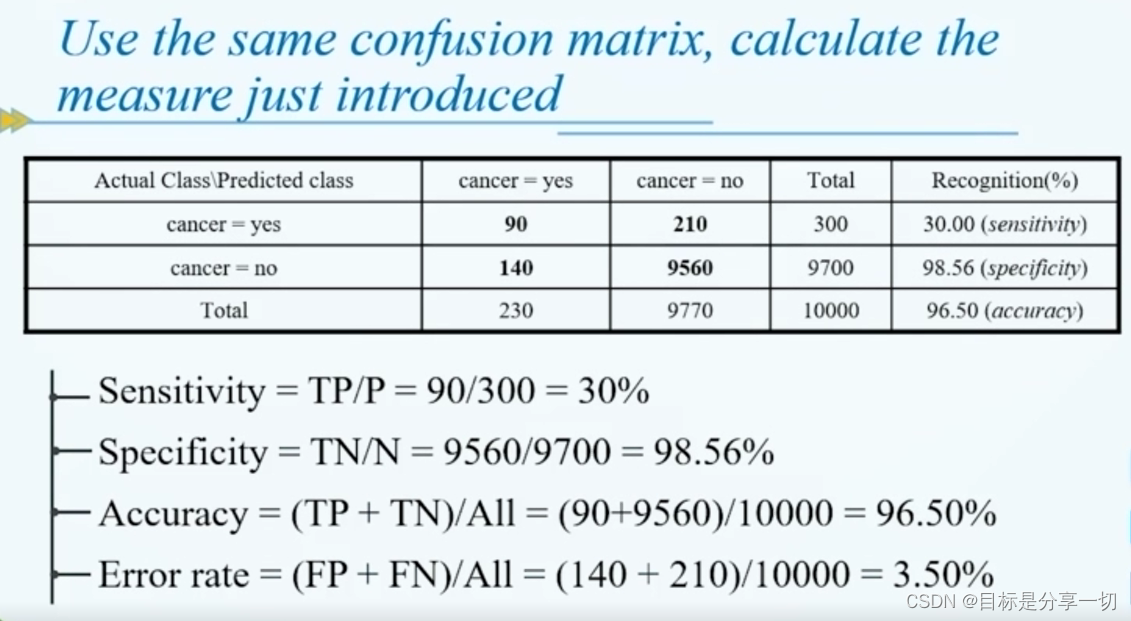





mooc题目
| 单选(2分)下面哪一项关于CART的说法是错误的 A.CART使用的分裂准则是Gini系数 B.分类回归树CART是一种典型的二叉决策树 C.CART输出变量只能是离散型 D.CART用“成本复杂性”标准(cost-complexity pruning) 来剪枝。 | CART的输入和输出变量可以是离散型和连续型, C4.5的输出变量只能是离散型 C4.5算法:可为多叉树,输出变量只能是分类型,能够处理连续型和离散型属性数据 | ||||
| 单选(2分) 假定你现在训练了一个线性SVM并推断出这个模型出现了欠拟合现象。在下一次训练时,应该采取下列什么措施? A.减少特征 B.增加数据点 C.增加特征 D.减少数据点 | 增加特征 | ||||
| 单选(2分) 以下哪项关于决策树的说法是错误的 A.子树可能在决策树中重复多次 B.余属性不会对决策树的准确率造成不利的影响 C.决策树算法对于噪声的干扰非常敏感 D.寻找最佳决策树是NP完全问题 | c | ||||
| 单选(2分) 通过聚集多个分类器的预测来提高分类准确率的技术称为 () A.投票(voting) B。合并(combination) C.组合(ensemble) D,聚集(aggregate) | Ensemble… | ||||
| 单选(2分) 以下哪些算法是基于规则的分类器 A.ANN B.KNN C.Naive Bayes D.C4 | D。基于规则的分类器有决策树、随机森林、Aprior。 1.决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。 2.在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 3.在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库。 D选项:C4.5算法是一个分类决策树算法。 | ||||
| 判断(2分) KNN算法不仅可以用于分类,还可以用于回归 A.X B.√ |
| ||||
| 判断(2分) KNN算法是一种典型的消极学习器 对… |
| ||||
| 判断(2分)在决策树中,随着树中结点数变得太大,即使模型的训练误差还在继续减低,但是检验误差开始增大,这是出现了模型拟合不足的问题。 | 过拟合:训练误差在降低,检验误差在增大
|


chapter6
内容
| 基本概念 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 基于划分的聚类方法 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
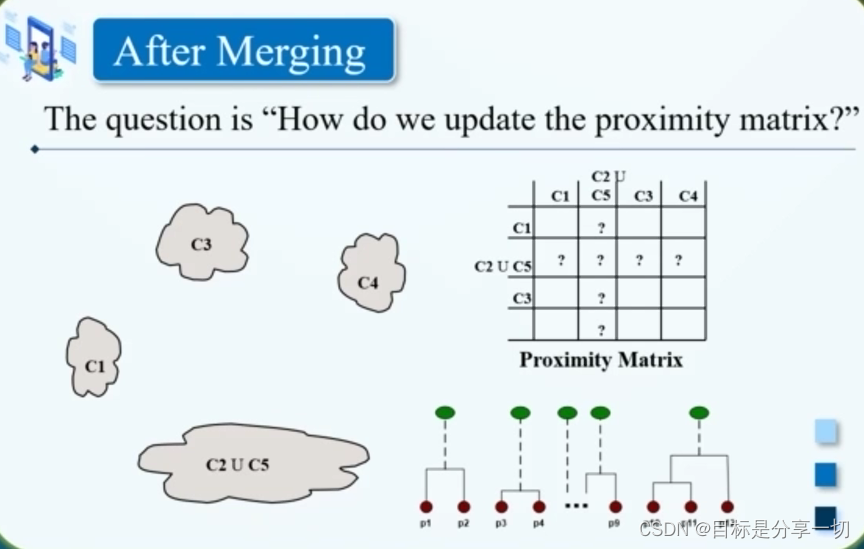
| 基于层次的聚类方法 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 基于密度和基于网格的聚类方法 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 对聚类的评估 |
|

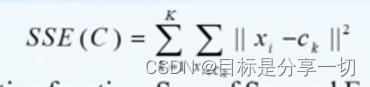









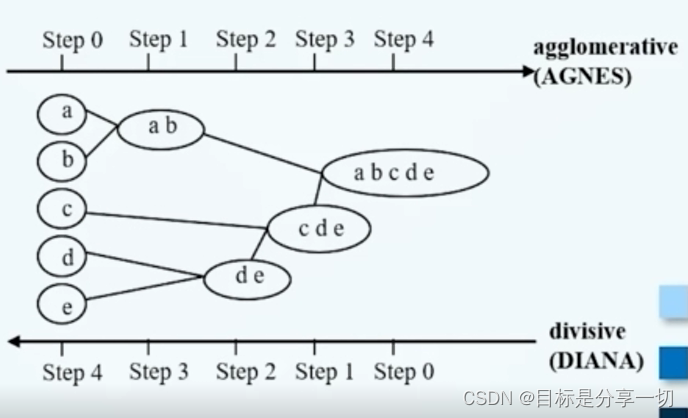

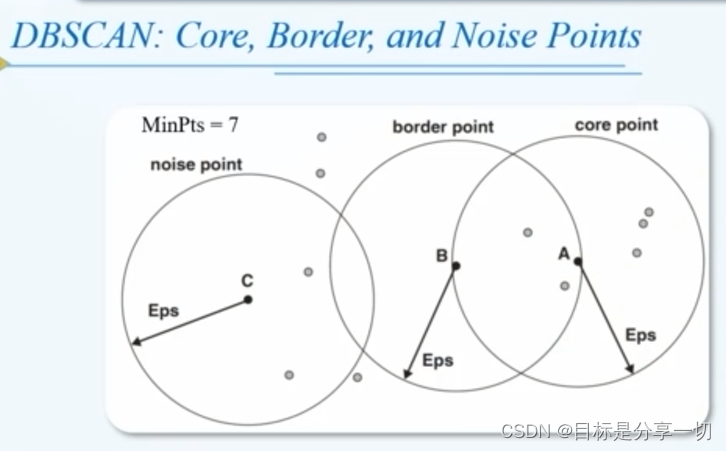

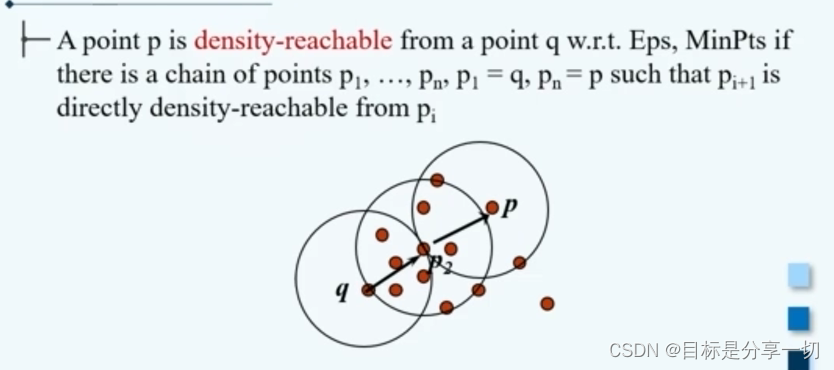


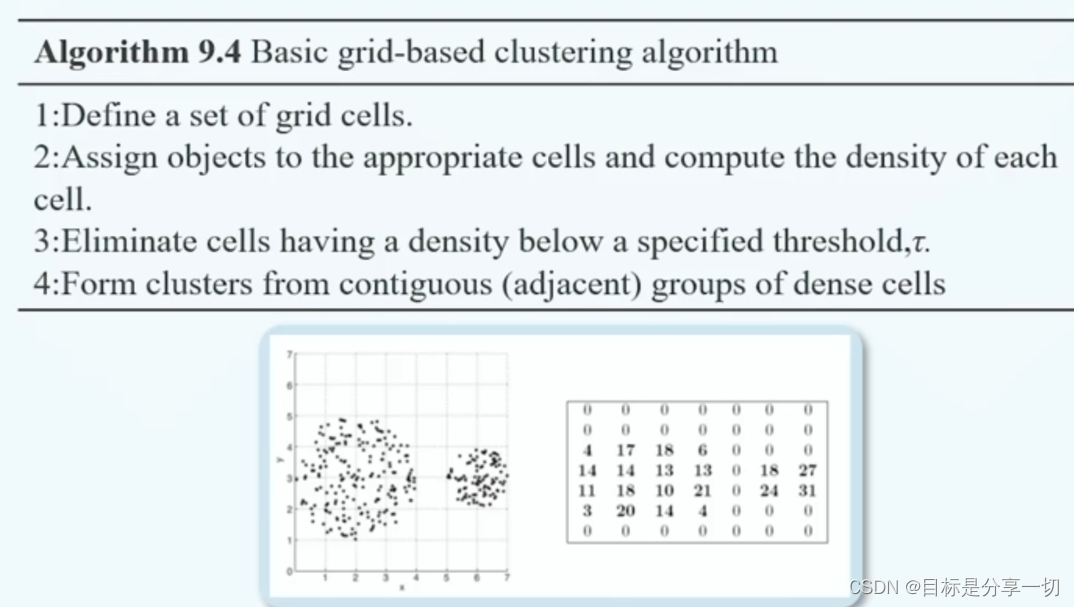








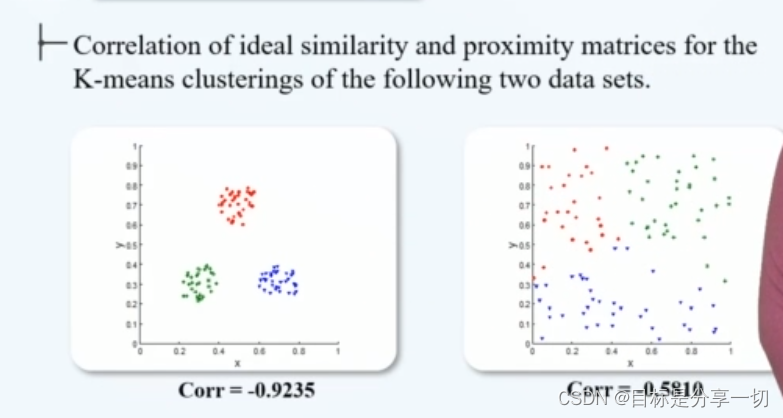
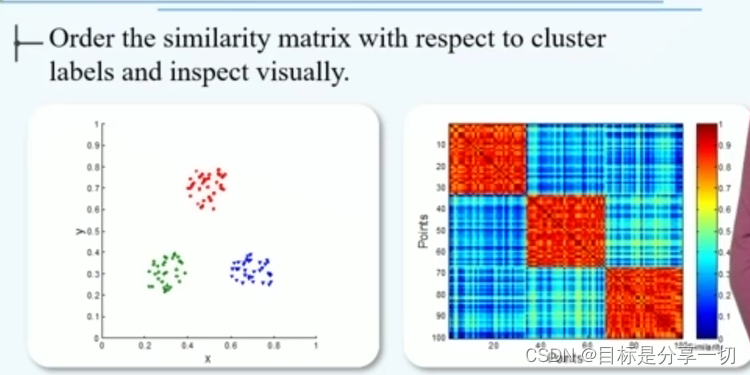
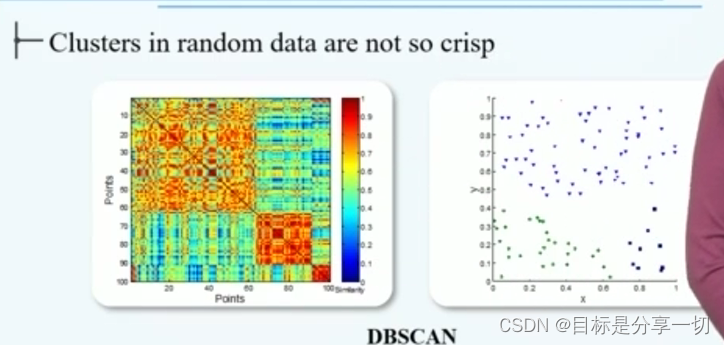

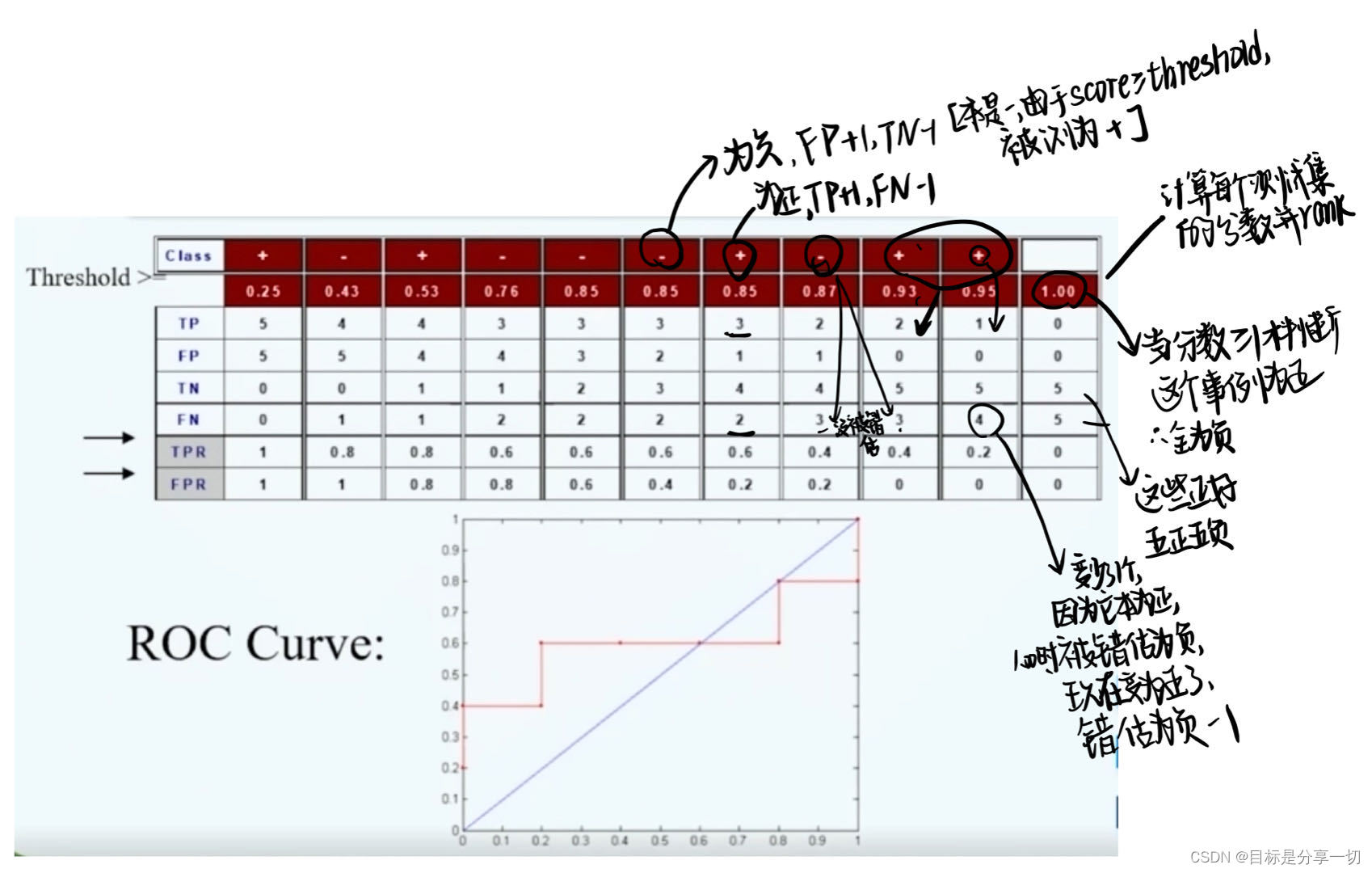
mooc题目
| 单选 (2分) 简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集中,这种聚类类型称作() A.划分聚类 B.模糊聚类 层次聚类 D.非互斥聚类 | 划分聚类 | ||||||||||||||||||||
| 在基本K均值算法里,当邻近度函数采用 ()的时候,合适的质心是簇中各点的中位数 A.曼哈顿距离 B.平方欧几里德距离 余弦距离 D.Breqman散度 |
| ||||||||||||||||||||
| 单选(2分)()将两个簇的邻近度定义为不同簇的所有点对的平均逐对邻近度,它是一种凝聚层次聚类技术。 A.MIN (单链) B.MAX(全链) C.组平均 D.Ward方法 |
| ||||||||||||||||||||
| 4 单选(2分)DBSCAN在最坏情况下的时间复杂度是 () A. O(n^2) B.O(n) c.o(logn) D.O(n*logn) |
| ||||||||||||||||||||
| 判断(2分)K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的 簇 A.V B.X |
| ||||||||||||||||||||
| 判断(2分) 从点作为个体族开始,每一步合并两个最接近的簇,这是一种分裂的层次聚类方法 A.X | 凝聚的: 从点作为个体簇开始,每一步合并两个最近的簇, 需要定义簇的邻近性概念(开始每个点都是一个簇,然后不断合并减少簇的数量)。 | ||||||||||||||||||||
| 判断(2分) DBSCAN中密度相连关系满足对称性【对】 | 密度相连:假设有样本集D,s到p是密度可达的,s到q也是密度可达的,那么称p到q是密度相连的。 | ||||||||||||||||||||
| 判断 (2分) 聚类中把小簇划分成更小簇比把大簇划分为小簇的危害更大【对】 |
| ||||||||||||||||||||
| 判断(2分) 聚类中,当对象o的轮廓系数值接近0时,意味着包含o的簇是紧凑的,并且o远离其他簇【错】 | 聚类总的轮廓系数SC为:SC= \frac {1} {N}\sum_ {i=1}^ {N} {SC (d_ {i})}
|
chapter7
内容
| 异常和异常分析的基本概念 |
| ||||||||||||||||||||||||||||||||||||||||||||
| 异常分析的方法 |
| ||||||||||||||||||||||||||||||||||||||||||||
| 基于统计的异常分析方法 |
| ||||||||||||||||||||||||||||||||||||||||||||
| 基于邻近性的异常检测方法 |
| ||||||||||||||||||||||||||||||||||||||||||||
| 基于聚类和分类的异常检测方法 |
|




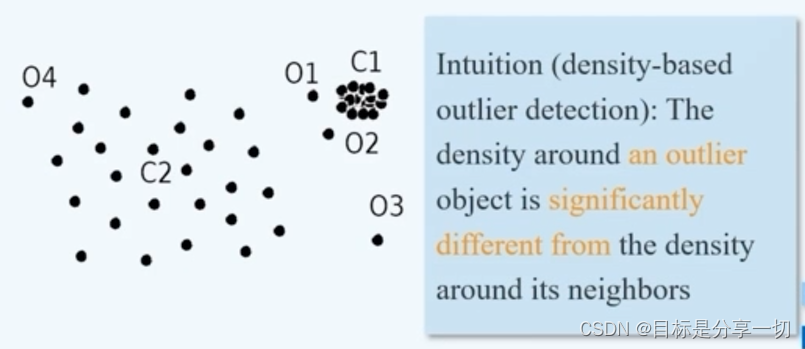


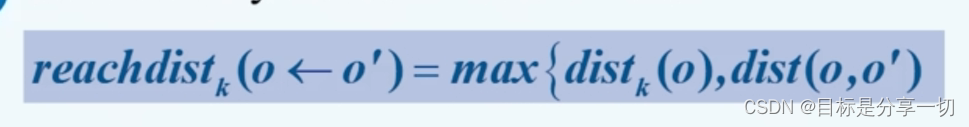
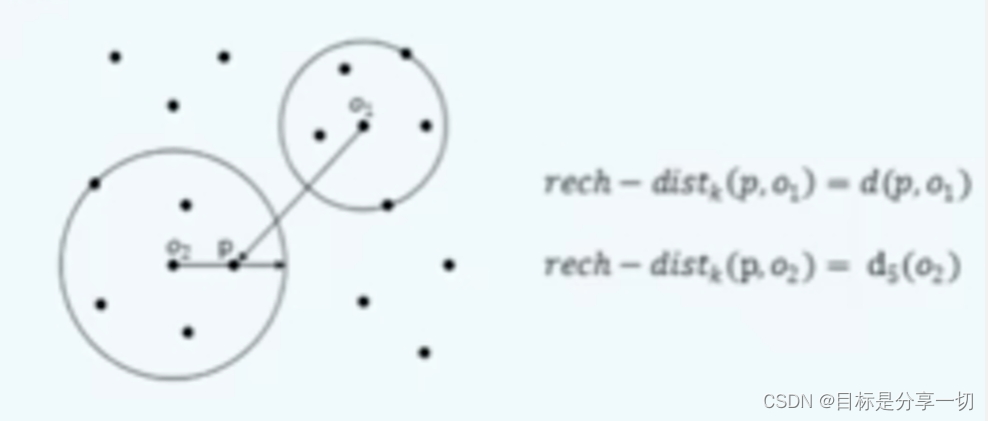



mooc题目
| 噪声不属于异常 | 异常分为群体异常、情境离群点、全局离群点 | ||||||
| 无参的异常检测方法和有参的异常检测方法 |
| ||||||
| 局部异常因子 |
| ||||||
| 异常检测前需要剔除噪声 | |||||||
| 在异常检测中召回率比精度更重要 | Recall[TP/P]异常中被抓出来的比例 | ||||||
| 聚类中的异常点 | 若一个数据对象不属于任何簇or这个数据对象离比较大的簇的距离较远or属于比较稀疏的簇 | ||||||
| 局部异常因子得到异常点的原理 | 局部异常评分:将样本的局部密度与其邻居的局部密度进行比较,样本密度明显低于其邻居的样本被认为是异常点。 | ||||||
| 局部异常因子计算中,样本 p 的第 k 邻域内点到 p 的平均可达距离的倒数成为样本p 的 | 局部可达密度 |
mooc期末考试试题
| 以下哪些算法是分类算法,A,DBSCAN B,C4.5 C,K-Mean D,EM (B) | C4.5就是决策树分类器,用于分类… | ||||||||
| 以下哪些算法是基于规则的分类器 () A. C4.5 B. KNN C. Naive Bayes--基于统计 D. ANN | 基于规则的分类器有决策树、随机森林、Aprior | ||||||||
| 召回率vs精确率 2.单选(2分) 以下两种描述分别对应哪两种对分类算法的评价标准?(a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。(b)描述有多少比例的小偷给警察抓了的标准。 A. Precision, Recall B. Recall.Precision C. Precision.ROC D.Recall,ROC |
| ||||||||
| 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务? A.频繁模式挖掘 B.分类和预测 数据预处理 数据流挖掘 | 数据预处理 | ||||||||
| 属性Hair_color = fauburn, black, blond, brown,grey, red, white),该属性属于 ()类型 A标称 B.二分 C.序数 数值 |
| ||||||||
| 下面不属于数据集特征的是:() A.连续性 B.维度 稀疏性 D.分辨率 | 数据集的一般特性: 维度 (具有的属性数目) 稀疏性(在非对称特征数据集,一个对象大部分属性上的值为0) 分辨率(分辨率太高,模式可能看不清楚,分辨率太低可能模式不出现) | ||||||||
| 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?() A.分类 聚类B. 关联分析 隐马尔可夫链 | 分类:已经有标签可以自动分类 聚类:不知道标签,按照范围内圈区域聚类贴标签 关联分析:对象之间蕴含的关系和规律,比如超市里小朋友感兴趣的商品大多数放下面的货架 隐马尔科夫链:统计分析,描述一个含有隐含未知参数的马尔可夫过程, | ||||||||
| 只有非零值才重要的二元属性被称作:( ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 | 二元属性:0和1.显而易见,0表示不出现,1表示出现 分为:对称性和非对称性 对称性二元属性:两个个状态同等重要 非对称性:两个状态不是同等重要的(更重要的/几率较小的赋值1),两个都取1(正匹配)比两个都取0(负匹配)的情况更有意义 | ||||||||
| 以下哪种方法不是常用的数据约减方法 () A.抽样 B. 回归 C.聚类 D.关联规则挖掘 |
| ||||||||
| 下面哪一项关于CART的说法是错误的 ) A.分类回归树CART是一种典型的二又决策树。 B.CART输出变量只能是离散型 C.CART用“成本复杂性”标准 (cost-complexity pruning) 来剪枝 D.CART使用的分裂准则是Gini系数 | ID3 Gain max 离散型 | ||||||||
| 检测一元正态分布中的离群点,属于异常检测中的基于 ()的离群点检测 A统计方法 B.邻近度 密度 聚类技术 | A | ||||||||
| 以下哪些算法是分类算法 A. DBSCAN B.C4.5 C.K-Mean D.EM |
| ||||||||
| 基于规则的分类器 | 有决策树、随机森林、Aprior。 | ||||||||
| ()是一个观测值,它与其他观测值的差别如此之大,以至于怀疑它是由不同的机制产生的。 A.边界点 B.质心 离群点 核心点 | 离群点 | ||||||||
|
|
| ||||||||
| 关于K均值和DBSCAN的比较,以下说法不正确的是 ()。 A.K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象。 B.K均值使用簇的基于原型的概念,而DBSCAN使用基于密度的概念 C.K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇 .D.K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇 | A 均值聚类k-means是基于划分的聚类, DBSCAN是基于密度的聚类。区别为:
| ||||||||
| 大于或等于 min-support 的非空子集,称为____。 | 频繁项集 | ||||||||
| 关联规则挖掘问题可以划分成两个子问题:发现频繁项目集和生成______。 | 关联规则 | ||||||||
| DBSCAN算法时间复杂性O(__) | DBSCAN 的基本时间复杂度是 O (m * 找出 Eps 邻域中的点所需要的时间 ),m 是点的个数。 最坏情况下,时间复杂度是O (m 2 ),用 kd 树 可以降到 O (m log m),即使对于高维数据,DBSCAN 的空间仍然是 O (m), | ||||||||
| 局部异常因子计算中,样本 p 的第 k 邻域内点到 p 的平均可达距离的倒数成为样本p 的____ | 局部可达密度 | ||||||||
| 数据挖掘是从大量数据中挖掘重要、隐含的、以前未知、______的模式或知识。 | 潜在有用的 | ||||||||
| 从数据仓库的角度可以将数据挖掘过程划分为_______、数据集成、数据选择与变换、数据挖掘及知识评估等阶段。 | 数据清理 | ||||||||
| 数据挖掘任务主要包括描述性和_____任务。 | 预测性 | ||||||||
| 数据集的属性可以划分为_____和连续型两种。 | 离散型 | ||||||||
| 通过离散化操作可以将连续属性转化为____属性 | 序数? | ||||||||
| 样本p的局部异常因子值接近____,说明 p 与其邻域点密度差不多,p 可能和邻域点属于同一簇。 | 1 | ||||||||
| 通过数据集成可以维护数据源整体上的数据______ | 一致性 | ||||||||
| 聚类中不属于任何簇的数据对象可以被认为是_____ | 离群点? | ||||||||
| 异常点类型包括全局异常、上下文异常和______ | 群体异常
| ||||||||
| KNN算法是一种典型的______学习器 | 消极 | ||||||||
| 使用DBSCAN进行异常点检测时,异常点被定义为________的数据对象。 | 不属于任何簇的点
| ||||||||
| C4.5算法采用基于_____作为选择分裂属性的度量标准。 | ID3--信息增益 C4.5--信息增益率 | ||||||||
| CART采用Gini指数来度量分裂时的不纯度。_____越大,样本集合的不确定性程度越高 | 基尼指标越大越不纯,不确定性越高 |









