
- 1jdbc连接mysql数据库的5种常用方法_javawebjdbc连接mysql数据库
- 2GIT常见问题_git postbuffer
- 3git下载ardupilot时出现“过早的文件结束符”问题解决方法_虚拟机中git 过早的文件结束符
- 4区块链|一份全面的区块链知识图谱_通过信息检索,制作一张区块链起源和发展的思维导图
- 5【SVD(奇异值分解)】详解及python-Numpy实现_numpy svd
- 6C#中常见集合类的底层原理与时间复杂度_c#集合类型时间复杂度
- 7感谢上天,我被失联2年后,终于活着从东南亚菠菜公司的技术“魔窟”逃出来了......
- 8git识别不到文件名大小写变更_git vscode校验文件大小写
- 9鸿蒙HarmonyOS实战-ArkTS语言基础类库(并发)_arkts线程(3)_鸿蒙arkts浅拷贝
- 10程序员每天会阅读哪些技术网站来提升自己?_程序员提升自己学习github上的项目吗
关系抽取常用方法_关系抽取方法
赞
踩
关系抽取通常会基于以下几种方式去做:
- 基于规则
- 监督学习
- 半监督 & 无监督学习
- Bootstrap
- Distant Supervision
- 无监督学习
下面分别举例去说明方法的实现方式。
1.基于规则的方法,表示 “is - a”
目的:找出尽可能多的拥有"is - a"关系的实体对(实体1,is - a,实体2)
比如我们有一些文章:
- " … apple is a fruit … "
- " … fruit such as apple … "
- " … fruit including apple , banala … "
拿到上述文章时,我们要先设计一些规则,例如:
- X is a Y
- Y such as X
- Y including X
然后通过这些规则我们可以对上述文章进行关系抽取,建立以下关系:
| 实体1 | 实体2 |
|---|---|
| apple | fruit |
| banala | fruit |
| … | … |
- 方法优点
- 比较准确
- 对于垂直场景,比较适合(具有针对性)
- 方法缺点
- 信息缺乏覆盖率(low recall rate)
- 人力成本较高
- 很难设计(规则冲突、重叠)
2.监督学习
在使用监督学习的方法时,需要做以下准备:
- 定义关系类型
- 定义好实体类型
- 准备训练数据
- 实体标注
- 实体之间的关系标注
下面拿一个经典的例子用以说明:
例子:American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said.
首先我们需要运用命名实体识别(NER)工具来分析这句话,可以找到:
- ORG : American Airlines
- PER:Tim Wagner
然后我们需要提取特征,将(特征(American Airlines),特征(Tim Wagner))放入分类算法。
特征提取部分可以有以下方式:
- Bag-of-words
例如我们可以用unigram提取出(American Airlines,Tim Wagner),或者使用Bi-gram提取出(American Airlines a,Tim Wagner said) - pos-tagging
提取出American Airlines和Tim Wagner的词性 - Bag-of-words feature
a ,unit, of, AMR, immediately, matched, the, move, spokesman - between words pos-tagging
抽取(a ,unit, of, AMR, immediately, matched, the, move, spokesman)的词性 - head feature
(Airlines,Wagner) - 实体类别
(ORG,PER) - 句法分析
以上都是词相关的特征,还可以抽取一些位置特征:例如“两个单词间有多少单词”,“单词是否在句子的第一位”,“句子在文不能中的位置”等。
在特征提取完后,可以将训练数据放入LR,SVM或者神经网络模型中进行训练。
3.Bootstrap方法
Bootstrap的大致思路如下:
- 目标关系:burial place
- Seed tuple: [Mark Twain, Elmira]
- 寻找包含Mark Twain, Elmira的句子
- " Mark Twain is burind in Elmira, NY."
-> X is burind in Y - " The grave of Mark Twain is in Elmira"
-> TH grave of X is in Y - " Elmira is Mark Twain’s final resting place"
-> Y is X’s final resting place
- " Mark Twain is burind in Elmira, NY."
- 利用这些pattern去搜索更多的Tuple
它有以下缺点:
- 对于每一种关系都需要sed tuples
- 对seed tuples比较敏感
- 循环会导致错误的叠加
- 精确率不高
- 没有概率的解释如confidence score
所以在传统的Bootstrap的框架下,我们引申出了snowball。
- step1 : 生成模板(Pattern)
比如我们有一个 [LOC] based [ORG]模板,如果文本中出现了 xxx base xxx ,此时在Bootstrap中是匹配不到的。snowball在此时做了优化,将模板部分进行向量化,然后将匹配的文本的实体间的内容,做相似度的对比。具体细节就不在这里多展开了,感兴趣的同学可以阅读原论文. - step2: 生成Tuples
遍历文本数据,将相似度超过设定阈值的tuple保存下来 - step3:评估Patterns和Tuples
使用已有的Tuples去评估Patterns的准确率
使用已有的Patterns评估Tuples的准确率
Confidence(Tuple) = 1 - (1-Conf(pi))* … *(1-Conf(pk)) # 多个靠谱的Patterns的乘积
4.半监督学习
一般在半监督学习的方法中,我们会有一个少量标注label的数据Freebase以及大量未进行任何标注的Corpus text(Unlabel Text)
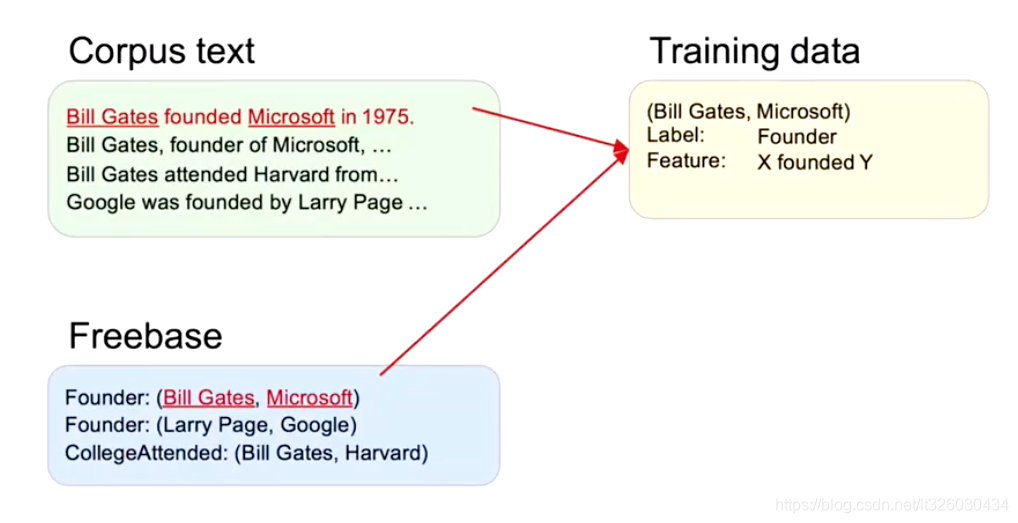
比如,在上述例子中,我们知道了Bill Gates 和 Micrrosoft是Founder的关系。所以通过第一条text,我们可以给Founder建立一个X founded Y 的Feature。
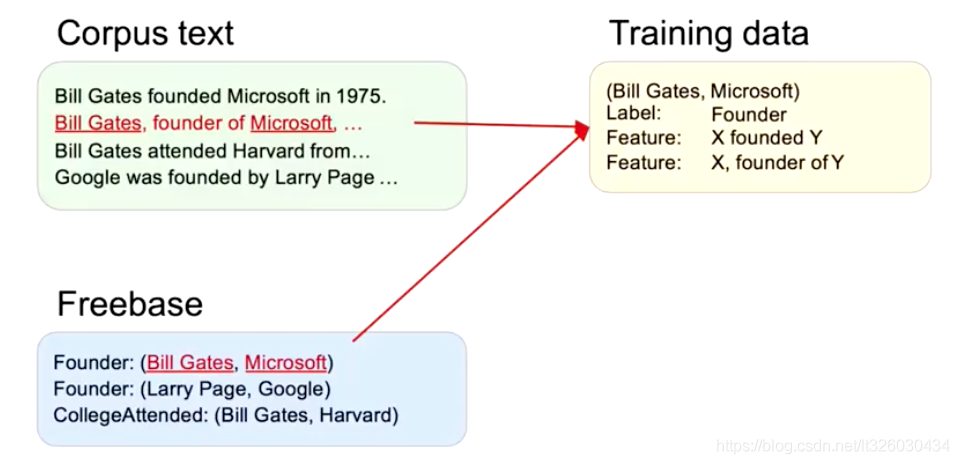
然后继续往下,同理我们也可以给Founder建立一个X, founded of Y 的Feature。
这样当Feature足够多的时候,我们的traning data就会有一定的容错率。
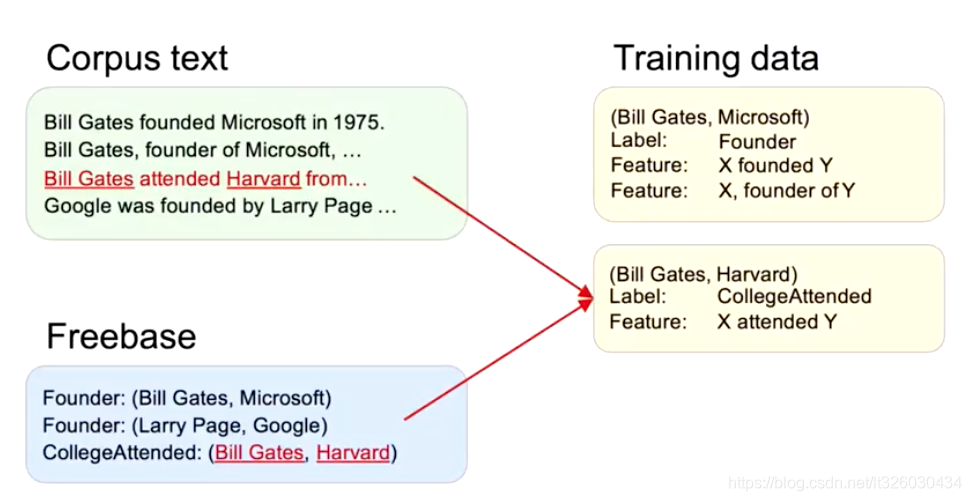
继续往下,到第三句时,我们可以给CollegeAttended建立一个X attended Y 的Feature。
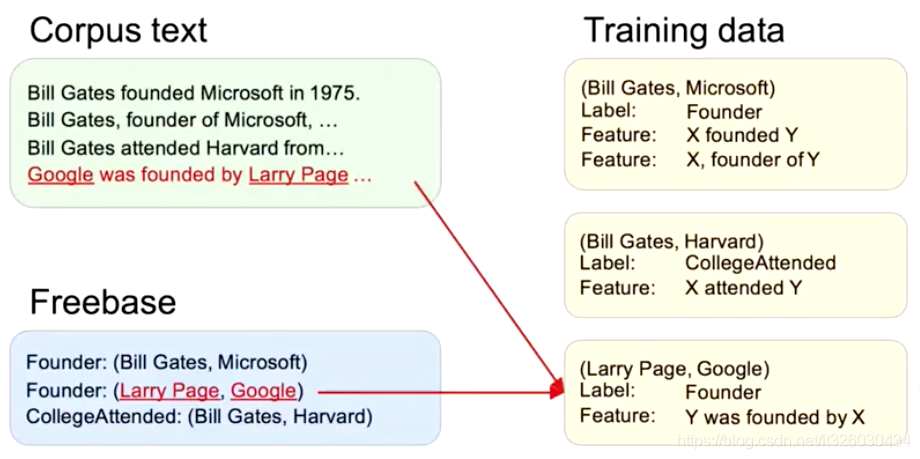
然后到第四句,我们可以新建一个sample,给Founder建立一个Y was founded by X 的Feature。
此时我们就可以开始建立如下的Training data:
| X | Y |
|---|---|
| X founded Y , X founder of Y | Founder |
| X attended Y | CollegeAttended |
| Y was founded by X | Founder |
以上都是postive training data,我们可以找一些不存在与Freebase中的关系的实体,标记label为NO_RELATION,作为nagtive training data,然后将训练数据放入机器学习模型中建立模型。

