
- 19.29. Event Trigger Functions_.pavcwetriggerfunction
- 2AI绘画ComfyUI超简单工作原理介绍_comfyui原理
- 3python接口自动化测试框架2.0,让你像Postman一样编写测试用例,支持多环境切换、多业务依赖、数据库断言等_python接口自动化框架码云
- 4揭秘5G+AI时代的机器人世界!七大核心技术改变人类生活【附下载】| 智东西内参...
- 5Django 页面继承 {% block %}
- 6Eclipse中使用Github_eclipse github
- 7媲美Sora,免费使用!带物理模拟的,文生视频模型_lumalabsaidreammachinecreations
- 8大学生线上搜题软件?8个免费好用的大学生搜题工具 #学习方法#知识分享#经验分享_在危机中,组织与利益相关者之间的共同体危机在哪三个方面
- 9探索未来对话式界面的利器:ChatUI 开源库
- 10异常com.rabbitmq.client.impl.ForgivingExceptionHandler - An unexpected connection driver error occured
RabbitMq之高可用与高性能_rabbitmq采用vhost解决数据量过大问题
赞
踩
RabbitMq之高可用与高性能
1、设计集群的目的
- 高可用:允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
- 高性能:通过增加更多的节点来扩展消息通信的吞吐量
2、Rabbit MQ的分布式部署方式
Rabbit MQ的分布式部署方式总共有三种,分别是集群部署、Federation(联邦)部署 和 Shovel部署。有趣的是,这三种部署方式并不是互斥的,而是可以联合使用的。用户可以根据实际情况,选择其中的一种或多种部署方式来满足自己的实际应用需求。这些部署方式的联合使用固然提高应用程序的性能和灵活性等,但同时也提高了部署的复杂性。
2.1、cluster(集群部署):
- 不支持跨网段,用于同一个网段内的局域网
- 可以随意的动态增加或者减少
- 节点之间需要运行相同版本的RabbitMQ和Erlang
2.2、federation(联邦)
应用于广域网,允许单台服务器上的交换机或队列接收发布到另一台服务器上交换机或队列的消息,可以是单独机器或集群。federation队列类似于单向点对点连接,消息会在联盟队列之间转发任意次,直到被消费者接受。通常使用federation来连接internet上的中间服务器,用作订阅分发消息或工作队列。
2.3、shovel
连接方式与federation的连接方式类似,但它工作在更低层次。可以应用于广域网
3、集群部署
三种部署方式各有其优缺点,需要根据具体的业务场景确定具体的部署方式,现在就来具体看一下集群部署方式的应用场景和底层实现。
在了解集群部署之前,先来介绍一下集群的概念吧。
集群就是将多个服务器部署在同一个网络区间内,集群的多个服务器可以看成是一个整体,一个逻辑上的服务器,因此集群可以提高应用程序的吞吐量和可靠性。
吞吐量很好理解,以前是一个机器干一个活,现在多了好几个机器,干的活肯定比以前多。 可靠性也很好理解,以前一个应用是部署在一个机器上,这个机器挂掉了,整个应用程序就不能工作。但是现在是多个机器,你挂掉一个,没事,还有其它机器可以继续工作,至少不会导致应用程序不能工作了。
那么什么时候需要用到集群部署呢,就是当你服务器抗不住你应用的程序的吞吐量时,比如你的应用程序一秒几十万的消息吞吐量,或者是更大,这个时候就需要用到Rabbit MQ的集群部署了。
Rabbit MQ的集群模式共分为以下两种:
- 普通集群部署
- 镜像集群模式
Rabbit MQ的集群配置方式也有三种:
- 通过 abbi mqct 工具配置
- 通过rabbitmq config 配置文件配置
- 通过 bitmq-aut cluster 插件配置
3.1、普通集群模式(默认的集群模式)
普通集群模式就是将多台Rabbit MQ服务器连接组成一个集群,在连接过程中需要正确的Erlang Cookie和节点名称才能保证机器之间相互进行连接访问,并且集群需要要局域网内进行部署。
集群中的每一台服务器可以说成是集群的一个节点,同学们应该知道,每一个Rabbit MQ服务器都是由连接池、信道、交换机、队列等组成,Rabbit MQ服务器的结构组成如下图所示:
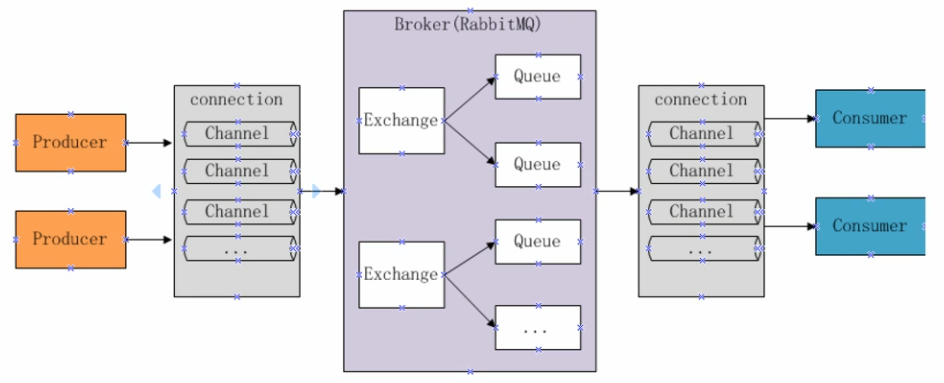
3.1.1、多机集群结构
多机集群结构图如下图所示:
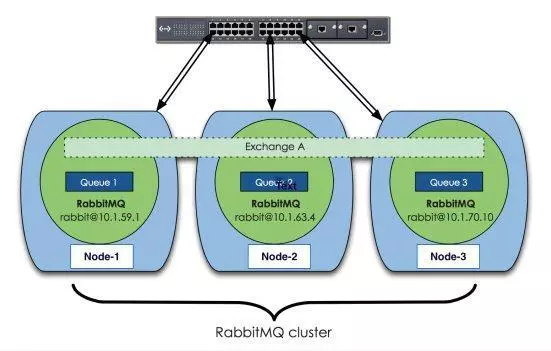
但是Rabbit MQ的集群不是每个节点都有所有队列的完全拷贝。从上面的图中也可以看出,交换机A的的元数据信息在所有节点上都是一致的,但是存放消息的队列的完整信息都只存在它所创建的节点上,所有其他节点只知道队列的元数据和指向该队列存在的那个节点的指针,元数据信息包括以下内容:
- 队列元数据:队列的名称及属性
- 交换器:交换器的名称及属性
- 绑定关系元数据:交换器与队列或者交换器与交换器之 的绑定关系
- vhost元数据:为 vhost内的队列、交换器和绑定提供命名空间及安全属性。
为什么Rabbit MQ不把所有数据拷贝到所有节点上呢?而是只拷贝元数据信息呢?
- 存储空间:如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据
- 性能:如果消息的发布需安全拷贝到每一个集群节点,那么新增节点对网络和磁盘负载都会有增加,这样违背了建立集群的初衷,新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
3.1.2、集群节点间的消息流转
以三个节点(node1、node2、node3)的集群为例来进行说明。消息实体是存在于队列之中的,而节点之间只有相同的元数据信息,假设消息存在于node1节点的A队列上,当消费者从node2节点上的B队列消费时,这时RabbitMQ会临时在node1和node2节点进行消息传输,把A队列上的消息实体传到B队列上,然后发送给消费者。
这个过程其实会对node1节点产生性能瓶颈,因为无论consumer连node1或node2,都会从node1拉取数据。针对这种情况,有一个中庸的做法就是将consumer尽量连接每一个节点。
3.1.3、集群节点类型
集群节点类型分为以下两类:
- 磁盘节点
- 内存节点
磁盘节点的数据信息是存储在磁盘上的,内存节点的信息是存储在内存上的,因此内存节点的性能要高于磁盘节点。
注意: Rabbit MQ要求集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入和离开集群时,必须通知磁盘节点。
当唯一的磁盘节点崩溃时,
集群可以继续发送或者接收消息, 但是不能执行创建队列、交换器、绑定关系、用户,以及更改权限、添加或删除集群节点的操作了。 也就是说,如果集群中唯一的磁盘节点崩溃,集群仍然可以保持运行,但是直到将该节点恢复到集群前,你无法更改任何东西。所以在建立集群的时候应该保证有两个或者多个磁盘节点的存在。
3.1.4、集群节点异常处理
当集群节点崩溃时,该节点的队列进程和关联的绑定都会消失。附加在那些队列上的消费者 会丢失其所订阅的信息 井且任何匹配该队列绑定信息的新消息也都会消失。那么面临这种情况应该如何处理呢:
- 持久化处理,当该节点重启的时候可以再次获取到该消息。
- 镜像模式,就是指创建一个镜像节点,镜像节点保存有崩溃节点的所有信息,那么该节点崩溃时,镜像节点可以接替它继续工作,直至崩溃节点重启。
3.1.5、普通集群模式总结
多机集群提高了系统的吞吐量和可靠性。但是并没有做到高可用性,因为当磁盘节点崩溃的话,其它节点不能进行创建队列、创建交换器等,可以这样说吧,其它内存节点就是为磁盘节点服务的,下面介绍的镜像模式部署解决了这个缺点,实现了集群的高可用性。
3.2、镜像集群模式(RabbitMQ的HA方案)
镜像集群模式其实就是把需要的队列做成镜像队列,然后将镜像队列放在多个节点当中,这种镜像集群模式解决了普通集群模式没有做到的高可用性的缺点,镜像集群模式属于Rabbit MQ的高可用性的集群部署方案。
3.2.1、镜像集群模式的结构
镜像集群模式的结构如下图所示:
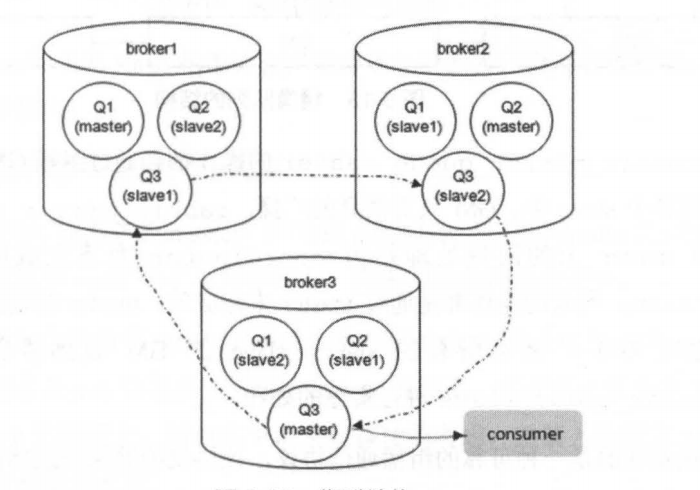
其中master是主节点(存放消息实体的队列),slave是从节点(镜像队列),一个主节点可以有多个从节点,消息实体 经过GM(Guaranteed Multicast)协议在主从镜像节点之间进行广播同步,这样无论哪一台服务器节点宕机了,其它服务器节点照样可以工作,它们的关系如下图所示:
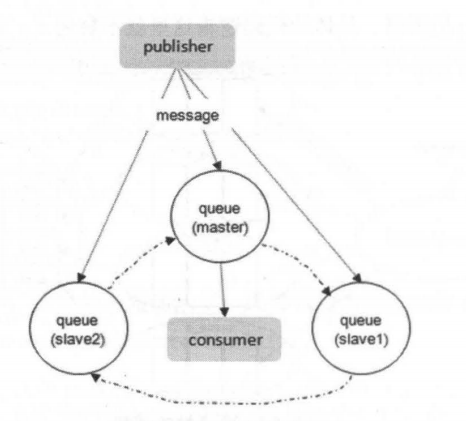
那么当master节点崩溃后,还有slave节点,slave节点会保存消息体,Rabbit MQ规定,当master节点宕机后,“资历最老”的 slave 会被提升为新的 master,根据 slave 加入的时间排序,时间最长的 slave 即为”资历最老”。
3.2.2、镜像队列间的消息流转
当消费者与master队列建立连接,消费者可以直接从master队列上获取信息,当消费者与slave队列建立连接呢?消费者是从slave队列直接获取数据的吗?当然不是的,消息的流转顺序如下所示:
- slave队列先将消费者的请求转发给master队列
- 然后再由master队列准备好数据返回给slave队列
- 最后由slave队列将消息返回给消费者
那这样就会有一个疑问?消费者的请求都是由master队列进行处理的,那么消息的负载是不是不能够做到有效的均衡呢?
3.2.3、负载均衡
Rabbit MQ的负载均衡是体现在物理机器层面上的,而不是体现在内存中的队列层面的。这样解释吧,现在有3台物理机,需要创建3个master队列和6个slave队列, 消息的请求负载都在3个master队列上,那么只需要将3个master队列和6个slave队列均匀的分布在3台物理机上,这样在很大程度上实现了每台机器的负载均衡。当然每个master队列消息请求的数量可能会有不同,无法保持绝对的负载均衡。
3.2.4、消息的可靠性
RabbitMQ的镜像队列使用 publisher confirm 和事务两种机制来保证其消息的可靠性。在事务机制中,只有当前事务在全部镜像中执行之后,客户端才会收到 Tx Commit-Ok 的消息。同样的,在 publisher confirm 机制中,生产者进行当前消息确认的前提是该消息被全部进行所接收了。
3.2.5、镜像集群模式总结
镜像队列的引入可以极大地提升 RabbitMQ 的可用性及可靠性,提供了数据冗余备份、避免单点故障的功能,因此推荐在实际应用中为每个重要的队列都配置镜像。
说了这么多的镜像队列的优点,那么镜像队列就没有缺点了吗?当然不是,那么镜像集群的缺点是什么呢?
首先镜像队列需要为每一个节点都要同步所有的消息实体,所以会导致网络带宽压力很大。 提供了数据的冗余备份,会导致存储压力变大,可能会出现IO瓶颈。
4、总结
普通集群模式增加了RabbitMq系统的吞吐量,但不能实现系统的高可用,如果磁盘节点崩溃可能会导致数据丢失,不能再对队列、交换器、绑定关系、用户进行更改,更改权限、添加或删除集群节点也不能操作。镜像集群模式是RabbitMq的HA部署方案,极大地提升 RabbitMQ 的可用性及可靠性,提供了数据冗余备份、避免单点故障的功能。但是镜像队列需要为每一个节点都要同步所有的消息实体,所以会导致网络带宽压力很大。 提供了数据的冗余备份,会导致存储压力变大,可能会出现IO瓶颈。具体怎样选择还需要使用者根据实际的业务场景选择合适的部署方案。

