- 1高效提升效率之sourcegraph的IntelliJ使用方式
- 2M-Arch(12)第十一个示例:如何用无源蜂鸣器播放音乐
- 3Java实现连接SQL Server解决方案及代码_java连接sqlserver数据库代码
- 4ChatGPT 成为 Nature 年度十大人物,首个非人类实体
- 5【机器学习-19】集成学习---投票法(Voting)_分类器性能差距大,使用软投票
- 6美团校招机试 - 小美的MT(20240309-T3)
- 7C++——预处理器_vs 预处理器 定义值
- 8GitHub本地上传文件_如何把本地文件夹上传到github中
- 98579 顺序表逆置 SCAU 华南农业大学 数据结构实验(个人笔记 勿喷)_scau链表逆序
- 10探索数据新境界:ScrapeGraphAI,一键触发智能网络抓取革命
浅谈词嵌入(word embedding)_两个单词能不能做词嵌入
赞
踩
今天在李宏毅老师的公开课上学习了word embedding,中文就是词嵌入的意思。故将学习内容整理一下,方便以后回顾。
1. 引入
计算机如何理解一句话,一篇文章的意思呢?计算机是用来做数值运算的,故需要将单词或者词组转换成数字,才能进行存入计算机进行计算机。怎么将文字转化成数字呢?
第一种方法是:one-hot方法
比如说有cat,dog,apple三个词汇。那么就生成一个三维向量,每个词占向量里面的一个位置,cat:[1,0,0] dog:[0,1,0] apple:[0,0,1]。那么假如现在一篇文章有1000个单词,那么每个词汇就要用一个1000维的向量来表述,其中只有单词所在的位置是1,其余位置全部是0,每个单词向量之间是无关的。这样做的好处是简单,但是不太符合现实情况。它忽略了单词之间的相关性,忽略了英语单词的时态,比如get和got都是一个意思,只是时态不一样而已。
第二种方法:word embedding方法
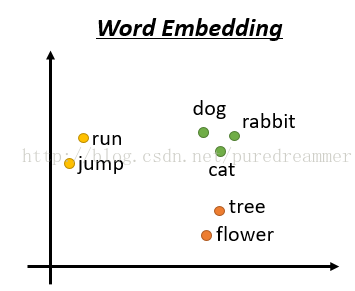
依旧是假设现在有一篇文章有1000个单词,但是我们现在不用1000维来表示,而是把这1000个单词映射到100维或者其他较小的维度,然后每个单词就是一个100维的向量。每个向量并不像one-hot方法那样都是稀疏的,而是都有具体的值。如下图所示,将这几个单词映射到2维空间。我们可以看到,映射后的两个单词如果在语义上比较相近,比如run和jump,都是动词,dog和rabbit都是动物。那么着两个单词的词向量(单词所在的点与原点连接的直线所在的向量)就离得比较近。这样做的好处就是同义词或者时态不同的词它们的词向量就会很接近,保留了文章的语义。
此外,词嵌入还有一个特性,可以做类比,比如
V(“hotter”) - V(“hot”) ≈V(“bigger”) - V(“big”)
V(“king”) - V(“queen”) ≈V(“uncle”) - V(“ant”)
这些都是语义空间的线性关系,可以做加减法,例如:
V(“hotter”) ≈V(“bigger”) - V(“big”) + V(“hot”)
1. 如何做词嵌入
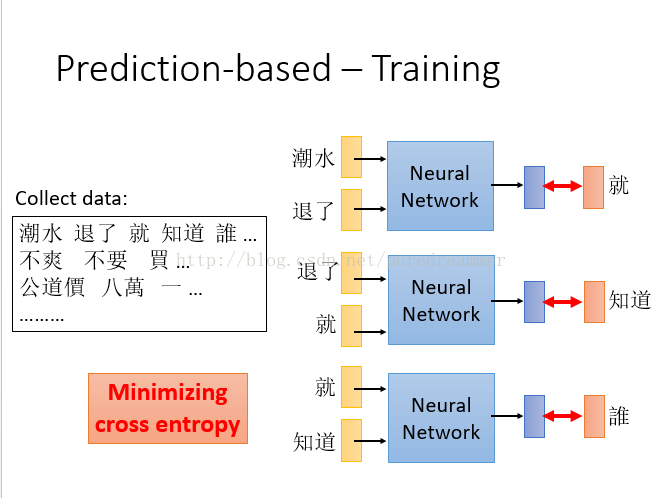
如图所示,将一篇文章的词输入神经网络,而将两个词后面的词作为结果进行训练。这样就会得到一个能够预测后面将要出现的词汇的神经网络。实际中可以用前一个或者前n个词汇作为输入,不一定是两个,这里只是举例而已。当用前几个单词来训练的时候,可以共享参数来加快训练速度和简化模型。如下图所示

我们可以看到,神经网络中的Z1,Z2…..就是我们刚才提到的降维后的词向量。
2. 最后
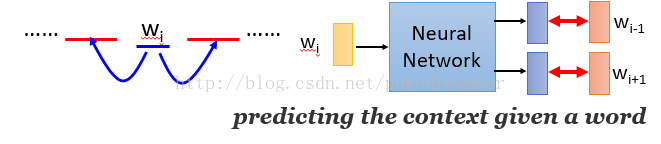
在实际应用中,除了用前面的单词预测后面的单词之外,还有其他的训练和预测方法
·用周边单词去预测中心单词的方式 Continuous Bag of Words(CBOW)

·用输入单词作为周边单词去预测中心单词的方式 The Skip-Gram Model