
- 1Spring Boot(五十五):基于redis防止接口恶意刷新和暴力请求_spring redis 防止恶意刷新
- 2编程练习的网站_pintia.cn
- 3Wireshark数据包分析——Slammer蠕虫攻击_sql蠕虫王(slammer)是利用什么漏洞进行传播的?该漏洞补丁是什么时候发布的?说
- 4python程序开机自启动_一键开机启动添加(python)_开机启动python脚本
- 5Python程序设计——文件操作(需要继续研究研究)_如何在d盘创建python文档
- 6(附源码)计算机毕业设计ssm餐厅管理系统_毕业设计主要功能图
- 7项目管理/Bug管理/问题管理—Phabricator_phabricator differential unit 配置
- 8【无人机编队】基于动态窗口法实现的无人机编队目标分配及路径规划问题研究附matlab代码_dwa算法用于编队
- 9Midjourney以图生图的详细教程(含6种案例介绍)_midjourney图生图
- 10AI加持,openEuler打造数字基础设施全场景操作系统
【AI】Stable-Diffusion-WebUI使用指南
赞
踩
注:csdn对图片有审核,审核还很奇葩,线稿都能违规,为保证完整的阅读体验建议移步至个人博客阅读
最近AI绘画实现了真人照片级绘画水准,导致AI绘画大火,公司也让我研究研究,借此机会正好了解一下深度学习在AIGC(AI Generated Content)----人工智能自动内容生成领域的应用。
AI绘画是AIGC领域的一个方向,AIGC有技术方向,其中比较火的有Txet-to-Image,Text-to-Video,Text-to-Speech技术,这三种技术都已经有了比较成熟的落地产品,但AIGC对算力的要求极高,一般的消费级显卡根本玩不起,而Stable-Diffusion模型的出现使Text-to-Image技术进入消费级显卡成为了现实,我自己测试过的最低配置是NVIDIA GeForce GTX 1660 Ti 6G + Intel® Core™ i7-9750H可以实现512x512图像分级的出图速度,即根据步数的不同3-5分钟出一张,测试的最高配置是NVIDIA GeForce RTX 3080 Ti 12G + Gen Intel® Core™ i7-12700K可以实现512x512秒级的出图速度,即根据步数的不同2-10秒出一张图。这已经是吊炸天级别的优化了。
我们讨论的就是基于Stable-Diffusion模型实现的NovelAI,一款开源软件。
我一直认为要想用好一个工具首先要知道它是怎么工作的,所以我们从AI绘画原理来入手,当然本人在接触NovelAI之前没有接触过AI,所以本文只是一些自己在学习的过程中的一些浅显的理解。
一、AI绘画原理
这里原理学习参考了:
【AI绘画】大魔导书:AI 是如何绘画的?Stable Diffusion 原理全解(一);
1.流程预览
NovelAI绘画的流程主要分三个步骤,TextEncoder(Clip),Diffusion(UNet+Scheduler),ImageDecoder(VAE),首先来看一下整体的流程:
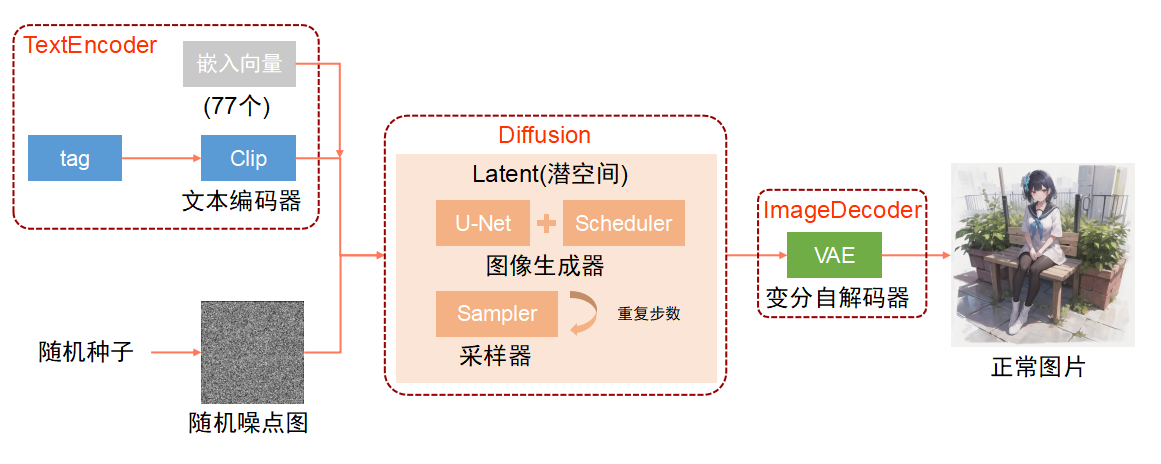
2.TextEncoder
学过编程的都知道,机器是无法直接理解自然语言的,而我们输入的描述tag是自然语言,机器自然无法直接理解,所以首先需要经过一次文本编码,将自然语言编程成机器能够理解的字节码,Stable-Diffusion模型采用了Clip中文本编码器,Clip(Constastive Language-Image Pretraining)是OpenAI开源的一个深度学习模型,由图像编码器和文本编码器组成,基于图像和文本并行的多模态模型,通过图像与文本两个分支的特征向量的相似度计算来构建训练目标,形成图像-文本对,以达到Text-to-Image的技术实现。
Clip将文本转换成的字节码在WebUI上的表现形式就是一串数字,在我使用的版本的WebUI上有一个词元分析器(Tokenizer)就是使用Clip的文本编码器,可以将文本编码成字节码并以数字的形式显示在WebUI上,也可以将数字编码成文本。这串数字是给Clip中的Text Transformer使用的,Text Transfomer会根据这串数字来解析文本对应的图像的生成条件。
通俗来说,Clip干的活就是将文本解析成机器能理解的语言,然后机器根据自己的理解搜索文本在机器的记忆中对应的画面图像,然后向Diffusion提供生成图像的条件。
这个过程中Clip有加入77个嵌入向量,Clip会固定占用两个,所以Clip所能接收的最大词元个数就是75个,这里说的是词元的数量,而不是tag的数量,比如我们在WebUI中输入3个字母dlg,Clip从中解析出来了两个词元,标签也会显示词元最大容量和当前使用数量。

我们通过词元分析器也可以分析出dlg对应的两个词元:

3.Diffusion
Stable Diffusion在Diffusion模块相对于以前的AI绘画的重大突破就是将扩散模型的核心计算从像素空间(即像素的集合)转换到了潜空间(图像的压缩数据),当模型计算一张512x512的图时,在潜空间中做核心部分的计算用的是一张更小的经过特殊编码的图,如64x64的特殊编码过的图,这可以使计算任务最重的核心计算的计算量大大的减小,并且出图速度提升100倍。
Stable Diffusion是以去噪的形式来绘制一张图片,在WebUI中的随机种子(seed)就是用来产生一张随机噪点图的,噪点图包含了大量的无规则的像素信息,Diffusion出图的过程就是将随机噪点图中按照Clip给出的出图条件给噪点图去噪的过程。
对于去噪可以阅读这边博客:图像处理——去噪 - E-Dreamer。
去噪的过程先是通过U-Net模型根据图像的生成条件从数据集中提取符合要求像素特征,一张图像的像素特征有很多的维度,如:像素的空间分布,像素颜色特征等,不同类型,不同场景的图像像素的特征也不一样,所以像素的特征提取是一项很复杂的任务,Scheduler就是用来异步处理这些任务的调度器。
然后在特征提取完成之后,通过Sampler(采样器)对特征相关的图像数据进行采样,完成一次采样之后模型就会根据采样结果来调整像素在噪点图中分布,经过多次采样调整的重复,一张符合文本描述的图片变产生了。
不同步数对图像的影响:

在WebUI中的采样方法(Sampler)调整的采样的算法,采样步数(Sampling steps)调整的就是采用重复的次数,提示词相关性(CFG Scale)调整的就采样的方向,数字越大就会越严格的按照提示词采样,越小则采样的随机性越强。
不同CFG Scale对图像的影响:

对于U-Net参考了:用U-Net做Auto-Encoder图像重建。
4.ImageDecoder
经过Diffusion的步骤,一张符合文本描述的图片实际上已经生成了,但是这张图片是在潜空间中进行计算得出的一张被特殊编码过的图片,是没办法直接进行观看的,所以需要ImageDecoder来进行图片解码,解码完成之后就得到了一张正常的图片了,然后将图片输出出来。
二、在本地部署(Win10)
首先AI绘画有很多的应用,比较有名的如:DALL-E 2、Midjourney、Stable Diffusion、Disco Diffusion、NovelAI、盗梦师、文心·一格,有的使用的自己的技术,但大部分都是使用的Stable Diffusion的开源技术,之前我还把NovelAI和Stable Diffusionr当成是一个东西了,惭愧。
我们能在自己的电脑上部署AI绘图首先要感谢Stable-Diffusion的开源。
Stable Diffusion的开源库:CompVis/stable-diffusion: A latent text-to-image diffusion model (github.com)。
1.环境部署
Stable Diffusion只是提供一个模型,提供基础的文本分析、特征提取、图片生成这些核心功能,但自身是没有可视化UI的,用起来就是各种文件加命令行。
所以很多牛人就为Stable Diffusion制作了UI界面,其中功能最强的,也是最火的就是大神AUTOMATIC1111制作的WebUI了。
WebUI原工程:AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)。
WebUI已经整合了Stable Diffusion模型,直接克隆下来配置好运行环境就可以使用了。
运行环境实际上就两东西,一个克隆代码仓库的Git,一个Python3.10以上的Python环境。
Git直接去Git官网下一个就好了,安装好之后,我们在任意文件夹内右键是可以看到Git bash here和Git GUI here两个右键菜单的。
我们选择Git Bash here,键入:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- 1
就可以将源码下载到当前文件夹内了,下载速度很慢,毕竟WebUI本体有十几G,会科学上网的上梯子或者直接找一个国内镜像肯能更快一点。
这里推荐一个国内的镜像:Hunter0725 / Stable Diffusion Webui · 极狐GitLab (jihulab.com)。
然后去Python官网下载3.10以上的版本,WebUI作者推荐的是3.10.6,安装的时候记得勾选Add Python to PATH,否则WebUI会识别不到Python环境。
检测是否安装成功,可以在cmd中输入python -V,如果打印了Python的版本号则安装成功了。
然后我们双击WebUI根目录下的webui-user.bat就可以启动Stable Diffusion服务了。
如果此时提示还找不到Python环境或者电脑本地有Python环境,我们可以打开webui-user.bat文件,在Set PYTHON=之后填上自己安装的Python路径。
如果我们要跟换Python版本,或者电脑里装了多个Python版本,我们也可以修改webui-user.bat文件来指定使用的版本。
如果之前用其他的版本的Python跑过WebUI,现在想换另一个Python版本,操作和上面一样,并且需要将新版本的python.exe拷贝一份到venv/Scripts文件夹替换旧的exe。
这里我看一下webui-user.bat文件没一行的作用:
#设置python路径
set PYTHON=C:\Users\UserName\AppData\Local\Programs\Python\Python310\python.exe
#设置git的路径
set GIT=E:\git\bin\git.exe
#设置venv文件夹路径
set VENV_DIR=E:\stable-diffusion-webui\venv
#设置启动参数
set COMMANDLINE_ARGS=--deepdanbooru --xformers
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在webui-user.bat第一次运行的时候,如果set PYTHON没有指定python路径会默认使用系统变量中的python来构建WebUI自己的虚拟环境,构建完之后,下次启动WebUI就会使用自己虚拟环境中的Python环境,位置在venv\Scripts。
下载完之后就可以双击webui-user.bat启动webui服务了,然后通过浏览器进入服务器地址就可以进入WebUI了。
但大多数时候很多库直接通过脚本基本下载不下来,这时候就只能手动下载下来了,具体可以参见第二小节。
由于墙的原因各种库总会出现链接不上库地址的情况,就算手动下载还要考虑webui使用的版本,所以建议还是使用整合包会方便很多。
我们可以在set COMMANDLINE_ARGS后添加--autolanch启用自动启动服务,在webui服务启动后会自动使用默认浏览器启动UI界面。
2.部署遇到的问题
在webui-user.bat下载依赖时经常会出现连不上git,导致下载失败,然后报Couldn’t install xxxx,没别的办法,我自己使用梯子也会出现连不上的情况,然后根据本地部署stable-diffusion-webui出现Couldn’t install gfpgan错误的解决方法 这个教程更改luanch.py中的源也一样。解决方法有两个,其一找到对应版本的依赖库,手动下载安装,其二多试几次,总有一次能成功,我就是跑了好几次成功了一次,就ok了。
当然想要更方便,解压即用的,推荐秋叶大佬的整合,秋叶大佬甚至提供了启动器,这是一个功能强大的管理器,其中为我们整合了很多优秀的模型、Lora、插件等,并且集成了UI汉化,甚至可以选择Stable Diffusion的版本等等,总之功能很强大,当然整合包和启动器都是Windows版本的,在其他的环境下使用还得自己来。
GFPGAN安装不上
gfpgan是腾讯ARC开源的一个库,也不知道为什么开不开梯子,WebUI都无法自行安装这个库,解决办法就是手动安装。
使用git将库clone到stable-diffusion-webui\venv\Scripts目录下,然后进入GFPGAN目录,依次次执行
E:\stable-diffusion-webui\venv\Scripts\python.exe -m pip install basicsr facexlib
E:\stable-diffusion-webui\venv\Scripts\python.exe -m pip install -r requirements.txt
- 1
- 2
安装GFPGAN的依赖库,安装完之后执行
E:\stable-diffusion-webui\venv\Scripts\python.exe setup.py develop
- 1
安装GFPGAN,然后再启动webui时就会检测到已安装,从而跳过自动安装。
clip安装不上
原因也是自动连接时连接不上clip库,解决方法同样是手动安装,将open_clip库clone到stable-diffusion-webui\venv\Scripts目录下,然后进入open_clip目录,然后执行
E:\stable-diffusion-webui\venv\Scripts\python.exe setup.py build install
- 1
再启动webui,如果还是提示要安装clip,说明clip没有安装上,上面的命令会构建并安装clip,但不知道为什么我没安装上,于是只能之际再手动安装一次了,可以执行
E:\stable-diffusion-webui\venv\Scripts\pip.exe install clip
- 1
然后再启动webui时就会检测到已安装,从而跳过自动安装。
缺少xxx模块
大多数情况都是WebUI在Installing requirements for Web UI时由于网络原因没装上,比较便捷的解决办法就是多跑几次,总有一次能安装上,或者也手动安装。
repositories中所用到的库下载失败
所有的库如果都下载不下载,就只能全部手动下载了,一共六个库
这个是AI绘图的核心库,Stability-AI公司开源的stablediffusion,直接通过git克隆到repositories目录,克隆下来的库存在stablediffusion目录下,由于还有另一个库叫stable-diffusion,所有AUTOMATIC1111把库命名成了stable-diffusion-stability-ai,所以我们要把库的目录名改成stable-diffusion-stability-ai。
k-diffusion-sd库AUTOMATIC1111命名为了k-diffusion,同样也要把库目录名改过来。
启动时报ImportError:Bad git executeable
打开venv\Lib\site-packages\git\cmd.py文件在from git.compat import前一行加入一行os.environ['GIT_PYTHON_REFRESH'] = 'quiet'。
库的hash值不确定
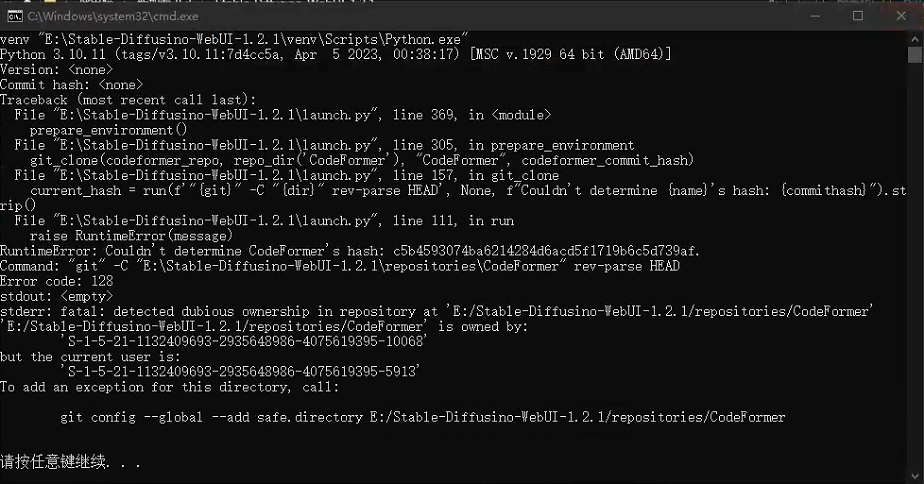
这种情况我只在迁移软件的过程中遇到,解决办法就是使用git,按照提示的命令把所有不确定hash值得库都执行一边就可以了,需要注意的是需要在电脑中安装git执行命令才生效,我没安装git的直接使用秋叶整合包里的git文件执行指令没效果。
3.注意事项
在开了梯子的情况下,UI界面有概率出现与服务器通信中断的问题。
三、WebUI文件夹功能
这里只说明一些我们会使用的文件夹的作用,不使用的就略过了。
-
embeddings:存放美术风格文件的目录,美术风格文件一般以
.pt结尾,大小在几十K左右; -
extensions:存放扩展插件的目录,我们下载的WebUI的插件就放在这个目录里,WebUI启动时会自动读取插件,插件目录都是git库,可以直接通过git更新;
-
extensions-builtin:存放WebUI内置的扩展;
-
models/hypernetworks:存放风格化文件的目录,风格化文件是配合Prompt使用的,以使AI会出对应风格的图片,风格化文件也以
.pt结尾,大小在几百MB左右; -
models/Lora:存放Lora的文件的目录,Lora文件是用来调整模型的,可以重映射模型文件的Prompt映射,使AI在相应的提示词下按照Lora的样式绘制,Lora文件一般以
.safetensors结尾,大小在几百MB左右; -
models/Stable-diffusion:存放模型的文件的目录,AI绘画时的采样基本从这个文件里采,影响图片的整体样式与画风,一般以
.ckpt或.safetensors结尾,大小在几个G左右; -
models/VAE:存放VAE文件的目录,VAE文件会影响图片整体的色调,如在刚开始玩WebUI时画出的图都比较灰,就是因为WebUI默认没有为我们设置VAE导致的,VAE文件一般以
.ckpt或.vae.pt结尾,大小在几百MB或几个G不等; -
outputs/extras-images:AI放大的原图的默认保存路径;
-
outputs/img2img-grids:批量图生图时的缩略图原图的默认保存路径;
-
outputs/img2img-images:图生图的原图的默认保存路径;
-
outputs/txt2img-grids:批量文生图时的缩略图原图的默认保存路径;
-
outputs/txt2img-images:文生图的原图的默认保存路径;
这些路径我们是可以在WebUI的设置界面修改成自定义路径的。
-
scripts:存放第三方脚本的目录;
-
venv:这个文件夹是WebUI首次运行时配置运行环境自己创建的,出现运行环境的问题时,可以删掉它让WebUI重新生成。
四、WebUI界面说明
这里以无第三方插件的原版的WebUI界面为例,使用了整合包或安装了第三方插件的界面会有所不同。
本节参考了:
AI绘画指南 stable diffusion webui (SD webui)如何设置与使用 — 秋风于渭水;
使用Automatic1111的WebUI的菜鸟指南:稳定扩散 ;
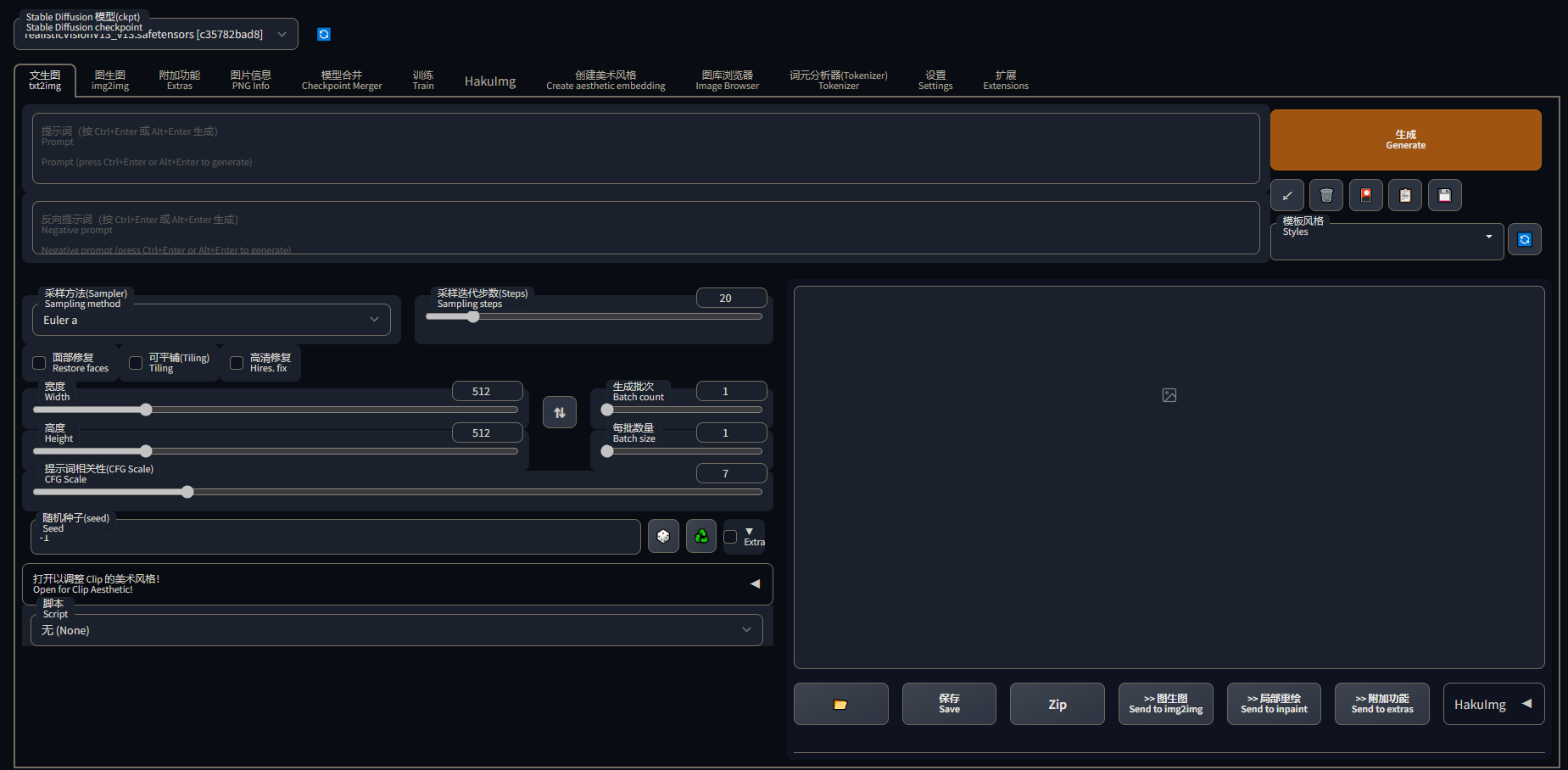
1.文生图(txt2img)
-
Prompt:正向提示词;
-
Negative prompt:反向提示词;
-
在Generate(生成)下有一排按钮:

箭头(第一个按钮):从提示词中提取通用的提示词,一般用于使用别人的提示词时过滤掉一些别人个性化的提示词;
垃圾篓(第二个按钮):快速清除提示词;
图画(第三个按钮):打开Textual Inversion、Hypernetworks、Checkpoints和Lora的管理界面,点击文件可以往提示词中加入对应的风格化应用;
文件(第四个按钮):这个按钮的功能是配合第五个按钮一起使用的,可以选择下方Styles下拉列表中已经保存起来的提示词模板应用到提示词中;
存储(第五个按钮):存储当前Prompt和Nagetive prompt的提示词作为提示词模板,存储好的提示词模板命好名后可以在Styles下来列表中看到,提示词模板存储在WebUI根目录的
styles.csv文件中,目前WebUI没有提供在UI中删除提示词模板的功能,想要删除不需要的提示词模板,我们需要通过修改styles.csv文件。 -
Sampling method(采样方法):生成图片时的采样算法;
-
Sampling steps(采样步数):生成图片时的采样重复次数;
-
Restore faces(面部修复):主要用于生成真人图片时对人脸进行算法修复,让人脸更接近真实的人脸,当画二次元图人脸崩坏时也可以使用这个选项来修复;
在Settings(设置)/Face restoration(人脸修复)中可以选择人脸修复的算法,目前WebUI只整合了CodeFormer和GFPGAN两种算法,默认是没有启用任何算法的,需要我们自己手动去启用,Code Former weight parameter参数可以调整算法的权重,注意:0是最大权重效果,1是最小权重效果,和我们常见权重是反过来的。
-
Tiling:是一种优化技术,对于性能比较差的机器可以勾选上来降低显存的占用,提高出图速度,对于性能足够的机器就不用勾选了,勾选了反而会起到反作用;
-
Hires.fix(高清分辨率修复):用于提高分辨率的优化,最大可以将分辨率提升4倍,512x512可以直接提升到4K;
由于Hires.fix是在AI画完一张图之后再进行优化的,要对细节进行补充,所以会对图片进行一定维度的重绘,所以对原有的图会有一些改动,不过这对文生图来说没有任何影响。Hires.fix也有一些自己参数:
Upscaler(放大算法):优化采用的放大算法,其中提供了很多内置的算法,同时我们也可以在Settings(设置)/Upscaling(放大)中添加没有预制出来的ESRGAN算法,里面有一个算法R-ESRGAN 4x+ Anime6B据说对二次元图的放大效果比较好;
Hires setps(高清修复的步数):和采样步数的效果一样;
Denoising strength(重绘幅度):重绘幅度就是Hires.fix在重绘细节的时候,AI的自由发挥空间,值越大AI就越放飞自我,值越小,AI就越按照原图重绘。
Resize width to(将宽度调整至)/Resize height to(将高度调整至):直接将图片放大至指定分辨率,和放大倍率是冲突的。
-
Width(图片宽度)/Height(图片高度):设定图片的分辨率;
-
Batch count(生成批次):批处理次数,设定同时处理多少批图片生成;
-
Batch size(每批数量):每次批处理同时生成的图片数量,最大值为8,需要根据自己电脑的显存大小来调节,如我的12G显存就没办法同时出8张1024x1024分辨率的图,只能同时出4张;
-
Seed(随机种子):用来设置用于AI去噪的噪点图,一个随机数唯一对应一张噪点图,默认值是-1,表示使用随机数,也可以设置一个随机数,来规定AI画同样的图。
Seed也有两个自己的参数,勾选Seed后面的Extra复选框可以编辑。
Variation seed(差异随机种子):组要用于在确定好一个自己比较想要的图片结构之后,设置好随机种子,然后通过设置差异随机种子,让AI在这张图的基础上每次画出有一点点区别的图;
Variation streenght(差异强度):控制AI在一张图的基础上出图的差异变化的强弱。
Resize seed from width/Resize seed from hright:控制AI绘图时在当前分辨率往指定分辨率的图靠近,实际使用过程感觉没什么卵用。
差异随机种子的另一种用法是,在出了一张构图很好的图时,通过图生图锁定随机种子和差异随机种子,然后调整差异强度,使差异随机种子出现一些细微的变化,来细微的调整出图效果,可以随机生成构图类似而又不同的图片。
-
CFG Scale(提示词相关性):控制AI是否严格按照提示词来绘图,越小AI绘画越随意,越大AI就越严格的按照提示词出图;
-
Script(脚本):用来启动第三方脚本,WebUI内置了三个脚本。
X/Y/Z plot:可以用来批量处理同一提示词在不同维度之间的效果,如不同的采样方法,不同的采样步数或者不同的提示词相关性等,用来测试不同维度的参数变化对出图的影响,以寻找最佳的图片质量的参数配置。
如不同采样算法在不同采样步数的情况下对图片的影响:

具体的可以参考这篇博文:
Stable Diffusion WebUI 小指南 - X/Y/Z Plot。
Prompt matrix(提词矩阵):用来分割不同关键词对图片的影响,操作方法就是通过|来分割关键词,如:
(masterpiece:1.3), (the best quality:1.2), (super fine illustrations:1.2), (Masterpiece)|, 1girl,black hair|, Sailor suit,Pleated shirt|,huge breasts,white pantyhose
- 1
Prompt matrix就会按照分割的关键次一次组合来绘制不同组合的出图效果:

这里参考了这篇博客:
AI绘画教程(3)基础篇-SDWEBUI的基础功能,你都会用了吗?。
Prompts from file or textbox:用于批量出图的工具,我们可以在List of prompt inputs(提示词输入列表)中输入提示词,也可以从文本中输入提示词,脚本会自动将文本的提示词填入提示词输入列表,然后勾选Iterate seed every line(每行使用一个随机种子)或Use same random seed for all lines(每行使用相同的随机种子),来达成每一行作为一份提示词输入来生成对应的图片。
2.图生图(img2img)
图生图界面上半部分、下半部分和文生图基本一样,只有中间部分不一样,上半部分多了两个按钮。
-
Interrogate CLIP(CLIP反推提示词):使用CLIP模型从图片中反推图片用到的正向提示词;
-
Interrogate DeepBooru(DeepBooru反推提示词):使用DeepBooru模型从图片中反推图片用到的正向提示词;
-
img2imge(图生图):全局图生图,AI会根据重绘幅度和原图进行创作;
-
Sketch(绘图):就是最简单的局部重绘功能,可以通过画面图绘区域,让AI只重绘所图的区域;
-
Inpaint(局部重绘):功能稍微强大一点的局部重绘,可以对蒙版进行操作,蒙版就是我们用画笔图黑的部分;
-
Inpaint sketch(手涂蒙版):手绘蒙版又是一个更强大的局部重绘,可以拾取画面中的像素颜色,以让AI识别要重绘的像素分布,能更精准的进行局部重绘;
-
Inpaint upload(上传蒙版重绘):这个功能主要是解决WebUI在绘制蒙版是的不精确,对想要精确选区的重绘区域使用WebUI的画笔很难精确的图绘,上传蒙版重绘则是通过上传一张与原图大小一致的黑白的蒙版图片来匹配原图,从而对原图进行重绘,这里要注意的是这里的颜色和Sketch、Inpaint的颜色刚好相反,Sketch是黑色区域为蒙版区域,这里这是白色区域为蒙版区域,如:我这里想重绘一下女孩身后的栏杆,我们就可以用PS将栏杆精确的选区出来,然后制作蒙版图,传到WebUI上来进行重绘:

-
Batch(批量重绘):指定一个输入文件夹和一个输出文件夹,就可以进行图片的批量重绘,如果指定了蒙版文件夹,还可以批量的使用蒙版图精确的进行局部重绘。
局部重绘还有一些自有的参数:
Mask blur(蒙版模糊):值越大重绘出来的区域越清晰,值越小重绘出来的区域越模糊;
Mask mode(蒙版模式):可以选择是重绘蒙版区域还是非蒙版区域;
Masked content(蒙版蒙住的内容):可以选择蒙版要蒙什么东西,可以是原图也可以是噪点等;
Inpaint area(重绘区域):可以选择要重绘的区域,感觉和蒙版模式的功能是一样的;
Only masked padding,pixels(仅蒙版边缘的预留像素):设定蒙版边缘预留多少像素不进行重绘,实际使用中没感觉出有什么作用。
-
Dinoising strength(重绘幅度):控制整个图生图过程中AI重绘过程的自由发挥程度,值越大AI重绘越随意,值越小AI重绘越接近原图。
-
Script(脚本):图生图除了拥有文生图的脚本外,还拥有一些专用的脚本。
Lookback(回送):可以将这一次的生成图作为图生图的输入进行下一次绘制,这个功能对于线稿上色简直是神助攻。
启用后会多出几个设置选项:
Loops:控制回送的次数;
Final denoising strength:最终重绘强度,是叠加在图生图的重绘强度之上的,第一次回送使用的实际重绘强度=[重绘强度]×[最终重绘强度],之后每一次回送时使用的[实际重绘强度]=[上一次实际重绘强度]×[最终重绘强度];
Denoising strength curve:可以选择脚本重绘强度的变化曲线,脚本为我们内置了三个曲线;
Append interrogated prompt at each iteration:为每一次回送自动反推图片提示词并应用;
Outpainting mk2(向外绘制第二版):可以将图片进行一定像素方位内的扩展,实测,发现脚本与双语对照插件存在冲突,启用双语对照插件后,扩展绘制的效果很差,关闭之后,效果就会变得很好;
SD upscale(SD 放大):这就是一个依赖于图生图的分块放大算法,可以使用更少的显存达到4K图的放大效果,实测放大到最大的4K,只需要5G+显存,放大效果回收重绘强度影响和提示词影响;
controlnet m2m(ConteolNet视频转绘):视频生成的脚本,转的视频效果比较渣,就不过多累述了,可以参见这个视频:【AI绘画进阶教程】制作跳舞小姐姐 m2m和mov2mov哪家强?。
3.附加功能(Extras)
附加功能界面主要是用来做图片放大用的。
-
Scale by(等比放大):按原图长宽各乘以相同比例来放大图片;
-
Scale to(按分辨率放大):可以将原图放大成任何比例,如正方形图可以被放大成长方形图,勾选Crop to fit,AI会自动为我们裁剪,不勾选则不会按照指定的分辨率放大,会默认用回等比放大;
-
Upscaler 1(升频器1)/Upscaler 2(升频器2):AI做图片放大时会处理两次,两次可以分别采用不同的放大算法,不同的算法放大效果不一样,所以WebUI做两次放大,以便组合不同放大效果达到更好的放大效果。
-
Upscaler 2 Visibility(升频器2可见度):用于设置第二次放大时使用的算法在放大过程中的权重;
-
GFPGAN visibility(GFPGAN模型可见度)/CodeFormer visibility(CodeFormer模型可见度)/CodeFormer weight(CodeFormer权重):这三个选项都是用来调整图片放大时对图片的修复作用的,GFPGAN和CodeFormer模型在前面文生图的Hire.fix中也有用到,主要作用就是用来做图片修复的,调整可见度就可以调整两个模型混合使用的程度,CodeFormer还可以更精细的调整权重,0表示最大权重,1表示最小权重。在我自己的测试中,两个模型对二次原图片的修复效果基本一致,在相对拟真的图片中存在差异,我们可以看一下两个模型的修复效果:
GFPGAN visibility=1,CodeFormer visibility=0,CodeFormer weight=0:

可以看到GFPGAN对纹理的修复还是可以的,但是对皮肤的纹理修复有点过度磨皮的刚觉了。
GFPGAN visibility=0,CodeFormer visibility=1,CodeFormer weight=0:

CodeFormer则是对皮肤纹理的修复更真实自然,但对其他的物体的纹理修复就不如GFPGAN,并且对五官有过度修复。
GFPGAN visibility=0.5,CodeFormer visibility=0.5,CodeFormer weight=0.5:

将二者结合后的效果,要好很多。
-
Batch Process(批量处理)/Batch from Directory(从目录进行批量处理):两个都是对图片放大做批量处理的。
本节参考了帖子:
GFPGAN and CodeFormer - seperately and together. : StableDiffusion。
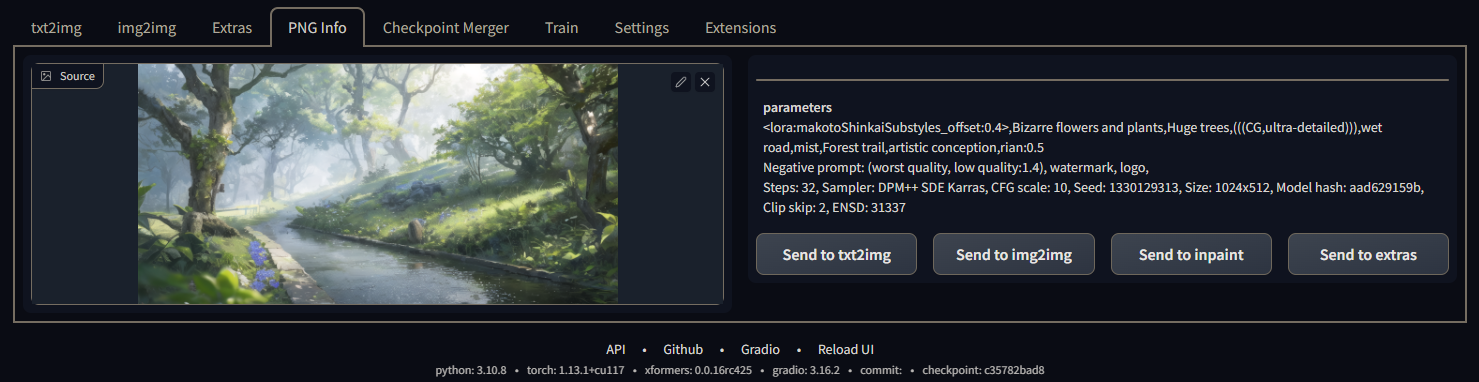
4.PNG图片信息(PNG Info)
PNG图片信息就是一个更强大的CLIP反推提示词,它可以将没有经过处理的AI生成的原图反推出生成这张图所有的所有参数,包括正反向提示词、采样步数、采样方法、提示词相关性、随机种子、尺寸、所用模型的hash值、Clip跳过的次数还有一个不知道有什么用的ENSD。
5.模型合并(Checkpoint Merger)
模型合并界面主要使用来合并模型的,具体参数后面在模型合并的章节一起讲。
6.训练(Train)
训练界面是专门用来做模型训练用的,具体参数也在后面模型训练的章节一起讲了。
7.设置(Settings)
设置界面的参数就太多了,建议弄一个汉化,或者用整合了汉化的整合包,大部分参数在汉化之后看一下名字就知道是作用了。
然后可以配合这个双译插件一起使用:sd-webui-bilingual-localization/README_ZH.md at main · journey-ad/sd-webui-bilingual-localization。
两个插件都安装之后的界面是这样的:
8.扩展(Extensions)
用来管理第三方插件的界面,所有安装的扩展,包括WebUI内置的都会在Installed(已安装)栏中显示,并且可以直接管理插件的更新。更新插件的时候需要确保自己的网络能连接得上github库,其实也没什么卵用,就算梯子没毛病,也经常连不上git库。
Available(可用):这是直接连接https://raw.githubusercontent.com/wiki/AUTOMATIC1111/stable-diffusion-webui/Extensions-index.md扩展列表,我们可以点击(加载自)来刷新扩展列表,然后从这里来下载列表里的第三方插件,实际测试基本上装不了。
Install from URL(从网址安装):用来安装扩展列表里没有的第三方库,就是用来给不会用git的人使用的。实际上也基本连不上git库,评价是不如直接用git来得舒服。
五、提示词原理
提示词不同的绘画程序会有所在区别,这里以webui为主。
本节参考了这几篇博文:
1.提示词的顺序
对于提示词对画面的影响,我们首先想到,也是最直观看到的自然就是提示词的顺序,AI对越靠前的提示词就越重视,我们可以做个实验来看看效果:

图1作为参考图,
图2:深林(Forest)被放置在首位,AI绘制的画面开始着重数目,草丛的特征被稀释,同时落叶增加了;
图3:林间小道(Forest trail)被放置在首位,AI绘制的画面小路的细节被增加;
图4:落叶(fallen leaves)被放置在首位,AI绘制的画面中落叶的数量被大量增加;
图5:草丛(Grass)被放置在首位,AI绘制的画面草丛的特征被方法,树下均被绘制了茂密的草丛;
图6:秋天(Autumn)被放置在首位,AI绘制的画面开始大片的出现秋天的特征,树叶变得更黄了,落叶变得更多了,连女孩也开始套上了围巾,换上了秋季得衣服。
2.提示词的权重
在stable diffusion webui中提示词可以被增加权重,以提高AI对某些提示词的重视程度,sd webui支持两种为提示词加权重的方式,其一使用英文小括号(),括号可以无限叠加,如:((Autumn))其二使用英文小括号加权重,括号也可以叠加,如:(Grass,(Autumn:1.3)),一个括号代表为提示词增加1.1倍权重,叠加一个括号表示增加1.1*1.1倍的权重,依次类推,而指定了权重的方式则是直接为提示词增加指定的权重,如在(Grass,(Autumn:1.3))中,Grass被增加了1.1倍的权重,Autumn则被增加了1.1*1.1*1.3被的权重。使用指定式权重时必须使用一个括号括起来。
我们测试一下提示词权重

图2给秋天(Autumn)增加了1.1*1.1=1.21倍的权重,秋天的氛围变浓了;
图3给秋天(Autumn)增加了1.1*1.3=1.43倍的权重,秋天的特征变得更明显,连草地都变黄了。
需要注意的是在给提示词增加权重时也不是加高越好的,加得太高了反而会适得其反,而是要根据整个提示词组,相对权重来增加,比如图2的提示词组中秋天这个提示词加了两个括号后,相对权重已经是最高的了,就没必要再给秋天这个提示词加七八个括号上去了。
权重过高反而会使绘制的图崩坏:

3.提示词的形式
我们在使用提示词描述一个画面的时候,有多种形式,可以用单个的词语组合、可以用一段完整的句子、也可以用单词与短句的结合,不同的提示词形式又有什么影响呢?我们还是通过实验来看看。
我们来画一个“一个穿着白色运动衫和粉红色运动鞋的黄色短发的站在街上的女孩”,使用文生图的Prompts from file or textbox脚本分别生成三种类型的提示词的图。
单词组:
1girl,short yellow hair,white sweatshirt,pink sneakers,standing,in street,full body,looking at viewer,
- 1
完整长句:
A girl with short yellow hair in a white sweatshirt and pink sneakers standing in the street,full body,looking at viewer,
- 1
短语与单词组合:
short yellow hair,a girl in a white sweatshirt and pink sneakers,standing,in street,full body,looking at viewer,
- 1
出图结果:
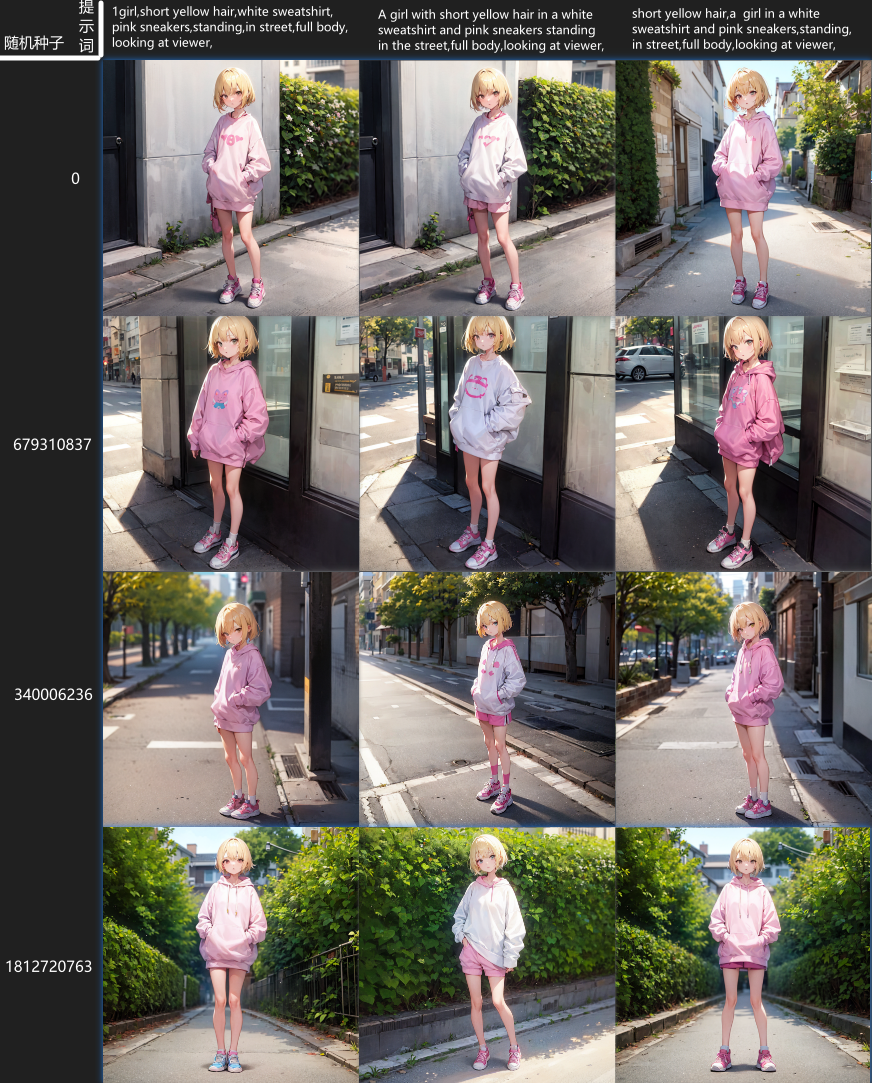
第一列:使用的是单词组提示词,画的四张测试图里面头发颜色都画对了,衣服颜色全部被子鞋子颜色污染没有一张是正确的,鞋子颜色也只有三张是正确的;
第二列:使用的是完整的长句提示词,画的四张测试图里面头发、衣服、鞋子颜色都正确;
第三列:使用的短句和单词组合的提示词,画的四张测试图里面头发颜色都正确,衣服杨色全部被鞋子颜色污染,鞋子颜色都正确。
现在不同类型的提示词的效果就出来了,很明显使用完整长句的提示词能很好的绑定物体的特征,短句与单词组合次之,单词组提示词绑定的最差。
不过大多数情况一个画面是很难使用一句完整的长句描述出来的,所以三种类型的提示词多数需要根据实际情况来选择使用。
4.分步描绘
stable diffusion支持多种分步绘制的语法,如:[a | b]、a | b、[a : b : 0.4]、[a : 10]、[a :: 10],a:0.5 AND b:0.6。
对主体的分步描绘
语法[a:b:0.4],假设采样步数为20,那么这个语法的意思就是前8步绘制特征a,后12步绘制特征b,分步描绘可以将多个提示词融合到一个主体上;
语法[a | b]和a | b,表示第一步画特征a,第二步画特征b,第三步画特征a,第四步画特征b,依次类推;
还是先来看一下实验:

不使用分步的(panda:0.4),(goblin:0.6)已经不知道在画什么了,使用可控分步的[panda:goblin:0.4]和均衡分步的[panda | goblin]的效果和我们先画大熊猫为整体画面定下结构然后往大熊猫身上添加哥布林的特征的预期比较接近,panda:0.4 AND goblin:0.6语法融合的感觉更加深入,有一种大熊猫和哥布林的杂交物种的感觉。
对修饰词的分布描绘
用于修饰某一主体的修饰词的混合和主体本身的混合又有一点细微的差别,我们渐变色头发为例,分步描绘渐变发色有两种方式,一种是分步描绘颜色,不分步头发,另一种是颜色和头发都分步描绘:

可以看到在不使用分步绘制1girl,red and blue hair,和1girl,red hair, blue hair,的情况下ai也能画出相应的颜色混合的头发,但是发色是直接硬拼接起来的,无论是只分步颜色还是颜色和头发都分步,效果是一样的;
在使用1girl,[red | blue] hair,和1girl,[red hair | blue hair],均衡分步绘制语法绘制的头发更接近正常的渐变色的染发 ;
在使用没有中括号的1girl,red | blue hair,和1girl,red hair | blue hair,均衡分步绘制语法绘制的头发 也有那么一点硬接的感觉,但是混合效果还可以,比不使用分步绘制的情况要好;
对于修饰词的分步描绘使用可控步数的语法1girl,[red:blue:0.5] hair,和1girl,[red hair:blue hair:0.5],则完全不起作用了;
使用AND语法的分步描绘1girl,red AND blue hair,和1girl,red hair AND blue hair,在只有分步颜色的情况下,AI直接做了红色和蓝色的混合,用混合后的颜色来作为头发的颜色了,在颜色和头发都分步描绘的情况下, 效果和使用中括号的均衡分步描绘的效果差不多了。
在我自己的使用过程中,分步描绘的混合效果很大程度上取决于大模型,比如测试发色混合时同一套提示词使用abyssorangemixAOM3模型混合的效果就很差,使用revAnimated模型混合的效果就很好。
指定开始步数和结束步数的分布描绘
语法[a : 10],表示从第10步开始画特征a;
语法[a :: 10],表示从第10步开始结束画特征a;
二者还可以结合[[a :: 16] : 4],表示从第4步开始,到第16步结束画特征a;
三者在出图效果上差别不大:

5.占位符
占位符指的是一些模型无法理解的符号或词语,这些符号或词语在模型中没有明确的特征与它们相关联,所以ai画不出这些符号或词语的特征,但是它们又会占用词元数量,这样的符号或词语对ai来说就是占位符,常见的占位符符号有:\ * + _等,词语可以是任何模型不理解的自造词。
占位词的一大作用就是拉开一个词元与另一个词元之间的距离,最常见的用法就是通过拉开词元距离来减少颜色污染,如:画一个一个穿着白色运动衫和粉红色运动鞋的黄色短发的站在街上的女孩,在使用的单词组的情况下颜色污染很严重,我们就可以使用占位词来拉开不用颜色词元之间的距离来避免颜色污染。

可以看到在使用占位符将white sweatshirt和pink sneakers的词元距离拉开之后,颜色污染被有效的避免了。
6.Emoji表情
Emoji表情也在stable diffusion webui的支持当中,并且能很精准的识别,比如在想让ai画出一些不太好描述的表情的时候,就可以使用emoji表情来控制。
(((声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/82815
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

