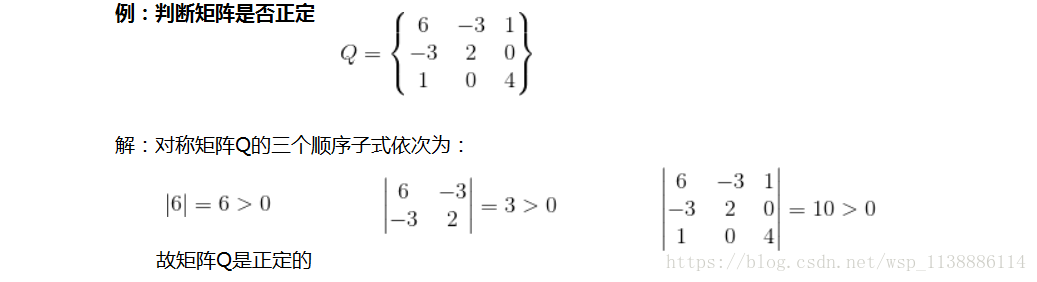- 1vs项目配置_vs项目属性配置
- 2oVirt快速安装指南_ovirt安装
- 3Kotlin入门之Kotlin中的设计模式_kotlin 设计模式
- 4ENSP实验抓取IP包分片_ensp抓包
- 5Linux开发工具详解
- 6pip 源更新为国内镜像_pip更新使用清华源
- 7Java学数据结构(2)——树Tree & 二叉树binary tree & 二叉查找树 & AVL树 & 树的遍历_java 树
- 8全网详细解决:无法将 “xxx” 项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次_telnet : 无法将“telnet”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。
- 92024年HarmonyOS鸿蒙最新HarmonyOS Next,你真的足够了解它么?_harmonyos next 开发语言,2024HarmonyOS鸿蒙高级面试题汇总解答_仓颉编程语言和arkts
- 10煤矿智能巡检机器人:推动煤矿行业变革的关键力量
协方差矩阵—Hessian矩阵—正定矩阵
赞
踩
一、基本概念
1.1 协方差矩阵 及推导
在统计学中用标准差描述样本数据的 “散布度” 公式中之所以除以 n-1 而不是 n,
是因为这样使我们以较少的样本集更好的逼近总体标准差。即统计学上所谓的 “无偏估计”。
关于 协方差 与 散度 :https://blog.csdn.net/wsp_1138886114/article/details/80967843
方差: v a r ( X ) = ∑ i = 1 n ( X i − X ˉ ) ( X i − X ˉ ) n − 1 var(X) = \frac{\sum_{i=1}^n(X_i-\bar{X})(X_i-\bar{X})}{n-1} var(X)=n−1∑i=1n(Xi−Xˉ)(Xi−Xˉ)
各个维度偏离其均值的程度,协方差: cov ( X , Y ) = ∑ i = 1 n ( X i − X ˉ ) ( Y i − Y ˉ ) n − 1 \text{cov}(X,Y) = \frac{\sum_{i=1}^n(X_i-\bar{X})(Y_i-\bar{Y})}{n-1} cov(X,Y)=n−1∑i=1n(Xi−Xˉ)(Yi−Yˉ)
协方差矩阵的计算:
c
o
v
(
z
)
=
(
1
2
3
4
3
4
1
2
2
3
1
4
)
j
cov(z) =

1.2 Hessian矩阵
Hessian矩阵定义:
若一元函数
f
(
x
)
f(x)
f(x) 在
x
=
x
(
0
)
x = x^{(0)}
x=x(0) 点的某个领域内具有任意阶导数,则
f
(
x
)
f(x)
f(x) 在
x
(
0
)
x^{(0)}
x(0) 点的泰勒展开式为:
f
(
x
)
=
f
(
x
(
0
)
)
+
f
′
(
x
(
0
)
)
Δ
x
+
1
2
f
′
′
(
x
(
0
)
)
(
Δ
x
2
)
+
⋯
(1)
f(x) = f(x^{(0)}) + f'(x^{(0)})\Delta x + \frac{1}{2} f''(x^{(0)})(\Delta x^2)+\cdots \tag{1}
f(x)=f(x(0))+f′(x(0))Δx+21f′′(x(0))(Δx2)+⋯(1)
其中: Δ x = x − x ( 0 ) , Δ x 2 = ( x − x ( 0 ) ) 2 \Delta x = x-x^{(0)},\Delta x^2 = (x-x^{(0)})^2 Δx=x−x(0),Δx2=(x−x(0))2
二元函数
f
(
x
1
,
x
2
)
f(x_1,x_2)
f(x1,x2)在
X
(
0
)
(
x
1
(
0
)
,
x
2
(
0
)
)
X^{(0)}(x^{(0)}_1,x^{(0)}_2)
X(0)(x1(0),x2(0))点处的泰勒展开式为:
1
2
[
∂
2
f
∂
2
x
1
2
∣
x
(
0
)
Δ
x
1
2
+
2
∂
2
f
∂
x
1
∂
x
2
∣
x
(
0
)
Δ
x
1
Δ
x
2
+
∂
2
f
∂
2
x
2
2
∣
x
(
0
)
Δ
x
2
2
]
+
⋯
(2)
\frac{1}{2}\left [ \frac{\partial^2f}{\partial^2x_1^2}|_{x^{(0)}} \Delta x_1^2 + 2\frac{\partial^2f}{\partial x_1\partial x_2}|_{x^{(0)}}\Delta x_1\Delta x_2+\frac{\partial^2f}{\partial^2x_2^2}|_{x^{(0)}} \Delta x_2^2\right ]+\cdots \tag{2}
21[∂2x12∂2f∣x(0)Δx12+2∂x1∂x2∂2f∣x(0)Δx1Δx2+∂2x22∂2f∣x(0)Δx22]+⋯(2)
其中: Δ x 1 = x 1 − x 1 ( 0 ) , Δ x 2 = x 2 − x 2 ( 0 ) \Delta x_1 = x_1-x^{(0)}_1,\Delta x_2 = x_2-x_2^{(0)} Δx1=x1−x1(0),Δx2=x2−x2(0)
将上述(2)展开式写成矩阵形式,则有:
f
(
X
)
=
f
(
X
(
0
)
)
+
(
∂
f
∂
x
1
,
∂
f
∂
x
2
)
x
(
0
)
(
Δ
x
1
Δ
x
2
)
+
1
2
(
Δ
x
1
,
Δ
x
2
)
{
∂
2
f
∂
x
1
2
∂
2
f
∂
x
1
∂
x
2
∂
2
f
∂
x
2
∂
x
1
∂
2
f
∂
x
2
2
}
∣
x
(
0
)
(
Δ
x
1
Δ
x
2
)
+
⋯
(3)
f(X) = f(X^{(0)})+\left ( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2} \right )_{x^{(0)}}
即为:
f
(
X
)
=
f
(
X
(
0
)
)
+
∇
f
(
X
(
0
)
)
T
+
1
2
Δ
x
T
G
(
X
(
0
)
)
Δ
X
+
⋯
(4)
f(X) = f(X^{(0)})+\nabla f(X^{(0)})^T + \frac{1}{2} \Delta x^T G(X^{(0)}) \Delta X +\cdots \tag{4}
f(X)=f(X(0))+∇f(X(0))T+21ΔxTG(X(0))ΔX+⋯(4)
其中:
G
(
X
(
0
)
)
=
{
∂
2
f
∂
x
1
2
∂
2
f
∂
x
1
∂
x
2
∂
2
f
∂
x
2
∂
x
1
∂
2
f
∂
x
2
2
}
∣
x
(
0
)
,
Δ
X
=
(
Δ
x
1
Δ
x
2
)
G(X^{(0)}) =
G ( X ( 0 ) ) G(X^{(0)}) G(X(0))是 f ( x 1 , x 2 ) f(x_1,x_2) f(x1,x2) 在 X ( 0 ) X^{(0)} X(0) 点处的Hessian矩阵。它是由函数 f ( x 1 , x 2 ) f(x_1,x_2) f(x1,x2) 在 X ( 0 ) X^{(0)} X(0)点处的二阶偏导数所组成的方阵。我们一般将其表示为:
H
(
f
)
=
[
∂
2
f
∂
x
1
2
∂
2
f
∂
x
1
∂
x
2
⋯
∂
2
f
∂
x
1
∂
x
n
∂
2
f
∂
x
2
∂
x
1
∂
2
f
∂
x
2
2
⋯
∂
2
f
∂
x
2
∂
x
n
⋮
⋮
⋱
⋮
∂
2
f
∂
x
n
∂
x
1
∂
2
f
∂
x
n
∂
x
2
⋯
∂
2
f
∂
x
n
2
]
H(f) =
简写成:
Q
H
e
s
s
i
a
n
=
[
I
x
x
I
x
y
I
y
x
I
y
y
]
\mathbf{Q_{Hessian}} =

1.3 Hessian矩阵 示例

1.3 正定矩阵定义及性质
在线性代数中,正定矩阵(positive definite matrix)简称正定阵。
定义:A是n阶方阵,如果对于任何非零向量x都有
x
T
A
x
>
0
x^TAx>0
xTAx>0就称A正定矩阵。